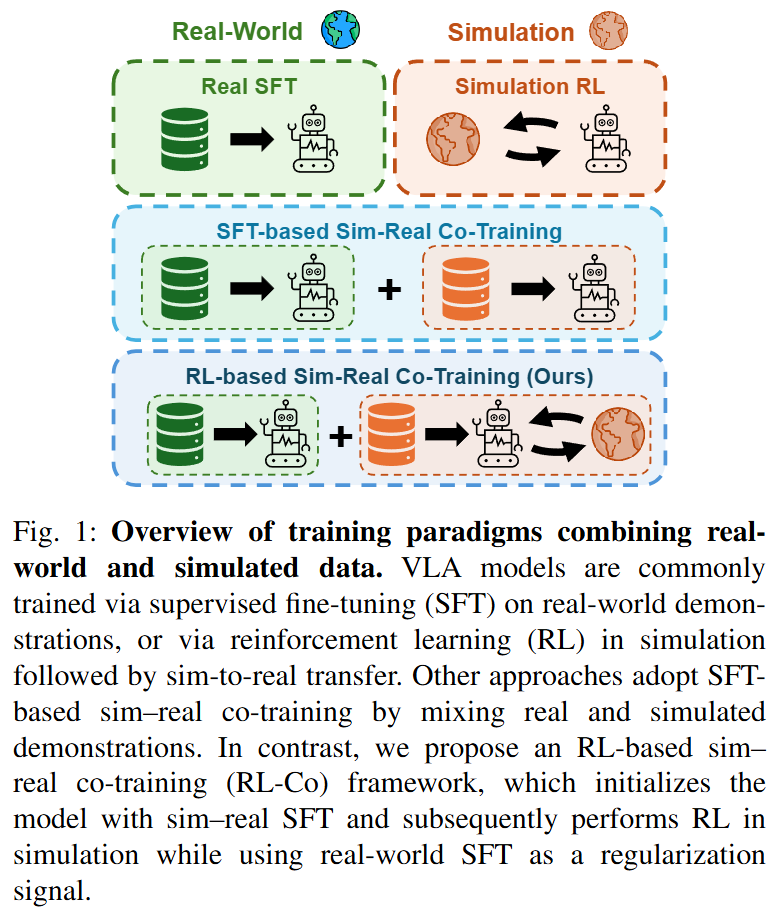
안녕하세요, 이번주는 RSS 2026에 submit된 Co-training 연구를 리뷰해보려고 합니다. 시뮬레이션 데이터는 현실 데이터와 함께 co-training되면서 low-cost로 VLA training을 풍부하게 해주는데, 대부분의 co-training 연구들은 SFT 방식으로 진행됐습니다. 저자들은 real-world capability를 최대로 하되 시뮬레이션의 interactive한 장점만을 살릴 수 있는 방법으로 해당 연구를 제안했습니다. 사실 co-training한 policy를 시뮬레이션 RL의 base policy로 활용하면서 RL objective에 real-world data의 BC loss를 추가한 간단한 구조인데, 처음 co-training이 등장할때도 그랬듯 누구도 시도해보지 않은 방법을 통해 새로운 결과를 보았습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
로봇이 현실 세계에서 다양한 작업을 안정적으로 수행하는데 있어서 VLA는 문제를 해결할 수 있는 유망한 방식으로 정해지고 연구가 되고 있습니다만, 아시다싶이 VLA 모델은 중요한 한계를 가지고 있습니다. 실제 환경에서 조금만 조건이 바뀌어도 성능이 크게 저하되는 문제가 존재합니다. 물체의 위치가 달라지거나 새로운 물체가 등장하거나, 초기 상태가 조금만 달라져도 기존에 학습된 정책이 제대로 작동하지 않는 경우가 많습니다. 이는 결국 VLA 모델이 distribution shift에 매우 취약하다는 것을 의미합니다. 더 근본적인 문제는 이러한 모델을 학습시키기 위해 필요한 real-world 데이터 자체가 매우 비싸고 수집하기 어렵다는 점입니다.
