thinking은 large reasoning model(LRM)이 답변을 할 때, 추론의 과정을 나열하게 하여 응답의 정확도를 높이는 추론 기법입니다. 그러나 너무 장황하게 늘어놓는다거나 기존의 내용을 반복하는등의 문제가 발생하곤 합니다. 논문에 따르면 LRM은 언제 thinking을 멈추어야하는지 알고있다고 하는데요, 이 발견을 기반으로 응답을 종료하는 시점에 답변이 멈출 수 있도록 새로운 샘플링 기법인 SAGE(Self-Aware Guided Efficient Reasoning)를 제안합니다. 또한 기존 그룹기반 업데이트 방식(GRPO)를 활용하여 제시한 강화학습 기법(SAGE-RL)을 적용하면 표준적인 샘플링 방식(pass@1)으로도 효율적인 추론을 달성할 수 있었습니다.
LRM 이 종료시점을 알고있음에도 중복 문장등의 답변을 계속 생성한 이유는 Pass@1(figure1 참조)이라는 기존의 샘플링 방식의 허점때문입니다. 일반적으로 모델이 만든 응답은 하나의 가장 확률이 높은 분포에서 샘플링된 토큰입니다. 모델이 내부적으로는 종료 토큰이 생성될 확률이 높아지지만, 이를 감지하기 어려운 구조입니다. 이를 해결하기 위해 SAGE라는 토큰 생성 중의 다양한 후보를 고려하며 샘플링 하는 방식(figure1 참조)으로 종료 토큰을 더욱 빠르게 감지하는 방법을 제시합니다.
현재 샘플링 방식 재검토
# Pass@k
thinking모델이 추론을 수행할 때 일반적오로 긴 cot가 높은 성능을 갖는다고 생각할 수 있습니다. 