안녕하세요 최인하입니다. 이번에 리뷰할 논문은 Functional Grasping에 대해서 다룬 논문을 리뷰해보겠습니다. 최근 매스컴에서 로봇을 이야기 할 때 로봇 손은 빠지지 않는 주제입니다. 하지만 아직까지 로봇 손은 관심과는 별개로 그림의 떡인 입장입니다. 5-finger hand는 2지, 3지 그리퍼와 비교해서 자유도도 높아 제어하기 어렵지, 높은 자유도를 커버하기 위해서 많은 모터가 들어가기 때문에 발열도 높지, 그 많은 모터가 들어가야 되기 때문에 모터가 작아지는 만큼 모터의 토크도 줄어들지, 내구성도 약하지 등등 다양한 단점이 존재합니다. 하지만 이러한 단점에도 불구하고 5-finger hand가 사용되는 이유는 Functional한 grasping이 가능하기 때문이라고 생각합니다. 즉 5-finger hand는 사람과 같이 grasping을 수행할 수 있다는 큰 장점이 있습니다. 2지 3지 그리퍼가 사람과 제대로 된 악수를 할 수 있을까요? 아니면 가위질이나 사과 깎기 등을 수행할 수 있을까요? 이처럼 human-centric하게 만들어진 다양한 object를 다룰 수 있는 큰 장점으로 5-finger hand는 가치가 있다고 생각합니다. 서론이 길었는데 시작해보겠습니다.
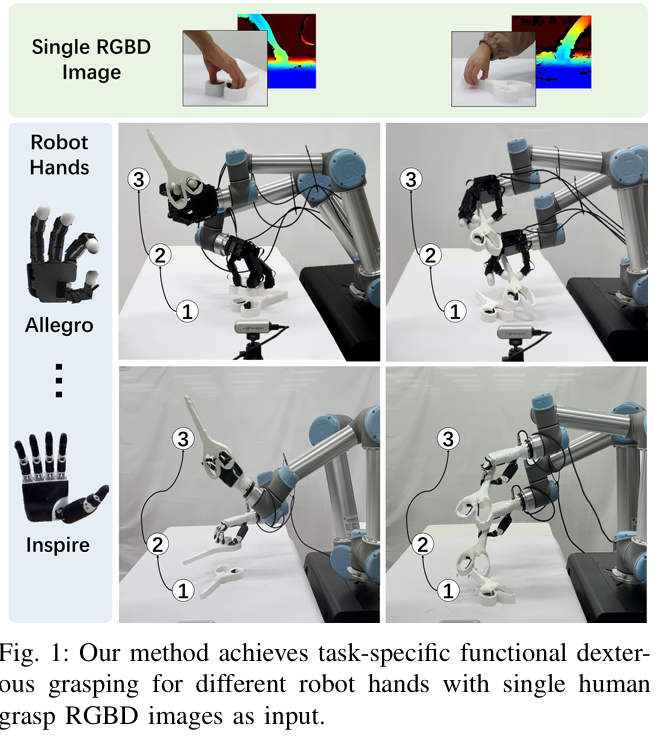
논문의 핵심 철학은 functional grasp 입니다. 더욱 나아가 single RGBD image of a human grasp 하나로 robust한 functional grasp를 수행할 수는 없을까? 입니다. 이 때 unseen object + diverse dexterous hand 까지 커버했다고 하네요.
Introduction
human-like FG(Functional grasping) 위해서는 task-specific human pose가 제공되어야 합니다. 하지만 human hand와 robot hand간 근본적인 morphology gap 때문에 기존 연구들은 단순한 power grasp task로 접근했다고 합니다. 또한 FG를 다양한 object에 적용하기 위해서는 object의 shape과 feature에 대한 부분을 알아야 하지만 기존의 방식들은 category level로 나누어 학습 시켰기 때문에 general한 FG가 안됐다고 합니다. 마지막으로 다양한 크기의 모터, 토크 등등이 sim2real을 방해했다고 합니다. 이러한 다양한 문제를 논문에서는 다음과 같이 풀어냅니다.
- Static Functional Grasp Retargeting: 논문에서는 specific hand morphologies를 요구하지 않는 retargeting module을 제안하다고 합니다. 구체적으로는 object frame을 기준으로 사람 손과 로봇 손의 대응되는 link들의 pose를 맞춰 로봇 손의 초기 pose를 초기화 했다고 합니다. 그 후 FG를 위해서 contact position과 human-like postures를 보존하도록 로봇 손의 pose를 최적화 한다고 합니다. 더불어 collision과 joint constraints, force closure까지 함께 고려한다고 하네요.
