안녕하세요. 이번에 리뷰로 가져온 논문은 Efficient Motion-Aware Video MLLM라는 논문입니다. 압축 비디오 안에는 이미 I-frame, P/B-frame, motion vector 같은 구조가 있고, 그 안에들어 있는 motion에 대한 힌트(?)를 활용함으로써 모든 프레임을 일일이 사용하는 방식보다 좀더 효율적으로 비디오를 처리하면서도 모델이 motion을 더 잘 이해할 수 있도록 하는 방법을 연구한 논문이라고 보시면 좋을 것 같습니다.
바로 리뷰 시작하도록 하겠습니다.
Introduction
기존 Video MLLM 흐름에 대해서는 잘 모르지만 저자가 언급하길 대부분 기존 연구같은 경우애는 비디오에서 프레임을 일정 간격으로 샘플링한 뒤 이를 이미지 encoder로 각각 처리하고 그 결과를 시간축으로 이어붙여서 LLM에 넣는 방식이 많다고 합니다. 근데 여기서 저자들은 비디오는 이미지랑은 다르게 움직이는 정보가 중요한데 기존 방식 같은 경우는 이러한 비디오가 가지는 움직임 정보를 직접적으로 다루는 구조는 아니라고 합니다.
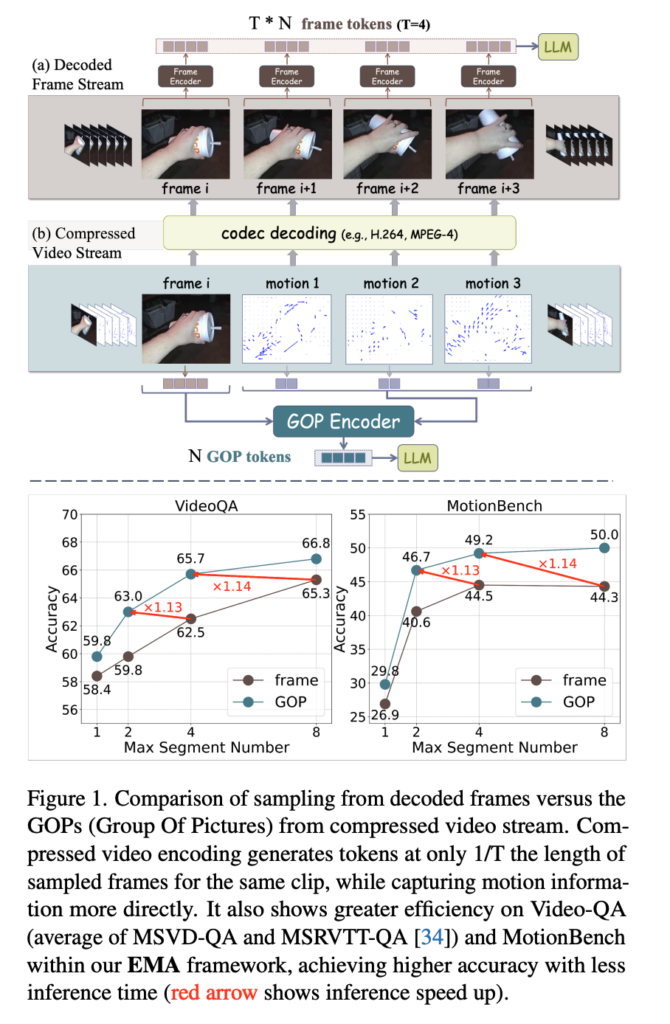
위 예시처럼 컵을 들고 있는 짧은 비디오를 생각해보면 프레임 하나만 봐서는 컵이 올라가는지 내려가는지 알기 어렵습니다. 결국 이론 motion정보를 파악할라면 보려면 좀더 촘촘하게 프레임을 샘플링해야 하고 그러면 비쥬얼 토큰 수가 많아져서 계산비용이 늘어나게 됩니다. 물론 기존에도 token compression이나 인접 프레임 사이의 중복을 활용해서 중복제거를 하는 인코딩전략을 활용해서 효율을 높이려는 시도들은 있었다고는 하지만 저자들은 이러한 중복성은 애초에 인코딩 이전 단계에서부터 줄일 수도 있다라고 주장합니다.
여기서 저자들은 압축된 비디오에 들어있는 정보를 활용하고자 합니다. H.264 같은 코덱에서는 모든 프레임을 RGB로 각각 독립적으로 저장하지 않고 일부 I-frame만 실제 RGB 정보로 저장하고 나머지 P/B-frame은 레퍼런스 프레임 기준 모션 벡터와 residual 정보로 분해되서 가볍게 압축이 이루어지게 된다고 합니다. 그리고 복원시에는 대부분 프레임은 I-frame을 참조해서 여기에 해당하는 모션 벡터와 와 residual을 적용해서 복원이 이루어진다고 합니다.
그래서 저자들은 이런 압축된 비디오의 애초에 중복 프레임들이 제거된, 더 가벼운 모션 벡터 형태들로 저장되어있는 이러한 구조를 활용하고자 합니다. 좀더 구체적으로 말씀드리면 수는 적지만 실제 RGB정보를 담은 정보량이 많은 I-frame이랑 I-frame보다는 수는 더 많지만 정보량이 sparse한 모션 벡터가 들어있는 이런 구조를 활용하고자 합니다.
