안녕하세요. 이번에 소개할 논문은 VLM의 fine-grained visual reasoning failure 분석에 관한 논문입니다. VLM이 광범위한 멀티모달 태스크에서는 좋은 성능을 보이고 있지만, 종종 fine-grained한 reasoning을 필요로하는 태스크에서는 제대로된 추론을 못하는 경우가 많습니다. 저자는 이 원인을 분석하여 무엇이 문제인지를 분석하여 제시합니다. 그럼 자세한 원인과 분석은 리뷰를 통해 자세히 말씀드리겠습니다.
1. Introduction
Vision-language model(VLM)은 최근 visual question answering, image captioning, document understanding, visual grounding까지 다양한 멀티모달 태스크에서 좋은 성능을 보여주고 있습니다. 대규모 image-text pair로 사전학습한 뒤, 잘 정제된 instruction-following 데이터로 추가 학습하는 현재의 파이프라인은 마치 이런 모델들이 새로운 멀티모달 문제도 범용적으로 잘 풀 수 있을 것이라는 기대를 줍니다.
그런데 저자들은 이 기대가 완전히 실현되지는 않았다고 지적합니다. 특히 VLM은 fine-grained visual perception이 필요한 문제에서 계속 한계를 드러낸다는 것입니다. 예를 들어 차트나 다이어그램 이해, optical illusion 해석, 추상적 시각 추론, 심지어는 기본적인 시각적 구분 과제에서도 성능이 무너지는 사례들이 보고되고 있습니다. 이런 실패는 특정 도메인이나 특정 모델 하나의 문제가 아니라, 모델이 단순한 패턴 매칭이 아니라 정말로 픽셀 수준의 시각적 비교와 추론을 해야 하는 상황에서 반복적으로 나타난다고 설명합니다.
물론 이런 문제들은 task-specific supervision을 추가하면 어느 정도 완화되기도 합니다. 하지만 저자들이 보기에 더 중요한 질문은 따로 있습니다.
애초에 왜 웹 규모 데이터로 사전학습된 VLM이 이런 문제를 일반화하지 못하느냐는 것입니다. 저자들은 그 원인이 단순히 데이터 부족이나 특정 벤치마크의 난이도 때문이 아니라, 현재의 standard pretraining + SFT 파이프라인 자체에 있다고 주장합니다. 즉, 이 학습 방식이 모델로 하여금 transferable한 visual skill을 배우게 하기보다, semantic shortcut에 의존하도록 만든다는 것입니다.
최근 연구에서는 VLM의 내부 표현을 probing해보면, 모델의 최종 verbal output은 실패하더라도 내부 representation에는 이미 문제를 풀 수 있을 만큼 충분한 시각 정보가 남아 있음을 보여주었습니다. 이를 “hidden-in-plain-sight” gap이라 부릅니다. 즉, 안에는 정보가 있는데 겉으로 답을 못 꺼내는 상황입니다. 기존 연구들은 이를 주로 language model backbone의 한계로 해석했지만, 왜 이런 현상이 생기는지 그 근본 메커니즘까지는 충분히 설명하지 못했습니다. 동시에 다른 연구들에서는 VLM이 language prior에 과도하게 의존한다는 점도 지적되어 왔습니다. 결국 시각 문제를 푸는 척하면서도, 실제로는 언어적 편향이나 LM이 이미 익숙한 의미 공간에 기대고 있다는 이야기입니다.
이 논문은 바로 이 두 관찰을 하나로 연결해 설명하려고 합니다. 저자들의 핵심 가설은 다음과 같습니다.
VLM은 가능할 때마다 시각적 추론을 직접 수행하는 대신, 시각적 대상을 언어 공간 안의 이산적인 semantic label로 사상한 뒤 문제를 풀어버리는 shortcut을 택한다는 것입니다. 예를 들어 어떤 시각적 대상이 명확하게 이름 붙일 수 있는 것이라면, 모델은 더 이상 픽셀 단위 비교를 하지 않고 그것을 언어 토큰 수준의 문제로 바꿔서 처리합니다. 반대로 명확한 이름이 없는 대상이 주어지더라도, 모델은 여전히 비슷한 전략을 쓰려 하며 이 과정에서 어설프고 종종 hallucinated된 설명을 만들어냅니다. 저자들은 이것이 바로 hidden-in-plain-sight gap이 생기는 이유이자, 왜 모델의 실패가 유독 새롭거나, 의미적으로 잘 정리되지 않거나, 이름 붙이기 어려운 시각적 대상 주변에서 집중적으로 발생하는지를 설명해준다고 봅니다.
이 가설을 검증하기 위해 저자들은 visual correspondence task를 사용합니다. 이 태스크는 두 이미지 사이에서 서로 대응되는 개체를 찾아야 하는 문제로, 의료 영상의 감별 진단부터 비디오의 시간적 변화 탐지까지 다양한 실제 응용과도 연결됩니다. 무엇보다 correspondence task는 이 논문의 가설을 시험하기에 적절한 설정입니다. 왜냐하면 대응시켜야 할 시각적 대상 중에는 이름을 붙이기 쉬운 것도 있고, 그렇지 않은 것도 자연스럽게 섞여 있기 때문입니다.
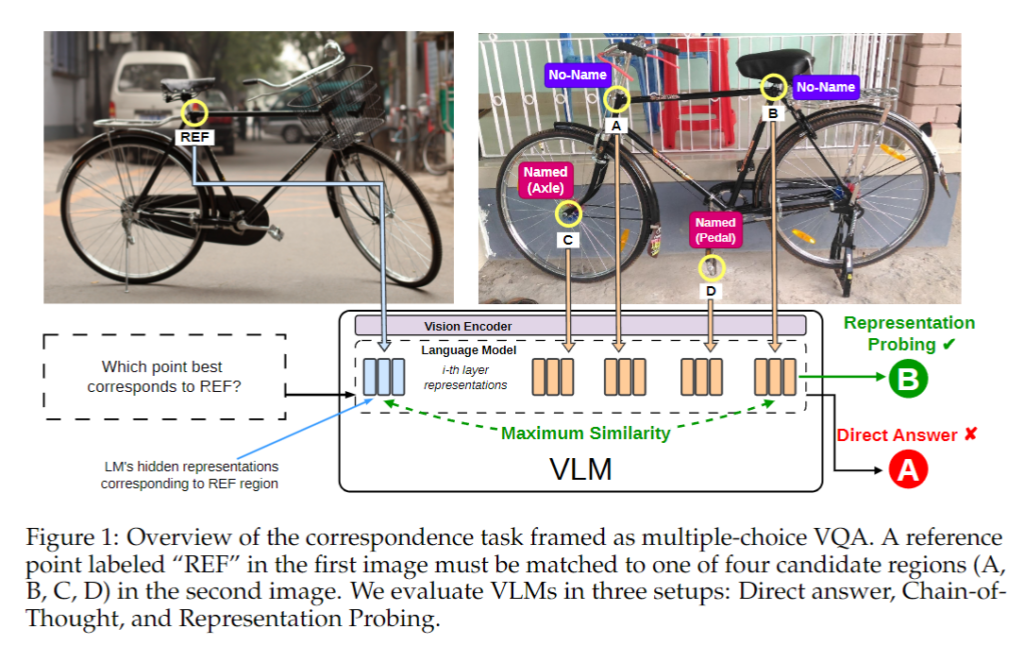
예를 들어 그림 1에서처럼 자전거의 pedal처럼 잘 알려진 이름이 있는 부위도 있지만, head tube와 top tube가 만나는 지점처럼 분명 눈에는 보이지만 명확한 단어로 지칭하기 어려운 부분도 있습니다.
