안녕하세요 이번에 리뷰로 가져온 논문은 IROS 2024에 올라온 FlowNav: Combining Flow Matching and Depth Priors for Efficient Navigation이라는 논문입니다. 이 논문은 기존 NoMaD처럼 diffusion policy를 사용해서 visual navigation action을 생성하는 방식의 한계를 이야기하면서 Conditional Flow Matching(CFM)과 monocular depth prior를 통해 개선하고자 한 연구라고 보시면 좋을 것 같습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
기존 visual navigation 모델들은 보통 로봇의 과거 시퀀스 RGB image와 goal image를 입력으로 받고, 앞으로 이동해야 할 waypoint 또는 velocity action을 예측합니다. 대표적으로는 ViNT, GNM, NoMaD 같은 연구들이 여기에 해당된다고 보시면됩니다. 오로지 순수 RGB 영상으로만 navigation 수행한다고 보시면 됩니다.
근데 여기서 저자들이 보기에 기존 방식에는 크게 두 가지 문제가 있다고 합니다.
첫 번째는 diffusion policy의 계산 비용을 언급합니다. 일단 기본적으로 NoMaD는 diffusion policy를 사용해 action trajectory를 생성합니다. diffusion은 여러 가능한 trajectory 후보를 샘플링할 수 있기 때문에 navigation처럼 정답 경로가 여러 개 존재할 수 있는 문제에 잘 맞습니다. 근데 diffusion은 기본적으로 noise에서 시작해서 여러 denoising step을 반복해야 합니다. 좋은 trajectory를 만들려면 네트워크를 여러 번 통과해야 하고 저자들은 이런 방식이 실제 로봇 제어에서는 latency로 이어질 수 있다고 합니다. 로봇은 계속 움직이고 있기 때문에 action prediction이 느리면 장애물을 발견했을 때 회피 명령이 늦어질 수 있습니다.
그리고 두 번째는 weak perception 문제라고 합니다. 기존 NoMaD 계열 구조는 RGB image를 EfficientNet과 작은 transformer로 encoding한 뒤 action을 생성합니다. 하지만 실내외 navigation에서 중요한 것은 단순히 이미지의 모습이 아니라 물체와 장애물의 거리, 복도나 벽의 위치와 같은 geometry 정보입니다. 그래서 이런 RGB-only encoder가 이런 depth-aware spatial structure를 충분히 학습하지 못하면 벽과 같은 장애물에 충돌하는 문제가 발생할 수 있다고 합니다.

위 Fig 1은 NoMaD랑 저자가 제안한 방법론인 FlowNav가 생성한 sampled trajectory를 비교하는 결과인데 파란색은 sampled trajectory 노란색은 실제 실행된 trajectory입니다. NoMaD는 장애물 주변에서 trajectory가 불안정하거나 충돌 가능성이 있는 방향으로 퍼지는 반면 FlowNav는 CFM과 depth prior를 통해 더 collision-free한 action을 생성하는 모습을 보여준다라고 저자들은 이야기 합니다.
정리하면 저자들이 말하고 싶은 핵심은 기존 diffusion-based navigation policy는 action generation 성능은 좋지만 느리고 RGB-only perception은 장애물과 depth 구조를 충분히 이해하기 어렵다 그리고 더 빠르고 depth-aware한 visual navigation policy가 필요하다 정도로 이해하시면 좋을 것 같습니다.
Method
간단하게 FlowNav의 방식을 설명드리면 FlowNav는 NoMaD의 전체적인 visual navigation 구조를 유지하면서, action generation 부분을 diffusion에서 Conditional Flow Matching으로 바꾸고, perception 부분에는 Depth-Anything-V2 기반 depth prior를 추가한것이 전부라고 보시면 좋을 것 같습니다.
그래서 FlowNav의 method를 아래 두가지 축에서 설명드리도록 하겠습니다.
첫 번째는 Diffusion Policy –> Conditional Flow Matching으로 action generation 방식을 바꾼 것이고 두 번째는 RGB observation feature + goal feature + depth token을 함께 transformer에 넣어 perception을 강화하는 것입니다.
