안녕하세요, 오늘은 좀 (저한테만?) 좀 신기한 논문을 가져왔습니다. VLA 관해서 “흠 뭐가 재밌을까”하다가 2026년 AAAI에 어쩌고 저쩌고 한 논문이라고 해서 쓱 훓어보니까 제가 알던 VLA의 Figure랑은 좀 다른 형태의 사진이 보이길래 신기해보이기도 하고, Semartic이라는 의미적 VLA가 무엇일까, 이제까지 VLA는 세상을 의미적으로 바라보지 않았던걸까?등등 좀 많은 궁금증이 들어서 읽어보게 되었걸랑요! 그러면 리뷰 시작해보겠습니다~~始めましょう~

- Conference: AAAI 2026
- Authors: Wei Li, Renshan Zhang, Rui Shao, Zhijian Fang, Kaiwen Zhou, Zhuotao Tian, Liqiang Nie
- Affiliation: Harbin Institute of Technology, Shenzhen; Shenzhen Loop Area Institute; Huawei Noah’s Ark Lab
- Title: SemanticVLA: Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation
1. Introduction
최근 VLA 모델들이 사전 학습된 VLM을 활용해서 언어로부터 행동까지 end-to-end 매핑을 수행하는 방식으로 로봇 조작 분야에서 발전을 이루고 있습니다. 하지만 기존 VLA 모델들에는 크게 두 가지 한계가 있다고 저자는 지적하고 있습니다.
첫 번째로 시각 인식의 중복성(Redundancy in visual perception)입니다. 기존 VLA 프레임워크들은 instruction과 무관하게 모든 시각 토큰을 균일하게 처리합니다. 즉, 배경 잡음이나 task와 관련 없는 객체까지 전부 인코딩해서 연산 비용이 과도하게 들고, 정작 중요한 task 관련 정보에 대한 attention이 희석된다는 문제가 있습니다.
두 번째로 Superficiality in instruction-vision semantic alignment입니다. 대부분의 VLA 모델들이 LLM을 통한 범용 cross-modal alignment에만 의존하다 보니, 로봇 조작에서 필요한 세밀한 시각적 구성(fine-grained visual compositionality)을 제대로 포착하지 못한다는 것입니다. 이로 인해 global action cue(전역 행동 단서)와 local semantic anchor(지역 의미 앵커), 그리고 instruction과 spatial 간의 구조적 의존성을 파악하는 능력이 크게 제한됩니다.
이를 해결하기 위해 저자는 SemanticVLA를 제안합니다. 핵심은 세 가지 수준의 상호 보완적 의미(semantics)를 활용하는 것입니다.
- instruction-level linguistic intent semantics: task prompt가 전달하는 언어적 의도
- vision-level spatial semantics: 객체와 배치를 설명하는 공간 의미
- control-level action semantics: translation, rotation, gripper 상태를 관장하는 행동 의미
이 세 가지 semantics를 정렬하면서 sparsification과 enhancement를 수행하는 것이 SemanticVLA의 핵심 설계라고 볼 수 있습니다.
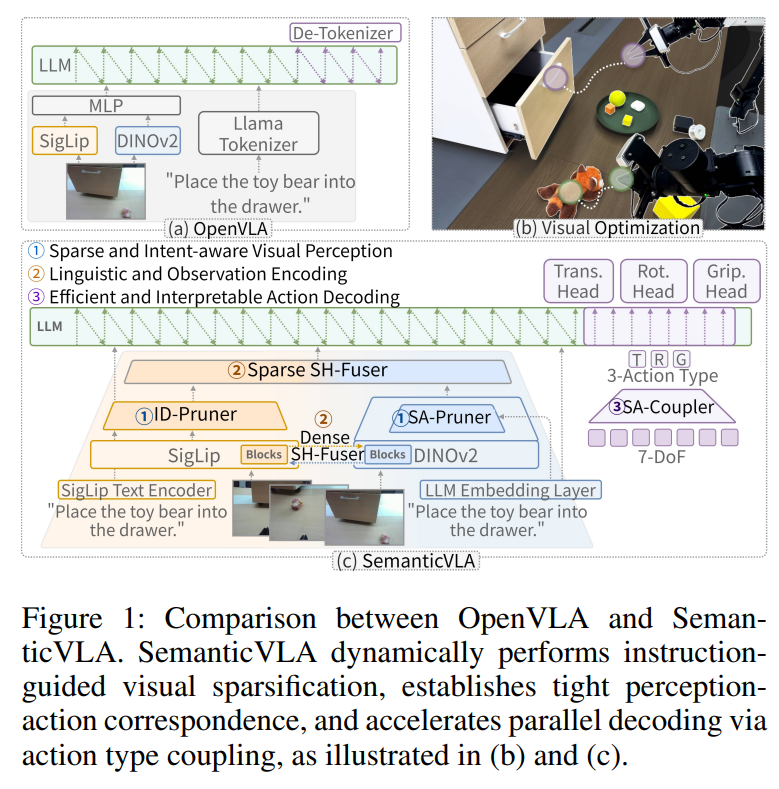
3. SemanticVLA
3.1 Proposed Framework
입력 컨텍스트를 X = {V, q, \ell}로 정의합니다. 여기서 V는 실시간 시각 관측, q는 로봇의 현재 proprioceptive state(관절 각도, end-effector pose 등), \ell은 자연어 instruction입니다. 모델은 K개의 미래 행동 청크 A = [a_0, a_1, \ldots, a_{K-1}] \in \mathbb{R}^{(K \times D) \times d}를 예측하며, D는 각 atomic action vector의 차원(예: 3-DoF translation + 3-DoF rotation + gripper = 7)입니다.
