Abstract
Open-Set Object Detection(OSOD)은 알려진 카테고리와 본적 없는 카테고리의 물체를 탐지하는 것을 목표로 합니다. 실제 환경에서는 도메인 변화와 새로운 객체 카테고리 추가가 동시에 이루어지는 경우가 존재하며, 기존의 OSOD는 도베인 변화까지는 고려하지 못하여 알려진 카테고리의 도메인 변화인지, 새로운 카테고리인지를 구분하지 못하는 문제가 존재합니다. 해당 논문은 도메인별 스타일을 의미론적 구조로 분리하여, 일반화 가능한 객체 탐지를 위한 DOAT 프레임워크를 제안합니다. DOAT는 wavelet기반의 특징 분리를 통해 스타일정보와 고주파의 구조적 디테일을 분리함으로써 도메인 및 카테고리를 명시적으로 분리합니다. 새로운 객체를 발견하기 위해, 고주파 성분을 활용하여 objectness score를 추정하며, open-set 벤치마크에서 다양한 실험을 통해 DOAT의 일반화 성능을 보였다고 합니다.
Introduction
unseen 환경에서의 일반화 능력은 실제 환경에서 중요한 인식 능력으로, 최근 보지 못한 카테고리를 다루기 위해 energy 기반의 점수, pseudo-labeling, uncertainty estimation, prototype 등을 이용하는 연구들이 활발히 이루어지고 있습니다. 그러나 실제 환경에서는 조명이나 날씨와 같은 요소에 의한 시각적 외형 도메인의 변화와 새로운 객체 카테고리 등장이 동시에 이루어질 수 있습니다. 그러나 기존 연구들은 도메인 변화에 대한 고려가 부족하며, 도메인 특유의 스타일 정보와 의미론적 정보가 representation 안에 꼬여있습니다. 따라서, 보지 못한 도메인에서 known 카테고리와 unknown 카테고리에 대한 혼동이 발생하여 성능 저하의 원인이 됩니다.
따라서, 해당 논문에서는 ‘도메인 분포가 변화하는 상황에도 어떻게 unknown 객체를 탐지하는 능력을 유지할 것인가?’에 대하여 해결하고자 하였습니다. 저자들은 도메인 변화가 발생하였을 때, 효과적으로 unknown 객체를 발견하기 위해서는 도메인 별 변동성과 의미론적 내용을 명시적으로 분리해야한다고 주장하였으며, 이를 기반으로 저자들은 주파수를 활용한 모델링을 통해 이 두가지를 분리하는 프레임워크 DOAT(Decompose and Attribute)를 제안합니다.
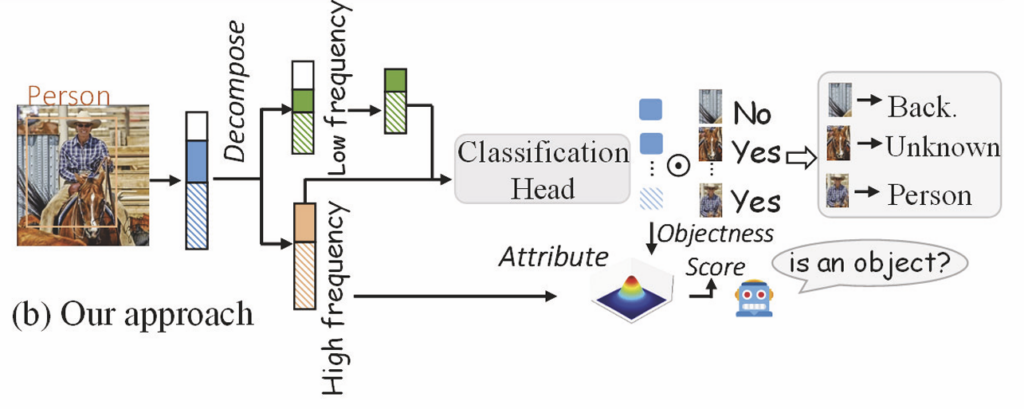
DOTA는 스타일과 의미론적 정보를 구분하기 위해 wavelet transform을 사용하여 feature map을 주파수 영역에서 분해합니다. 저자들은 저주파 성분이 주로 도메인 변화에 민감한 스타일 정보를 담고, 고주파 성분은 도메인 불변적인 구조적 특징을 보존한다는 점에 집중하였습니다. 이에 따라, 저주파 성분은 다양한 도메인 변화를 모사하도록 교란하고, 고주파 성분은 객체성 판단에 활용하므로써, 도메인 변화 상황에서도 unknown 객체를 안정적으로 탐지하고자 하였습니다. 또한, wavelet energy와 known 카테고리의 프로토타입의 의미론적 정보의 편차를 함께 사용하여 unknown 카테고리를 직접 정의하지 않고도 objectness score를 추정하도록 설계하였다고 합니다.
