안녕하세요 손우진입니다.
이번에 제가 리뷰할 논문은 로봇 관련 논문입니다. 매번 6D pose나 pose refinement와 같은 물체 perception 관련해서 리뷰를 많이 했는데요, 시대가 시대인 만큼 로봇을 계속 찾아보려고 하는 것 같습니다ㅎㅎ
처음으로 리뷰해보는 VLA 관련 논문입니다. 연구실 level에서 대규모로 VLA를 연구하기에는 쉽지 않겠지만, VLA를 활용해볼 수는 있지 않을까 개인적인 생각이 듭니다. 과연 그럼 활용할 수 있는 것이 무엇인가 고민해보면,
최근 로봇에는 이미지와 로봇 상태가 들어가는 것으로는 해결하지 못하는 문제가 많다보니 여러 센서를 통합하는 논문들이 집중되고 있습니다. 이와 관련해서 좋은 아이디어를 제시한 논문을 소개해 드리려 합니다.
Introduction
본격적인 리뷰에 앞서 이 논문이 왜 등장하게 되었는지 배경을 살펴보겠습니다. 최근 VLA(Vision-Language-Action) 연구가 집중되고 있다는 것은 모두가 알거라 생각이듭니다. 최근들어 현실 세계의 복잡한 물리적 상호작용을 해결하기 위해 기존의 2D RGB 이미지를 넘어 깊이, 촉각, 열화상, 오디오 등 다양한 모달리티를 추가로 접목하여 로봇의 인지 능력을 확장하는 추세입니다. 하지만 기존 연구들은 단순히 입력 센서의 종류만 늘렸을 뿐, 들어오는 모든 modlaity를 항상 동일한 비중으로 통합하여 처리하는 Static Fusion 방식에 머물러 있다는 명확한 한계가 있습니다. 이러한 방식은 현재 작업과 무관한 데이터까지 고차원 feature space에 투영시켜 불필요한 연산을 유발시키며, 무엇보다 특정 작업 단계에서는 필요 없는 센서 정보가 오히려 노이즈로 작용해 모델의 신뢰성과 강건성이 무너집니다.
논문은 이 문제를 인간의 ‘능동적 인지’ 메커니즘에서 찾았습니다. 인간은 알게 모르게 외부의 감각을 똑같이 수용하지 않습니다, 현재 수행 중인 작업의 목표에 따라 각 감각의 가중치를 능동적으로 조절합니다. 논문에서 제시한 ‘과열된 전자기기 끄기’ 작업의 예시를 보면, 인간은 처음 기기의 위치를 찾을 때는 시각적 단서에 전적으로 의존하다가, 기기에 접근해 위험을 평가할 때는 열 감각으로 주의를 전환하고, 실제로 기기를 쥐는 순간에는 촉각 피드백으로 처리합니다. 음 쉽게 말해서 작업의 단계에 따라 가장 신뢰할 수 있는 감각은 살리고 불필요한 감각 신호는 일시적으로 억제하여 정보 간섭을 최소화하는 것입니다.
이렇듯 인간의 인지적 선택 과정을 모방하여 로봇 역시 상황에 맞춰 감각을 조율해야 한다고 주장합니다. 실시간으로 불필요한 센서 데이터는 감쇠시키고 필수적인 시각 정보만 정책 네트워크에 전달하는 동적 라우팅 아키텍처를 핵심 방법론으로 제안합니다. 추가적으로, 언제 어떤 센서를 켜야 하는지 라벨링을 하려면 비용이많이 들어갑니다. 이에 저자들은 대규모 데이터셋 구축에 있어 어려운 점을, VLM을 활용해 사람의 개입 없이도 라우팅 학습 데이터를 만들어낼 수 있는 자동 라벨링 파이프라인을 함께 제시하여 입증하였습니다.
저자들의 Contributions는 다음과 같이 세 가지로 요약됩니다.
