지난번 세미나 때 공유드린 논문인데 좋은 논문이라 x리뷰로도 작성해보고자 합니다.
Intro
해당 논문은 영상 생성 분야에서 좋은 모습을 보여주고 있는 diffusion 방법론들이 대부분 Stable Diffusion 형식의 Variable AutoEncoder (SD-VAE)를 베이스로 설계되었다는 점을 지적합니다.
기본적으로 diffusion 방식으로 영상을 생성하는 방법론은 크게 reconstruction 단계와 diffusion 단계로 구분이 됩니다. reconstruction 단계는 입력 영상을 어떠한 encoder에 태워서 latent를 생성한 뒤, 해당 latent를 다시 decoder에 태우면 원래의 입력 영상으로 만드는 과정입니다.
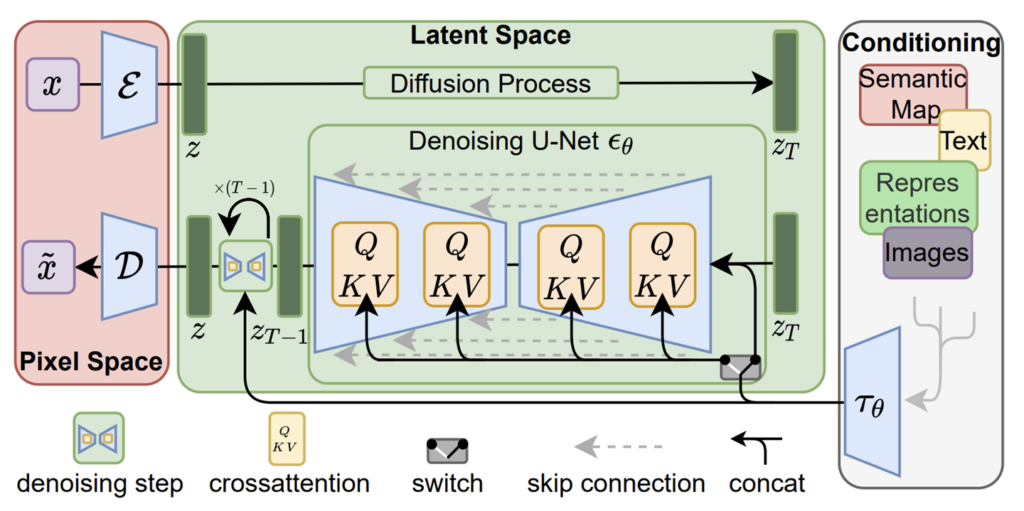
이렇게 encoder와 decoder가 잘 학습이 된다면, 두번째 단계인 diffusion 단계에서는 encoder를 타고 나온 latent에 noise를 넣고, 해당 noise를 diffusion 모델이 denoising하는 것을 학습하게 됩니다. 만약 denoising이 덜 되었다면 해당 latent로 decoder를 태워서 만든 영상의 품질은 좋지 않겠죠. 이렇듯 diffusion model은 encoder의 latent를 GT 삼아 denoising 과정을 학습하는 방식으로 진행이 됩니다.
그런데 기존의 stable diffusion에서 사용하는 VAE의 encoder가 출력으로 하는 latent의 차원은 HxWx4입니다. 즉, latent의 차원이 작아도 너무 작아서 가지고 있는 정보량 과연 있기는 한지에 대한 의문이 듭니다. 물론 이것의 의문을 품은 사람들이 DINOv2나 CLIP같이 저희가 많이 사용하는 고차원 특징을 추출하는 vision encoder를 기반으로 reconstruction을 수행하는 decoder를 만들고자 하였으나 reconstruction의 결과물이 high-level semantic context는 일치하지만 local detail 등이 기존과 달랐다는 문제점들이 발견되었다고 합니다.
