안녕하세요, 이번주는 Large-Scale RL에 대해 다루어보려고 합니다. RL을 통해 policy를 학습하게되면 너무 optimal한 행동에 fitting되고 여러 상황에 대응하기는 좀 힘들 뿐 만 아니라 reward shaping이 너무 오래 걸린다는 단점이 존재합니다. 저자들은 이를 RL 알고리즘 자체의 한계라기보다, 학습 중 만나게 되는 상태 분포가 너무 좁기 때문이라고 보았습니다. 그래서 reward shaping, curriculum, demonstration을 더 정교하게 넣는 대신, 시뮬레이터에서 environment reset 자체를 잘 설계해서 로봇이 핵심 중간 상호작용 상태들을 다양한 상황에서 대량으로 경험하게 만들자는 철학으로 접근한 연구입니다. 물론 시뮬레이터에서 학습했기 때문에 real로 distill하는 부분도 연구되었습니다. 바로 리뷰 시작해보도록 하겠습니다.
Introduction

저자들은 시뮬레이션 기반 RL이 locomotion이나 navigation에서는 큰 성과를 냈지만, manipulation에서는 여전히 잘 안 풀리고 있다는 문제를 정의합니다. 이론적으로는 manipulation도 반복 상호작용을 통해 충분히 contact-rich behavior를 배울 수 있어야 하지만, 실제로는 robust하고 performant한 정책을 얻으려면 task별 reward engineering, curriculum, demonstration 같은 사람 손이 너무 많이 들어간다고 합니다. 그리고 이런 점이 데이터와 computing power를 키우면 성능이 올라가는 LLM의 scale-up 패러다임과 대비된다고 합니다. 저자들은 가장 중요한 문제가 ‘왜 로봇 manipulation에서는 언어모델들에서 보인 scale law 가 잘 안 보이는지’ 라고 합니다.
이에 대해 저자들은 병목이 exploration 구조의 문제라고 합니다. PPO나 SAC 같은 기법은 병렬 환경 수를 아무리 늘려도, 결국 비슷한 좁은 state-action distribution만 반복 경험하다 보니 local minima에 갇히고 성능이 포화된다고 합니다. 따라서 최근 RL 연구들이 이 문제를 해결하기 위해 reward shaping, hand-designed curriculum, user demonstration, 혹은 motion planning이나 base policy를 RL에 녹이는 hybrid 구조등 다양하게 진행되고 있다고 합니다. 저자들은 이에 대해 RL에 계속 추가적인 구조를 더하는 방향이 아니라, 애초에 학습이 만나야 할 상태 공간을 더 잘 설계해서 RL이 제대로 scale되게 만들어야 문제가 해결된다고 합니다.
또 저자들이 집중한 부분은 성공적인 조작 행동의 전체 형태는 매우 다양해 보이지만, 그 안을 이루는 상호작용 자체는 상대적으로 반복적이라는 것입니다. 예를 들면 접근하기, 안정된 grasp 만들기, goal 근처에서 insertion이나 twisting 하기 같은 스킬들은 다양한 상황의 manipulation에서 반복되는 본질적으로 의미가 있는 skill들입니다. 저자들은 이 recurring interaction modes를 사이사이를 촘촘히 연결해주면 sparse reward도 더 잘 전파되고, RL 과정에서 작은 조각의 skill들을 이어 붙여 long-horizon behavior를 만들 수 있다고 합니다. 또 정답을 명시적으로 알려주는 식의 복잡하고 명확하게 설계된 reward가 아니고 단지 다양한 상태를 경험하게 해주기 때문에 그 상태들을 어떤 순서로 연결하고 어떤 dynamic behavior를 쓸지는 RL이 emergent하게 학습할 수 있다고 합니다.
위 Figure 1을 보면 Drawer insertion, table leg screwing, peg insertion 같은 task에서 시뮬레이션(위)과 현실 시퀀스(아래)를 보여주는데, 저자들은 성공 과정에서 중간에 뒤집고, 밀고, 다시 맞추고, 재시도하는 식의 dynamic하고 contact-rich한 recovery behavior가 자연스럽게 나왔다는 점을 강조했습니다. 정답이 있는 motion을 단순하게 imitation하는 것 보다 다양한 상호작용을 단순한 PPO알고리즘과 sparse reward로 학습한것이 핵심이라고 보면 될 것 같습니다. 저자들은 이러한 학습이 가능하도록 OmniReset이라는 프레임워크를 제안했습니다.
Related Works
Exploiting Resets in Reinforcement Learning
Reset을 활용하는 RL 연구들은 초기 상태를 더 고르게 샘플링하는 것을 목표로 goal state에서 역방향으로 curriculum을 짜는 reverse curriculum방식, dynamics model을 활용해 feasible reset을 제안하는 방식, demonstration을 활용해 goal까지 가는 feasible pathway를 만드는 방식으로 접근했다고 합니다. OmniReset은 이들과 비슷하게 reset을 활용하지만, 차별점은 explicit curriculum도, human demonstration도 없이, task-relevant한 중간 state들을 랜덤하게 설정하는 단순한 reset 생성만으로 scaling law를 활용해 exploration 문제를 풀었다는 점입니다.