전체 파이프라인을 보면, 시각 관측 V는 두 개의 병렬 경로로 처리됩니다.
- SigLIP 기반 visual encoder → ID-Pruner로 instruction에 따라 희소화
- DINOv2 기반 spatial encoder → SA-Pruner로 dense geometric feature 추출
이 두 스트림이 SH-Fuser를 통해 계층적으로 통합되어 task-relevant representation Z를 생성합니다. 그 다음 Z에 instruction \ell, proprioceptive state q, K개의 learnable action placeholder를 concatenation해서 병렬 디코딩을 위한 입력을 구성합니다.
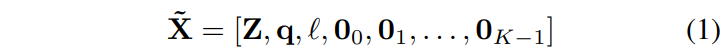
여기서 SA-Coupler에 따라 각 placeholder 0_i = {t^0_i, r^0_i, g^0_i} \in \mathbb{R}^{3 \times d}는 translation, rotation, gripper 토큰을 명시적으로 분리하면서도 7-DoF atomic action vector를 함께 인코딩합니다. 마지막으로 bidirectional decoding f_{\parallel}(\cdot)이 단일 forward pass로 K개의 미래 행동을 동시에 생성합니다: A = f_{\parallel}(\tilde{X}).
정리하면 semantic sparsification, hierarchical fusion, compositional action modeling, 즉 핵심 시각 정보, 의미 정보와 공간 정보를 여러 단계에서 결합, 행동을 회전&이동&잡기로 나누어서 이해하는 3가지 프로세스를 하나의 통합 아키텍처 내에서 수행하는 것이 SemanticVLA의 구조적 특징이라고 볼 수 있습니다.
3.2 ID-Pruner for SigLIP
ID-Pruner는 SigLIP encoder에서 추출된 visual token {v^{Sig}_i}^N_{i=1} \in \mathbb{R}^{N \times d^{Sig}_v}과 SigLIP text encoder에서 생성된 instruction embedding {l^{Sig}_j}^M{j=1} \in \mathbb{R}^{M \times d^{Sig}_l} 사이에서 이중 pruning을 수행합니다. 두 가지 경로를 통해 작동하는데, Vision-to-Language Mapping은 global action cue(전체적인 액션의 동작 목표)를 위한 것이고, Language-to-Vision Filtering은 local semantic anchor(액션을 수행할 때 보는 구체적인 위치)를 위한 것입니다.
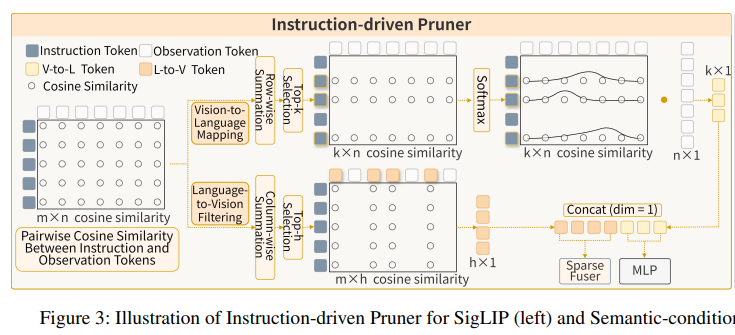
Step 1: Cosine Similarity Matrix 구성
각 instruction token l^{Sig}_j를 변환 행렬 W_l \in \mathbb{R}^{d^{Sig}_v \times d^{Sig}_l}로 visual token 공간에 투영한 뒤 cosine similarity를 계산합니다.