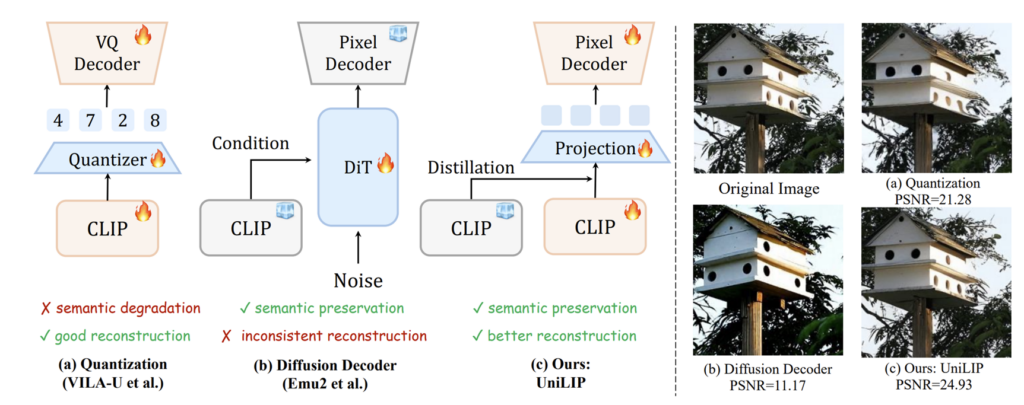
영상 생성을 하는 연구자들은 이러한 경향을 토대로, 영상 생성 관점에서 DINOv2와 같은 semantic encoder보다는 local detail을 잘 볼 수 있는 저차원의 SD-VAE 형식이 더 좋다는 의견이 지배적이었던 것 같습니다. 하지만, 여전히 무거운 encoder를 타고 나온 latent의 값이 고작 4차원 특징이라는 점은 여전히 찜찜함으로 남게되며, 과연 해당 정보가 local detail은 유지할 지 모르겠으나 global context와 semantic 정보들까지 가지고 있을지에 대한 의문이 남게되는 것이죠.
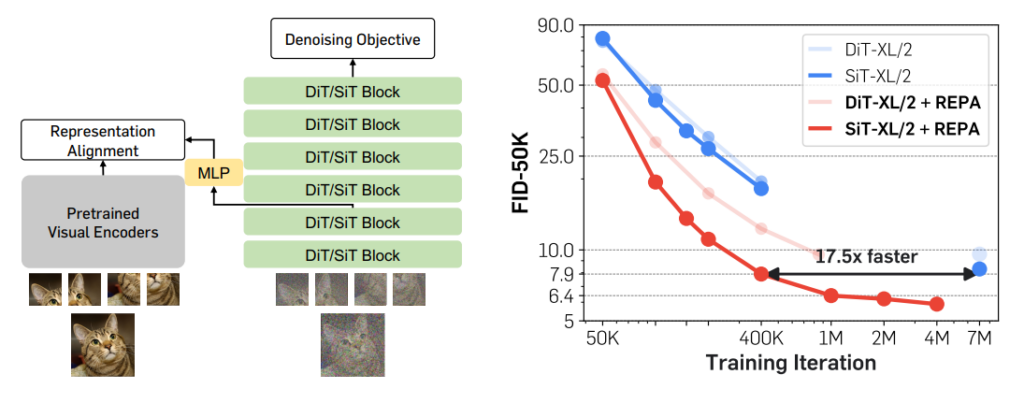
실제로, 기존의 저차원 latent로 학습하는 SD-VAE 구조는 모델을 학습하는데 매우 오랜 시간이 걸리게 됩니다. 위의 그림과 같이 기존의 DiT나 SiT 모델들은 비슷한 영상 생성 품질을 만들기 위해서 7M의 training iteration을 거쳐야만 했던 것이죠. 그런데 단순히 CLIP이나 DINOv2와 같은 semantic encoder에서 추출한 특징을 diffusion model 중간에 feature distillation을 해주는 것만으로 training iteration의 수를 17.5배 더 줄일 수 있다는 연구가 등장합니다.
결국 영상을 생성하는 관점에서 (그리고 디노이징을 하는 관점에서), semantic encoder의 고차원 정보가 분명 모델에게 도움이 된다는 것의 반증이었습니다. 그래서 최근 연구들은 어떻게하면 semantic encoder가 추출하는 latent 정보를 어떻게 활용하면 더 고품질의 영상을 생성할 수 있을까에 집중하는 듯 보입니다.
이러한 맥락에서 제가 이번에 소개드릴 논문도 마찬가지로 DINOv2와 같은 semantic encoder를 잘 활용해서 영상 생성을 잘 해보자에 대한 논문입니다. 하지만 SD-VAE와 semantic encoder를 같이 활용하거나 semantic encoder만을 위해 추가적인 규제화 혹은 학습 단계를 요구하는 기존 연구들과 달리 해당 논문은 사전학습된 semantic encoder의 표현력은 그대로 활용하고 단순히 diffusion과 decoder만 학습시키는, 기존 SD-VAE에서 encoder만 semantic encoder로 바뀐 구조를 제안합니다.