- Dynamic Dexterous Grasping: 논문에서는 D-Grasp[CVPR 2022]에서 영감을 받아서 static grasping poses를 reference로 활용하여 diverse dexterous robot hand의 FG를 수행하기 위해서 RL을 사용한다고 합니다. 하나의 policy로 다양한 object shape과 geometry를 다루기 위해서 D-Grasp에서 제시한 visual-tactile perception module을 사용한다고 하네요. 이는 target joint position과 contact points를 포함하는 grasping pose reference가 object의 local shape에 대한 implict prior를 제공한다고 합니다. 또한 robot hand는 proprioception과 실시간 contact states를 사용하는데요. 이는 previleged information 일 수도 있고, proprioception으로 부터 재구성 될 수 있다고 합니다. 이는 암묵적인 정보를 더욱 보완할 수 있다고 합니다.
- Sim-to-real Transfer: 논문에서는 sim2real gap을 해소하기 위해서 여러 방법들을 사용합니다. 구체적으로 previleged learning 방식을 사용하는데 previleged contact information을 이용하여 policy를 학습 시킨 후 real world에서 사용 가능한 정보에 의존하는 policy로 distill 합니다. 또한 joint stiffness와 damping ratio를 optimization함으로써 정확한 액츄에이터의 동역학을 모델링 한다고 하네요. 순서대로 설명하면 sim에서 초기 rough한 파라미터로 대략적으로 grasp policy를 학습하고 이 policy를 하드웨어에 open-loop 방식으로 deploy하여 다양한 action-state trajectory를 수집합니다. 다음으로 수집된 trajectory를 sim에서 적용하고 sim 에서와 real world 하드웨어에서 기록된 state의 차이를 최소화 하도록 파라미터를 최적화 한다고 합니다. 이렇게 최적화된 파라미터로 policy fine-tuning한다고 하네요. 실제 하드웨어의 state와 sim에서의 state 차이를 최소화 하려는 노력으로 보였습니다.
Related Work
related work에 리타게팅에 관련된 내용이 담겨 있어서 간략하게 소개하기 위해서 가져왔습니다. 사람과 같은 dexterity함을 로봇 손에 transfer하기 위해 리타게팅 기법이 사용되는데요. 제가 봤을 때 큰 틀로는 joint-to-joint 리타게팅, vector 기반 리타게팅이 있습니다. 논문에서도 두가지 방법을 언급합니다. joint-to-joint 방식을 사용했을 때는 사람 손의 관절 값을 대응 되는 로봇 관절 값으로 transfer하게 되는데요. 이러한 방식은 인간 손과 로봇 손의 morphology에 대한 gap이 있기 때문에 손 모양은 비슷하게 만들 수는 있어도 contact나 정밀한 조작 같은 일을 처리할 때는 불리합니다. isomorphic한 device를 사용한다면 해결 될 수는 있는 것 같습니다. 또한 vector 방식을 사용할 경우에는 보통 finger tip의 위치 정보를 사용을하게 되는데 이로 인해서 리타게팅 과정을 단순화 할 수 있고 grasp를 안정적으로 수행할 수 있습니다. 하지만 이 방식 또한 singularity 등 다양한 문제가 있을 수 있다고 합니다. 논문에서 사용한 리타게팅 방식은 사람과 유사한 pose와 정확한 contact point를 고려함으로써 효과적으로 로봇 손에 매핑 할 수 있다고 합니다.
