오늘은 비디오에서의 compositionality 를 분석한 논문을 리뷰해보겠습니다. 리뷰하고보니, 2022년에 저희 연구실에서 세미나를 진행해주신 구글 딥마인드의 김다훈 박사님의 논문이네요 리뷰 시작해보겠습니다.

- Venue: CVPR 2025
- Authors: Dahun Kim, AJ Piergiovanni, Ganesh Mallya, Anelia Angelova
- Affiliation: Google DeepMind
- Title: VideoComp: Advancing Fine-Grained Compositional and Temporal Alignment in Video-Text Models
- Code: GitHub
0. Background
VLM이 장면을 제대로 이해하려면, 단순히 객체를 인식하는 것을 넘어 속성, 관계, 상태를 함께 해석하는 구성성(compositionality) 추론 능력이 필요합니다. 이미지에서는 같은 객체가 등장하더라도 어떤 속성이 어떤 객체에 대응되는지, 또 객체들 사이의 관계가 어떻게 맺어지는지를 정확히 구분할 수 있어야 합니다. 예를 들어 dog chasing cat과 “cat chasing dog”는 등장 객체는 같지만 의미는 전혀 다르기 때문에, 이러한 차이를 이해하는 것이 compositionality의 핵심이라고 볼 수 있습니다.
그런데 비디오에서는 시간 축이 추가되면서 문제가 더 복잡해집니다. 비디오는 여러 사건이 순차적으로 전개되기 때문에, 모델은 어떤 객체와 행동이 등장했는지만이 아니라 각 사건이 어떤 순서로 일어나는지, 그리고 문장 속 설명이 비디오의 각 구간과 정확히 대응하는지까지 함께 이해해야 합니다. 따라서 비디오에서의 compositionality는 단순한 장면 이해를 넘어, 사건 간의 관계와 시간적 정합성까지 포함하는 문제라고 볼 수 있습니다.
1. Introduction
기존 vision-language / video-language 모델들은 보통 이 비디오가 이 문장과 대체로 맞는가 정도의 alignment를 중심으로 학습됩니다. 그러나 저자들은 이러한 모델들이 사건 순서, 행동의 미세한 차이, 비디오 구간과 문장 구간의 대응 관계와 같은 fine-grained compositionality에는 여전히 약하다고 봅니다.
비디오 compositionality 중에서도 아래 요소들에 집중하였는데요,
– 사건들의 순서가 맞는지
– 행동 단어가 미세하게 바뀌었는지
– 비디오 일부 구간과 문장 일부가 서로 정확히 대응하는지
– 긴 멀티이벤트 비디오 전체가 하나의 coherent한 서사로 맞는지
즉 이 논문은 비디오-텍스트 정렬을 단순한 의미 유사도 문제가 아니라, 사건 순서와 부분 구간 대응까지 포함한 compositional alignment 문제로 보고 있습니다.
물론 video에서의 compositionality를 다룬 연구가 아예 없던 것은 아닙니다. 기존 benchmark들인 PerceptionTest, VITATECS, ViLMA, ICSVR 등도 video compositionality를 보긴 했지만, 저자들은 이들이 주로 isolated single-event scenario에 가깝다고 합니다. 즉 짧은 클립에서 특정 개념이나 temporal concept를 보는 데는 좋지만, 긴 멀티이벤트 서사 전체의 coherence를 보기는 부족하다는 것이죠
그래서 본 논문에서는 ActivityNet-Captions와 YouCook2 같은 dense captioning 데이터셋을 바탕으로, 멀티이벤트 비디오에 대한 compositional benchmark를 새로 만들고, 이를 잘 학습시키는 loss와 pretraining 방법까지 제안하였습니다. 본격적으로 리뷰 시작해보겠습니다.
2. Benchmark: VideoComp
먼저 멀티이벤트 비디오의 compositionality를 평가할 수 있는 benchmark를 구축하는 것 방법을 설명드리겠습니다.
우선 저자들은 기존에 존재하는 데이터셋을 재 구성하였는데요. 이를 위해 ActivityNet-Captions와 YouCook2처럼 하나의 비디오 안에 여러 이벤트 캡션이 시간 구간별로 주어진 dense captioning 데이터셋을 사용하였습니다.