해당 논문의 contribution을 정리하면 다음과 같습니다.
- 주파수 분해를 통해 스타일과 구조를 구분하여 도메인 변화 상황에도 강인하게 unknown 객체를 탐지할 수 있는 object detection 프레임워크 DOAT를 제안
- energy-guided attribution과 semantic-guided attribution을 결합해 query에 category-agnostic score를 부여하는 새로운 objectness attribution 메커니즘을 제안
- 다양한 실험을 통해 DOAT의 효과를 입증함
Preliminary and Motivation
[Problem Formulation]
라벨이 있는 source 도메인 \mathcal{D}_s = \{(x^i_s,y^i_s)\}^{n_s}_{i=1}가 주어졌을 때, x^i_s는 이미지, y_s^i는 knwon 카테고리 집합C_s.으로 구성된 bounding box들과 라벨 집합들을 의미합니다. 일반화 가능한 object detection은 Domain shift 문제와 Category shift 문제를 다룹니다. 즉, 학습은 레이블이 있는 소스 도메인에서만 수행되지만, 테스트 시에는 분포가 다른 타깃 도메인에서 알려진 클래스뿐 아니라 학습에 없던 미지 객체까지 탐지하는 것을 목표로 합니다.
[Motivation of Objectness Score]
unknown객체는 학습 과정에 관찰되지 않은 새로운 카테고리뿐만 아니라 source 도메인 내부에 존재하지만 라벨이 없었던 객체들도 포함됩니다. 많은 기존 연구들이 C_s+1 개의 클래스를 갖는 classification head를 학습시키기 위한 pseudo labeling 방식을 사용하였으며, 이러한 방식은 도메인 변화가 발생할 경우 신뢰성이 떨어집니다. 따라서, 최근에는 known객체와 unknown객체가 모두 배경과 구분되는 ‘객체 다운 특성’을 가지고 있다는 점에 집중하여 객체의 존재 여부를 카테고리와 무관하게 명시적으로 모델링하는 objectness head를 도입한 연구가 등장하였습니다. 이는 쿼리 \mathbf{q}_i가 주어졌을 때 objectness 확률 p(o|\mathbf{q}_i)을 추정하는 것으로, 아래의 식으로 정의됩니다.
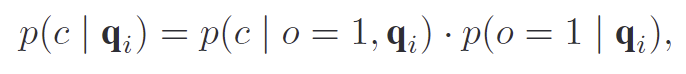
여기서 p(c| o=1, \mathbf{q}_i)는 객체가 존재한다고 가정했을 때, 해당 쿼리가 클래스 c에 속할 확률을 의미합니다. 이를 통해 unknown 객체가 known 카테고리로 잘못 분류될 가능성을 줄이고자 하였으며, unknwon 객체에 대하여 명시적인 라벨을 생성할 필요가 없도록 하였다고 합니다. 이러한 objectness head는 카테고리와는 무관하게, 객체 존재 여부를 추정하는 역할만을 담당합니다.
Method
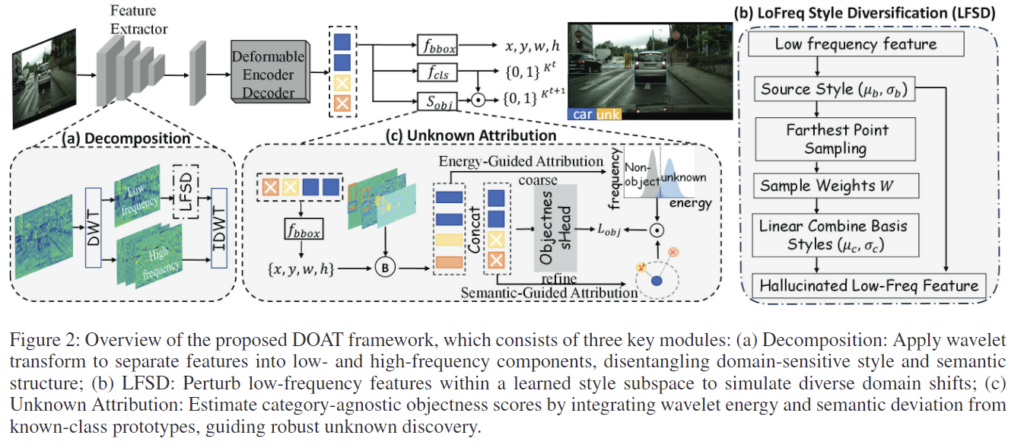
figure 2는 해당 논문에서 제안하는 DOAT 프레임워크로, deformable DETR를 기반으로 설계되었습니다. DOAT는 크게 3가지 요소로 구성됩니다. (1) 고주파와 저주파 feature를 구분하는 wavelet transform 기반의 Frequency-based Feature Decomposition, (2) 저주파 feature에 변동을 주어 새로운 환경에 적응력을 높이는 style diversification for unseen perception, (3) 고주파 단서를 활용하여 이전에 보지 못한 객체를 인식하는 objectness attribution or unknown discovery.