이러한 한계를 해결하기 위한 대안으로 자연스럽게 떠오른 것이 시뮬레이션 입니다. 시뮬레이션 환경에서는 다양한 조건을 자유롭게 설정할 수 있고, 대규모 데이터를 저비용으로 생성할 수 있기 때문입니다. 특히 최근에는 고성능 시뮬레이터와 다양한 오픈소스 3D 자산들이 등장하면서, 복잡한 환경에서도 비교적 손쉽게 학습 데이터를 생성할 수 있게 되었습니다. 하지만 시뮬레이션 역시 완전한 해결책은 아닙니다. Sim-to-real gap이 해결되지 않는한 한계가 존재하는데요, 시뮬레이션 환경과 실제 환경 사이에는 시각적 차이뿐 아니라 물리적 상호작용, 센서 노이즈 등 다양한 차이가 존재하기 때문입니다. 과거에는 이러한 문제를 해결하기 위해 domain randomization과 같은 기법이 사용되었지만, 이는 많은 튜닝이 필요하고 복잡한 작업에서는 확장성이 떨어지는 한계를 가지고 있습니다. 최근에는 real-to-sim-to-real 파이프라인이나 생성 모델 기반 접근을 통해 이 격차를 줄이려는 시도가 있었지만, 여전히 현실과 완전히 동일한 시뮬레이션을 구축하는 것은 높은 비요을 요구합니다.
Sim-to-real gap을 해결하기 위한 방법으로 최근 co-training이 떠오르고 있는 상황인데요, simulation과 real-world 데이터를 함께 활용하는 방식입니다. 하지만 기존의 sim-real co-training 방법들은 대부분 imitation learning 기반의 supervised learning으로 설계되어 있습니다. 다시 말해, 시뮬레이션 데이터를 단순히 정적인 demonstration 데이터로 취급하고, 이를 그대로 모방하도록 학습시키는 방식입니다. 저자들은 이러한 접근이 시뮬레이션의 가장 큰 장점인 reliable한 closed-loop interaction을 제대로 활용하지 못한다는 한계를 진다며 문제를 정의헀습니다. 시뮬레이션의 진짜 강점은 단순한 데이터 생성이 아니라, 환경과의 상호작용을 통해 정책을 개선할 수 있다는 점인데, 기존 방법들은 이 부분을 충분히 활용하지 못하고 있다는 것입니다.
저자들은 이러한 한계를 극복하기 위해 강화학습(RL)을 활용한 접근을 제안했습니다. RL은 환경과의 상호작용을 통해 정책을 점진적으로 개선할 수 있기 때문에, unseen 환경에 대한 일반화 성능을 향상시키는 데 효과적이라고 합니다. 실제로 VLA 모델에 RL을 적용한 연구들은 기존의 supervised fine-tuning 방식보다 더 높은 성공률과 더 강한 일반화 성능을 보여주고 있기도 합니다. 하지만 RL 역시 대부분 안전성과 효율성 문제로 인해 시뮬레이션에서 수행되는데, 이 경우 다시 sim-to-real gap 문제가 발생합니다.
따라서 저자들의 핵심 아이디어는 시뮬레이션을 단순한 데이터 생성 도구가 아니라 정책을 학습하는 상호작용 환경으로 적극 활용하는 동시에, real-world 데이터를 통해 정책이 현실에서의 성능을 유지하도록 설계했다고 합니다. 시뮬레이션에서 reinforcement learning을 수행하면서 동시에 real-world 데이터에 대한 supervised loss를 추가로 적용해 정책이 RL 과정에서 real-world 성능을 잃어버리는 것을 방지하는 컨셉입니다. 이러한 구조를 통해 시뮬레이션의 확장성과 RL의 탐색 능력을 활용하면서도 real-world에서의 성능을 안정적으로 유지할 수 있었다고 합니다. 실험 결과에서도 기존의 real-only 학습이나 SFT 기반 co-training 방법 대비 실제 로봇 환경에서의 성공률이 크게 향상되었으며, unseen 환경에 대한 일반화 성능 또한 유의미하게 개선되는 것을 확인할 수 있습니다.