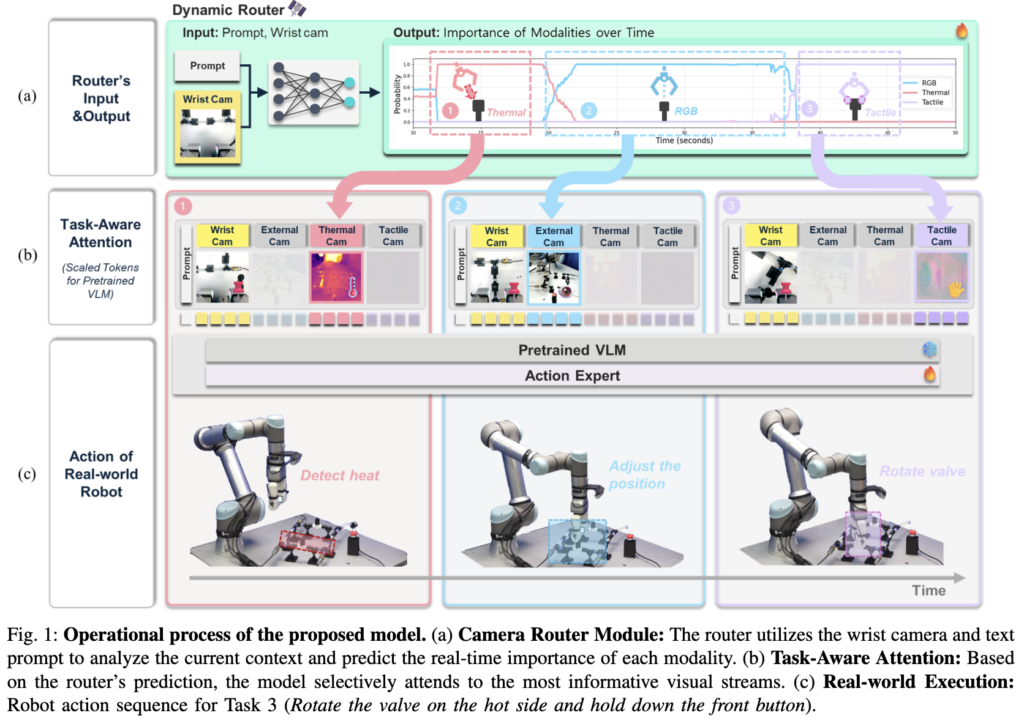
Context-Aware Router & Gating 메커니즘을 제안했습니다. 저자들은 로봇의 손목에 장착된 카메라를 기준점으로 삼아, 실시간으로 각 감각 모달리티의 중요도를 예측하는 Dynamic Router를 도입했습니다.
Long-Horizon 작업에서의 강건성을 확보했습니다. 핵심 모달리티들을 통합하기 위해 라우터 기반의 feature fusion 구조를 활용함으로써 모달리티 간의 정보 간섭을 줄이고, 결과적으로 연속적이고 긴 조작 작업에서 기존 방법들보다 더 높은 성공률을 달성했습니다.
확장 가능한 VLM 지도 학습(Scalable VLM Supervision) 을 구현했습니다. 라우터 학습에 필요한 라벨링 데이터를 확보하기 위해 VLM 기반의 자동 라벨링 파이프라인을 구축하였으며, 이를 통해 추가적인 데이터 수집 비용 없이 카메라 중요도 라벨을 자동으로 생성할 수 있었습니다.