Exploration Strategies for Reinforcement Learning
Count-based exploration, curiosity, value-level stochasticity, diversity-seeking exploration 등 다양한 exploration 기법들이 등장했지만, 저자들은 exploration bonus를 더 교묘하게 설계한 것이 아니라, 대규모 병렬 환경에서 랜덤하게 reset 하는 설계만으로도 surprisingly strong dexterity가 가능했다고 합니다. 엄청나게 정교한 설계보다는 역시 LLM쪽에서 보여준 scaling law를 적용하는것이 핵심이라고 보면 될 것 같습니다.
Leveraging Demonstrations
BC loss를 RL에 보조로 넣거나, replay buffer에 demo를 넣거나, 주어진 demonstration을 잘 따라가게 reward shaping을 하거나, demo를 기준으로 다른 초기 상태로 augmentation, recovery behavior에 대한 reward를 추가하는등 imitation-based 한 RL 연구들이 사실 대부분을 이룹니다. 저자들은 scratch에서 demonstration을 쓰지 않고도 reset만으로 imitation based 방법론들을 이긴다고 합니다. 어떻게 보면 task를 수행할 때 action을 로봇 관점에서 최대한 의미있는 RL로 해야한다는 X-sim의 object trajectory centric한 철학과도 좀 결이 맞는 것 같습니다.
Method – Generating Diverse Resets For Learning Dextrous Manipulation

Problem Setting
저자들은 OmniReset의 RL을 MDP(상태 s, 행동 a, 전이 확률 P, reward r, discount γ)로 정의했습니다. 그리고 초기 상태 분포 ρ 를 어떻게 설계하느냐를 핵심 문제로 정의했습니다. RL 자체는 먼저 compact state representation(물체와 로봇의 state 기반)으로 학습하고, 이후 vision policy로 distill했습니다. 기존 real-to-sim-to-real의 근본 철학이었던 state-space에서 behavior generation을 확실히 하고 perception을 붙여주는 식입니다.
OmniReset은 세 가지의 user input을 요구하도록 설계했다고 합니다. 조작할 target object, 해당 객체의 goal configuration, 로봇의 workspace가 주어지면 environment definition에서 target object를 지정하고, goal state sampler를 통해 workspace 내에서 operating region을 가지고 학습합니다. 저자들은 이 세 가지가 최소한의 입력이면서도 task structure에 대한 충분한 정보를 담고 있다고 합니다. 완전히 task-agnostic black box는 아니고, 목표 객체와 목표 상태, 작업 공간이라는 문제 구조를 받아 reset distribution을 자동 설계하는 방식입니다.
Automatically Generating RL Problems With Diverse Resets
저자들은 RL이 실패하는 이유를 학습이 너무 좁은 robot-object interaction만 보기 때문으로 보고 coverage를 넓혔습니다. 먼저 target object가 goal까지 이동하는 경로 공간을 넓히고, 로봇이 해당 object와 상호작용하는 방식의 공간도 넓혔습니다. Motion planning 관점에서 말하면, RL이 지나가기 어려운 narrow passages를 reset으로 미리 열어 준다고 합니다.
이를 위해 먼저 target object에 대한 feasible grasp point 1000개를 grasp sampler로 구합니다. 그리고 goal 근처 상태를 만들기 위해 target object를 goal에 배치한 뒤 작은 랜덤 힘으로 살짝 밀어 goal에서 이탈시켜 near-goal offset states를 만듭니다. 예를 들어 peg insertion이면 peg가 hole에 완전히 들어간 상태가 아니라, 부분적으로 삽입된 연속적인 상태들이 만들어집니다. 즉, 저자들은 reset library를 만들기 전에 grasp space와 goal-neighborhood state space를 미리 구축한다고 합니다. 그다음 네 종류의 reset을 만듭니다.

첫째는 Reaching resets입니다. target object를 tabletop의 다양한 위치에 놓고, gripper는 workspace 안 임의 pose에 배치합니다. 이 상태는 말 그대로 로봇이 아직 물체를 잡지 않았고, 물체를 향해 접근해야 하는 첫 step입니다.
둘째는 Near-object resets입니다. 물체는 여전히 tabletop에 있지만, end-effector를 미리 계산한 grasp point 근처에 작은 offset을 두고 배치하며, gripper는 open 또는 closed를 랜덤으로 둡니다. 이 reset은 물체와 접촉을 시작하는 상태, 즉 non-prehensile interaction과 grasp initiation이 섞인 상태를 폭넓게 커버합니다. 단순히 grasp 상태만 주는 것이 아니라, 접촉 직전/직후의 실패할만한 포인트들의 상태들을 유도하는 것이 핵심이라고 보면 될 것 같습니다.
셋째는 Stable grasp resets입니다. object를 공중의 다양한 위치에 놓고, gripper를 feasible grasp point에 맞춰 배치합니다. 이 상태는 이미 prehensile manipulation이 가능한 단계입니다. 즉, 잡고나서 물체의 위치를 고치거나 하는 등의 상호작용입니다.
넷째는 Near-goal resets입니다. object를 goal 근처 offset state에 놓고, gripper는 near-object reset처럼 object에 접촉하도록 배치합니다. 이 reset은 insertion, twisting 같은 goal 근처의 contact-rich micro-skill을 학습하는 과정이라고 합니다.
