제가 연구하고 있는 분야의 affordance의 실용성을 보이기 위해서는 장기 작업으로의 적용이 필요하다는 생각을 하고 있습니다. 해당 논문은 실제 로봇으로 적용하여, 가구 조립이라는 장기 작업을 수행하는 연구를 다루고 있어서 리뷰하게 되었습니다.
Abstract
가구 조립은 한 팔이 부품을 조작하는 동안 다른 팔이 함께 물체를 지지하고 안정화하는 정밀한 양팔 조작을필요로 하기 때문에 어려운 작업입니다. 이를 수행하기 위해, 로봇은 긴 조립 과정동안 다양한 기하학적 형태의 부품에 맞추어 로봇을 적응적으로 지지 전략이 필요합니다. 따라서 해당 논문은 부가구 부품에서 최적의 지지 및 안정화 위치를 식별하기 위해 적응적 affordance를 학습하는 프레임워크인 A3D를 제안합니다. A3D는 dense point-level의 기하학적 표현을 통해 상호작용 패턴을 모델링하고, adaptive 모듈을 통해 상호작용 피드백을 바탕으로 조립 중의 지지 전략을 동적으로 조정합니다. 저자들은 8가지 가구 유형에 50개의 부품을 포함하는 시뮬레이션 환경을 구축하였으며, 시뮬레이션과 real-world에서 모두 다양한 부품과 가구에 효과적로 일반화 가능함을 보였다고 합니다.
Introduction
로봇을 이용하여 가구를 조립하기 위해, motion planning, assembly pose estimation, RL 기반의 방법론 등 다양한 방향으로 연구가 이루어지고 있습니다. 그러나 이러한 선행 연구들은 여전히 다양한 물체 조립으로는 확장이 어려우며, 싱글 암에만 집중하고 있습니다. 그러나 일반화 가능한 가구 조립은 시각적 이해 뿐만 아니라 양손 조작 능력이 필요합니다. 따라서, 해당 논문을 통해 저자들은 가구 조립을 위한 도전과제 3가지를 제시합니다.
- unseen 가구 조립을 위해 다양한 기하학적 형태의 부품의 기능적 affordance를 이해하고, 적절한 지지 위치 식별
- 장기 조립 과정에 변화하는 동적 지지 전략
- contact-rich(접촉이 많은)한 상호작용 상황에 강인한 제어 기술
저자들은 양팔 조작을 위한 적응적 affordance 프레임워크인 A3D를 제안합니다. 기하학적 인식을 가능하게 하기 위해, A3D는 point마다 행동가능성을 나타내는 표현으로 affordance를 활용합니다. 이를 위해 지지와 안정화에 필요한 local 기하학 정보 뿐만 아니라 특정 행동이 다른 부품을 방해하는 지와 같은 global한 맥락적 정보까지 계층적으로 feature를 추출합니다.
