Abstract
시뮬레이션 기반의 데이터 생성 방식이 로봇 조작 정책 학습의 지배적 흐름이 되었습니다. 그러나 기존의 방식들은 affordance 정보를 trajectory에 포함하지 못하며, 이로 인해 특정 기능이 가능한 영역과 정밀한 상호작용을 위한 작업에는 적용이 어려웠습니다. 해당 논문은 open-vocabulary 3D affordance 예측을 통합한 최초의 시뮬레이션 파이프라인인 AffordSim을 제안합니다. AffordSim은 IsaacSim에서 구축되었으며, cross-embodiment를 지원하고, 실제 이미지로부터 DA3기반의 3D Gaussian reconstruction을 활용한 새로운 domain randomization 기법을 통해 강인하고 확장 가능한 조작 데이터 생성 파이프라인을 구축하였다고 합니다. 이러한 AffordSim은 7개의 작업 유형으로 구성된 총 50가지 조작 작업 벤치마크를 만들고, 여러 imitation learning 베이스라인을 평가하였습니다. 실험 결과 ‘pouring into narrow containers’, ‘mug haning’과 같이 affordance가 중요한 작업에서 기존 imitation learning은 40% 이하의 낮은 성능을 보였으며, 이를 통해 affordance를 고려한 데이터 생성이 필요함을 강조하며, 실제 Franka FR3에서 zero-shot sim-to-real 실험을 통해 생성된 데이터의 전이 가능성을 보였습니다.
Introduction
낮은 비용으로 다양하고 많은 trajectory를 생성할 수 있다는 이점으로 시뮬레이션 기반의 데이터 생성이 로봇 조작 정책 학습의 중요한 패러다임이 되었습니다. 그러나 기존의 데이터 생성 연구들은 affordance 정보를 trajectory 생성 파이프라인에 고려하지 않고 있습니다. 단순히 안정적으로 물체를 잡는 것만으로는 pouring, mug hanging과 같이 물체의 특정 영역에 맞추어 상호작용해야 하는 작업을 해결하기 어렵습니다.
현재 시뮬레이션 플랫폼들은 grasp pose를 추정하기 위해 수동으로 grasp를 설계하거나, grasp estimation을 수행합니다. 그러나 수동 방식은 사람이 직접 수행하여 노동력이 너무 많이 들고 확장이 어렵고, AnyGrasp와 같은 grasp estimation을 이용하는 방식은 안정적인 파지에 집중하여 task에 특화된 기능적 영역을 파지하는데는 어려움이 있습니다. 저자들은 실험을 통해 pouring 작업의 경우 머그컵 손잡이를 잡아야 이후의 작업을 수행하는 데 어려움이 없지만, 일반적인 grasp는 머그컵의 몸통을 잡도록 되어있어 policy 성공률이 최대 10%로 낮은 성능을 보였으며, affordance guidance를 사용할 경우 의미있는 성능 향상을 관찰하였다고 합니다.
따라서 저자들은 처음으로 affordance를 로봇 조작 데이터 생성 파이프라인에 통합한 AffordSim을 제안하였습니다. AffordSim은, open-vocabulary 3D affordance detection방식인 저자들의 VoxAfford 모델을 통해 객체와 로봇이 어디서 어떻게 상호작용해야하는지를 나타내는 affordance map을 예측합니다. 이러한 예측을 grasp pose esitmation과 motion planning에 활용하여 물리적으로 합리적이고 작업 목적에 부합하는 trajectory를 생성하도록 합니다. 또한, AffordSim은 VLM 기반의 자동 task-scene generation을 통해 자연어 작업 설명이 주어졌을 때 시뮬레이션 장면을 생성하여 작업에 특화된 엔지니어링 없이 cross-embodiment를 지원한다고 합니다. 또한, 실제 사진으로부터 DA3 기반 3D Gaussian reconstruction을 수행하는 방식을 포함하여 5가지 randomization 축을 사용하여 sim-to-real transfer에서 발생하는 시각적 도메인 갭을 줄이고자 하였습니다. 마지막으로, 해당 논문은 7개 유형의 50개 작업 벤치마크를 구성하여 BC(Behavioral cloning), Diffusion Policy, ACT, pi-0.5 4가지 imitation learning 베이스라인을 평가하였습니다.