이 때 저자들은 두 가지를 강조했는데, 이 reset들은 어떤 graph나 curriculum 순서로 연결되지 않고 어떤 dynamic behavior도 직접 알려주지 않는다고 합니다. RL 학습 과정에서 어떤 reset state를 유용하게 쓸지, 어떤 순서로 행동을 이어 붙일지는 전부 optimization 과정에서 emergent하게 결정된다고 합니다. 그래서 어떤 task에서는 grasp를 거의 쓰지 않고 뒤집고 밀어 넣는 행동이 나오고, 다른 task에서는 물체를 집어 테이블에 눌러 더 좋은 grasp를 만든 다음 비틀어 삽입하는 모습이 나오기도 한다고 합니다. 여러번 언급했지만 reset을 통해서 행동을 지정하지 않고 행동을 알아서 학습할 수 있는 상황들만 만들어주는게 핵심인 것 같스빈다.
실제 코드 단계의 구현에서는 invalid reset이 학습을 망칠 수 있으므로, offline phase에서 후보 reset을 많이 샘플링한 뒤 collision checking과 몇 step simulator stabilization을 거쳐 feasible한 것만 남긴다고 합니다. 그렇게 얻은 네 개의 validated dataset에서 training 중에는 uniform하게 샘플링해서 온라인 생성형 reset이 아니라, 사전에 검증된 reset library를 offline으로 수집해서 학습하는 방식으로 학습합니다.
Algorithmic Decisions for RL Training

RL의 알고리즘은 PPO를 씁니다. PPO 식에 특별한 튜닝을 하지는 않고 reset diversity를 잘 수용할 수 있게 몇 가지 실용적 설계만 했다고 합니다.
먼저 task-agnostic reward입니다. reward는 성공 보상, goal까지의 거리 보상, gripper가 target에 가까워지도록 하는 reach 보상, action smoothness 패널티, abnormal termination 패널티로 구성됩니다. 핵심은 이 reward가 task-specific strategy를 encode하지 않는다는 것이라고 합니다. Component와 weight를 task마다 바꾸지 않고 그대로 사용하면서 RL 성능의 핵심이 reward tuning이 아니라 initial-state coverage라고 보고, moderate한 가중치 변화에는 꽤 둔감하다고 말합니다.
Reward에 대해서 좀 이야기를 하자면 r_success는 pose, orientation 오차가 미리 정해둔 threshold 아래로 내려가면 1.0의 성공 보상을 줍니다. 가중치가 1로 global한 영향을 줍니다.
r_dist는 아래와 같은 식을 사용합니다.
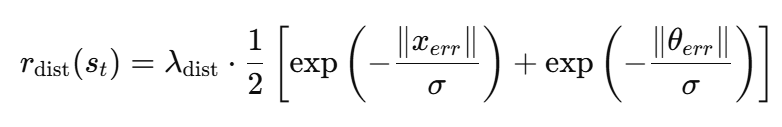
x_err는 목표 위치와의 오차, θ_err는 목표 자세와의 오차입니다. 둘 다 goal frame에서 계산된 relative pose error입니다. 물체가 goal 위치와 어떤 위치 차이, 방향 차이를 갖는지를 동시에 보는 reward 입니다. 가중치는 0.1입니다. Peg insertion은 위치만 맞아도 orientation이 틀리면 실패하고, leg twisting이나 drawer insertion은 orientation mismatch가 더 치명적일 수 있기 때문에 단순히 위치나 orientation중에 하나만 중요한게 아니고, 그렇기 때문에 두 오차를 각각 exponential decay 형태로 shaping해서 평균냈다고 합니다. 정리하면 object pose가 goal pose에 가까워질수록 reward가 서서히 커지고, 특히 near-goal 영역에서 더 예민한 gradient-like signal을 제공할 수 있다고 합니다.
r_reach는 아래와 같은 식을 사용합니다.
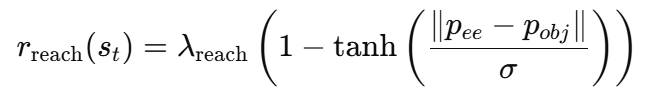
여기서 p_ee는 end-effector 위치이고, p_obj는 target object 위치입니다. 즉, gripper와 목표 물체 사이의 거리가 가까워질수록 reward가 커집니다. tanh를 쓴 이유는 멀리 떨어진 구간에서는 reward 변화가 완만해지고, 가까워졌을 때 더 민감하게 반응하게 하기 위함입니다. 가중치는 0.1을 줬다고 합니다.
r_smooth는 아래와 같은 식을 사용합니다.
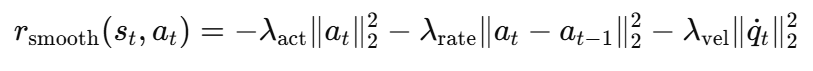
첫 번째 항은 action 자체의 크기가 너무 크지 않도록, 두번째 항은 이전 action과 현재 action간 매끄럽지 않은 action이 생기지 않도록, 세번째 항은 velocity가 크지 않도록 하는 penalty 항들로 구성돼있습니다. 각 -0.0001로 작은 penalty이지만 velocity항의 경우에는 -0.01의 패널티를 주어서 위험한 장면을 피한다고 합니다.
마지막 r_term은 아래와 같습니다. 로봇의 충돌이 감지되는 unsafe한 상황에서는 -100의 가중치를 두어 그냥 학습을 못하게 한다고 합니다. 워낙 reset 범위가 넓다보니 singularity에 걸리는 상황 등이 많아서 설정했다고 봅니다.