그러나 앞선 연구에 따르면 DeepSeek-R1이 Claud 3.7 Sonnet보다 5배 긴 응답을 생성하지만 정확도가 비슷한 성과를 보이거나 AIME2025에서 긴 응답이 오답을 생성할 확률이 높은것을 확인하는 등 응답과 cot의 길이의 상관관계 무효성을 검토했습니다. 따라서 여러가지 응답을 생성하고 가장 길거나 짧은 응답을 생성하는 pass@k 방식이 아닌 새로운 샘플링 방식이 필요함을 알 수 있습니다.
# Pass@1
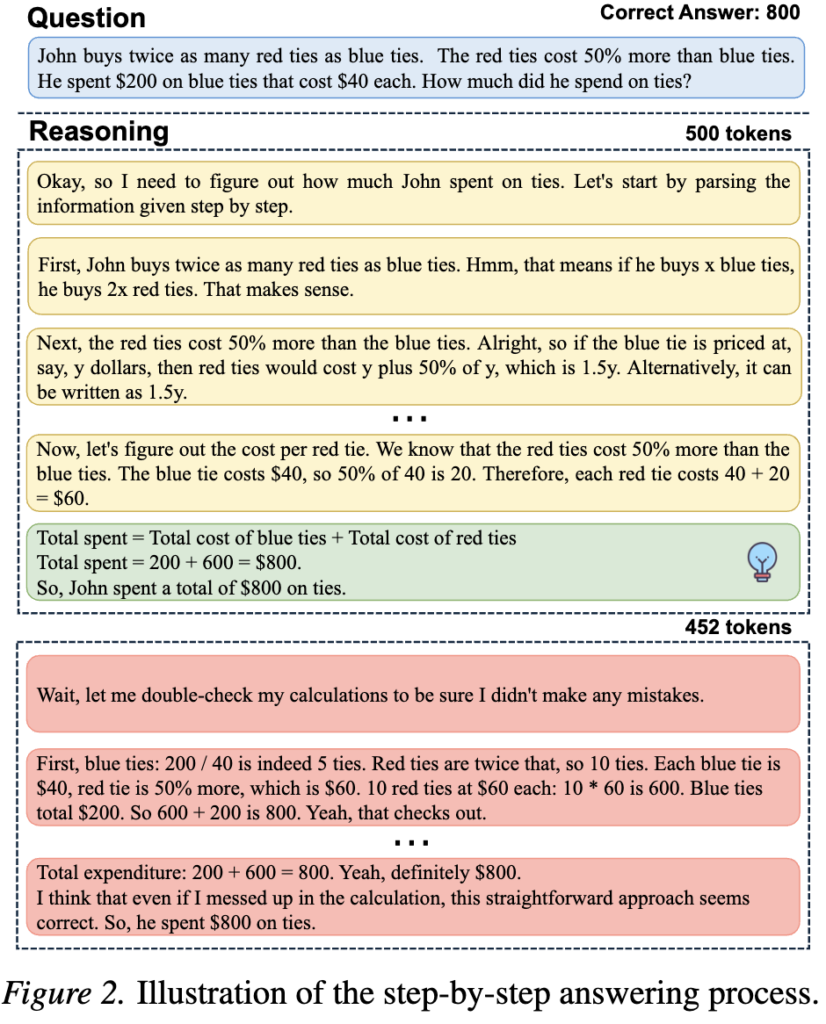
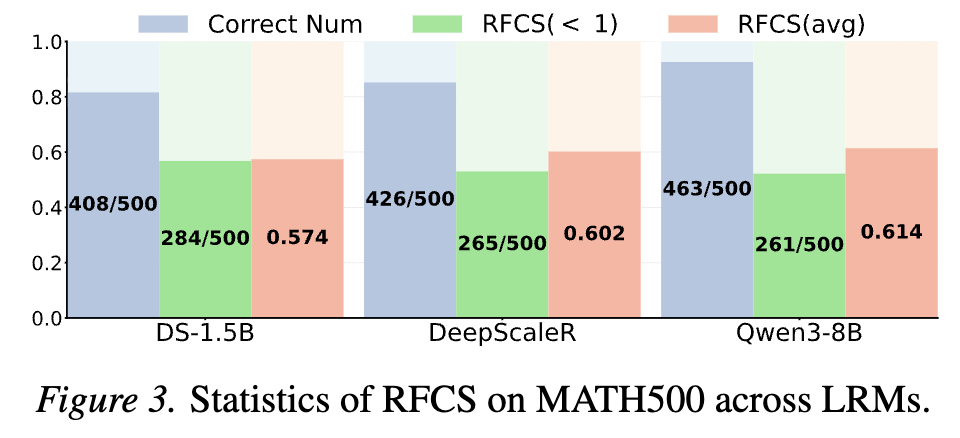
일반적인 LRM의 응답 생성 방식을 통해 기존 생성 방식의 문제점을 확인할 수 있었습니다. 명확한 비교를 위해 응답에서 처음 정답이 등장하는 속도를 RFCS(Ratio of First Correct Step) 지표로 하였습니다. 이는 처음 응답이 등장한 토큰의 인덱스를 전체 응답 토큰의 길이로 나눈 값으로 1이 아니라면 사실상 추가적 리즈닝을 수행한 것으로, 비효율적인 응답에 해당 합니다. 실험 결과 정답을 맞춘 응답(파란색) 중에 상당수가 비효율 적인 응답(녹색)을 수행했으며 평균적인 RFCS는 0.6 정도임을 확인할 수 있습니다. 즉 충분히 효율적인 추론을 하고있지 못한 것이지요.
효율적인 응답을 생성하는 법
figure3을 통해 모델이 응답을 종료하기 전, 이미 정답이 등장하는 비율이 높음을 확인할 수 있었습니다. 그렇다면 정답을 외친 이후에는 빠르게 응답을 종료하는것이 중요하겠지요. 논문에서는 효율적인 응답 생성을 위해 모델이 정답을 이미 알고있는 시점 즉, 종료 토큰을 생성해야하는 시점을 모델이 이미 알고있다는 가정으로 샘플링 기법을 설계합니다.