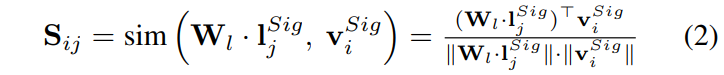
여기서 S \in \mathbb{R}^{N \times M}은 visual-instruction similarity matrix로, 모든 visual patch와 모든 instruction word 간의 세밀한 관련성을 포착합니다.
Step 2: Vision-to-Language Mapping
이 경로는 핵심 instruction token(예: 타겟 명사, 행동 동사)을 식별하고 그에 대응하는 시각적 요소를 찾아내는 역할을 합니다. 각 instruction token l^{Sig}_j의 saliency score s^{VL}_j를 모든 visual token에 대한 similarity를 합산해서 계산합니다.
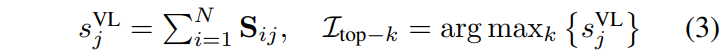
I_{top-k}는 top-k개의 가장 두드러진 instruction token의 인덱스를 나타내며, task의 핵심 요소를 캡처합니다. 선택된 각 instruction token에 대해 softmax-normalized 가중치로 aggregation하여 global cue vector를 형성합니다.
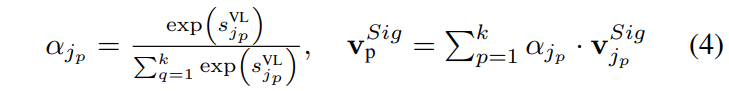
최종적으로 V^{VL} = {v^{Sig}_p | p \in I_{top-k}} \in \mathbb{R}^{k \times d_v}를 instruction-aware global action cue feature로 얻게 됩니다. 쉽게 말하면 목표는 알지만 단계를 모르는 문제를 해결하기 위한 경로입니다.
Step 3: Language-to-Vision Filtering
VL Mapping과 반대 방향으로, 전체 instruction에 대해 가장 관련성이 높은 시각 영역을 보존하는 것이 목적입니다. 각 visual token v^{Sig}_i의 종합 relevance score s^{LV}_i를 모든 instruction token에 대한 similarity 합으로 계산합니다.
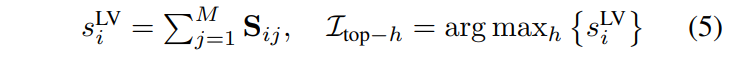
Top-h 개의 visual token을 선택해서 sparse하지만 핵심적인 visual subset V^{LV} = {v_q | q \in I_{top-h}}를 형성합니다. 이 단계는 배경 노이즈와 무관한 방해 요소를 효과적으로 필터링하여 local semantic anchor가 있는 핵심 영역에 초점을 맞춥니다. 볼 수 없으면 할 수 없는? 문제를 해결하기 위한 것이라고 볼 수 있습니다.
Step 4
최종적으로 ID-Pruner의 출력은 두 pruned set의 합집합 V^{VL} \cup V^{LV} \in \mathbb{R}^{(k+h) \times d^{Sig}_v}입니다. 이 dual-path 설계가 global action cue(조작 세부사항 오해 방지)와 local semantic anchor(핵심 영역 누락 방지) 사이의 균형을 맞추면서, 필수적인 vision-language-action 정보를 최대한 보존하는 효율적인 visual compression을 달성합니다.
3.3 SA-Pruner for DINOv2
SigLIP 기반의 ID-Pruner와 병렬로, DINOv2 기반 SA-Pruner가 동작합니다. SA-Pruner의 역할은 observation token V^{Din} \in \mathbb{R}^{N \times d^{Din}_v}으로부터 dense spatial representation을 뽑아내는 것입니다.
여기서 DINOv2를 사용하는 이유는 DINOv2는 self-supervised 방식으로 학습된 모델이라서 라벨 없이도 이미지 내의 공간적 구조나 기하학적 디테일을 잘 잡아냅니다. 앞서 ID-Pruner가 SigLIP을 통해 instruction과 관련된 핵심 객체가 뭔지를 sparse하게 뽑아냈다면, SA-Pruner는 DINOv2를 통해 장면 전체의 공간 배치와 기하학 정보를 dense하게 보완해주는 역할을 한다고 보면 됩니다. 즉, 두 pruner가 서로 다른 관점에서 상호 보완적으로 동작하는 구조입니다.
구체적인 동작 방식을 보면, 먼저 spatial aggregation을 위해 zero-initialized aggregation token V^{Agg} \in \mathbb{R}^{(N/8) \times d^{Din}_v}을 V^{Din}에 append합니다. 이 aggregation token은 처음에는 0으로 초기화되어 있고, self-attention을 거치면서 주변 observation token들의 공간 정보를 aggregation하는 역할을 합니다. 토큰 수가 N/8이니까 원래의 1/8 크기로 정보를 압축하는 정도라고 합니다.
