안녕하세요. 오랜만에 x-diary를 작성하는 것 같습니다. 제가 정말 좋은 기회로, 동그라미 재단에서 후원하여 국내 1호 프롬프트 엔지니어로 유명한 강수진 박사님께서 진행하시는 [프롬프트 엔지니어링(심화)] 수업을 수강하게 되었는데요. 매우 유익한 시간이었습니다. 다시 이런 기회가 있었으면 하는 마음이 드는 수업이었어요. 너무나도 귀한 정보가 많이 있었다고 생각이 들어 여러분들께 꼭 정리해서 공유드리고 싶었습니다. 최대한 수업 내용을 꾹꾹 담아서 고봉밥처럼 담았습니다. (너무 많아 2편으로 나눴으니 참고해주면 감사하겠습니다)
1. 좋은 프롬프팅은 답변 품질이 아니라 제어력을 만든다.
수업을 들으면서 느꼈던 것은, 수업을 관통하는 핵심은 프롬프트를 “질문을 잘 쓰는 법”으로 보지 않는 데에 있다는 것입니다. 최근 논문을 보면 알 수 있겠지만, 프롬프트는 모델에게 던지는 자연어 문장이 아니라, 모델의 역할, 입력, 맥락, 출력 형식, 도구 사용, 평가 기준을 한 곳에 묶는 engineering interface라고 보는 것이 좋습니다. 그래서 좋은 프롬프팅의 효과도 단순히 “답이 좋아졌다”로 끝나는게 아닙니다. 반복 실행해도 출력 패턴이 안정되고, 불필요한 토큰과 비용이 줄고, 환각과 편향이 드러나고, 코드가 받을 수 있는 형식으로 결과가 고정되는 것입니다.

위의 Figure는 제가 만든 Figure인데요. 수업자료를 사용할 수 없어서 가내수공업하였습니다.
본 글은 Figure 1과 같은 구조로 요약할 수 있을 것 같습니다. 혹여나 잘 안보이실 것 같아 작성하자면, “문장으로서의 프롬프트 -> 구조화 프롬프트 -> 메세지 구조 -> 프롬프트 템플릿 -> 체인과 출력 파서 -> 컨텍스트 엔지니어링 -> 하네스 엔지니어링 -> 스킬”과 같습니다.
2. 프롬프트 엔지니어링(Prompt Engineering)의 실제 정의
수업에서 프롬프트 엔지니어링은 모델에게 말 잘 거는 기술이 아니었는데요. 더 정확히는 LLM의 비결정성, 모델별 차이, context window, 비용, latency, 출력 형식, 평가 모호성을 다루는 설계 작업이었습니다.
박사님께서 반복해서 표현하시기를 “프롬프트는 설계와 평가의 대상”이라는 관점이었습니다. 좋은 프롬프트는 한번 잘 나온 답변이 아니라, 실패가 났을 떄 어디를 고쳐야 하는지 위치를 알 수 있게 만드는데요. 그래서 박사님께서 프롬프트를 코드처럼 다루는 태도, 즉, 구조화, 변수화, 반복 태스트, 비용 측정, 평가 로그를 강조하셨습니다.
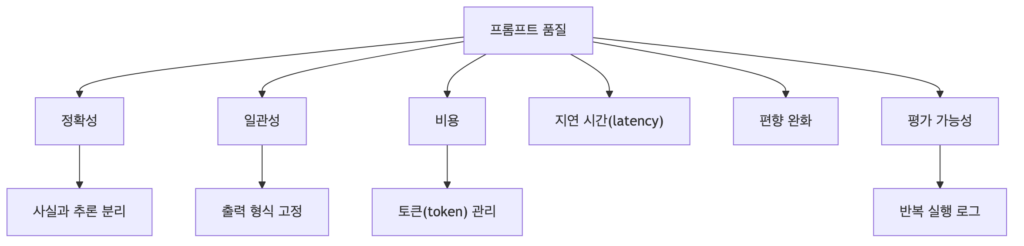
그럼 이런 관점이 중요할까요? LLM을 이해하면 알지만, 모델이 사람처럼 문장을 이해해서 답하는 것이 아니라 실제 출력은 다음 토큰의 확률 분포 위에서 만들어지기 때문입니다. 단어 하나, 순서 하나, 심지어 구두점 하나까지 답변의 분포를 바꿀 수 있습니다. 그래서 “대충 뜻은 같으니까 괜찮겠지~”가 잘 통하지 않습니다.
프롬프트가 어려운 이유는 4가지로 정리할 수 있는데요.
- 표현과 서식 민감도
앞에서 방금 언급했듯이 모델은 의미가 비슷한 문당이더라도 header, 구분자, 줄바꿈, 순서가 달라지면 다른 확률 경로로 응답할 수 있습니다
-> 이는 Markdown, JSON, XML처럼 구조를 드러내는 형식 고정하게 되면 대응이 가능하게 됩니다.
2. 예시와 샘플 순서 민감도
few-shot으로 예시를 들게되면 모델에게 빠르게 패턴을 알려주지만, 예시의 위치, 개수, 분포, 순서가 모델의 판단 기준 자체를 끌고 갈 수 있습니다
-> 그래서 zero-shot으로 baseline을 확인하고 정말 반드시 필요한 경우에만 대표성 있는 예시를 추가한다고 합니다. 실제로 박사님께서는 많은 기업들의 프롬프트를 컨설팅하면서 zero-shot을 적극 활용한다고 하셨습니다.
3. 재서술에 따른 성능 분산
multi-turn 대회에서는 사용자가 요청을 다시 말하는 과정에서 원래 조건이 빠지거나 바뀌기 쉽습니다. 이 때문에 같은 의도라도 재서술 과정에 따라 출력이 달라질 수 있습니다
-> 그래서 중요한 작업일수록, singe-turn에 충분히 명시하거나, 흩어진 조건을 요약하고 재정렬해 다시 입력하는 방식으로 대응해야 합니다. 박사님께서는 수업때 이 부분을 정말 강조하셨던 것이 본인의 경우, 무엇을 요청할 때 반드시 아주 명확히 작성하여 무조건 singe-turn 안에 원하는 바를 끝내려고 하셨다고 합니다.
4. 평가의 어려움
이 부분은 정말 많은 연구원분들이 공감하실 것이라 생각합니다. 요약, 분류, 추출, 번역처럼 작업 마다 좋은 답의 기준이 다르기 때문에 한번의 성공 사례만 보고 프롬프트를 확정하면 위험합니다.
-> 따라서 평가 기준, 비교, 샘플, 반복 테스트, 비용 로그를 함께 기록하면서 프롬프트가 실제로 안정적인지 확인해야합니다.
3. 프롬프트의 제어 대상
프롬프트가 제어해야 하는 것은 답변 내용만은 아닌데요. 출력 제어, 정확성, 편향 완화, 적응성, 문맥 이해, 경제성, 윤리적 사용이 서로 trade-off를 가집니다.
예를 들어서, 매우 긴 system prompt를 쓰면 모델의 행동을 더 많이 제어할 수 있습니다. 그러면 input token이 매우 많이 늘어나게 되겠죠. 출력 형식을 강하게 제한하면 후속 처리는 쉬워지지만, 설명이 필요한 task에서는 정보량이 부족해질 수 있고, few-shot 예시를 많이 넣으면 패턴은 잘 잡히지만 example bias가 생길 수 있습니다.
그래서 좋은 프롬프팅은 task의 목적에 맞게 제어 수준을 정하는 것인데요. (박사님의 말로는 프롬프트의 이해도가 낮은 분들은 만능 프롬프팅 문장이 있다고 생각한다고 하네요. 당연히 아닙니다.) sentiment analysis처럼 출력이 하나의 label이면 출력 형식을 아주 강하게 제한해야하고, 반대로 보고서 요약처럼 관점과 맥락이 중요한 과제라면 목적, 독자, ㅓ근거, 요약, 수준 등의 제외할 요소를 함께 넣어야 합니다.
