안녕하세요, 이번에 리뷰할 논문은 SAR 이미지를 위한 자기주도 사전학습법을 제안한 논문입니다. 현재 창의학기제와 기업과제가 모두 SAR Object Detection이기 때문에 논문에서의 인사이트가 도움이 될 만한 부분이 있지 않을까 싶어 읽어보게 되었습니다. SAR를 잘 모르시는 분들도 읽으시는 데 부담 없도록 관련 추가 설명을 곁들였으니 편하게 읽어주시면 되겠습니다..!
SAR
SAR(합성 개구 레이더)은 렌즈로 빛을 모으는 일반 카메라와 달리, 스스로 마이크로파(전파)를 쏘고 반사되어 돌아오는 신호를 측정해 이미지를 그리는 기술입니다. 가시광선에 의존하지 않기 때문에 구름이나 안개가 짙게 끼는 날씨 또는 태양빛이 없는 밤에도 지표면을 선명하게 관측할 수 있기 때문에 전천후 관측에 유리하다는 장점이 있습니다. 그렇기 때문에 SAR 이미지는 재난 감시, 국방 등에서 핵심적인 역할을 수행합니다.

하지만 전파가 다양한 표면에 부딪혀 반사될 때 파동 간의 간섭으로 인해, 파동 간 위상이 같아 보강 간섭이 일어난 부분과 위상이 달라 상쇄 간섭이 일어난 부분이 SAR 이미지 모래알 같은 노이즈를 발생시키는데, 이를 스펙클 노이즈(Speckle Noise)라고 합니다. 이 노이즈 때문에 SAR 이미지는 일반 광학 사진보다 대상의 형태를 직관적으로 파악하기 어렵고, 구조적인 세부 정보도 심하게 훼손됩니다. 따라서 딥러닝으로 SAR 이미지의 객체를 탐지하는 데에 있어 가장 큰 목표는 그러한 스펙클 노이즈에 강건한 특징을 모델이 어떻게 잘 학습할 것이냐 라고 볼 수 있겠습니다.

Introduction
이처럼 SAR 이미지는 기상 조건이나 밤낮에 구애받지 않고 데이터를 수집할 수 있지만 딥러닝으로 SAR 이미지를 학습시키기는 데에는 몇 가지 한계점이 존재했습니다. 우선 간단하게 데이터셋이 부족합니다. SAR 이미지는 국방 등 private한 목적으로 수집되는 경우가 많아 공개 데이터셋이 굉장히 적고, 이미지를 annotate해줄 사람도 부족하기 때문에 detection dataset은 더더욱 부족한 상황입니다. 저자들은 이로 인해 SAR 도메인에 대한 대규모 사전 학습이 불가능하다고 지적합니다. 또, SAR 특유의 기존의 SAR 사전학습 방법론들은 광학 이미지용 사전학습 전략을 그대로 차용하는데 SAR 특유의 스펙클 노이즈로 인해 일반 광학 이미지와는 물리적 다른 특성을 가지고 있어 알맞은 방식이 아니며, 그렇다고 SAR 데이터에만 의존하는 사전학습 패러다임은 정보가 풍부한 광학 이미지 등의 타 모달리티 가이드를 활용하지 못하기 때문에 학습된 representation이 downstream task에 적용될 만큼의 일반화 능력을 갖추기 못했다고 합니다.
