안녕하세요. 이번에 리뷰로 가져온 논문은 DrivoR: Driving on Registers라는 논문입니다. 기존에는 Mobile robot navigation 관련 논문만 리뷰하고 다뤘었는데 이번에는 한번 차량 AD(자율주행) 관련 논문을 리뷰하고자 가져왔습니다. 생각보다 차량 주행분야는 mobile robot navigation보다 open-loop, closed-loop 평가 체계와 벤치마크가 더 잘 정리되어 있고 다양한 방법론들이 동일한 benchmark 위에서 SOTA 경쟁을 벌이고 있다라는 느낌을 받았습니다. 물론 mobile robot navigation도 중요한 연구들이 많지만 자율주행은 차량이라는 비교적 비슷한 플랫폼이나 그리고 outdoor만의 도로 주행이라는 비교적 비슷한 환경을 다루기 때문에 대규모 데이터셋 구축이나 공통 평가 프로토콜을 만드는게 더 수월했던 것 같습니다. 그래서 KITTI, nuScenes, Waymo, nuPlan 같은 데이터셋이 대표적이고 이런 부분 때문에 좀더 AD분야가 mobilr robot navigation 분야 보다는 체계적인 느낌을 받았습니다. 다시 돌아와서 해당 논문은 DrivoR라는 간단하고 효율적인 transformer 기반 end-to-end 자율주행 아키텍처를 제안합니다. 핵심은 pretrained ViT 위에 camera-aware register token을 추가해서 멀티카메라로(다중 시점)부터 나온 많은 이미지 토큰을 소수의 장면 표현으로 압축하는 것이고 이렇게 압축된 scene token을 기반으로 하나의 decoder는 trajectory 후보를 생성하고 다른 decoder는 그 후보들을 safety, comfort, efficiency 같은 해석 가능한 sub-score로 평가했다고 합니다. 결과적으로 DrivoR는 단순한 구조인데도 NAVSIM-v1, NAVSIM-v2, HUGSIM에서 강한 baseline을 능가하거나 비슷한 성능을 보였고 동시에 계산량도 크게 줄이는 결과를 보였다고 합니다.
Introduction
최근 end-to-end driving은 trajectory proposal 기반 접근이 좋은 성능을 보이는데 이 방식은 많은 trajectory 후보를 만들고 각각을 평가해야합니다. 근데 어떤 traj가 좋은 traj를 평가하기 위해서는 front 씬, 왼쪽 오른쪽 씬, 뒷쪽 씬을 참고해서 평가를 해야하는데 대형 백본 인코더 같은 경우는 프레임마다 수천 개의 토큰을 내놓기 때문에 이걸 수십~수백 개 trajectory에 대해 다시 활용하려면 계산량이 급격히 커지는 문제가 발생합니다. 특히 카메라 수나 입력 해상도가 늘어날수록 이 병목은 더 심해집니다. 물론 이런 병목을 줄이기 위해서 보통 feature map을 평균 풀링해버리는데(기존의 단순한 spatial pooling) 이런 방식 같은 경우에는 모든 카메라 정보를 똑같이 평균 처리해서 어떤 토큰이 planning에 중요한지 구분하지 못하는 문제가 생깁니다. 장면을 그냥 평균내서 줄여버리기 때문에 planning critical context를 잘 보존하지 못할 수 있다라는게 저자의 핵심 주장으로 보시면 좋을 것 같습니다.
그레서 저자들은 이런 병목과 spatial pooling의 한계를 해결하기 위해서 DrivoR라는 ViT 기반 E2E planning 아키텍처를 제안합니다. 이 방법은 기존의 uniform pooling을 각 카메라마다 고정된 수의 register token으로 대체하고 이 token들은 장면을 압축적으로 표현하는 scene descriptor 역할을 한다고 보시면 좋을 것 같습니다. (register DINO의 register token과는 약간 역할이 다른 토큰) 이러한 token들은 planning에 필요한 문맥 정보는 유지하면서도 해당 토큰들로만 처리하기 때문에 visual representation의 길이는 크게 줄여주게 됩니다.
또 추가적인 문제 의식은 trajectory proposal 계열에서 사실상 성능의 핵심은 좋은 trajectory를 얼마나 잘 고르는지 에 대한 traj scoring가 중요하다 라는 점입니다. 그래서 저자들은 후보를 여러 개 만드는 것만으로는 부족하고 최종 traj 선택을 잘해야 하기 때문에 traj generation과 scoring을 구분해서 설계할 필요가 있다라고 주장합니다. 그래서 앞서 register 토큰의 이렇게 압축된 표현을 바탕으로 DrivoR는 서로 분리된 두 개의 모듈을 사용해 trajectory proposal을 생성하고 scoring을 하고 그리고 나서 최종 trajectory는 앞서 예측된 sub-score를 이용해 선택하게 됩니다. 자세한 내용은 method 파트에서 다루도록 하겠습니다.
Method
일단 전체 구조는 아래와 같습니다.