정리하면 기존 방식은 frame을 많이 넣어야 motion을 보지만 비효율적이고 GOP 기반 입력은 더 적은 token으로 더 좋은 motion 이해를 한다정도로 이해하시면 좋을 것 같습니다. (여기서 GOP(Group of Pictures)는 하나의 I-frame과 그에 종속된 여러 P/B-frame으로 이루어진 압축 비디오의 기본 단위라고 합니다.)
사실 압축 포맷 자체가 중복을를 줄이기 위한거라고 생각하면 해당 포맷을 모델의 입력으로써 사용하는 것이 효율적인 방식이라고 생각합니다. 근데 이 모션벡터가 비디오를 잘 압축하기 위해서 뽑아낸 정보이기때문에 이 정보가 실제 모델이 시맨틱하게 모션을 이해하기에 좋은 정보와는 약간의 차이는 있을 수 있을 것 같긴합니다.
Method
이 논문의 방법론은 크게 두 부분으로 나눠서 볼 수 있는데 첫 번째는 compressed-domain video input을 처리하는 EMA 모델 구조이고, 두 번째는 motion understanding을 평가하기 위해서 저자들이 새롭게 제안한 MotionBench 입니다. 먼저 모델부터 설명드리도록하겠습니다.
Compressed-domain Video Input
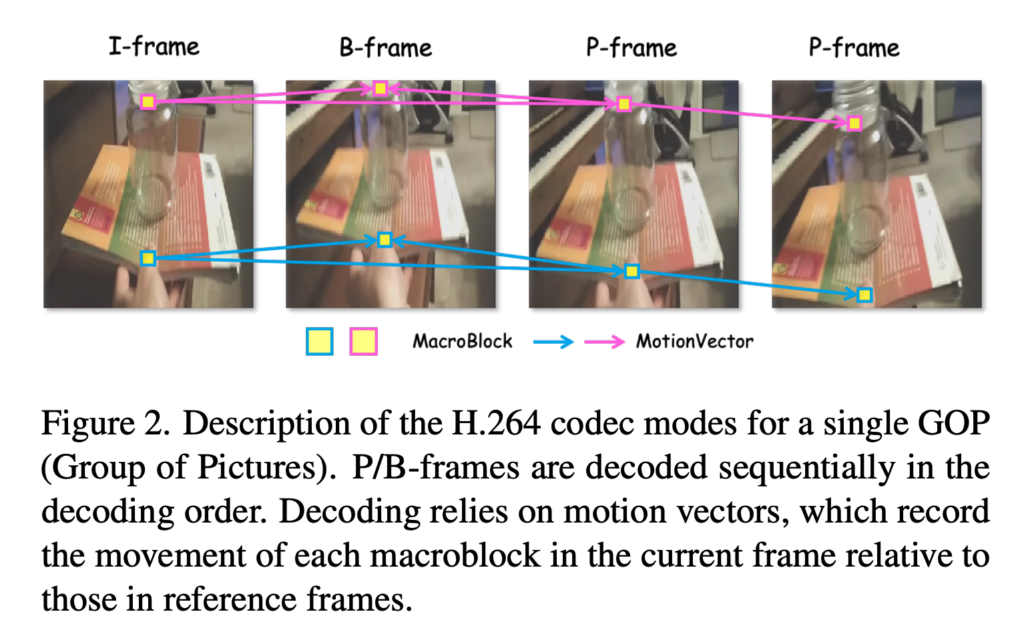
저자들은 비디오를 H.264 압축 기준으로 보고 프레임을 I-frame, P-frame, B-frame 으로 나눠 설명합니다. I-frame은 모션벡터가 없는 프레임으로 단순하게 rgb 키 프레임이라고 생각하면 좋을 것 같습니다.(압축 비디오안에서 다른 프레임 참조 안하고 독립적으로 인토딩된 프레임 ) 반면에 P/B-frame은 인접한 참조 프레임과 모션 벡터, residual을 이용해 현재 프레임을 구하게 됩니다. 여기서 B-frame같은 경우에는 인점합 참조 프레임이 과거가 아니라 미래 프레임이 될 수 도 있는데 설명은 과거 프레임을 참조프레임이라고 생각하고 설명드리도록 하겠습니다. 논문에서는 모션 벡터를 현재 프레임의 macroblock(여기서는 4×4 정도)이 인접한 참조 프래임의 어디에 대응하는지를 나타내는 대표 이동량으로 정의하고 residual은 실제 매크로블록과 예측된 매크로블록 사이의 예측 오차를 의미한다고 합니다. 좀더 수식적으로 설명드리면 아래와 같습니다.
일단 인점한 참조 프레임 안에서 현재 이 블록이 어디서 왔으면 가장 잘 설명되는지를 찾고 해당 블록과 현재 플록의 위치 차이를 아래차람 정의한다고 합니다.