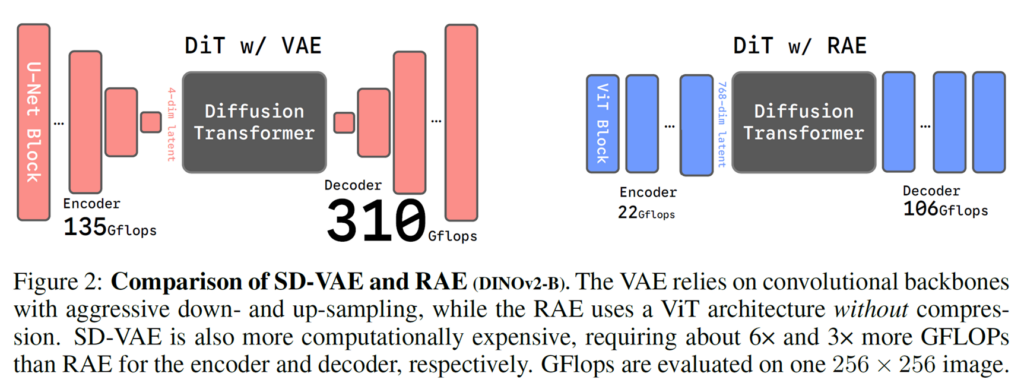
기존의 고차원 latent를 출력하던 semantic encoder를 통해서 그대로 SD-VAE의 framework을 설계하게 되면 reconstruction 또는 denoising 과정에서 문제가 생겨 영상의 퀄리티가 좋지 못하던 문제를 해결하는 것이 본 논문의 주 관심사이며, 다양한 실험과 수학적 증명을 토대로 semantic encoder에 맞추어 디퓨전 프레임워크를 수정해나가 결과적으로 VAE가 아닌 Represenative Autoencoder (RAE)라는 개념을 새롭게 만들어냅니다.
RAE training
아까 diffusion 기반 영상 생성 모델의 학습 과정은 크게 2가지라고 했습니다. latent를 생성하는 encoder와 해당 latent로 원래 영상으로 복원을 시켜주는 decoder를 학습해야합니다. 저자들의 RAE는 DINOv2와 같은 semantic encoder를 사용하기 때문에 encoder는 따로 학습할 필요 없이 사전학습된 모델을 그대로 사용합니다. 단지 semantic encoder의 latent를 가지고 decoder가 다시 원본 영상으로 만드는 reconstruction 과정만 학습시켜주면 됩니다. 논문의 notation과 학습 과정에 대한 정리는 아래와 같습니다.



학습에 사용한 loss는 위와 같은데 LPIPS는 영상 품질을 책정하는 모델 기반 유사도 측정 방식이며, L1은 단순히 픽셀 오차, GAN은 실제 영상인지 가짜 영상인지 구분하는 목적 함수입니다.
저자들은 semantic encoder의 예시로 DINOv2, CLIP, MAE를 활용했다고 합니다.

표a부터 살펴보면 우선 rFID는 reconstruction에 대한 영상 퀄리티를 나타내는 지표로 값이 낮을수록 좋은 것입니다. DINO, Siglip, MAE와 같은 semantic encoder들 모두 SD-VAE보다 더 좋은 reconstruction 지표를 보여주고 있으며 특히 MAE는 학습 과정 자체가 입력 영상을 마스킹하고 마스킹된 영역을 복원하는 masked autoencoder답게 reconstruction quality가 매우 좋은 것을 볼 수 있습니다. 이러한 reconstruction 능력은 후에 diffusion model이 latent를 denoising한 다음에 decoder에 태워 재구성하는 단계에 필요하기에 중요한 능력이지만, 후에 밝히길 reconstruction을 잘한다고 해서 generation을 잘하는 것은 아니라고 합니다. 즉 MAE가 reconstruction 수치가 가장 좋아도 generation을 가장 잘하는건 아니라고 하네요.
b 테이블은 저자들의 RAE를 구성할 때 만든 transformer decoder의 구조를 나타낸 것인데 당연하게도 모델의 사이즈가 더 무거워질수록 reconstruction 품질이 좋아지지만, 마찬가지로 GFLOPS도 크게 늘어나고 있습니다. 인코더의 사이즈는 DINOv2를 기준으로 진행했으며 인코더가 가장 무겁다고해서 reconstruction 품질이 가장 좋은 것은 아니었다고 합니다. 저자들은 DINOv2 base가 가장 좋은 rFID를 지니고 있어서 DINOv2 base를 기준으로 앞으로의 실험을 진행하게 됩니다.