Method
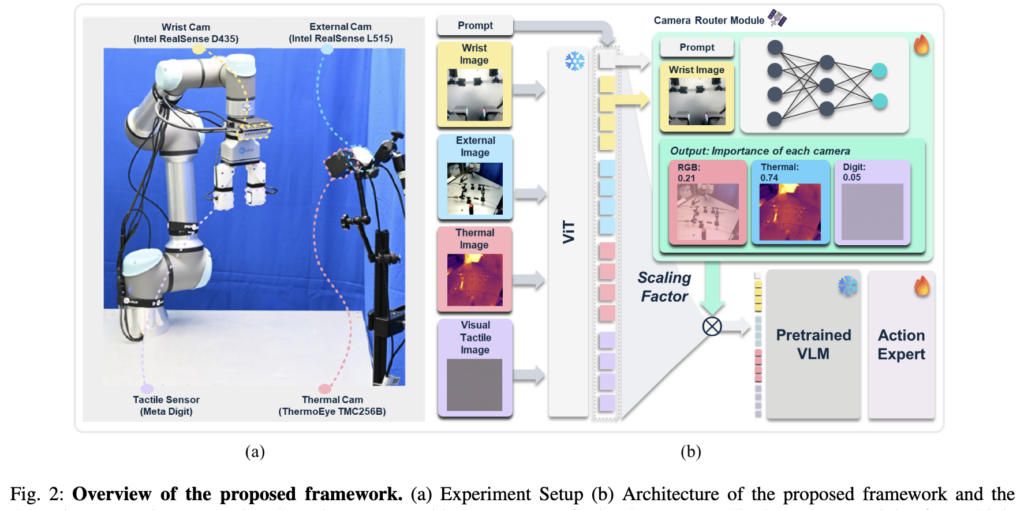
방법론에 설명드리겠습니다 우선 프레임워크는 위 Fig. 2와 같습니다 wrist cam에는 RGB 이미지 Third cam에는 RGB/Thermal 이 탑재되어있고 Gripper에는 Meta Digi이 달려있다고 합니다.
우선 전체적으로 설명드리면 핵심 아이디어는 VIT 와 VLM 사이에 카메라 라우터라는 새로운 문지기 모듈을 끼워 넣은 것입니다. 이 라우터는 들어오는 여러 시점의 센서 정보들이 현재 작업에 얼마나 필요한지 실시간으로 중요도를 계산하여, 작업 관련성에 비례하는 정보만 Policy Network에 전달하는 역할을 수행합니다. 하나하나 씩 디테일하게 설명드리겠습니다.
A. Training with Vision Language Action Model && B.camera Router Architecture
저자들은 엔드투엔드로 학습시켰고. VLA(파이0)는 LoRA파인튜닝을 통해 학습시켰습니다 전체 손실 함수는 행동 예측 오차 Action Loss (논문에서는 Flow Matching Loss 사용)와 라우터가 센서를 고르도록 학습시키는 Routing Loss의 가중합으로 구성됩니다. 여기서 주 목적인 행동 예측 성능을 떨어뜨리지 않기 위해 라우팅 오차의 반영 비율 람다 값은 은 0.1로 설정되었습니다.
그럼 이제 저자들의 핵심인 라우터를 설명드리겠습니다.
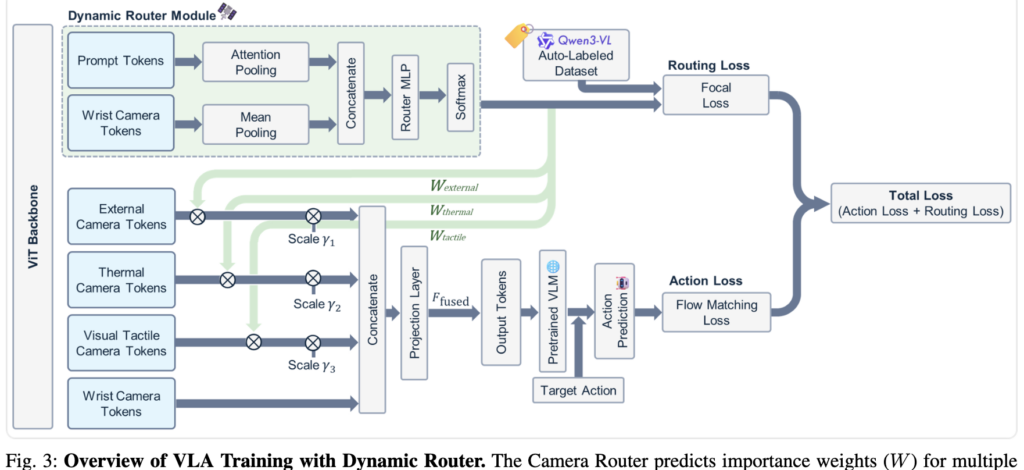
디테일 하게 모델을 보시면 VIT에서 나온 토큰으로부터 라우터 학습이 시작이되는데요 우선 라우터가 현재 로봇을 실시간으로 파악하기위해서 텍스트 프롬프트와 wrist cam이미지입니다. 두 토큰을 Pooling 연산을 통해서 Feeature fusion을 1차적으로 해주게됩니다. 그후 softmax를 연산해주고 W를 뽑압내게 됩니다 W 요소에는 각 센서들의 중요도가 담겨진다고 보시면됩니다.