(1) Frequency-based Feature Decomposition
먼저, 서로 다른 정보를 담고있는 feature의 저주파 성분과 고주파 성분을 분리합니다. 저주파는 주로 대략적 구조와 관련 있고, 고주파는 더 세밀한 디테일과 물체 윤곽 정보를 얻을 수 있다고 알려져 있으며, 기존의 주파수 기반의 방법론들은 FFT(Fast Fourier Transform)를 이용하여 접근하였습니다. 그러나 저자들은 FFT는 전역적인 주파수 표현을 사용하기 때문에 객체 탐지와 같이 local한 구조가 중요한 작업에는 부적절하다고 보았습니다. 따라서 저자들은 공간적 지역성을 보존하는 DWT(Discrete Wavelet Trasnform)를 채택하여 시각적 특징의 비정상적이고 국소적으로 구조화 된 특성을 모델링하고자 하였습니다.
백본의 l번째 feature \mathbf{f}_l를 아래의 식으로 정의되는 4가지 커널(LL^T, LH^T, HL^T, HH^T)과 각각 convolution 연산을 거쳐 고주파 특징(\mathbf{f}^{LH}_l,\mathbf{f}^{HL}_l,\mathbf{f}^{HH}_l)과 저주파 특징(\mathbf{f}^{LL}_l)으로 분해합니다.
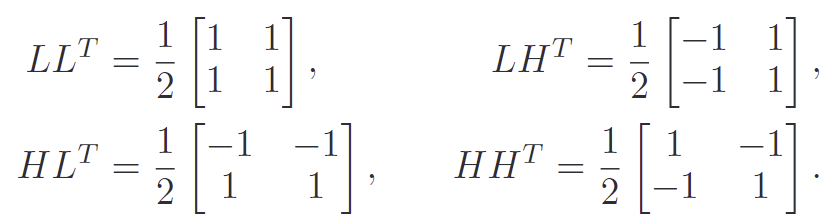
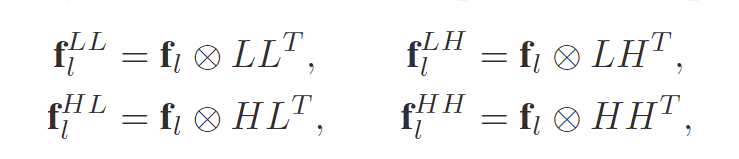
(2) Style diversification for unseen perception
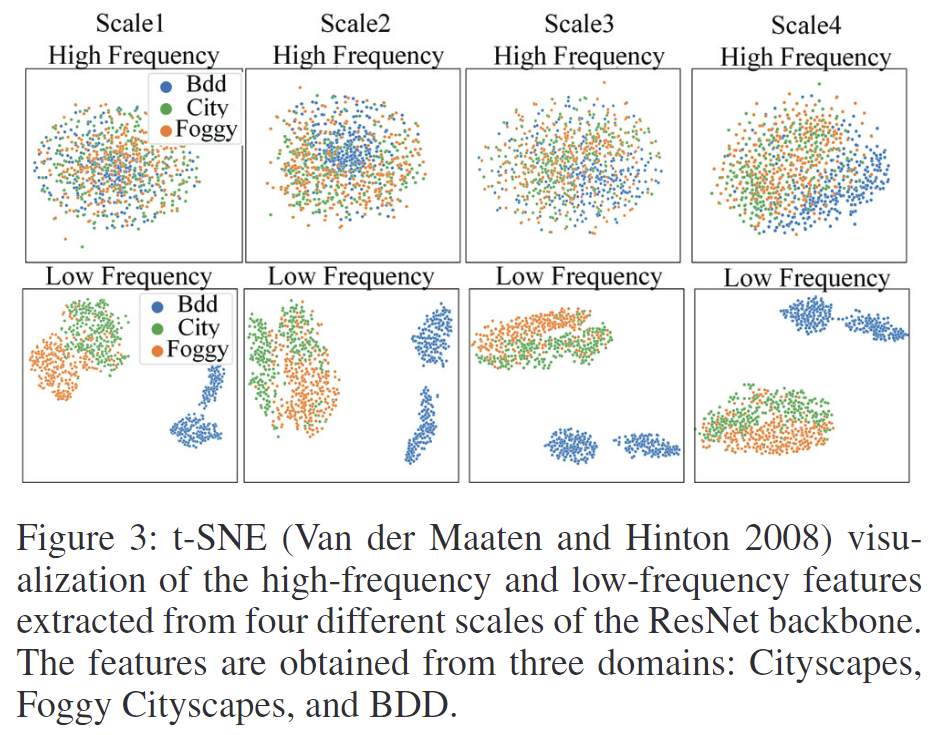
위의 Figure 3은 백본에서 나온 특징들의 저주파와 고주파 특징을 시각화 한 결과입니다. 저주파의 경우 3가지 환경에서 구분이 뚜렷하였으며, 저주파는 3가지 환경에서 중첩되어 나타나는 것을 확인할 수 있습니다. 저자들은 저주파 성분에 스타일 정보가 포함되고, 고주파 성분에 도메인 간에도 비교적 일관된 의미 구조와 객체 경계를 유지한다고 보았고, 이러한 저주파 특징에만 변동을 주어 도메인 특유의 변화를 모사하는 LoFreq Style Diversification
(LFSD)를 제안하였습니다.