Method
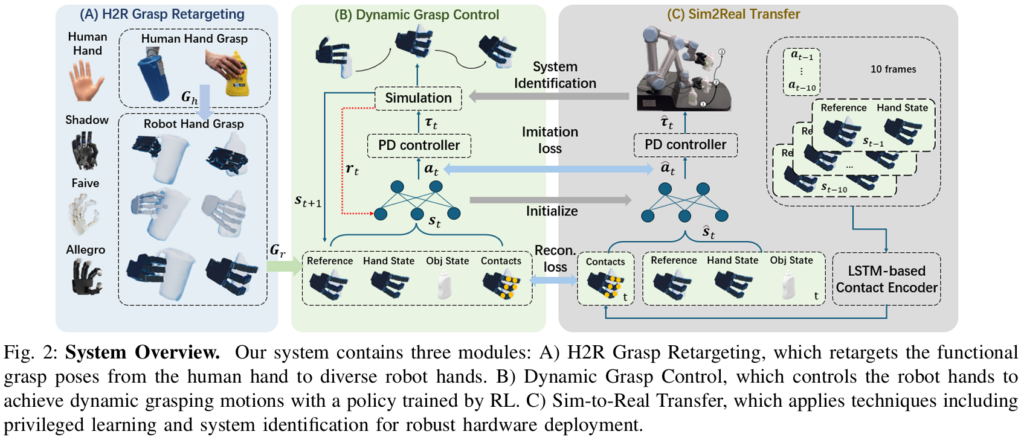
논문에서 소개하는 파이프라인은 크게 3가지의 모듈로 구성됩니다. (A) Human to robot retargeting, (B) Dynamic Grasp Control, (C) sim2real Transfer 이 때 G_h는 static functional human hand grasp reference로 주어지게 됩니다.
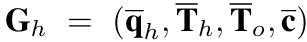
T_h와 T_o는 hand와 object의 6D 정보 q_h는 target finger- joint position, c는 거리 기반의 finger link와 object의 binary contact states information입니다.
(A) H2R Grasp Retargeting
위에서 계속 언급한 것 처럼 사람 손과 로봇 손의 morphology는 다릅니다. 따라서 G_h 는 G_r로 리타게팅 되어야 합니다. 이 부분에서는 G-h를 어떻게 G_r로 리타게팅 할 것인가?에 대해서 설명합니다. 논문에서는 우선 G_h를 object frame 내에서 G_r과 finger tip과 finger link의 방향을 같도록 설정합니다. 이 때 손가락 수가 적거나 link수가 더 적은 로봇은 pinky를 단순히 제거하거나 finger tip과 가까운 관절들을 제거합니다. 그 후 loss function을 사용해서 hand-object interaction을 고려하면서 리타게팅 pose를 optimization합니다. 이 때 사용되는 loss function은 penetration energy loss L_pen, force closure loss L_fc를 사용하여 안정적인 grasp를 보장한다고 하네요. 또한 object와의 contact를 유지하기 위한 다음과 같은 L_pos도 사용한다고 합니다.
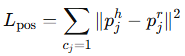
이 때 c_j는 contact한 j번째 관절을 의미합니다. p_h와 p_r은 각각 j번째 human & robot 대응 관절을 의미합니다. 또한 joint angle 을 보장하기 위해서 다음과 같은 loss를 사용합니다.
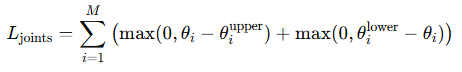
이 때 i는 각각의 관절을 의미합니다.
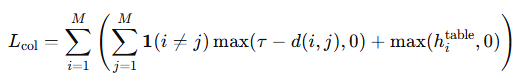
마지막으로 로봇 손의 collision loss입니다. 각각의 손가락이 충돌하는 것과 table과 충돌하는 것을 방지하기 위해 사용됩니다. d(i,j)는 i번째 관절과 j번째 관절 사이의 거리를 의미합니다. tau는 threshold 값입니다. 그리고 h는 i번째 관절과 table 간 distance를 의미합니다.
(B) Dynamic Grasp Control
논문에서는 리타게팅으로 정의된 pose reference G_r에 의해서 유도되는 Dynamic Grasp control을 RL로 정의한다고 합니다.
- Network structure
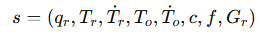
simulation에서 state space는 위와 같이 정의됩니다. robot joint angle q_r, 6D global wrist pose T_r, object 6D pose T_o, wrist와 object의 속도, contact binary states c, contact forces f, reference G_r로 구성됩니다. 그 후 state s를 model learning 관점에서 더욱 효과적으로 사용하기 위해서 feature extraction layer를 사용해서 다음과 같이 변경합니다.
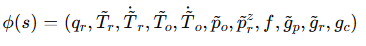
이 때 ~ 표시는 wrist 기준 좌표계로 표현 되었다는 의미입니다. p_o와 p_r은 각각 object의 변위와 wrist와 tabel간의 거리를 나타냅니다. g_p는 각 관절의 현재 위치와 target 위치의 차를 3D로 나타내고, g_r은 현재 wrist rotation과 target rotation의 차이를 의미합니다. g_c는 binary target contacts와 현재 contacts의 차이를 나타냅니다. feature extration layer로 인해서 추출된 위와 같은 feature들을 input으로 하여 policy의 action output a를 출력하는데 이는 다음 프레임에서 예측된 wrist의 6D pose와 finger joint angle이라고 합니다. 그 후 예측된 손목 6D pose를 가지고 IK를 계산하여 팔의 joint angle을 구한다고 합니다. 그 후 로봇의 joint angle 값들은 PD controller에 입력되어 joint torques를 계산하다고 하네요.
