안녕하세요. SayCan에 이어서 또 다른 유명한 LLM을 이용한 논문인 Inner Monologue 입니다. 사람이 독백을 하면서 생각을 정리하는 것처럼 LLM도 이를 이용해 action 성능을 향상시켜보겠다는 논문으로 보시면 되겠습니다. 그럼 시작하겠습니다.
1. Introduction
로봇은 여러 기본 행동을 상황에 맞게 사용할 수 있어야 하고, long-horizon task를 위해 행동들을 순서대로 배열할 수 있어야 하며, 어떤 행동이나 계획이 실패했을 때 다른 접근 방식으로 바꿀 수 있을 수 있어야합니다. 이렇게 행동하기 위해서는 high-level planing, perceptual feedback, low-level control이 함께 작동되야 하는데요. 사람으로 비유하면 머리로 순서를 정하는 일, 눈으로 상황을 확인하는 일, 손과 발을 실제로 움직이는 일에 가깝습니다. 또한 추가로 논문에서 언급하기를 기존에도 TAMP(task and motion planning)이나 HRL(hierarchical reinforcement learning) 관점에서도 해당문제를 다뤄왔지만 복잡한 문제를 잘 수행하기 위해서는 세상에 대한 semantic knowlege도 필요하다고 합니다.
그리고 여기에 추가로 LLM의 가능성도 제시하는데요. LLM은 자연스러운 문장을 생성할 뿐아니라 세계에 대한 semantic knowledge를 가진것처럼 보이기도 하는데요. 그래서 적절한 prompt가 주어지면, LLM은 어느정도 연역과 추론을 요구하는 질문에도 답할 수 있습니다. 그러면 LLM이 단순 language insturction을 처리하는 것을 넘어서, 여러 feedback source를 결합하는 추론 모델이 되어서 로봇 조작 같은 체화된 작업의 문제를 해결할 수 있지도 않을까요?
본 논문의 연구자들은 이를 인간의 내적 독백(inner monologue)로 해결해보고자 했는데요. 사람이 문을 열려고 할때 “열쇠를 집어 좌물쇠에 넣어 보자” -> “맞지 않네” -> “다른 열쇠를 시도해보자”와 같이 생각합니다. 이 과정에서 high-level의 목표를 해결하기 위한 즉각적 행동 선택, 시도한 행동의 결과 관찰, 관찰에 따른 행동 수정이 들어있는데요. 이러한 사고에 영감을 받아 LLM이 feedback을 통합하는 자연스러운 틀로 inner monologue를 제안하였습니다.
논문에서 제안하는 Inner monologue의 핵심은 LLM을 로봇의 직접적인 controller로 쓰는 것이 아닌데요. 이미 사전학습된 로봇 skill들이 있고, LLM은 그 skill들을 어떤 순서로 사용할지 정하는 planner 역할을 합니다. prompt는 LLM에게 보여주는 입력 기록이라고 보시면 되겠습니다. prompt에는 user instruction뿐만 아니라 로봇이 한 행동, 성공 여부, 장면 설명, 사람의 응답까지 함께 들어갑니다.
또한, 논문에서는 LLM을 여러 종류의 text feedback과 결합해 사용하는데요. 여기서 중요한 점은 추가 학습 없이 few-shot prompting으로만 사용한다는 것입니다.
정리하자면, 논문에서는 agent와 environment사이의 루프를 닫는 feedback 방법과 feedback source를 연구합니다. 여기에는 장면을 설명하거나 의미적으로 분류하는 여러 인식 모델, 로봇과 협력하는 인간 사용자, language description이 붙은 사전학습 로봇 조작 skill이 포합됩니다.
마지막으로 실험적으로, frozen language model과 사전학습된 로봇 skill외에 추가 학습을 요구하지 않고도, Inner monologue가 시뮬레이션과 두 실제 로봇 플렛폼에서 long-horizon task를 수행할 수 있음을 확인하였다고 합니다.