LFSD는 변동을 줄 때 의미론적 내용을 훼손하지 않고, 스타일 다양성을 증가시키면서도 현실성을 유지하기 위해, 변동을 실제 데이터에서 추출한 스타일 공간\mathcal{S}내부로 제한합니다. 랜덤하게 스타일 벡터를 샘플링하면 비현실적인 스타일이 생길 수 있으므로, \mathcal{S} 내에서 AdaIN-style re-normalization 방식으로 저주파 특징의 평균과 분산을 조정합니다.
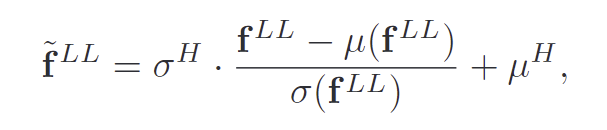
- (\mu^H,\sigma^H): 합성된 스타일의 평균과 표준편차
기존 연구들처럼 단순하게 혼합하는 방식은 단일 source환경에서 다양성을 충분히 반영하지 못하므로, 이를 보완하기 위해 저자들은 source style \{(\mu^j_b,\sigma^j_b)\}^N_{j=1}에 FPS(가장 먼 점들을 선택하는 샘플링 방식 farthest point sampling)를 적용하여 최대한 다양한 표현력을 가지는 \{(\mu^k_b,\sigma^k_b)\}^K_{k=1}를 구성한 뒤, 아래의 식을 적용하여 스타일을 합성합니다.
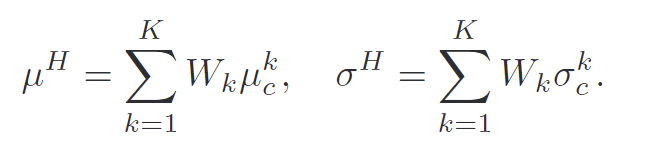
이때, K=C(\mathcal{S}의 feature 차원 수)로 설정하여, \mathcal{S}를 충분히 커버할 수 있도록 하였다고 합니다. 이러한 과정을 통해 LFSD는 스타일적으로는 다양하면서도 현실적인 변동을 주어 도메인 변화에도 일반화가 가능하도록 설계하였습니다.
(3) Objectness attribution or unknown discovery
고주파 단서를 활용하여 학습 과정에 본 적 없는 unknown 물체를 발견하기 위해, 저자들은 class-agnostic한 방식으로 objectness를 효과적으로 부여하는 방식을 설계하였습니다. 일반적 객체성 특성으로 윤곽, local contrast, 구조적 폐쇠성이 있으며, 이러한 특성은 wavelet으로 분해된 고주파 성분에 보존된다는 것을 관찰하여, 이를 활용하는 objectness attribution 모듈을 제안합니다.
먼저, objectness score를 효과적으로 추정하기 위해, 저자들은 2가지 상호보완적인 attribution 메커니즘을 설계합니다.