벤치마크 실험을 통해 현재 imitation learning 방식은 grasping에서는 50~90%의 높은 성공률을 달성하지만, 물을 붓거나 고리에 컵을 거는 등의 affordance를 고려해야하는 작업에서는 0~47%의 낮은 성공률을 기록하였습니다. 저자들은 이를 통해 어려운 조작 작업에 affordance-aware data generation이 필요함을 확인하였음, 실제 Frank FR3에 zero-shot sim-to-real transfer 실험을 통해 AffordSim 데이터만으로 학습된 policy가 실제 환경에 전이가 가능함을 확인하였습니다. 또한, grasping에서 60%, mug haning에서 10%의 성공률을 나타내었으며 저자들은 이를 시뮬레이션의 성능 경향과 유사하다고 주장합니다.
Method
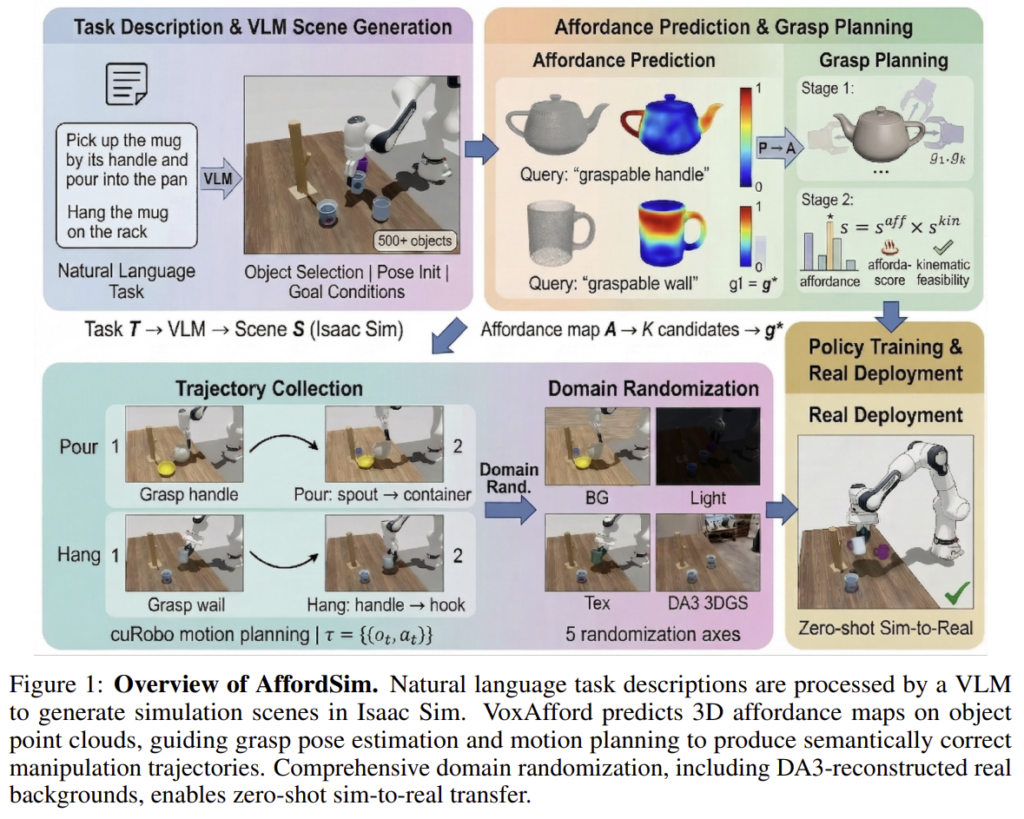
AffordSim은 크게 4가지로 단계로 이루어집니다. 먼저 작업에 대한 자연어 지시문 \mathcal{T}가 주어졌을 때, AffordSim은 (1) VLM을 이용하여 물체와 물체의 자세, 로봇 embodiment, 목표 condition으로 구성된 시뮬레이션 장면 정보 \mathcal{S}로 변환하여 시뮬레이션 장면을 자동으로 생성합니다. (2) 시뮬레이션 상에서 대상 물체마다 point cloud를 포착한 뒤, VoxAfford를 통해 각 point p_i \in \mathcal{P}의 작업에 적합한지 나타내는 affordance map \mathcal{A} : \mathcal{P} → [0,1] 을 생성합니다. 이후 (3) 예측된 affordance를 가중치로 이용하여 최적의 grasp pose \mathbf{g}* \in SE(3)를 선별합니다. 마지막으로 (4) motion planner를 통해 trajectory \tau를 생성하고 실행하며, 렌더링된 observation에 domain randomization을 적용합니다.