그런데 DINOv2의 spatial feature만으로는 지금 어떤 task를 수행해야 하는지에 대한 정보가 부족합니다. 그래서 FiLM(Feature-wise Linear Modulation) layer를 통해 instruction 정보를 경량으로 주입합니다. pooled instruction representation \bar{\ell}^{Din}으로부터 scale parameter \gamma와 shift parameter \beta를 생성하는데,
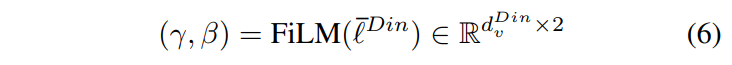
이 파라미터를 concatenated V^{Din} \cup V^{Agg}에 적용하면 modulated representation(instruction 정보를 반영해서 조정된 특징)을 얻게 됩니다.
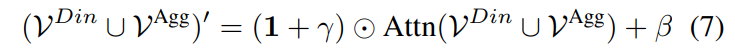
여기서 \odot은 element-wise multiplication입니다. 수식을 풀어서 보면, 먼저 self-attention을 통해 observation token과 aggregation token 간에 정보를 교환한 뒤, (1 + \gamma)로 스케일링하고 \beta를 더해주는 구조입니다. 1 + \gamma 형태를 쓰는 이유는 \gamma가 0에 가까울 때 원래 feature를 거의 그대로 유지하면서, task에 따라 필요한 만큼만 조정할 수 있게 하기 위함이라고 합니다.
결과적으로 이 과정을 거치면 aggregation token V^{Agg}에는 instruction과 관련된 공간 정보가 압축되어 담기게 되고, 이 출력이 ID-Pruner의 출력과 구조적으로 정렬되어 있어서 이후 SH-Fuser에서의 cross-modal fusion이 자연스럽게 이루어질 수 있습니다.
3.4 SH-Fuser cross SigLIP & DINOv2
앞서 ID-Pruner는 SigLIP에서 instruction과 관련된 sparse semantic feature를, SA-Pruner는 DINOv2에서 공간 구조가 풍부한 dense geometric feature를 각각 추출했습니다. SH-Fuser는 이 두 가지를 합치는 모듈인데, 단순히 마지막에 concatenation하는 것이 아니라 인코딩 과정 전반에 걸쳐서 계층적으로 통합한다는 점이 핵심입니다.
SH-Fuser는 Dense-Fuser와 Sparse-Fuser 두 부분으로 나뉩니다.
Dense-Fuser부터 보면, SigLIP과 DINOv2의 Transformer block 사이사이에 삽입되어 동작합니다. 예를 들어 shallow layer, intermediate layer, deep layer 등 여러 깊이에서 한 번씩 fusion을 수행하는 식입니다.
이렇게 하는 이유는, Transformer의 각 depth마다 추출하는 feature의 수준이 다르기 때문에, 각 단계마다 SigLIP의 semantic cue와 DINOv2의 spatial-geometric prior를 교환해주면 두 encoder가 서로의 장점을 단계별로 흡수할 수 있다고 합니다. 즉 최종 결과물만 합치는 게 아니라, 인코딩하는 중간중간에 계속 정보를 주고받는 구조입니다. (이 부분이 단순 late fusion 대비 얼마나 차이가 나는지는 ablation에서 확인할 수 있습니다)
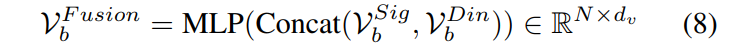
해당 depth에서 SigLIP의 patch feature V^{Sig}_b와 DINOv2의 patch feature V^{Din}_b를 concat한 뒤 MLP를 통과시켜 하나의 fused representation으로 만드는 구조입니다. 이렇게 만들어진 fused feature가 다시 각 encoder의 다음 block으로 전달되면서 점점 더 상호 보완적인 표현이 만들어지게 됩니다.
Sparse-Fuser는 인코딩이 끝난 최종 단계에서 동작합니다. ID-Pruner가 뽑아낸 local semantic anchor token V^{LV}와 SA-Pruner가 뽑아낸 aggregation token V^{Agg}를 병합하여 최종적인 compact representation을 형성합니다.
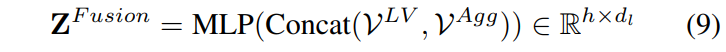
정리하면, Dense-Fuser는 인코딩 과정 중간중간에 두 encoder의 dense patch-level 정보를 교환하는 역할이고, Sparse-Fuser는 최종적으로 pruning된 핵심 token들만 모아서 LLM에 넣을 compact representation을 만드는 역할입니다. 이 두 단계의 fusion을 통해 visual token을 8~16배 줄이면서도 semantic grounding(instruction과의 의미 연결)과 geometric precision(공간 구조의 정확성)을 모두 유지할 수 있다는 것이 SH-Fuser의 장점이라고 볼 수 있습니다.