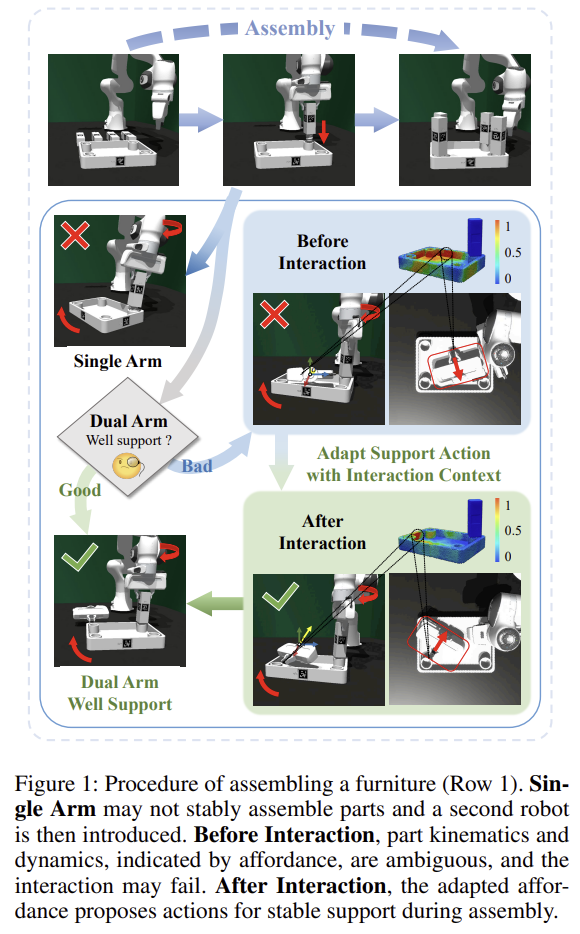
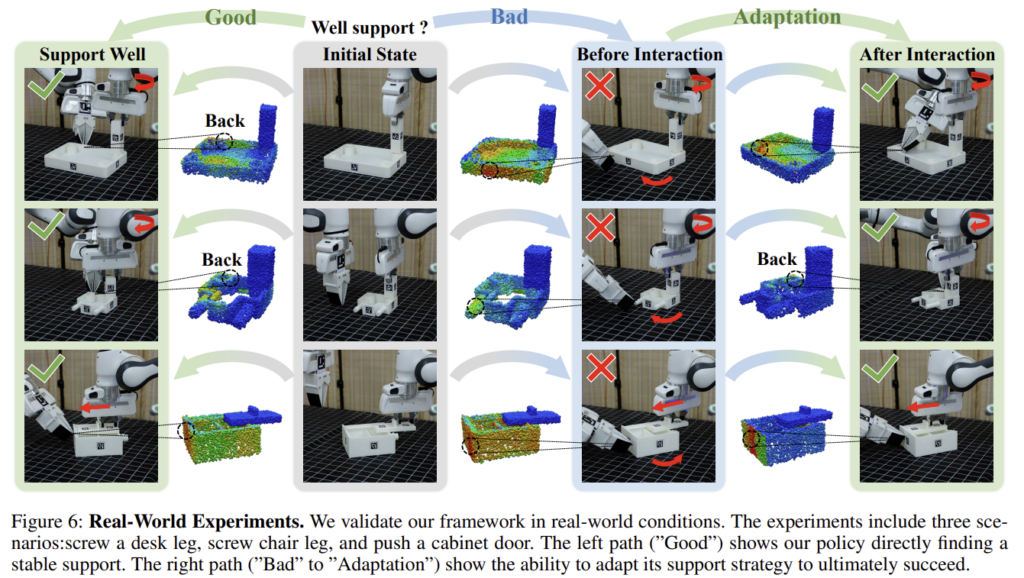
그러나, 정적인 affordance는 관절 위치와 한계 같은 운동학적 정보와 동적 불확실성을 충분히 반영하지 못하며, 이는 잘못된 조작으로 이어질 수 있습니다. 따라서 저자들은 affordance 예측에 상호작용 피드백을 통합하여 조립 전 과정에서 지지 전략을 동적으로 조정할 수 있도록 합니다. 위의 Figure 1의 파란 배경과 초록 배경 그림의 예시를 보시면, 조립할 때 판이 돌아가지 않도록 다른 손이 잡아야 하는데, 상호작용 전에는 잘못된 부분에 그리퍼가 있고, after interaction에서는 대각선 부분을 지지해주는 것을 확인할 수 있습니다.
또한, 기존의 시뮬레이션은 단일 팔 조작에 집중하거나, 한정된 가구 asset을 사용하였으며, 저자들은 FurnitureBench를 확장한 새로운 평가 시뮬레이션을 제안합니다. 8가지 가구 유형에 대하여 50가지 부품과 4가지 조립 과제가 주어지며, 저자들은 시뮬레이션과 real-world에서 정성적/정량적으로 평가하여 제안한 프레임워크의 효과를 검증합니다. 또한, 최대 3번의 적응 과정을 허용하였음에도, 대부분 1번의 상호작용만으로도 성공하였으며, 이러한 실험 결과들을 통하여 제안한 방법론의 강인서오가 효율성을 입증하였다고 합니다.