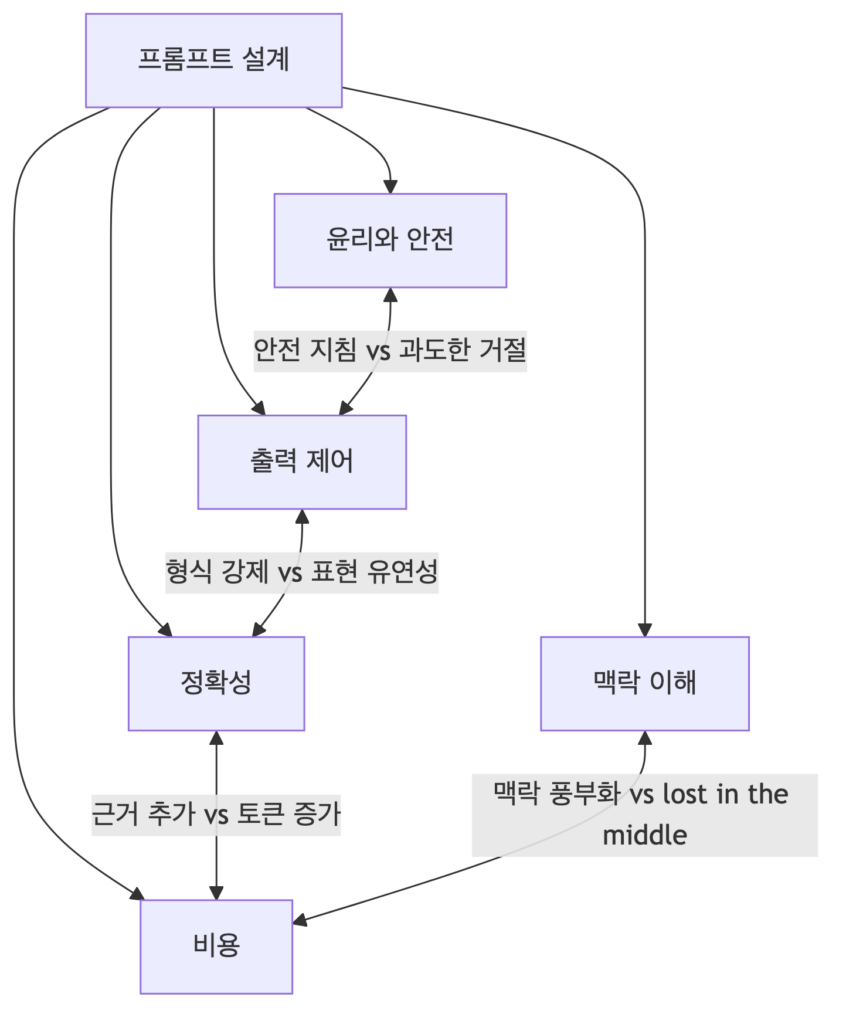
Figure 3은 위의 내용을 정리하여 만들었는데요. 표현하고자 했던 것은 프롬프트 설계가 하나의 목표만 최적화하는 일이 아니라는 점을 보여드리고 싶었습니다. 그리고 각 요소에서 어떤 것을 풍부하게 가져갈 수록 무엇을 trade 할 것인지를 직관적으로 작성하였습니다. 그 예시로 맥락 이해를 보시면, 맥락을 풍부화 하는 것은 비용과 연관되어 있고, 적당히 정보를 추가하여 맥락을 풍부하게 할 것인지 혹은 너무나도 많은 정보를 넣어 중간에 묻혀 소실될 것인지를 vs로 작성해봤습니다.
4. 메세지 구조(Message Structure)
수업에서 다룬 것 중에 중요했던 것은 메세지 구조(message strucure)였습니다. Web UI에서는 한 입력창에 모든 것을 넣기 쉽지만, API나 프레임워크에서는 role을 분리해야하는 데요.
여기서 주의해야할 것은 역할 이름과 우선순위는 모델 제공사와 API에 따라 조금씩 다릅니다. 예를 들어서 OpenAI의 Responses API와 평가(evals)입력에서는 system, developer, user, assistant 역할을 구분하지만, 일부 프레임워크나 다른 제공사의 API는 system, user, assistant만 노출되어 있거나 별도 파라미터로 시스템 지침을 받는 경우도 있습니다.
그래서 아래 표를 준비해봤는데요. 특정 SDK 문법이라기보다는 역할을 나누는 설계 원리로 읽는 편이 참고하기 좋을 것 같습니다.
| 역할 | 한국어 설명 | 넣어야 하는 내용 | 흔한 실수 |
|---|---|---|---|
| 시스템 메시지 (system message) | 모델의 운영체제 또는 매뉴얼 | 장기 유지 지침, 역할, 정책, 출력 원칙 | 현재 입력 데이터까지 넣어 매번 흔들리게 함 |
| 개발자 메시지 (developer message) | 애플리케이션 개발자가 정한 실행 규칙 | 보안, 도구 사용, 앱 정책, 우선순위 | 사용자 요구와 충돌하는 정책을 애매하게 씀 |
| 사용자 메시지 (user message) | 매번 바뀌는 요청과 입력 | 현재 질문, 문서, 변수 데이터 | 시스템 지침까지 사용자 메시지에 모두 넣음 |
| 어시스턴트 메시지 (assistant message) | 이전 응답 또는 프리필(prefill) | 대화 이력, 출력 시작 조건, 역할 지속 | 예시와 실제 답변을 혼동하게 만듦 |
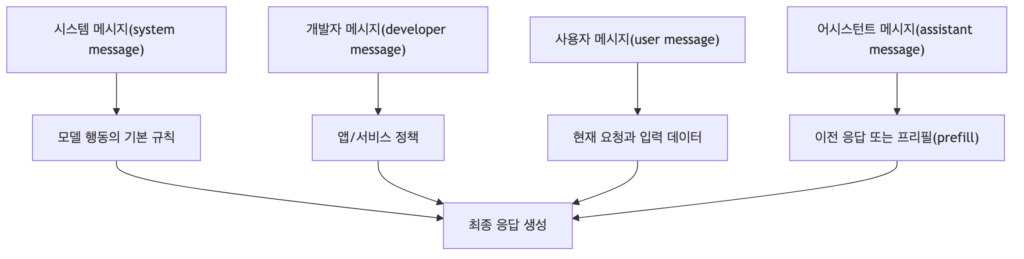
해당 표는 메세지 구조를 “누가 어떤 책임을 갖는가”의 관점에서 나누었는데요. 해당 관점을 딱 가지고 보시면 쉽게 이해하실 수 있습니다. 핵심은 모든 지시를 한 덩어리의 user message에 넣지 않고 바뀌지 않는 규칙과 매번 바뀌는 입력을 분리하는 데 있습니다. system message는 모델의 기본 행동 규칙을 알고, developer message는 서비스나 애플리케이션의 실챙 정책을 조정하며, user message는 현재 요청과 입력 데이터만 답는 것이 이상적입니다.
마지막 열에 [흔한 실수]는 시제 품질 저하가 어디서 시작되는지 보여주는데요. system message에 현재 입력 데이터를 넣으면 재사용이 어려워지고, developer message가 애매모호하게 작성되어 있으면 사용자 요청이 정책을 덮어쓸 수 있습니다. user message에 장기 규칙까지 모두 넣으면 multi-turn 대화에서 지시가 프려지고, assistant message의 예시와 실제 답변을 구분하지 않으면 모델이 예시 형식을 그대로 답변으로 착각할 수 있습니다. 그래서 message structure는 프롬프트의 재현성과 보안성을 만드는 첫 단계라고 보시면 좋습니다.
수업 때 강조 되었던 것이 “system message는 OS 또는 매뉴얼이고, user message는 변수”라는 구분이었습니다. 그래서 실제 예시로 프롬프트를 보면 아래와 같습니다.