테이블 d는 각 모델의 latent를 가지고 linear porbing 방식으로 ImageNet에서의 영상 분류 성능을 평가한 것입니다. 여기서 중요한 점은 DINOv2를 포함한 semantic encoder들이 기존 SD-VAE의 encoder보다 훨씬 더 좋은 분류 성능을 보여주고 있다는 점이며, 해당 결과의 의미는 영상을 이해하는 high-level semantic information이 얼만큼 담겨져있는지를 간접적으로 보여주는 것입니다.
Training Diffusion Transformer for RAE
앞에서 semantic encoder를 기반으로 reconstruction을 하는 decoder까지 RAE 프레임워크를 구축했으니, 이제 해당 RAE를 기반으로 diffusion model을 학습시켜야합니다. 저자들은 diffusion model로 Diffusion Transformer (DiT)를 채택했으며, 학습 방식은 영상 생성 도메인에서 보편적으로 활용하는 flow matching loss를 활용했습니다.
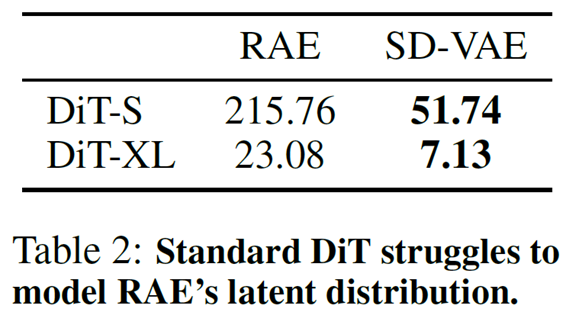
기존의 framework대로 학습을 시킨 뒤 만들어진 영상의 품질을 평가하였는데 그 결과는 처참했습니다. 지금 지표는 gFID로 generation에 대한 FID 품질을 평가한 것인데, RAE의 latent를 기반으로 학습한 DiT가 SD-VAE의 latent로 학습한 것보다 훨씬 더 안좋은 결과를 낸 것이죠. DiT의 사이즈를 매우 크게 하였을 때 gFID가 개선된 것이 확인은 되지만 여전히 SD-VAE와 비교하면 3배 이상의 생성 품질 차이가 발생하였습니다.
저자들은 문제의 원인을 찾고 분석을 하기 위해서 다음과 같은 실험을 구성합니다. 바로 DiT 모델에게 단 한장의 이미지만을 생성할 수 있도록 학습시키는 것이었죠. 해당 실험은 RAE의 latent를 기반으로 기존의 diffusion model이 잘 학습이 된다면 1장의 이미지를 생성하는 것 자체에는 overfitting이 될 수 있을 것이며, 반대로 올바르게 생성하지 못한다면 1장의 이미지 조차 overfitting 하지 못할정도로 학습 과정에서 근본적인 문제가 있다는 것으로 추측할 수 있습니다.
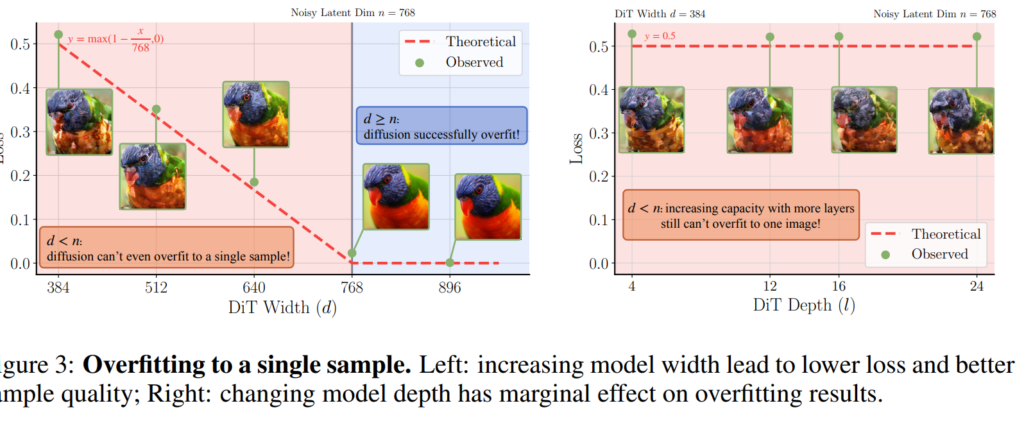
결과가 참 재밌게 나왔는데, diffusion transformer 내부 레이어의 차원 수(width)가 semantic encoder의 output latent의 차원 수보다 작은 상황에서는 loss가 크게 발생했다는 점입니다. 예시로 DINOv2-B 모델의 경우 output latent의 차원 크기가 768인데, DiT의 차원 크기가 384인 경우 loss가 0.5로 나왔으며, 값이 768에 맞추어 커질수록 loss가 점점 더 작게 수렴이 된다는 것이죠. 그리고 768과 같거나 그 이상일 때는 loss가 거의 0에 수렴이 되면서 학습 영상에 완벽히 overfitting이 되던 것입니다.