저자들은 이 대비를 더 분명하게 만들기 위해 세 가지 설정을 사용합니다.
첫째는 객체의 의미적 파트들, 둘째는 star나 circle처럼 익숙한 도형과 절차적으로 생성된 낯선 도형의 대응, 셋째는 잘 알려진 celebrity face와 AI로 생성된 무명의 얼굴을 비교하는 설정입니다. 즉, 공통적으로 “이 대상은 이름이 있는가?”라는 축을 중심에 두고 실험을 설계했습니다.
실험 결과는 세 설정 모두에서 매우 일관되게 나타납니다.
VLM은 내부 representation만 놓고 보면 알려진 대상이든 낯선 대상이든 문제를 풀기에 충분한 정보를 가지고 있음에도 불구하고, 실제 정답 성능은 이름 붙일 수 있는 대상에서 훨씬 높고, 이름 붙이기 어려운 대상에서는 크게 낮아집니다. 이 결과는 단순히 representation의 품질 차이만으로는 설명되지 않습니다. 즉, 모델 안에 정보가 없어서가 아니라, 그 정보를 끌어내는 방식이 semantic label의 존재 여부에 크게 좌우된다는 뜻입니다.
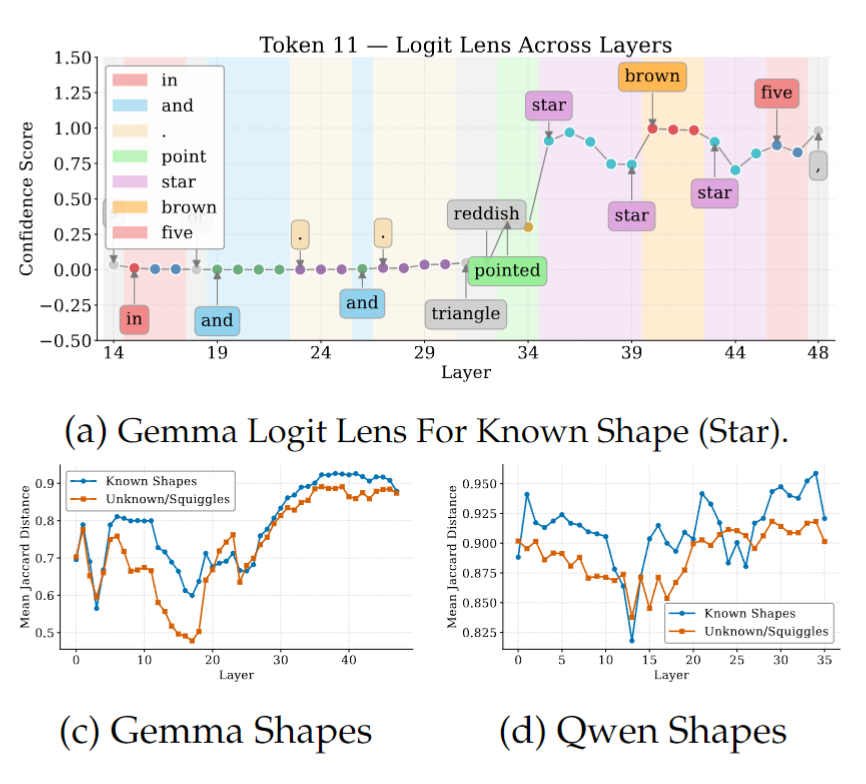
흥미로운 점은 chain-of-thought reasoning도 이런 경향을 더 강화한다는 것입니다. CoT는 이름이 있는 대상에서 훨씬 더 큰 도움이 되는데, 이는 모델이 verbal reasoning을 통해 해당 대상을 점점 더 명확한 discrete label로 복원한 뒤 그것을 기준으로 matching을 수행하고 있음을 보여줍니다. 저자들은 이를 Logit Lens 분석으로도 보여줍니다. 알려진 대상의 경우, hidden state는 초기에는 시각 입력과 무관한 토큰에 가깝게 나타나지만, 층이 깊어질수록 점차 대상의 특징을 근사적으로 설명하는 표현으로 이동하고, 최종적으로는 정확한 semantic label에 수렴합니다. 예를 들어 처음에는 “triangle”처럼 부정확한 표현으로 나타나다가, 이후 “pointed”와 같은 중간 단계를 거쳐, 마지막에는 “star”처럼 명확한 이름으로 정리되는 식입니다. 반면 이름 붙이기 어려운 대상은 이러한 semantic crystallization이 충분히 일어나지 못해, 끝까지 모호한 표현에 머무르는 경향을 보입니다.
더 나아가 저자들은 아주 직접적인 실험도 수행합니다.
기존에 이름이 없던 낯선 도형들에 대해 완전히 임의적인 이름을 새로 가르쳐주면, VLM의 성능 격차가 상당 부분 줄어든다는 것입니다. 이 결과는 꽤 인상적인데, 왜냐하면 모델이 그 이름을 배우는 순간 더 이상 픽셀 수준의 시각 비교를 정교하게 하지 않아도, 새로 학습한 label만으로 shape matching을 수행할 수 있게 되기 때문입니다. 말 그대로 semantic shortcut이 작동한 사례라고 볼 수 있습니다. 그리고 name-trained model의 Logit Lens 결과 역시 semantic discernibility가 높아질수록 최종 정확도도 함께 올라간다는 점을 보여줍니다.
하지만 저자들은 여기서 한 단계 더 나아갑니다.
그렇다면 성능 향상을 위해 반드시 semantic label이 필요할까? 저자들의 답은 그렇지는 않다는 것입니다. 대응 태스크 자체에 대해 모델을 직접 finetuning하면, 이름을 가르친 경우보다도 더 높은 성능을 얻을 수 있는데, 이때는 오히려 semantic discernibility가 더 낮게 나타납니다. 이 말은 곧, task-specific finetuning이 모델에게 또 다른 메커니즘, 즉 언어를 경유하지 않는 direct visual comparison을 학습시킨다는 뜻입니다. 다시 말해 semantic labeling은 성능 향상을 위한 충분조건일 수는 있지만, 필요조건은 아니라는 것이죠.
결국 이 논문이 전달하려는 메시지는 현재 VLM이 보이는 여러 시각적 실패는 아키텍처 자체의 근본적 한계라기보다, 표준적인 pretraining과 SFT 파이프라인이 학습시킨 shortcut behavior의 결과라는 것입니다. 모델은 시각 정보를 볼 수 없는 것이 아니라, 볼 수 있어도 자꾸 그것을 언어적 이름표로 바꿔 문제를 푸는 쪽을 먼저 선택한다는 이야기입니다. 그리고 이 습관이 통하지 않는 상황, 즉 이름 붙이기 어렵고 언어로 환원하기 힘든 시각적 콘텐츠 앞에서 성능이 무너진다는 것이 저자들의 핵심 주장입니다.