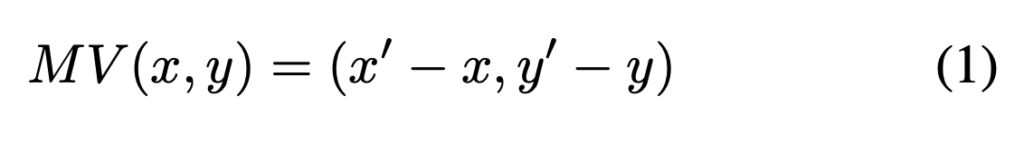
현재 프레임의 실제 픽셀 값이P(x, y) 이고,motion vector를 이용해 참조 프레임으로부터 예측된 픽셀 값이 P'(x, y) 라면 residual은 아래처럼 정의됩니다.
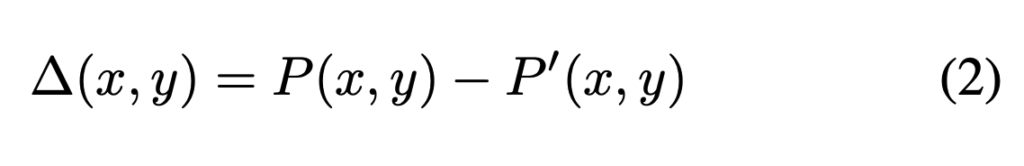
논문에서는 자세하게 나와있지 않지만 실제 참조 프레임에서 현재 프레임까지 넘어오는 과정에서 조명변화나 이런게 있을 수 있기 때문에 실제 현재 프레임과 참조 프레임 기준 모션벡터를 통해 움직인 결과의 차이를 보정하기위해 구하는게 아닐까 싶습니다. 그래서 최종적으로 아래와 같이 복원됩니다.
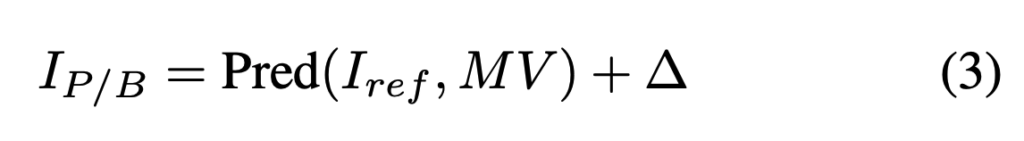
그리고 저자들은 비디오 입력을 프레임 시퀀스단위로 안보고 GOP 단위로 처리합니다. 각 GOP 안에서 저자들은I-frame의 RGB 값 P/B-frame들에서 샘플링한 forward motion vector를 가져와 아래 처럼 하나의 compressed video segment를 구성합니다.

여기서 N은 GOP 개수라고 보시면되고 M은 각 GOP 안의 모션벡터 프레임 개수로 보시면 됩니다.
Motion-aware GOP Encoder
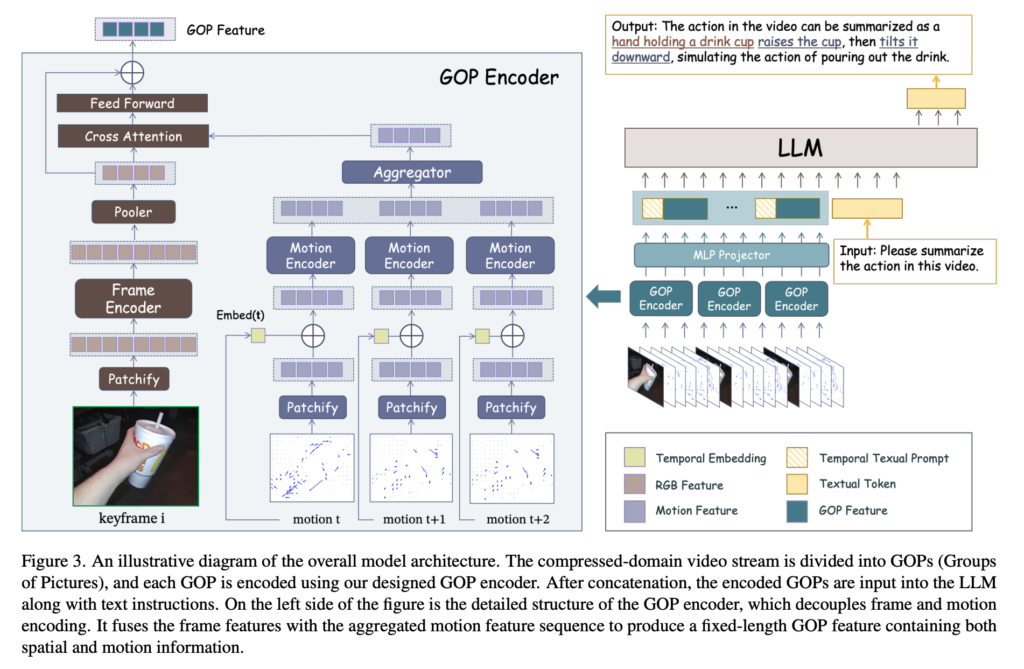
이제 구성된 compressed video segment가 GOP 인코더에 들어가게 되는데 해당 인코더에 대해서 자세하게 설명 드리도록 하겠습니다. 이 encoder의 목표는 한 GOP 안의 RGB + motion 정보를 single frame 정도의 token 예산 안에 최대한 잘 포함시키도록 하는 느낌이라고 보시면 좋을 것 같습니다.