- 나쁜 구조
너는 친절한 분석가야. 아래 데이터를 공정하게 분석하고 JSON으로 답해.
이번에는 채용 점수표를 줄게. 학력 보너스가 있는지 봐줘.
데이터: ...- 개선된 구조
[System]
You are an evaluation analyst.
Separate facts, assumptions, and recommendations.
Return only valid JSON.
[User]
Analyze the following hiring evaluation data.
Input data:
...
개선된 구조의 효과는 단순한데요. 바뀌지 않는 규칙과 매번 바뀌는 입력을 분리하므로 재사용성과 디버깅 가능성이 올라갑니다. 이후 tool calling, 구조화 출력, MCP에서도 같은 원리가 반복됩니다.
5. 프리필(Prefill)과 연속성(Continuation)
프리필(prefill)은 assistant message에 출력의 시작 부분을 미리 넣어 모델의 다음 생성을 유도하는 방식입니다. 이 기법은 특히 Claude API에서 명시적으로 지원되는 패턴이고, extend thinking 모드에서는 제한이 있다고 합니다. OpenAI 계열 API에서는 이전 assistant message를 대화 이력으로 넣을 수 있지만, 모든 엔드포인트가 부분 assistant message를 Claude식 프리필로 처리한다고 가정할 수는 없습니다.
예를 들어서 JSON만 출력해야할 때 다음과 같이 system message만 쓰는 방법은 종종 실패하는 경우가 있습니다.
# Output Format
Return only JSON.이때 assistent message에 {를 미리 넣어두면 모델은 “이미 JSON을 시작했다“고 보고 이어서 생성합니다
[Assistant prefill]
{연속성(continuation)도 비슷한데요. “우리는 이전에 이 문제를 논의하고 있었다” 같은 신호를 넣으면 모델은 처음 만난 사용자에게 답변하는 대신, 이어지는 대화의 톤과 맥락을 더 쉽게 유지합니다. 다만 주의할 것이 이 기법을 잘못 쓰면 가짜 맥락을 만들어낼 수 있으므로 실제로 필요한 경우에만 사용해야 합니다.
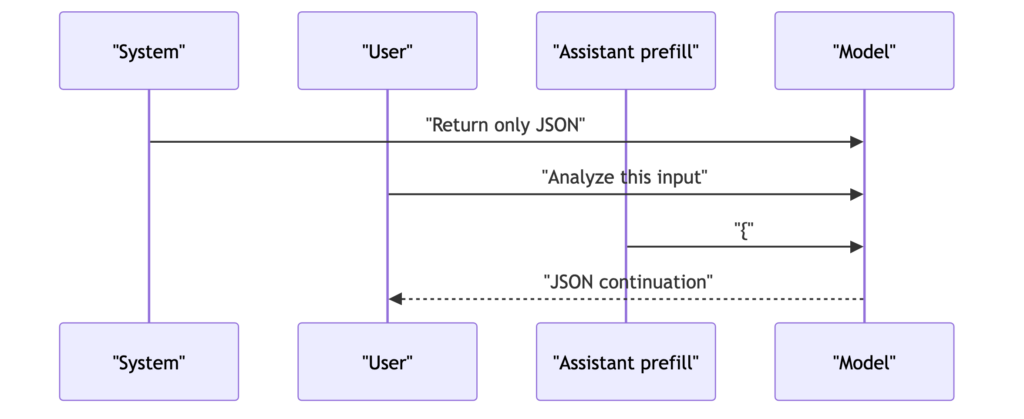
Figure 5는 프리필이 실제 메시지 흐름 안에서 어디에 놓이는지를 보여줍니다. system message는 “JSON만 출력하라”는 규칙을 주고, user message는 분석할 입력을 제공합니다. 여기에 어시스턴트 프리필(assistant prefill)로 {를 먼저 넣으면, 모델은 빈 화면에서 답변을 시작하는 것이 아니라 이미 열린 JSON 객체를 이어 쓰는 상태가 됩니다.
Figure의 핵심은 프리필이 별도의 후처리 장치가 아니라 메시지 구조 안에 들어가는 시작 조건이라는 점입니다. system message가 규칙을 설명한다면, 프리필은 모델이 그 규칙을 따르기 쉬운 첫 토큰을 제공합니다. 그래서 출력 형식이 중요한 작업에서는 “무엇을 출력하라”는 지시와 “어디서부터 시작하라”는 초기조건을 함께 설계해야 합니다.
또 하나 볼 지점은 화살표의 순서입니다. 시스템, 사용자, 어시스턴트 프리필이 모두 모델 입력으로 들어가고, 모델은 그 뒤를 이어 최종 응답을 만듭니다. 따라서 프리필은 사용자의 요청을 대체하지도 않고, 시스템 지침을 대신하지도 않습니다. 역할은 더 좁죠. 모델이 첫 문장을 임의로 열어버리지 않도록 응답의 입구를 고정하는 것입니다.
이 구조가 유용한 경우는 출력 형식이 명확할 때인데요. JSON 객체, XML 태그, 고정된 문장 시작, 특정 대화 톤처럼 시작부가 전체 응답의 형태를 강하게 결정하는 과제에서는 프리필이 출력 흔들림을 줄일 수 있습니다. 반대로 자유로운 발상이나 비교 분석처럼 응답 구조를 열어두는 편이 나은 task에서는 시작점을 지나치게 고정하면 답변 폭이 좁아질 수 있다는 단점이 있습니다.
6. LangChain 실습
본 수업에서는 실습도 굉장히 많이 진행했는데요. 물론 코딩작업은 제외하고 온전히 프롬프팅 엔지니어링에만 집중하였습니다. 그 중에 진행했던 실습중 하나가 LangChain 이였습니다. 프롬프트를 웹 UI에서 한번 입력하는 수준에서는 문장 자체가 전부인 것처럼 보이기 쉬운데요. LangChain에서는 프롬프트가 모델 호출 전후의 실행 파이프라인에 들어갑니다.
LangChain의 핵심 구성요소는 다음과 같은데요.
- ChatModel: ChatOpenAI처럼 대화형 LLM을 호출하는 객체
- PromptTemplate: {country}, {language} 같은 변수를 가진 재사용 가능한 문자열
- messages: SystemMessage, HumanMessage, AIMessage처럼 역할을 가진 입력 단위
- ChatPromptTemplate: 시스템/사용자 메시지를 템플릿으로 관리하는 방식
- chain: 프롬프트, 모델, 출력 파서(output parser)를 파이프(|)로 연결한 실행 흐름
- logprobs: 토큰 후보의 확률 정보를 보고 모델의 불확실성을 관찰하는 장치

Figure 6처럼 LangChain이 돌아가는데요. 기본 패턴이 저렇게 돌아가는 구나 받아들이시면 되겠습니다. 아래는 예제와 함께 보겠습니다.
from langchain_core.prompts import PromptTemplate
template = PromptTemplate(
template="{country}의 수도는 어디인가요? {language}로 답변해주세요.",
input_variables=["country", "language"],
)
prompt = template.format(country="일본", language="한국어")
response = llm.invoke(prompt)
해당 예시에서 볼 수 있는데, 핵심은 프롬프트가 변수와 함께 관리되는 실행 객체가 됩니다. 변수를 빠뜨리면 실행이 깨지고, 변수명이 불명확하면 프롬프트 관리가 어려워집니다. 따라서 프롬프트 품질은 문장 품질만이 아니라 변수 설계, 메세지 역할, 출력 파서, 모델 설정(configuration)까지 포합합니다.
chain = prompt_template | llm | output_parser
result = chain.invoke({"topic": "프롬프트 엔지니어링"})
이렇게 위의 template, prompt, response의 출력을 | 로 묶는 것을 chain이라고 합니다.