정리하면 이 논문의 contribution은 다음과 같습니다.
- 저자들은 semantic correspondence, shape correspondence, face correspondence의 세 가지 설정에서, VLM의 성능이 내부 representation의 정보량 그 자체보다도 대상이 semantic label을 가질 수 있는지 여부에 더 강하게 의존한다는 점을 보여줌
- 또한 Logit Lens 분석을 통해, 알려진 대상은 LM 내부에서 점차 semantic하게 명확한 표현으로 정제되는 반면, 알려지지 않은 대상은 끝까지 semantic하게 분간되지 않는다는 메커니즘적 증거를 제시합니다. 더불어 임의의 이름을 가르쳤을 때 이 discernibility gap이 줄어든다는 점도 함께 보임
- 마지막으로, semantic labeling은 representation-to-output gap을 줄이는 데 충분하지만 반드시 필요한 것은 아니며, task-specific finetuning은 언어 기반 semantic shortcut이 아니라 진짜 visual comparison 능력을 끌어낼 수 있음을 보
2. The Performance Gap Between Textual Response and Representation Space is Larger for Unknown Entities
이 절에서는 저자들이 말하는 semantic anchor, 즉 시각적 대상을 언어적으로 붙잡아줄 수 있는 이름표 같은 것이 실제로 얼마나 중요한지를 본격적으로 살펴봅니다. 먼저 실제 이미지에서 이름이 있는 개체(named entity) 와 이름 붙이기 어려운 개체(unnamed entity) 를 비교하고, 그 다음에는 2D 도형과 얼굴처럼 더 통제된 synthetic setting을 만들어 이 효과를 직접적으로 확인합니다.
Experimental Setup
이 절의 correspondence task는 모두 multiple-choice visual question answering (MC-VQA) 형태로 구성됩니다. 구체적으로는 두 장의 이미지를 주고, 첫 번째 이미지에 표시된 기준점과 대응되는 지점을 두 번째 이미지의 보기 A, B, C, D 중에서 고르게 하는 방식입니다. 평가 방식은 세 가지입니다.
첫째는 MC-VQA with Direct Answer입니다. 이 설정에서는 모델이 별다른 설명 없이 바로 정답만 내야 합니다. 저자들이 보기에 이 경우 모델은 사실상 한 번의 forward pass 안에서 비언어적으로 문제를 해결해야 하므로, 가장 직접적인 출력 성능을 본다고 할 수 있습니다.
둘째는 MC-VQA with Chain-of-Thought입니다. 여기서는 “Think step by step before choosing an option.” 같은 문장을 붙여, 모델이 중간 추론 과정을 언어로 만듭니다.
셋째는 Representation Probing입니다. 이건 모델이 실제로 말로 답을 내기 전에, 내부 hidden representation 자체만으로 정답을 복원할 수 있는지를 보는 방식입니다. 각 관심 지점에 대해 30×30 픽셀 영역을 잡고, 해당 visual token들의 hidden state를 뽑아 기준점과 보기들 사이의 유사도를 계산합니다. 이때 하나의 영역이 여러 토큰으로 대응되기 때문에, 단순 cosine similarity 대신 MaxSim을 사용합니다.
2.1 Testing Nameable and Unnameable Key Points in Semantic Correspondenc
여기서 사용하는 SPair-71k는 총 70,958개의 이미지 쌍으로 이루어져 있고, 비행기나 병 같은 일반 사물부터 동물까지 다양한 객체 카테고리를 포함합니다. SPair-71k는 같은 카테고리 안에서 일관된 keypoint annotation을 제공하기 때문에, 저자들은 각 keypoint를 수작업으로 Named 또는 No-Name으로 나눕니다. 예를 들어 pedal, seat, handlebar처럼 누구나 비교적 쉽게 이름 붙일 수 있는 부위는 Named로 두고, handlebar와 stem의 접합부처럼 눈에는 보이지만 딱 떨어지는 단어로 부르기 어려운 위치는 No-Name으로 둡니다.
이렇게 나눈 뒤, reference keypoint 기준으로 task를 분할하면 Named 샘플은 11,362개, No-Name 샘플은 11,792개가 됩니다.
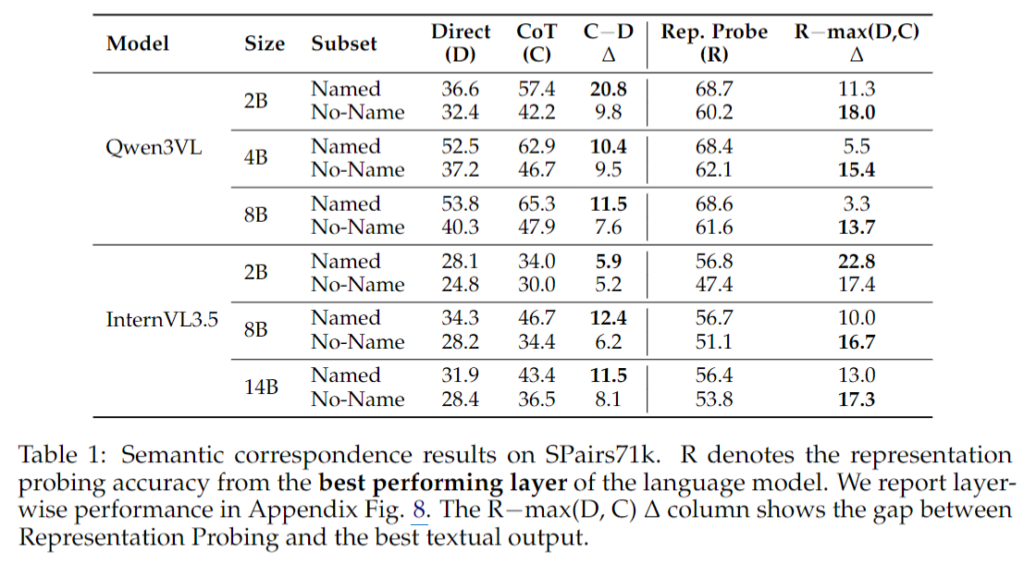
결과는 Table 1에 나와있는데, 보는 것처럼 모든 모델 크기, 모든 모델 패밀리, 그리고 Direct와 CoT 두 설정 모두에서 No-Name subset의 정확도가 Named subset보다 낮게 나옵니다. 다시 말해, 기준점이 명확한 semantic label을 가질 수 없는 순간, VLM은 correspondence task를 훨씬 더 어려워한다는 것입니다.
추가로 저자는 Representation Probing 성능과 최선의 텍스트 기반 성능 사이의 격차, 즉 R−max(D,C)R – \max(D, C)R−max(D,C)를 함께 봅니다. 이 값은 “모델 안에는 정보가 있었는데, 텍스트 출력 단계에서 얼마나 못 꺼냈는가”를 대략적으로 보여주는 지표라고 볼 수 있습니다.