Methods
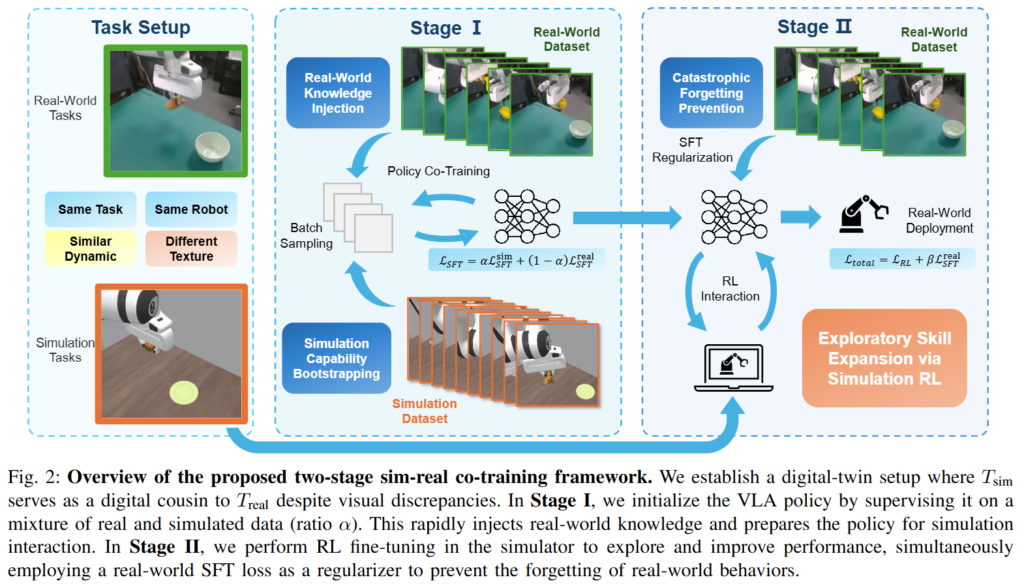
저자들은 sim-to-real gap을 해소하기 위한 co-training의 imitation learning용 데이터 생성 기반 접근이 시뮬레이션의 interactive한 exploration을 사용하지 못한다는 문제를 해결하기 위해 RL-based Sim-Real Co-Training (RL-Co)를 제안했습니다.
Problem Formulation
저자들은 하나의 real-world manipulation task와 이에 대응하는 simulation task를 동시에 고려하는 구조를 사용합니다. 즉, 현실 환경에서 수행해야 할 작업이 주어지면, 이를 가능한 한 유사하게 반영한 시뮬레이션 환경을 함께 구성합니다. 이 두 환경은 완전히 동일하지는 않지만, 동일한 로봇과 동일한 task를 공유하는 pair 관계입니다. 이 쌍은 동일한 제어 인터페이스와 action space를 갖지만 state transition dynamics와 observation의 차이가 발생하기 때문에 저자들은 환경을 POMDP로 모델링했습니다. 완전히 동일한 환경은 아니지만, 공통적인 구조를 공유하면서 그 정의 아래에서 단순히 state->action 매핑을 하는게 아니라 문맥을 고려한 sequence prediction을 목표로 한다고 생각하면 될 것 같습니다.
Stage 1 : SFT Co-Training for Policy Initialization
먼저 pre-trained VLA를 가지고 시작합니다. 첫번째 단계에서는 real과 sim 데이터를 모두 사용해 policy를 supervised finetuning 해줍니다. 이때는 여타 SFT 기반 co-training 연구들과 다를것 없이 alpha가 정해주는 시뮬레이션 데이터와 현실 데이터의 비율로 배치를 구성해 BC loss를 최소화 합니다.
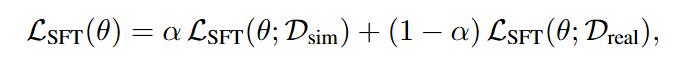
이 과정에서 policy는 task-specific한 real-world knowledge와 시뮬레이션 환경에서 완벽하지는 않지만 어느정도 작동 가능한, RL을 하기 위한 warmup된 policy를 획득할 수 있습니다. 저자들의 SFT Co-Training은 다른점이 기존 연구들이 바로 현실에서 작동할 수 있는 정책을 기대하며 진행했다면, 시뮬레이션 내에서 real world knowledge를 포함한 채로 RL을 진행할 수 있는 agent를 만드는 용입니다.
Stage II: Sim-Real Co-Training with Real-Regularized RL
두번째 단계에서는 시뮬레이션 환경에서 RL을 수행합니다. 첫 단계에서 task에 대한 의미론적인 행동을 어느정도 배웠다면, 이를 깎는 단계라고 생각하시면 될 것 같습니다. 가장 큰 차이점은 RL을 업데이트 할 때 real 데이터를 섞어서 가팅 업데이트 하는 것입니다. 이를 통해서 시뮬레이션에서 행동을 배우며 real world 데이터를 통해 얻은 현실 적응력을 잃지 않는다고 합니다.
시뮬레이션 상의 reward를 최대화하는 방향으로 policy를 업데이트 하는 RL loss, real-world 데이터에 대한 supervised loss (Real SFT loss)를 함께 사용하여 아래와 같이 가중합된 loss 형태로 objective를 최적화합니다.