3.5 Semantic-conditioned Action Coupler
1~3을 거쳐 LLM에 입력되는 visual input은 composite token set Z = Z^{VL} \cup Z^{Fusion}으로 구성됩니다(Z^{VL} = \text{MLP}(V^{VL}) \in \mathbb{R}^{h \times d_l}). 여기까지가 보는 것에 대한 처리였다면, SA-Coupler는 행동하는 것에 대한 처리를 담당합니다.
먼저 기존 VLA의 action 표현 방식을 짚고 넘어가면, OpenVLA 같은 모델에서는 7-DoF action(x, y, z 이동 3개 + 회전 3개 + 그리퍼 1개)을 각각 하나의 DoF마다 독립적인 binned token으로 이산화합니다. 즉 하나의 action step을 표현하는 데 7개의 토큰이 필요한 구조입니다. 이 방식은 각 DoF를 독립적으로 다루다 보니 이동과 회전과 그리퍼 사이의 의미적 관계가 제대로 반영되지 않고, 토큰 수도 많아져서 비효율적입니다.
SemanticVLA에서는 이를 대체하여 SA-Coupler를 도입합니다. 핵심 아이디어는 단순합니다. 7개의 DoF를 개별적으로 토큰화하는 대신, 의미적으로 같은 종류끼리 묶어서 3개의 토큰으로 표현하는 것입니다.
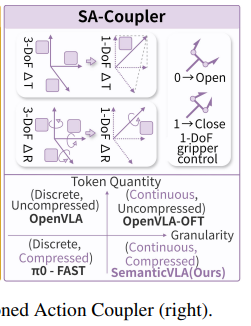
Token-Level Semantic Alignment에서는 세 가지 기본 motion primitive를 각각 하나의 token으로 표현합니다.
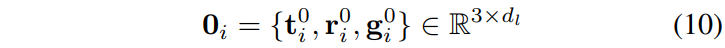
t^0_i는 3-DoF translation(x, y, z 이동)을 하나의 토큰으로, r^0_i는 3-DoF rotation(세 축의 회전)을 하나의 토큰으로, g^0_i는 1-DoF gripper control(열기와 닫기)을 하나의 토큰으로 표현합니다. 이렇게 하면 이동은 이동끼리, 회전은 회전끼리 의미적으로 연관된 DoF들이 하나의 토큰 안에서 함께 모델링되기 때문에 action type 간의 semantic 구분이 자연스럽게 유지된다고 합니다.
Head-Level Modularity for Action Prediction에서는 입력 시퀀스 [Z, q, \ell, 0_0, 0_1, \ldots, 0_{K-1}]를 bidirectional decoding f_{\parallel}(\cdot)에 넣어서 업데이트된 action representation h_i = {t^h_i, r^h_i, g^h_i} \in \mathbb{R}^{3 \times d_l}를 얻습니다. 그 다음 token-to-value 디코딩 시, 하나의 통합 head가 아니라 각 action type에 특화된 세 개의 prediction head(Translation Head, Rotation Head, Gripper Head)가 각각 연속적인 motion parameter를 직접 regress합니다.
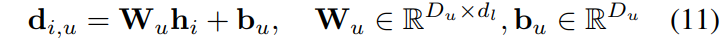
여기서 u \in {\text{trans, rot, grip}}이고, D_u는 해당 action type의 DoF 차원입니다. 예를 들어 translation head는 D_u = 3이므로 x, y, z 세 축의 이동량을 한 번에 출력하고, gripper head는 D_u = 1이므로 열기/닫기 하나만 출력하는 식입니다. 이렇게 head를 분리하면 각 action type의 특성에 맞는 학습이 가능해지고, 해석 가능성도 높아집니다.
정리하면, 기존에 7개의 토큰이 필요했던 action 표현을 3개로 줄이면서도 각 action type의 의미적 구분을 유지하고, 전용 head를 통해 더 정확한 연속값 예측이 가능하다는 것이 SA-Coupler의 핵심입니다. 토큰 수 감소 효과는 action chunk가 커질수록 더 극적이라고 하는데, 예를 들어 ALOHA 셋업처럼 action chunk당 25개 행동을 예측하는 경우를 생각해보면, 기존 방식에서는 25 x 7 = 175개의 action token이 필요했지만 SA-Coupler에서는 25 x 3 = 75개로 줄어들어 inference overhead가 크게 감소합니다.
