안녕하세요 손우진입니다.
이번에 소개드릴 논문은 6D 정보와 Tactile 센서를 활용하여 물체를 조작하는 논문에 대해서 소개드리려 합니다. 특히 로봇이 물체를 잡고 있는 상황에서 발생하는 가림 문제를 해결하기 위해 촉각정보를 활용한 논문입니다.
Introduction
객체 포즈를 통해서 로봇이 조작 수행하기 위해 많이 되어 왔습니다 . FoundationPose와 같은 모델들이 대규모 데이터를 활용해 시각 기반 트래킹 성능을 크게 향상시켰지만 , 실제 로봇이 물체를 쥐고 다루는 ‘In-hand manipulation’ 시나리오에서는 여전히 시각 정보만으로 해결하기 어려운 문제들이 존재합니다. 특히나 로봇의 손에 의해 물체가 가려지는 상황과 조작 시 발생하는 빠른 동적 움직임에서 어려움이 있습니다. 저희 인간같은 경우는 이러한 상황에서 시각과 햅틱정보를 자연스럽게 통합하여 물체를 인지하고 조작합니다. 시각을 통해 물체의 대략적인 위치를 알고 접근 후, 실제 접촉 시 발생하는 촉각 피드백을 통해 정밀한 파지를 수정하는 방식입니다. 로봇 분야에서도 이를 모방하여 촉각 센서와 조인트 정보를 시각과 결합 하려는 시도가 계속되고있습니다. 그러나 기존의 시각-촉각 융합 방식들은 실제 환경에 배포하기에 두 가지 한계가 있었습니다. 첫 번째로는 Cross-embodiment 입니다. 대부분의 연구가 특정 형태의 그리퍼나 센서 레이아웃에 과적합 되어, 로봇 플랫폼이 바뀌면 적용하기가 매우 어렵습니다. 추가적으로 Domain generalization 문제인데요 시각모델에 비해 데이터 다양성이 부족하다보니 , 매 프레임을 독립적으로 추정하는 경향이 있어 연속적인 트래킹 과정에서 일관성이 무너지는 경우가 많습니다. 저자들은 이러한 문제를 극복한 방법을 제안하였습니다.
해결책의 핵심은 모양이 제각각인 로봇 손과 촉각 센서들의 신호를 ‘3D 포인트 클라우드’라는 3차원 점들로 표현하였습니다. 저자들은 이 ‘통합 햅틱 표현’을 도입하여 하드웨어가 바뀌어도 문제없이 적용할 수 있는 Cross-embodiment 학습을 가능하게 만들었습니다. 또한, 이 통일된 햅틱 데이터를 시각 데이터와 함께 모델에 넣어 추적의 일관성을 높였습니다. 결과로는 학습 과정에서 본 적 없는 새로운 형태의 로봇 손이나 물체에 대해서도 일반화 성능을 보여주었고, 기존모델 대비 10배빠른 실시간 속도를 달성하였습니다.
논문에서 저자들이 제시한 Contribution을 정리하면 다음과 같습니다.
- 통합 햅틱 표현(Unified Haptic Representation) 제안: 다양한 로봇 손(Embodiment)과 센서에 범용적으로 적용할 수 있도록 촉각 신호와 그리퍼의 자세를 하나로 통합한 새로운 햅틱 표현을 도입하여 Cross-embodiment 학습을 가능하게 했습니다.
- 시각-촉각 융합 트랜스포머(Visuo-haptic Transformer) 설계: 시각 및 햅틱 데이터를 통합하는 트랜스포머 모델을 제시하여 포즈 추적의 일관성을 높이고 도메인 일반화 문제를 해결했습니다.