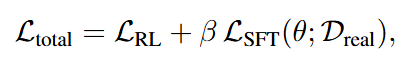
이를 통해 정책이 시뮬레이션에 과적합되며 real world 성능이 무너지는 catastrophic forgetting문제도 해결할 수 있을 뿐 만 아니라 wide range의 RL이 가능하다고 합니다.
Experiments
실험은 아래의 세가지 research question들을 답하는 식으로 진행되었습니다.
- Does RL-Co improve real-world performance compared to training with real-world data only or SFT-based sim–real co-training?
- How do the individual components in our two-stage framework contribute to the final performance?
- To what extent can our method reduce the amount of required real-world demonstration data?
해당 실험을 진행하기 위해 현실 데이터만을 통해 SFT한 policy와 SFT만을 활용한 sim-real co-training을 baseline으로 삼았다고 합니다.
Experimental Setting
Task는 panda로봇을 사용해 총 4가지 task를 진행했다고 합니다. 간단한 pick and place, 3개의 큐브중 자연어 명령에 맞는 큐브를 밀어야 하는 Push Cube via Instruction, Open drawer, Close drawer입니다.

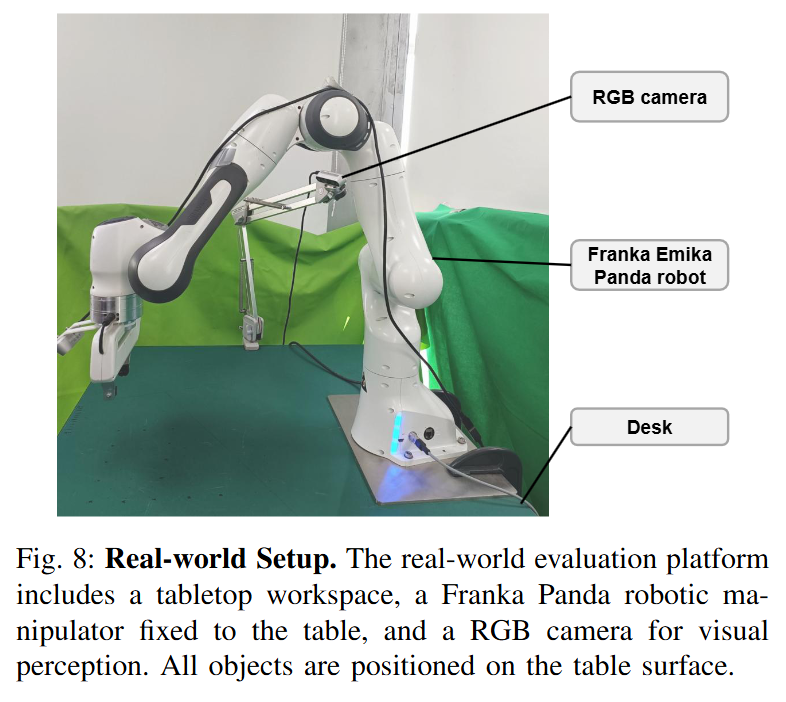
시뮬레이션 환경은 ManiSkill을 통해 제작했고, camera viewpoint와 scene layout은 동일하게 세팅한 뒤 진행했다고 합니다. 이 때 저자들은 photorealistic simulation이나 배경과 같은 고도화된 visual reconstruction대신 essential한 object mesh와 geometry grounding만 신경썼다고 합니다. 사용된 asset은 아래 fig.10에 정리돼있습니다. Sim, Real 모두 RGB input을 observation으로 받아 EE-delta space에서 제어됐다고 합니다. Sim-to-real gap을 줄이는데는 joint space가 압도적으로 유리하다는 최근 연구 결과를 봤었는데, 실험이 안 된 것인지 co-training에서는 다른건지, EE-delta space에서 진행됐습니다. 모든 실험을 진행할때 camera pose와 robot의 initial pose는 고정됐다고 합니다.
Dataset Generation
Real-world demonstration의 경우 모든 task에 대해서 3D SpaceMouse를 사용해 현실에서 데이터를 취득했고, object들은 매 에피소드 마다 랜덤한 위치에 두었다고 합니다. Task에 따라 20개에서 50개 정도의 trajectory를 생성했고, D_real로 정의합니다.