자세하게 설명드리면 일단 저자들은 각 GOP 안에서 frame과 motion을 분리해서 인코딩합니다.
먼저 I-frame은 vision encoder Enc_I로 처리되고 adaptive pooling을 통해 token 수를 줄입니다.
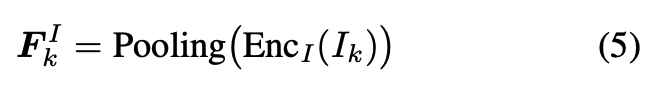
그 다음 모션 벡터 같은 경우는 MV_{(k,t)}들도 patchify된 뒤 여기서 모션 시퀀스 안의 시간 순서 temporal 정보를 유지하기 위해 learnable한 positional embedding이 더해지고 motion encoder Enc_{MV}를 통과하게됩니다.
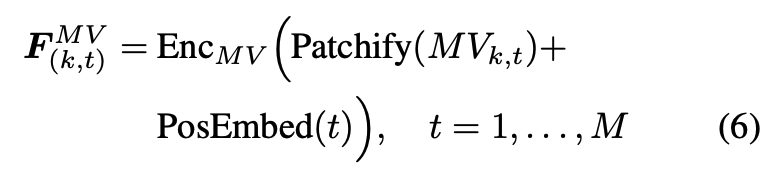
이 후 GOP 안의 motion feature들은 temporal 축에 대해서 mean pooling적용해서 하나의 motion summary로 합치고
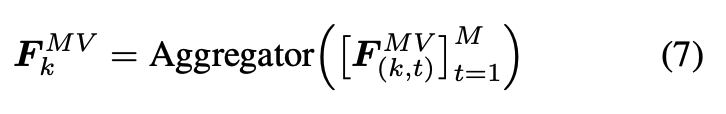
그 다음 이 motion summary를 프레임 feature(i-frame 피쳐) 위에 cross-attention으로 붙이는 식으로 구성되어있습니다.
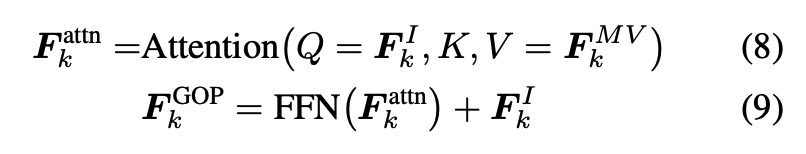
프레임 feature가 쿼리가 되고 모션 feature가 키, 밸류로가 들어가서 각 spatial token이 자신과 관련된 모션 정보를 끌어오는 구조라고 보시면 좋을 것 같습니다.
supplementary까지 보면 RGB frame encoder 같은 경우는 SigLIP-so400m, motion encoder는 256 디멘젼 피쳐를 처리하는 2-layer transformer를 사용한다고 합니다. 모션 벡터 같은 경우는 96×96 의 2D 맵으로 한번 전처리를 해주고 그다음 7×7 패치로 처리하여 인코딩 한다고 합니다.
각 GOP는 고정된 길이의 GOP feature로 바뀌고 MLP를 거쳐 visual token으로 변환되고 그리고 각 GOP 앞에는 Segment k 같은 이번에는 GOP 단위에서 시간 축으로 temporal prompt(TP)가 붙어 시간 순서가 LLM에 전달되게끔 설계되어있습니다.
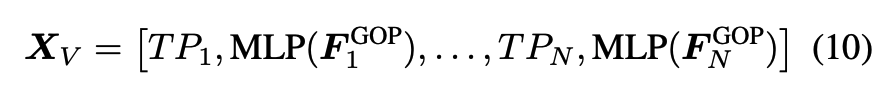
그래서 최종적으로 이 visual token들이랑 인스트럭션이 같이 LLM에 들어가게됩니다.
그리고 학습은 두 단계로 진행된다고 합니다. 1단계는 visual-text alignment로 이미지-텍스트 데이터 LLaVA-558k와 비디오-텍스트 데이터 Valley-702k를 사용해서 두 모달리티간에 정렬 맞추고자 합니다. 여기서 보시면 비디오가 아니라 이미지-텍스트 데이터도 있는데 이 경우에는 해당 이미지를 단일 GOP로 취급하고 이때 motion이 없음을 나타내기 위해서 빈 motion vector를 사용했다고 합니다. loss 수식은 아래와 같습니다.L 은 시퀀스 길이를 의미하고 X_{cap,<i} 는 i번째 토큰 이전까지의 캡션 토큰들을 의미합니다.
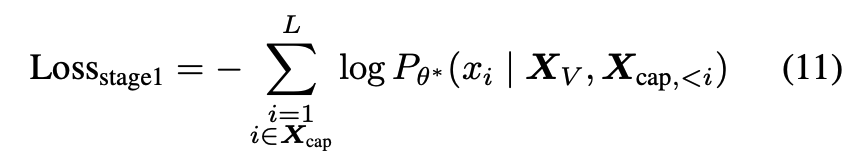
2단계는 시각적 맥락 속에서 사람의 지시를 더 잘 이해할 수 있도록 하는 visual instruction tuning으로 Cauldron과 VideoChat2-IT 로 부터 instruction tuning 데이터를 수집해서 모델을 학습시켰다고 합니다. X_{ans,<i}랑 X_{ins,<i}는 각각 i번째 토큰 이전까지의 응답 시퀀스와 지시문 시퀀스에 속한 토큰들이라고 합니다.