Methodology
Pasted i
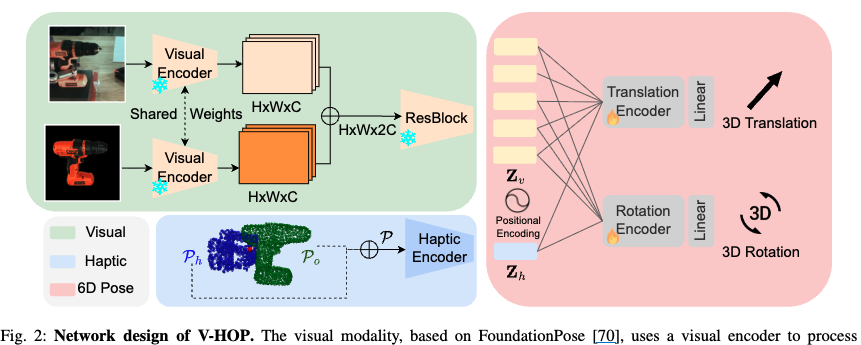
저자들은 V-HOP라는 모델을 제안하였고 촉각과 이미지를 통해서 3차원공간에서 일치시키고 융합하는 것이 핵심입니다. 파이프라인은 위와같으며, 우선 저자들이 제안한 표현방법을 통일한 것부터 설명 드리도록 하겠습니다
Gripper Representation
우선은 기본적으로 기존 연구에서 촉각 데이터를 처리할 때는 센서 신호를 2D 이미지로 투영하거나, 센서를 노드로 연결하는 그래프 방식을 주로 사용했습니다. 하지만 이런 방식들은 센서의 그리퍼 형태가 조금만 바뀌어도 구조가 틀어져 다른 하드웨어에 일반화하기 어렵다는 단점이 있었습니다. 저자들은 이러한 Cross-embodiment 문제를 해결하기 위해 ‘3D 포인트 클라우드’를 선택했습니다. 구체적으로는 로봇의 URDF와 현재 관절 각도(Joint positions) 정보를 이용해 Forward Kinematics으로 그리퍼의 3D 메시를 생성합니다. 이를 다운샘플링하여 9차원(3D 좌표, 노말 벡터, 접촉 여부 라벨)의 포인트 클라우드 P_h로 변환합니다. 접촉여부 같은경우는 원핫 인코딩으로 접촉의 유무를 통해 들어가게됩니다.
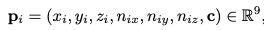
Object Representation
그리퍼와 마찬가지로 대상인 물체 또한 포인트 클라우드(P_o) 형식으로 표현됩니다. 이 과정에서 저자들은 물체의 기하학적 정보와 이전 프레임의 포즈정보를 활용합니다. 구체적으로는 이전 타임스텝(t-1)에서 얻은 물체의 6D 포즈 추정값(T_{t-1})을 기준점으로 삼아, 물체의 CAD 모델로부터 샘플링된 포인트들을 현재 예상되는 위치로 변환(Transformation)합니다. 이렇게 변환된 물체 포인트 클라우드(P_o)는 앞서 구성한 9차원의 그리퍼 포인트 클라우드(P_h)와 결합되어, 최종적으로 ‘Gripper-Object Point Cloud’라는 통합된 입력 데이터를 형성합니다.
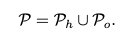
방식은 6D 모델에서 주로 사용하는 ‘Render-and-compare’을 통해서 FoudationPose기반으로 추출되게됩니다. 모델은 렌더링 되어있는 이미지를 비교하는 것이 아니라, 3D 공간 상에서 현재 물체가 있을 것으로 예상되는 지점과 실제 로봇 손의 위치 및 접촉 정보가 서로 어떻게 물리적으로 상호작용하고 있는지를 기대할 수 있습니다. 이런 표현을 통해서 네트워크가 가림이 발생한 상황에서도 햅틱 피드백을 통해서 Pose를 수정할 수 있다고 합니다.