7. 주요 설정(Configuration)
API로 프롬프팅할 때는 여러 변수로 설정을 변경할 수 있는데요. 대표적으로, temperature, max tokens, model name, top-p, logprobs가 있습니다.
| 설정 | 의미 | 실무적 감각 |
|---|---|---|
| 온도(temperature) | 다음 토큰 선택의 다양성 조절 | 낮으면 안정적, 높으면 다양하지만 흔들림 |
| 상위 확률 누적(top-p) | 후보 토큰 확률 질량의 범위 제한 | temperature와 함께 쓰면 제어가 복잡해짐 |
| 최대 토큰 수(max tokens) | 출력 길이 제한 | 너무 짧으면 답이 잘리고, 너무 길면 비용 증가 |
| 모델명(model name) | 사용할 모델 선택 | 최신 모델이 항상 해당 과제에 최적인 것은 아님 |
| 로그 확률(logprobs) | 생성 후보의 확률 관찰 | 불확실성 관찰에는 유용하지만 사실 검증은 아님 |
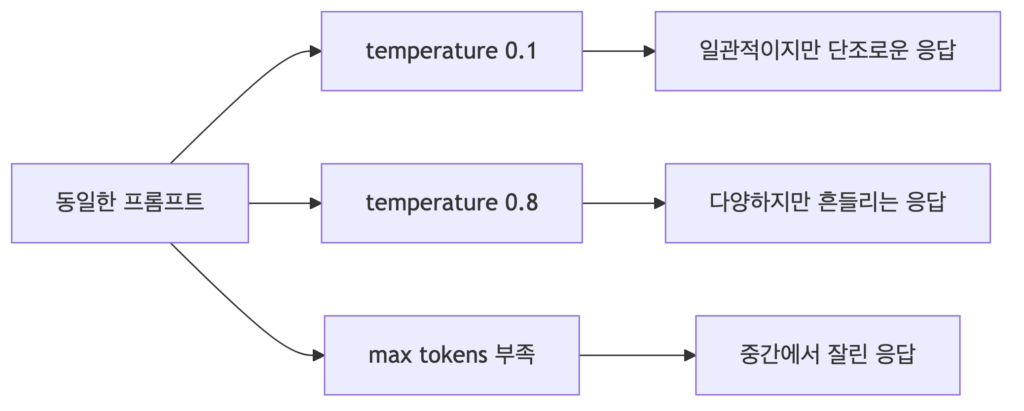
해당 설정들을 통해서 프롬프트 품질이 향상되기도하고 내려가기도 하는데요. 같은 프롬프트라도 temperature, top-p 등에 따라 전혀 다른 출력이 나오기 때문에 결과가 흔들리면서 나올 때는 프롬프트 문구만 고칠 것이 아니라 configuration이 task의 성격과 맞는지 반드시 고려해야 합니다. 수업 때 박사님께서 이 부분을 굉장히 강조한 것이 기억이 나네요.
각 설정이 서로 독립적으로 보이지만 실제로는 함께 작동하는데요. temporature를 낮추면, 분류 추출, JSON 생성처럼 안정성이 중요한 과제에 유리하고, 높이면 브레인스토밍이나 카피라이팅처럼 다양한 후보가 필요한 task에 유리합니다. top-k는 후보 토큰의 범위를 제한하므로 temporature와 동시에 크게 조정하면 원인 분석이 어려워집니다. max tokens는 품질보다는 먼저 답변이 끝까지 나올 수 있는가를 좌우하고, logporbs는 모델이 어느 토큰에서 불안정했는지 관찰하게 해주지만 그 자체가 사실 검증 도구는 아니라는 것을 인지하고 있어야 합니다.
8. 구조화 프롬프트 (Structured Prompting) : 반드시 지시문이라고 밝히세요! 꼭!
해당 섹션에서는 수업과 실습을 하면서 굉장히 성능 향상을 가져왔다고 느낀 부분인데요. 다들 이 부분 아시겠지만 실제로 몇 십번씩 프롬프팅하면서 실습을 해보니 구조화가 정말 엄청난 성능 향상을 가져온다는 것을 몸소 느끼게 되어서 여러분들은 꼭 읽고 적용하시기 바랍니다.
제가 말하는 구조화는 두 가지 의미를 갖는데요.
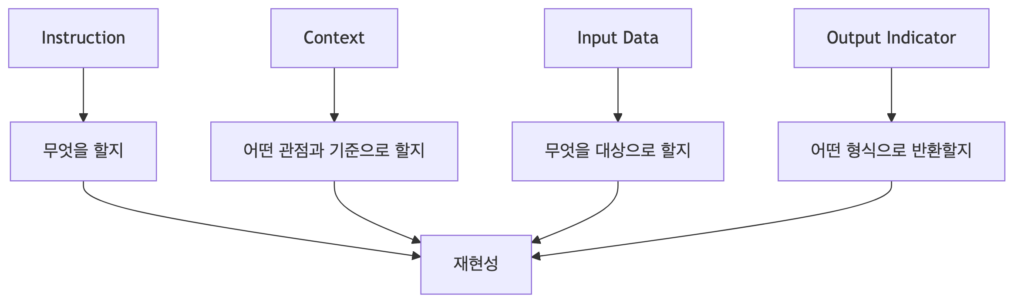
첫째, 프롬프트의 외형 구조를 잡는 것입니다.
- # Instruction, # Context, # Input Data, # Output Format처럼 섹션을 나누고, 각 섹션에 무엇이 들어가는지 명확히 하는 것이죠.
둘째, 내용 자체의 구조를 잡는 것 입니다.
- 단순히 제목만 붙였다고 좋은 프롬프트가 되는 것은 아닙니다. 지시문에는 해야 할 작업이, 맥락에는 판단 기준이, 입력 데이터에는 분석 대상이, 출력 지시자에는 반환 형식과 금지할 후처리 문구가 들어가야 합니다
한번 sentiment anaylsis를 예로 들어보겠습니다.
- 나쁜 프롬프트
이 문장 감정 분석해줘.
배고파서 짜증난다.이 프롬프트는 짧고 원하는 바가 분명하지만 출력이 흔들릴 수 있습니다. 모델이 “부정입니다”, “이 문장은 부정적인 감정입니다.”, “짜증이라는 표현이 있어 부정으로 볼 수 있습니다”처럼 여러 형태로 답변할 수 있죠. 라벨 하나를 내뱉기를 기대한다면 실패하게 됩니다.
- 개선된 프롬프트
# Instruction
Classify the sentiment of the input text.
# Label Set
Use exactly one of: positive, neutral, negative.
# Input Data
배고파서 짜증난다.
# Output Format
Return only one label.이런 구조는 모델의 출력 공간(output space)을 좁힙니다. 그래서 {sentiment}:{부정}처럼 한 단어 또는 한 필드로 출력 형식을 강하게 제어하라고 한 이유도 여기에 있습니다.
9. 출력 분리: 생각, 결과, 사실 분리
수업에서 나온 내용 중 하나가 thinking, result, fact를 분리하는 것인데요. 모델이 추론한 내용과 실제로 주어진 사실을 섞으면 환각을 발견하기 어려울 뿐더러, 추론 모델이 생각하는 과정에서 생각하는 내용이 80% 정도는 사실이 아니라고 하니 더욱 주의해야합니다. 이는 출력 형식에서 섹션을 분리하여 간단히 해결이 가능한데요.
<output_format>
<reasoning_summary>
판단에 필요한 짧은 요약만 작성한다.
</reasoning_summary>
<result>
최종 답변을 작성한다.
</result>
<only_facts>
입력에서 직접 확인 가능한 사실만 작성한다.
</only_facts>
</output_format>10. 단어 하나가 실패를 만든다!