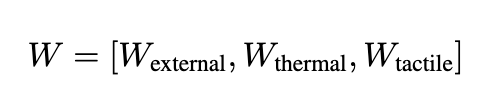
그 이후 감마 값을 곱해줘서 기존 Wrist cam과 다시한번 합쳐지게 됩니다.
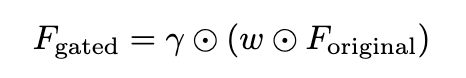
산출된 가중치 값들은 각 센서 모달리티의 벡터들에 실시간으로 곱해져서, 당장 필요 없는 센서 정보의 중요도는 줄이고 중요한 정보만 더 많은 가중치를 주게됩니다. 그리고 저자는 학습 안정성을 높이기 위해 스케일링 파라미터도 적용하였습니다. 이렇게 필터링을 거친 센서 정보들은 앵커 카메라인 손목 카메라 정보와 다시 하나로 합쳐진 후, 최종적으로 사전 학습된 거대 VLM에 융합된 시각 정보로 전달됩니다.
추가적으로, 저자들은 이 라우터를 학습시킬 때 ‘데이터 불균형’ 문제를 해결하기 위해 Focal Loss를 도입했습니다. 로봇 조작에서 열화상이나 촉각 센서는 대상과 접촉하거나 온도를 파악하는 순간에만 필요하게 되다보니 대부분의 동작에서 weight가 작을 거기때문에 데이터 불균형이 생기는 데 이를 조절하기위해서 Focal Loss를 통해서 조율하였습니다.
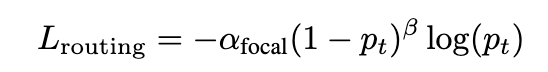
C. Auto-Labeling with VLM Labels
이 논문의 또 다른 Contribution은 라벨링 파이프라인입니다. 앞서 설명해 드린 라우터를 학습시키려면 비디오 프레임마다 지금 어떤 센서가 필요한지에 대한 라벨이 있어야 합니다. 하지만 사람이 일일이 확인하며 라벨링하는 것은 시간과 비용이 꽤나 드는 일입니다 저자들은 이 문제를 해결하기 위해 VLM(Qwen3-VL)을 활용해 자동으로 생성하는 방식을 제안했습니다. 과정은 간단합니다. 먼저 수집된 비디오를 약 2초 단위(30프레임)의 청크로 나누고, 그 안에서 10장의 대표 이미지를 뽑아냅니다. 그리고 이 이미지들과 함께 로봇의 작업 목표, 현재 그리퍼의 상태, 이전 행동 기록 등이 담긴 프롬프트를 VLM에 입력합니다.
VLM은 제공된 시각 정보와 상황 맥락을 종합적으로 분석하여, 각 단계마다 어떤 센서가 활성화되어야 하는지 [0, 1, 0]과 같은 형태의 ouput을 출력합니다. 이렇게 만들어진 자동 정답지는 앞서 언급한 Focal Loss를 통해 라우터를 학습시키는 기준이 됩니다. 결과적으로 저자들은 사람이 직접 라벨링하지 않고도 VLM을 통해 대규모의 학습 데이터를 확보할 수 있었다고 합니다.
Experiments
마지막으로 이 논문이 모델이 실제 환경에서 얼마나 효과적인지 증명하는 실험 부분을 살펴보겠습니다. 저자들은 세 가지 Task를 구성하였습니다.