이게 단순히 layer의 width가 커졌기 때문에 모델의 capacity가 좋아져서 학습이 된 것이 아닌가에 대한 의문을 저자들이 해결하기 위해, DiT 모델의 width가 아닌 layer의 수를 더 늘리는 depth 관련 실험을 진행하였는데, 차원 수를 4개로 하나, 24개로 하나 dimension이 384로 고정되었기 때문에 loss가 0.5 이상으로 나오는 것을 확인할 수 있습니다.
요약하자면, semantic encoder의 latent를 기준으로 diffusion model을 학습시킬 때는 최소 latent의 차원수와 같거나 그 이상의 값을 가져야한다는 것입니다. 그 이유에 대해서 저자들이 설명하길, semantic encoder의 latent는 768차원 내에서 어떠한 mainfold로 잘 구성이 되어있지만약하자면, semantic encoder의 latent를 기준으로 diffusion model을 학습시킬 때는 최소 latent의 차원수와 같거나 그 이상의 값을 가져야한다는 것입니다.
그 이유에 대해서 저자들이 설명하길, semantic encoder의 latent는 가령 768차원 내에서 유의미한 데이터들이 manifold에 잘 구성되어 있을 것인데, diffusion의 과정은 해당 데이터들에 강제로 noise를 주입해서 기존에 구성된 manifold를 흐트려 놓은 상황입니다. 이때 diffusion model은 흐트러진 데이터를 다시 원래의 manifold로 되돌려놓는 작업을 수행해야 하는데, 이때 디노이징을 수행하는 diffusion model의 width가 작아서 해당 latent 공간 축을 다 다루지 못할 경우, 원래의 manifold로 다시 되돌릴 수 없기 때문에 diffusion 모델을 타고 나온 output latent는 여전히 noise가 잔뜩 남아 있다는 것이죠. 결과적으로 noise가 덜 제거된 latent를 decoder에 입력하는 바람에 영상의 퀄리티가 나빠졌다는 의미입니다.
반대로 얘기해서, 기존의 SD-VAE는 encoder가 뱉은 latent의 차원 크기가 고작 4입니다. 그렇기 때문에 DiT 모델에 입력하면서 384, 256 같은 작은 width로도 충분히 denoising이 가능한 것이죠. 즉, 연구자들이 크게 고민 없이 디퓨전 모델을 설계해도 웬만해서는 학습을 오래 시켜 놓으면 denoising이 될 수밖에 없었다는 것입니다.
저자들은 이러한 경험적 증명 말고도 왜 diffusion model의 width가 latent보다 작으면 절대 loss가 0에 수렴할 수 없는지에 대하여 수학적으로 증명을 합니다. 해당 내용은 제가 수학적 지식 선이 짧아 관심있으신 분들은 논문의 아래 내용을 확인해보시면 좋지 않을까 싶습니다 하하^^.. 저 아래 내용의 요약은 결국 loss의 최소 값은 1-d/n이며 여기서 d는 diffusion model의 width, n은 semantic encoder의 차원 길이를 의미합니다.

정리해보면, RAE 방식으로 diffusion model을 학습시키기 위해서는 반드시 diffusion model이 취급하는 차원의 width가 RAE의 latent 차원 길이와 같거나 더 커야한다는 점입니다.
DIMENSION-DEPENDENT NOISE SCHEDULE SHIFT
다음은 모델 학습 단계에서 latent의 dfifusion을 어떻게 제공하면 좋은가에 대한 설명입니다. 해당 내용의 결론부터 말씀드리면, denoising을 해야하는 latent의 차원이 기존 SD-VAE보다 훨씬 더 커졌기 때문에 더 강한 noise를 줘야한다는 점입니다.