- Energy-Guided Attribution(EGA)
- 각 query가 주목하는 영역의 구조적 풍부함(structural richness)을 고주파 wavelet energy를 기반으로 정량화
- Semantic-Guided Attribution(SGA)
- semantic space에서 해당 query가 알려진 클래스 임베딩 분포로부터 얼마나 벗어나 있는지를 측정
이 두가지 단서를 활용하여 objectness head를 학습하므로써, class-agnostic하게 objectness를 추정하도록 합니다.
[Energy-Guided Attribution(EGA)]
예측된 박스 영역 내 고주파의 energy를 계산하여 해당 쿼리 영역의 구조적 풍부함을 측정합니다. 각 bbox에 해당하는 feature의 \mathbf{f}^{LH}_l,\mathbf{f}^{HL}_l,\mathbf{f}^{HH}_l를 추출한 뒤, 아래의 식을 이용하여 eneregy를 계산합니다.
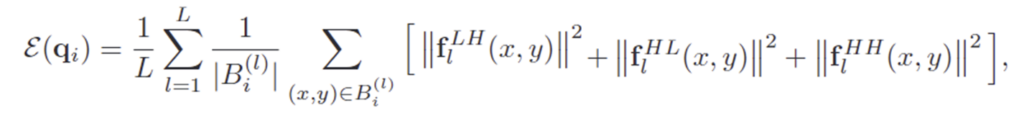
- ||.||^2: channel 방향 제곱을 의미하며, feature의 차원을 유지
이렇게 계산된 energy는 쿼리의 임베딩과 concat되어 objectness head에 입력으로 들어가 objectness socre를 예측하는 데 사용됩니다.
[Semantic-Guided Attribution(SGA)]
그러나 energy 만을 이용할 경우, 텍스쳐가 풍부한 배경도 객체로 잘못 강조될 가능성이 있습니다. 이를 보정하기 위해 저자들은 semantic-guided attribution을 설계하였습니다. known 카테고리의 query들과 semantic distance를 계산하여 unknown 객체를 찾기 위한 사전 지식으로 활용합니다. 구체적으로, known 객체 임베딩의 중심을 나타내는 프로토타입 \hat{\mathbf{q}}과 각 쿼리에 대하여 아래의 식으로 semantic distance를 구합니다.
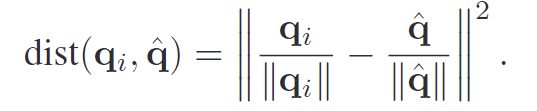
최종 semantic-guided objectness socre는 아래의 식으로 계산되며, \hat{\mathcal{E}}는 정규화된 energy score를 의미하며, \tau는 영향 정도를 조절하는 하이퍼파라미터입니다.
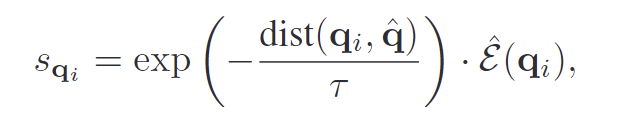
s_{\mathbf{q}_i}는 0~1 사이의 값으로, objectness head 학습에 사용되며, loss는 아래의 식으로 정의됩니다.
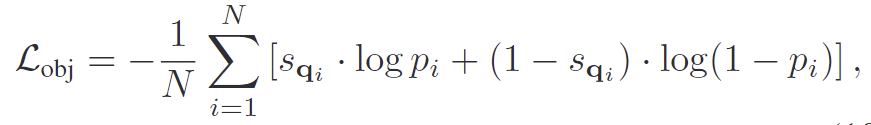
- p_i: 예측된 objectness 확률
- N: 쿼리 개수
Experiments
저자들은 domain shift와 unknown category shift가 동시에 존재하는 세팅에서 DOAT의 효과를 검증하고자 하였습니다. Cityscapes → Foggy Cityscapes/BDD100K와 Pascal VOC → Clipart1K라는 2가지 케이스로 구분되며, 전자의 경우 known과 unknown의 의미론적 유사성에 따라 4가지(아래 참고)와 unknown 클래스 수에 따른 3가지 케이스로 총 12가지 케이스로 실험을 진행하였으며, 후자의 경우는 unknown category 개수로만 구분하여 3가지 케이스로 실험을 진행하였다고 합니다. 사용한 평가지표는 known 카테고리의 성능은 mAPk, unknown 카테고리 탐지는 ARu, WI, AOSE를 사용하였으며, WI와 AOSE는 새로운 객체를 기존 base class로 잘못 예측하는 정도를 나타냅니다.