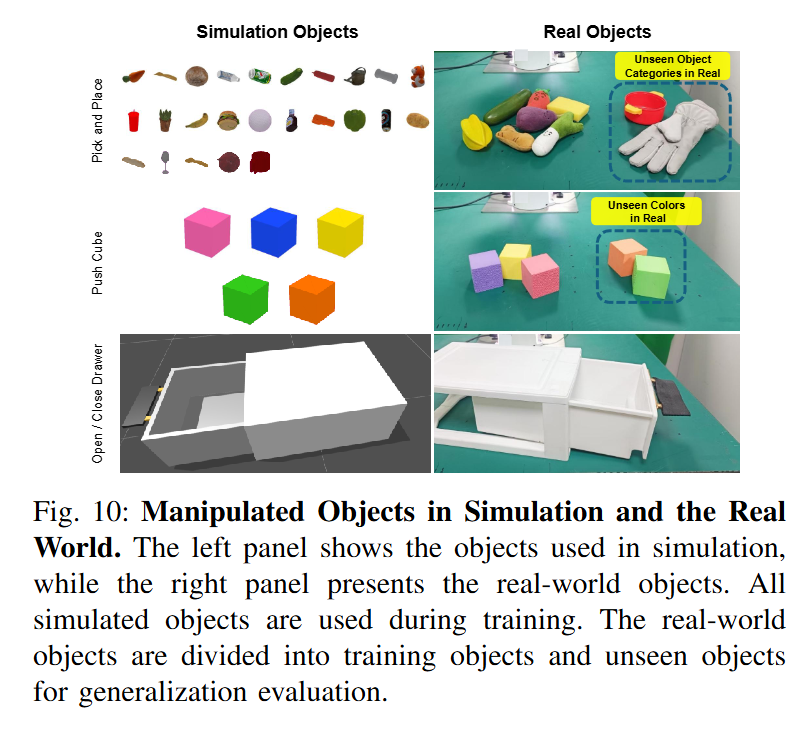
Simulation demonstration은 MimicGen을 사용하여 teleoperation을 수행하는 대신 real world의 trajectory를 replay해서 base를 만든 뒤 scale up을 진행했다고 합니다. 이후 MimicGen의 결과물들 중 task 수행에 필요하지 않은 free-space ee motion은 pruning 한 채로 구성했고, D_sim으로 정의합니다. Initial state의 변화는 아래 사진처럼 진행됐습니다.

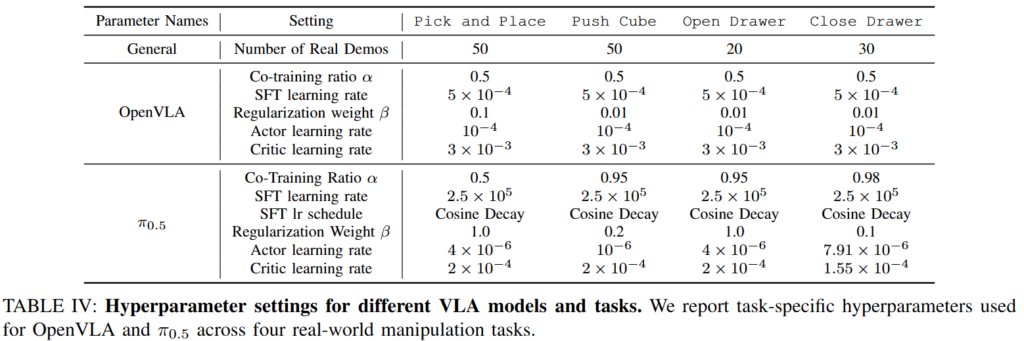
Policy의 경우 next token prediction 형태의 Open-VLA와 flow matching 기반의 pi-0.5를 가지고 진행했습니다. 아래에 training detail을 볼 수 있습니다. RL은 PPO 방식으로 진행됐고, 대부분 목표 객체에 대한 is grasped로 reach에 대한 dense reward를 구성하고 목표 상태에 대한 is success로 sparse reward를 크게 부여했습니다. Drawer의 경우 대상 객체의 마찰력을 통해서 reward를 설계했다고 합니다.