2.1 Positive pair 생성
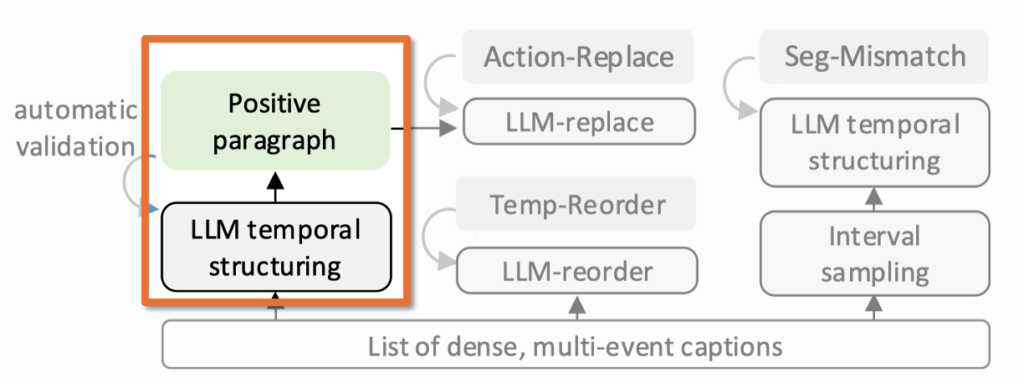
우선 positive pair 만드는 방식입니다. 각 비디오 안에는 여러 이벤트 캡션이 시간 구간별로 붙어 있는데, 이를 start time 기준으로 정렬해서 하나의 긴 paragraph로 합칩니다.
여기서 ActivityNet-Captions에는 여러 이벤트를 두루 설명하는 global caption도 있어서, 너무 넓게 커버하는 캡션은 걸러냈다고 합니다. temporal overlap이 큰 경우는 temporal IoU를 계산해서 더 긴 구간을 커버하는 쪽을 남겼습니다.
YouCook2는 원래 overlap도 적어서 별도 필터링이 거의 필요 없었다고 합니다. 이후 남은 캡션들을 합쳐 하나의 coherent paragraph를 만들고, LLM을 써서 then, meanwhile 같은 temporal cue를 조금 넣어 읽기 좋게 다듬었습니다. 중요한 점은 새 정보를 넣지 않고 연결 표현만 보완한다는 것이죠
따라서 정리하면, VideoComp에서의 positive는 단순한 캡션 나열이 아니라, 시간 흐름이 살아 있는 긴 문단입니다.
2.2 Negative Sample
이 논문의 핵심은 negative가 매우 정교하다는 점입니다. 아래 Figure 1 에서 이걸 자세히 확인해보겠습니다.

원래 올바른 서술이 있고, 거기에 subtle disruption을 가해 negative를 만듭니다.
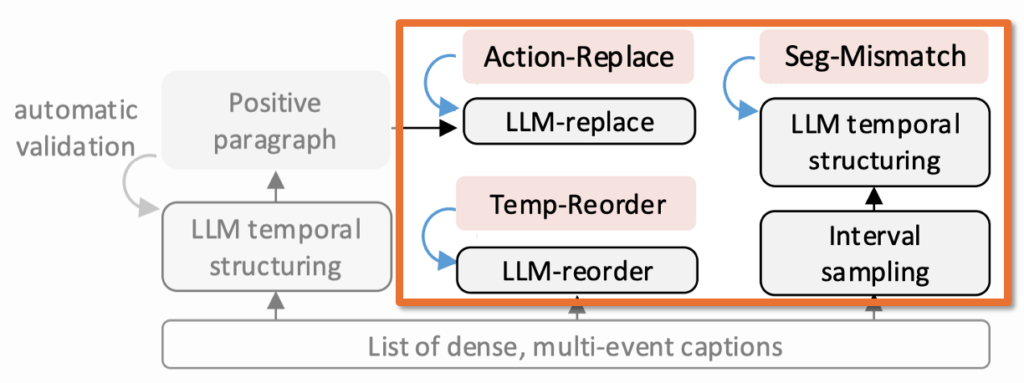
(1) Temp-Reorder (문장 순서 섞기)
예를 들어 원래는 ‘다이빙대에 서 있다 → 물로 뛰어든다 → 관중이 환호한다 → 축하를 받는다’ 인데, 이를 섞어서 시간 순서를 깨버립니다. 문장 자체 의미는 보존하지만, 사건의 서사가 틀려집니다.
(2) Action-Replace (핵심 동작 단어를 비슷하지만 다른 행동으로 바꾸기)
예를 들어 ‘dives’를 ‘waves to the crowd’처럼 바꿔서, 문장 전체는 그럴듯하지만 비디오와는 어긋나게 합니다. 즉, semantic fine-grained mismatch를 만드는 방식입니다.