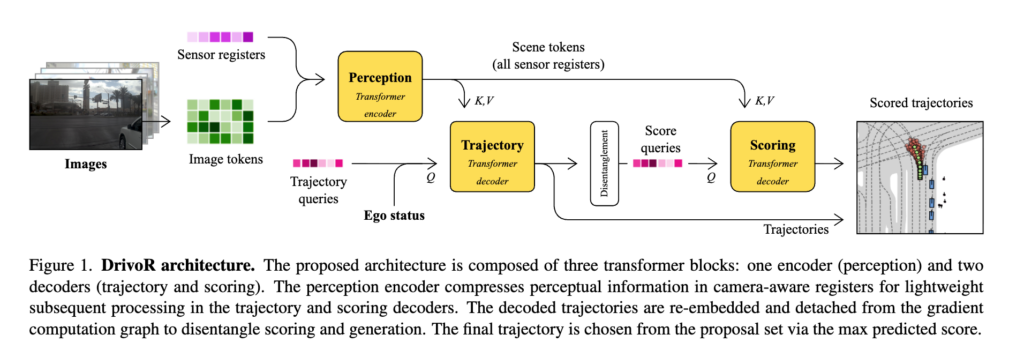
크게 보면 perception encoder, trajectory decoder, scoring decoder 세 부분으로 이루어진 transformer 기반 구조라고 보시면 좋을 것 같습니다. perception 쪽에서 장면을 압축하고(register 토큰) trajectory decoder가 후보를 만들고 scoring decoder가 그 후보를 평가해서 최종 trajectory를 선택하는 구조입니다.
Perception Encoder
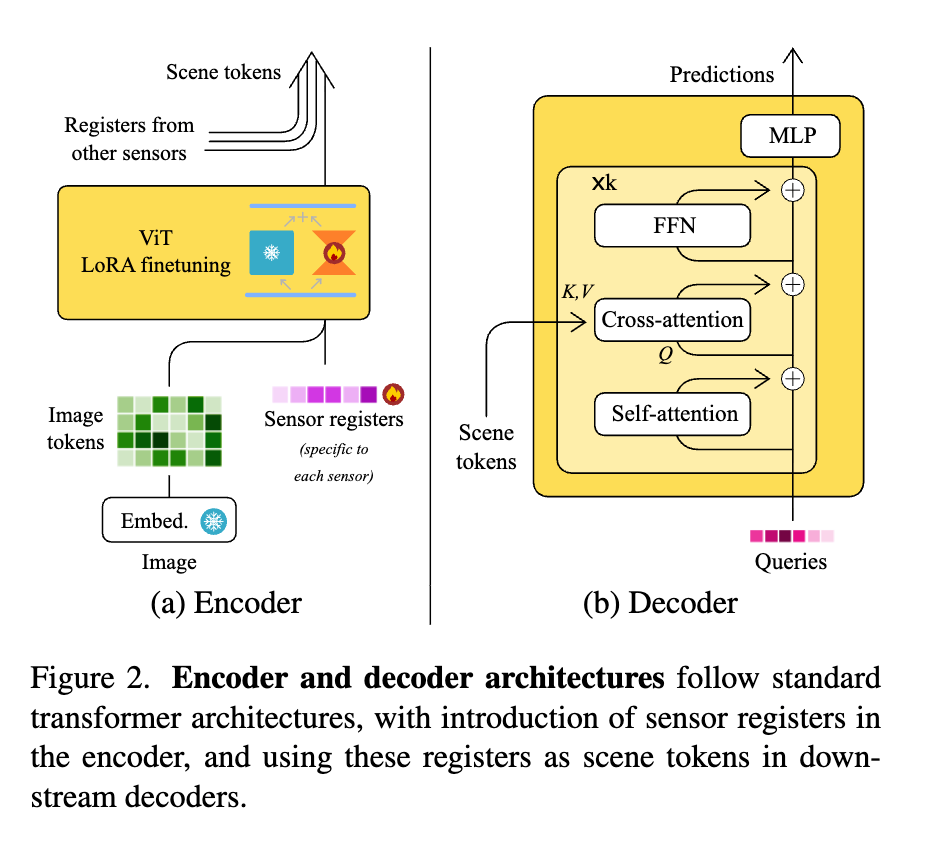
여기서 핵심은 camera-aware register token입니다. 각 카메라 이미지를 pretrained ViT에 통과시키되 일반 patch token들만 쓰는 게 아니라 카메라별 register token(길이 16)을 추가합니다 그리고 최종 layer에서 이 register token들만 뽑아내서 scene representation으로 쓰는 방식입니다. 여기서 이 register token은 각 프레임끼리 공유되는 토큰이 아니라 각 센서마다 전용 register 토큰이 있다고 보시면 좋을 것 같습니다.(front camera용 register, front-left용 register, back camera용 register를 각각 따로 둠) 그래서 register token classification token, 그리고 patch token과 함께 이어 붙이고 ViT에 들어가게 됩니다. 그리고 ViT의 마지막 layer에서camera token(register token)만을 추출합니다. 그리고 N개의 카메라 각각에서 얻은 최종 camera token들을 모아서 총 NxR 개의 scene token을 구성하게 됩니다. (R은 register 토큰 길이)
자율주행에서는 카메라별 역할이 다르기 때문에 이렇게 따러 토큰을 설계한 것 닽습니다. 예를 들어 앞 카메라는 진행 방향 정보와 장애물 정보를 담고 있고 옆 카메라는 차선 변경이나 회전 상황에서 중요하고 뒤 카메라는 상대적으로 덜 자주 보지만 특정 상황에서는 중요할 수 있기 때문에 이런 설계를 한 것 같습니다. pooling은 이런 차이를 반영하지 못한다는 문제를 이런 설계로 보완한 것 같습니다.