VLM-Powered Task and Scene Generation
‘pick up the mug by its handle and pour into the pan’와 같은 작업 지시문 \mathcal{T}이 주어졌을 때, VLM을 이용하여 USD 에셋의 경로 리스트, 각 물체의 초기 pose, target 로봇, 작업에 특화된 goal condition(e.g. ‘object A is inside container B’)를 생성합니다. 사람이 수동으로 생성하는 것 보다 빠르고 많이 작업을 생성할 수 있으며, 다양한 로봇으로 적용이 가능합니다.
Affordance-Aware Trajectory Generation
AfforSim의 핵심은 affordance를 데이터 생성 파이프라인에 통합하였다는 것 입니다. 작업 지시문\mathcal{T}와 객체의 point cloud \mathcal{P}가 주어졌을 때, VoxAfford는 각 표면의 point가 해당 작업에 얼마나 적합한지를 나타내는 affordance score a_i \in [0,1 ]를 예측하게 됩니다.
구체적으로, VoxAfford는 IROS 2023에서 공개된 open-vocabulary 3D affordance detection 연구를 기반으로 합니다. 해당 방식은 해당 방법론은 open-vocabulary 3D affordance detection을 위해, 3D 시각 정보와 자연어 text 정보 사이의 상관 관계를 학습하는 방식으로, 학습 데이터에 포함되지 않은 새로운 affordance text로도 언어의 의미론적 유사성을 통해 감지할 수 있도록 하는 방법론입니다. 저자들은 freeze 된 3D VQAE encoder에서 얻은 multi-scale geometric feature를 cross-attention을 통해 MLLM의 출력 토큰에 결합한 뒤, 이를 통해 affordance mask를 생성합니다. 이를 통해 ‘graspable handle’, ‘pourable rim’과 같은 자연어 쿼리를 입력으로 사용할 수 있으며, 작어베 특화된 학습이 없어 객체 카테고리 전반으로 일반화가 가능하다고 합니다.
[ Affordance-guided Grasp Selection ]
VoxAfford를 이용하여 포인트 별 affordance score를 구한뒤, 최적의 grasp pose를 선정하기 위해 affordance 정보를 활용합니다. 먼저 affordance map \mathcal{A}에서 높은 확률을 가지는 표면에 대해 여러 grasp pose 후보 \mathcal{G}=\{\mathbf{g}_1, ..., \mathbf{g}_K\}를 생성합니다. 이후 각 후보 \mathbf{g}_k에 대하여 아래의 식으로 정의된 score를 계산하여, 가장 높은 score를 가지는 grasp pose를 선별합니다.
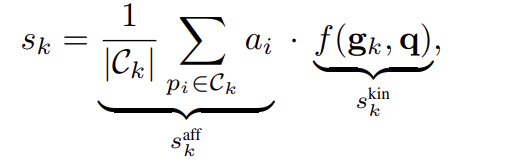
위의 식에서 \mathcal{C}_k는 grasp \mathbf{g}_k의 접촉점들 집합으로, s^{aff}_{k}는 접촉점들의 평균 affordance score를 나타냅니다. s^{kin}_k= f(\mathbf{g}_k,\mathbf{q})는 reachability와 충돌 가능성을 평가한 것으로, 현재 configuration \mathbf{q}가 주어졌을 때 시뮬레이션을 활용하여 구하는 것으로 보입니다. 이렇게 구해진 score s_k를 통해, 작업에 대한 확률과 물리적 가능성을 고려한 최적의 grasp pose \mathbf{g}*를 선별합니다.
[ Motion Planning ]
grasp pose \mathbf{g}*를 cuRobo 라이브러리를 활용하여 충돌이 없는 trajectory를 생성하고, 작업을 실행한 뒤 이후의 조작을 동작을 계획합니다. 전체 궤적은 \tau = \{(o_t,a_t)\}^T_{t=1}로 정의되며, o_t는 RGBD와 로봇 자체 정보를 포함하는 observation, a_t는 end-effector의 pose command를 의미합니다.