해당 논문의 contribution을 정리하면
- 다양한 가구 부품에 대해 일반화 가능한 지지 및 안정화 위치를 예측하기 위한 affordance 학습 프레임워크를 제안
- 이전 상호작용에서 얻은 피드백을 바탕으로 조립 과정 중 지지 전략을 동적으로 조정하는 adaptive 모듈 설계
- 8종의 가구와 4가지 과제에 걸친 50개 이상의 기하학적으로 다양한 부품을 포함하는 양팔 협업 조립 시뮬레이션 환경을 구축
- 시뮬레이션과 real-world에서 폭넓은 실험을 통해 제안 프레임워크의 효과를 검증
Method
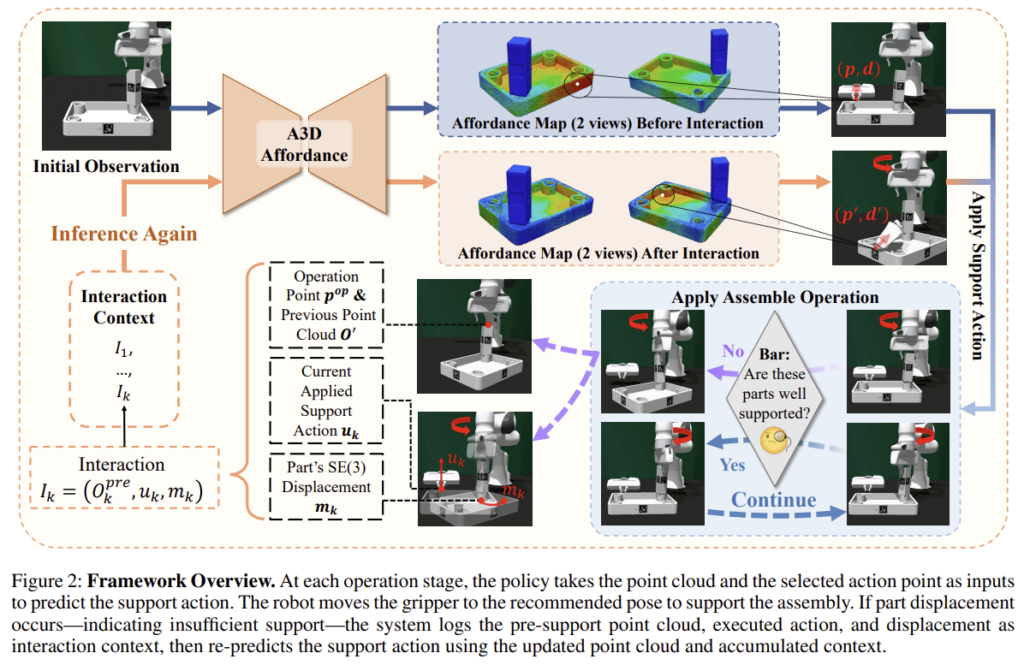
저저자들은 양팔을 이용하여 효율적으로 가구를 조립하는 것을 목표로 합니다. 이때, tool arm은 조립 작업을 수행하고, support arm은 적응적으로 안정화를 위한 지지 작업을 수행하며, 저자들은 support arm에 집중합니다. 위의 Figure 2는 저자들이 제안하는 프레임워크에 대한 그림으로, 크게 2가지 요소로 구성됩니다. 먼저, Support Affordance Module은 시각 관찰 정보로부터 초기 affordance heatmap과 action 방향을 예측합니다. Interaction Context Adaptaion Module은 상호작용 기록의 물리적 피드백을 이용하여 affordance 예측을 조정합니다.