근데 여기서 register token을 새로 넣었다고 해도 원래 pretrained DINO backbone은 driving용으로 학습된 게 아니고 camera register를 입력으로 받는 구조에 완전히 맞춰져 있지도 않습니다. 그래서 backbone이 이 새로운 입력 구성에 맞게 파인튜닝해야 합니다. 어차피 모델 내에서 self attention 과정에서 register와 다른 csl,patch 토큰간 attention 연산이 이뤄지기 때문에 따로 추가적인 모듈은 설계하지 않고 기존 pretrained ViT 구조를 유지하되 backbone 전체를 무겁게 풀 파인튜닝하는 대신 저자들은 LoRA 파인튜닝을 진행합니다. (아래 (a)가 파인튜닝 구조 입니다.)
Trajectory Decoder
그 다음 단계는 trajectory decoder입니다. 구조는 fig 2 (b)에서 보이는 transformer decoder구조 입니다. 여기서는 learnable trajectory query(Q_{\text{traj}})라는 친구를 입력으로 넣고(이 쿼리들은 처음에 랜덤 초기화), self-attention과 scene token에 대한 cross-attention을 통해 여러 개의 trajectory candidate를 생성합니다. 좀더 자세히는 decoder 입력 전에 ego status라는 친구가 있는데 ego status 입력은 pose, velocity, acceleration, 그리고 driving command로 구성되어있습니다. 이것들을 인코딩한 뒤 decoder에 들어가기 전에 trajectory query에 더해준 것이 디토더 입력으로 들어간다고 보시면 좋을 것 같습니다. 이 transformer를 지난 최종 trajectory token은 MLP를 통해 실제 trajectory sequence ((x,y,θ)의 시퀀스)로 디코딩 됩니다. (각각의 디코딩된 candidate trajectory \tau_i는 현재 시점 t 이후부터 미래 시점 t+T 까지의 n_p개 pose로 이루어진 시퀀스이고 여기서 T는 전체 예측 시간 구간을 의미) AD에서도 마찬가지로 모든 값은 시점 t에서의 ego vehicle local coordinate frame을 기준으로 표현된다고 하고 연속된 pose들 사이의 시간 간격은 균일하다고 가정합니다.
Trajectory loss
학습은 WTA(Winner-Takes-All), 혹은 minimum-over-n 방식으로 loss를 설계했다고 합니다. 여러 trajectory 후보 중에서 GT와 가장 가까운 것 하나만 supervise하는 방식인데 이건 multi-modal future prediction에서 자주 쓰이는 설계 방식이라고 합니다. 한 장면에 그럴듯한 future가 여러 개 있을 수 있기 때문에 모든 후보를 하나의 GT에 맞추려 하지 않고 가장 잘 맞는 후보만 밀어주는 방식이라고 합니다.
Loss는 아래와 같이 정의 됩니다.
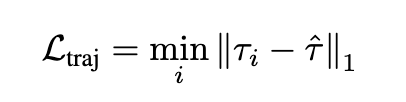
여기서 \hat{\tau}는 GT trajectory이고 \tau_i 는 모델이 예측한 candidate trajectory입니다.
추가로 저자들은 더 먼 waypoint까지 도달하도록 유도하기 위해서 더 긴 horizon T’ > T의 trajectory를 다시 샘플링한 \hat{\tau}'도 함께 사용했다고 하고 이 경우 loss는 아래와 같습니다.
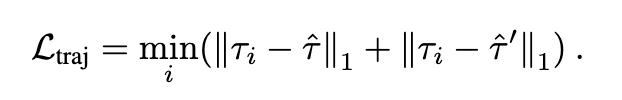
Scoring Decoder
trajectory proposal 기반 방법은 좋은 trajectory를 잘 고르는 것이 중요하다고 저자들은 주장합니다. 그래서 저자들은 traj 생성과 score 평가를 분리해서 다룹니다. 구체적으로는 scoring decoder가 trajectory decoder의 token을 그대로 쓰지 않고 대신 이미 decode된 trajectory 자체를 다시 embedding해서 score query로 만듭니다. 그리고 score branch에서 trajectory branch로 gradient가 역전파되지 않도록 막습니다.이렇게 하면 trajectory를 생성할 때 사용되는 정보랑 그것을 점수화할 때 사용되는 정보를 분리할 수 있다고 합니다. scorer는 trajectory token 안에 아직 남아 있을 수 있는 추가적인 latent 정보는 보지 않고오직 디코딩된 trajectory 자체만 보게 되는 설계라고 합니다.
Scoring, behavior control
DrivoR의 또 하나 중요한 포인트는 단순히 trajectory를 하나 고르는 데서 끝나지 않고 어떤 성향의 주행을 할지까지 조절할 수 있다는 점이라고 합니다. 그래서 저자들은 하나의 점수로 평가하는게 아니라 safety, comfort, progress 같은 주행 품질 요소를 여러 개의 sub-score로 나누어 예측하게끔 한다고 합니다. 그리고 추론 시에는 이 sub-score들을 다시 가중합해서 최종 meta score를 만들기 때문에 모델을 다시 학습하지 않고도 더 안전한 주행이나 좀더 적극적인 주행처럼 behavior를 조절할 수 있다고 합니다. 여기서 사용한 sub-score는 NAVSIM-v1의 PDMS 구성 요소라고 합니다.
scoring network는 각 sub-score c를 맞추도록 binary cross entropy로 학습됩니다.
