안녕하세요 이번에 들고온 논문도 VLM 에서의 Token pruning 논문입니다.
최근에 나온 VLM token pruning 논문들의 성능이 훨씬 개선되기도 했지만, 24년도의 FastV와 마찬가지로 llm decoder단에서의 visual-text 토큰을 이용한 pruning 방법론을 사용합니다.
그럼 리뷰 시작하겠습니다.
Abstract
최근 SOTA 방법론들이 나오기 직전 논문인지라 기존의 방법론들과의 차별성으로 training free라는 점을 강조하면서 시작하는데, 다들 잘 알다싶이 VLM 에서의 visual token 들이 텍스트 토큰에 비해 훨씬 많은 계산량을 차지한다는 문제점을 해결하고자 합니다.
저자의 핵심 주장은 visual token이 독립적인 의미를 가지기 보다는 텍스트 기반의 reasoning을 보조하는 역할을 한다는 점이라고 합니다. 따라서 visual token이 필요한지는 결국 text token과의 관계를 통해 판단할 수 있다고 보고, sefl-attention matrix를 활용하여 text token 과 관련된 visual token의 중요도를 계산합니다. ( 이는 FastV 계열이라 생각하면 됩니다. ) 즉 text 기준으로 relevant한 visual token 을 남기고 나머지를 제거하는 방식입니다.
또한 단순히 일정 비율로 토큰을 제거하는 것이 아니라, attention 기반 ranking을 통해 각 layer마다 pruning 비율을 다르게 설정하는 rank-based 전략을 사용합니다. 이를 통해 layer 별로 필요한 정보량에 맞게 token 수를 조절할 수 있습니다. 여기에 더해, 제거되는 token을 단순히 버리는 것이 아니라 더 compact 한 형태로 압축하여 활용하는 token recycling 방법을 도입함으로써 정보 손실을 줄이려는 시도를 합니다.
저자는 결과적으로 SparseVLM이 별도의 학습이 없고 다양한 VLM 구조와 이미지 및 비디오 이해 task 에서 계산 효율을 크게 개선하면서도 성능을 유지하는 결과를 보여, text 기준으로 visual token을 선택하는 방식의 효과를 보여줍니다.
Introduction
최근 LLM의 발전과 함께 VLM 들도 빠르게 발전해왔습니다. 현재 대부분의 VLM은 이미지를 visual token으로 변환한 뒤 이를 LLM의 decoder에 입력하는 sequential representation 구조를 사용하며, 여기에 modal alignment와 instruction tuning을 결합해 LLM의 추론 능력을 시각 영역까지 확장하고 있습니다.
여러번 언급했지만, Visual token 이 LLM에 추가가 되면서, 메모리와 계산량이 크게 증가하는 문제가 생겼고, LLaVA에서 672*672 해상도의 이미지를 사용하면 2304개의 visual token이 생성되어 전체 context 길이의 절반 이상을 차지하게 됩니다.
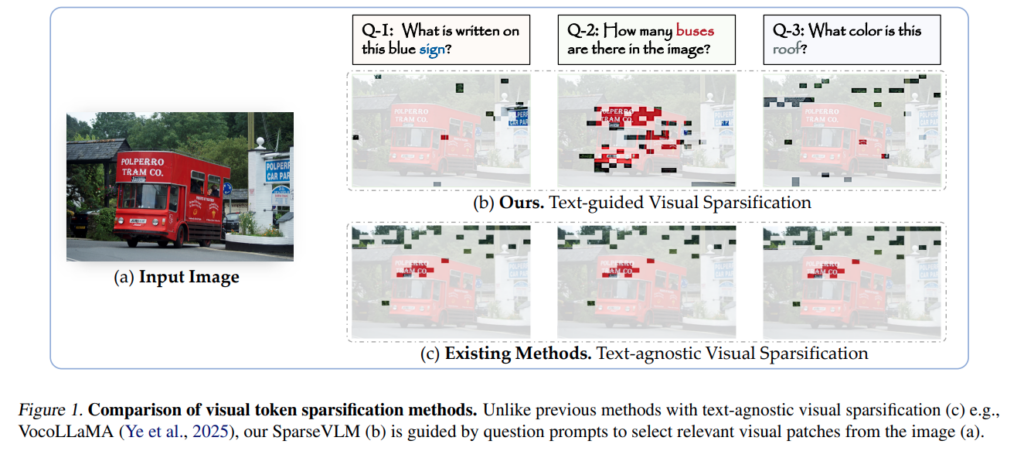
해당 저자의 논문 이전에는 이러한 문제를 해결하기 위해서 image encoder나 projector를 수정하여 compact한 representation을 만들거나, decoding 과정에서 visual token을 줄이는 방식을 제안해왔다고 합니다. 다만 이러한 방법들은 대부분 text정보를 고려하지 않고 visual token을 줄이는 방식이며, 이는 멀티모달 구조에서 text와 visual의 상호작용을 충분히 활용하지 못한다는 한계가 있습니다. 실제로 하나의 이미지라도 질문에 따라 모델이 집중해야 하는 영역이 달라질 수 있기 때문에, visual token은 입력 텍스트에 따라 적응적으로 선택될 필요가 있습니다. Figure 1에서도 동일한 이미지에 대해 질문이 달라지면 모델이 봐야 하는 영역이 달라지는 것을 보여주고 있습니다.