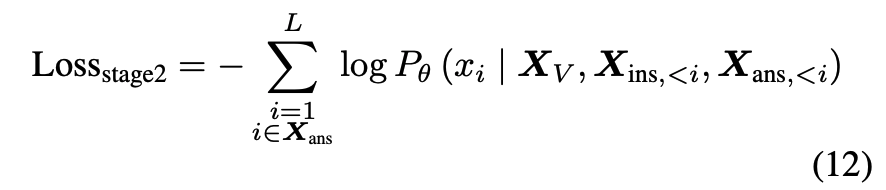
MotionBench
저자들은 기존 비디오 벤치마크들이 모션 정보에 대해 특화돤 평가 지표가 부족하다고 보고 motion pattern 이해를 위한 별도 benchmark를 설계합니다. MotionBench는 총 2.3k videos로 구성되고, 각 비디오는 장면 전환없는 뚜렷한 motion pattern만 포함했다고 합니다. 최종적으로는 114개의 motion pattern을 수집한 뒤 이를Linear, Curved, Rotation, Contact 라는 총 네 가지 범주로 나눕니다.

평가 방식은 multiple-choice QA로 각 비디오마다 정답 1개와 hard negative 3개를 넣어 모델이 헷갈리기 쉬운 motion label 사이를 잘 구분하는지를 보믄 평가라고 합니다.

supplementary를 보면 이 benchmark를 만들 때 SSV2 label set의 174개 후보에서 GPT-4o를 이용해 114개 클래스를 추리고, 추가 외부 데이터셋 비디오들에는 GPT-4o로 dense caption을 달아서 후보 카테고리와 matching하는 과정도 거쳤다고하는데 자세한 내용은 잘 모르겠습니다. 마지막에는 사람이 직접 잘못된 샘플이나 static image만 봐도 답이 너무 쉬운 샘플을 제거했다고 합니다. 최종 샘플 수는 Linear 800, Curved 500, Rotation 300, Contact 700 로 구성했다고 합니다.

Experiments
저자들은 keyframe interval을 8, frame rate 4 fps 설정으로 비디오를 H.264로 재인코딩하고 학습 시에는 각 비디오에서 GOP를 균일하게 샘플링해서 최대 GOP 수는 8개, 각 GOP 안의 motion vector 수도 최대 8개로 구성하고 RGB는 384×384, motion vector는 96×96으로 맞췄다고 합니다.
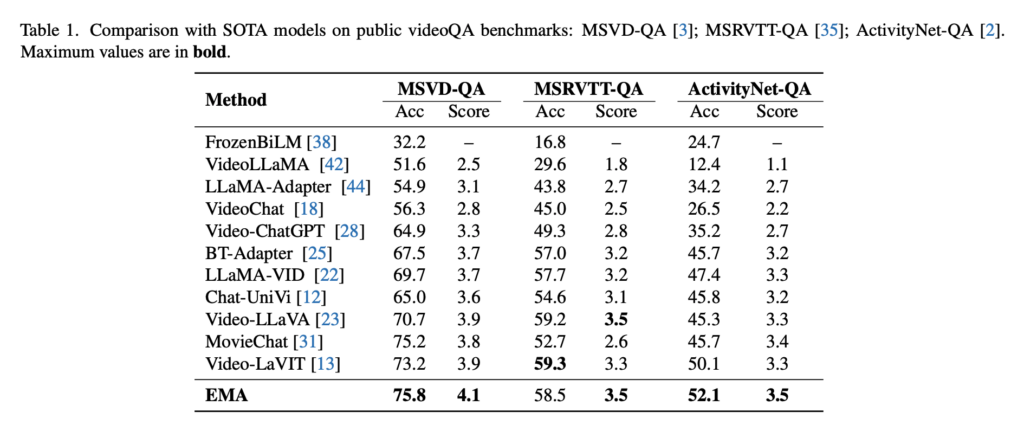
공개 Video-QA benchmark인 MSVD-QA, MSRVTT-QA, ActivityNet-QA에서 EMA는 기존 프레임 시퀀스를 처리하는 모델들보다 전반적으로 좋은 성능을 보입니다.
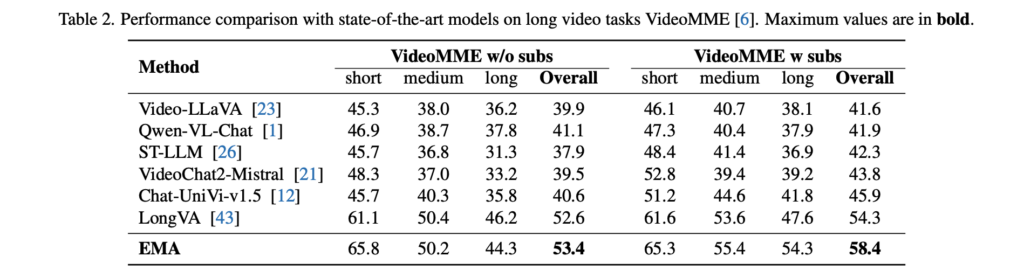
그리고 저자들은 long video 쪽으로도 확장 실험을 했습니다. 최대 GOP 수를 32개로 늘려 같은 방식으로 학습하고 VideoMME에서 평가했는데 결과적으로 저자들의 GOP 방식 long video understanding에서도 다른 비디오 모델들과 비교해도 경쟁력 있는 성능을 보여준다고 주장합니다.