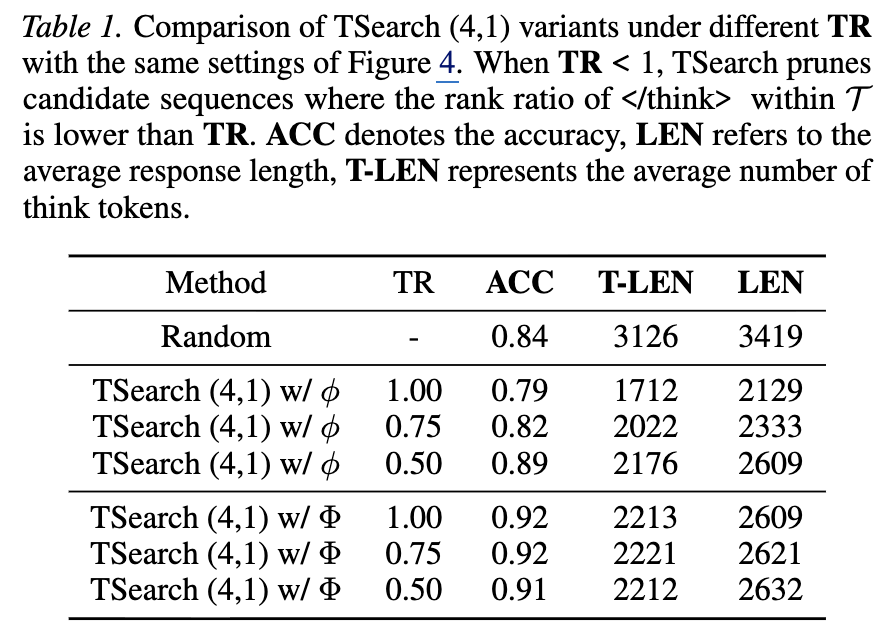
먼저 저자들은 응답 생성 과정에서 토큰 생성시에 m개의 토큰을 생성합니다. 이후 각 토큰에 대해 2m개로 path를 확장합니다. 총 2m*m개의 응답 path 중에서 가장 가능도가 높은 m개만을 유지하고 하고 다음 단계를 반복합니다. 최종적으로 path중에 종료 토큰인 </think>가 충분히 높은 순위에 들어오면 그 path를 종료하게 됩니다. 이때 종료 조건은 하이퍼파라미터(h)로 TR=h/2m 로 표기됩니다. 2m개의 path에 h 순위에 종료 토큰이 생성되면 종료하는 것으로, TR이 작을수록 허용하는 범위(h)가 작은 엄격한 상태입니다. 이렇게 허용범위에 인정되는 종료 path가 r개가 모이면 탐색을 종료합니다. 그러나 탐색 길이가 최대에 도달했음에도 r개를 모으지 못하면 모든 path에 강제로 종료 토큰을 붙인 후 가능도가 가장 높은 순으로 선택해 추가합니다. r개의 응답에 대해 길이로 최적의 응답을 선택하는것이 아니라 그리디 방식으로 가장 응답일 확률이 높은 응답(전체 토큰 확률의 로그합)을 선택합니다.
위의 샘플링 방식의 유효성을 검토하기 위한 몇가지 실험이 있습니다. 먼저 TSearch 실험 입니다. TSearch(m, r) w/ Φ: 위에서 설명한 알고리즘으로 탐색 너비 m개를 평균 누적 로그 확률인 Φ 로 유지하며 탐색합니다
TSearch (m, r) w/ ϕ: 한편 해당 실험은 m개의 후보를 유지할 때 전체 path를 고려하지 않고 가장 확률이 높은 다음 토큰 ϕ만을 고려하여 탐색합니다.