4. Experiments
4.1 Experiment Settings
모든 실험은 8× A800(80GB) GPU에서 수행되었습니다.
시뮬레이션 평가는 LIBERO 벤치마크에서 수행되며, Spatial, Object, Goal, Long 네 가지 task suite로 구성되어 있고 각각 500개의 human-teleoperated demonstration을 가집니다. Real-world 실험은 AgileX Cobot Magic 플랫폼에서 object placement, drawer manipulation, multi-step deformable task 등을 포함하여 수행되었습니다.
Baseline으로는 LIBERO에서 50개 이상의 SOTA baseline과 비교하고, 효율성 비교는 OpenVLA와 그 가속 변형인 OpenVLA-OFT, PD-VLA와 동일 조건에서 수행됩니다.
4.2 Overall Performance & Efficiency
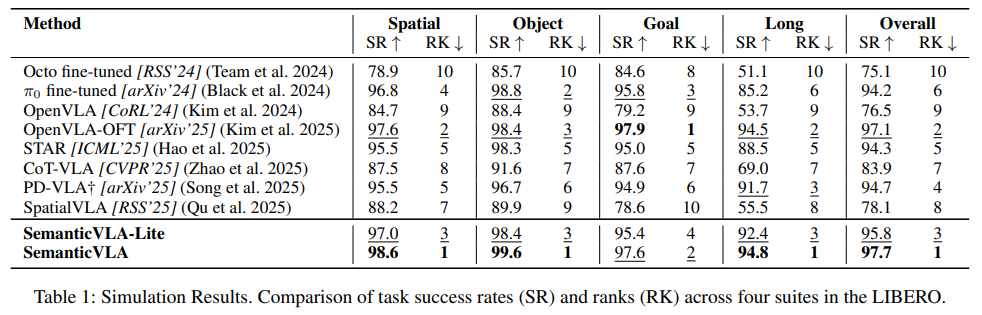
Simulation 결과를 보면, SemanticVLA가 97.7%의 최고 성공률(rank 1)을 달성하며 최근? SOTA 방법들을 일관되게 능가합니다. SemanticVLA-Lite도 95.8%(rank 3)를 달성하면서 복잡도를 줄인 상태에서도 robustness와 scalability를 보여줍니다.
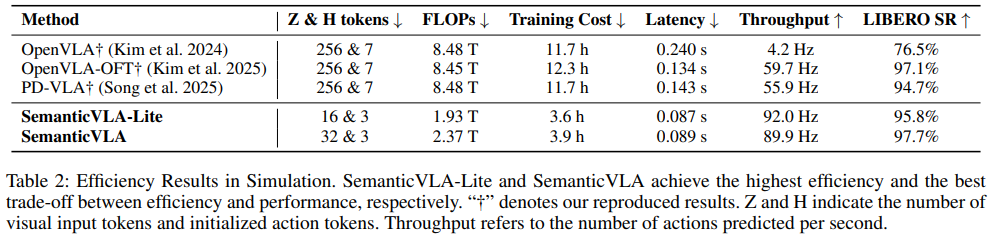
효율성 측면에서, SemanticVLA는 visual input의 1/16 또는 1/8만 사용하고 action representation도 3/7만 사용하면서도 training FLOPs, cost, inference latency, throughput 모든 면에서 OpenVLA 및 기타 효율적 baseline을 크게 능가합니다. 구체적으로 OpenVLA 대비 training cost 3.0배, inference latency 2.7배 감소를 달성했습니다. 이를 본다면 OpenVLA-OFT가 256개의 visual token과 7개의 action token을 사용하는 반면, SemanticVLA는 32개와 3개만으로도 오히려 더 높은 성공률을 보인다는 점입니다. 토큰 수를 이 정도로 줄여도 성능이 유지되거나 오히려 올라간다는 게 pruning 설계가 잘 된 것 같다는 생각이 들었습니다.