(3) Seg-Mismatch (비디오 앞부분과 텍스트 뒷부분 붙이기)
캡션 시퀀스에서 부분 구간 둘을 샘플링하고, 각각에 맞게 비디오도 crop한 뒤, 서로 안 맞는 video-text 부분쌍을 일부러 연결하는 방식입니다. 이건 단순한 문장 순서 shuffle보다 더 어렵다고 하는데요. 왜냐하면 일부는 맞고 일부만 안 맞기 때문입니다.
(4) Multi-Disrupt(순서도 바꾸고, Action도 바꾸기)
학습 때는 여러 disruption을 동시에 섞은 더 어려운 negative도 씁니다. 평가는 주로 앞의 세 가지를 따로 본다고 합니다.
2.3 생성 데이터 검증
다만 여기서 LLM을 써서 negative를 만드는게 괜찮은건가? 하는 의문이 들 것 같은데요. 저자들도 이 문제를 의식해서 automatic validation을 넣었다고 합니다.
LLM이 원본 의미를 너무 많이 바꾸면 안 되니까, 원문과 생성문 사이의 word-level precision / recall을 계산하고, 둘 중 하나라도 80% 아래로 떨어지면 버리는 방식이죠. 다시말해, negative가 ‘원문과 너무 다른 엉뚱한 문장’이 되지 않도록 통제하는 추가 장치를 넣은 거죠.
다만 한계도 있긴 합니다. word overlap 80%가 된다고 해서 무조건 의미가 보존된다는 얘기가 아니기 때문이죠. 겉보기에 단어는 많이 겹치는데도 의미가 크게 변할 수 있다는게 그 이유이고, 그 한계에 대해서는 이따 뒷부분에서 더 다뤄보도록 하겠습니다.
2.4 VideoComp 규묘
그렇게 compositionality를 고려한 데이터셋 재가공에 대한 설명을 완료했습니다. 데이터셋 규모는 아래와 같습니다.
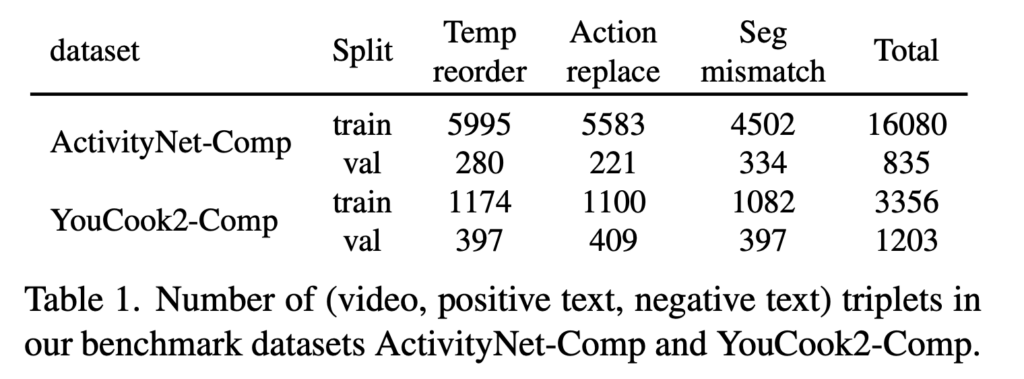
ActivityNet-Comp
train 약 16,080 triplets, val 835
YouCook2-Comp
train 약 3,356 triplets, val 1,203
ActivityNet-Comp가 더 크고, YouCook2-Comp는 상대적으로 작네용
3. Training
3.1. Compositionality-aware Learning Objective (CompLoss)
이제 앞서 설계한 benchmark에서 잘 동작하도록, compositionality를 고려한 학습 objective를 설명드리겠습니다. 우선 논문에서 사용한 backbone은 dual-encoder CLIP 구조입니다. 즉 비디오와 텍스트를 각각 독립적으로 인코딩한 뒤 similarity를 계산하는 방식입니다. 여기에 기본적인 InfoNCE contrastive loss를 사용하고, 추가로 hierarchical pairwise preference loss를 더한 것이 저자들이 제안하는 CompLoss입니다.
아이디어는 비교적 단순합니다. 모델이 similarity를
positive > 덜 교란된 negative > 더 심하게 교란된 negative
순으로 매기도록 학습하자는 것입니다.