예를 들어 Qwen3VL-8B는 Named keypoint에서는 이 격차가 3.3%에 불과합니다. 즉, semantic anchor가 주어지면 텍스트 출력이 내부 표현을 거의 따라잡는다는 뜻입니다. 반면 No-Name keypoint에서는 이 격차가 13.7%로 크게 벌어집니다. 내부 representation 자체는 어느 정도 정보를 담고 있지만, 이름이 없는 대상에 대해서는 그 정보를 언어로 표면화하는 단계에서 큰 병목이 생긴다는 것이죠. InternVL3.5의 8B, 14B 모델에서도 비슷한 패턴이 나타나고, 2B 모델은 애초에 Named subset에서도 거의 랜덤에 가까운 성능을 보여 baseline capability 자체가 부족하다는 점도 확인됩니다.
CoT의 결과도 확인을 해보면 모든 경우에 무조건 도움이 되는 것이 아니라, 이름 있는 대상에서 훨씬 더 크게 도움이 됩니다. 예를 들어 Qwen3VL-2B는 Named keypoint에서는 CoT로 20.8%나 향상되지만, No-Name에서는 9.8% 향상에 그칩니다. 저자들은 실제 CoT chain을 살펴본 결과, 모델이 이름이 있는 지점에 대해서는 그 부위 이름을 명시적으로 생성하면서 correspondence 문제를 사실상 시각적 매칭이 아니라 언어적 문자열 매칭 문제로 바꿔서 풀고 있다고 분석합니다. 왜냐하면 이름이 붙는 순간 visual comparison 자체를 끝까지 하지 않아도 되기 때문입니다.
반면 Representation Probing 성능은 같은 패밀리 안에서 모델 크기가 달라져도 비교적 안정적입니다. 예를 들어 Qwen3VL은 Named에서 68.4–68.7%, No-Name에서 60.2–62.1% 수준으로 크게 흔들리지 않습니다. 저자들은 이를 두고, 같은 패밀리 내에서는 vision encoder가 비슷하므로 LLM이 visual information을 망가뜨리고 있는 것이 아니라, 큰 LM일수록 그 정보를 텍스트로 더 잘 끌어올린다고 해석합니다.
2.2 Confirming the Effect of Semantic Anchors on Shape and Face Correspondence
다만 SPair-71k는 실제 이미지 기반 데이터셋이기 때문에, occlusion, 해상도 차이, 객체 크기 변화, 시각적 artifact 같은 여러 요인이 함께 섞여 있습니다. 그리고 VLM은 결국 이미지를 non-overlapping patch token으로 처리하기 때문에, 이런 요인들이 결과에 어떤 식으로 영향을 주는지 완전히 분리해서 보기 어렵습니다.
그래서 저자들은 semantic anchor의 효과를 더 깔끔하게 보기 위해 2D object correspondence와 face correspondence라는 synthetic task를 별도로 설계합니다. 이 설정으로 해상도와 객체 크기를 통제할 수 있고, 부분 가림이나 배경 artifact도 없으니, 정말로 “이 대상이 이름을 가질 수 있는가 없는가”에 더 집중할 수 있게 됩니다.
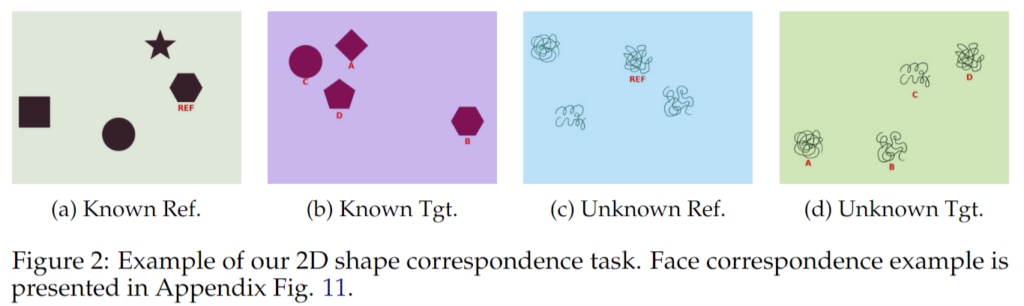
예시는 위 그림에 나와 있습니다. 여기서 Ref는 기준이 되는 도형을 뜻하고, Tgt는 기준 도형과 일치하는 대상을 찾아야 하는 후보 도형들을 뜻합니다. 먼저 (a), (b)는 원, 별, 육각형처럼 우리가 쉽게 이름을 말할 수 있는 familiar shape들로 구성된 setting입니다. 반면 (c), (d)는 절차적으로 생성된 불규칙한 squiggle shape들로 구성되어 있으며, 이런 도형들은 눈으로는 서로 구분할 수 있지만 일반적으로 붙일 수 있는 명확한 이름이 없습니다. 따라서 이 setting에서는 모델이 semantic anchor에 기대기 어렵고, 실제로는 픽셀 수준의 시각적 비교 능력에 더 의존해야 합니다. 결국 이 실험은 VLM이 정말 시각적 디테일을 보고 correspondence를 수행하는지, 아니면 이름 붙일 수 있는 대상에 한해서 언어적 shortcut을 활용하는지를 보다 직접적으로 드러내기 위한 설정이라고 볼 수 있습니다.

Face correspondence도 비슷합니다. 잘 알려진 celebrity의 얼굴과, FluxSynID에서 가져온 synthetic unknown face를 준비한 뒤, Nano-Banana-2를 이용해 각 인물당 여러 포즈와 조명, 배경을 가진 이미지를 생성합니다.
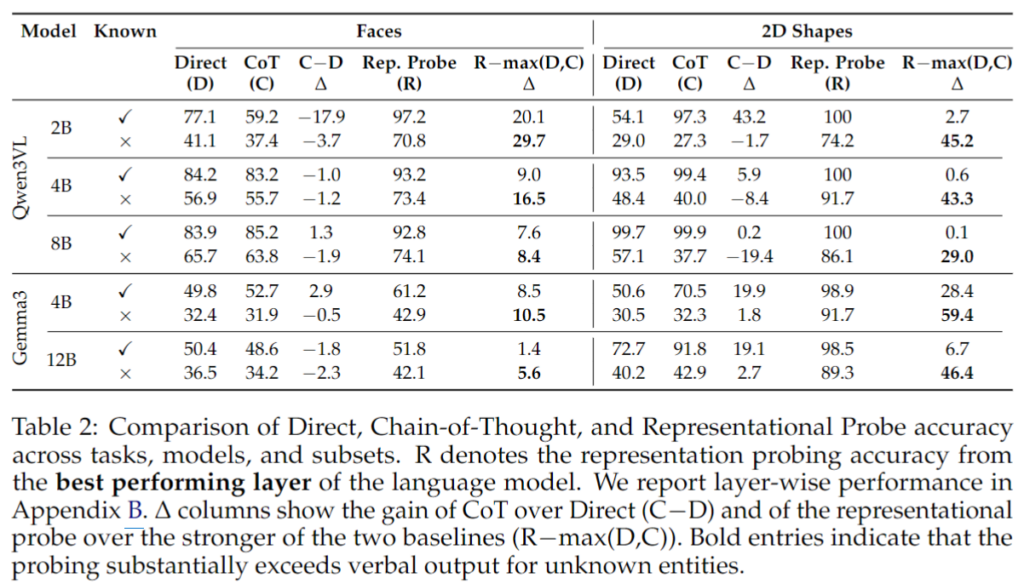
결과는 Table 2에 나와있습니다. Table1 과 다른 통제된 synthetic setting에서는 known과 unknown 사이의 격차가 더 크게 나타납니다. 그리고 여기서도 Representation Probing과 최선의 텍스트 기반 성능 사이의 격차 R−max(D,C)R – \max(D, C)R−max(D,C)는 unknown entity에서 훨씬 크게 나타납니다.