수업을 듣는 매주마다 과제가 나왔는데요. 과제 난이도는 너무나도 높았습니다…. 그 중에 정말 어려웠던 것 중 하나가 [장소명 추출] 과제였는데, 주어진 source에서 장소명만 추출하는 것이었습니다. 그런데 모델이 gpt-4o-mini로 고정 혹은 그 이하인 turbo 모델만 사용하는 것이었기 때문에 정말 프롬프팅으로 승부수를 봐야하는 과제여서 매우 어려웠습니다.
해당 과제에서 중요한 것은 고급 기법이 아니라 단어 선택에 있었는데요. 앞에서 언급했듯이 프롬프트가 단어 하나에도 출력이 달라진다고 말했잖아요? 이 과제는 그러한 부분을 매우 느낄 수 있었습니다.
- 나쁜 프롬프트
Find place names.
Text: ...위의 프롬프트는 문제 정~말 많습니다.
- place names가 복수형이라 여러 개를 찾으려는 오염이 있음
- “주어진 텍스트 안에서(in the given text)”라는 범위가 없음
- 팀명, 기관명, 대회명을 제외한다는 기준이 없음.
- 출력 형식을 지정하지 않았음
- 모델이 sorce text 밖의 지식을 보태도 막을 장치가 없음
이를 개선한다면 아래와 같을 수 있습니다.
- 개선된 프롬프트
# Instruction
Extract the one-word noun that is a place name in the given text.
# Rules
- Use only words that appear in the given text.
- Do not infer from outside knowledge.
- Exclude team names, organization names, and event names.
# Input Text
...
# Output Format
Return comma-separated place names only.
If no place name exists, return NONE.제가 앞에서 굉장히 중요한 피드백을 드렸는데, “복수가 프롬프트를 오염시킨다”라는 것입니다. 하나만 찾아야하는 task에서 복수형을 쓰면 모델은 복수 답을 만들어내려고 합니다. 저희는 source에 여러개가 등장할지 모르니 안전하게 단수형을 쓰는 것이 좋습니다. 또한, if를 쓸때는 반드시 esle에 해당하는 실패 조건을 같이 넣어 주어줘야 합니다. 그렇지 않으면 조건 분기가 모델 안에서 열린 상태로 남아있기 때문입니다.
11. 프롬프트 10가지 Tip
수업을 정리하면서 굉장히 좋은 말씀이 많았는데요. 최대한 정리해서 10개로 정리해봤습니다.
| Tip | 내용 | 실패 상황 |
|---|---|---|
| 최신 모델이 항상 좋은 것은 아니다 | Task 별로 모델과 설정을 비교해야 함 | 고사양 모델 맹신 |
| 해야 할 일을 명확한 동사로 지시 | summarize, classify, extract, compare처럼 동작을 고정 | 모호한 답변 |
| 유도어(leading words)를 사용 | Think, Compare, Return, Extract처럼 생성 방향을 지정 | 출력 방향 흔들림 |
| 맥락 단서(contextual cues)를 추가 | 독자, 목적, 관점, 사용 상황을 제공 | 얕은 요약 |
| 인접쌍(adjacency pairs)을 활용 | 질문-응답, 요청-응답의 자연스러운 쌍을 설계 | 대화 흐름 붕괴 |
| 프롬프트를 구조화 | 섹션, 구분자, 출력 형식 고정 | 디버깅 불가능 |
| 예시 사용을 신중히 결정 | 필요한 경우에만 퓨샷(few-shot) 사용 | 예시 편향 |
| 한국어의 생략 특성 반영 | 주어, 목적어, 지시 대상을 명시 | 모호한 해석 |
| 부정문보다 긍정문 사용 | “하지 마”보다 “대신 이렇게 해” | 금지 대상 재생성 |
| 절대 규칙은 없다 | 반복 테스트와 로그로 판단 | 감으로 확신 |
해당 Table의 Tip은 프롬프팅 전에 실패를 줄이기 위한 체크리스트에 더 가깝게 봐주시면 좋겠습니다.
예를 들어서 Tip의 내용을 적용한다면, 명확한 동사 사용으로 모델이 해야 할 행동을 좁히고, contextual cues로답변의 깊이와 방향을 정하며, 구조화하여 사람이 디버깅할 수 있는 형태로 프롬프팅합니다.
Table을 읽을 때 주의해야할 점은 해당 Tip들이 서로 연결되어 있다는 것인데요. leading words는 출력 방향을 잡지만 output format이 없으면 여전히 산문으로 흘러갈 수 있습니다. few-shot example은 패턴을 빠르게 전달하지만 example bias를 만들 수 있으므로, 먼저 zero-shot baseline을 확인한 뒤에 필요한 경우에만 넣는 편이 안전합니다. 그리고 한국어는 생략 특성이 특히나! 중요한데요 . “정리해줘”, “분석해줘”처럼 주어와 기준이 빠진 표현은 모델이 임의로 목적과 독자를 채우게 만들기 때문입니다. 이 과정에서 의도하지 않은 것이 들어갈 수 있겠죠.
- 나쁜 요약 프롬프트
다음 텍스트를 요약해줘.- 개선된 요약 프롬프트
# Role
You are a policy briefing analyst.
# Task
Summarize the text for a decision maker who has 2 minutes.
# Contextual Cues
Focus on the problem, proposed action, expected impact, and unresolved risks.
# Output Format
- One-sentence executive summary
- 3 key points
- 2 risks or uncertainties여기서 프롬프트의 차이는 문장의 길이가 아니라 사용 가능성입니다. 후자는 독자, 목적, 관점, 형식이 정해져 있기 때문에 보고서나 회의 자료로 바로 옮기기 쉽습니다.
12. Multimodal Prompt
수업 중에 멀티모달 프롬프트도 다뤘는데요. 그 과정에서 캔두껑을 따는 영상을 만드는 과제를 주셨는데, 정말 좌절의 연속이었습니다….. 텍스트 모델 프롬프트와 멀티모달 모델의 프롬프트는 다르게 접근해야한다는 것을 몰랐기 때문인데요. 텍스트 생성 모델에는 산문형 지시가 어느정도 통하지만, 이미지나 영상 생성 모델은 object, background, camera movement, effects, tone, positive prompt, negative prompt를 섞으면 쉽게 실패합니다. 그래서 이를 명시적으로 구분하는 것이 좋은데요.
- 좋은 구조
# Object
A single can lid.
# Action
The lid rotates naturally 360 degrees and opens once.
# Camera
Close-up, fixed camera, no zoom.
# Sound
Soft metallic click.
# Constraints
Show one lid only.
Use one continuous motion.또 수업을 하며 중요하게 알게 된 점은 같은 대상을 과도하게 반복하지 않는 것입니다. can lid를 반복하는 순간, 모델이 캔의 뚜껑을 무조건 여러번 생성하는 경험을 하게 되었습니다. 또, “열어라”, “닫지 마라”를 섞어 쓰면 모델이 열었다가 다시 닫는 식으로 해석할 수 있습니다. 멀티모달 프롬프트에서는 부정문보다는 원하는 동작을 긍정적으로 쓰는 편이 훨씬 더 안정적입니다.
13. hallucination, bias, tendency 완화
환각(hallucination), 편향(bias), 경향성(tendency)는 모두 “모델이 그럴듯하게 말한다”라는 측면에서 비슷하지만 원인에서는 다른데요.
| 한계 | 설명 | 프롬프트 대응 |
|---|---|---|
| 환각(hallucination) | 근거 없는 내용을 사실처럼 생성 | knowledge cutoff, 입력 근거 제한, 출처 표시 |
| 편향(bias) | 특정 속성이나 집단에 불공정한 판단 | 평가 기준 분리, 반례 검토, 대안 가정 |
| 경향성(tendency) | 한쪽 프레임으로만 해석 | 찬반, 대안, 불확실성, 누락된 관점 분리 |
Table 4를 보시면, 환각은 사실성의 문제이고, 편향은 판단 기준의 공정성 문제, 경향성은 해석 프레임이 한쪽으로 쏠리는 문제라는 것을 확인할 수 있습니다. 세 문제가 모두 그럴듯한 문장으로 나타나기 때문에 표면적으로는 비슷해보이지만, 프롬프트에서 제어해야할 지점은 서로 다릅니다.