먼저 앞서 말씀 드린 것 처럼 논문 구조 자체는 NoMaD를 많이 따릅니다. 그래서 전체 input-output 관점에서 보면 NoMaD와 거의 비슷합니다.
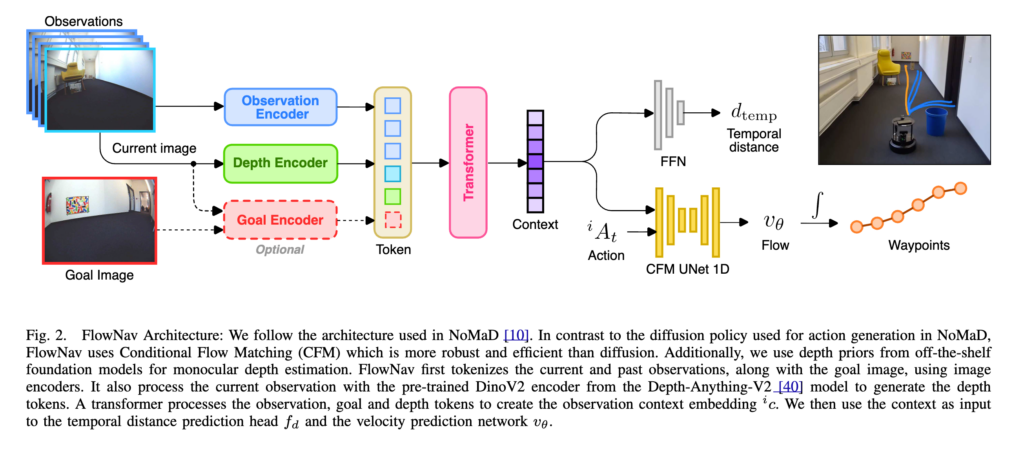
FlowNav의 전체 흐름에 대해서 설명드리겠습니다. 먼저 과거 observation image(3프레임)들을 EfficientNet-B0 observation encoder로 인코딩합니다. 그 다음 current image와 goal image를 컨캣한 뒤, 별도의 EfficientNet-B0 goal encoder로 인코딩히고 current image를 Depth-Anything-V2의 DINOv2 인코더에 넣어 depth 임베딩을 추출한 후 depth 임베딩을 pooling과 MLP를 통해 depth token으로 변환합니다. 이후에 observation token, goal token, depth token을 트랜스포머에 넣어 context 임베딩을 만들고 context 임베딩을 사용해 temporal distance와 future waypoint를 예측합니다. 이때 waypoint 생성은 diffusion이 아니라 Conditional Flow Matching 기반 velocity prediction 헤드가 수행한다고 보시면 좋을 것 같습니다.
Depth Encoder
FlowNav의 가장 중요한 추가 요소 중 하나는 Depth Encoder입니다. Flowmatch로 살짝 빨라진 속도를 무거운 Depth Encoder로 상쇄를 시키는 모습입니다. 물론 저자들의 의도는 planner 부분 쪽 한해서만 얘기한 것이긴 한것 같습니다. 돌아와서 저자들은 navigation에서 depth perception은 장애물 회피에 중요하다고 봅니다. 그래서 current observation image를 사전학습된 모델에 넣어 depth 임베딩을 얻습니다. 논문에서는 Depth-Anything-V2의 DINOv2 ViT-small encoder를 사용하고 이때 이 encoder는 current image 한장만 입력으로 받습니다.
State Encoder
c_i = F(f(iO), g(g_o, i_o), d_i)여기서 F 는 최종 context를 뽑아내는 트랜스포머 state encoder이고, c_i 최종 context 임베딩입니다. 논문에서는 NoMaD랑 비슷하게 4-layer, 4-head transformer를 사용합니다. 이후에 context 임베딩은 두 가지 head로 전달됩니다. 첫 번째는 temporal distance prediction 헤드이고 두 번째는 velocity prediction 헤드(여기서 velocity는 로봇 velocity가 아니라 flowmatch에서 flow velocity)입니다. Temporal distance prediction 헤드는 현재 observation과 goal image 사이의 시간적 거리를 예측합니다 이 값은 topological map 기반 navigation에서 현재 위치에서 어떤 map node가 가장 가까운 goal인지를 판단하는 데 사용됩니다. 그리고 Velocity prediction 헤드는 FlowNav의 action 생성을 수행하소 여기서 기존 NoMaD의 diffusion 헤드 대신 CFM 기반 1D conditional U-Net이 들어가게 됩니다.