Network Design
V-HOP의 네트워크 아키텍처는 시각적 파운데이션 모델과 햅틱 포인트 클라우드의 기하학적 정보를 Early Fusion 구조를 사용하고 있습니다. 단순히 두 데이터를 합치는 것을 넘어, 상황에 따라 최적의 감각에 의존하도록 설계된 것이 핵심입니다. Visual Modality (좌상단) 같은 경우 FoundationPose 의 Visual Encoder를 그대로 활용합니다. 이를 통해 RGB-D 관측값으로부터 Z_v임베딩 생성합니다. 또한, Haptic Modality(좌하단) 앞서 최종적으로 생성된 통합 포인트 클라우드 \mathcal{P}는 Haptic Encoder인 PointNet++를 통해 처리됩니다. 여기서 핵심은 서로 다른 하드웨어의 그리퍼 Kinesthesis와 실제 Tactile정보를 3차원 공간상의 공통된 포인트 클라우드 형식으로 변환하여 입력한다는 점입니다. 이러한 방식은 센서의 배치나 그리퍼의 형태에 상관없이 동일한 물리적 상호작용 패턴을 학습할 수 있게 함으로써, 결과적으로 Tactile 데이터의 학습 효율과 범용적 하드웨어 대응 능력을 높였습니다. Visuo-haptic Fusion 은 추출된 Z_v와 Z_h는 Transformer Encoder 내부에서 Self-attention 메커니즘을 통해 융합됩니다. 생각보다 모델구조는 간단하지만 pointcloud로 tactile을 활용했다는 점과 이를 통해 fusion함으로써 인간의 인지능력과 유사하게 나올거라는 결과가 재밌는 것 같습니다 그 후 융합된 feature는 최종적으로 두 개의 헤드로 전달됩니다. 포즈 추정의 수렴 안정성을 높이기 위해 6D 포즈를 3D Translation과 3D Rotation으로 분리하여 개별적으로 예측하게됩니다.
학습에서 사용되는 Loss는 총 3가지로 구성되어있습니다. 우선 6D loss 입니다
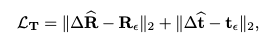
L2 loss를 통해 Rotation과 Translation에 대한 loss를 구현하였습니다.
다음 두 loss는 pointcloud에 대한 loss입니다 .
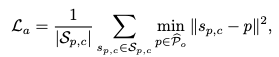
활성화된 촉각 센서이 반드시 물체 표면과 맞닿아 있어야 하기에 이를 수식화한 것입니다. 햅틱 센서에서 감지된 접촉 포인트S와 물체 포인트 클라우드 사이의 거리를 최소화하여, 추정된 포즈가 실제 햅틱 관측값에 밀착되도록 당겨주는 역할을 합니다. 이를 통해서 물체의 위치가 불확신할때 즉 가림현상이 일어 날때 물체포즈 정보를 센서를 통해 추정하기 위함이라고 보시면 될 것 같습니다.
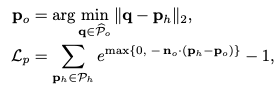
이 손실 함수는 로봇 손이 물체 내부를 파고드는 물리적 오류를 방지하는 로스라고 저자들은 얘기를 하는데 이부분에 이해가 저도 어려워서. 확실한 설명은 좀 더 알아봐야할 것 같습니다. 개인적인 생각으로는 물체가 심하게 가려지는상황에서 depth를 판단하기 어렵기에 추정에 어려움이있고 하다보니 객체의 표면으로 부터 구분하는 것 같습니다. 그래서 저자들은 SDF를 활용하는데, 추정된 포즈에서 그리퍼의 포인트가 객체의 내부 영역(SDF < 0)으로 추정이된다면, 잘못 추정했기에 지수적으로 loss를 주는 것 같습니다. 최종적으로는
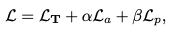
3개의 loss를 통해 모델을 학습시키게됩니다.
Experiments
저자들은 Isaac Sim을 활용하여 8종의 그리퍼와 13종의 YCB 객체를 조합한 약 1,550,000 프레임 규모의 대규모 멀티-엠보디먼트 데이터셋을 직접 구축하여 실험을 진행했습니다. 성능 평가는 6D 포즈 추정의 표준 지표인 ADD 및 ADD-S로 계산되었습니다.