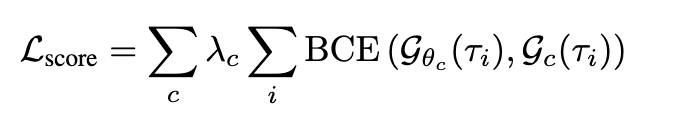
여기서 G_c(\tau_i)는 oracle scorer가 계산한 sub score이고G^\theta_c(\tau_i)는 모델이 예측한 값입니다. 즉 각 trajectory 후보 \tau_i에 대해 모델이 oracle의 scoring 방식을 따라 배우도록 만드는 구조라고 이해하시면 좋을 것 같습니다. 그리고 여기서 c는 safety, comfort, progress와 같은 각 sub-score 종류를 하나씩 가리키는 변수라고 합니다.
추론 시에는 이 scoring network를 일종의 reward function처럼 써서 sub-score들에 곱하는 가중치 lambda_c를 바꾸면 주행 성향도 함께 바뀌게 된다고 하는데 예를 들어 progress 쪽 가중치를 높이면 더 전진적인 trajectory를 선호하도록 만들 수 있다고 하는데 이부분은 신기하면서도 이해는 잘 되지는 않습니다. CtRL-Sim과 같은 Offline-RL 아이디어를 가져왔다고 하는데 시간되면 한번 관련 논문도 읽어봐야 할 것 같습니다.
결과적으로 최종 학습 손실은 trajectory loss와 scoring loss를 더한 형태로 아래와 같습니다.
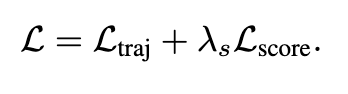
Experiments
기본 설정은 4개 카메라 입력 DINOv2 ViT-S backbone, camera당 16개 registerm 4-layer decoders, LoRA rank 32입니다. 그리고 전체 모델이 약 40M parameters 수준이라고 합니다.
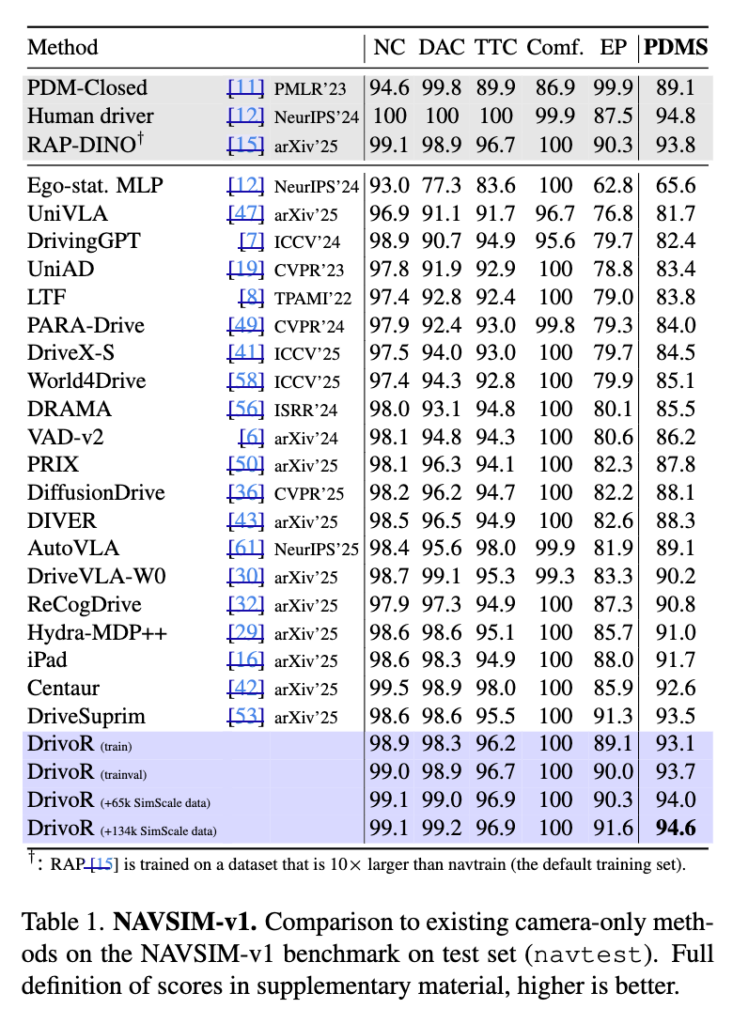
먼저 NAVSIM-v1 은 nuPlan을 기반으로 구축된 데이터셋으로OpenScene의 부분집합이라고 합니다. 기존의 nuScenes와 같은 벤치마크들이 주로 주행 품질을 전문가 human trajectory와의 유사도로 평가했던 것과 다르게 NAVSIM-v1은 closed-loop simulation에서 영감을 받은 평가 지표를 도입했다고 합니다. 전통적인 open-loop trajectory similarity 평가를 넘어서 충돌,진행성,안전성 등을 반영한 closed-loop-inspired metric에있는 평가지표(PDMS)를 사용하는 benchmark라고 보시면 좋을 것 같습니다. HUGSIM처럼 실제 시뮬레이터에서 agent를 굴리는 완전한 closed-loop 평가는 아님.