Domain Randomization for Sim-to-Real Transfer

마지막으로 AffordSim은 시뮬레이션과 실제 세계 사이의 시각적 차이를 줄이기 위해 5가지 축을 따라 domain randomization을 수행합니다. (위의 Figure 2 참고)
- Background texture: texture library에서 랜덤하게 texture를 선택하여 작업 공간과 주변 표면에 적용
- Lighting: 광원의 개수, 위치, 강도, 색상을 랜덤하게 변화
- Object texture: 객체의 PBR material 속성(albedo, roughness, metallicity 등)에 변동을 줌
- Object pose: 객체의 초기 위치 및 방향에 랜덤한 변동
- DA3 Gaussian background: 실제 deploy 환경을 10~20장의 사진으로 촬영한뒤, DA3 based 3D Gaussian Splatting을 적용하여 해당 장면을 재구성한뒤, 임의의 시점에서 photo-realistic 한 배경을 렌더링하여 시뮬레이션 장면 뒤에 합성
이러한 domain randomization을 통해 실제 환경의 시각적 통계를 보존하고, sim-to-real transfer시 발생하는 도메인 갭을 줄일 수 있었다고 합니다.
Benchmark Design

- Grasping(10 tasks): 물체를 잡아서 올리기. 잡을 수 있는 표면 affordance 필요
- Placing(10 tasks): 물체를 잡아서 target 위치에 담기. release-point affordance 필요
- Stacking(5 tasks): 특정한 순서로 물체를 쌓기. 안정적으로 놓을 수 있는 표면 affordance와 순서에 따른 조작 필요
- Pushing/Pulling(6 tasks): 목표 위치로 물체를 밀거나 문을 당겨 여는 작업. 접촉해야하는 표면 affordance 필요
- Pouring(8 tasks): 서로 다른 기하학 구조의 용기 사이에 내용물을 따르는 작업. 컵이나 용기의 rim affordance와 기울임 제어 필요
- Mug Hanging(3 tasks): 머그컵을 랙이나 고리에 거는 작업. 손잡이 구멍 affordance와 정밀한 alignment 필요
- Long-Horizon Composite(8 tasks): 서로 다른 카테고리의 조작들로 이루어진 multi-step 작업.(e.g. pick-pour-place, open-and-place) 여러 객체와 상호작용이 이루어지는 순차적인 affordance 추론이 필요
각 작업은 30번의 시뮬레이션으로 평가되며, 주요 평가지표는 Success Rate(SR)로, long-horizon composite 케이스의 경우 각 단계별 SR을 평가합니다.
Experiments
저자들은 4가지 측면에서 실험을 진행하였습니다. 먼저, 기존의 imitation learning 베이스라인(Behavioral cloning, Diffusion Policy, ACT, pi-0.5)을 벤치마크에 적용하여 성능을 확인하고, cross-embodiment에 대한 일반화 성능을 평가합니다. 이후 affordance 정보를 활용하는 것의 효과를 검증한 뒤, zero-shot sim-to-real transfer를 실험합니다. 또한 평가시에는 일반화 성능 평가를 위해 객체가 놓인 pose도 랜덤하게 설정하였다고 합니다.
모든 policy는 AffordSim에 생성한 작업당 300개의 데모로 학습되며, 입력은 RGBD와 proprioceptive state를 활용합니다.