위와 같은 문제를 해결하기 위해 저자들은 SAR representation learning을 위한 MAE(Masked AutoEncoder) 기반의 프레임워크인 SARMAE를 제안합니다. 먼저, 저자들은 SAR-1M 데이터셋을 구축하여 다양한 장면 및 객체 카테고리를 포괄하는 최초의 million-scale SAR 데이터셋을 제안했습니다. 본 데이터셋은 SAR 이미지와 더불어 지리적으로 align된 광학 이미지도 추가하여 대규모 사전 학습을 목표로 했습니다. Speckle-Aware Representation Enhancement (SARE) 모듈을 통해 사전 학습 과정에서 원본 이미지에 스펙클 노이즈를 명시적으로 통합하고, 이 노이즈가 포함된 이미지를 masking시킨 채로 AutoEncoder에 넣어 masking된 부분을 복원하도록 학습시킴으로써 모델이 스펙클 노이즈에 강건한 특징을 학습할 수 있도록 설계했습니다. 마지막으로 Semantic Anchor Representation Constraint (SARC)는 광학 이미지가 가지는 ‘의미적 풍부함’을 활용하기 위해, SAR-1M에서 짝을 이루는 광학 이미지의 사전 지식(prior)과 SAR의 represenation을 정렬시켜 인코더 학습을 가이드함으로써 의미적 일관성을 확보하고 일반화 성능을 향상시켰습니다. 결과적으로 SARMAE는 이러한 방법론들은 통해 Classification, Detection, Segmentation 등의 다양한 SAR downstream task에서 SOTA를 달성했습니다.
Contribution
- SAR-1M 데이터셋 구축: 광학 이미지 쌍을 포함하여 대규모 사전 학습을 가능하게 하는 최초의 100만 장 규모의 다목적 SAR 데이터셋을 구축
- SARE(Speckle-Aware Representation Enhancement) 도입: SAR 특유의 스펙클 노이즈를 훼손된 입력의 복원 과정에 명시적으로 통합하여, 노이즈에 강건한 특징을 학습하도록 설계
- SARC(Semantic Anchor Representation Constraint) 설계: paired 광학 이미지의 semantic prior를 활용해 SAR 특징을 정렬함으로써, 모델의 의미적 일관성을 보장하고 일반화 성능 향상
Related Work
SAR Representation Learning
데이터셋 부족과 광학 도메인에서의 unsupervised learning의 성공에 영향을 받아, self-supervised SAR representation learning이 연구되었습니다. SARATR-X, SUMMIT 등의 SAR 특화 사전학습 프레임워크는 Masked Image Modeling(MIM)으로 SAR 표현을 학습하여 일반화의 가능성을 보았으나, SAR 이미지의 물리적 prior를 간과했다는 한계를 가집니다. 기존 모델들은 노이즈가 많은 데이터를 그대로 학습에 사용하여, 학습된 결과물이 의미적으로 풍부해지는 데 한계가 있을 수 밖에 없다고 주장합니다.
Methods
SAR-1M Dataset
저자들은 기존 SAR 데이터셋의 규모 한계와, task 다양성을 위해 18개의 공개 데이터셋을 병합하여 millioin scale 데이터셋인 SAR-1M을 구축했습니다. 의미적 풍부함(Semantic Richness)를 위해 선박, 항공기 등의 대표적인 target 뿐만 아니라 지진, 농경지 등의 57개의 다양한 카테고리를 구성했습니다. 또한 여러 종류의 위성 레이더 센서와 주파수 대역을 섞어 센서의 다양성까지 확보했다고 합니다. 하지만 이 데이터셋이 기존과 가장 차별화되는 점은 SAR 이미지와 align된 광학 이미지 쌍으로, SAR 이미지와 지리적으로 정확히 같은 위치를 촬영한 광학 이미지를 매칭시켜 거대한 스케일의 이미지 쌍 데이터를 구축했습니다. 그러나 모든 SAR 이미지가 ‘매칭된 광학 이미지 쌍’을 가지고 있진 않다고 합니다. (기존 데이터셋은 약 6개 카테고리의, 10만 장 수준의 SAR 이미지만 포함했습니다.