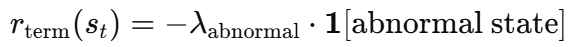
둘째는 parallel environments scaling입니다. Reset diversity가 늘어난 상황에서는 parallel env 수를 크게 키우는 것이 굉장히 중요하다고 합니다. 저자들은 large batch PPO가 unsuccessful reset이 많이 섞여 있어도 catastrophic forgetting 없이 value propagation을 유지하는 데 필요 중요했다고 합니다. Computing power를 많이 쓰는것이 단순히 scaling 한다는 의미 보다 large-batch on-policy optimization을 결합함으로써 exploration saturation을 늦춘다고 합니다.
셋째는 asymmetric actor-critic입니다. Actor는 로봇 state, scene object pose, 이전 action의 5-step history 정도만 보고, critic이 privileged parameter를 더 보는 구조입니다. Actor에 너무 많은 privileged 정보를 넣으면 오히려 학습이 불안정해졌다고 합니다. Sim privileged information들을 전부 actor에 넣는것 보다 critic 쪽에 주로 두는 설계로, 최근 많은 연구들이 해당 방식을 취하는 것 같습니다.
넷째는 gSDE 기반 state-dependent exploration noise입니다. 서로 다른 상태 영역에서 서로 다른 temporally correlated exploration을 하게 만들어 heterogeneous multi-stage task에 맞는 탐색을 하도록 했다고 합니다. 이런 exploration noise 기법도 그 noise가 의미 있게 작동할 수 있을 만큼 state space를 넓히고, batch를 키워서 scaling하는 설계와 연관이 있는 것 같습니다.
이렇게 reset states 들을 수집하고, state-based RL expert를 학습한 다음, photorealistic rendering과 visual randomization으로 대규모 RGB dataset을 만들고, student-teacher distillation으로 vision policy를 학습한 뒤 real robot에 zero-shot transfer 하는 구조로 현실에서 작동하게 됩니다.
Distillation and Real World Transfer
시뮬레이션에서 학습한 state-based RL expert는 RGB 기반 visuomotor policy로 distill해서 실제 로봇에 zero-shot transfer 합니다. 하드웨어는 UR7e + Robotiq 2F-85 gripper를 사용했다고 하고, front view의 D455, side view의 D435, wrist-mounted D415를 사용해 총 세 대의 카메라를 사용했다고 합니다. Student policy는 224×224 RGB 입력, ImageNet-pretrained ResNet-18 encoder, Gaussian MLP head, 그리고 최근 5개 observation stack을 사용해 4090에서 10Hz로 동작한다고 합니다.
State 기반의 policy를 distill 할 때는 DextrAH-RGB를 따라, pose reconstruction과 expert action distribution에 대한 KL matching을 함께 쓰는 조합이 가장 성능이 좋았다고 합니다. 그리고 실제 inference 시에도 Gaussian policy의 샘플을 쓰는 것이 아니라 mean action만 사용하는 것이 성능이 좋았다고 합니다. 단순 behavior cloning은 보통 이미지에서 바로 action을 regression 하는데, RGB 입력만으로는 state 기반으로 학습한 action의 imitation이 불완전 했다고 합니다. Pose reconstruction이 없으면 RGB policy가 물체를 안정적으로 localize하고 grasp하는 데 실패하는 경우가 있었다고 합니다. 또 이때 vision encoder를 freeze해도 성능이 급감했다고 합니다.
추가적으로 발견한 부분은 pi0.5를 finetuning 해도 이점이 없었고, 단순 action chuncking을 하는 Diffusion policy는 오히려 MLP로 구성된 경우보다 성능이 낮아서, rgb를 통해서만 action을 만들어내는 것과는 teacher의 특성이 다르기 때문에 간단한 접근이 오히려 유용했다고 합니다.
Isaac Lab 시뮬레이션에서 8만 개의 expert rollout을 수집하고, synchronized image-action pair로 student-teacher distillation을 합니다. Figure 11은 이때 사용한 visual randomization 예시를 보여줍니다. lighting, background, object appearance, robot appearance, workspace texture, camera pose, FOV jitter 등을 모두 augmentation 하며 visual gap을 줄인다고 합니다. 저자들은 이를 DextrAH의 randomization 설정을 따라했다고 합니다. 예시는 아래와 같습니다.

Dynamics gap을 줄이는 접근도 있었는데요, operational space controller를 simulation과 hardware에서 동일하게 구현하고, friction, armature, motor delay 같은 actuator parameter를 system identification으로 맞춘 뒤에 object mass와 friction을 randomize하고, 제어 시에도 identical Jacobian-based control을 유지했다고 합니다. 아래에서 그 효과를 확인할 수 있습니다.