Benchmark Evaluation
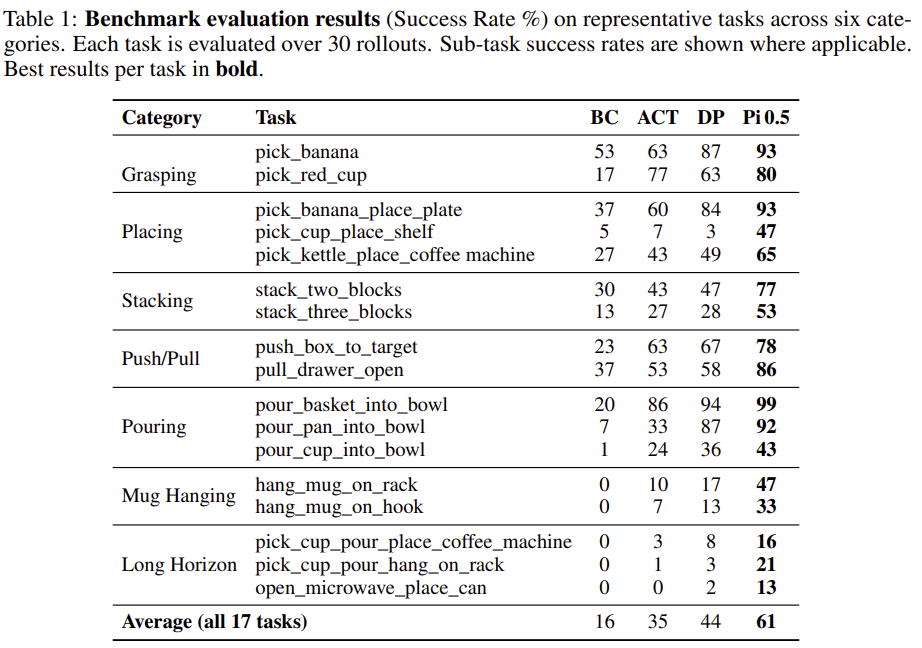
위의 Table 1은 각 조작 유형의 대표 작업에 대한 결과로, grasping 작업은 대체로 가장 높은 성공률을 보였으며, 53~93%의 성공률을 달성하였습니다. 이는 베이스라인 방식이 기본적인 pick-up 작업에 대해서는 잘 작동한다는 것을 의미하며, placing과 push/pull의 경우 grasping보다는 대체로 낮은 성능을 보여주었습니다. 저자들은 초기 grasp 단계보다 정밀한 위치에 놓는 과정에서 실패가 발생하였다고 합니다. 이러한 실험을 통해 저자들은 affordance 정보가 많이 요구되는 작업에서 성능이 크게 저하된다고 분석하였습니다. 특히, pouring의 경우, 넓은 바구니에 붓는 작업에 비해 좁은 컵에 붓는 작업에서 성공률이 크게 저하되었으며, 이러한 성공 여부가 기능적 영역과 정밀한 상호작용에 의존하는 케이스의 경우 기존 방법론들이 여전히 어려움을 겪는다는 것을 통해 affordance-guided 데이터 생성에 대한 필요성을 강조합니다.
Cross-Embodiment Evaluation
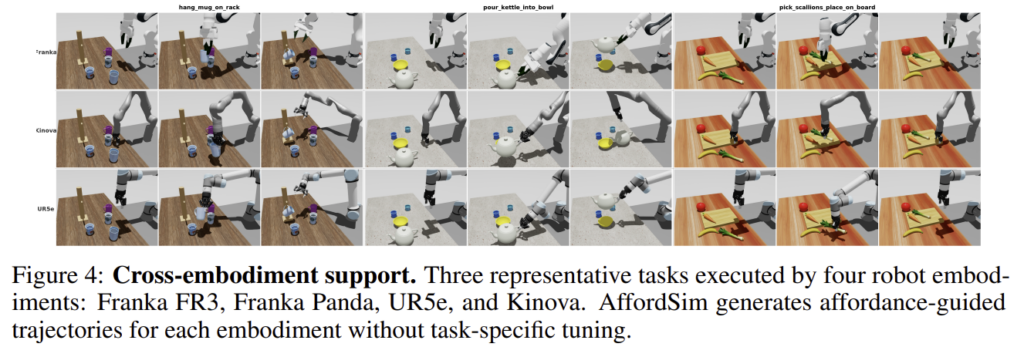
저자들은 10개의 작업에 대하여 4가지 로봇 embodiment에 대하여 성공률을 평가하였습니다. AffordSim의 경우 모든 로봇에 대해 성공적으로 affordance-guided trajectory를 생성하였으며, 각 로봇에 대해 Franka FR3 94%, Franka Panda 92%, UR5e 83%, Kinova 95%의 성공률을 확인하였다고 합니다. 저자들은 이러한 성능 차이에 대하여 VoxAfford는 로봇과 무관하게 동작하므로, affordance 예측의 문제라기보다는 로봇 간 kinematic 차이에서 비롯된 것으로 보았습니다. UR5e의 경우 6DoF로, 7DoF인 다른 로봇들에 비해 손목의 유연성이 제한되어 pouring작업에서 어려움이 있었다고 합니다. 이러한 실험을 통해 AffordSim이 작업에 특화된 학습 없이도 다양한 로봇 플랫폼으로 일반화 가능하다는 것을 보였습니다.