- heterogeneous semantics (het-sem): known과 unknwon이 차이가 큰 경우. semantic overlap이 낮은 경우
- homogeneous semantics (hom-sem): known과 unknwon이 의미론적으로 유사한 경우. semantic overlap이 높아서 더 헷갈리는 경우
- frequency decrease (freq-dec): unknown 객체가 드물게 등장
- frequency increase (freq-inc): unknown 객체가 상대적으로 더 자주 등장
Main Results
[Cityscapes → Foggy Cityscapes]
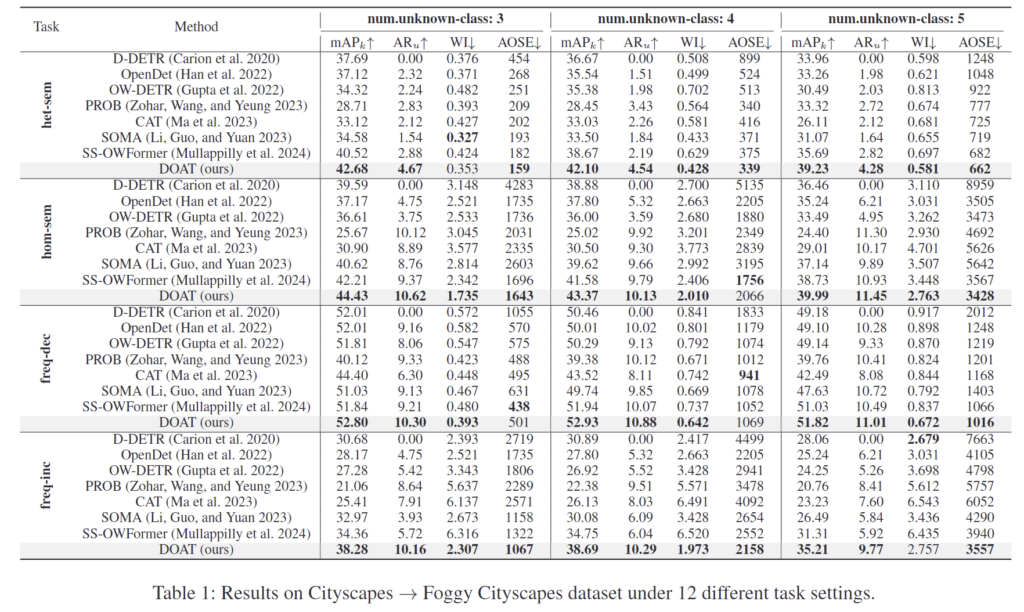
Table 1은 12가지 설정에서 실험 결과를 나타낸 것으로, 전반적으로 unknonw class detection 성능이 우수한 결과를 나타낸다는 것을 확인할 수 있습니다. 이를 통해 저자들이 제안한 DOAT가 category shift 상황에도 효과적이라는 것을 보였습니다. 아래의 Figure 4는 정성적 결과로, DOAT가 unknwon 인스턴스를 더 정확히 식별하며 BBox도 정밀하게 예측하는 것을 볼 수 있습니다.

[Pascal VOC → Clipart]
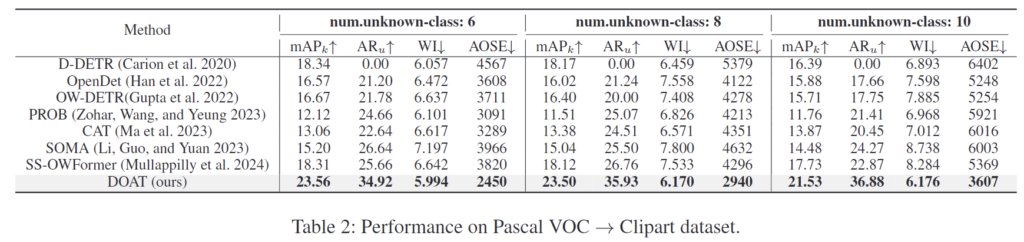
Table 2를 통해 DOAT가 unknown class 수가 달라지는 모든 케이스에서 성능이 개선되었다는 것을 확인할 수 있습니다. 이는 큰 도메인 및 스타일 변화가 있어도 새로운 객체를 잘 탐지하며, unknown class 수가 증가해도 안정적으로 성능이 유지된다는 것을 보여줍니다.