Figure 1에서 Introduction에서 소개한 Inner monologue의 동작을 확인할 수 있습니다. user instruction, 로봇의 행동, scene descriptor, success detector, 사람의 응답이 하나의 언어 기반의 루프 아에서 연결이 되는 모습을 보여줍니다.
2. Leveraging Embodied Language Feedback with Inner Monologue
2.1 Problem Statement
로봇 에이전트는 high-level language insturction i 를 수행하려고 합니다. 로봇은 “컵 집기”,”물체 놓기”처럼 미리 배운 작은 행동들만 할 수 있습니다. 이런 작은 행동을 policy 또는 skill로 다루고, policy 라이브러리 $\Pi$ 안의 한 기술을 $\pi_k \in \Pi$ 로 표기합니다. 각 기술에는 짧은 language desctiption $\ell_k$ 가 붙어있습니다.
정리하면 다음과 같습니다.
- i : 사용자의 high-level language instrcution
- $\Pi$ : 로봇이 사용할 수 있는 사전 학습된 기술들의 집합
- $\pi_k$ : 기술 집합 안에 있는 한 개의 low-level의 로봇 기술
- $\ell_k$ : 특정 기술을 설명하는 짧은 language description
- o : 환경에서 들어오는 observation feedback
여기서 o 는 성공 감지, object dection, scene desctipotion, VQA 등으로 구성될 수 있습니다. 중요한 점은 LLM이 읽을 수 있는 텍스트 형태로 제공된다는 것입니다.
2.2 Inner Monologue
논문에서는 Inner monologue를 “로봇이 환경과 상호작용하는 동안 여러 feedback source의 정보를 LLM plan prompt에 계속 넣는 과정”으로 설명합닏아. 기존 LLM planning 방식은 행동 목록을 한 방향으로 생성하는 경우가 많았는데요. 예를 들어서 [LLM 계획 -> 처음 행동 목록 생성 -> 그대로 실행 -> 실패해도 LLM이 모를 수도 있음]와 같은 경우가 있을 수 있는 것이죠. Inner monologue는 이런 흐름을 바꿔 실행 후의 관찰을 다시 LLM에게 알려줍니다. 예를 들어서 [Inner monologue -> 다음 행동 생성 -> 로봇 실행 -> 성공 여부와 장면 피드백 -> 피드백을 프롬프트에 추가 -> 다음행동 생성으로 다시 연결]처럼 이어집니다.
2.3 Sources of Feedback

논문에서는 Figure2에서 볼 수 있듯이 Feedback의 종류를 3가지로 분류하였는데요. 성공 감지(Success detection), 수동적 장면 설명(Passive Scene desctiption), 능동적 장면 설명(Active Scene Desctiption)입니다. 먼저 성공 감지에 대해서 설명해보겠습니다.
성공 감지는 low-level skill $\pi_k$ 가 성공했는지 판단하는 이진 분류입니다. 예를 들어서 “콜라를 집는다”라는 기술을 실행한 뒤, 성공 또는 실패를 텍스트로 LLM에게 알려줍니다. 시물레이션 환경에서는 Ground-truth 상태를 기반으로 작동할 수 있는 반면에, 현실 세계에서 작동할 때는 성공 감지기를 학습시켜 사용합니다.
수동적 장면 설명은 LLM이 따로 묻지 않아도 계속 구조화된 장면 정보를 제공합니다. 또한, LLM의 능동적인 프롬프팅이나 쿼리 없이 자동으로 제공되어 LLM 프롬프트에 주입되는 모든 환경 기반 feedback source를 포함합니다. 이러한 feedback의 일반적인 유형중 하나가 객체인인데요. 이러한 객체 인식의 텍스트 출력을 Object feedback이라고 부릅니다.