이 벤치마크의 주요 지표는 PDMS (Predictive Driver Model Score) 로 여러 종류의 penalty를 종합한 값이라고 합니다. 여기에는 예를 들어 반응하지 않는 다른 agent와의 충돌이나 도로를 벗어나지 않고 올바른 방향으로 주행하는지 여부 그리고 다른 agent와의 near-miss를 피하는지 등이 포함된다고 하고 그리고 여기에 더해서 comfort와 progress(얼마나 잘 앞으로 나아갔는지) 같은 품질 관련 점수도 함께 반영된다고 합니다. 이때 progress는 GT 정보에 접근할 수 있는 PDM agent의 centerline-progress와 비교하여 측정된다고 하는데 학습 시에는 벤치마크(위 테이블 [12])에서 정의한 기본 PDMS 가중치를 사용한다고 합니다. 이 부분이 이해가 잘 안갔는데 이 지표들은 GT trajectory와의 단순 거리 비교가 아니라 벤치마크 안에 정의된 scorer가 계산해주는 규칙 기반이나 시뮬레이션 기반 평가값이다 정도로 이해하고 넘어갔습니다. (내 모델이 낸 trajectory가 얼마나 전진했는지 계산하고 benchmark 안의 기준 레퍼런스 planner(PDM agent)도 같은 상황에서 얼마나 전진했는지 계산해서 비교해서 progress 점수를 정하는 느낌)
암튼 결과적으로 DrivoR는 NAVSIM-v1에서 다른 모든 방법들보다 좋은 성능을 보입니다.
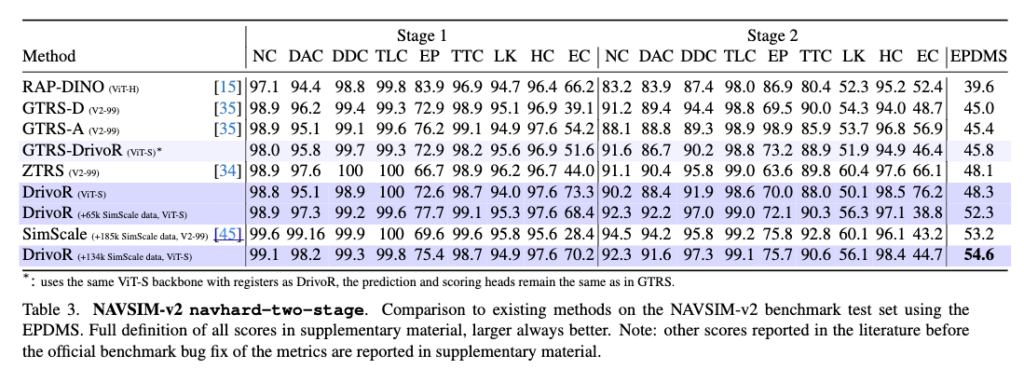
NAVSIM-v2는 v1보다 더 어렵다고 합니다.
NAVSIM-v1은 기존처럼 expert trajectory와의 단순 유사도만 보는 대신 PDMS라는 closed-loop-inspired metric을 도입해서 충돌, drivable area 준수, progress, comfort 같은 요소를 함께 평가합니다. 완전한 closed-loop simulator는 아니지만, 적어도 이 trajectory가 실제 주행 관점에서 괜찮은지를 더 종합적으로 보려는 벤치마크 느낌이고 NAVSIM-v2는 여기서 더 나아가, 진짜 closed-loop benchmark와의 격차를 줄이기 위해 two-stage evaluation을 도입합니다. 특히 두 번째 단계에서는 Gaussian Splatting으로 scene의 새로운 변형을 생성하고, ego vehicle의 위치나 heading에 shift, rotation 같은 perturbation을 줍니다. 그래서 모델이 단순히 학습 분포 안에서만 잘하는 게 아니, 조금 어긋난 초기 상태나 새로운 시점에서도 안전하게 일반화할 수 있는지를 시험하는 벤치마크라고 보시면 좋을 것 같습니다.
다시 돌아와서 NAVSIM-v2는 ego 상태에 perturbation(ego vehicle의 상태를 원래 데이터 그대로 두지 않고 위치나 방향을 조금 틀어놓는 것)이 들어가고, novel view, scene variation이 추가되기 때문에 distribution shift에 대한 robustness가 더 많이 요구되는 설정이기 때문에 v1보다는 좀더 어려운데, 여기서도 DrivoR는 좋은 성능을 보이고 synthetic SimScale data를 추가했을 때에는 SOTA를 기록하는 결과를 보입니다.
그리고 GTRS-DrivoR-ViT-S를 보면 이건 GTRS의 prediction/scoring head는 그대로 두고 비전 백본과 compression만 DrivoR 스타일로 바꾼 버전입니다. register-based compression만 바꿔껴도 얼마나 좋아지는지 를 보는 실험인데 성능이 향상되는 결과를 보입니다.