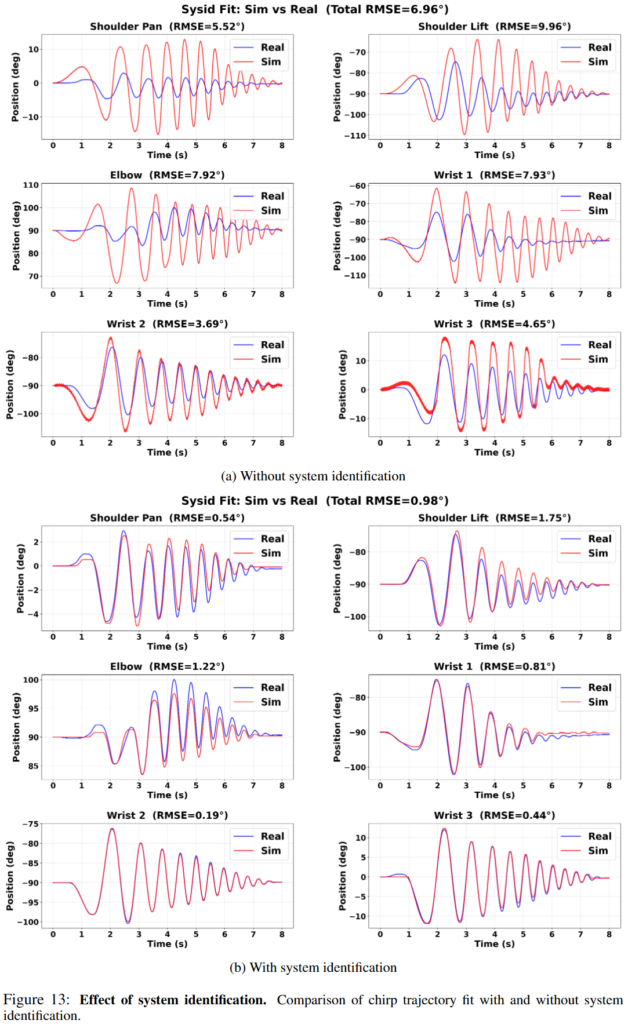
조금 디테일한 점을 언급하자면 시뮬레이터 상에서의 학습 용이성과 현실로 전이할 때의 용이성을 위해 wrist의 joint 범위를 [-360, 360]에서 [-180, 180]으로 조정하고 조작 대상 객체들을 SDF로 직접 정밀하게 제작해 contact에 신경 썼다고 합니다. 또 Isaac Sim의 step_dt라는 변수가 있는데 (시뮬레이터 상에서의 physics 엔진 계산 단위) 이것을 1/120초로 세팅했을 때 현실과 유사한 contact를 구현할 수 있었다고 합니다. 현실에서 작동할 때는 top-down view가 아닌 side view cam들과 wrist cam을 같이 사용할 때 훨씬 더 성능이 좋았다고 합니다. 따로 실험결과는 없었습니다.
Experiments
실험 task는 Leg Twisting, Drawer Insertion, Peg Insertion, Cube Stacking, Wall Slide, Cupcake Placement로 설정했습니다. 각 task에는 Easy/Hard variant를 두고 진행했다고 합니다. Hard는 tabletop에서 object 초기 위치 범위가 넓고 goal도 랜덤성이 있으며, Easy는 매우 제한된 초기 조건과 고정 goal을 씁니다. Four leg table assembly도 진행했는데 이 task를 통해서는 각 leg별 policy를 따로 학습한 뒤 간단한 scripting policy로 switching해서 더 긴 horizon의 task를 풀어high-level planning과 결합 가능하다는 것을 보여주기 위한 세팅이라고 보면 될 것 같습니다. 이런 task에서 성능이 잘 나오는 것을 통해 rigid-body single-object-to-goal 계열의 manipulation task에는 일반적으로 적용될 수 있다는 것을 증명했다고 합니다

Baseline Comparison in simulation