이는 예전 diffusion 방법론들이 고해상도 영상에 대하여 denoising을 수행할 때는 저해상도 영상보다 더 강한 수준의 noise가 들어가야한다고 했던 점과 비슷한 맥락입니다.

고해상도일수록 주변에 활용할 수 있는 정보의 양이 더 많아지기 때문에 diffusion model이 참고할 수 있는 정보가 더 많아지므로 denoising 과정이 더 쉬워지게 됩니다. 이러면 학습을 매우 쉽게 할 수는 있지만 사실 학습이 쉽다고 해서 모델이 추론 단계에서 더 좋은 퀄리티의 영상을 생성하는 것은 아닙니다. 실제 추론 단계에서는 noise 100%인 상태에서 모델이 직접 denoising을 해야하기 때문에, 노이즈가 강하게 들어간 latent에 대해 denoising을 잘하는 능력이 diffusion model 입장에서는 더 중요하기 때문이죠.
저자들의 RAE도 마찬가지입니다. latent가 기존 SD-VAE보다 훨씬 더 큰 차원으로 구성이 되어있기 때문에 해상도는 동일하더라도 각 픽셀이 가지고 있는 정보의 양은 큰 차이가 있습니다. 따라서 기존의 SD-VAE 방식의 노이즈를 삽입하는 경우 모델이 denoising을 쉽게 수행할 수 있다는 문제가 발생합니다. 따라서 저자들은 아래와 같이 입력된 차원 n,m의 크기에 따라서 노이즈의 강도를 결정하는 방식을 채택했다고 합니다.
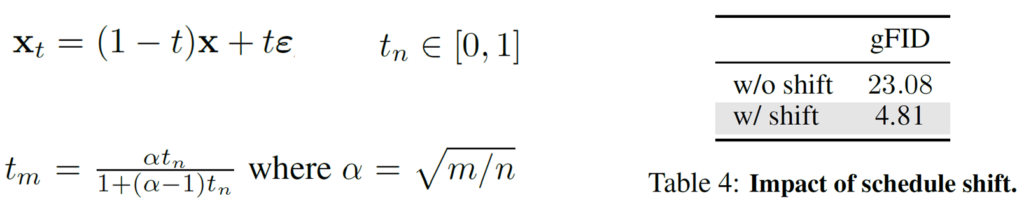
이러한 noise 스케쥴링 역시 모델의 학습에 매우 중요한 역할을 수행했으며 실제로 해당 스케쥴링이 적용되지 않은 경우 gFID가 매우 커진 모습을 확인할 수 있습니다.
NOISE-AUGMENTED DECODING
SD-VAE에서 VAE는 Variable AutoEncoder의 약어입니다. 기존의 AutoEncoder는 입력 영상에 대해서 latent를 추출하고 해당 latent를 다시 decoder에 태워서 reconstruction을 한 결과값 y를 입력 x와 비교하는 방식으로 학습합니다.
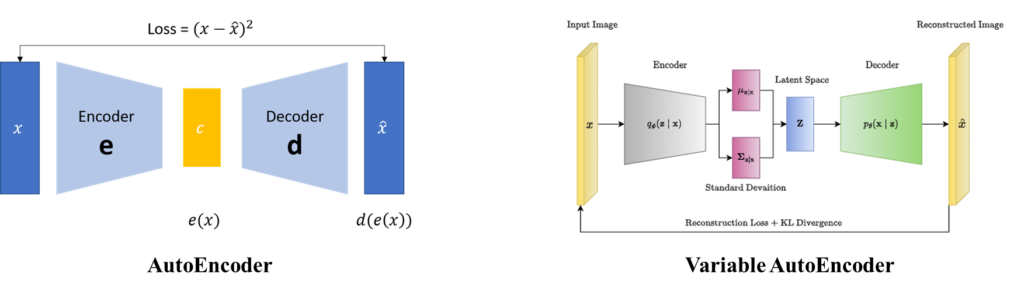
반면에 VAE의 경우에는 입력 x에 대하여 인코더가 평균과 표준편차를 예측하게 됩니다. 그리고 0~1사이의 랜덤한 노이즈를 하나 샘플링해서 encoder가 예측한 평균과 표준 편차를 더하고 곱해줌으로써 latent 하나를 결정하게 됩니다. 이렇게 결정된 latent가 decoder에 입력으로 들어가 y를 만들고 해당 y와 입력 x를 비교하는 방식이죠. 요약하면 AutoEncoder는 1:1 매칭 방식이고, VAE는 입력 데이터의 분포를 예측하는 구조입니다.