또한 기존 방법들은 대부분 별도의 네트워크를 학습해서 visual token을 제거하는 방식이기 때문에 추가적인 학습 데이터와 비용이 필요하다는 문제도 존재합니다.
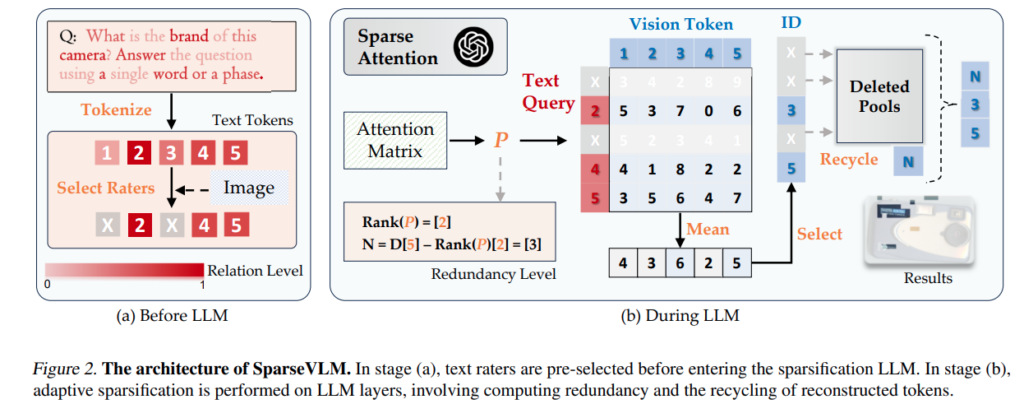
이 논문에서는 이러한 문제를 해결하기 위해 SparseVLm이라는 text-guided, training-free 방식의 framework를 제안합니다. 이 방법은 별도의 학습 없이 language model 내부의 self-attention을 그대로 활용하여 visual token을 선택하고 줄이는 방식입니다. 여기서 중요한 점은 모든 text token을 동일하게 사용하는 것이 아니라, visual 정보와 강하게 연관된 text token만을 선택한다는 것입니다. 논문에서는 이러한 token을 visual-relevant text token, 즉 ‘rater’ 라고 정의하고, 이들이 visual token의 중요도를 평가하도록 합니다.
구체적으로는 먼저 cross-attention을 통해 visual과 관련된 text token을 선택하고, 이후 이 text token들이 각 visual token에 얼마나 기여하는지를 기준으로 중요도를 계산하여 불필요한 visual token을 제거합니다.
그리고 단순히 token을 버리는 것이 아니라, 제거된 token들을 다시 모아서 더 compact한 형태로 재구성하는 token recycling 과정을 통해 정보 손실을 줄입니다.
또한 이미지마다 정보 밀도가 다르다는 점을 고려하여, attention matrix의 rank를 활용해 redundancy수준을 추정하고 layer별로 pruning 비율을 adaptive하게 조절합니다.
이 방법이 구조적으로 단순하면서도 plug-and-play 방식으로 다양한 VLM에 적용할 수 있으며, 추가적인 학습 없이도 계산량을 크게 줄이면서 성능을 유지했다고 합니다. 실제 LLaVA에서 44.5배의 압축률에 97%의 성능을 유지하며 latency도 37%나 감소하는 결과를 보였다고 합니다.
Method
전체 흐름은 먼저 VLM에서의 attention 구조를 정리하고, 그 다음에 visual token을 줄이기 위한 세 가지 핵심 단계를 제안합니다.
- visual token 중요도 계산
- relevant text toekn 선택
- sparsification 비율을 결정하는 방식
이후에는 pruning 과정에서 발생하는 정보 손실을 줄이기 위해 token recycling을 추가로 제안합니다.
Sparsification Guidance from Text to Vision
먼저 visual token 하나가 text 에 얼마나 중요한지를 정의합니다.