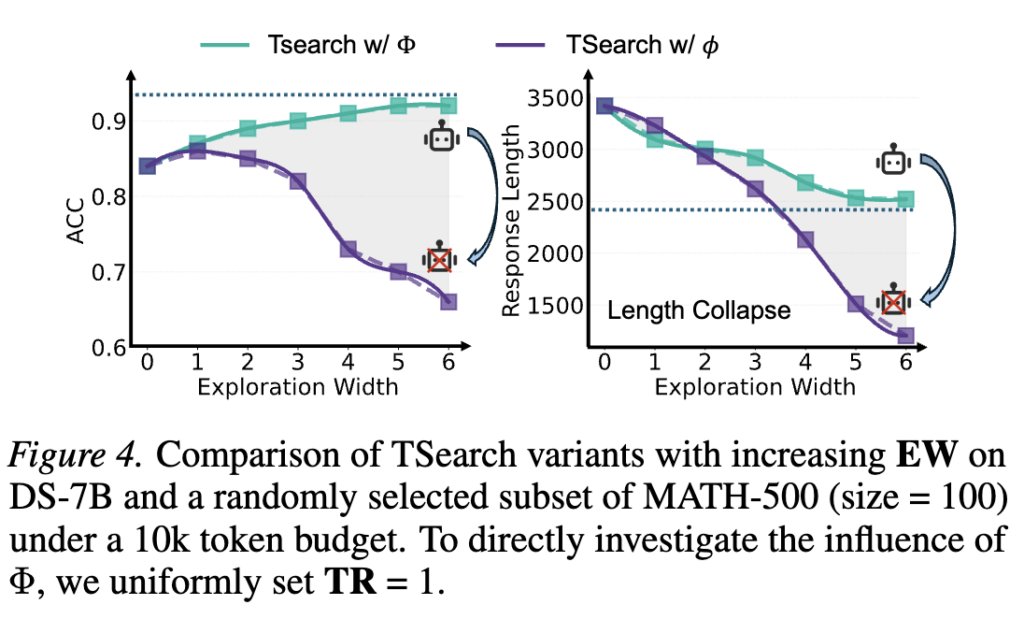
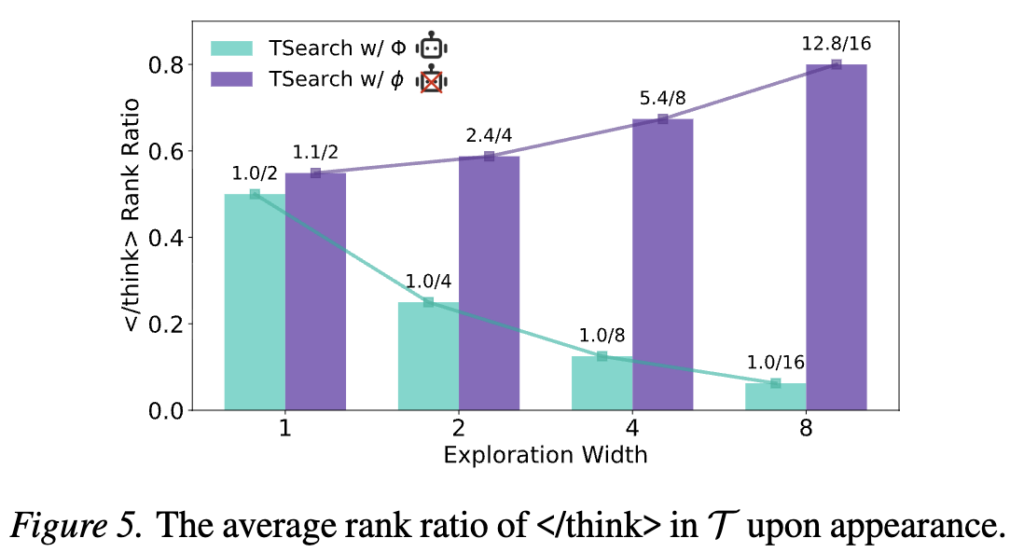
실험 결과 Figure4와 같이 전체 경로를 고려한 경우가 더 좋음을 확인할 수 있습니다. Ew는 탐색공간 크기로 m과 같은 의미인데, 탐색공간이 넓어질수록 본래 방식(청록색, TSearch(m, r) w/ Φ)은 개선폭이 넓어지나 TSearch (m, r) w/ ϕ는 그렇지 않음을 확인할 수 있으며, TSearch(m, r) w/ Φ의 경우 탐색 공간에 따라 효율적인 답변을 생성할 확률(응답 길이 감소)을 보이나 TSearch (m, r) w/ ϕ는 그렇지 않음을 확인할 수 있습니다. 또한 응답 종료 조건의 엄격함(TR, 작을수록 엄격)을 다양화하여 검토했을 때, TSearch (m, r) w/ ϕ의 경우 엄격하게 종료 토큰 생성시에만 종료하는 TR=0.5 에서만 베이스라인 대비 성능 개선이 있는 반면 원래 버전(TSearch (m, r) w/ Φ)의 경우 전반적인 성능 및 효율성 개선이 있었음을 확인할 수 있습니다. 즉, 전체 맥락을 보지않고 </think>의 등장여부만을 보는것은 좋지 않음을 확인할 수 있습니다.