특히 2D shape 결과에서는 Qwen3VL-2B는 unknown shape에서 Direct accuracy가 29.0%에 불과한데, Representation Probing은 74.2%까지 올라갑니다. 반면 known shape에서는 Representation Probing이 100%, CoT가 97.3%의 성능을 보여주고 있습니다. 즉, 모델 안에는 정보를 충분히 가지고 있는데, 이름 없는 도형에 대해서는 그 정보를 텍스트 추론으로 꺼내는 데 심각한 병목이 발생한다는 것이 아주 잘 드러납니다.
하지만 여기서는 CoT가 오히려 해가 될 수 있습니다.
semantic correspondence에서는 CoT가 적어도 어느 정도 도움이 되었지만, shapes나 faces처럼 semantic anchor가 약한 setting에서는 CoT가 성능을 떨어뜨리는 경우도 나타납니다. 예를 들어 Qwen3VL-8B는 unknown shape에서 CoT를 쓰면 Direct보다 19.4포인트나 하락합니다. 저자들은 이를 두고, semantic anchor가 없는 상태에서 verbal reasoning이 의미 있는 추론으로 이어지는 것이 아니라 hallucinated description으로 흘러가면서 오히려 모델을 잘못된 방향으로 이끈다고 해석합니다.
흔히 CoT를 붙이면 무조건 reasoning이 좋아진다고 생각하기 쉬운데, 이 논문은 적어도 이런 시각 대응 문제에서는 그렇지 않다고 보여주고 있습니다. 오히려 이름 붙이기 어려운 대상에서는 “생각을 말로 풀어보라”는 요구가 visual reasoning을 돕는 게 아니라, 잘못된 언어적 근사치를 만들게 해서 성능을 해칠 수 있다는 것이죠.
2.3 Logit Lens Reveals VLMs Explicitly Recover Semantic Anchors
앞 절들에서는 성능 패턴을 통해 semantic anchor의 존재를 간접적으로 추론했다면, 여기서는 저자들이 Logit Lens를 사용해 그 메커니즘을 좀 더 직접적으로 들여다봅니다. 즉, language model 내부를 지나가는 visual token의 hidden representation을 바로 decoding해보면서, 모델이 정말로 known entity를 semantic label 쪽으로 끌고 가고 있는지를 확인하는 것입니다.
여기서부터는 각 visual token의 hidden state를 LM의 unembedding matrix에 통과시켜 top-1 decoded token을 얻고, 이를 Logit Lens token이라고 부릅니다. 하나의 시각적 대상은 여러 visual token으로 구성되기 때문에, 저자들은 두 대상의 semantic discernibility를 그 token set이 얼마나 다른지로 근사합니다. 구체적으로는 각 레이어에서 두 대상의 Logit Lens token 집합 사이의 Jaccard Distance를 계산합니다. 값이 클수록 두 대상이 언어 공간에서 더 구분 가능하다는 뜻입니다.
결과는 위그림에 나와있습니다.
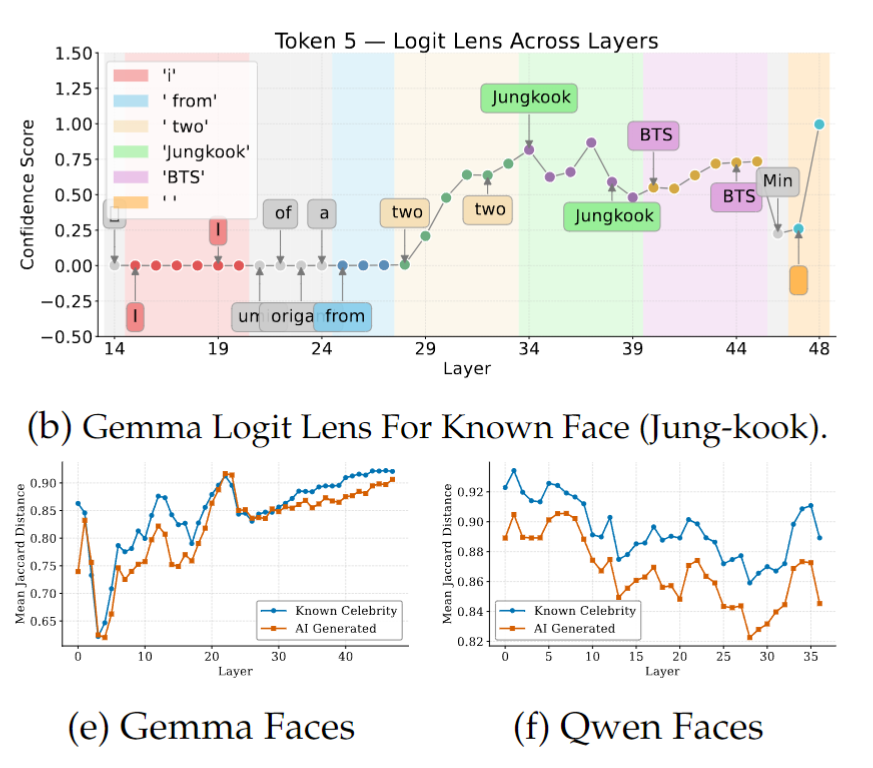
그림 3a와 3b는 Gemma3-12B가 별 모양과 정국 얼굴 사진을 볼 때, 모델 내부의 visual token이 레이어를 지나면서 어떤 단어에 가까워지는지를 보여줍니다. 여기서 Logit Lens는 각 레이어의 hidden state를 억지로 단어로 읽어보는 도구라고 생각하면 됩니다. 즉, 모델이 그 시점에 해당 대상을 어떤 말로 해석하고 있는지를 보는 것입니다.
결과를 보면, 처음 몇 개 레이어에서는 visual token이 아직 제대로 해석되지 않아서 “and”, “in”, “from”처럼 입력과 거의 상관없는 토큰이 나옵니다. 그러다가 중간 레이어쯤 가면, 완전히 정확하진 않지만 대상의 특징을 어느 정도 반영하는 표현들이 나타나기 시작합니다. 예를 들어 별 모양에 대해서는 “triangle”, “reddish”, “pointed”처럼 대략적인 묘사가 등장합니다. 이건 모델이 아직 “별”이라고 정확히 짚지는 못했지만, 적어도 뾰족한 모양이나 형태적 특징은 잡아내고 있다는 뜻입니다.
이후 더 깊은 레이어로 가면, hidden state가 갑자기 해당 대상을 정확히 가리키는 이름으로 수렴합니다. 별 모양은 “star”, 정국 얼굴은 “Jungkook”처럼 명확한 semantic label이 튀어나옵니다. 그리고 가장 깊은 레이어에서는 여기서 멈추지 않고, 그 대상과 연관된 더 높은 수준의 정보까지 붙습니다. 별은 “five”처럼 오각별의 특징을 반영하는 단어로, 정국은 “BTS”처럼 해당 인물의 소속 그룹을 반영하는 단어로 확장됩니다.