[Cityscapes → BDD100K]
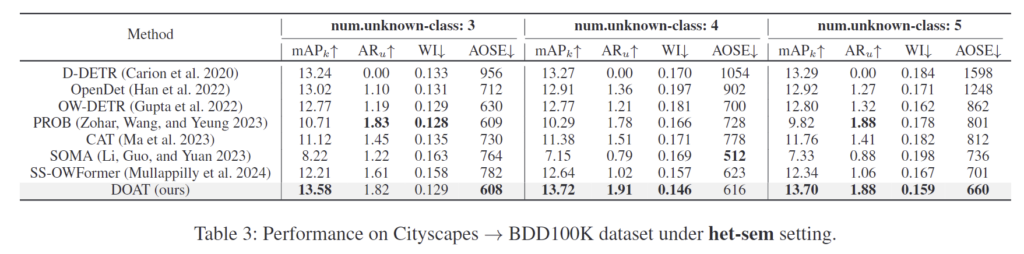
Table 3은 known과 unknown의 의미론적 차이가 큰 케이스에서 unknown class 수에 따른 성능을 나타냅니다. 대부분 DOAT 성능이 좋지만, 앞선 실험들에 비해 성능 개선 폭이 적습니다. 이에 대해 저자들은 BDD100K 자체가 저조도, motion blur, small object 등 난이도가 높은 데이터 셋 이기 때문이라고 설명하였습니다.
Ablation study
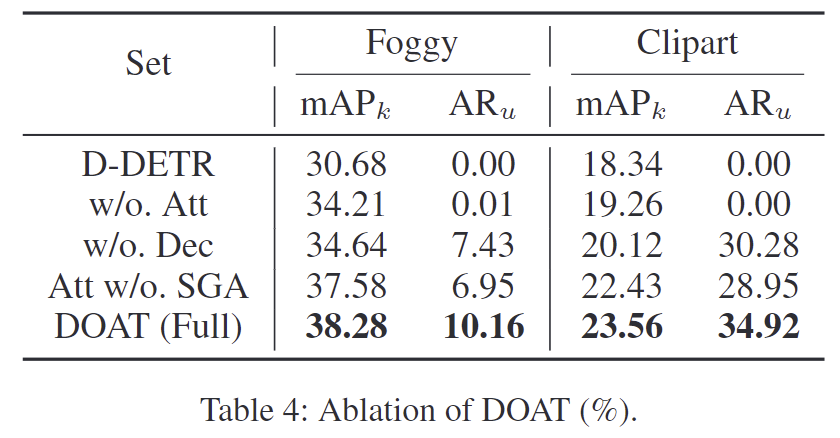
Table 4는 주파수에 따라 구분한 decomposition(Dec)과 objectness attribution 모듈(Att)의 효과를 확인하기 위한 ablation study 입니다. 두 모듈 모두 unknown 객체를 탐지하는 데 유의미하게 기여하였다는 것을 확인할 수 있으며, 둘 중 하나를 제거하였을 대 성능이 크게 저하되는 것을 확인할 수 있습니다. 또한, SGA를 제거할 경우 objectness 추정 성능(AR)이 크게 저하됨을 확인할 수 있습니다.
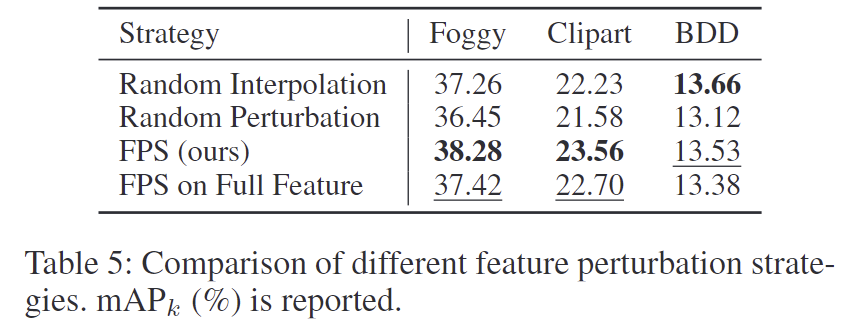
Table 5는 style을 다양화 하는 과정에 대한 실험 결과로, 랜덤한 방식보다 FPS로 샘플링하여 변동을 주는 방식이 더 좋은 효과를 보여주는 것을 확인할 수 있습니다.