Problem Definition
각 time step t에서 support arm의 안정화 작업u_t을 위한 adaptive policy \pi(u_t|S_t,I_t)를 학습하는 것을 목표로 합니다. observed state S_t=(O_t,p_t^{op})로, O_t는 surface normal이 포함된 3D Point Cloud, p^{op}는 tool arm의 그리퍼가 대상 물체와 접촉한 point를 의미합니다. action u_t=(p^{sp}_t,\mathbf{d_t})로, 각각 suport point와 그리퍼의 방향을 의미합니다. 마지막으로 상호작용에 대한 정보인 interaction context I_t=\{(O_i,u_i,m_i)\}^{t-1}_{i=t-k}는 이전 k 상호작용 단계의 정보를 저장한 것으로, m_i는 base 부품의 변위를 의미합니다. (위의 Figure 2를 보시면, 조립되는 베이스 부품이 움직인 정도라는 것을 확인하실 수 있습니다.) 안정적으로 지지하고 조작하도록 하기 위한 것이라 베이스가 움직인 정도를 저장한 것으로 보입니다. 이러한 관점에서, 저자들은 작업 성공여부 판단에 주요 조작 성공 뿐만 아니라 수행 중 base 부품의 변위가 m_i < \epsilon를 만족하는 것을 성공으로 판단합니다.
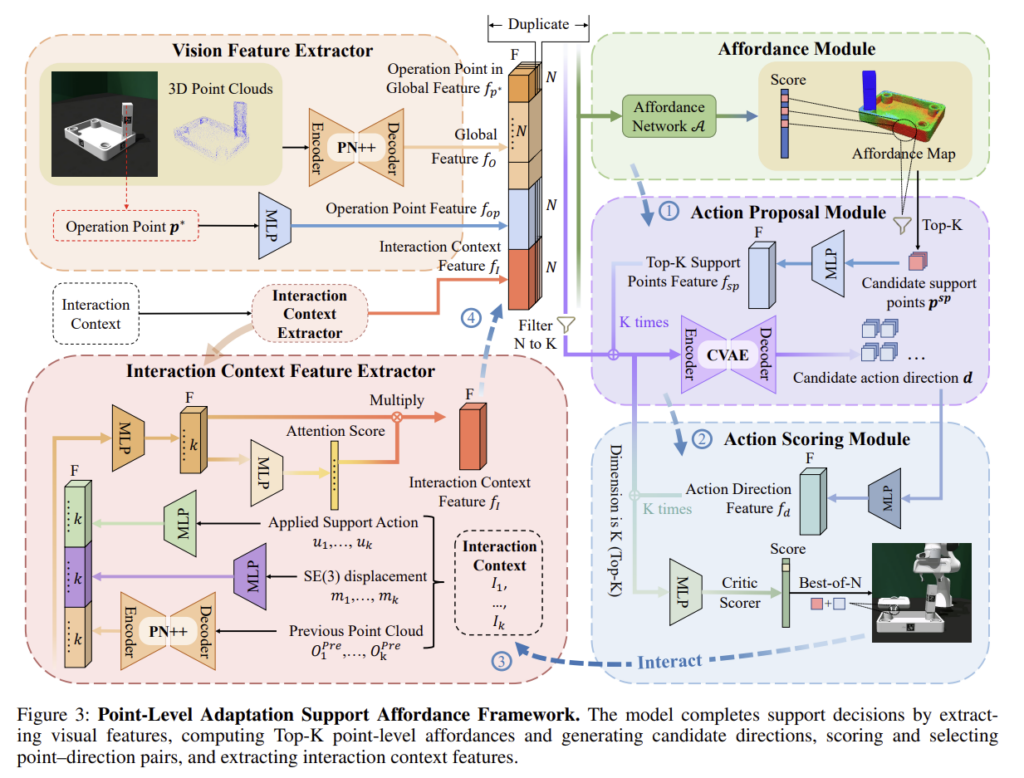
Support Affordance Module
support affordance 모듈은 affordance-proposal-scoring 구조로 이루어집니다. affordance 모듈을 통해 affordance heatmap을 예측하고 상위 K개의 후보 지점을 선택하며, proposal 모듈은 각 지점에 대해 여러 후보 방향을 생성하고, scoring 모듈을 통해모든 지점과 방향 쌍에 대한 점수를 구하여 최적의 지지 작업에 대한 액션을 선택하게 됩니다.