Main Results
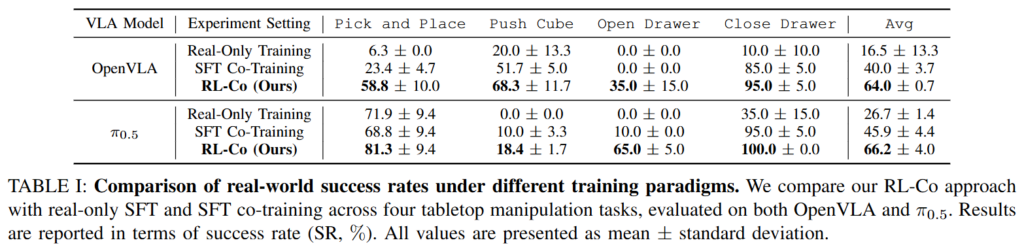
결과를 보면 real-only training을 가지고 finetuning 했을때는 확실히 성능이 낮은것을 볼 수 있습니다. Co-training을 하는것이 대부분 도움이 되고, RL-Co 방식이 최종적으로 제일 좋은 성능을 내는것을 볼 수 있습니다. 다만 pi-0.5가 대부분 잘하지만 pick and place의 경우 오히려 시뮬레이션 데이터가 성능을 드랍시킨 점이 흥미롭고, OpenVLA도 대부분 박살나있지만 language instruction을 따라야하는 push cube에서는 오히려 성능이 좋은 것 같습니다. Token based 방법이라 그런가? 싶기도 한데 좀 흥미로운 결과입니다.
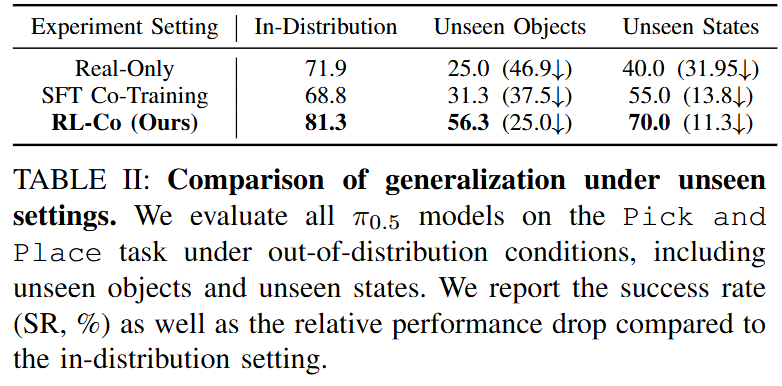
Unseen 환경에 대한 일반화 성능 검증입니다. Unseen Object와 Unseen state에 대해 성능 하락을 잘 방어하는 모습을 보여줍니다. 시뮬레이션에서 RL을 진행했지만, 현실에서의 적응 능력을 배울 수 있다는 것을 증명한 실험이라고 보면 될 것 같습니다.
Impact of Different SFT Co-Training Ratios α and RealWorld Regularization Weights β
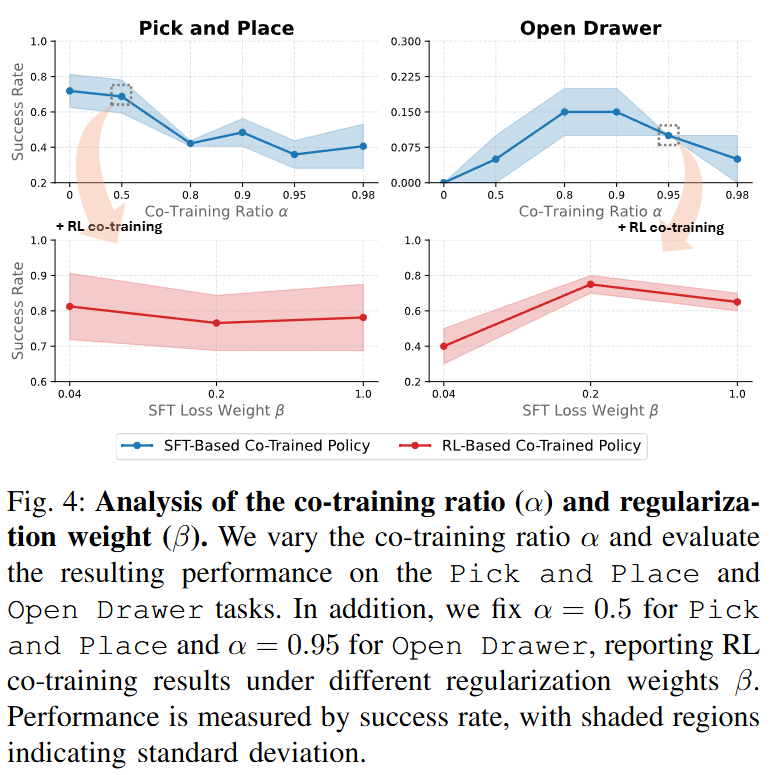
Pick and place와 open drawer task에 대해서 실험이 진행되었습니다. Pick and place의 경우 real world 데이터로부터 이미 퍼포먼스가 좀 나오기 때문에 오히려 시뮬레이션 데이터가 많아질수록 성능이 하락했다고 합니다. 반대로 Open drawer같이 좀 어려운 task에서는 RL을 통해 얻은 지식이 더 가티있어졌다고 합니다. SFT 진행시의 데이터 비율은 task에 따라 다르고, 어려운 task일수록 alpha를 증가시키는 것이 효율적이라고 볼 수 있을 것 같습니다. RL시의 regularization weight의 경우 시뮬레이션 데이터가 의미있는 구간에서 0.2 정도가 효율적이었고, 1.0 ( real data BC loss 없음)의 경우에도 의미있는 결과가 나온만큼 시뮬레이션 데이터가 중요한 task에서는 RL의 힘이 세다고 보면 될 것 같습니다.