즉 정답 문단이 가장 높은 similarity를 가져야 하고, 단순한 temporal reordering은 그보다 낮아야 하며, reordering과 action replacement가 함께 들어간 더 강한 negative는 더 낮은 similarity를 가져야 한다는 것입니다. 이를 위해 논문에서는 두 가지를 함께 강제합니다. 첫째, 모든 negative는 positive보다 similarity가 낮아야 합니다. 둘째, 더 심한 negative는 덜 심한 negative보다 similarity가 더 낮아야 합니다.
(이 아이디어는 가장 대표적인 Compositionality 페이퍼인 [ICLR 2023] NegCLIP에서 가져온 것 같습니다)
이러한 설계가 필요한 이유는 VideoComp에서 만든 negative들이 전부 완전히 엉뚱한 오답이 아니라, 전체적으로는 그럴듯해 보이는 hard negative이기 때문입니다. 순서만 조금 틀린 경우, 행동 하나만 바뀐 경우, 부분 구간만 어긋난 경우처럼 negative의 종류와 강도가 다르기 때문에, 이들을 모두 동일한 오답으로 묶어 학습하는 것보다 교란 정도를 구분해서 학습하는 편이 더 compositional한 정렬을 유도할 수 있습니다. 즉 CompLoss의 핵심은 단순히 맞다/틀리다를 구분하는 것이 아니라, 얼마나 정합적인가를 similarity 공간 안에 계층적으로 반영하도록 만든 것이라고 볼 수 있습니다.
3.2. Pretraining with Short-form Video-text Data (CompPretrain)
그 다음으로 pretraining 방식을 설명드리겠습니다. 여러 이벤트가 시간 순서에 따라 자세히 주어진 dense caption 비디오는 양이 많지 않기 때문에, 이런 데이터만으로 compositionality를 충분히 학습하기는 어렵습니다. 이를 해결하기 위해 저자들은 VideoCC3M과 같은 short-form video-text 데이터를 활용하여, 여러 개의 짧은 비디오-텍스트 쌍을 하나로 이어 붙이는 CompPretrain 전략을 제안하였습니다.

정말 Figure 3처럼, 여러 짧은 비디오-캡션 쌍을 이어 붙여 pseudo long-form sequence를 만든 뒤 이를 긴 멀티이벤트 시퀀스처럼 다루는 방식입니다. 예를 들어 (V1, T1), (V2, T2), (V3, T3)를 이어서 하나의 stacked sequence로 구성하고, 여기에 순서 뒤섞기나 partial caption removal과 같은 disruption을 적용합니다. 이후 원래의 positive paragraph와 교란된 paragraph 사이에서 앞서 설명한 preference loss를 계산함으로써, 모델이 긴 사건 흐름 속 compositional structure를 미리 학습하도록 합니다.
즉 CompPretrain은 실제로 긴 멀티이벤트 비디오가 충분하지 않은 상황에서, 짧은 데이터들을 조합해 비슷한 학습 환경을 인위적으로 만들어 주는 기법이라고 볼 수 있겠네요
4. Experiment
4.1 Evaluation Metric & implementation
Retrieval Accuracy
먼저 retrieval입니다. 기존 video-text retrieval처럼 Recall@1을 평가합니다.
여기서는 positive pair만 사용하였다고 하는데, 다시말해 모델이 일반적인 video-text alignment를 얼마나 잘하느냐를 측정합니다.
Binary Classification Accuracy
이게 이 논문의 메인 평가인데, 입력으로 (video, positive text, negative text) triplet를 주고, 모델이 positive에 더 높은 similarity를 주면 정답으로 처리하는 방식이고, disruption 종류별로 따로 점수를 내는 방식입니다.
- temp-reorder
- action-replace
- seg-mismatch
를 따로 보고, 마지막에는 All (comprehensive) 점수도 계산합니다.
그리고 baseline으로는 VidCLIP-base를 사용합니다. image CLIP을 출발점으로, 비디오에 맞게 temporal positional encoding과 attention pooling을 추가한 것이라고 하네요. 텍스트 길이도 원래 64에서 160으로 늘려 긴 설명을 다룰 수 있게 합니다. 프레임은 16개를 사용합니다.