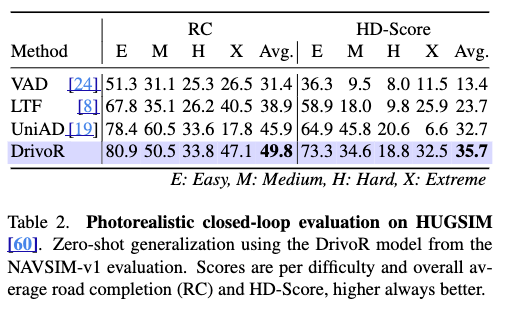
앞선 NAVSIM 계열 결과는은 아무래도 closed loop는 아니지만 간접적으로나마 평가하는 프록시 벤치마크 느낌이 있는데 HUGSIM은 photorealistic closed-loop simulator 평가라고 보시면 좋을 것 샅습니다. 여기서 DrivoR는 NAVSIM-v1으로만 학습한 모델을 zero-shot으로 평가했는데 가장 좋은 성능을 보입니다.이 모델이 단순히 open-loop metric에 overfit 된게 아니다라는 것을 해당 실험으로 보여주는 것 같습니다.(open loop 평가는 과적합에 민감함)
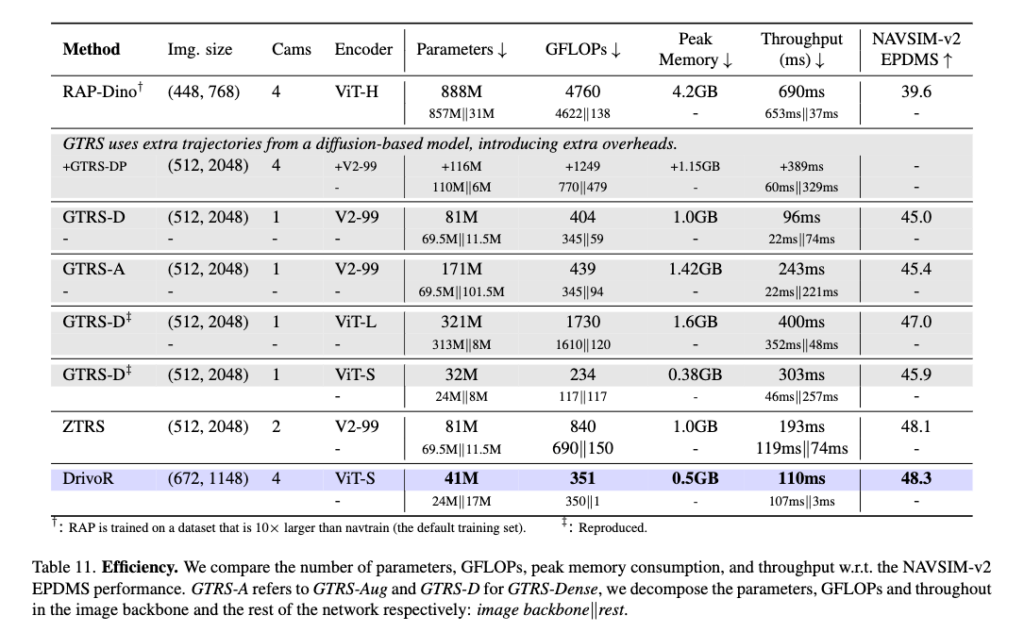
그리고 efficient 측면에서 저자들은 DrivoR의 runtime 성능을 ViT-L 기반 baseline인 GTRS와 비교합니다. 비교는 batch size 1, A100 GPU 1장, 그리고 quantization이나 별도의 가속 기법 없이 수행했다고 하고 결과적으로 DrivoR는 f3배 이상의 throughput 향상을 보아고 또 GFLOPs와 peak memory usage도 3배 감소시키면서도 동시에 성능 점수는 오히려 더 향상되는 결과를 보입니다.
여기서부터 ablation 결과인데 이 부분이 핵심인것 같습니다.
Pretrained DINOv2 backbone은 거의 필수다

먼저 pretrained backbone의 효과를 보면 random init 대비 ImageNet21k,그리고 DINOv2로 갈수록 planning score가 크게 좋아지는 결과를 보입니다.
Pooling보다 register compression이 낫다
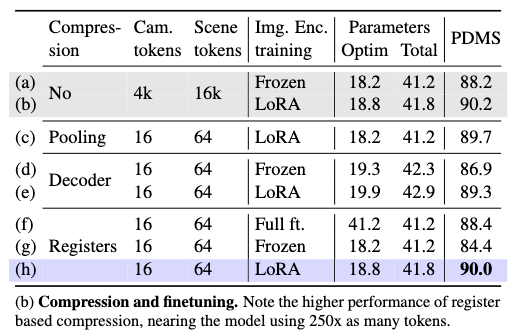
압축 방식 비교가 이 논문의 핵심 ablation인것 같은데 pooling, decoder-based compression, no compression, register-based compression을 비교했을 때, register 방식이 pooling보다 좋고, no-compression에 거의 근접한 결과를 보입니다. 그것도 downstream에서 사용하는 토큰 수는 훨씬 적습니다. 는 250배 적은 토큰으로 거의 비슷한 성능을 보입니다.
전방 camera token은 specialization되고, 후방 camera token은 collapse된다

fig 4같은 경우는 각 카메라에 대해 register token들 사이의 cosine similarity를 보여줍니다. front camera의 token들은 서로 decorrelated되어 있는 결과를 보이는데 저자가 말하기를 각 register가 서로 다른 역할로 specialization되어있기 때문이라고 합니다. 반면 back camera의 token들 사이의 유사도는 다 높은 결과를 보입니다. 대부분의 token이 거의 같은 representation으로 collapse된결과라고 저자들은 표현을 합니다. back camera에서는 사실상 하나의 token만 뚜렷하게 구분되는 수준인데 저자들의 이런 주장을 Fig 5 결과로 뒷받침 합니다. 실제로 서로 다른 front camera register들은 선행 차량, 신호등, 보도 등 서로 다른 영역에 attention을 하는 결과를 보이고 back cam에 대한 attention map도 이런 collapse 현상을 그대로 보여줍니다. 저자들은 실제 주행에서는 대부분의 attention이 전방 장면에 집중되고 후방은 짧게 확인하는 수준에 그치기 때문에 이런 결과가 나온 것이라고 주장합니다. 그래서 오히려 이부분에서 저자들은 side나 back처럼 상대적으로 덜 중요한 시점을 이렇게 collapse시키는 것이 downstream planning에서 노이즈를 줄이는 데 도움이 될 수 있다고 해석합니다. 그리고 이런 현상은 uniform pooling으로는 관찰할 수 없고 해결할 수 없는 register 기반 압축의 장점이라고 주장합니다.