</think> 토큰의 관찰에 있어 전체 문맥의 고려는 아래의 figure에서 더욱 명확히 확인할 수 있습니다. 전체 탐색 영역인 2m개에서 </think>를 관찰할 확률이 오리지널 버전은 급격히 증가하지 않고 1개로 유지되고 있으나 마지막 토큰만을 보는 변형 방법은 탐색공간에 따라 크게 증가하며 노이즈가 많음을 알 수 있습니다.
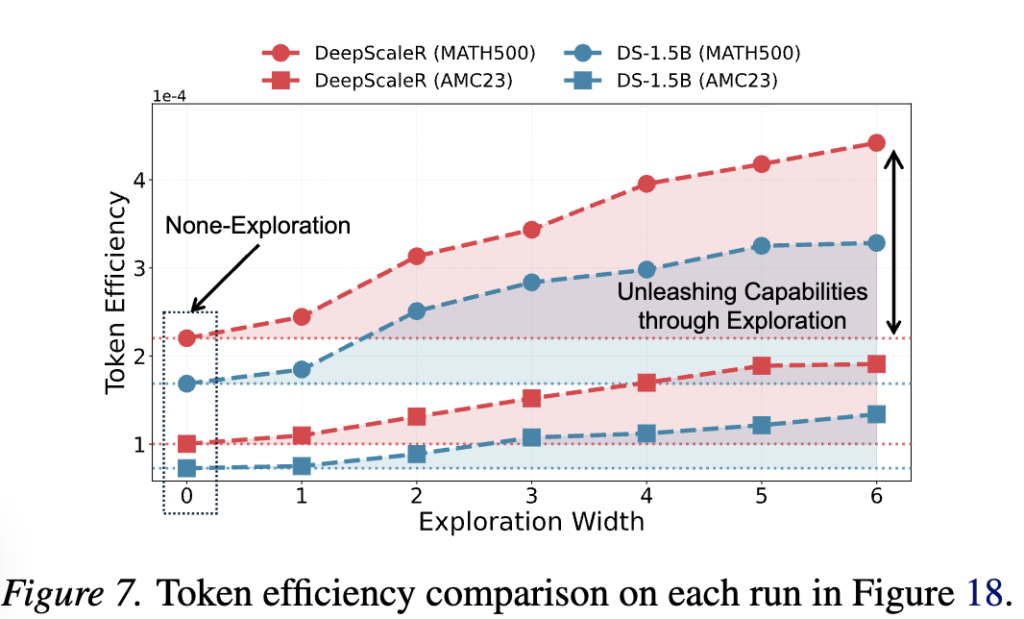
또한 재미있는 점은 탐색 영역의 크기를 증가할수록 토큰 효율성(정답률/토큰의 길이)이 증가함을 확인할 수 있습니다. 탐색 공간이 확장될수록 모델의 정확한 종료 토큰을 감지할 확률이 높아진다는 것입니다. 2가지 데이터와 이종 모델에 대해 동일한 추세를 보이며 이것이 일반적인 현상임을 검토할 수 있습니다.