구체적으로, 먼저 PointNet++ 모델을 이용하여 point cloud O에서 point-wise features f_{p_i} \in \mathbb{R}^{128}를 생성합니다. shared MLP를 이용하여 작동점과 지지점을 f_{op},f_{sp}\in\mathbb{R}^{32}, 그리퍼 방향과 베이스의 변위를 f_{\mathbf{d}},f_{m}\in\mathbb{R}^{32}로 인코딩합니다. 이후 작동점의 feature f_{p^{op}}와 f_{p_i}, 작동점의 임베딩 f_{op}과 interaction context f_I를 결합하여 affordance module \mathcal{A}를 통해 각 point에 대한 affordance score a_p \in [0,1]를 예측합니다. 이렇게 구한 score를 기준으로 top-K개의 point를 support 후보로 선정합니다.
action proposal 모듈\mathcal{P}는 conditional VAE를 사용하며, 작동점의 feature f_{p^{op}}와 앞서 선정된 support 후보 점의 feature f_{sp}, 작동점과 support 지점의 임베딩 f_{op}, f_{sp}를 f_{I}와 함께 인코더로 처리하여 latent vector z \in \mathbb{R}^{128}을 생성한 뒤, 디코더를 이용하여 방향 벡터 \mathbf{d}를 생성합니다.
마지막으로 action scoring 모듈\mathcal{S}는 action scorec \in [0,1]를 예측하며 이는 성공 확률을 의미합니다. 즉, c가 높다는 것은 support 를 통해 작업을 성공적으로 수행할 확률이 높다는 것을 의미하게 됩니다.
Interaction Context Adaptation Module
저자들은 시각 정보만으로는 충분하지 않다고 판단하여, support 작업에 대한 피드백을 기록하였다가 이 기록으로부터 특징을 추출하고, 현재의 시각적 특징에 결합하여 다시 affordance-proposal-scoring 모듈을 수행하도록 합니다. 상호작용에 대한 맥락 정보 I_t=\{(O_i,u_i,m_i)\}^{t-1}_{i=t-k}는 각 과거 단계의 정보들로, 위의 Support Affordance Module과 동일한 인코더를 활용하여 특징을 추출하고 결합합니다.
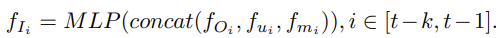
경량 attention 매커니즘을 사용하여 이전 상호작용 정보를 모으며, 이전 단계의 interaction context feature f_I는 MLP를 통해 attention 가중치 w_i를 계산하고, 최종적인 interaction context 은 아래의 수식을 통해 구해집니다.
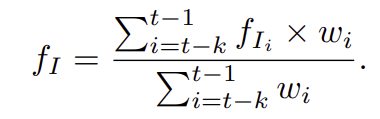
Training Loss
[Action Scoring Loss]
action scoring 모듈은 성공 점수 \hat{r}을 예측하며, 실제 점수 r과 MSE loss를 이용하여 학습됩니다. 실제 점수는 물체의 변위 g_d와 작업 성공에 대한 항 g_c를 결합하여 구해지며, 이를 가중합 하고 0~1 범위로 clamp하여 구해집니다.