LoRA finetuning
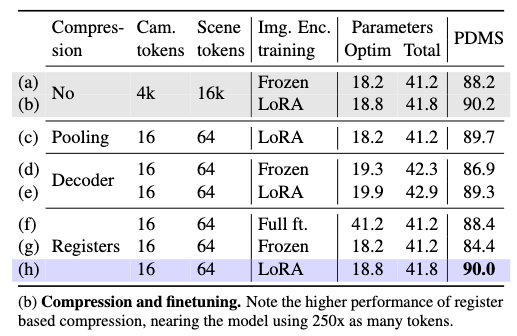
frozen backbone, full finetuning, LoRA를 비교했을 때 LoRA가 가장 좋은 결과를 보입니다. backbone에 특화된 learning rate scheduling을 더 세심하게 조정하면 full finetuning도 좋은 결과를 보일 수 있다고 저자들은 해석하지만 이런 메타파라미터에 덜 민감한 LoRA 파인튜능을 기본세팅으로 했다고 합니다.
레지스터 토큰 개수/ register DINO의 register 토큰 활용 여뷰
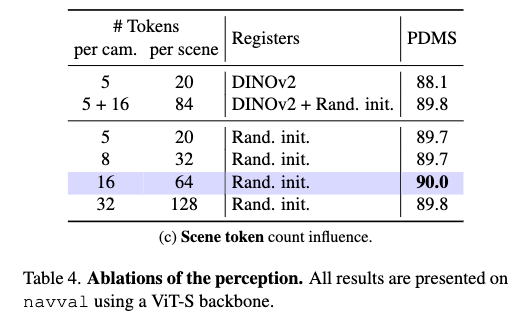
여기서는 두 가지 설정을 비교하는데 하나는 새로운 register를 랜덤 초기화해서 사용하는 경우로 이때는 DINOv2 backbone이 원래 가지고 있던 4개의 register는 버립니다.(아래 4개) 다른 하나는 DINOv2의 기존 register를 유지하면서(유지만 하면 맨 위 ,5-20 세팅), 여기에 새로 랜덤 초기화한 register를 함께 사용하는 경우입니다. (5+16 – 84 세팅) 후자의 경우 카메라를 구분하기 위해 DINOv2 register 출력에 카메라별 learnable positional encoding을 추가했다고 합니다.
먼저 DINOv2의 기존 register를 활용하는 것은 랜덤 초기화한 새로운 register에 비해 도움이 되지 않는 결과를 보입니다. 저자들은 이미 특정 목적에 specialization된 기존 register가 driving task에는 오히려 좋지 않은 초기값일 수 있다고 해석합니다. 또 register 수를 늘릴수록 성능은 오르긴 하지만 16 이후부터는 그렇게 성능이 오르거나 오히려 떨어지는 모습을 보입니다.
learnable traj 토큰 개수

마찬가지로 64개 이후부터는 성능이 plateau(성능이 정체되는 구간)에 도달하는 모습을 보입니다.
Scoring disentanglement
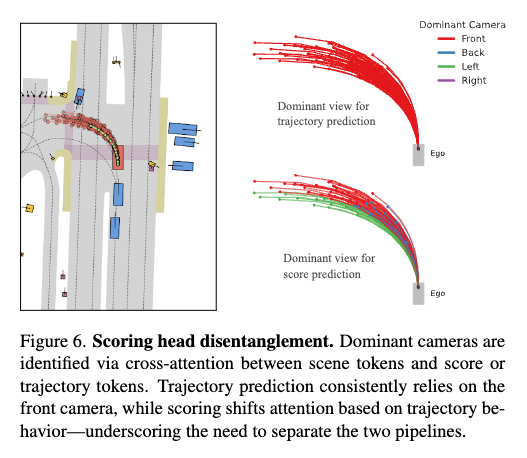
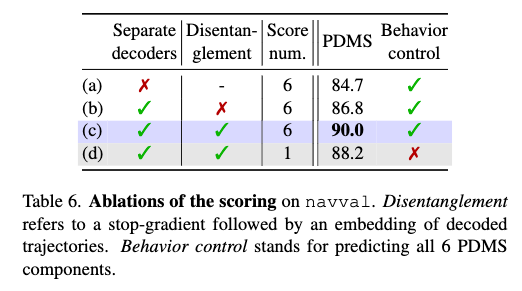
(a)에서는 trajectory generation과 scoring을 하나의 transformer branch에서 같이 처리하고 마지막에만 별도의 MLP head를 두는 방식을 사용하는 식의 평가인데 이 방식은 성능을 저하시키는 결과를 보입니다. Fig 6를 보면 두 작업은 실제로 참조하는 카메라 정보가 다른 모습을 보입니다. trajectory generation은 좌회전 상황에서도 주로 front view에 집중하는 반면,scoring은 trajectory의 급격한 방향 변화나 충돌 위험에 따라 left camera나 rear camera의 feature를 더 많이 활용한다고 합니다. 따라서 저자들은 이러한 차이때문에 traj generation과 scoring을 분리해서 따로 설계하는게 맞다고 주장합니다.