이를 위해 self-attention matrix에서 text→visual 방향 interaction만 가져옵니다.

그 다음 이걸 text 방향으로 평균내서 계산하고 각 visual token의 중요도를 나타내는 벡터로 사용합니다.
그 다음 Relevant Text Token을 선택하는 과정이 있는데 모든 Text Token을 쓰면 안되고 visual 과 관련 있는 text token만 골라서 그걸 ‘rater’로 사용합니다. 아래의 figure 3을 확인해보면 일부 단어는 이미지와 거의 관련이 없다는 것을 알 수 있습니다.

그 다음 text와 visual embedding 간 similarity를 구하고 이 값을 기준으로 평균보다 큰 Token만 선택합니다.
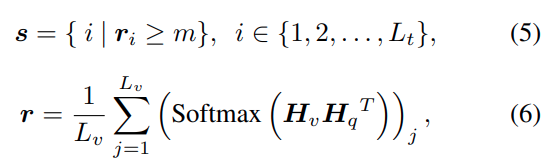
여기서 H_v와 H_q는 각각 embedding vector로 생각하시면 됩니다.
이제 얼마나 token을 줄일지 결정합니다.
Sparsification Level Adaptation
여기서 저자는 attention matrix의 rank를 사용하는데, rank가 높으면 정보가 다양하여 덜 줄여야한다고 판단하고, rank가 낮으면 redundancy가 많아서 많이 줄여도 된다고 판단합니다.
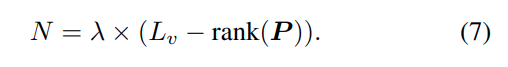
삭제할 token은 위의 수식으로 결정합니다. 즉 입력마다 pruning 비율이 다르게 적용됩니다. 위에서 P라는 text-visual interaction 행렬은, text token이 visual token을 얼마나 참조하는지를 나타내는 행렬이라고 볼 수 있습니다. 따라서 논문에서는 L_v - \mathrm{rank}(P)를 redundancy로 정의하고, 여기에 \lambda를 곱하여 실제로 삭제할 token 개수 N을 결정합니다.
결과적으로 입력마다, 그리고 layer마다 visual token이 얼마나 줄어들지가 달라지게 되며, “이 이미지가 얼마나 중복되어 있느냐”에 따라 adaptive하게 pruning이 이루어지는 구조라고 볼 수 있습니다. 위의 Figure 2를 보면 앞단에서 rater를 먼저 고르고, 그 다음에 이를 기준으로 P를 계산하고, 그 rank를 이용하여 pruning 강도를 결정하는 흐름이라고 생각하면 됩니다. 그리고 rank를 계산하는데에는 아래의 FLOPS가 든다고 합니다.
L_t \times L_v \times \min(L_t, L_v)Visual Token Recycling
앞에서 pruning을 layer마다 계속 진행하게 되면, 뒤로 갈수록 점점 더 많은 visual token이 제거됩니다. 그런데 여기서 제거된 token들이 전부 쓸모없는 정보는 아니라는 점입니다. 실제로는 중요도가 낮긴 하지만, 그 중에서도 상대적으로 값이 큰 token들은 여전히 일정 수준의 정보를 가지고 있습니다. 저자는 그래서 단순히 token을 버리는 것이 아닌 다시 활용해서 정보 손실을 줄이겠다는 접근을 취합니다.
먼저 Token Aggregation 단계에서는 삭제된 token 들 중에서 상위 τ%정도, 즉 완전히 중요하지는 않은 token들을 다시 가져옵니다. 이걸 recycled token이라고 보면 됩니다.이후 이 token들을 서로 비슷한 것끼리 묶는 clustering을 수행하는데 이때 사용하는 방식이 density 기반 clustering이라고 하고 각 token에 대해 두 가지 값을 계산합니다.
첫 번째는 local density ρ인데 KNN 기반으로 그로게 되고, 동시에 자신보다 더 높은 density를 가지는 token과의 최소 거리 $\delta_i$를 계산합니다. 이후 $p_i$ X $\delta_i$ 를 기준으로 score를 정의하며, score가 높은 token을 cluster center로 선택합니다. 나머지 token들은 cosine similarity를 기준으로 가장 가까운 cluster center에 할당됩니다.