Ablation Study
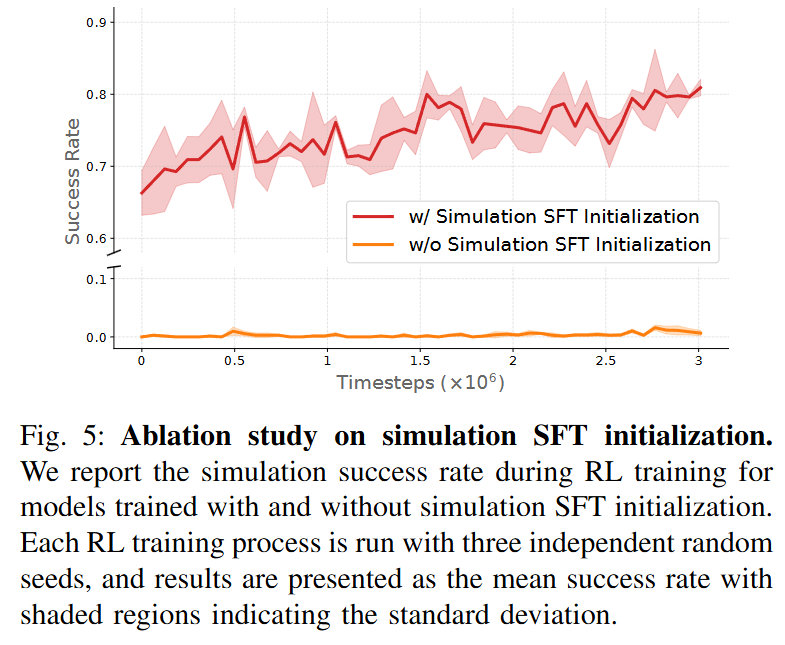
Stage 1이 필요한가?에 대한 ablation입니다. 시뮬레이션이 포함된 SFT 없이는 시뮬레이션 상에서 3백만 timestep동안에도 의미있는 결과를 내지 못 한 것을 볼 수 있습니다. Warm-up stage (base policy 학습)에서 의미있는 exploration을 하기 위해서는 시뮬레이션 데이터가 필수라고 생각하면 될 것 같습니다.
다음은 Stage 1과 Stage 2에대한 real-training ablation입니다. Real data또한 stage 1과 2에서 모두 중요하다고 생각하면 될 것 같습니다. Sim to real gap이 정말 큰 벽입니다. 다만 여기서도 Stage 1에서의 부재가 더 큰 하락을 유도하는 만큼 RL을 시작하는 agent가 가지는 능력이 전체 파이프라인에서 굉장히 중요하다는 것을 알 수 있습니다.