Baseline은 BC-PPO, DeepMimic-style reward augmentation, Demo Curriculum으로 설정했습니다. 공정성을 위해 baseline들에는 buffer에 100개의 성공 demonstration을 주었다고 합니다. 해당 demo들은 full task가 시작되는 reaching region을 학습하는 과정에서 뽑힙니다. 워낙 넓은 범위에서 reaching을 하니 reaching 이후를 비교하려고 advantage를 준 것 같습니다.
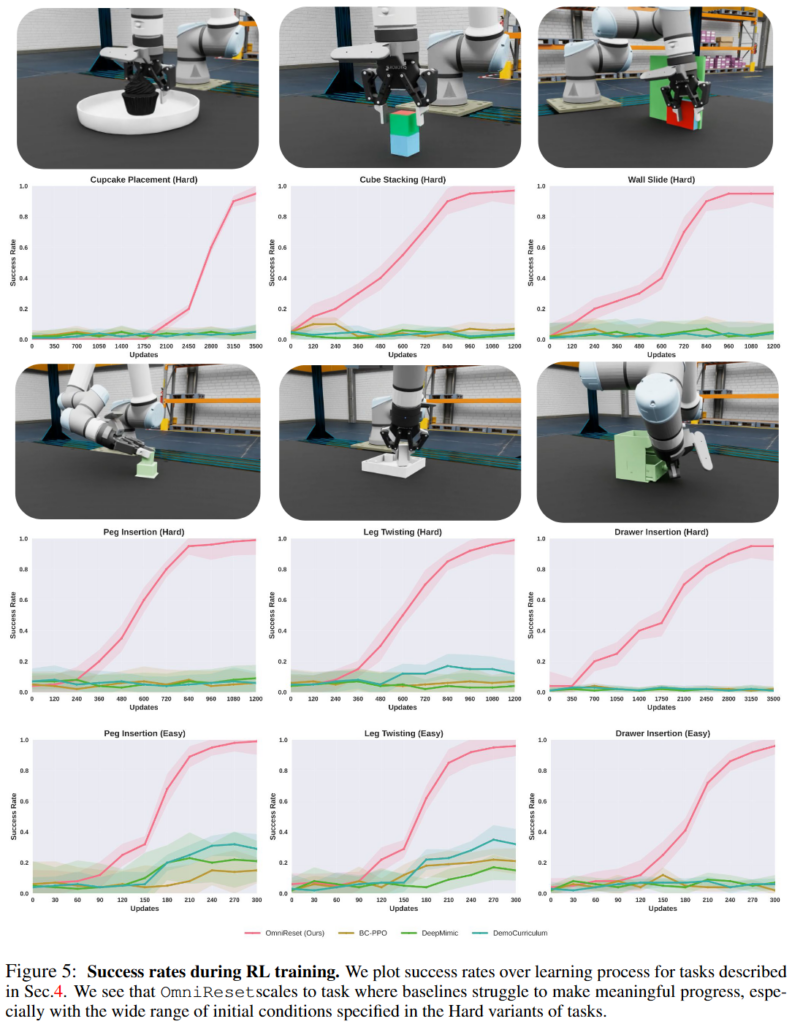
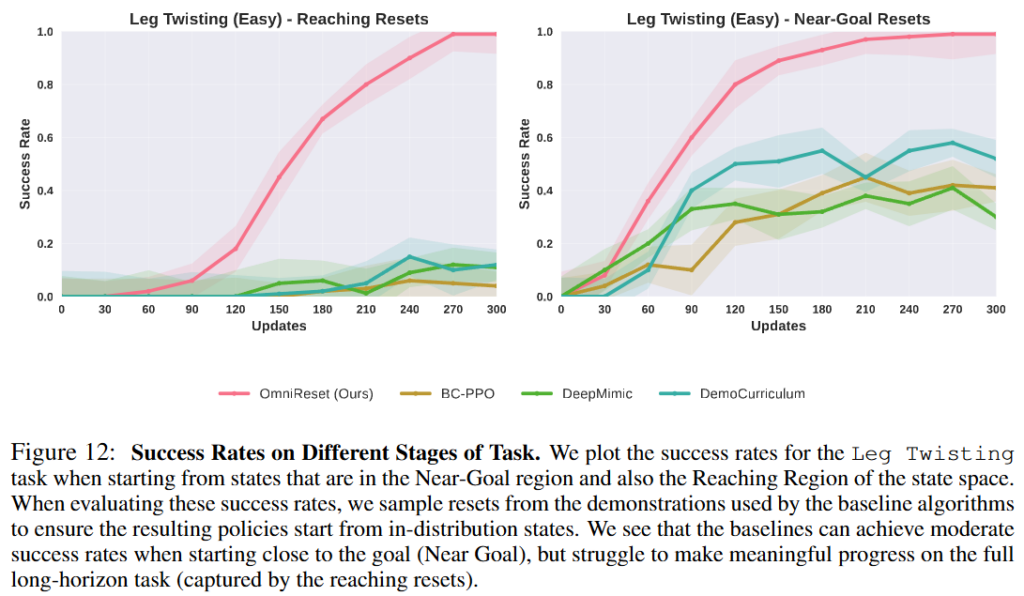
Figure 5의 learning curve를 보면 OmniReset은 각 task에서 높은 success rate를 지속적으로 얻고, baseline들은 Easy에서는 어느 정도 진전이 있어도 Hard처럼 초기 조건 범위가 넓어지면 학습이 잘 안되는 것을 볼 수 있습니다. Reset, 즉 exploration의 분포가 극단적으로 넓어졌을 때의 결과를 볼 수 있습니다. Baseline은 near-goal 같은 쉬운 부분은 어느 정도 배우지만, 공통적으로 full long-horizon task로 scale되지 못했습니다.Near-goal region과 reaching region을 나눠서 분석한 실험도 Figure 12를 보면 baseline도 near-goal에서는 moderate success를 낼 수 있지만, reaching에서 출발하는 full task에서는 의미 있는 진전이 거의 없습니다. 기존 baseline들이 끝부분의 local skill은 배워도 전체 task를 연결하는 데 실패한다는 것을 볼 수 있습니다.
Robustness and Emergent Curriculum
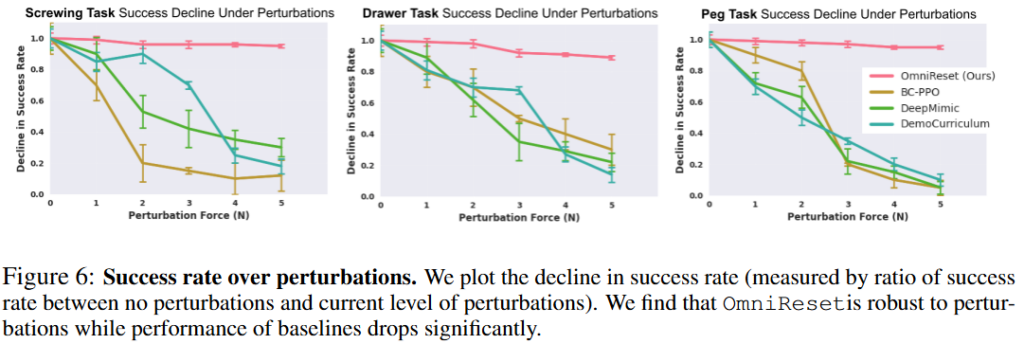
Figure 6은 perturbation robustness를 보여줍니다. Demonstration에서 뽑은 초기 상태를 힘으로 점점 교란했을 때, baseline은 작은 perturbation에도 성능이 빠르게 떨어지는 반면 OmniReset은 훨씬 더 견고한것을 볼 수 있습니다. Reset diversity가 외력에 의한 perturbation에 대한 regularizer 역할도 할 수 있었다고 합니다.