Conditional Flow Matching
FlowNav의 핵심 부분인 Conditional Flow Matching에 대해 설명하겠습니다. 기존 diffusion policy 같은 경우는 처음에 Gaussian noise에서 시작하고 여러 denoising step을 거치면서 점점 실제 action trajectory에 가까운 샘플을 만듭니다. 반면에 FlowNav는 noise에서 target action으로 가는 velocity field를 직접 학습한다고 보시면 될거 같습니다. 여기서 velocity field는 action space에서, waypoint trajectory space 안에서 현재 noisy trajectory를 어느 방향으로 얼마나 업데이트해야 target trajectory에 가까워지는지를 나타내는 벡터장이라고 보시면 좋을 것 같습니다. 따라서 FlowNav의 velocity prediction head는 최종 제어 명령을 직접 예측한다기보다는 Gaussian noise로부터 유효한 waypoint sequence를 생성하기 위한 변화 방향을 예측한다고 이해하면 좋을 것 같습니다.
Loss
기존 diffusion policy는 noise가 섞인 action에서 noise를 여러 번 제거하면서 최종 action을 만듭니다. 반면 FlowNav는 noise trajectory가 expert waypoint trajectory 쪽으로 이동하려면 어떤 방향으로 바뀌어야 하는지, action space에서의 변화 방향을 학습하는 방식입니다.
dx = u_t(x)dt여기서 x는 현재 action sample이고, u_t(x)는 이 sample이 target action 쪽으로 이동하기 위해 따라야 하는 velocity field입니다. 여기서 velocity는 로봇의 실제 선속도나 각속도가 아니라, waypoint trajectory 좌표를 어떻게 바꿔야 하는지에 대한 변화량이라고 보면 됩니다.
일반적인 Flow Matching의 목적은 아래 수식처럼 모델이 예측한 velocity v_\theta가 실제 velocity u_t와 같아지도록 학습하는 것입니다.
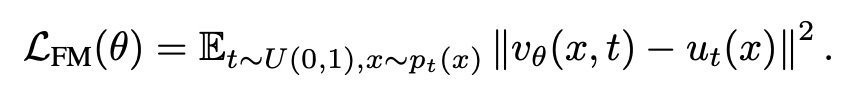
그런데 실제 u_t를 정의하기 위해서 저자들은 아래와 같이 정의합니다.
A_0: Gaussian noise에서 샘플링한 초기 action trajectory
A_1: 데이터셋에 있는 expert waypoint trajectory
A_0는 랜덤하게 생성된 이상한 waypoint이고
A_1은 실제 로봇이 따라야 하는 정답 waypoint입니다. 그다음 A_0
와 A_1 사이의 중간 trajectory를 만듭니다.
A_t = tA_1 + (1-t)A_0여기서 t=0이면 완전한 noise trajectory이고 t=1이면 expert waypoint trajectory입니다. t=0.5라면 noise와 정답의 중간 상태라고 보면 됩니다.
u_t = A_1 - A_0FlowNav는 현재 noisy trajectory A_t가 주어졌을 때 애를 expert trajectory A_1 쪽으로 보내려면 어느 방향으로 좌표들을 바꿔야 하는지를 변화량을 학습하게 됩니다.