- Reward Function
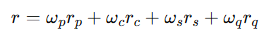
보상은 위와 같습니다. joint postion reward r_p, contact reward r_c, safety reward r_s, pose reward r_q로 구성되어 있습니다. r_p와r r_c reference paper와 같은 식을 썼다고 하길래 D-grasp 논문에서 사용된 reward function을 가져와 보면 다음과 같습니다.
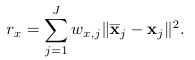
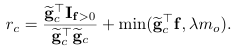
설명해보면 r_p는 쉽게 각 joint position 사이 오차의 L2_norm이고, contact reward r_c의 앞 항은 g_c 즉 실제 object와 접촉한 joint I_f는 GT 값 즉 GT와 비교해서 접촉한 비율을 나타내고, 뒷 항은 접촉한 g_c에서의 force값을 나타내며 너무 커지지 않게 min 값으로 제한합니다. D-grasp 논문에서는 w_p 값으로 1.0 을 사용했습니다. 여기서도 똑같이 사용했습니다. 하지만 논문에서는 w_c 값을 다음과 같이 변경해주었습니다.
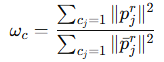
즉 실제 GT와 같이 접촉 한다면 더 큰 보상을 주겠다는 의미인 것 같습니다. safety reward r_s는 다음과 같습니다.
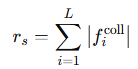
r_s는 패널티 항입니다. 즉 각 관절이 책상이나 서로 부딪힐 경우 패널티를 주는 식으로 설계되었습니다. f는 collision force입니다.
pose reward r_q는 로봇 손이 사람 손과 같은 posture를 취하게 하기 위해서 다음과 같이 설계되었습니다.
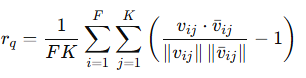
여기서 F는 손가락 개수, K는 손가락 당 링크의 개수를 의미합니다. v는 i번째 손가락의 j번째 링크에 대한 현재 방향과 target 방향을 의미합니다.
(C) Sim-to-Real Transfer
논문에서는 sim2real gap을 줄이기 위해 다양한 방식들을 사용합니다. previleged learning, system identification, domain randomization 등등 차례대로 설명해보겠습니다.
- Previleged learning
위에서 grasping을 진행할 때 contact에 대한 정보와 force에 대한 정보를 사용했는데요. 하지만 실제 hand hardware를 고려했을 때 contact와 force sensor가 없을 경우 이러한 정보를 얻기 힘들겠죠. 이러한 privileged information이 없는 경우에도 robust하게 grasping을 진행하기 위해서 저자들은 privileged learning 방식을 사용합니다. 즉 simulation에서는 contact와 force에 대한 정보를 가지고 학습한 teacher policy를 real 에서 contact와 force에 대한 정보를 모르는 student poolicy에게 distill 합니다. 위의 fig2를 보시면 이해가 빠를 것 같습니다. 논문에서는 RL을 통해서 MLP 기반의 policy(sim)를 학습합니다. 그 후 student policy의 MLP는 teacher의 가중치로 init 됩니다. 근데 real에서는 contact와 force에 대한 정보가 없죠. 따라서 논문에서는 LSTM encoder를 사용해서 contact와 force를 예측합니다. 구체적으로 LSTM 인코더는 과거 10개의 프레임의 state-action pairs를 입력으로 받습니다. 여기에는 관절각, 현재 손목과 target 손목의 6D pose 차이, target contact, action이 포함됩니다. 그 후 인코더는 입력된 정보를 가지고 contact와 force를 예측하게 됩니다. 이 부분이 뭔가 킥인 것 같은 느낌이 듭니다.
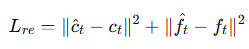
Loss는 위와 같이 주어지고 imitation loss는 다음과 같이 주어집니다.