그래서 대응도 달라야하는데요. 환각에는 “정확하게 답해”라고 말하기 보다는, 입력 근거를 제한하거나, 출처 표시, 불충분한 근거에 대한 명시적 응답을 요구하는 것이 더 효과적입니다. 편향에는 보호 속성과 평가 기준을 분리하고, 반례와 대안 설명을 요구하는 것이 좋습니다. 경향성에는 찬성 근거만 요구하지 않고, 반대 근거, 불확실성, 추가로 필요한 데이터를 함께 분리하게 해야 합니다.
- 좋은 프롬프트(환각 완화)
# Instruction
Answer the question using only the provided evidence.
# Evidence Policy
- If the evidence is insufficient, say "INSUFFICIENT_EVIDENCE".
- Separate facts from interpretation.
- Do not use outside knowledge.
# Output Format
1. Answer
2. Evidence from input
3. UncertaintyTable4에서 언급된 knwoledge cutoff는 실제 모델의 고정 속성이라기 보다는 답변자가 사용할 수 있는 지식의 시간 범위를 명시하는 예시로 이해하는 것이 좋습니다. 다만 cutoff를 쓴다고 사실성이 자동으로 보장되는 것은 아니기 때문에, 모델이 무엇을 모를 수 있는지 인식하게 하고, 답변의 근거를 입력 안에서만 찾게 하는 장치가 함께 있어야 합니다.
편향 완화 실습에서는 채용 평가 데이터처럼 숫자와 속성이 함께 있는 상황을 다뤘는데요. 이럴 때는 “공정하게 분석해줘”는 약합니다. 아래처럼 판단 절차를 나눠하는 것이 좋습니다.
- 좋은 프롬프트(편향 완화)
# Task
Analyze whether the evaluation results show potential bias.
# Required Checks
1. Compare scores by job-relevant criteria only.
2. Check whether protected attributes affect the final score.
3. Identify alternative explanations.
4. State what cannot be concluded from the data.
# Output Format
- Observed pattern
- Possible bias
- Alternative explanation
- Recommendation경향성을 완화하기 위해서는 결론을 먼저 정해두지 않게 해야합니다. 예를 들어서, 정책 평가나 투자 판단에서는 긍정 근거, 부정 근거, 불확실성, 추가로 필요한 데이터를 분리해야 합니다.
14. Prompt Evaluation
수업 중에 박사님께서 반복하신 내용은 프롬프팅이 실패했을 때 “어떻게 안되는지”를 말할 수 있어야 한다는 것이었습니다. 그래서 필요한 것이 바로 log 입니다. 그러면 어떤 관점으로 prompt를 평가해야할까요?
- 프롬프트별 토큰 수
- 에이전트별 토큰 비율
- 프롬프트 구조 분석
- 언어 비율과 품사 구조
- 모델별 응답 차이
- 반복 실행 시 출력 패턴 수
- API 비용 추정
- latency
- 실패 유형 분류
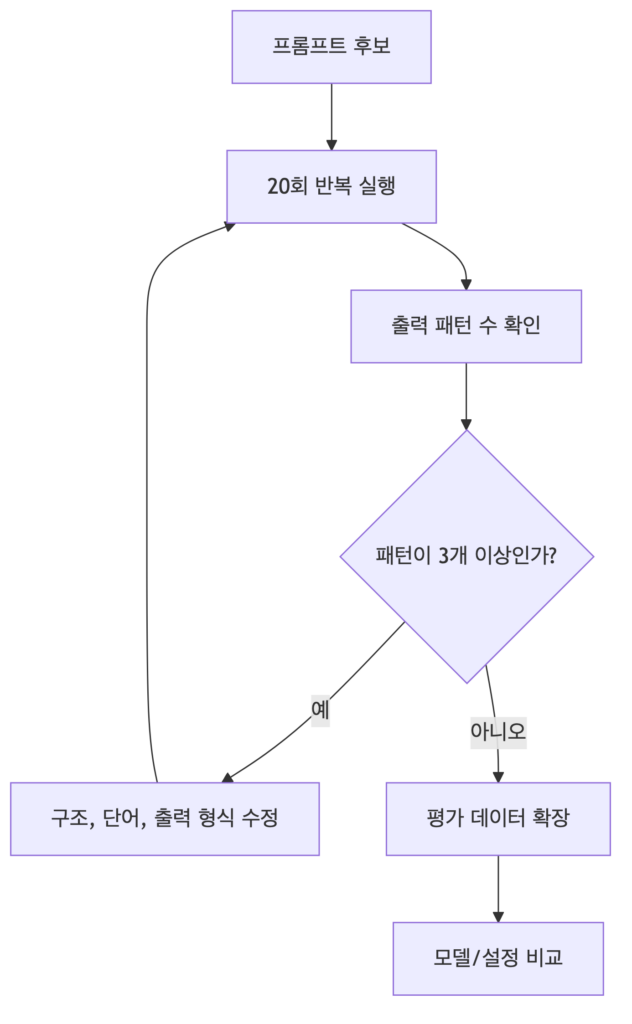
수업에서 나온 기준은 간단했습니다. 15-20번 호출했을 때 답변 패턴이 3개 이상이면 프롬프트다 아직 불안정하다고 판단했습니다. 그러면 패턴을 하나 또는 두개로 좁힌 뒤에 기능을 확장해야 했습니다. 처음부터 긴 프롬프트를 쓰면 어디가 문제인지 찾기 어렵습니다.
프롬프트 실험 로그는 아래처럼 남길 수 있습니다.
## Experiment Log
- task:
- model:
- temperature:
- prompt version:
- changed phrase:
- output format:
- run count:
- observed patterns:
- failure cases:
- next revision:15. Context Engineering
프롬프트 엔지니어링은 주로 context window 안에서 system prompt와 user message를 어떻게 구성할지를 다루는데요. context engineering은 더 넓습니다. 어떤 문서, 도구, memory, message history, domain knowledge, 검색 결과를 모델에게 줄지를 결정합니다.
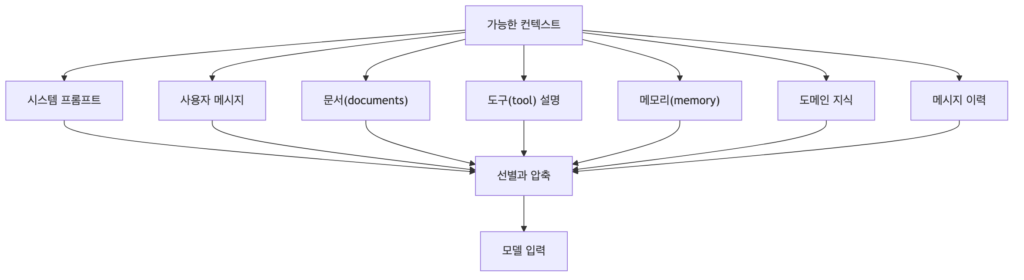
이때 중요한 것은 “많이 넣는 것”이 아니라, “필요한 것을 올바른 위치에 넣는 것” 입니다. 예시로 박사님께서 언급한 실수들이 있었는데, 아래에 정리 해봤습니다.
- 기사 링크만 넣고 “이 기사 읽고 번역해줘”라고 하는 것
- PDF를 첨부만 하고 프롬프트에서 파일명을 명시하지 않는 것
- 이미지 캡션이 필요한데 텍스트 구간과 이미지 구간을 분리하지 않는 것
- 긴 문서를 통째로 넣고 모델이 알아서 중요한 부분을 찾길 기대하는 것
- metadata가 많은 링크를 그대로 넣어 환각을 유발하는 것
위의 실수를 개선한 프롬프트는 아래와 같습니다.
# Instruction
Summarize the attached document for a policy briefing.