수동의 반대는 능동이죠. 수동 장면 설명의 능동적인 대응으로서 능동 장면 설명(Active Scene Description)은 LLM의 능동적인 쿼리에 직접 응답하여 제공되는 feedback source를 포함합니다. 이 경우 LLM은 장면에 대해 직접 질문할 수 있으며, 이 질문은 사람이나 VQA 모델과 같은 다른 사전 훈련된 모델에 의해 답변될 수 있습니다. 능동 장면 설명 설정에서는 LLM이 개방형 질문에 대한 비구조화된 답변을 받을 수 있어, 장면, 작업 또는 사용자의 선호도(사람이 제공한 응답의 경우)와 관련된 정보를 능동적으로 수집할 수 있습니다. 본 논문에서는 LLM planer가 feedback을 어떻게 통합할 수 있는지 조사하는 것을 목포로 하며, 구조화된 VQA 스타일의 fuman feedback과 비구조화된 인간 선호도의 feedback을 모두 연구하고 싶었기 때문에 사람이 제공한 답만 고려하여 이를 Human feedback이라고 부릅니다.
3. Experimental Results
본 논문에서는 Inner Monolgue가 특정 LLM이나 특정 로봇 플랫폼에만 의존하지 않는지 보기 위해서 3가지 환경에서 실험하였습니다. 첫째는 시뮬레이션 테이블탑 재배치(simulated tabletop rearrangement)이고, 둘째는 실제 테이블탑 재배치(real-world tabletop rearrangement)이며, 셋째는 실제 주방 환경의 모바일 매니퓰레이터(real-world mobile manipulator) 입니다.

Figure 3의 예시가 Inner Monologue의 작동 방식을 잘 보여주는데요. 사용자가 “탁자에서 음료를 가져와라”라고 요청하면, 로봇은 탁자로 이동하고, 보이는 물체를 장면 정보로 받으며, 사용자의 선호를 물어봅니다. 이후 콜라를 집는 행동이 실패하면 성공 감지 피드백을 받고 다시 집기를 시도합니다. 이는 단순히 처음 계획을 실행하는 방식과 다르다는 것을 보여줍니다.
3.1 Simulated Tabletop Rearrangement
시뮬레이션 실험은 Ravens 기반 환경에서 수행됩니다. 테이블 위에 여러 색의 블록과 그롯을 놓고, 로봇 팔은 자연어로 주어진 목표 배치에 맞게 물체를 옮겨야 합니다. 4개의 unseen task와 seen task에 대해서 평가하였습니다.
LLM은 InstructGPT를 사용하였구요. 여기서 알아야할 점은 LLM이 직접 로봇 팔의 관절 명령을 만들지는 않는 다는 것입니다. high-level의 행동 문장인 “노란 블록을 집어 파란 그릇에 놓아라”와 같은 문장을 생성합니다.
그리고 여러 형태의 feedback을 사용하였는데요. Object feedback은 현재 장면에 어떤 물체가 있는지 LLM에게 알려줍니다. Success feedback은 가장 최근의 low-level의 pick-and-place 실행이 성공했는지 알려줍니다. Scene feedback은 LLM이 처음에 추론한 하위 목록들 중 현재 어떤 목표가 달성되었는지를 알려줍니다. Object + Scene에서는 달성된 하위 목표 뒤에 ‘Robot thought’ 형태의 요약을 생성하도록 하였다고 합니다.
비교군으로는 long-horizon task instruction을 입력으로 받는 multi-task CLIPort policy를 사용합니다. CLIPort는 단일 단계 policy이브로 rollout 중 스스로 종료하지 않는데요. 그래서 종료 oracle을 받은 설정과 고정된 최대 단계 수로 반복하는 설정을 함께 리포팅하였습니다. Inner monologue도 실용적인 이유로 최대 step 수를 k=15로 두었다고 합니다.