즉, 이 결과는 모델이 알려진 대상을 볼 때 처음부터 바로 이름을 아는 것이 아니라, 무의미한 상태 → 대략적인 특징 묘사 → 정확한 이름 → 그와 관련된 배경지식의 순서로 내부 표현을 점점 정교하게 바꿔간다는 것을 보여줍니다. 저자들은 이를 근거로, VLM이 known entity에 대해서는 중간 표현 안에서 실제로 discrete한 이름표, 즉 semantic anchor를 복원한다고 주장합니다.
이어지는 그림 3c부터 3f는, 이런 현상이 특정 예시에만 국한되지 않는다는 점을 보여줍니다. known shapes와 known faces는 unknown ones보다 레이어 4 이후부터 계속 더 높은 Mean Jaccard Distance를 보입니다. 쉽게 말하면, 이름이 있는 대상일수록 Logit Lens로 읽었을 때 서로 더 구분되는 단어들이 나온다는 뜻입니다. 반대로 이름이 없는 대상은 내부 표현이 존재하더라도 language model 입장에서 뚜렷하게 “이건 이거다”라고 말할 만큼 semantic하게 분리되지 않는다는 것이죠.
정리하면, 이 결과는 VLM이 이름을 붙일 수 있는 대상에 대해서는 내부적으로 점점 더 명확한 semantic label을 만들어가지만, 이름 붙이기 어려운 대상은 끝까지 모호하게 남는 경향이 있다는 것을 보여줍니다.
3. Teaching Arbitrary Names
이전 섹션에서 VLM이 기준이 되는 시각적 대상에 명확한 semantic label을 붙일 수 없을 때 성능이 크게 떨어진다는 점을 보여주었습니다. 이번에는 여기서 더 나아가 원래 이름이 없던 unknown shape에 임의의 이름을 새로 가르쳐주면 이 성능 격차가 실제로 줄어드는지를 확인합니다.
Experimental Setup
이를 검증하기 위해 저자들은 Qwen3VL-2B와 Gemma3-4B를 finetuning하여, 각 squiggle shape마다 임의의 이름(arbitrary name) 을 가르칩니다. 방식은 shape 하나가 있는 이미지를 보여주고, “What is the name of this object?”라고 물은 뒤, 해당 도형에 대응하는 이름을 생성하도록 학습시키는 것입니다. 즉, 모델에게 도형의 시각적 특징을 직접 비교하는 법을 다시 가르치는 것이 아니라, 낯선 도형과 특정한 이름표를 연결하는 것 자체를 학습시키는 셈입니다.
저자는 이름도 한 종류만 쓰지 않고 세 가지로 나누어 실험합니다.
첫째는 ordinary object names로, cup, anchor, feather처럼 이미 일반적인 시각적 대상을 떠올릴 수 있는 단어들입니다. 둘째는 human names로, John, Mary, Charles처럼 LLM이 알고는 있지만 특정한 시각적 대응 대상을 갖지는 않는 이름들입니다. 셋째는 random strings로, “0QK2Z2”, “5F1FT3”, “OZ0W0M”처럼 완전히 인공적으로 만든 문자열입니다. 이 구성도 꽤 흥미로운데, 결국 저자들은 단순히 “이름이 있으면 된다”를 넘어서, 어떤 종류의 이름이 더 잘 semantic anchor 역할을 하는가까지 함께 보려는 것입니다.
Results
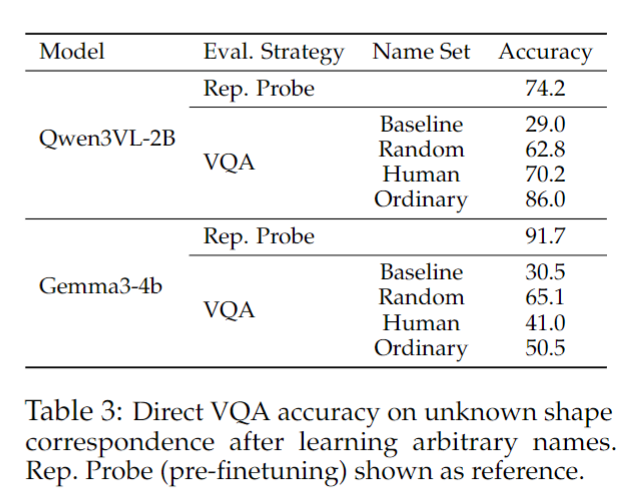
Table 3을 보면, 세 종류의 이름 모두 baseline 대비 VQA accuracy를 일관되게 끌어올립니다. 즉, unknown squiggle에 임의의 이름만 붙여줘도 모델 성능이 확실히 좋아진다는 것입니다. 이건 결국 모델이 원래 이름 없는 대상을 잘 못 맞히는 이유가, 정말 시각 정보를 못 봐서라기보다 그 대상을 언어적으로 붙잡을 semantic anchor가 없기 때문이라고 해석할 수 있습니다.
예를 들어 Qwen3VL-2B는 baseline이 29.0%였는데, ordinary names를 가르치면 86.0%까지 올라갑니다. 이 수치는 심지어 finetuning 전 Representation Probe 성능인 74.2%보다도 높습니다. 즉, 이름만 새로 붙여줘도 모델은 내부에 있던 시각 정보를 훨씬 더 잘 활용하게 되고, 그 결과 이전에는 끌어내지 못하던 성능까지 텍스트 출력 수준에서 회복하게 되는 셈입니다. Human names는 70.2%, random names는 62.8%로 역시 모두 baseline보다 크게 향상됩니다.
모델마다 가장 잘 먹히는 이름의 종류가 조금씩 다른 점도 재밌는데, Qwen3VL-2B는 ordinary names에서 가장 큰 이득을 보고, Gemma3-4B는 오히려 random names에서 가장 좋은 성능을 보입니다. 저자들은 이 차이가 이름 세트별 tokenization 길이 차이와 관련 있을 가능성을 언급합니다. ordinary names는 평균 1 token, human names는 약 1.4 token, random strings는 약 4.7 token 정도로 나뉘는데, 각 모델이 이들을 얼마나 쉽게 학습하고 활용하느냐가 성능 차이로 이어질 수 있다는 것입니다. 다만 이 부분은 저자들도 확정적으로 주장하기보다는 가능성 수준에서 언급하고 있습니다.