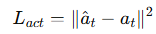
- System Identification
sim2real gap을 줄이기 위해 논문에서는 actuator의 파라미터 joint stiffness와 joint damping을 최적화 함으로써 finger dynamics를 모델링한다고 합니다. 우선 논문에서는 임의의 값으로 파라미터를 정하고 sim에서 pre-training을 수행합니다. 그 후 pre-training된 policy를 real_world에서 open-loop방식으로 deploy 한 후 action trajectory를 수집합니다. 수집한 action trajectory를 바탕으로 sim에서의 파라미터를 최적화합니다. 그 후 최적화된 파라미터를 가지고 training 된 policy를 fine tuning 한다고 하네요.
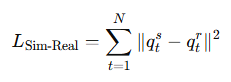
loss function은 위와 같습니다. simulation의 관절 값과 real-world에서의 관절값 간의 차이를 최소화 하도록 파라미터를 최적화 합니다.
또한 domain rendomization 과정에서는 PD gain, friction coefficient, mass, 테이블의 높이 등등의 파라미터를 randomization 한다고 합니다.
Experiments
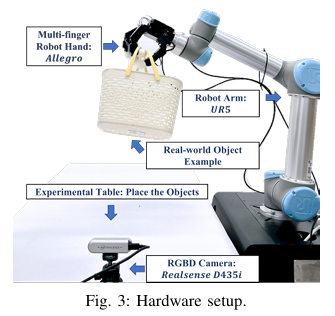
학습 때 사용하는 Hardware setup은 위와 같습니다. sim으로는 RaiSim을 사용하였고, RL은 PPO를 사용했다고 합니다. 학습에는 DexYCB의 오른 데이터가 사용된다고 하네요. object의 6D pose와 속도를 추정하기 위해서 FoundationPose를 사용한다고 합니다. 또한 추정된 pose의 jitter를 줄이기 위해서 low pass filter도 적용한다고 합니다.
논문에서 제시하는 평가지표는 다음과 같습니다.
- Grasping SR: object를 0.1m 이상 들어올리거나 3초 동안 떨어뜨리지 않으면 성공
- Simulated Distance: D-grasp 논문과 유사하게 object를 mm 단위로 매 초마다 평가한다고 합니다. D-grasp가 계속 언급되는데 이 논문을 정확히 이해하기 위해서 꼭 읽어봐야 될 것 같습니다.
- Contact Ratio: 말 그대로 sim에서 성공한 contact와 target contact 간의 비율입니다.

처음으로는 Unseen object에 대한 성능을 보여줍니다. 이 때 논문에서는 unseen object의 mesh는 3D 스캐너를 사용하여 얻고, 각 object에 대해서 서로 다른 grasp pose RGBD image 3장을 촬영한다고 합니다. 결과적으로 unseen object에 대해서도 74 % 의 성능을 보인다고 합니다.

위의 사진은 unseen object에 functional grasping을 수행한 RGBD image라고 합니다.
또한 논문은 다양한 robot hand의 일반화 성능이라며 다음과 같은 표를 소개합니다.
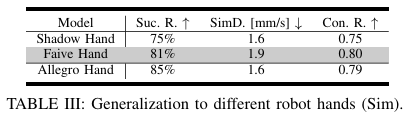
저는 사실 다양한 핸드에 대한 일반화 능력이라고 하길래 하나의 핸드 모델로만 학습된 policy가 다양한 핸드에 적용 될 수 있으려나? 생각하고 있었는데 그런건 아니었던 것 같습니다. 논문에서는 hand 모델에 맞게 각각의 policy를 학습시키고 성능을 비교한 결과 비슷하면서 높은 성공률이 나온 것을 보고 일반화 능력이라고 표현한 것 같습니다.
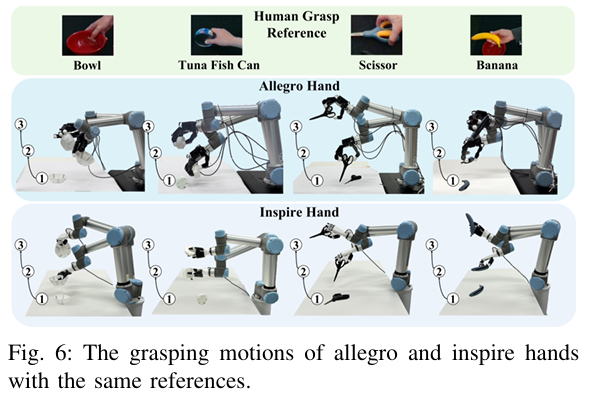
그림에서 보는 것과 같이 다양한 하드웨어에 일관적으로 작동하는 것을 볼 수 있습니다. 또한 table에 놓여있는 납작한 물체는 table 과의 충돌 때문에 grasp가 어려운데 이러한 동작도 잘 수행하는 것을 보아서 논문에서 제시한 시스템이 효과적임을 보여준다고 합니다.