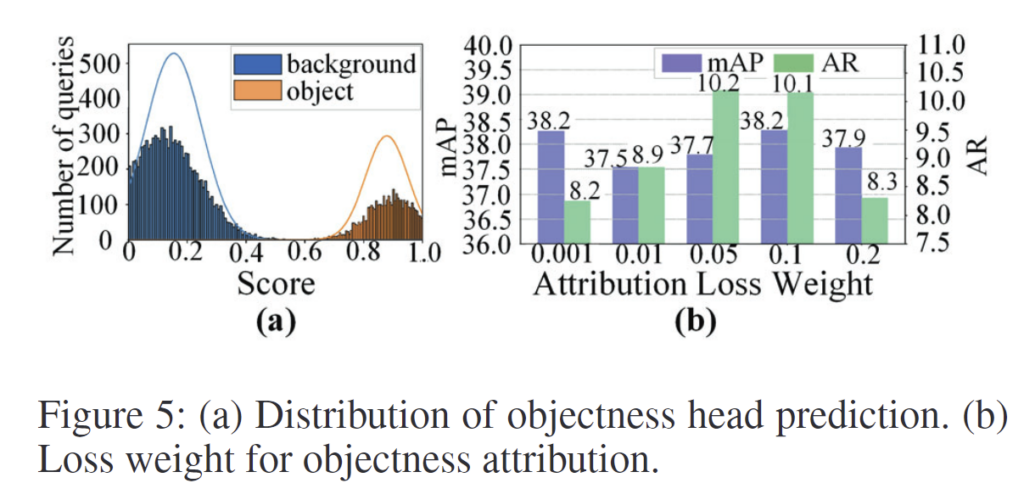
위의 Figure 5(a)는 objectness head가 예측한 점수 분포를 보여주며, 전경과 배경에 대한 query가 비교적 뚜렷하게 구분되는 분포를 형성한다는 것을 확인할 수 있습니다. 이는 제안한 방식이 해석 가능한 objectness space를 안정적으로 학습하고 있음을 보여줍니다.
또한 Figure 5(b)에서는 attribution loss weight를 변화시켜도 성능이 전반적으로 안정적으로 유지되는 것을 확인할 수 있습니다. 이를 통해 objectness attribution 방식이 해당 하이퍼파라미터에 크게 민감하지 않으며, 실제 적용 시에도 비교적 안정적으로 사용할 수 있다고 설명하였습니다.
좋은 리뷰 감사합니다.
DWT를 backbone feature에 적용한다고 하셨는데, 이 feature는 FPN의 특정 레벨(feature pyramid 중 하나)인지, 아니면 multi-scale feature를 모두 사용하는지 궁금합니다.
질문 감사합니다.
multi-scale을 사용하는 것으로 보입니다. 제가 수식 설명에 누락하였는데, Energy-Guided Attribution과정의 energy 계산식에 있는 l이 multi-scale의 feature를 나타내는 것 입니다.
안녕하세요 승현님 좋은 리뷰 감사합니다!
Semantic-Guided Attribution(SGA)에서 구한 semantic distance가 unknown 객체를 찾기 위한 사전 지식으로 활용된다고 해주셨는데, known 카테고리의 프로토타입과 거리를 비교하는 것이, 어떻게 텍스쳐가 풍부한 배경과 object를 구분하는데 도움을 준다는 것인지 궁금합니다.
질문 감사합니다.
우선, energy를 구하는 방식은 구조적으로 풍부한 영역으로, 텍스쳐가 풍부한 배경이 잘못 인식되는 경우 이를 걸러내는 과정이 필요합니다. SGA는, known 카테고리의 임베딩 중심과 쿼리 영역의 임베딩 feature의 distance를 측정하고, 구해진 distance를 score에 이 수치를 활용하여 score를 조정하게 됩니다. distance의 음수값을 지수함수에 적용하는 것이므로, distance가 커질수로, 0에 가까워지게 되는 것 입니다. 즉, score값이 작아지게 되는 것이죠. 이렇게 하여, known 클래스와 너무 먼 물체들은 유의미한 객체 영역이 아니라 생각하고 지우게 됩니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
제가 요즘 FFT에 부쩍 관심이 많이 생겼는데요.
policy steering 을 위한 failure detection 관점에서 시퀀셜한 action generation 데이터나 obs로부터 실패할 수 있는 상황을 잘 특정할 요소나 정량화를 단순 uncertainty 말고 어떻게 표현하면 좋을까에 대해 요즘 고민이 많은데, 저에게 정말 많은 영감을 주는 리뷰인 것 같습니다! 도움이 많이 되었습니다.
SGA와 EGA 모두 policy steering 관점에서의 OOD detection 의 정량화요소로 적용해볼 수 있을 것 같은데, 승현님은 이 관점에 대해 어떻게 생각하시는지 궁금합니다!
질문 감사합니다.
우선, 재찬님이 구두로 설명해주신 내용을 들었는데, 생각하시는 방식이 steering 관점에서는 유의미하게 적용이 될 수 있을 것 같습니다. 그러나, 작업 관점에서의 고주파와 저주파에 대해서 이야기하신 내용은 가설이다보니 해당 논문의 figure 3처럼 실험을 통해 확인해야 할 것 같고, OOD detection 관점에서는 어떻게 활용 될 수 있을지에 대한 고민이 더 필요할 것 같습니다.