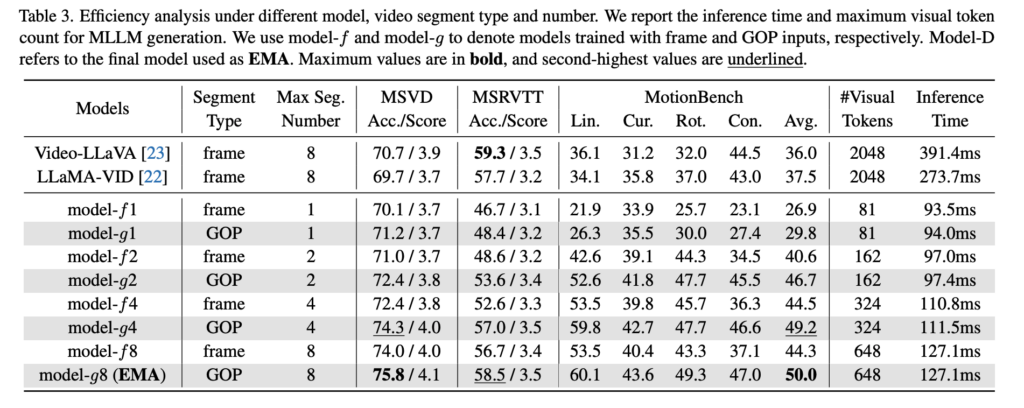
위 표는 효율성을 비교하는 평가인데 위를 보면 EMA는 Video-LLaVA, LLaMA-VID 대비 visual token 수를 2048에서 648로 줄이면서도 MSVD-QA와 MotionBench에서 더 좋은 성능을 보이고 inference time도 각각 2-3배 더 빠르다고 합니다. 그리고 frame 기반 model-f와 GOP 기반 model-g 비교 평가도 진행했는데 같은 segment 수, 같은 visual token 수일 때도 GOP 기반 쪽이 더 좋은 성능을 내는 결과를 보입니다. 심지어는 GOP 4개를 쓴 model-g4가 frame 8개를 쓴 model-f8보다 더 빠르면서도 성능이 좋은 모습을 보입니다. 저자들은 여기서 GOP 인코딩은 더 조밀한 frame 샘플링을 사용하는 모델보다도 더 나은 성능을 보이면서 추론 시간은 더 적게 든다는 점을 가지고 저자들의 접근법이 추론 효율 뿐만아니라 Video MLLM의 입력에서 중복성까지 줄인다는 점을 강조합니다.
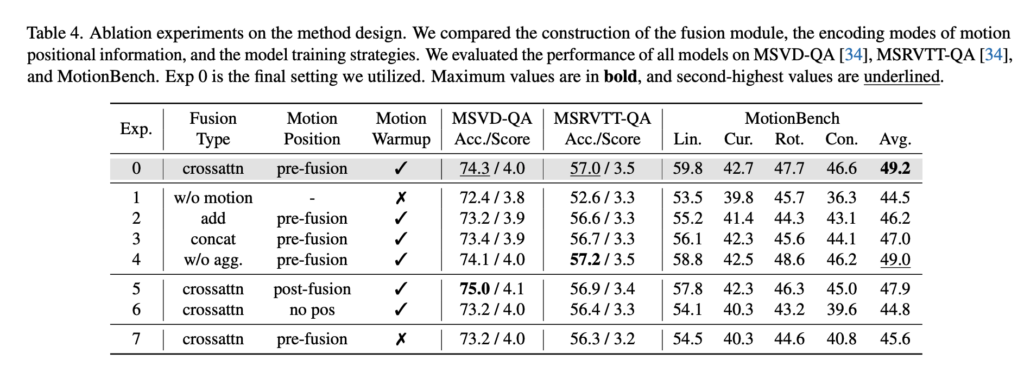
위는 어블레이션 결과 입니다. 먼저 fusion module 구조를 보면 motion을 아예 빼버린 경우보다 add, concat, cross-attn이 모두 낫고 그중에서도 cross-attn + pre-fusion pos 설정이 좋은 성능을 냅니다. add는 motion feature와 frame feature를 단순 합산, concat은 마지막 차원에서 이어붙이기, cross-attn은 frame embedding이 motion feature를 attention으로 끌어오는 구조라곡 보시면 좋을 것 같습니다.
그리고 motion feature 전체 sequence를 cross-attention에 그대로 넣는 방식이랑 temporal pooling으로 요약한 뒤 넣는 방식을 비교했을 때 성능은 거의 비슷하고 계산량은 pooling 쪽이 더 적었다고합니다. 그래서 최종 구조를 cross-attention fusion + pooling aggregator로 설정했다고 합니다.