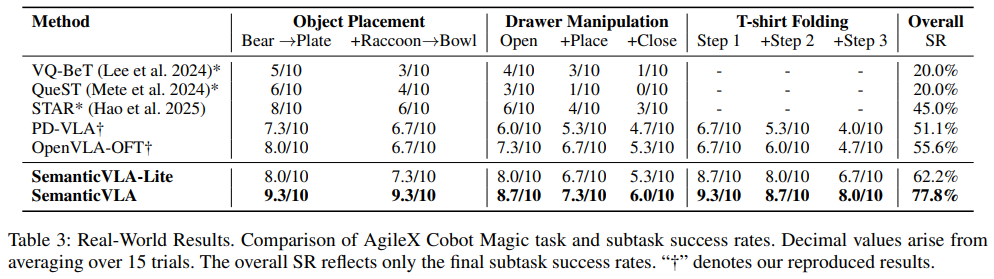
Real-world 결과에서는, SemanticVLA가 세 가지 도전적인 long-horizon task에서 77.8%의 성공률을 달성하여 OpenVLA-OFT 대비 22.2% 향상을 보였습니다. 다만 T-shirt Folding 같은 deformable object task에서는 Step 3까지 갈수록 성공률이 떨어지는 것을 볼 수 있는데, 이런 multi-step task에서의 error accumulation 문제는 아직 완전히 해결되지 않은 것 같습니다.
4.3 Ablation Studies
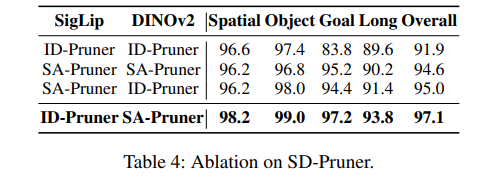
SD-Pruner에 대한 ablation에서는 SigLIP에 ID-Pruner, DINOv2에 SA-Pruner를 조합한 것이 가장 좋은 성능을 보였습니다. SigLIP에 ID-Pruner를 적용하면 language-supervised feature alignment를 통해 instruction-driven token pruning이 가능해져서 semantic density를 극대화하고, DINOv2에 SA-Pruner를 적용하면 token aggregation을 통해 global geometric structure를 보존하면서 FiLM을 통해 경량 semantics를 주입한다고 합니다. 역으로 조합하거나 단일 구성을 사용했을 때보다 2.1%~5.2% 높은 성공률을 보였습니다.
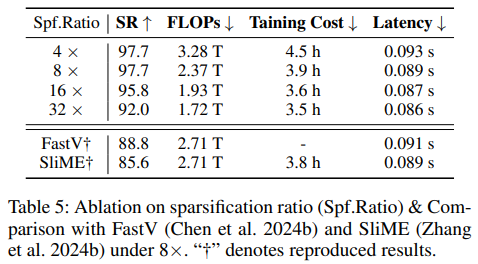
Sparsification ratio에 대한 ablation에서는 R \in {4, 8, 16, 32}를 테스트했을 때 R=8에서 97.7%로 성능과 효율성 사이의 최적 trade-off를 달성했습니다. R=16은 1.9%만 떨어져서 SemanticVLA-Lite로 정의되었고, R=4는 redundancy가 남아 속도 향상이 제한적이며, R=32는 critical semantic context가 손실되어 성능이 저하됩니다. 또한 같은 8배 압축 수준에서 FastV, SliME 같은 plug-and-play sparsification baseline 대비 SemanticVLA가 훨씬 좋은 성능을 보여, instruction-aware pruning과 HF-Fuser를 통한 구조적 보존의 결합이 성능-효율성 모두에서 Pareto-optimal을 달성한다는 것을 보여줍니다.
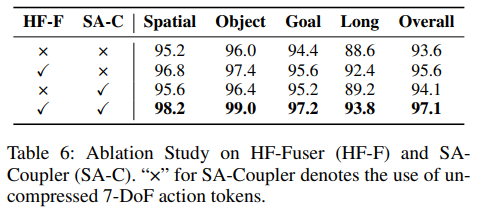
HF-Fuser와 SA-Coupler에 대한 ablation에서는 두 모듈이 모든 task에서 상호 보완적인 개선을 제공하며, 특히 long-horizon task에서 가장 큰 향상을 보였습니다. HF-Fuser는 두 visual encoder의 fine-grained observation token을 계층적으로 통합해서 성공률을 개선하고, SA-Coupler는 redundant action token을 제거하고 action space에서의 overfitting을 줄여줍니다. 두 모듈이 서로 다른 token granularity에서 작동하면서 cross-modal alignment을 강화하여 단순 합산 이상의 시너지 효과를 낸다고 합니다.
4.4 Qualitative Analysis

시각화 결과를 보면 세 가지 long-horizon real-world task에서 모델이 instruction에 정렬된 action sequence를 최소한의 편차로 일관되게 생성하는 것을 확인할 수 있습니다.

위 사진에서는 ID-Pruner가 SigLIP에서 global action cue와 local semantic anchor 모두를 강조하는 반면, SA-Pruner가 DINOv2에서 geometric structure에 집중하는 것을 보여주어, 두 pruner의 semantic과 spatial grounding에서의 상호 보완적 강점을 확인할 수 있습니다. SD-Pruner, HF-Fuser, SA-Coupler의 시너지가 해석 가능한 중간 표현과 신뢰할 수 있는 downstream control을 생성한다는 것을 검증합니다.