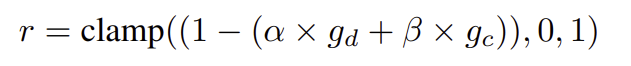
- \alpha, \beta: 균형을 위한 가중합 파라미터
[Action Proposal Loss]
예측된 support 방향\mathbf{d}과 GT 방향 \hat{\mathbf{d}}가 일치하도록 하기 위하여 cosine similarity loss사용하고, latent vector z가 표준 정규분포를 따로도록 정규화 하기 위해 KL-Divergence 항을 추가하여 아래의 식으로 loss를 구합니다.
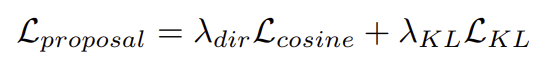
- \lambda_{dir}, \lambda_{KL}: 균형을 위한 가중합 파라미터
[Affordance Prediction Loss]
각 포인트의 affordance score a는 동작이 성공하 확률로 정의되며, 이는 다시 action scoring 모듈을 통해 평가됩니다. 구체적으로, 각 포인트 p_i에 대해 N개의 support 방향을 샘플링하고, 이를 action scoring 모듈로 평가하여 N개의 action score를 얻은 뒤, 상위 K개의 평균을 계산합니다.
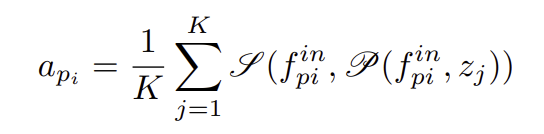
이렇게 구한 action scorea_{pi}와 예측된 affordance score \hat{a}_{pi}에 L1 loss를 적용하여 loss를 구합니다.
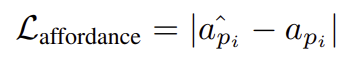
Experiments
Setup
저자들은 IssacGym상의 FurnitureBench를 기반으로 확장하였으며, 양팔 작업이 가능하도록 하고, 카메라 구성을 수정하여 두번째 팔의 지지 및 안정화에 대한 평가가 가능하도록 하였다고 합니다. 또한, 일반화 성능을 평가하기 위해 기하학적 다양성을 늘려 asset 수를 증가시켰으며, 특정 가구 유형에 대하여 각 유형에 변형을 포함하여 작업별로 1만개의 샘플을 수집하였고, test는 학습에 보지 못한 가구 유형만을 이용하여 평가하였다고 합니다. 저자들은 Screwing, Insertion, Extraction, Picking 4가지 기본 조립 작업에 대한 성능읖 평가하였으며, success rate을 평가 지표로 활용합니다. 참고로, 성공 여부는 target 부품이 원하는 자세에 도달해야 함, 베이스 부품의 변위가 안정적으로 유지되어야 합니다.
또한, 적응적으로 물체를 지지한다는 새로운 문제를 다루는 만큼, 직접적으로 베이스라인으로 삼을 수 있는 방법론이 없으므로, support 지점과 방향을 무작위로 선택하는 random, 기하학적 규칙에 따라 선택하는 heuristic 방법론과, 모방학습 기반의 DP3, Gemini 2.5 pro를 이용하여 support 지점과 동작을 추론하는 LLM-Guided 방식을 이용하여 비교 실험을 진행하였다고 합니다.