SARMAE
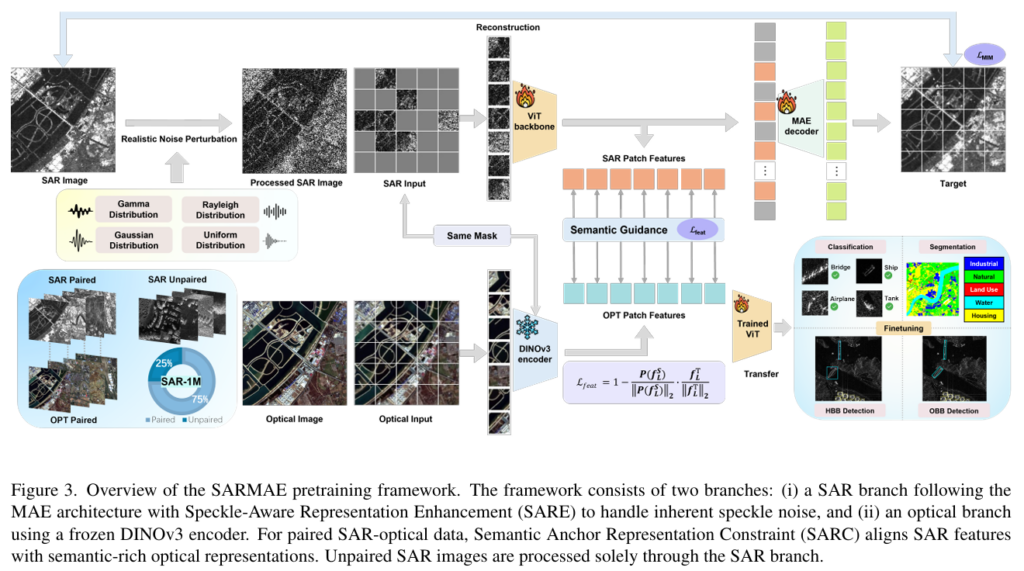
자기 주도 사전학습 프레임워크인 SARMAE는 크게 SAR Branch와 Optical Branch로 나뉩니다. SAR Branch는 기존 MAE(Masked AutoEncoder)의 구조를 따르며, 이전 연구들처럼 마스킹된 SAR 이미지를 입력하면 모델이 마스킹 영역을 재구성하여 SAR 표현을 자기주도 학습하는 방식입니다. Optical Branch는 frozen DINOv3를 사용했는데, SAR branch와 동일한 ViT 기반 인코더를 가지기 때문에 두 모달리티 간 특징을 align시킵니다.
사전 학습 과정은 다음과 같이 진행됩니다. 입력이 단일 SAR 이미지일 경우, SAR Branch만 통과하여 SARE 모듈을 통해 노이즈 특성을 학습하게 됩니다. 입력이 SAR-Optical Pair 일 경우 SAR 이미지는 똑같이 SAR branch에서 처리되며 동시에 Optical image는 Optical branch에서 semantic feature를 추출하여 이를 SAR representation 학습의 teacher/guide로 활용됩니다.
Speckle-Aware Representation Enhancement(SARE)
기존 MAE는 노이즈가 있는 원본 이미지를 마스킹한 뒤 다시 그 노이즈 낀 원본으로 복원하도록 학습시켰는데, 저자들은 SAR 이미지의 스펙클 노이즈가 단순한 additive Gaussian noise가 아닌 곱셈적multiplicative phenomenon을 지닌 Gamma Distribution을 따른다는 점에 주목했습니다.
Z=\frac{1}{L}\sum_{i=1}^{L}I_{i} ( I_{i}\sim Exp(\overline{I}), E[I_{i}]=\overline{I} )
SAR 이미지는 위성이나 비행체가 target을 설정해놓고, 이동하면서 전파 송수신 정보를 여러 장 기록한 뒤 이 정보를 평균내는 과정으로 촬영이 진행됩니다. 여기서 I_i는 단일 관측에서 얻은 측정값으로, 실제 지표면의 반사 강도인 \overline{I}를 평균으로 하는 지수 분포를 따르며, Z는 다중 관측 SAR 이미지의 픽셀값으로, L개의 독립적인 측정값을 평균 내어 얻게 됩니다. 결국 여러 지수 분포의 합으로 구성된 관측값 Z는 감마 분포(Gamma Distribution)을 따르게 됩니다.
p_{Z}(z|\overline{I},L)=\frac{L^{L}}{\Gamma(L)\overline{I}^{L}}z^{L-1}exp(-\frac{Lz}{\overline{I}}) — (2)
Γ(·)는 Gamma Function, L은 한 번의 이미지를 찍기 위해 합성했던 이미지 개수입니다. 결국 (2) 수식이 말하고자 하는 바는, pixel intensity Z가 실제 scene의 신호에 의해 그 모양이 결정되는 확률 분포에서 뽑혀 나온 랜덤 변수라는 점입니다. 저자들은 바로 이 복잡한 얽힘entanglement 로 인해 기존의 광학 도메인 기반 사전 학습 방식이 SAR에서 잘 동작하지 못했다고 분석합니다.