Affordance Integration Ablation
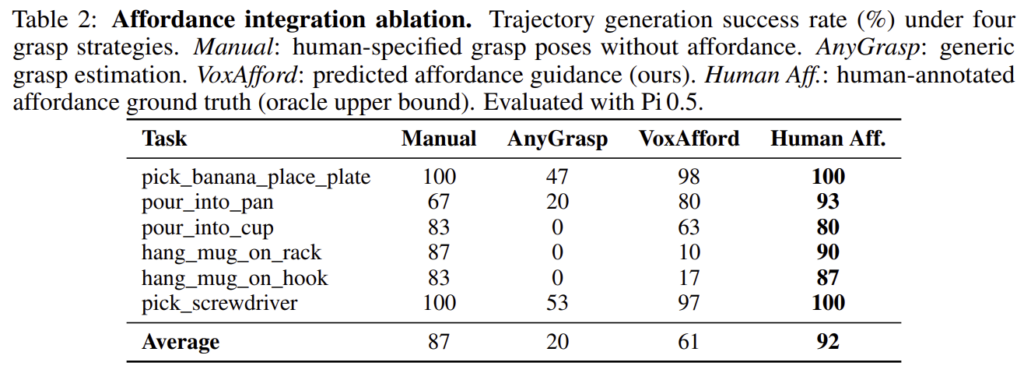
위의 Table 2는 affordance가 중요한 작업에서 4가지 grasp 방식에 대하여 평가합니다. Manual은 affordance를 고려하지 않고 사람이 물체의 grasp pose를 지정하는 방식, AnyGrasp는 사전학습된 모델, VoxAfford는 저자들이 사용한 affordance를 가중치로 사용하는 방식, Human Aff는 사람이 어노테이션한 pose를 이용한 방식(upper bound)이라 합니다. Manual의 경우 높은 성능을 달성하였으나, 새로운 객체가 주어졌을 때 사람이 직접 추가해야하므로 시간과 비용이 많이 들어 확장에 어려움이 있습니다. 또한, affordance를 고려하지 않는 AnyGrasp는 확연히 낮은 성능을 기록하였으며, affordance guidance를 통해 성능이 크게 개선된 것을 확인할 수 있습니다.
그러나 컵을 어디에 거는 작업에서는 VoxAfford도 상당히 낮은 성능을 보였으며, 저자들은 VoxAfford가 hanging 작업에 특화된 affordance를 학습하지 않았기 때문이라고 분석하였습니다. 한편, VoxAfford가 충분한 학습 데이터를 가진 작업(e.g. pick-and-place, pouring, screwdriver)에서는 이미 oracle 성능의 80% 이상을 달성하였습니다.
Zero-shot Sim-to-Real Transfer
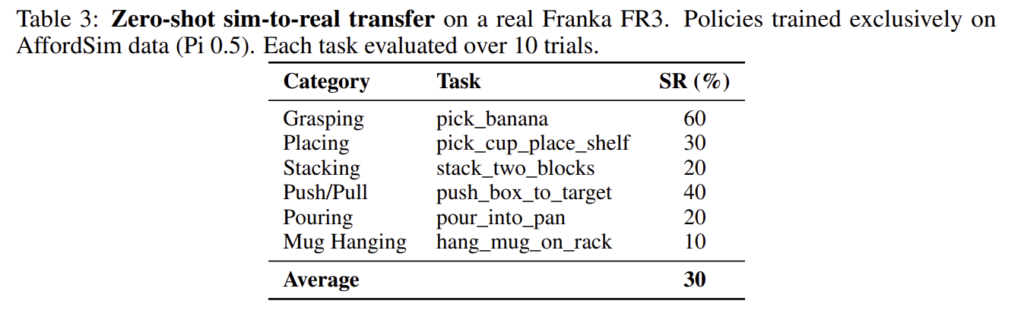
다음으로 저자들은 AffordSim 데이터만으로 학습한 policy가 실제 로봇에 전이될 수 있는지를 평가하였습니다. pi-0.5를 실제 Franka FR3에 zero-shot으로 deploy 한 결과, grasping은 60%로 비교적 높았지만, pouring은 20%, mug hanging은 10%로 낮은 성능을 보였습니다. 이러한 경향은 시뮬레이션에서와 유사한 결과를 보였습니다.