Results
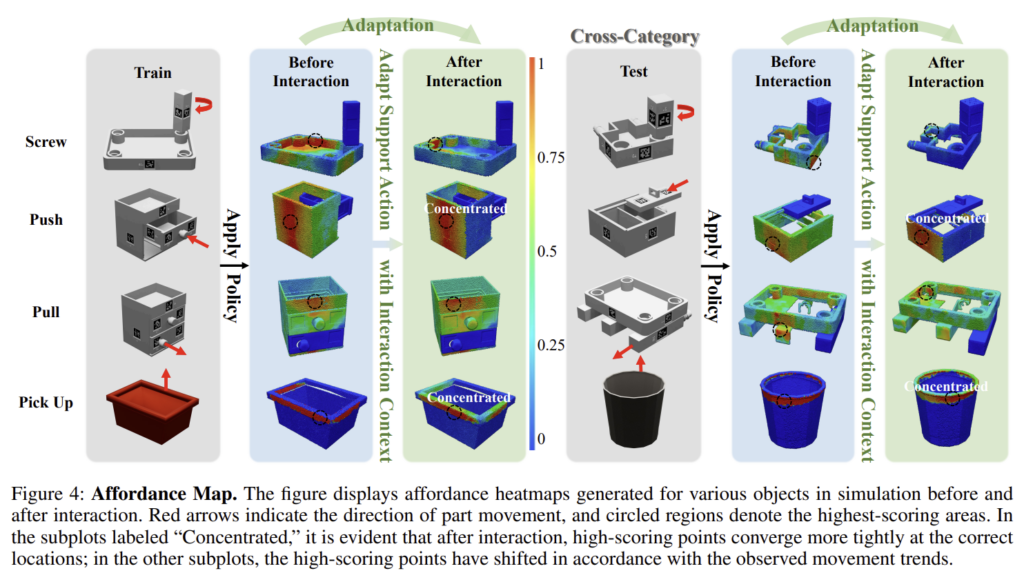
위의 Figure 4는 학습된 객체(train)와 새로운 객체(test)에 대해 4가지 작업에 대한 상호작용을 이용한 adaption 전 후의 affordance 예측 결과입니다. 상호작용이 이루어지기 전에는 affordance 영역이 모호하였으나, 상호작용을 통한 피드백을 활용한 결과 더욱 타당한 위치에 집중하는 것을 확인할 수 있습니다. 특히 학습에 사용되지 않은 객체로 이루어진 test에서도 적용이 가능함을 확인할 수 있습니다.
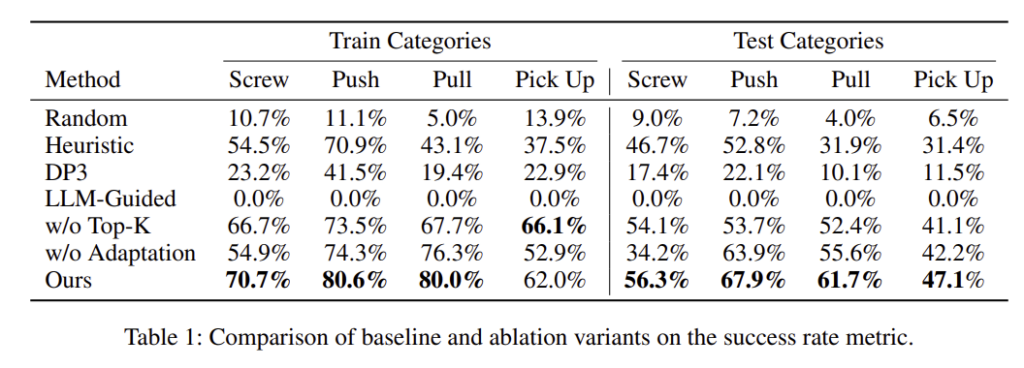
Table 1은 이에 대한 정량 적 결과로, 제안한 프레임워크가 모든 베이스라인 방식과 비교하였을 때 효과적이라는 것을 확인할 수 있습니다. 저자들은 heuristic 방식은 random 방식보다 효과적이지만, 각 작업과 객체마다 수동으로 규칙을 설계해야하며, DP3는 다양한 형상과 범주에 대한 이해 능력이 부족하였다고 분석합니다. 특히, LLM-Guided 방식의 경우, 성공률이 0%로, 이에 대해 저자들은 3차원 기하정보와 행동에 대한 이해가 부족하기 때문이라고 분석합니다. w/o Top-K와 w/o Adaptation은 ablation study에 대한 결과로 보시면 됩니다.