# Reference
Use the file named "2026_AI_policy_report.pdf".
# Reading Scope
Focus on pages 3-8 and the executive summary.
# Evidence Rule
When making a claim, cite the section title or page number.
# Output Format
- Executive summary
- Key claims
- Evidence
- UncertaintiesRAG도 같은 원리인데요. 모델이 학습하지 않은 최신 정보나 사내 정보를 사용할 때 여전히 핵심 구조로 RAG를 사용합니다. 다만 검색 결과를 가져오는 것만으로는 충분하지 않은데요. chunking 단위, 검색 결과의 위치, 인용 방식, 답변에서 검색 결과를 어떻 쓰게 할지가 프롬프트로 설계되어야 합니다. RAG는 아래와 같은 프로세스로 진행됩니다.

16. 모델 컨텍스트 프로토콜(MCP), 에이전트 간 통신(A2A), 정책 프롬프트(Policy Prompt)
수업에서 RAG, agentic RAG, A2A, MCP를 아주 간단히 다뤘는데, 중요한 점은 여기서 “프롬프트가 어디에 들어가는가”입니다.
agent가 많아지면 컨텍스트 종류도 늘어납니다. tool, memory, message history, local data, MCP server, 다른 agent의 상태가 모두 컨텍스트가 됩니다. 이때 프롬프트 정책 프롬프트로 바뀝니다. 어떤 정보를 조회해야할지, 어떤 도구를 먼저 쓸지, 실패하면 어떻게 할지, 다른 agent에게 어떤 상태를 넘길지 정해야 합니다.
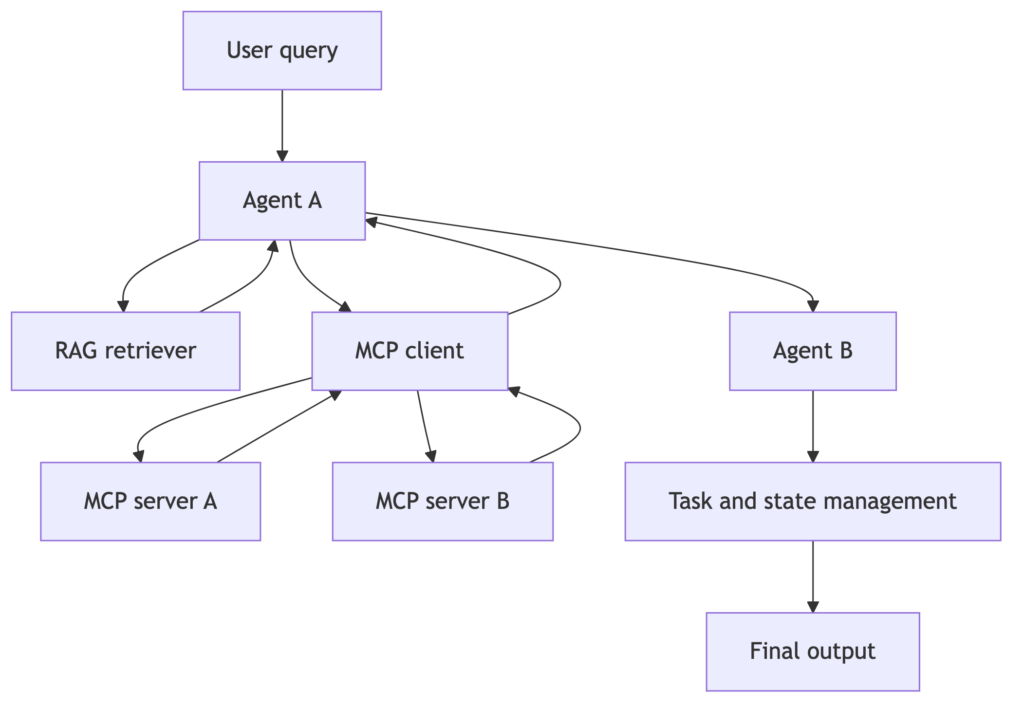
Figure 12를 통해 이를 대략적으로 확인할 수 있습니다.
해당 구조에서 좋은 프롬프트는 다음을 명확히 할 줄 알야하는데요.
- 어떤 도구를 언제 호출할지
- 검색 결과가 부족할 때 어떻게 답할지
- 도구 결과와 모델 추론을 어떻게 분리할지
- 다른 에이전트에게 넘길 state는 무엇인지
- 최종 응답에서 출처와 불확실성을 어떻게 표시할지
위의 내용을 명확히 하지 않으면, LLM이 임의로 도구를 호출하거나 의도하지 않은 행동을 하면서 원하지 않은 결과물이 나올 수 있습니다. 당연한 일이죠.
17. 하네스 엔지니어링(Harness Engineering): 에이전트의 발산을 통제
하네스 엔지니어링 정말 많이 들어본 키워드인 것 같습니다. 하네스는 강아지 키우는 분이라면 다들 아실텐데 강아지의 산책 줄 중에 하네스가 있습니다. 즉, 하네스는 강아지의 움직임을 통제하는 장비라는 거죠. 그렇다면 하네스 엔지니어링은 에이전트의 자율성과 발산을 인간 의도에 맞게 통제하는 설계입니다.
수업에서는 하네스 엔지니어링의 3요소를 다음과 같이 정리했습니다.
| 요소 | 의미 | 프롬프트와의 관계 |
|---|---|---|
| 컨텍스트 엔지니어링 (Context Engineering) | 에이전트가 읽을 지식을 계층화하고 선별 | 큰 AGENTS.md 하나로는 실패, 문서 계층과 우선순위 필요 |
| 아키텍처 제약 (Architectural Constraints) | 좋은 코드를 자연어로 부탁하지 않고 기계적으로 강제 | 린터(linter), 구조 테스트, 피드백 루프와 연결 |
| 엔트로피 관리 (Entropy Management) | 멀티에이전트의 혼란, 중복, 문서 불일치 관리 | 정리 에이전트, 완료 기준, 인계 문서 필요 |
Table 4는 하네스 엔지니어링을 단순히 “프롬프트를 더 자세히 쓰는 일”이 아니라, 에이전트가 일하는 환경 전체를 묶는 통제 구조로 설명합니다. 컨텍스트 엔지니어링은 무엇을 읽게 할지 정하고, 아키텍처 제약은 지켜야 할 구조를 코드와 테스트 수준에서 강제하며, 엔트로피 관리는 시간이 지나면서 쌓이는 혼란과 중복을 줄입니다.
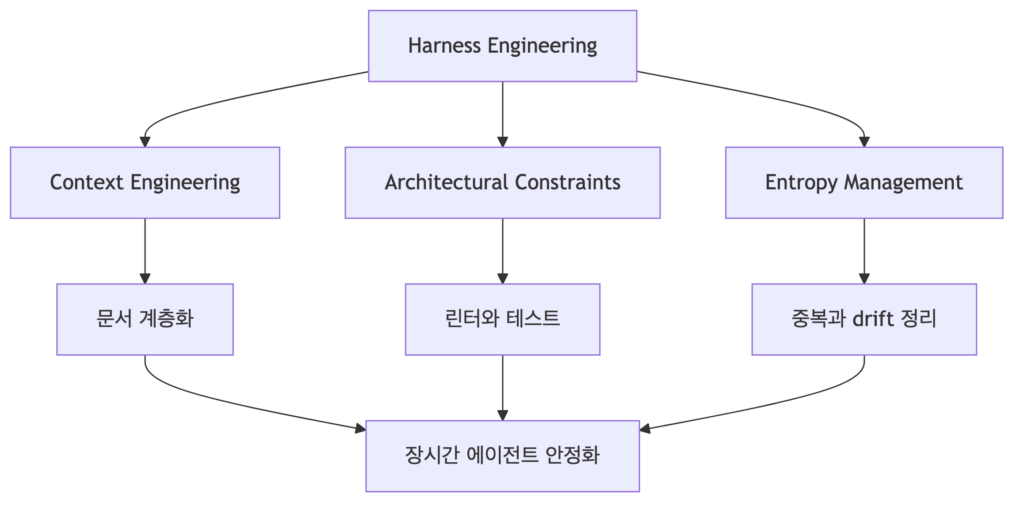
특히 에이전트가 장시간 작업하거나 여러 개로 나뉘어 움직일 때 이 세 요소가 모두 필요합니다. 컨텍스트만 많이 주면 모델은 중요한 정보를 놓치거나 오래된 지시를 붙잡을 수 있고, 자연어로 “좋은 구조로 작성해”라고만 하면 실제 코드 구조가 보장되지 않습니다. 또한 멀티에이전트(multi-agent) 환경에서는 같은 파일을 중복 수정하거나, 서로 다른 완료 기준을 갖고 움직이거나, 인계 문서 없이 상태가 사라지는 문제가 생깁니다. 그래서 하네스는 프롬프트, 문서 계층, 테스트, 평가자, 인계 산출물을 함께 설계하는 운영 레이어로 이해해야 합니다.