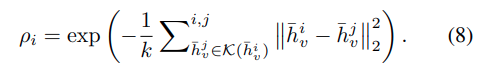
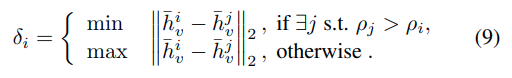
이 과정을 통해 유사한 semantic을 가지는 token들이 하나의 그룹으로 묶이게 되며, 이후 token reconstruction 단계에서 각 그룹에 속한 token들을 element-wise-sum 을 통해 하나의 token으로 압축합니다. 결과적으로 여러 개의 token을 하나의 compact representation으로 변환함으로써 정보 손실을 최소화하며 token수를 줄이는 것이 가능합니다.
Theoretical Analysis of Computational Complexity
이 부분에서는 제안한 방법을 통해 줄어드는 계산량을 분석합니다. transformer layer에서의 주요 연산은 multi-head attention과 FFN에 의해 결정되며, token 수가 감소하면 이 두 연산의 FLOPs가 동시에 줄어들게 됩니다. 논문에서는 pruning을 통해 감소하는 연산량과, rank 계산 및 token recycling 과정에서 추가되는 연산량을 각각 정의한 후, 이를 종합한 전체 FLOPs감소량을 알려줍니다.
결과적으로 추가되는 overhead가 상대적으로 작고 pruning 을 통해 감소하는 연산량이 훨씬 크다고 합니다. 다만 저자의 방식으로 pruning을 하게되면, Flashattention을 사용할 수 없기 때문에 그러한 점에서는 엄청난 단점이라고 생각할 수 있습니다. 다만 저자는 이 점을 의식했는지 appendix에 이attention을 따로 추출하는 방법을 구현했다고 합니다.
Experiment
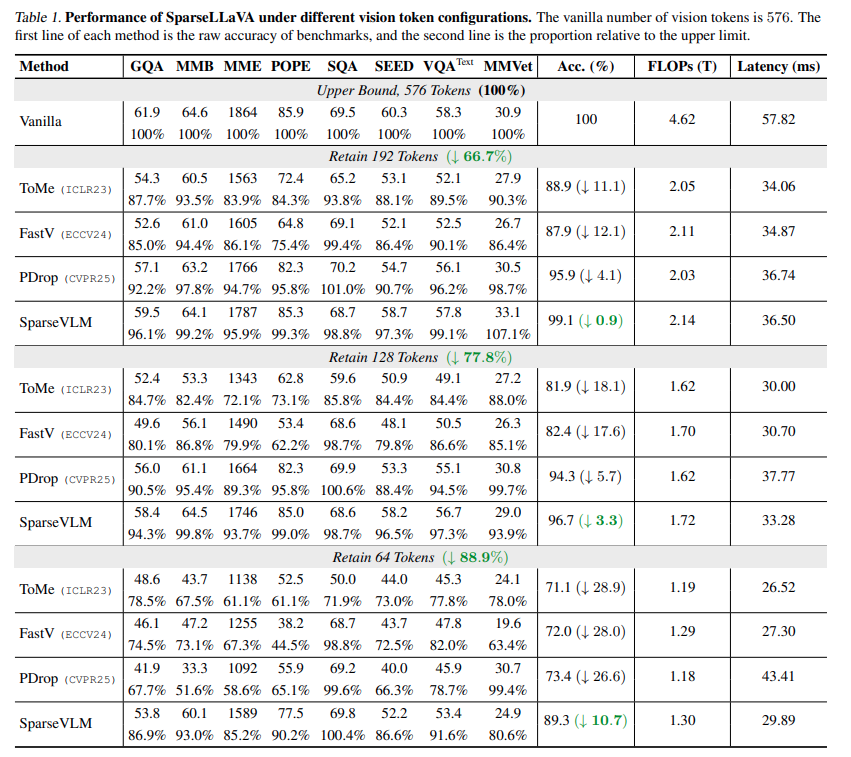
기존 방법론들과의 성능차이입니다. 이전 X-review를 생각하면 SparseVLM도 성능이 높은편은 아니지만 저 당시에는 64token에서도 꽤나 높은 성능 향상을 이룬 것을 알 수 있습니다. 해당 SparseVLM논문 이후 여기까지의 논문들을 비판하는 ACL findings 논문이 나오는데, SparseVLM까지의 성능이 사실 random 성능보다도 낮다는 분석이 나옵니다. 이후 25년 상위학회논문들은 random 성능보다는 높게 발전되는데, 전부 CLIP ViT의 [CLS]토큰 기반의 attention 을 이용한 방법론들입니다.
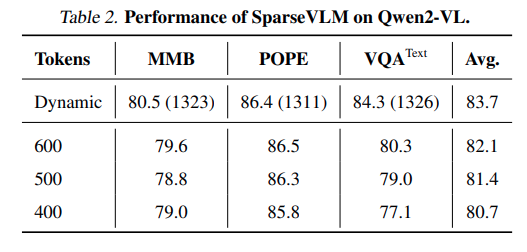
해당 Table은 Qwen2-VL에서의 성능입니다.