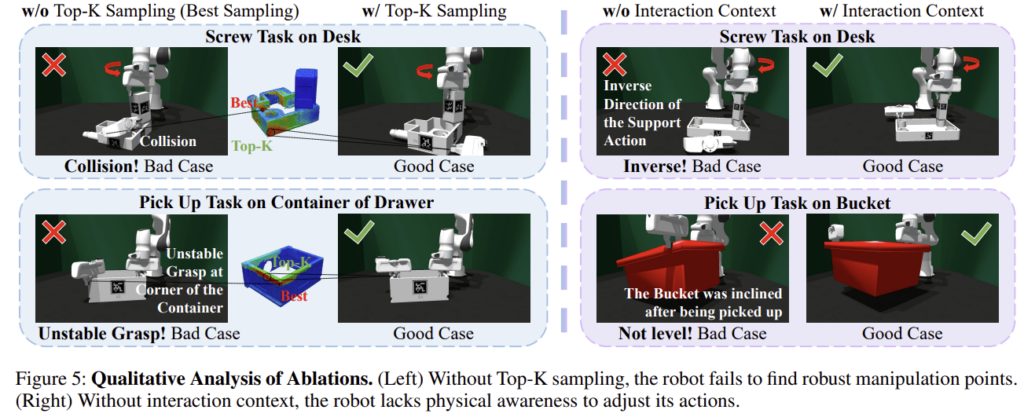
위의 Figure 5는 ablation study에 대한 정성적 결과로, 각 케이스의 2가지 실패 케이스를 나타낸 것 입니다. Top-K sampling은 단일 최고 score의 지점만 고르는 대신 여러 후보를 남겨 두어, 실제로 더 좋은 방향과 더 안정적인 지지 행동을 찾을 가능성을 높입니다. 왼쪽 케이스들이 이에 해당하며, Best 지점은 collision이 발생하거나 불안정한 파지가 이루어지지만, Top-K개를 통해 안정적으로 지지가 가능해진다는 것을 나타냅니다.
Adaptation 은 이전 상호작용에서 발생한 기울어짐, 힘 방향, 나사산 방향 같은 물리적 정보를 반영해, 현재 지지 전략을 수정하도록 돕습니다. Figure 5의 오른쪽 케이스들로, 위의 케이스는 나사가 도는 방향을 반영하지 못하여 잘못된 위치를 지지하도록 하는 케이스이며, 아래는 바구니가 기울어지게 지지한 케이스입니다. 이러한 피드백을 반영하므로써 모델이 자동으로 support 지점을 조정하여, 작업을 성공하도록 합니다. 즉, Top-k samppling은 탐색 공간을 넓혀 더 나은 행동을 찾게 하는 역할, adaptation은 실제 물리 결과를 반영해 행동을 보정하는 역할을 담당하는 것을 확인할 수 있습니다.
Real-world
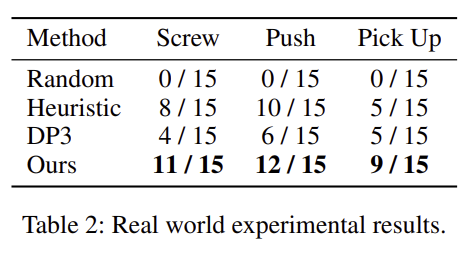
저자들은 Franka Panda를 이용하여 real-world에서 가구 조립에 대한 평가를 수행하였습니다. 3개의 realsense 카메라를 이용하여 3D point cloud를 수집하고, 로봇은 RoS를 이용하여 컨트롤하였다고 합니다. Figure 6은 adaptive affordance 예측 결과와 상호작용에 의한 피드백 결과를 모두 나타낸 것 입니다. Table 2는 real-world에서 3가지 작업에 대하여 15번 시도에 대한 성공여부를 기록한 것으로, 정량적 결과를 통해 저자들이 제안하는 A3D 파이프라인이 실제로 효과가 있다는 것을 입증하였습니다.