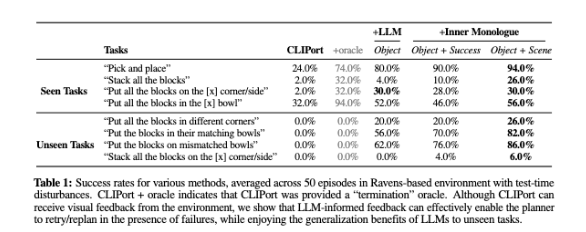
Table 1을 통해서 그 성능을 확인할 수 있는데요. Seen task에서 잘 수행하는 것을 확인할 수 있으며, 추가학습 없이도 unseen task에서도 동작하는 것을 볼 수 있습니다. 또한, Inner Monolobue 방식에서 Object + Scene 방식을 사용한 것이 가장 성능이 높은 것을 볼 수 있습니다. 마지막으로 CLIPort와 같은 비계층적이고 독립적인 시스템은 (1) 테스트 시간 교란 상황에서 학습되지 않은 long-horizon task의 일반화에 어려움이 있고, (2) 학습된 task에서는 좋은 성능을 위해 oracle이 필요하다고 합니다.
3.2 Real-World Tabletop Rearrangement
실제 테이블탑 실험은 시뮬레이션 테이블탑 재배치와 비슷한 유형의 작업을 실제 로봇 플랫폼에서 평가합니다. 하드웨어는 UR5e 로봇 팔과 손목 장착 Intel RealSense RGB-D 카메라로 구성됩니다. 작업 공간에는 블록, 음식 모형, 조미료 같은 다양한 물체가 사용되었다고 합니다. 물체 인식에는 open-vocabulary object detection 모델인 MDETR을 사용하였습니다. MDETR은 현재 보이는 물체 목록과 이전에는 보였지만 지금은 보이지 않는 물체 목록을 만드는 데 사용됩니다. 실제 테이블탑의 low-level 실행은 object-centric pick-and-place policy가 담당합니다. 이 policy는 장면의 물체 bounding box, 집을 물체 이름, 놓을 대상 이름, depth image, camera intrinsics, camera pose를 입력으로 받아 3D 집기 위치와 3D 놓기 위치를 산출합니다. 이후 로봇은 의도한 위치 15cm 위로 이동한 뒤, 접촉력이 감지될 때까지 end-effector를 낮추는 방식으로 집기와 놓기를 수행합니다. 물체 분류 작업에서는 접시 안에서 다른 물체와 멀리 떨어진 위치를 놓기 위치로 선택하여 불필요한 쌓임이나 낙하를 줄입니다.
성공 감지는 MDETR bounding box에서 얻은 물체 중심의 2D 위치와 의도한 놓기 위치를 비교하는 휴리스틱으로 구성됩니다. 휴리스틱은 학습 모델이 아니라 사람이 정한 간단한 규칙인데요. 블록 쌓기에서는 threshold가 3cm이고, 물체 분류에서는 접시 안에서 물체가 굴러갈 수 있으므로 threshold가 10cm로 설정됩니다. 논문에서는 실제 perception과 clutter 때문에 물체 인식과 성공 감지 모두 noisy할 수 있다고 명시되어있습니다.
평가 작업은 두 가지인데요. 첫째는 이미 두 블록이 쌓인 상태에서 세 블록 쌓기를 완성하는 작업입니다. 둘째는 과일과 병을 서로 다른 접시에 분류하는 장기 작업입니다. 회복 능력을 평가하기 위해 논문은 행동에 작은 가우시안 노이즈를 인위적으로 넣습니다. 본문에서는 policy action에 표준편차 4mm, 2배 표준편차 clipping의 노이즈를 추가했다고 합니다.
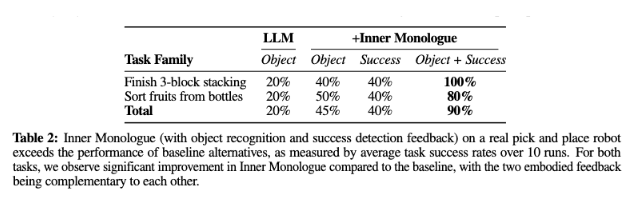
Table 2를 통해 실제 테이블탑 환경의 성공률을 확인할 수 있습니다. 초기 물체 정보만 사용하는 open-loop 변형, 매 단계 물체 정보를 갱신하는 변형, Sucess feedback 변형, Object+Sucess Feedback 변형 조합을 볼 수 있습니다. Object+Sucess 방식이 가장 높은 성공률을 가록한 것을 볼 수 있습니다.