저자들의 RAE도 frozen DINOv2 등을 사용하는데 해당 모델은 autoencoder 구조입니다. 즉 DINOv2의 latent에는 어떠한 샘플링이나 분포 개념이 등장하지 않는 autoencoder 구조인 것이죠. 저자들은 이러한 구조가 영상 생성 관점에서 좋지 못하다고 합니다. 실제 영상 생성시에는 DiT가 추론한 denoising latent를 디코더의 입력으로 주어서 영상을 생성하게 되는데, 이때 입력되는 latent가 아무리 디노이징을 잘했다고 할지라도 노이즈가 살짝은 남아있다는 것이죠.
즉, decoder는 학습 단계에서 DINOv2의 깨끗한 latent만 입력으로 받아서 이를 복원하였지만, 실제 생성을 수행하는 추론 단계에서는 살짝은 노이지한 latent로 reconstruction을 수행해야하다보니 생성 퀄리티가 떨어지게 되는 것입니다.
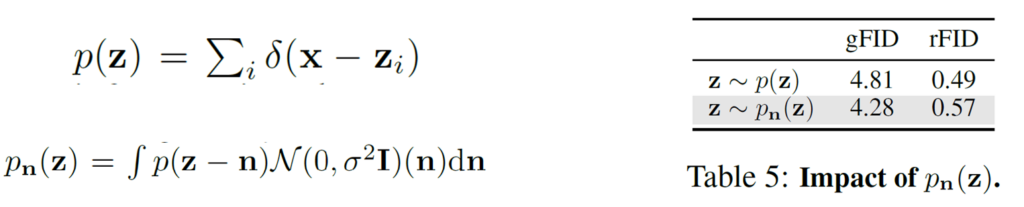
그래서 저자들은 decoder 학습 단계에서 기존 1:1 매칭의 autoencoder 구조가 아닌 DINOv2의 latent에 노이즈를 삽입한 뒤 decoder가 reconstruction하도록 학습 구조를 변경했습니다. latex]p_{n} [/latex]이 바로 노이즈가 삽입된 latent z를 decoder 입력에 사용했다는 것으로 이렇게 노이즈가 삽입되는 경우 reconstruction에 대한 퀄리티는 떨어지게 되었지만 (rFID 값 상승), 영상 생성 품질은 더 좋아진 것을 표5에서 확인할 수 있습니다.(gFID 하락)
Improving the model scalability with Wide diffusion head
다음은 저자들이 DiT 모델 구조의 변형에 대한 실험입니다. 아까 diffusion model의 width가 매우 중요하다라고 설명을 드렸습니다. 모델의 노이지를 효과적으로 제거하기 위해서는 디노이징 단계에서 width의 크기가 충분히 보장되어야한다는 것이죠. 하지만 그렇다고 모델의 width를 너무 무식하게 키워버리면 연산량이 많이 필요한 것도 사실입니다.
그래서 저자들은 아래 그림5와 같이 DiT 블록 뒷편에 DDT head를 추가하는 형식으로 모델의 구조를 바꾸게 됩니다. 이 DiT는 기존의 base DiT처럼 작은 차원으로 이루어져있으며, DDT Head 부분에서 width를 매우 크게 가져가는 것입니다. 즉 노이즈 제거하는 과정을 DDT Head에 다 몰아주겠다는 것이죠.
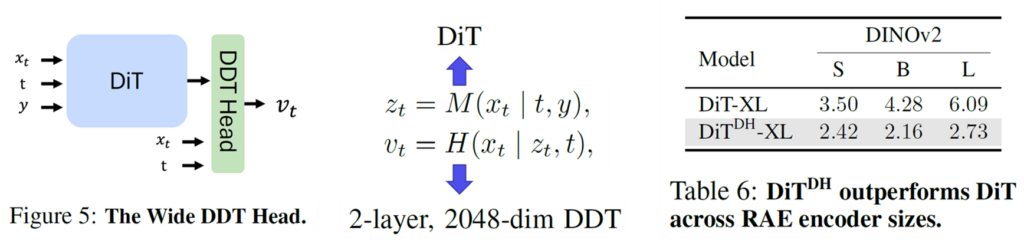
이를 저자들은 DiT^{DH} 구조라고 명시하였는데 해당 구조를 활용하게 될 경우 gFID가 크게 개선되는 것을 표6에서 확인할 수 있습니다.