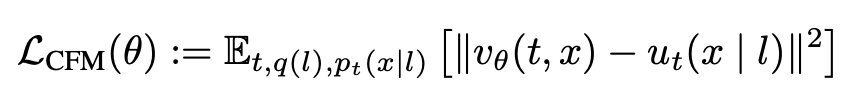
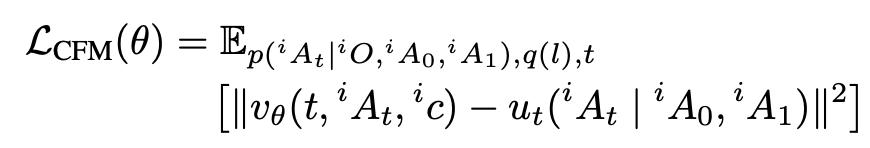
여기서 v_\theta(t, A_t, c_i)는 모델이 예측한 velocity입니다. c_i는 observation image, goal image, depth token을 transformer에 넣어 얻은 context embedding입니다.
그리고 FlowNav는 waypoint trajectory만 생성하는 것이 아니라, NoMaD랑 동일하게 현재 observation과 goal image 사이의 temporal distance도 함께 예측합니다.
Temporal distance loss는 아래와 같습니다.
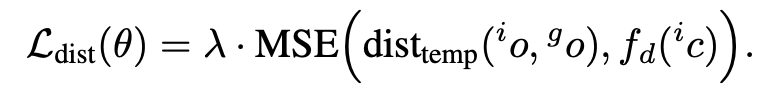
여기서 dist_temp(i_o, g_o)는 현재 이미지와 goal image 사이의 정답 temporal distance이고, f_d(c_i)는 모델이 예측한 temporal distance입니다.
최종 loss는 CFM loss와 temporal distance loss를 더한 값입니다.
L(\theta) = L_{CFM}(\theta) + L_{dist}(\theta)Goal-directed Navigation과 Task-agnostic Exploration
FlowNav는 두 가지 모드로 동작합니다. 먼저 Goal-directed navigation에서는 pre-collected topological map이 필요합니다. 이 map의 각 node는 image로 표현이 되고. 로봇은 현재 observation과 map node image 사이의 temporal distance를 예측하고, 가장 가까운 node를 goal image로 선택하는 식으로 동작합니다. 그리고 나서 이 goal image를 조건으로 CFM action head가 waypoint를 생성합니다. 그리고 Task agnostic Exploration mode에서는 goal image를 사용하지 않습니다. 논문에서는 goal encoding을 mask한다고 설명합니다. 특정 목표가 없는 상태에서 로봇이 주변에 안부딪히고 주변 환경을 탐색하도록 합니다.

Fig 4를 보시면 Navigation mode에서는 goal image가 있기 때문에 sampled trajectory들이 한 방향으로 비교적 모이는 반면에 exploration mode에서는 goal이 없기 때문에 trajectory들이 여러 방향으로 퍼지는 다양한 분포의 traj 를 예측하는 모습을 보입니다.
Experiments
실험은 실제 TurtleBot4 로봇을 사용해 진행됩니다. 학습 데이터셋은 총 5개의 open-source dataset으로 학습을 진행했다고 합니다. (Go Stanford, RECON, Tartan Drive, SACSoN, SCAND)

실험은 TurtleBot4에서 진행했다고 합니다. 환경은 easy부터 hard까지 총 4개 환경을 구성했고. 실험 환경에는 fig3과 같이 soft turn, tight turn, boxes, chairs, table legs, glass walls, cluttered environments와 같은 요소를 포함시켜서 실험하였습니다.