저자들은 learnable positional embedding을 넣는 시점에 대한 결과도 분석했는데 motion encoder 입력 전(pre fusion)에 positional embedding을 넣는 방식이 가장 좋았다고 합니다.
그리고 motion warmup같은 경우는 frame encoder는 사전학습된 SigLIP인데 motion encoder는 random init이기 때문에warm up 설정을 추가하였고 Exp 0과 Exp 7 비교했을 때 warm up 설정이 더 좋은 결과를 보입니다.
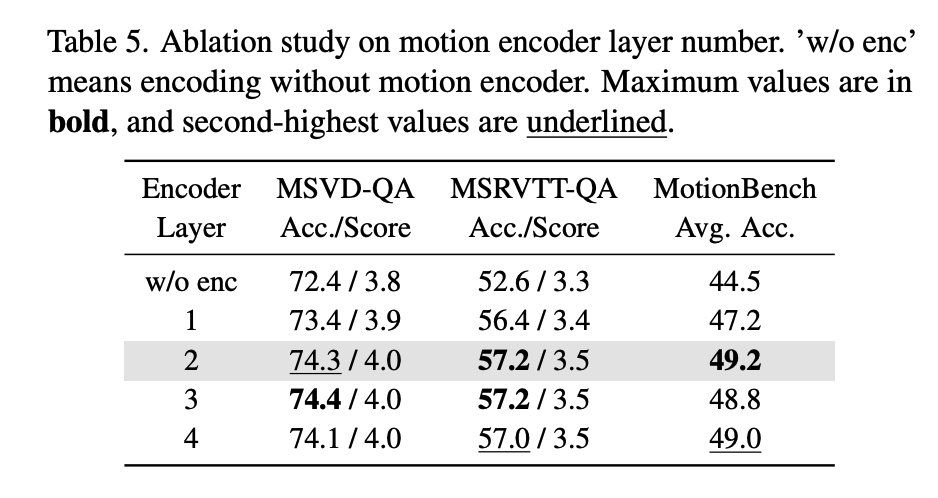
위는 motion encoder의 layer 수를 다르게 했을 때의 모델 성능을 비교한 결과입니다. 2-layer 이상부터는 큰 차이가 없는 모습을 보이고 저자들은 이 결과로 sparse motion vector는 그렇게 복잡한 encoder를 필요로 하지 않는다고 해석합니다.
motion position encoding도 중요합니다. 저자들은 motion vector가 previous frame에서 current frame으로의 movement를 나타내기 때문에 GOP 안에서 자연스러운 chronological order를 가진다고 보고, learnable positional embedding을 넣습니다.
Conclusion
비디오 분야에 대해서 잘은 몰라서 이 모션 벡터를 해당 분야에서 얼만큼 활용이 되는지는 잘 모르지만 이 논문만 읽었을 때 개인적으로 드는 생각은 비디오라는 데이터의 표현 자체를 다시 보자는 것 처럼 느껴져서 아직 이 모션 벡터를 활용하는 연구가 많이 없는건가 라는 생각이 들었습니다. 굳이 비디오를 다 RGB frame으로 복원해서 볼 필요가 없고 추후에 휴먼 비디오를 다루는 많은 로보틱스 분야에서 이 비디오의 모션 벡터를 싸고 빠르게 활용되지 않을까 생각이 듭니다. 물론 이 모션 벡터들은 비디오의 압축효율을 목적으로 만들어진 것이라 실제 움직임의 정보와는 항상 잘 맞는 것은 아닐 수 있다는 생각이 듭니다. 암튼 웹스테일의 video에서 모션 시그널 정보를 싸게 싸게 뽑아가지고 이걸 모션 정보처럼 움직임과 직접적으로 연관될 수 있는 action generation 으로 확장하는 방향도 충분히 생각해볼 수 있을 것 같습니다. 이만 리뷰 마치도록 하겠습니다. 감사합니다.
리뷰 잘 읽었습니다. 비디오 코덱을 사용하는 시도가 점점 늘어나는거 같은데 해당 논문도 그런가보네요 재밌게 읽었습니다. 몇 가지 궁금한 점이 있어 댓글 남겨두겠습닌다
1. GOP 앞에 붙는 temporal prompt가 시간 순서를 전달한다고 하셨는데, 이 prompt가 없을 때와 비교했을 때 성능 차이가 어느 정도 나는지도 궁금합니다.
2. 같은 token budget에서도 GOP 방식이 더 좋았다고 하셨는데, 이게 단순히 효율 때문인지, 아니면 motion vector가 실제로 더 informative한 representation을 제공하기 때문인지 궁금합니다.
안녕하세요 주영님 좋은 댓글 감사합니다.
첫번 째 질문에 대해서 답변드리자면 논문 supplementary의 ablation을 보면 GOP 앞에 붙는 temporal prompt는 짧은 Video-QA에서는 영향이 그렇게 크지 않았고 long video 쪽에서는 차이가 좀 있는 결과를 보입니다. 개인적인 생각으로 이 prompt는 짧은 clip에서는 큰 역할을 한다기보다는 GOP 개수가 늘어나고 시간축이 길어질수록 segment 순서를 LLM에 명시해주는 장치이지 않을까라는 생각이 드는 것 같습니다! 정량 결과테이블은 리뷰에 다시 첨부 하였습니다!