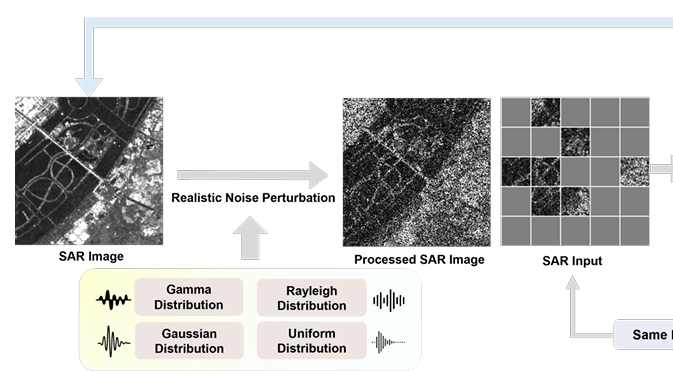
위 인사이트를 바탕으로, 저자들은 모델 훈련을 위한 “더 심하게 훼손된” 이미지를 인위적으로 만듭니다.
x^{\prime}(i,j) \sim Gamma(L_{syn}, x(i,j)/L_{syn}) —(3)
원본 패치 x를 기반으로, 가짜 노이즈가 주입된 패치 x’을 감마 분포에서 샘플링해서 생성합니다. 결과적으로 픽셀의 평균값은 원본과 같게 유지하면서, 분산만 키워 원본보다 노이즈가 심한 상태를 만들어냅니다.
이 훼손된 이미지(패치) x^{\prime}를 모델에 던져주고, 원본 이미지로 복원하게끔 강제하는 손실함수를 정의합니다.
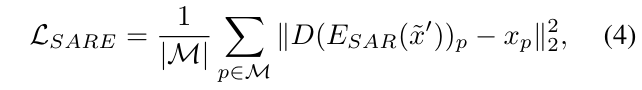
- \mathcal{M}: 마스킹된 영역의 인덱스
- D(E_{SAR}(\tilde{x}^{\prime}))_{p} : 모델이 훼손된 이미지를 보고 복원해낸 패치 값
- x_{p} : 원본 패치(정답지)
훼손된 패치 x^{\prime}에 75%의 masking을 적용해서 \tilde{x}^{\prime}를 만들고, 이를 인코더(E_{SAR})와 디코더(D)에 통과시켜 이미지를 복원합니다. 수식이 의미하는 바를 간단하게 말하면, 모델의 예측값(=복원해낸 패치 값)과 원본 패치 값 사이의 MSE라고 보시면 되겠습니다. 결국 인코더는 단순한 픽셀 패턴을 외우는 게 아니라, 노이즈의 통계적 변동성을 파악하고 이를 실제 이미지의 구조적 특징과 완벽히 분리해 내는 방법을 학습하게 됩니다.
Semantic Anchor Representation Constraint(SARC)
앞서 SARE가 스펙클 노이즈에 대한 강건성을 향상시켰다면, SARC는 feature에 의미적 단서를 주입하는 과정입니다. SAR-1M 소개 때 말씀드린, SAR 이미지와 짝지어진 지리적으로 동일하게 촬영된 광학 이미지를 가지고 이를 정답지 삼아 SAR 특징에 가이드를 주는 흐름으로 전개됩니다.