SAGE
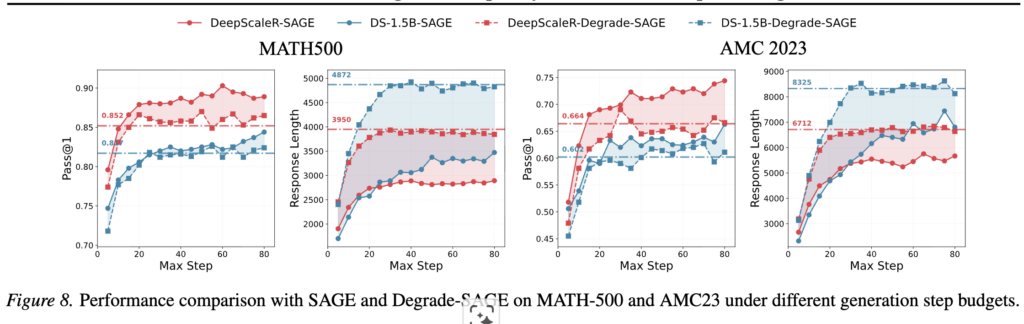
TSearch(m, r) w/ Φ 를 통해 논문은 모델이 종료토큰을 생성하기 전에 종료에 대한 확신이 생길 수 있음을 검토했습니다. 특히 탐색공간이 넓어질수록 효율이 증가했습니다 .그러나 추론시에 탐색공간을 무한히 증가시킬 수는 없습니다. 저자들은 이를 활용하여 실제 추론에 사용할 탐색기법인 SAGE를 제안합니다. SAGE는 TSearch(m, r) w/ Φ 를 효율화하기 위해 토큰 단위로 평가하는 것이 아니라 step 단위(일반적으로 줄변경 등 활용)로 확장을 평가합니다. 또한 table1에서 확인할 수 있듯이 문맥을 전체 고려하면 TR에 관계없이 성능이 개선됨을 확인하였으므로 생성 토큰에 </think> 가 포함될경우 종료되도록 조건을 단순화 했습니다. SAGE의 효과를 확인하기 위해 Degrade SAGE를 정의하여 비교하였습니다. Degrade SAGE는 pass@1과 다르게 m개의 탐색 브런치를 갖지만 </think>를 고려하지 않고 단순히 가능도만을 고려하여 최적 응답을 선택합니다. 그 결과는 figure8과 같으며 이종 모델과 데이터셋 모두에서 제안 방법이 효과적임을 확인하였습니다.
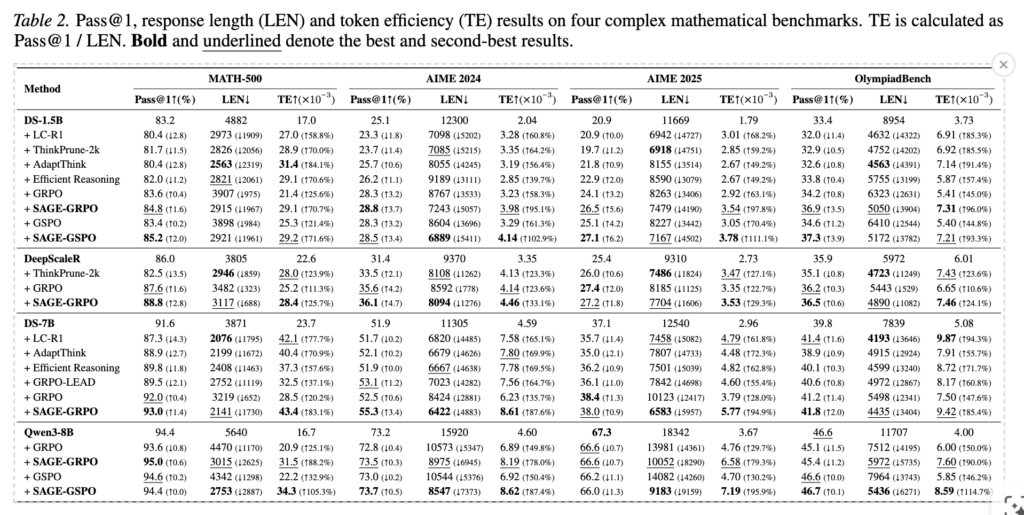
다음으로 논문은 이를 활용한 강화학습 기법 또한 제안했습니다. 기존의 학습 방법은 그룹의 응답을 활용하여 정답이라고 판단될 경우 보상을 주는 방식이였습니다. SAGE-RL은 pass@1으로 생성한 응답과 SAGE sampling 방식을 적용한 응답을 함께 학습합니다. 이를 통해 reward 함수 자체를 변경하지는 않았지만 고효율의 reasoning 분포를 학습 과정중에 관찰하게 되면서 효율적인 추론 패턴을 학습하게 됩니다. 그 결과는 table2와 같으며 다양한 모델, 데이터셋에서 효율적인 응답 생성에 기여하였음을 확인할 수 있습니다. 대부분의 베이스라인에서 토큰의 효율성과 응답의 정확도가 동시에 개선되었음을 확인할 수 있으며 SAGE-RL가 일관적으로 가장 좋거나 두번째로 좋은 효율성을 보이고 있음을 확인할 수 있습니다.