그리고 저자들은 이어서 scoring branch가 trajectory를 새로운 feature space에 embedding하고, 동시에 scoring 쪽 gradient가 generator로 흘러가지 않도록 막아야 하는지도 실험합니다. (b) 설정은 disentanglement를 적용하지 않은 경우이고(그레디언트 흐름, scoring과 그레디언트 섞임) (c), (d)는 disentanglement를 적용한 경우입니다. 결과적으로 generation과 scoring을 더 분리할수록 성능이 향상되는 모습을 보입니다.
하나의 token으로 trajectory 전체를 표현
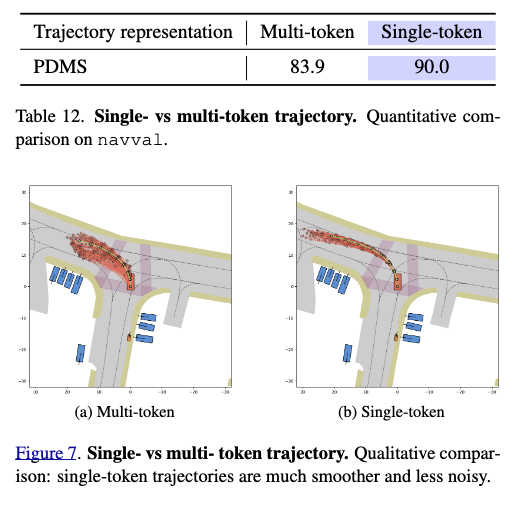
위는 Supplementary에 있는 실험인데 trajectory를 pose마다 token 하나씩 할당하는 대신 trajectory 하나를 token 하나가 대표하게 했더니 성능이 크게 좋아졌다고 합니다.
Conclusion
일단 전체적으로 보면 DrivoR의 큰 파이프라인 자체가 mobile navigation이랑 크게 다를게 없다고 느꼈고 단순히 trajectory proposal 기반 end-to-end 구조 위에 register token을 활용한 scene compression과 generation , scoring disentanglement 같은 디테일을을 얹은 그런느낌인 것 같습니다. 근데 체감이 느껴지는 차이는 평가 프로토콜과 디테일한 실험 설계인 것 같습니다. 물론 논문을 해당 논문밖에 안읽어봤긴 하지만 그래도 NAVSIM-v1, NAVSIM-v2, HUGSIM처럼 서로 다른 성격의 공통된 벤치마크에서 성능을 비교하고 sota 경쟁하고 perception compression, register 개수, scoring 분리, disentanglement, behavior tuning까지 세세하게 ablation을 진행한 부분은 확실히 AD 분야 모바일 로봇보다는 벤치마크 중심으로 정교하게 연구되고 있다는 느낌을 받았습니다. 물론 모바일 로봇 쪽에도 Habitat 시뮬레이터이 기반의 R2R,RxR closed loop 평가는 있지만 indoor씬에서 room to room이라는 한정된 공간만을 움직이고 VLN 전용 벤치마크라 그런지 NoMaD류의 방법론들은 공통된 벤치마크 내에서 Closed loop 평가로 쓰이지는 않는 느낌입니다. 잘은 모르지만 이쪽 분야에도 Hugsim 을 가지고 이런 평가 세팅을 만드는 것도 좋은 연구가 될 것 같다는 생각도 듭니다. 그리고 리뷰에서는 실험이 많아서 모든 내용을 다 담지는 못했는 궁금한 부분이 있으면 댓글주시면 감사하겠습니다.
이만 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
몇가지 질문이 있는데, 우선 레지스터 토큰을 추가하는 것이 단순히 visual patch 숫자가 늘어난 것처럼 입력으로 들어가 기존 ViT가 가지고 있는 attention 매커니즘에 의해 프레임들의 정보를 흡수하고 이후 유사[CLS]처럼 정보를 활용하는 것처럼 이해를 했습니다. 당연히 처음에는 random 초기화를 할테니 학습을 진행해야하겠지만 굳이 LoRA를 쓴 이유가 있나요? 아니면 LoRA를 사용하지않아도 단순히 래지스터 토큰을 선언하는 것만으로도 학습이 가능한 것 아닌가하는 생각이 있습니다.
두번째 질문은 ego status가 현재상태를 나타내는 것으로 이해를 하였는데, driving command 가 뭔지 궁금합니다.
감사합니다.
안녕하세요 인택님 좋은 댓글 감사합니다.
말씀하신대로 굳이 LoRA를 사용하지 않고 단순히 해당 러너블한 토큰만으로도 학습이 가능합니다. 그래서 저자들도 관련해서 해당 실험을 진행을 하였고 ablation 결과로 리포팅하였습니다.
두번째 질문에 대해서는 논문에 자세한 언급은 없었지만 제가 추측하기로는 driving 할 때 차량의 선속도, 각속도 정보이지 않을까 생각됩니다.
감사합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
세미나 때 한번 들었는 논문이라 더 쉽게 읽힌 것 같습니다.
궁금한 점이 있습니다.
측면 scene은 무시하는 이유가 전방과 확연하게 다르기 때문인 것 같습니다.
그러나 후방은 전방과 꽤 비슷한 장면 구성이 들어오는데 attention이 대부분 무시되는 것이 신기했습니다.
이는 register가 차의 앞부분이 보이고, 신호등의 뒷부분이 보이고 와 같은 의미적인 부분을 잡아내어 무시한다고 이해하면 될까요?