해당 figure는 저자가 질문에 적합한 부분만 token으로 남는 것을 잘 보여주는데, 이러한 pruning 능력에도 불구하고 현재는 text-agnostic한 방법론들이 SOTA인점이 아이러니합니다.
Conclusion
이 논문에서는 text-aware, training free 방식의 token optimization 방법을 제안하고 이를 통해 다양한VLM 에서의 추론 시 계산량을 크게 줄일 수 있음을 보여줍니다. text에 관련된 지역을 pruning 하는 방식이 사실 성능이 더 좋을 것 같은데, 다른 논문들이 밝힌 attention shift등의 문제때문일 수 있지만 성능이 더 낮다는 점이 분석하기 쉽지 않은 것 같습니다.
감사합니다.
안녕하세요 인택님
지우게 될 토큰 수를 다양성 측면에서 적응적으로 선택하는 방법이 흥미롭습니다. 프루닝 연구에서 일반적인 접근/구현 방법인지 궁금하네요! 질문이 몇가지 있는데 먼저 뒤로 갈수록 점점 더 많은 visual token이 제거되는 이유는 layer가 깊어질수록 맥락적 정보를 담고있어 공통 정보가 많기 때문일까요?
두번째로는 recycling 과정이 결국은 중요도 중간 수준의 토큰은 머징해서 사용하는 방법같은데 해당 방법이 너무 엔지니어링 측면이라는 비판이 있을 수 있는지 궁금합니다. 혹시 중간 수준이 아닌 모든 토큰을 머징해서 줄이는 방법과도 비교가 되었는지도 궁금하네요!
좋은 리뷰 감사합니다!
안녕하세요 유진님 좋은 답글 감사합니다.
지우게될 토큰수를 적응적으로 선택하는게 제가 읽은 논문들 기준으로는 일반적인 접근은 아닌 것 같습니다.
다만 실제 코드를 확인해본 결과 llm layer에서 얼마나 지울지에 대한 비율이 그냥 하드코딩되어있네요..
두번째 질문에 대해서는 기존의 ToMe 방법론이 전체 merge 계열이기 때문에 간접적인 비교가 가능할 것 같습니다.
감사합니다.
안녕하세요 신인택 연구원님 좋은 리뷰 감사합니다.
plug-and-play 방식으로 다양한 VLM에 사용할 수 있음이 SparseVLM의 강점인것 같습니다. 한가지 궁금한 점이 있습니다.
우선, 저자의 방법이 flash attention을 사용할 수 없는 이유가 궁금합니다. 그리고, appendix에서 이 attention을 따로 추출하는 방법을 구현했다고 언급해주셨는데 attention을 따로 추출하는게 KV 캐싱하는 방법을 구현했다는 의미인가요?
감사합니다.
안녕하세요 성준님 좋은 답글 감사합니다.
우선 flash attention 을 완전히 못사용하는 것은 아닙니다.
저자의 코드를 확인한 결과 2,6,15 layer에서만 pruning을 진행하여 해당 layer에서만 flash attention을 사용하지 못하고 나머지 layer에서는 flash attention을 사용하게 됩니다.
appendix에서 attention 을 따로 추출하는 방법을 구현했다는 내용은 pruning 을 진행하는 layer들에서는 flash attention 사용이 불가하기 때문에, 해당 layer들에서만 full attention 을 기존 ‘eager’ 모드처럼 구현해서 pruning하는 것으로 이해하면 될 것 같습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
token recycling 부분에서 pruning된 token 중 상위 일부 t%를 다시 모아서 clustering 후 reconstruction하는 방식이라고 하셨는데 이런 recycling하는 방식을 다양한 토큰 프루닝 방식에서 자주 사용하는 것 같습니다. 근데 여기서 recycling을 얼만큼 하느냐에 따라서도 성능이 달라질 것 같고 또 성능 이득이 pruning 자체에서 오는지 아니면 recycling 비율이 적절하다면 사실상 이부분 또한 성능 향상에 많은 기여를 할것 같은데 이걸 분리해서 결과를 보여주는 실험이 따로 있었는지 궁금힙니다.
감사합니다.
안녕하세요 우현님 좋은 답글 감사합니다.
좋은 생각이지만 개별 토큰들이 결과에 미치는 영향이 동일한 경우에만 분리해서 생각할 수 있을 것 같다고 생각했는데, ablation 충분히 해볼 수 있을 것 같긴 하네요. 따로 실험은 없었습니다!
감사합니다.