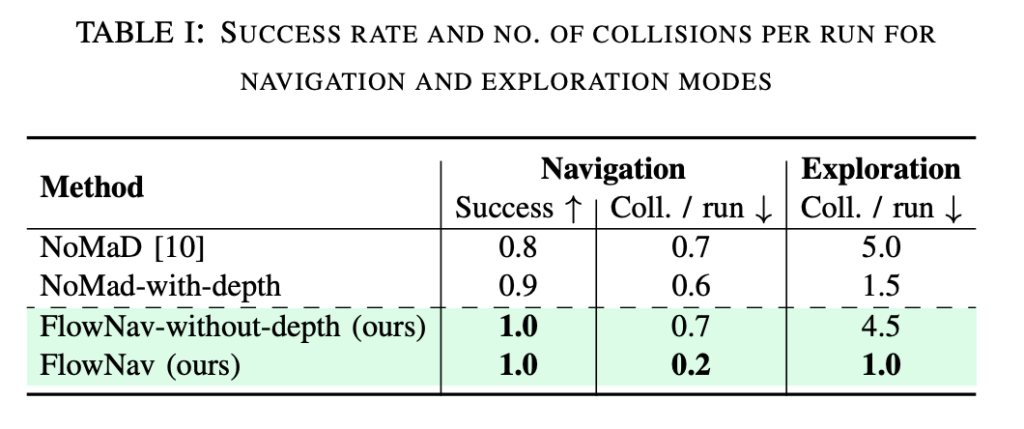
위는 실제 real robot 환경에서의 평가 결과입니다. 저자가 제안한 방식인 FlowNav가 전체적으로 가장 좋은 성능을 보입니다. Navigation success rate도 1.0이고 collision도 가장 적습니다.
저자들은 위 결과를 가지고 depth prior는 collision을 줄이는 데 효과적임을 주장합니다. NoMaD와 NoMaD-with-depth를 비교하면 exploration collision이 5.0에서 1.5로 많이 줄어드는 결과를 확인할 수 있습니다. 그리고 FlowNav-without-depth와 FlowNav를 비교해도 exploration collision이 4.5에서 1.0으로 줄어듭니다.
CFM은 action generation 효율성 측면에서 중요하고, depth prior는 특히 obstacle avoidance와 collision 감소 측면에서 중요하다라고 저자들은 분석합니다.

위는FlowNav의 rollout 시각화결과입니다. Navigation mode에서는 goal image가 주어지기 때문에 trajectory들이 비교적 한 방향으로 모이는 모습을 보이고 반면 exploration mode에서는 goal image가 없기 때문에 여러 방향의 trajectory가 나옵니다. 근데 해당 결과는 사실 NoMaD의 방법론 그대로 보여준거나 다름이 없는 결과이긴 합니다.
그리고 저자들은 자신들이 학습한 NoMaD가 원래 NoMaD보다 collision이 많은 이유가 데이터 subset 때문일 수 있다고 보고 pre-trained NoMaD model을 추가로 평가를 했다고 합니다.(따로 성능 리포팅은 하지 않았음)결과적으로 pre-trained NoMaD는 exploration에서 collision per run이 3.0 정도로 나왔다고 하는데 이는 저자들이 직접 학습한 NoMaD의 5.0보다는 낫지만 FlowNav의 1.0보다는 여전히 좋지 않은 결과라고 합니다. 결국 training data scale은 navigation generalization에 확실히 중요하다고 저자들은 주장합니다.

위 그림은 K=2, 5, 10 inference step에서 NoMaD-with-depth와 FlowNav가 생성한 trajectory를 비교하는 결과 입니다. 여기서 K는 최종 waypoint trajectory를 생성하기 위해 수행하는 inference step 수를 의미합니다. NoMaD에서는 denoising step 수이고 FlowNav에서는 velocity field를 따라 Euler update를 반복하는 횟수라고 보시면 좋을 것 같습니다. FlowNav는 적은 step에서도 유효한 trajectory를 만들지만 NoMaD-with-depth는 K가 작을 때 trajectory가 불안정한 모습을 보이는 것을 확인할 수 있습니다. K가 클수록 trajectory는 더 정제될 수 있지만 inference time이 증가하는데 FlowNav의 핵심은 NoMaD보다 작은 K에서도 유효한 waypoint를 생성할 수 있다라는 것을 보여주는 결과입니다.