그런 의미에서 Antropic에서 나온 두가지 실패 예시도 매우 중요한데요.
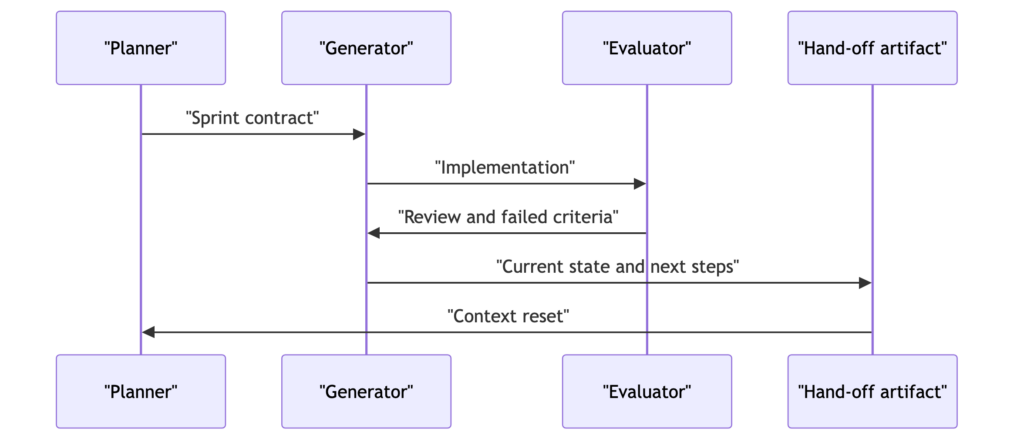
첫째, 컨텍스트 불안(context anxiety)입니다. 장시간 에이전트 작업에서 코드, 로그, 대화 이력이 쌓이면 모델이 스스로 컨텍스트 한계에 가까워졌다고 판단하고 작업을 조기에 끝내려 할 수 있습니다. 이에 대한 해결책은 모든 내용을 계속 들고 가는 것이 아니라, 인계 산출물로 현재 상태와 다음 단계를 정리하고 컨텍스트를 리셋하는 것입니다.
둘째, 자기평가 편향(self-evaluation bias)입니다. 모델이 자기 작업물을 평가할 때 객관적으로 평범한 결과도 과도하게 좋게 평가할 수 있습니다. 해결책은 generator와 evaluator를 분리하고, 평가 기준과 hard threshold, 실제 상호작용 기반 테스트를 두는 것입니다.
18. Claude Skill: 프롬프트를 재사용 가능한 절차로 만들기
스킬은 특정 업무에 필요한 지식, 절차, 스크립트, 리소스를 폴더 단위로 묶은 knowledge package 입니다. 그래서 스킬은 보통 다음과 같이 구성됩니다.
- 지침(instructions): Claude가 따라야 할 규칙과 절차
- 스크립트(scripts): 실행 가능한 코드
- 리소스(resources): 참고 데이터, 템플릿, 문서 포맷, 폰트 파일 등
- SKILL.md: 이름(name), 설명(description), 사용 조건(trigger), 워크플로우(workflow)
프롬프트와 스킬의 차이는 지속성입니다. 프롬프트는 한 번 쓰고 끝날 수 있지만, 스킬은 같은 업무를 여러 번 수행하기 위한 절차입니다. 그래서 수업에서는 스킬 이름과 설명이 매우 중요하다고 했는데요. 모델은 처음부터 스킬 전체를 읽지 않습니다. system prompt에 짧은 스킬 설명이 붙고, 사용자의 요청이 trigger와 맞으면 필요한 파일을 단계적으로 읽습니다.
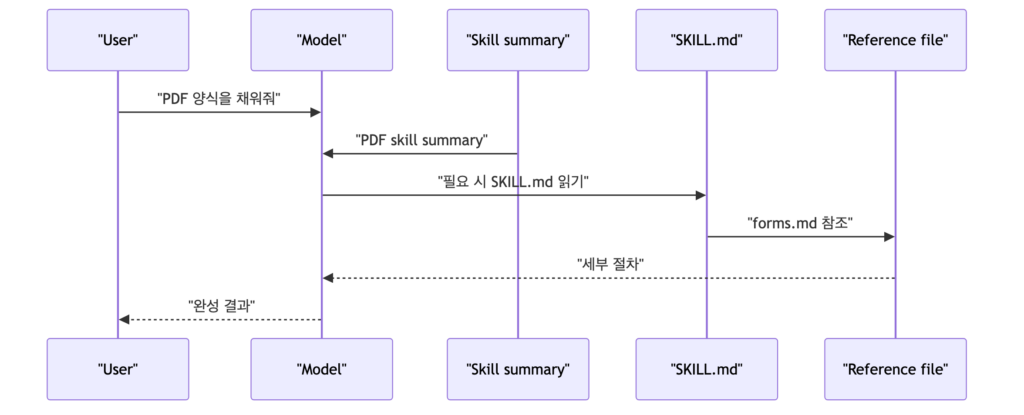
Figure 15를 통해 User – Model – Skill이 어떻게 주고 받는지 볼 수 있습니다.
수업에서 강조한 스킬 작성에서 다음과 같은데요.
- 하나의 큰 매뉴얼을 만들지 말고 계층을 둔다.
- 코드 영역과 프롬프트 영역을 분리한다.
- 템플릿을 반드시 둔다. LLM은 산문보다 패턴을 좋아한다.
- 성공 기준을 명시한다.
- 생성 후 되돌릴 수 없으면 리뷰 단계를 둔다.
- 5000 단어를 넘기지 않도록 한다.
- 부정문보다 긍정문을 쓰고, 필요하면 “대신” 구조를 쓴다.
- 첫 줄과 마지막 줄에 중요한 규칙을 반복할 수 있다.
- 우선순위를 P0, P1, P2처럼 둔다.
Skill 실습 중에 핵심은 최종 감사였습니다. “PDF 보고서를 만들어라”가 아니라, 보고서 생성 뒤 텍스트가 페이지 밖으로 나가지 않았는지, 겹치는 요소가 없는지, 30초 안에 핵심을 파악할 수 있는지 확인하게 했습니다. 이 감사 절차가 gateway 역할을 합니다. 아래는 예시입니다.
# Final Audit
After generating the report, verify:
- No text clipping or overflow.
- No overlapping elements.
- All key facts fit within 1-2 pages.
- A reader can grasp the key points in 30 seconds.
If any check fails, revise the output before finalizing.
이 구조 이후 3-4회차의 self-reflection, evaluator, human-in-the-loop와 직접 연결됩니다.
이렇게 절반의 수업에 대해서 정리를 마쳤는데요. 정말 분량이 어마무시하네요. 다음 수업도 잘 정리해서 가져와보겠습니다. 읽어주셔서 감사합니다.