Task 1은 ‘배터리 온도 기반 분류’ 작업입니다. 로봇 앞에 여러 개의 배터리가 놓여 있는데, 이 중에는 정상 배터리도 있지만 과열되어 위험한 배터리도 섞여 있습니다. 겉모습은 모두 똑같기 때문에 일반적인 RGB 카메라만으로는 무엇이 위험한지 알 수 없는데. 이때 로봇은 열화상 카메라 정보를 실시간으로 받아와 과열된 것은 폐기함에 넣는 작업입니다 (Visual + Thermal)
Task 2는 ‘와이어 선택’ 작업으로, 로봇의 Tectile 센서를 포함합니다. 구분되지 않는 두 종류의 와이어가 놓여 있는데 이들의 두께 차이는 0.4mm입니다 ㄷㄷ. 로봇은 직접 와이어를 손가락로 살짝 grasping하고, 이때 느껴지는 촉각 센서의 압력 피드백을 통해 정확한 와이어를 골라내야 합니다. (Visual + Tactile)
Task 3은 모두를 포함한 ‘Long-horizon’ 시나리오입니다. 로봇은 먼저 과열된 밸브를 안전하게 돌려서 닫은 뒤, 이어서 바로 옆에 있는 버튼을 눌러 시스템을 정지시켜야 합니다. 이 과정에서 로봇은 뜨거운 밸브를 다룰 때는 열화상 정보에 집중해야 하고, 버튼을 누를 때는 정확한 위치 파악을 위해 다시 시각 정보로 주의를 돌려야 합니다. (Visual + Thermal + Tectile)
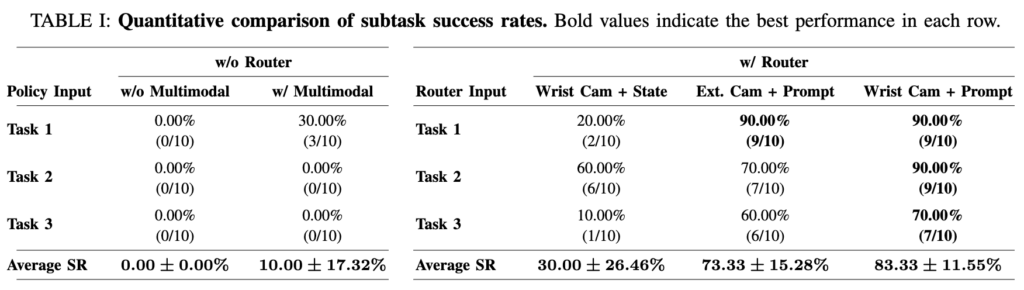
Table I에 나타난 모델별 성공률 비교입니다. 오직 RGB 이미지만 사용하는 베이스라인 모델(Base Policy)은 당연하게도 열이나 촉각 정보를 알 수 없어 모든 작업에서 성공률 0%입니다. 추가적으로 모든 센서를 항상 켜두고 정보를 섞어버리는 Static Fusion 방식 역시 성공률이 10%에 그쳤습니다. 반면, 저자들이 제안한 동적 라우터 모델을 통해 83.33%라는 성공률을 기록하며 라우터의 효과를 볼수있습니다. 또한 wrist cam과 prompt를 주면서 실시간으로 접근이나 grasping하는것을 보는 wrist cam과의 중요성을 보여주는것 같습니다.