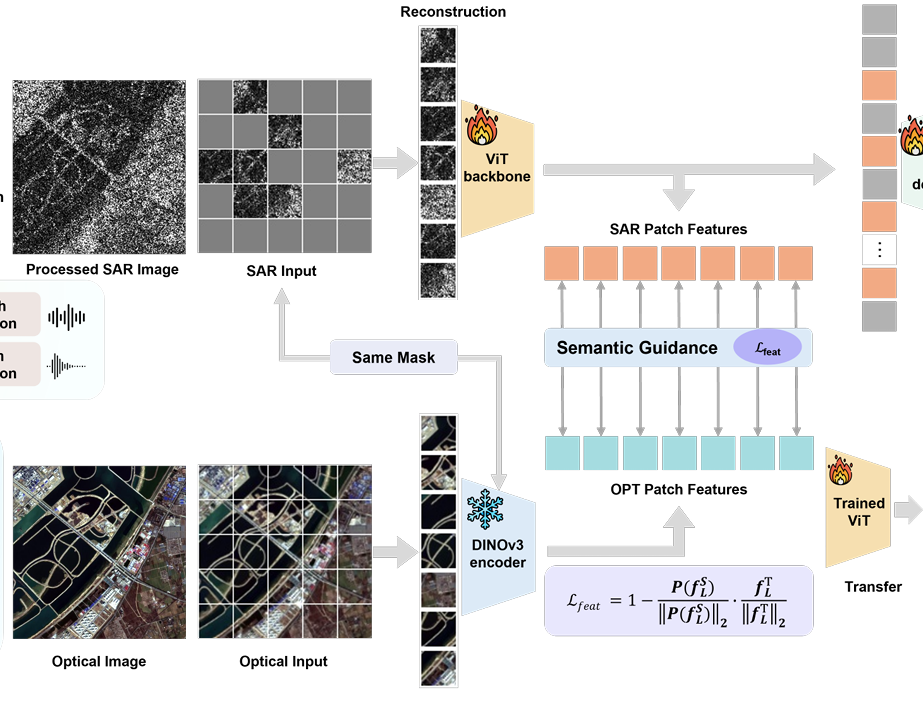
먼저 SAR 이미지와 광학 이미지를 각각의 branch에 입력합니다. SAR 이미지는 SARE 때처럼 높은 비율의 masking을 거친 후, 살아남은 패치들만 SAR ViT Encoder를 통과합니다. 광학 이미지는 마스킹 없이 원본 그대로 frozen DINOv3 Encoder를 통과해서 특징을 추출합니다. SAR patch embedding이 공간적으로 동일한 위치의 optical patch embedding과 의미적으로 가까워지도록 코사인 유사도를 사용해서 손실 함수를 정의합니다.
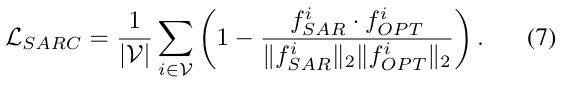
결과적으로, masking에서 살아남은 SAR patch feature들은 optical patch embedding과 가까워지는 방향으로 추가적으로 학습하고, 이 추가 학습된 SAR feature를 기준을 MAE reconstruction을 진행하게 됩니다. 최종 손실 함수는 아래와 같이 정의됩니다.
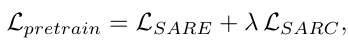
Experiments
SARMAEs는 classification, detection, segmentation 등 여러 task로 전이시킬 수 있으며 각 task에서 SOTA를 달성했습니다. Main Table은 제 주제인 object detection만 확인해보겠습니다.
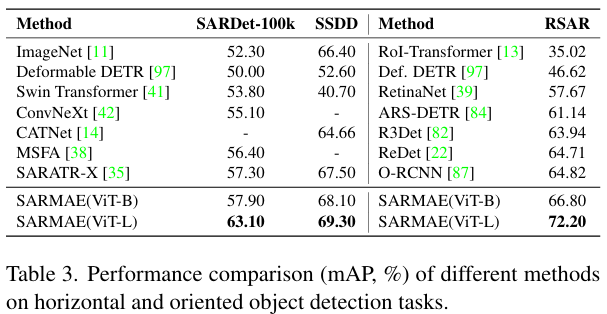
수평 객체 탐지(HBB) 모델 평가에는 SARDet-100K, SSDD 데이터셋이 사용되었으며 detector는 Faster R CNN입니다. SARMAE는 SARDet-100K에서 57.9 mAP를 기록하여, HiViT라는 비교적 우수한 backbone을 사용한 SARATR-X를 상회했습니다. SARMAE가 일반 ViT Backbone으로 더 높은 성능을 보였다는 점은 아키텍처의 이점보다 제안한 framework 자체가 detection에 더 효과적이었다는 것을 보여줍니다. 회전 객체 탐지(OBB)에서는 RSAR 데이터셋 및 Oriented R-CNN Detector를 사용했으며 역시 SOTA를 기록했고, 특히 ViT-B 백본에서 ViT-L 백본으로 모델 크기를 키웠을 때 성능이 5.4 mAP 상승하여 확장성이 준수하다는 것이 확인되었습니다.