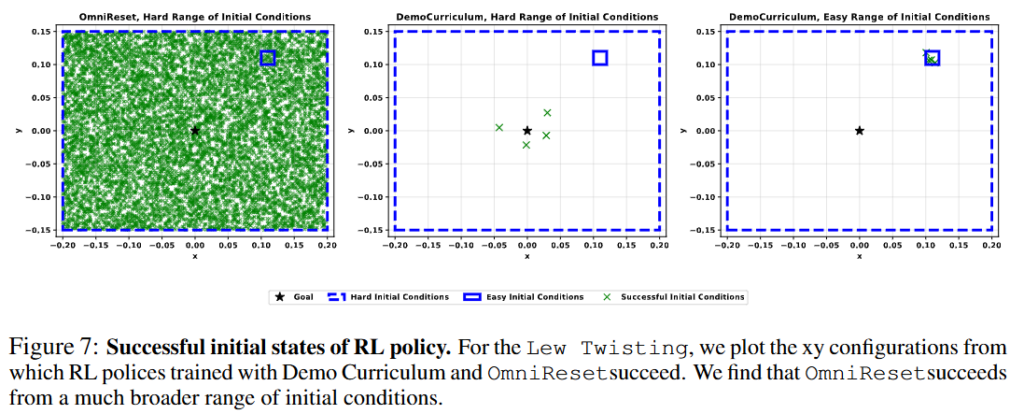
또 OmniReset은 curriculum을 명시적으로 쓰지 않지만, 학습 과정에서 emergent curriculum이 나타난다 흥미로운 결과를 볼 수 있었다고 합니다. Policy는 먼저 near-goal state에서 성공하는 법을 배우고, 그 다음 점점 더 앞쪽 상태에서 성공하게 되었다고 합니다. Task 수행을 역순으로 배운다는 것입니다. 작업을 배우는 순서는 설계한 것이 아니었다고 합니다. Diverse reset과 large-scale PPO만으로도 backward-like learning progression이 자연스럽게 생겼고, 다양한 커리큘럼을 짜는 연구들 없이도 자연스럽게 유도가 돼서 정말 놀라운 결과였다고 합니다.Figure 7은 Leg Twisting에서 성공한 초기 상태들의 xy 분포를 산점도로 보여줍니다. Demo Curriculum은 hard range 전체를 거의 덮지 못하고 성공 영역이 제한적인 반면, OmniReset은 훨씬 넓은 초기 조건 범위에서 성공해 competence region 자체가 넓어졌다는 것을 보여주었습니다. 뭔가 scaling을 통해서 emergent한 결과가 RL에서도 드러나는 것이 좀 인상깊습니다 개인적으로는.
Ablation
Figure 8은 parallel environment 수를 바꾼 실험입니다. Near-goal reset에서는 작은 환경 수로도 어느 정도 학습이 되지만, full multi-stage task, 즉 reaching에서 시작하는 전체 문제를 풀려면 아주 많은 병렬 환경이 필요했다고 보고합니다. 저자들은 2048에서 65536 environments까지 비교하면서, 대규모 병렬성이 단순한 속도 문제가 아니라, long-horizon task에서 성공을 퍼뜨리는 데 필수적인 구조적 요소라는 것을 증명했다고 합니다. Reset diversity가 큰 만큼 forgetting 없이 초반 reaching부터 task를 전부 다 RL이 흡수하려면 충분히 큰 batch PPO가 필요하다고 이해하면 될 것 같습니다.
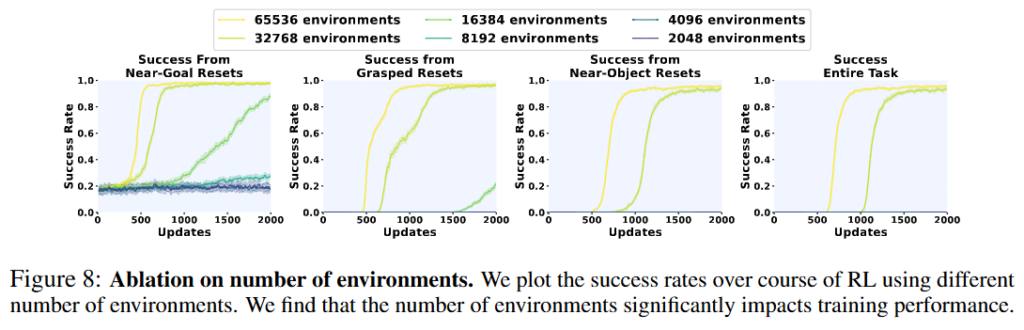
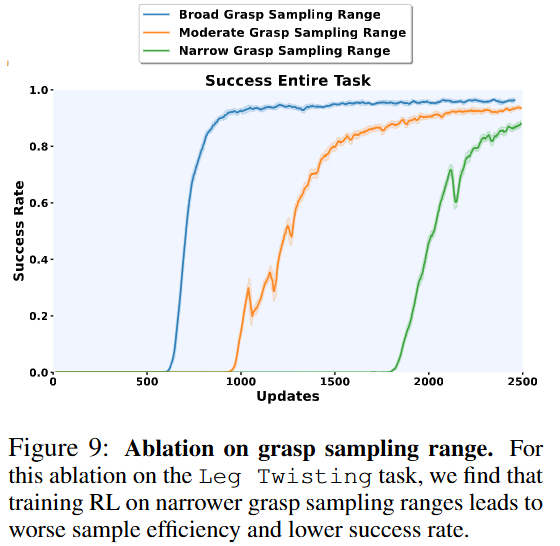
Figure 9는 grasp sampling range의 폭을 줄였을 때의 성능 저하를 보여줍니다. Broad range일수록 sample efficiency와 최종 success rate가 좋고, narrow range로 갈수록 나빠지는것을 확인할 수 있습니다. 저자들의 다양한 robot-object interaction mode를 많이 보게 하자는 철학이 쭉 보이는 실험들인 것 같습니다.