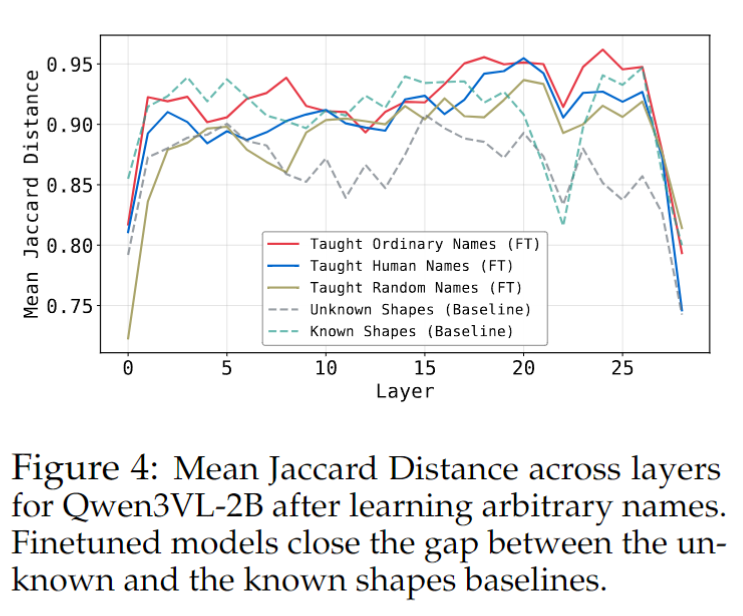
여기서 가장 중요한 건 단순히 성능이 올랐다는 사실보다, 왜 성능이 올랐는지에 대한 메커니즘입니다. Figure 4를 보면, finetuned Qwen 모델은 unknown shape와 known shape baseline 사이의 Mean Jaccard Distance 격차를 상당 부분 줄입니다. 다시 말해, 이름을 가르친 뒤에는 원래 semantic하게 잘 구분되지 않던 unknown shape들이 Logit Lens 상에서도 점점 더 구분 가능한 토큰들을 가지게 된다는 것입니다. 그리고 ordinary > human > random이라는 순서 역시 VQA accuracy의 순서와 일치합니다. 즉, semantic discernibility가 높아질수록 downstream performance도 함께 올라간다는 상관관계가 확인됩니다.
저자들은 모델이 실제로 어떻게 생각하는지도 Chain-of-Thought를 통해 확인합니다. 그 결과, finetuning 이후의 모델은 도형의 세부 모양을 하나하나 비교하기보다는, 먼저 그 도형에 붙여준 이름을 떠올린 뒤 그 이름이 같은지를 확인하는 방식으로 문제를 푸는 모습을 보입니다. 예를 들어 모델은 “REF는 brick이고, 보기 D도 brick이니까 정답은 D다”처럼 아주 단순하게 추론합니다.
즉, 모델이 도형의 모서리나 곡선 같은 시각적 특징을 더 정교하게 비교하게 된 것이 아니라, 원래 이름이 없던 도형에 새로 붙여준 이름을 이용해 문제를 훨씬 쉽게 풀게 된 것입니다. 저자들은 이것을 통해, 성능 향상이 진짜 visual reasoning의 향상 때문이라기보다 시각적 대상을 언어적 이름표로 바꿔 처리하는 방식 덕분이라고 해석합니다.
4. Is Semantic Alignment A Requirement or A Side Effect?
앞선 2절과 3절에서 저자들은 VLM이 시각적 대상을 잘 맞히는 데 있어 semantic anchor, 즉 이름표처럼 작동하는 의미적 정렬이 얼마나 큰 영향을 주는지를 보여주었습니다. 그렇다면 VLM이 시각 태스크를 잘 풀기 위해서는 정말 이런 semantic alignment가 반드시 필요한 것일까, 아니면 현재의 pretraining 방식 때문에 모델이 그쪽으로 습관이 들어버린 것일까 하는 의문이 생깁니다.
만약 semantic anchor가 꼭 필요하다면, 결국 VLM은 기존 vocabulary가 표현할 수 있는 수준까지만 이해할 수 있게 됩니다. 다시 말해, 이름 붙이기 어려운 새로운 시각 패턴이나 세밀한 차이는 구조적으로 다루기 어려워진다는 뜻이죠. 저자들은 이런 semantic alignment가 성능 향상의 필수 조건인지, 아니면 단지 자주 쓰이는 편한 경로인지를 따져봅니다.
Experimental Setup
이를 검증하기 위해 저자들은 이번에는 shape correspondence task 자체에 대해 VLM을 직접 finetuning합니다. 여기서는 학습에는 한 종류의 shape만 보여주고, 평가 때는 모델이 한 번도 본 적 없는 전혀 다른 shape들, 심지어는 shape family 자체가 다른 데이터까지 사용합니다.
이 실험에서 모델이 진짜로 시각적 디테일을 직접 비교하는 능력을 배웠다면, 훈련 때 본 적 없는 새로운 도형이나 다른 형태의 패턴이 나와도 어느 정도 일반화할 수 있어야 합니다. 반대로 모델이 여전히 내부적으로 semantic label 비슷한 것을 붙여가며 문제를 푼다면, 새로운 도형에는 그런 이름표가 없기 때문에 성능이 무너져야 합니다.

저자들은 이번 실험에서 Qwen3VL-2B와 Gemma3-4B를 squiggle 도형 맞추기 문제로 finetuning합니다. 여기서 squiggle은 이름 없는 꼬불꼬불한 도형이고, 복잡도는 도형을 만들 때 사용하는 점의 개수로 조절됩니다. 이 실험에서는 점을 30개 사용한, 즉 중간 정도로 복잡한 squiggle을 학습에 사용합니다. 학습 데이터는 Figure 2c, 2d처럼 왼쪽의 기준 도형(REF) 과 오른쪽의 보기 A, B, C, D 중에서 같은 도형을 찾는 형태의 synthetic image pair 1000개로 이루어져 있습니다. 중요한 점은, 이전처럼 도형마다 이름을 붙여주는 학습을 한 것이 아니라, 이번에는 두 이미지를 보고 어떤 도형이 서로 대응되는지를 직접 맞히는 태스크 자체를 학습시켰다는 것입니다.
평가는 여러 수준으로 나누어 이루어집니다.
먼저 학습 때 쓴 squiggle과 같은 계열이지만 더 단순하거나 더 복잡한 held-out squiggle을 사용합니다. 그리고 전혀 다른 구조를 가진 maze도 평가에 포함합니다. maze는 직교 격자 형태라서, 훈련 때 본 squiggle과는 기하학적으로 거의 닮지 않았습니다. 말 그대로 shape family가 바뀌는 것이죠. 더 나아가 semantic correspondence와 face correspondence처럼, squiggle과는 거의 관계가 없는 out-of-distribution domain까지 함께 평가합니다.
Results
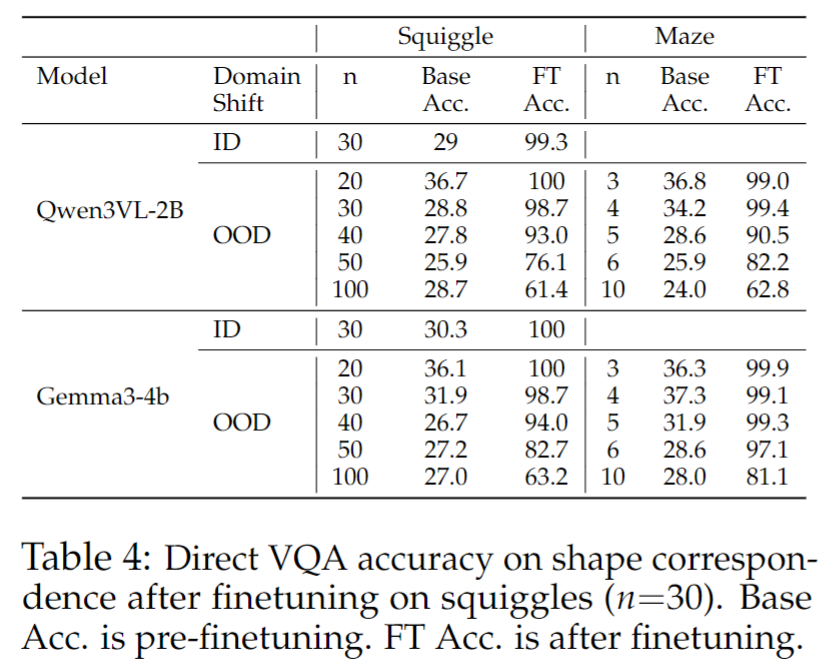
결과를 보면 finetuning의 효과 자체가 매우 크다는 것을 알 수 있습니다. finetuning 이후에는 거의 100%에 가까운 성능까지 올라갑니다. 그뿐만 아니라, 학습에 쓰지 않은 더 복잡한 squiggle(OOD)이나 전혀 다른 형태의 maze에도 높은 성능을 유지합니다. 만약 모델이 단순히 훈련 중 본 squiggle들에 내부적인 이름표를 붙여 외우는 방식으로 문제를 풀었다면, 이렇게 생김새가 완전히 다른 maze에서는 일반화가 잘 되기 어려울 것 입니다. 그런데 실제로는 maze에서도 높은 성능이 유지되므로, 저자들은 이를 두고 모델이 특정 도형을 암기한 것이 아니라 시각적 유사성을 직접 비교하는 능력을 학습했다고 해석합니다.