Domain Randomization Robustness
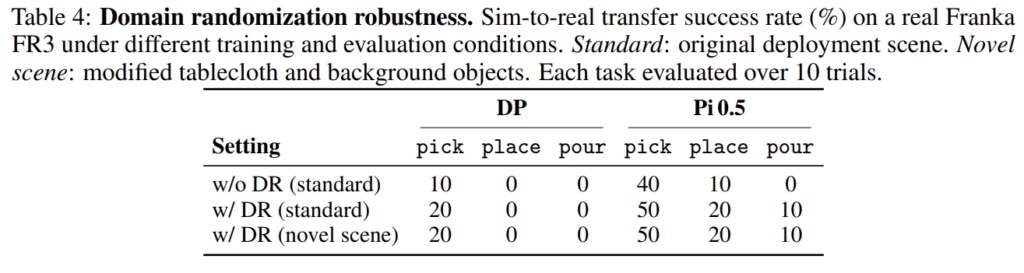
마지막으로 Table 4는 domain randomization(DR)에 대한 효과를 검증한 것 입니다. 실험을 통해 DR을 적용함으로써 policy의 real-world에서 성공률이 향상되었으며, 실제 환경의 테이블보나 배경 물체가 바뀌어도 성능이 유지되어, AffordSim의 randomization이 환경 변화에 대한 robustness를 높이는 데 기여함을 보였습니다.
그러나 수치적으로 보았을 때, sim-to-real 성공률 자체는 전반적으로 낮았으며, 이를 통해 실제 환경에서도 완전히 잘 작동한다라고 주장하기보다는, AffordSim 데이터가 어느 정도 zero-shot transfer 가능성을 보이며, 특히 affordance가 복잡한 작업은 실제에서도 여전히 어려움이 있다는 것을 보였다고 강조합니다.
안녕하세요 승현님 리뷰 감사합니다.
시뮬레이션을 활용해서 affordance를 고려한 데이터를 생성하는 연구.. 관심있게 읽었습니다. 읽다보니 질문들이 좀 생겼는데요,
Q1. Grasping까지는 VoxAfford와 grasp pose estimation을 통해 가능할 것 같은데, 예를들어 주전자로 물을 따르라 했을 때 주전자를 잡은 다음 물을 따르는 action 까지는 어떻게 처리하는지 알 수 있을까요?
Q2. Figure 1을 보면 Input으로 들어가는 자연어에 조작 객체 뿐만 아니라 상호작용 부위까지 명시적으로 언급이 돼있는데, 혹시 파이프라인의 affordance 쪽이 상호작용 부위 없이는 잘 작동하지 못하는 빈틈(?)이 있을까요?
질문 감사합니다.
Q1. Grasping까지는 VoxAfford와 grasp pose estimation을 통해 가능할 것 같은데, 예를들어 주전자로 물을 따르라 했을 때 주전자를 잡은 다음 물을 따르는 action 까지는 어떻게 처리하는지 알 수 있을까요?
-> 해당 과정은 cuRobo 라이브러리를 이용한 것으로 보입니다.
Q2. Figure 1을 보면 Input으로 들어가는 자연어에 조작 객체 뿐만 아니라 상호작용 부위까지 명시적으로 언급이 돼있는데, 혹시 파이프라인의 affordance 쪽이 상호작용 부위 없이는 잘 작동하지 못하는 빈틈(?)이 있을까요?
-> 아무래도 상호작용 부위 정보는 조작이 이루어진 시뮬레이션 장면 정보를 생성하는 과정에서 정확도에 중요한 역할을 하기는 할 것 같습니다. 예를 들어 컵을 렉에 거는 작업을 수행한다고 하였을 때, 손잡이를 걸라는 말을 하지 않으면 컵의 몸통 부분을 거는 등의 케이스가 생길 것 같습니다. 조금 더 원하는 방향의 작업을 위해서는 중요한 정보가 될 것 같습니다.