Real-World Transfer

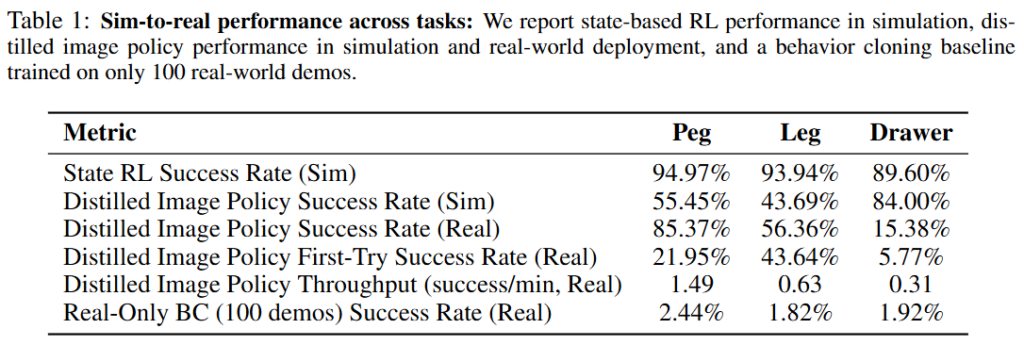
Figure 10에서와 같이 Peg insertion, leg twisting, drawer insertion task로 sim, real에서 비교하며 진행했다고 합니다. 물체를 단순히 집고 옮기는 수준이 아니라, contact geometry와 자세 정렬, 미세한 pushing/flipping이 함께 필요한 task들로 선정했다고 합니다. Table 1을 보면 state RL success rate의 sim에서 성능과 distillation된 image policy의 sim success를 확인할 수 있고, real-world zero-shot success 성능도 100개 real demo로만 학습한 BC baseline은 박살난 모습을 볼 수 있습니다. 다만 역시나 contact-rich task는 real transfer가 어려운 것 같스빈다.
데이터셋은 10K에서 80K trajectory까지 늘려도 simulation 내 성능은 비슷했지만, real-world transfer는 dataset이 커질수록 유의미하게 좋아졌다 합니다. 또한 학습 iteration 수도 늘어날수록 좋아서 350K iteration을 학습했고, H200 GPU에서 2일이 걸렸다고 합니다… 한편 80K trajectory를 모으는 데에는 한 대의 3090 GPU 기준 약 24 GPU hours가 들었다고 합니다.
또 appendix에 보면 많은 노력을 했음에도 불구하고, simulation 안에서조차 RGB policy의 성능이 state 기반보다 많이 약하다고 합니다. 따라서 저자들은 image-based DAgger나 RGB 기반 RL fine-tuning 같은 online adaptation 방법이 더 필요할 수 있다고 합니다.
Conclusion
저자들은 diverse reset states 과 large-batch on-policy RL만 해줘도 dexterous behavior가 long-horizon으로 emergent하게 나온다는 것을 증명했다는 점이 인상깊은 것 같습니다. 아마 simulation data generator로도 활용할 수 있지 않을까 싶습니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
리뷰를 읽으면서 느낀점은 제가 맞는지 모르겠지만 model이 너무 좁은 정보만 학습하기 때문에 spatial 한 정보가 부족해서 이러한 부분은 reset을 이용해서 randomize 하여 다양한 state를 학습하게 한다라고 이해했는데 맞을까요?
최근 visual motor policy의 성능도 spatial한 information이 부족해서 낮게 나온다는 논문을 읽어봤는데 그 논문에서도 시작 위치와, 주변 view에 대한 정보를 더 많이 주는 식으로 데이터 증강을 수행하던데 이 방식과 유사하게 이해하면 될까요?
감사합니다.
안녕하세요 인하님 댓글 감사합니다.
맞습니다. 큰 그림은 reset을 randomize하는 영역을 initial state에서 더 나아가서 task를 진행하는 전반에 결친 state로 확장시켜서 Large Scale로 진행한다면 sparse reward 만으로도 기존에 학습할 수 없었던 다양한 dexterity를 얻게된다는 것입니다.
해당 내용은 강화학습 기반이기 때문에 완전히 유사하다고 할 수는 없을 것 같습니다. 하지만 spatial information을 이해시키는데 있어서 시작 위치나 주변 view에 대한 정보나 augmentation은 유효한 것 같습니다.