또 하나 흥미로운 점은, 이런 학습 효과가 squiggle과 maze 같은 shape correspondence 내부에만 머무르지 않는다는 것입니다. 논문에서는 squiggle로 finetuning한 뒤 face correspondence와 semantic correspondence 성능도 함께 향상된다고 보고합니다. 즉, 모델이 특정 도형 몇 개에만 적응한 것이 아니라, 더 일반적인 수준에서 fine-grained visual comparison 능력을 끌어올렸다는 해석이 가능해집니다.
5. Conclusion
정리하면 이 논문에서 VLM에서 반복적으로 관찰되는 hidden-in-plain-sight gap에 대해 VLM이 시각 정보를 전혀 보지 못하는 것이 아니라, 그 정보를 언어적으로 이름 붙일 수 있을 때 훨씬 더 잘 활용한다는 것을 실험적으로 보여줬습니다.
다만, 단순히 이름이 중요하다에서 끝나는 것이 아니라, semantic labeling이 성능 향상의 충분조건일 수는 있어도 필요조건은 아니라는 점도 함께 보여주었습니다. task-specific finetuning을 통해 correspondence task 자체를 직접 학습시키면, 모델은 semantic anchor에 덜 의존하면서도 더 강한 성능을 낼 수 있었고, 학습에 쓰지 않은 새로운 shape와 다른 shape family로도 일반화할 수 있었습니다. 이를 통해 VLM이 적절한 학습 신호만 주어지면, 언어적 이름표를 경유하지 않고도 더 일반적인 visual comparison 능력을 배울 수 있음을 보여주었습니다.
결국 현재 VLM이 여러 비주얼 태스크에서 보이는 실패는 멀티모달 추론 아키텍처 자체의 근본적 한계라기보다, 기존 pretraining과 SFT 과정에서 형성된 learned shortcut의 결과일 가능성이 크다는 것을 알 수 있었고, direct visual comparison 쪽으로도 충분히 학습될 수 있다는 것을 알 수 있었네요.
감사합니다.
안녕하세요 의철님 좋은 리뷰 감사합니다.
생각보다 많은 정보들을 얻을 수 있는 논문이네요.. 실험세팅도 다양하고 납득가능한 수준인 것 같습니다.
제가 이전에 리뷰했던 VLM 내부에서 visual 정보가 text 정보로 흡수되는게 중간 layer에서 일어나더라를 이번 의철님 논문의 logit lens 실험으로도 엿볼 수 있겠네요.
그리고 probing을 naming을 해주느냐와 naming을 해주지 않아도 성능 향상이 있는지를 보여주는 실험세팅이 인상깊었습니다.
뭔가 실험적으로 리포팅 되어있을지는 모르겠으나, 마지막 squiggles와 maze 실험이 A,B,C,D 의 형태로 대답해줘, 라는 방식으로 학습이 되었다면 저자의 이전 실험세팅인 이름을 붙여주는 것과 같은 효과일 것 같은데, 학습과정과 평가과정에서의 instruction이나 system prompt가 공개되어있나요?
감사합니다.
안녕하세요 인택님 좋은 질문 감사합니다.
아쉽게도 Section 4의 학습 prompt는 자세히 공개되지 않았습니다. 그래서 말씀하신 우려처럼 A/B/C/D 형식에 적응한 효과가 섞였을 가능성은 있어 보입니다. 다만 저자들은 maze까지 일반화된 결과를 근거로, 단순 형식 학습만은 아니라고 본 것 같습니다.
저도 이번 논문은 재미있게 읽었는데 인택님도 논문 한 번 보시면 얻어갈 수 있는 정보가 많을 것 같아 한 번 정독해서 읽어보시는 것도 좋을 것 같네요~
감사합니다.
회사 멘토님도 저한테 이거 논문 보라고 추천해줬는데 딱 맞게 리뷰하셨네요 감사합니다.
최근에 하고 있는 개인적인 고민이라도 좀 연관이 있는거 같습니다. Thinking Mode의 메커니즘이 모호한 부분이 있었는데, textual clue에 과하게 의존하던 것도 해당 논문을 통해서 어느정도 이해가 된 거 같습니다.
근데 근본적으로 하나 궁금한건
저희가 살아가고 있는 world에서 언어로 표현하기 어려운 개념들은 사람도 설명하기 어려워하지 않나 생각이 듭니다.
과연 언어로 표현되기 어려운 것들까지 우리의 관심사라고 볼 수 있을까? 라는 생각이 들긴합니다.
결국 정보라는 것도 다 글자나 말로 표현되고 전달되어야 의미가 생기는 것이다 보니…
흥미로운 발견인 것 같지만 뭔가 문제를 위해 문제를 만든 느낌이 들긴 하네요.
어떻게 생각하시나요???
안녕하세요 근택님 좋은 질문 감사합니다.
논문을 읽어보니 멘토님이 추천해주신 이유를 알 것 같습니다ㅎㅎ
제가 이 논문을 이해하기로는 “언어로 표현하기 어려운 것까지 전부 언어화해야 한다”는 쪽보다는, 모델이 실제로는 볼 수 있는 시각 정보조차 너무 빨리 이름표나 textual clue로 환원해서 처리하려는 경향이 있다는 점인 것 같습니다. 그래서 이런 경향 때문에 fine-grained한 정보를 필요로 하는 태스크에서 성능이 떨어진다는 것을 보여 준 것 같습니다.
말씀하신것처럼 언어로 표현되기 어려운 것들이 우리의 관심사는 아닐 수 있다고 생각합니다. 다만 실제로는 세계를 이해하는 데 있어, 언어로 설명되지 않는 정보들도 충분히 유의미한 정보로 활용된다고 생각합니다.
예를 들어 미세한 형태 차이에 대한 정보는 시각적 대상을 구별하는 데 유의미한 단서로 작용할 수 있어서, 비전 태스크에서는 이러한 정보가 중요할 것 같다는 생각이 드네요.
감사합니다.