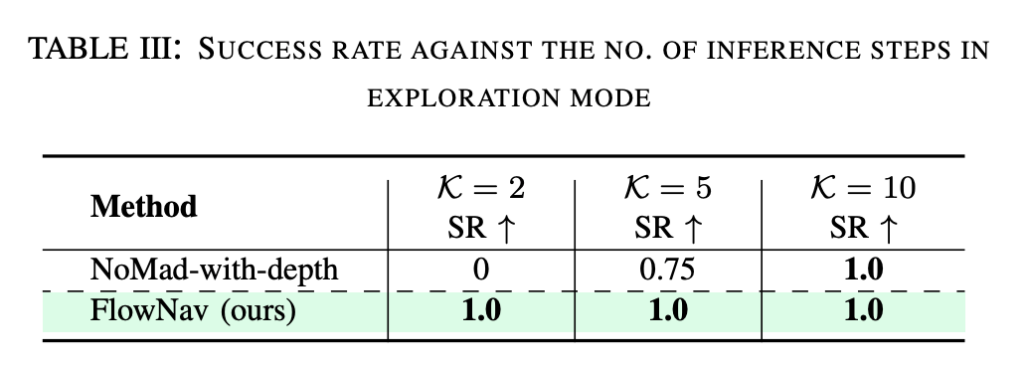

위 결과는 Navigation mode에서 inference step K에 따른 success rate와 collision 결과입니다. NoMaD-with-depth는 K=10에서는 좋은 성능을 보이지만, K=2나 K=5에서는 성능이 낮은 모습을 보입니다. 즉, diffusion policy는 충분한 denoising step이 있어야 좋은 trajectory를 만들 수 있습니다. 결국 Flow Matching은 diffusion보다 적은 inference step으로도 유효한 action trajectory를 만들 수 있다라는 것을 보여줍니다.
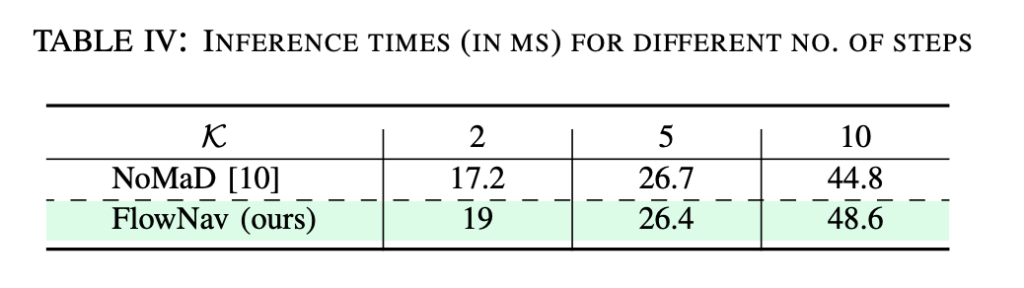
위는 inference 시간을 리포팅한 결과 입니다. Table IV만 보면 FlowNav가 같은 K에서 항상 더 빠른 것만은 아닌데 K=2에서는 오히려 NoMaD가 조금 빠르고, K=10에서도 NoMaD가 약간 빠릅니다. 그래서 저자의 입장에서 해석을 하면 결국 FlowNav는 더 작은 K로도 NoMaD의 큰 K 성능에 도달할 수 있기 때문에 결과적으로 더 효율적인 navigation이 가능하다라는 것을 보여주는 것 같습니다. 그리고 이부분은 논문에서 따로 명시적으로 언급하지는 않았지만 모델 전체 inference time이 아니라 아마 action generation 쪽 부분만 따로 측정해서 리포팅한것 같습니다. 왜냐면 FLowNav는 앞에 depth encoder (ViT)가추가로 붙어있기 때문에 아마 모델 전체 inference time으로 측정하면 NoMaD보다 느린 결과가 나왔지 않았을까 싶습니다. 이상리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 좋은리뷰 감사합니다.
한가지 궁금한점이 존재하는데, diffusion policy의 문제점에 대해서 이미 잘 학습된 diffusion 모델의 최종입력과 결과 state만 distill하여 속도를 빠르게 하는 생성형 방법론들이 존재하는 것으로 아는데, NoMAD가 이미 그런 방식으로 사용되고 있던건가요?
감사합니다.
안녕하세요 인택님 좋은 댓글 감사합니다.
NoMaD는 diffusion policy를 waypoint generation에 사용한 모델이지만 잘 학습된 diffusion model의 최종 입출력 state를 student로 distill해서 속도를 빠르게 만든 방식은 아닌 것으로 알고 있습니다.
감사합니다.