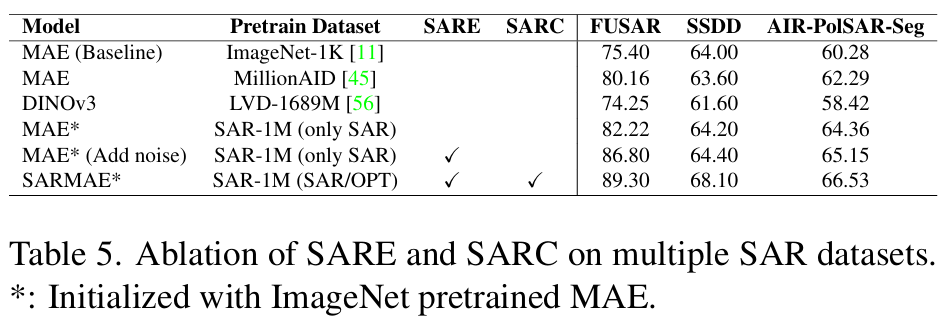
다음 Ablation 실험으로, SAR-1M 데이터셋 및 SARE,SARC 모듈의 영향을 알아보기 위한 세팅입니다. Detection 성능 평가인 SSDD 기준으로, SARC 즉 광학 이미지의 semantic guidance를 받았을 때 성능이 약 4 mAP 정도 상승했습니다. 기존의 SAR object detection 모델들은 스펙클 노이즈를 target 또는 의미 있는 정보로 잘못 판단해서 오탐지가 다수 발생하는 현상을 겪는데, SARC 모듈은 짝을 이루는 광학 이미지로부터 명확한 의미 정보를 모델에 주입함으로써 객체를 더 명확하게 분리할 수 있게 되어 성능이 향상되었다고 분석했습니다. 솔직히 method 자체가 novel, 신박하다기보다 paired optical image라는 사기적인 shortcut이 성능 향상의 주 원인인 것 같네요. detection을 제외한 나머지 task에서는 SAR-1M 데이터셋으로 사전학습을 진행했을 때가 그렇지 않았을 때와 비교했을 때 유의미한 성능 차이를 보여주고 있어 데이터셋의 효율성 또한 증명했습니다.
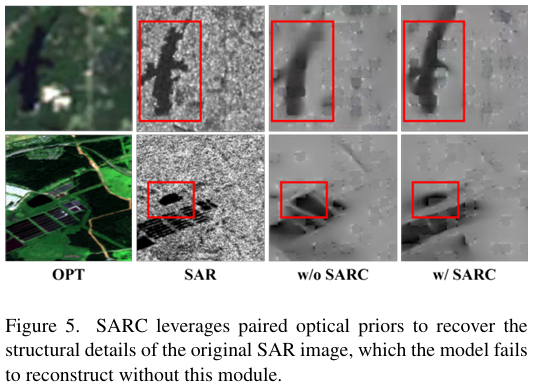
마지막으로 시각화 결과 하나 보면서 마무리하겠습니다. Fig 5는 SARC 모듈이 모델 학습에 미친 영향을 시각적으로 확인하기 위해 MAE Reconstruction 결과 시각화 figure 입니다. 특히 아래쪽 결과가 더 직관적인 것 같은데, SARC를 적용하지 않았을 때는 target 영역과 그 아래의 어두운 부분이 합쳐진 형태로 reconstruct되었으나, SARC를 적용했을 때 뚜렷하게 경계를 구분해낸 것을 보여주어 local한 detail을 복원해내는 데 성공했음을 시각적으로 확인할 수 있었습니다.
안녕하세요 재윤님 좋은 리뷰 감사합니다.