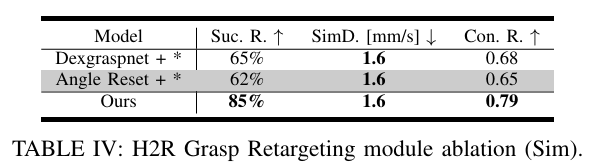
논문은 또한 논문에서 제시하는 retargeting module의 성능을 보여주기 위해서 기존 방식들과의 비교 평가를 진행하였는데요. Dexgraspnet과 Angle Reset(그냥 인간의 관절 각도와 단순히 일치시킴) Dexgraspnet 같은 경우 contact rich하고 power grasping pose만 고려하기 때문에 정교한 조작이 어려웠다고 하며, Angle reset 같은 경우 contact state에 대한 고려가 없어서 부정확한 grasping을 초래했다고 합니다.
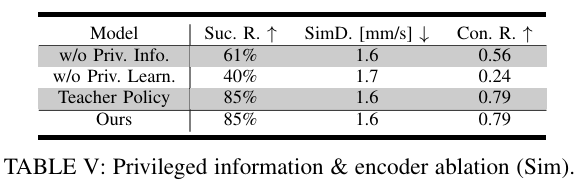
논문에서는 ablation study도 진행하였습니다. 처음부터 contact, force 정보가 없이 학습된 policy, privileged learning 방식이 아닌 처음부터 scratch로 학습된 student policy, teacher policy 그 후 논문에서 소개한 policy를 평가 하였는데요. 이를 통해 contact 와 force가 중요하게 작용한다는 것과, teacher policy의 distill이 중요하다는 것을 보여줍니다.
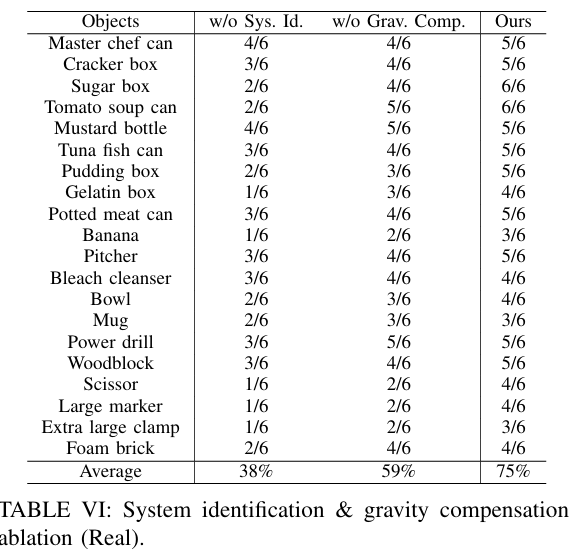
마지막으로는 system indentification 을 없애고 수행한 결과 성공률이 많이 떨어진다는 것을 보여줍니다. 액츄에이터의 정확한 파라미터가 policy의 성능에 큰 영향을 미치는 것 같습니다. 이 정도의 gap차이가 있다는 것에 깜짝 놀랐습니다. 아마 정교한 manipulation 작업이어서 더 크게 체감이 되는 것 같습니다.
읽어주셔서 감사합니다.
안녕하세요, 인하님. 좋은 리뷰 감사합니다.
최근 손 관련 주제를 자주 다뤄주셔서 저도 많이 배우고 있습니다.
조금 별개의 질문일 수도 있는데, Allegro hand는 손가락이 4개인 것으로 보여서요. 혹시 5손가락 핸드에 비해 이런 형태가 학습이나 제어 측면에서 조금 더 수렴시키기 쉬운 편인지 궁금합니다.
그리고 예시로 나온 가위 작업을 보면서 든 생각인데, 해당 task가 Allegro hand의 형태에 어느 정도 맞춰진 설정인지도 궁금했습니다. 만약 그렇다면, 실제로는 손가락 수 자체보다도 로봇 손의 섬세함이나 task와의 형태적 적합성이 성능에 더 크게 작용하는 것인지 여쭤보고 싶습니다.
리뷰 감사합니다.