5. Conclusion
SemanticVLA는 SD-Pruner를 통한 semantic-guided visual sparsification, SH-Fuser를 통한 cross-encoder semantic-structural fusion, SA-Coupler를 통한 modular action control을 통합하여, SOTA task 성공률을 달성하면서도 연산 비용을 크게 줄인 프레임워크입니다. LIBERO 벤치마크에서 OpenVLA 대비 21.1% 성공률 향상, training cost 3.0배 감소, inference latency 2.7배 감소를 달성했으며, 시뮬레이션과 real-world task 모두에서 robustness, scalability, efficiency를 입증했다고 합니다.
해당 논문을 보면서 느낀 부분은 제가 최근까지 보던 그냥 VLM에서 나온 토큰을 action head에 넣는 방식과는 좀 다르다고 느껴졌습니다. VLA라는 것 자체가 VLM이 수행하는 동작과는 다르게 현실 세계에서 어떻게 동작을 해야 하는가에 대한 문제인데, 이런 점에서 VLM이 학습한 것 자체로는 목표를 이해해서 Action Head가 받아들이기 힘든 정보로 제공될 수도 있다고 느꼈습니다. 그리고 로봇의 동작에서도 회전과 이동, 그리퍼를 별개로 분류한 부분을 보고 제가 쓰는 xlerobot 같은 경우에는 14개의 관절에 대한 정보를 그냥 토큰으로 넣어버리는데 이런 방식으로 접근하면 사람이 직접 뭔가 매핑을 해주어야 할 것 같지만 학습에서 동작에 대한 신경망의 이해는 잘 될 것이라고 생각되었습니다. 다만 실험 부분에서 잡아서 이동하는 동작에 대해서만 설명한 것 같아서 단순히 물건을 잘 잡아서 이동하기 위한 것이 목표인 VLA인가? 라는 생각이 들기도 하여서 이 부분은 좀 추가적으로 보아야 되겠다고 느꼈습니다.

리뷰 읽어주셔서 감사합니다~!
안녕하세요 기현님!
리뷰하신 VLA 논문은 VLA 구조에서 VLM 부분을 다룬 느낌으로 받아들여졌습니다. 최근 VLA 연구를 보면 어떤 연구는 VLM scaling을 통해서 성능을 올리는 듯한 모습을 보이며, 다른 연구는 action expert scaling을 통해서 성능을 올리는 듯한 모습을 보이는 것 같습니다. curriculum learning을 사용해서 학습 방법을 제시하는 논문도 있지만요.
그런 측면에서 이 VLA 연구는 어떤 철학과 방향을 가지고 하는 연구인지 풀어서 설명해주실 수 있나요?
감사합니다!
안녕하세요 인하님. 답글 감사합니다.
해당 연구는 기존의 VLA에 초점을 맞춘게 아니라 카메라로 보이는 공간과 문자가 가지는 의미를 서로 잘 임베딩해서 이를 로봇의 움직임과 임베딩한다고 보면 편하실 것 같습니다.
그래서 기존 VLA 연구와는 달리 clip?처럼 공간에 대한 이해를 vision과 문장만으로 잘 맞춘다 라는 느낌으로 보시면 될 것 같습니다.
좋은 질문 감사합니다!
안녕하세요 기현님 좋은 리뷰 감사합니다.
리뷰에서 instruction-aware pruning으로 불필요한 토큰을 제거한다고 이해했는데 long-horizon manipulation에서는 초반에는 중요해 보이지 않던 물체나 공간 정보가 뒤 단계에서 갑자기 중요해질 수도 있을 것 같다는 생각이 들었습니다. 이런 경우 ID-Pruner가 초기에 그런 토큰을 많이 제거해버리면 뒤 단계에서 중요한 토큰이 버려지면 long horizon 태스크 수행이 힘들 수 도 있지 않을까 라는 생각이 들었는데 이와 관련된 pruning failure case 분석이 있었는지 궁금합니다.
안녕하세요, 우현님 답글 감사합니다.
실제로 이에 대한 failure case 분석은 보이지 않은 것으로 보고 있습니다.
그리고 제가 논문에서 직접 언급된 내용을 보았는지 아니면 부가적으로 찾아보다가 알게 되었는지 기억은 나지 않지만 long horizon task에 대해서 수행이 힘들 수도 있다고 말하고 있었던 것으로 기억합니다.
이 부분에 대해서는 어떻게 해결될 수 있을지 좀 더 생각해봐야 겠습니다
좋은 질문 감사합니다!