100만장이 넘는데 align까지 맞춘 데이터셋을 제공해준것이 인상 깊었습니다.
align이 맞기에 patch level로 코사인 유사도를 맞춰주는 학습을 진행할 수 있는것 같습니다.
궁금한 점이 있습니다.
optical branch는 freeze DINOv3로 진행하는 반면 SAR branch는 DINOv3를 학습시키는 것으로 이해했습니다.
그러나 full-tuning을 하면 일반적으로 catastrophic forgetting이 일어나는 것으로 알고 있습니다. 그렇기에 해당 논문은 어떤 식으로 foundation model을 학습시키는지 궁금한니다.
안녕하세요 정우님, 좋은 질문 감사합니다.
DINOv3는 frozen 상태로 optical branch에서 이미지 패치 feature를 추출하는 용도로만 사용되며, SAR branch에서는 일반적인 ViT Backbone을 사용 및 학습합니다. 굳이 optical branch에서만 DINOv3를 쓴 이유는 단순히 Teacher로서의 역할 위해 광학 도메인에서 가장 좋은 특징 추출기를 가져오겠다는 의도로 이해했습니다.
안녕하세요 재윤님 좋은 리뷰 감사합니다.
약간 헷갈리는 것이 있는데, 단일 SAR 이미지가 들어올때와 pair dataset이 들어올때를 구별해서 사전학습을 해야하는 것인지 궁금합니다.
감사합니다.
안녕하세요 인택님, 좋은 질문 감사합니다.
말씀주신 대로 SAR-1M 데이터셋은 SAR 이미지 중 매칭된 광학 이미지 쌍이 존재하는 경우도 있고, 아닌 경우도 있기 때문에 두 케이스를 구분해서 사전학습을 진행하게 됩니다. 참고로 SAR 이미지만 입력되었을 때는 semantic guidance 목적의 SARC가 사용되지 않습니다.
안녕하세요 재윤님 리뷰감사합니다.
제가 질문드리고싶은 것은 어쩌다가 이쪽 도메인의 논문을 접했는지 입니다.. 제가 알기로는 마이크로파와 이미지를 같이 다루기위해 재윤님이 말씀주신것 처럼 데이터셋 취득이 어려울거같습니다. 이미지와 센서간의 캘리브레이션이 7시간 많게는 더 오래걸리고 힘드실거같은데 앞으로 계속 마이크로파 센서와 융합하는 연구를 고민중에있으신가요 ?
감사합니다
안녕하세요 우진님, 좋은 질문 감사합니다.
이쪽 분야를 접한 이유는 저희 팀 기업 과제가 task가 SAR object detection이고, 과제 팔로우업을 겸해서 창의학기제 주제까지 해당 task로 결정되었기 때문입니다. 창의학기제와 과제 팔로우업이 마무리된다면 미련 없이 다시 비디오 연구로 돌아가서 서베이부터 진행해보지 않을까 싶습니다 하하,, 감사합니다..
안녕하세요 재윤님, 리뷰 잘 읽었습니다. 궁금한 부분이 있어서 질문 남겨놓습니다.
SARE이 reconstruction 하도록 학습시키는데, reconstruction의 향상이 실제 semantic representation 성능 향상으로 이어진 것인지 언급하거나 분석한 내용이 논문에 있었는지 궁금합니다.
안녕하세요 성민님, 좋은 질문 감사합니다.
먼저 본 논문의 방법론에 사용된 reconstruciton(masked image modeling)은 이전 SAR object detection 연구에서도 활발히 사용된 방식입니다. 모델이 masking된 부분을 복원하기 위해서는 마스킹된 객체의 전체적인 형태나 주변과의 맥락을 잘 이해하고 구조화해야만 하기 때문에 그 과정에서 고차원적인 표현을 학습하게 되는 것이 밝혀졌기 때문에, reconstruction의 영향에 관한 실험은 없습니다. 본 논문은 이 개념을 가져와서 Gamma noise를 추가한 노이즈를 보고 원본 이미지를 맞추게 하는 방식으로 난이도를 높이도록 변형시켰을 뿐이라고 이해하시면 되겠습니다. 감사합니다.