그리고 두번 째 질문에 대해서는 단순히 효율뿐만아니라 논문이 말하고 싶은 핵심은 motion vector가 실제로 더 informative한 representation을 제공한다는 쪽에 가까운것 같습니다. Table 3을 보면 같은 visual token 수와 비슷한 추론시간 혹은 토큰수가 적음에도 불구하고 frame 기반 model-f보다 GOP 기반 model-g가 consistently 더 좋은 성능을 보였고 특히 MotionBench에서 차이가 더 큰걸 보면 motion vector가 실제로 기존 방식보다는 더 informative한 representation을 제공함을 보여주는 것 같습니다.
감사합니다.
안녕하세요 우현님 리뷰 감사합니다
Motion Vector가 Optical Flow처럼 픽셀 단위로 매번 정밀하게 계산하는 것이 아니라 코덱 압축 과정에서 이미 생성된 sparse 블록 단위 정보라는 점이 차이 인거같은데 맞나요? Flow랑 비슷해서 차이점을 비교하면서 읽었네요..혹시 다른 차이점이있나요 ? Temporal token이 그 역활을 해주는것같은데 설명주시면 감사하겠습니다!
안녕하세요 우진님 좋은 댓글 감사합니다.
이해하신게 맞습니다. 이 논문에서 쓰는 모션 벡터는 optical flow처럼 픽셀 단위로 새로 계산한 dense motion이 아니라 코덱 압축 과정에서 이미 만들어진 sparse한 블록 단위 motion 정보에 가깝습니다. 그래서 flow보다는 노이즈가 있을 수 있고 sparse한데 대신 추가 계산 없이 바로 활용할 수 있다는점이 가장 큰차이이지 않을까 싶습니다. 그리고 temporal prompt는 motion 자체를 만드는 역할은 아닙니다. 여러 GOP가 시간축에서 어떤 순서로 들어왔는지를 LLM에 알려주는 역할에 가깝습니다. 감사합니다.
안녕하세요 우현님 리뷰 감사합니다.
혹시 이 연구를 통해 장면 내 motion이 카메라 움직임에서 비롯된 것인지, 아니면 물체 자체의 움직임에서 비롯된 것인지까지 구분하여 추론하는 것도 가능할까요? 예를 들어 로봇의 wrist에 카메라가 장착된 경우에는 카메라가 지속적으로 움직이게 되는데, 이러한 환경에서도 해당 방법이 유효하게 동작할지 궁금합니다.
안녕하세요 영규님 좋은 댓글 감사합니다.
제 생각에는 이 논문만으로 카메라 모션이랑 물체 모션을 구분해서 추론하기는 어려운 것 같습니다. 비디오를 압축할 때 어떤 메커니즘으로 모션벡터를 생성하는지는 모르지만 이 신호에는 말씀하신 것처럼 카메라 움직임으로 인한 전역적인 모션이랑 물체의 움직임으로 인한 모션 같이 섞여 들어있고 논문도 motion vector를 활용해 motion aware한 표현을 만들었다는 점은 강조하지만, 이런 카메라 전역적임 모션과 물체 자체의 움직임에 의한 모션을 분리하는 별도 모듈까지 두지는 않았습니다. 그래서 wrist camera처럼 카메라가 계속 크게 움직이는 환경이나 동적인 객체가 많은 세팅에서는 해당 방법이 어렵지 않을까 싶습니다. 감사합니다.
안녕하세요 안우현 연구원님 좋은 리뷰 감사합니다.
코덱을 활용하여 비디오를 압축하는 활용방식이 token compression보다 효율적이라는 주장이 인상적인 것 같습니다.
우현님이 언급해주신 것처럼 코덱을 활용하여 압축하는 방식이 압축에는 더 좋지만 모션 벡터의 표현력? 관점에서는 실제 모델이 시맨틱하게 모션을 이해하기에 좋은 정보와는 약간의 차이가 있을 수 있을 것 같습니다.
저자는 코덱 사용의 장점만을 언급하고 있는데 저자가 언급하는 단점이 논문에 있을까요? 그리고 ablation에서 코덱을 사용했을 때와 사용하지 않았을 때의 차이는 다루지 않는 것 같은데 이부분은 이전 방법론과의 성능 비교를 통해 보이고 있다고 이해하면 될까요?
감사합니다.
안녕하세요 성준님 좋은 댓글 감사합니다.
말씀해주신 모션 벡터의 표현력 관점에서 저자들은 실제 모델이 시맨틱하게 모션을 이해하기에 좋은 정보인지에 대해서는 따로 깊게 분석하지는 않았습니다. 그래서 해당 방식에 대한 단점에 대해서는 따로 언급되어있지가 않네요 허허
그리고 두 번째 질문에 대해서는 Table 3에서 frame 기반 입력(model-f) GOP 기반 입력(model-g)
을 같은 token budget과 비슷한 조건에서 비교하면서 성능차이를 다룹니다!
감사합니다.