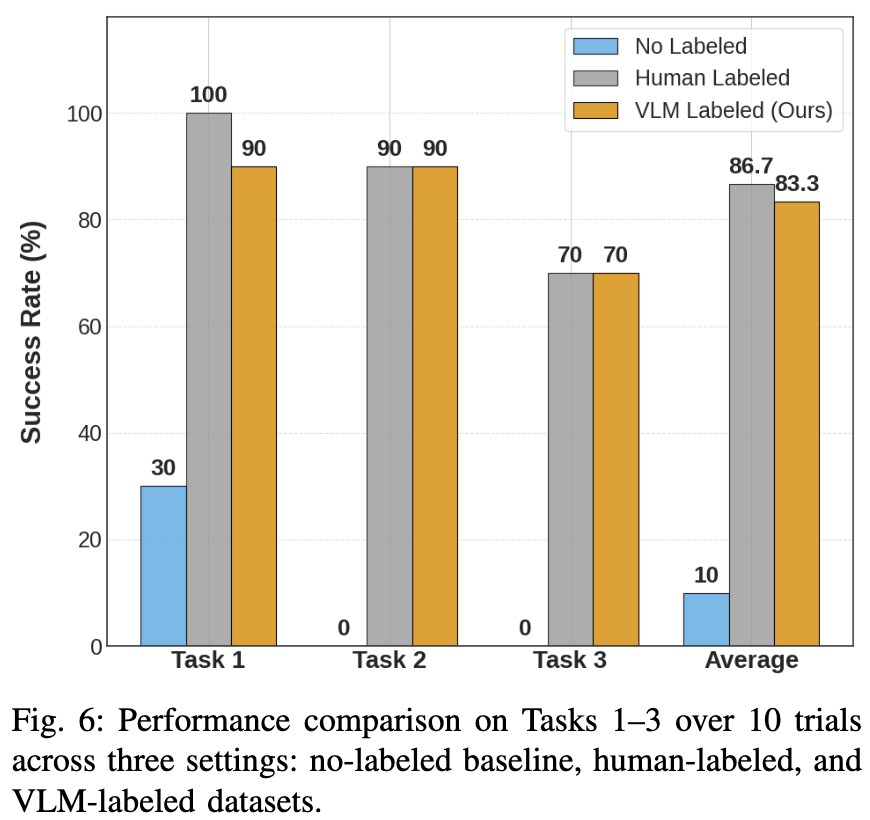
마지막으로 자동 라벨링의 성능입니다. 직접 라벨링 한것과 VLM을 이용하여 라벨링 한 성능비교인데요 사람이라벨링 작업을 하지 않더라도, VLM을 활용한 파이프라인만으로 로봇 제어 모델을 학습시킬 수 있다는 것으로 저자들은 제시하는 것 같습니다. 라벨링이 없는 것 같은경우에는 각 센서들이 노이즈하게 들어갔기에 성능이 안나오지않았을까 예상이됩니다.
리뷰 읽어주셔서 감사합니다 멀티센서가 유행이여서 한번 리뷰해보았습니다. 센서를 고려할때 인가의 행동에서 아이디어를 먼저생각하고 이를 모델에 적용하는 방향이 맞는것 같습니다 또한 멀티센서를 사용할때 유연하게 동작할 수 있는 학습방법 또한 효율적으로 보입니다.
감사합니다
안녕하세요 우진님 좋은 리뷰 감사합니다.
몇가지 궁금증이 생겨서 질문 남깁니다.
Q1. 앵커 카메라가 왜 wrist cam으로 사용하였는지 논문에서는 따로 언급한 내용이 있을까요?
Q2. 논문에서는 visual tactile sensor를 사용한 것 처럼 보입니다. task를 수행할 때 압력 정보의 차이로 구분한다고 하셨는데 visual tactile에서 압력 정보가 어떻게 쓰이는지 궁금합니다.
감사합니다.
질문 감사합니다
Q1 . 앵커 카메라가 왜 wrist cam으로 사용하였는지 논문에서는 따로 언급한 내용이 있을까요?
저자들은 wrist cam을 사용함으로썬 ego-centric 관점에서 실시간으로 물체와 로봇간의 관계를 이어주기에 wrist cam을 사용하였다고 하고 ablation 에서도 third cam과 prompt도 진행되었지만 wristcam과 prompt를 진행하는 것이 더 성능이 좋았다고 합니다
Q2 . 논문에서는 visual tactile sensor를 사용한 것 처럼 보입니다. task를 수행할 때 압력 정보의 차이로 구분한다고 하셨는데 visual tactile에서 압력 정보가 어떻게 쓰이는지 궁금합니다
논문에서 압력정보는 이용되지않고 tactile 센서가 입력되는 시각적 이미지로만 사용하였습니다. 추가적인 압력정보에 대한 것은 저자들의 따로 작성된 것은 없고 vision이미지로만 처리되었다고 나와있습니다.!