P
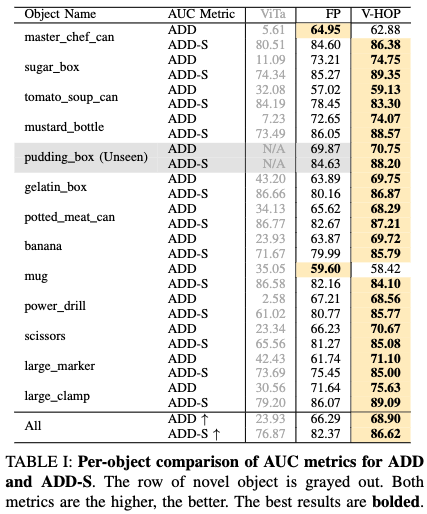
우선 저자들이 제작한 sim데이터를 통해 Foudation pose 와 visual + Tactile을 함께 사용한 baseline 대비 높은 성능을 보여주면 pudding_box같은 경우느 unseen임에도 불구하고 좋은 성능을 보여주는 모습입니다. 추가적으로 저자들은 그리퍼에 대한 제약에 대해서도 리포팅을 하는데요
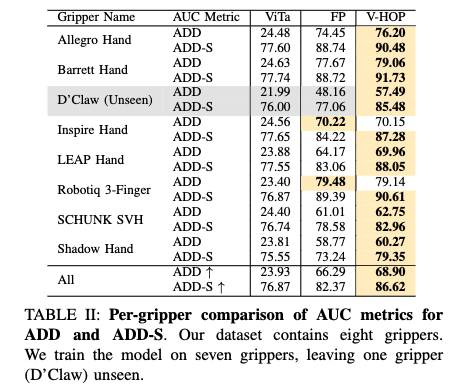
위는 다른 그리퍼들을 통해서 6D를 평가하였고 그리퍼에 상관없이 가장 좋은 성능을 보여주었습니다. 여기서 새로운 그리퍼 D’calw를 사용하여도 기존모델들 대비 가장 좋은 성능을 보여줌으로써 Cross-embodiment에 대해 입증을 하였습니다.
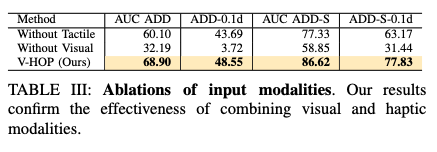
다음으로는 ablation 입니다. visual정보만을 사용했을때 보다 tactile정보를 사용함으로써 occlusion이 발생하였을때 정확도가 상승하였고 그것이 촉각정보를 사용함으로써 pose정보에 활용할 수 있었습니다. 다음으로는 실제 리얼데이터에 대한 일반화 성능입니다

real data에서 일반화 실험을 하였습니다. 저자들은 point cloud로 변환함으로써 속도를 챙겼고 real data에서의 일반화를 챙길수있었다고 얘기를 합니다. 음,, 아무래도 이 데이터셋 같은경우는 물체들이 조금 쉽다보니 높은 성능이 나왔지 않을까 싶습니다.
요즘 여러 센서들을 융합하고 또 다른 모달리티의 센서들이 들어올때 어떻게 이를 활용하고 잘 융합하는지에 대해서 관심있게 보고있었는데 그에 맞는 논문이여서 리뷰를 해보았습니다. 내용이 조금 어려웠다보니 중간에 의문점이 드셨을 수 도 있다고 생각합니다. 그런 부분은 댓글 남겨주시면 감사하겠습니다!
안녕하세요 우진님, 좋은 리뷰 잘 읽었습니다.
Gripper Representation에서 URDF를 통해 만든 3D mesh와 실제 이미지의 align이 맞지 않을 수 있을 것 같은데, align에 대한 언급은 없었나요?