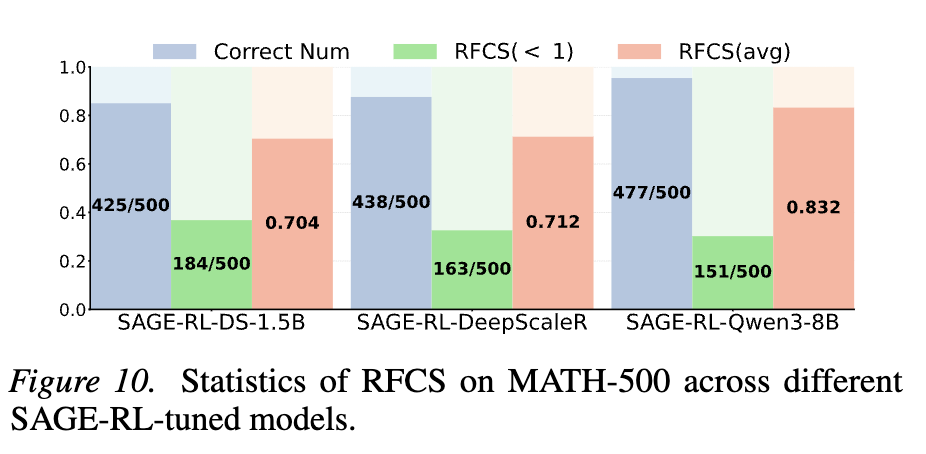
또한 앞서 확인하였던 효율성 지표인 RFCS 수치가 SAGE-RL 적용시 개선됨을 figure10을 통해 확인할 수 있습니다.
Conclusion
본 논문에서는 LRM이 암시적으로 생각을 멈추어야하는 시점을 알고있는지 확인하였습니다. 또한 샘플링 페러다임인 SAGE를 제안하여 효율적인 응답 생성을 위한 방법을 제시합니다. 이 뿐만 아니라 SAGE를 활용해 생성한 효율적인 응답을 학습에 활용시에 효과적으로 학습이 가능함을 SAGE-RL을 통해 보였습니다.
유진님 좋은 리뷰 감사합니다.
해당 논문은 과도하게 긴 추론 시간을 줄이기 위한 샘플링 방식을 제안한 것으로 이해하였습니다.
해당 논문과 관련하여 몇가지 질문이 있습니다.
먼저, RFCS는 정답을 맞춘 경우만을 측정하는 것 인가요? 그렇다면, 저자들이 제안한 방식으로 응답 시간이 빨라졌는지에 대해서 RFCS와 같은 상대적인 지표가 아닌 시간을 측정한 결과는 따로 없었는 지 궁금합니다.
또한, 해당 논문에서 설명하였던 샘플링 과정에서 2m개로 path를 확장하는 이유가 궁금합니다.
안녕하세요 승현님
리뷰를 읽어주셔서 감사합니다
오답일 경우 0/전체토큰 길이 로 계산됩니다. 또한 응답 시간 개선에 대한 내용은 아쉽게도 확인하지 못했습니다
2m개로 확장하는 이유는 샘플링 다양성을 높이기 위함입니다.
감사합니다.