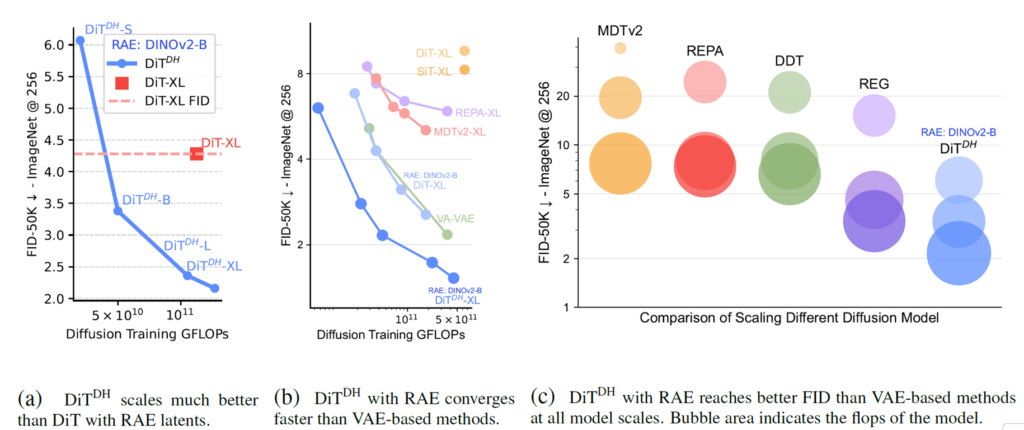
위 그래프 a부분 살펴보시면 같은 DINOv2-B임에도 불구하고 DiT-XL 사이즈보다 더 적은 훈련 GFLOPS로 더 좋은 FID 성능을 보여주는 것을 확인할 수 있으며, 비슷한 크기일 때는 성능의 차이가 80% 이상 나는 것을 볼 수 있습니다.
그래프 b에서는 비슷한 학습 GLFOPS를 지니는 DiT-XL, REPA-XL, VA-VAE 등과 비교해도 DiT-DH가 제일 좋은 gFID를 보여주는 모습입니다.

위에 ablation study는 저자들이 RAE를 위하여 DiT 구조 및 노이즈 스케쥴링 등을 다 적용한 뒤에 대한 ablation study인데, 크게 눈여겨 보실점은 (a) 정도인 것으로 보입니다. DINOv2가 가장 gFID가 좋았으며, 다음으로 siglip2와 MAE 순서였습니다. 아까 Linear Probing 방식으로 ImageNet 성능을 평가하였을 때에도 DINov2가 가장 좋은 분류 성능을 보여주고 그 다음 siglip2, MAE 순서였는데 의미론적인 정보가 좋을수록 저자들의 RAE 프레임워크에서 영상 품질 퀄리티가 더 좋은 것을 확인할 수 있습니다.
또한 MAE는 매우 좋은 rFID 성능을 보여준 것과 비교해서 gFID의 퀄리티가 상대적으로 많이 안좋은 것을 확인할 수 있는데 이를 토대로 reconstruction을 잘한다고 해서 generation을 잘하는 것은 아니구나 라는 교훈?을 얻을 수도 있겠습니다.

이러한 3가지 철칙 아래에서 저자들은 성공적으로 semantic encoder의 high-level semantic information으로 영상 생성하였기 때문에 우측 그래프와 같이 기존의 SD-VAE 방식으로 학습한 SiT보다는 무려 47배, semantic encoder로 feature distillation하여 학습 속도를 대폭 개선시켰다고 알려진 REPA보다도 16배 더 적은 학습 epoch만으로 동일한 gFID를 보여주었습니다.
결론
Diffusion 분야에 대해서 크게 관심을 가지지 않아서 해당 연구자들의 흐름과 철학에 대해 잘 알지 못하였는데 해당 논문을 읽으면서 그들의 background과 철학에 대해 알게 되어서 첫째로 좋았고, 둘째로는 저자들이 문제를 해결해 나가는 과정과 그 사이에 주는 깨달음이 정말 좋았습니다. 특히 문제를 분석하기 위해 이미지 한장에 대해 overfitting을 시키는 실험은 이런식으로도 문제를 분석할 수 있구나 라는 깨달음을 얻게 해줬던 것 같네요.