감사합니다
안녕하세요 우진님 좋은 리뷰 감사합니다. 궁금한 부분이 있어서 남겨놓습니다.
Q1. router의 input에 다른 sensor나 camera는 포함하지 않고 prompt와 wrist cam만 들어가는 이유가 궁금합니다.
Q2. 사람이 labeling 할 때, 어떤 sensor가 중요한지 판단하는 기준이 언급되었는지 궁금합니다.
감사합니다.
Q1. router의 input에 다른 sensor나 camera는 포함하지 않고 prompt와 wrist cam만 들어가는 이유가 궁금합니다.
Table 1에 보면 third cam과 state를 넣는 실험들이 진행되었습니다. 아무래도 저자들이 얘기하는것은 다른 외부센서는 계속해서 필요한것이아니라 필요한 순간에만 이용하기에 가장 메인은 RGB이기에 다른 외부센서는 이용하지않은 것 같습니다!
Q2. 사람이 labeling 할 때, 어떤 sensor가 중요한지 판단하는 기준이 언급되었는지 궁금합니다
사람이 labeling할때 저도 annotation 을 안해봐서 모르겠네요 ..ㅋㅋㅋㅋ논문을 찾아봐야할 것 같은데 뭐 만질때는 촉각이 중요하다 이런 것 아닐까요 ? 휴리스틱하게 접근한다고 저는 이해를 했습니다..!
감사합니ㅏㄷ
안녕하세요 우진님, 좋은 리뷰 감사합니다.
1. 수집된 비디오를 약 2초 단위(30프레임)의 청크로 나누고, 그 안에서 10장의 대표 이미지를 뽑아내는 과정은 어떤 방식으로 이루어지나요? frame selection 되는 방식에 따라 데이터의 의미가 크게 달라질 것 같은데요.
2. 인하님의 Q1과 연결되는 질문인데, 동적 라우팅 모듈의 anchor input이 결국에 prompt와 wrist cam이고, 그 밑에선 wrist cam token이 또 들어가잖아요. 결국 anchor input을 어떻게 정의했냐에 따라 라우터에서 각 모달리티 특화된 정보 간 fusion되며 학습되는 경향이 달라질텐데, 애초에 prompt+wrist input 위주로 학습된 놈 가지고, Table I 에서는 아무튼 prompt+wrist input 가 성능 좋다고 과하게 주장하는 거 아닌가 싶습니다. anchor input을 바꿔서 학습했을 때의 ablation이나 anchor가 wrist여야 하는 점과 관련된 저자들의 언급이 있나요?
감사합니다.
Q1. 수집된 비디오를 약 2초 단위(30프레임)의 청크로 나누고, 그 안에서 10장의 대표 이미지를 뽑아내는 과정은 어떤 방식으로 이루어지나요? frame selection 되는 방식에 따라 데이터의 의미가 크게 달라질 것 같은데요.
frame selection 또한 중요하겠네요 자세하게 언급은 없었습니다. 재찬님이 말씀주신 30프레임의 청크로 나누고 10장의 이미지를 사용해서 그 10장의 이미지를 통해 vlm 입력으로 넣어주게되는 구조입니다 이전 프레임들을 보면서 vlm이 이해하기에 이것이 접근중인지 또는 짚고 물체를 놓으러 가는건지 등등 을 구분해주기위해 10장을 씁니다. 선택에 중요성도 물론 있게지만 저자의 언급은 따로없었습니다..ㅎㅎ
Q2. 인하님 Q1에 답변 달았습니다. ㅎㅎㅎ 재찬님이 말씀주신 부분에 충분히 이해가 갑니다. 애초에 모델 설계를 그런식으로 하였고 다른 외부캠과 프롬프트 wrist cam과 state는 ablation 처럼 보이는 것 처럼 느껴지는 것이 저자들이 얘기하는 routing과 gating을 적용해서 하였는지등 이런 디테일은 언급은 없었습니다.