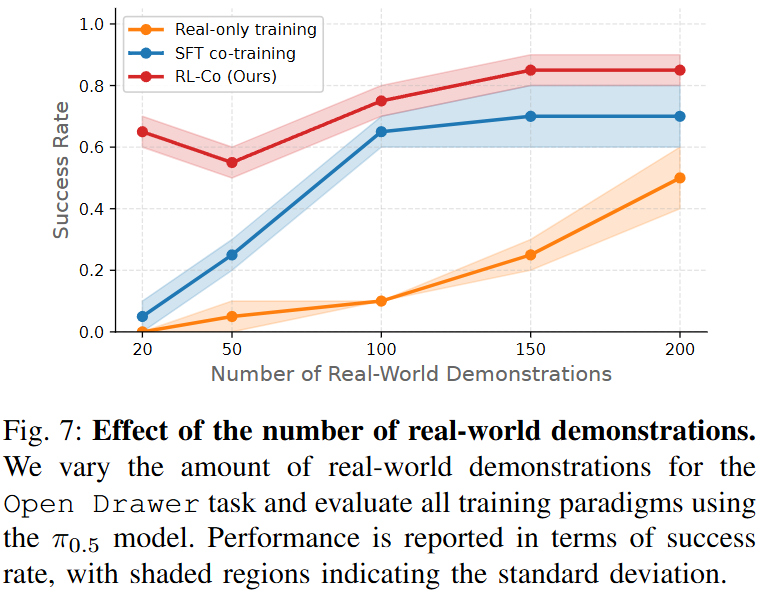
마지막으로는 real-world demonstration의 숫자에 대한 내용입니다. Open-drawer task를 기준으로 리포팅 된 결과이고, real-only training도 200개정도 찍으면 나름 SR이 오르고 co-training도 100개정도 모으면 나름 성능이 나오지만, RL-Co를 진행했을 때 소수의 데모 만으로도 이미 높은 성능이 나오고, real demo는 갯수가 200개까지밖에 없어서 천장을 알 수 없지만 SFT 기반의 co-training보다는 천장또한 높은 것을 알 수 있습니다.
영규님 좋은 리뷰 감사합니다.
해당 방법론 중, Stage 2에서 시뮬레이션에서 행동을 배우며 real world 데이터를 통해 얻은 현실 적응력을 잃지 않는다고 하셨는데, 이는 real-world에 대한 SFT loss를 함께 사용하기 때문인가요? 해당 과정의 real-world 데이터는 stage 1을 학습할 때 사용했던 데이터가 다시 사용되는 것인지 궁금합니다.
시뮬레이션 데이터가 중요한 task는, 작업의 성능이 낮은 케이스를 의미하는 것으로 이해하면 될까요?
해당 방법론은 unseen object와 unseen state에 일반화 성능을 평가하였는데, 작업에 대해서는 일반화가 불가능한 것인지 궁금합니다.
마지막으로, Fig. 7의 그래프에서 real-only training 방식의 경우 성능이 오르는 경향이 있는데, 200으로 한정시킨 것이 아쉬운 것 같습니다. 이에 대해 저자들이 200개로 제한한 이유가 따로 있는지 궁금합니다. (그래도, 해당 방법론이 적은 real데이터에서는 굉장히 효과적이라는 것을 확인할 수 있어 유의미한 것 같습니다.)
안녕하세요 승현님 댓글 감사합니다.
첫 질문에 대해서는 real world 데이터와의 SFT loss (베타 항) 때문이 맞습니다. stage 1 학습 때 데이터가 다시 사용됩니다.
시뮬레이션 데이터가 중요한 task는 소수의 real world로는 성능이 낮은, 어려운 task라고 생각하면 될 것 같습니다. 그렇기 때문에 시뮬레이션에서 RL을 통해 배운 지식이 추가로 필요한 경우입니다.
보통 문제정의가 real only training이 굉장히 cost가 높기 때문에 현실적으로 하나의 task에 대해서 모을 수 있는 데이터의 상한을 두는 것 같습니다. Real world 데이터를 엄청 늘리면 당연히 제일 좋겠지만, 현실적으로 어디까지가 상식적인 데이터 수집 cost인지를 200개로 정한듯 싶습니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
조금 다른 이야기긴 한데.. Joint space가 sim2real gap을 줄이는데 좋다고 언급하셨는데 이유가 궁금합니다. 각각의 joint들을 전부 고려하게 되면 real에서 발생할 수 있는 motor friction, backlash 등등이 있을텐데 이러한 점을 고려해도 joint space를 사용하는 것이 이점이 있나요?
감사합니다.
안녕하세요 인하님 댓글 감사합니다.
우선 저자들이 Joint space에서 sim2real gap이 줄었다는 것은 실험적으로 발견한 것이라고 합니다. 또한 인하님이 말씀해주신 제어단에서 일어날 수 있는 sim2real gap은 보통 시뮬레이션의 파라미터를 조정하는 식으로 추가로 해소해주는데, 해당 연구에서 직접적인 언급은 없었습니다.