논문에서는 초기 장면 설명만 사용하는 방식이 부분적으로 가려진 물체를 놓치기 쉽다고 분석하는데요. 그 결과 planner가 필요한 물체를 계획에 포함하지 못하거나, 한 번의 pick-and-place 이후 회복하지 못하는 실패가 발생한다고 합니다. Inner monologue는 매 단계 후 장면 설명과 성공 여부를 다시 받아 이러한 문제를 줄일 수 있다고 합니다.
3.3 Real-World Mobile Manipulator in a Kitchen Setting
주방 환경 실험은 SayCan에서 사용한 Everyday Robots 모바일 매니퓰레이터 환경과 작업 정의를 따릅니다. 로봇은 RGB 관찰을 사용하며, 7자유도 팔과 그리퍼를 가진 모바일 매니퓰레이터를 사용하였습니다. 5개 위치와 15개 물체가 있는 mock office kitchen에서 실험을 수행했다고 합니다.
사용한 LLM은 PaLM입니다. 기본 비교 대상인 SayCan은 LLM의 행동 후보 점수와 low-level의 정책의 value function를 결합하여 행동을 선택한다. 이는 제가 앞서 작성한 SayCan 리뷰를 참고하시면 좋을 것 같습니다.
주방 환경의 Inner Monologue는 SayCan의 affordance grounding을 유지하면서, LLM 프롬프트에 언어 피드백을 추가합니다. low-level policy는 SayCan 구현을 따릅니다. 평가는 총 120회 수행되며, 세 작업군을 포합하는데요. 첫째는 manipulation으로 “소다를 집어라”, “카페인이 있는 음료를 집어라” 같은 명령을 포함합니다. 둘째는 mobile manipulation으로 “탁자 위 소다를 버려라”, “콜라를 쏟았으니 닦을 것을 가져와라” 같은 명령을 포함합니다. 셋째는 drawer manipulation으로 “위 서랍을 열어 두어라” 또는 “위 서랍에 콜라를 넣어라” 같은 명령을 포함합니다.
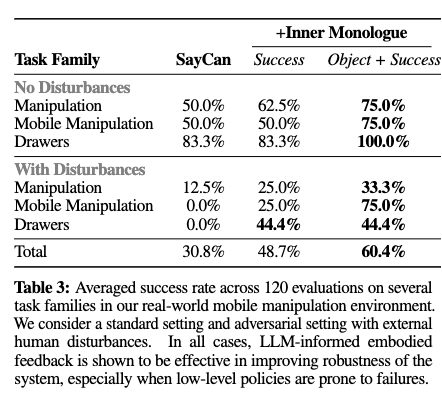
Table 3에서 SayCan, SayCan에 Inner Monologue를 추가한 것, Sucess + Object feedback을 추가한 Inner Monologue의 실제 주방 모바일 조작 환경에서의 성공률을 볼 수 있습니다. SayCan일 때 성능도 좋지만, 독백을 추가했을 때, 특히나 Object + Succuess를 추가했을 때 성능이 더 높아지는 것을 볼 수 있습니다.
4. Conclusion
해당 논문은 로봇 planning에서 LLM을 사용할 때 “계획을 한 번 잘 생성하는가”만인 아니라는 점을 보여주는 논문이었습니다. 실제 환경에서는 로봇이 행동하고, 실패하고, 물체를 새로 보고, 인간에게 묻고, 다시 계획해야 한다는 것이죠. Inner monologue는 이 반복 과정을 자연어 피드백으로 구성하였습니다.
SayCan에 이어서 Inner Monologue도 리뷰마쳐봤습니다. 앞으로도 계속 이쪽 계보를 찬찬히 리뷰해볼 예정입니다. 읽어주셔서 감사합니다.