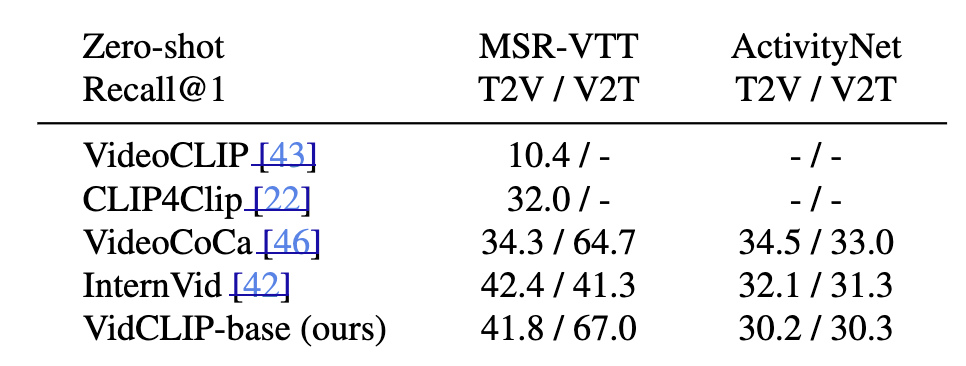
저자가 사용한 베이스라인의 zero-shot 성능을 보면, 제법 나쁘진 않습니다. MSR-VTT에서 T2V 41.8, V2T 67.0이고, ActivityNet에서는 30.2 / 30.3으로, 최근 dual-encoder들과 경쟁력 있는 baseline이라고 하네요
4.2 Main Results
compositional benchmark 성능을 먼저 보겠습니다.
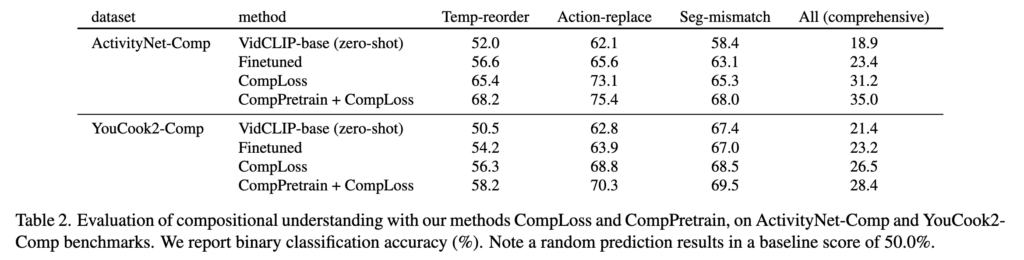
Table2를 보면 저자가 제안하는 VidCLIP-base는 그냥 fine-tuning만 해도 올라가지만, CompLoss에서 크게 뛰고, CompPretrain을 추가하면 한 번 더 성능이 오르는 것을 알 수 있습니다.
특히 중요한 건 All score인데, 모든 데이터셋에서 점차적으로 성능이 오르는 것을 볼 수 있습닏아. 그 결과 All에서의 성능 향상은 단순히 한 태스크만 좋아진 게 아니라, 전체 disruption robustness가 같이 오른다는 뜻이라서 의미있는 결과라고 할 수 있습니다.
다음으로 Retrieval 성능입니다. 이 부분이 제법 중요한데, 보통 기존 연구들에서 compositional training을 세게 하면 retrieval이 나빠진다는 경향이 있었기 때문입니다.
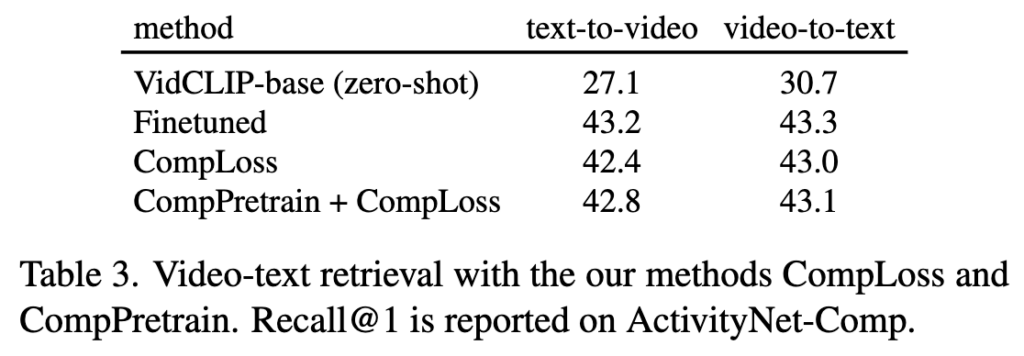
Table 3를 보면 ActivityNet-Comp에서의 Recall@1 을 볼 수 있는데, standard finetuning이 retrieval 점수는 가장 약간 높지만, CompLoss/CompPretrain을 써도 큰 하락은 없었습니다. 이를 통해 저자들은 compositional robustness를 높이면서 일반 retrieval 성능은 거의 유지했다고 주장합니다.
4.3 Ablation Study
다음으로 CompLoss 성능을 살펴보겠습니다.
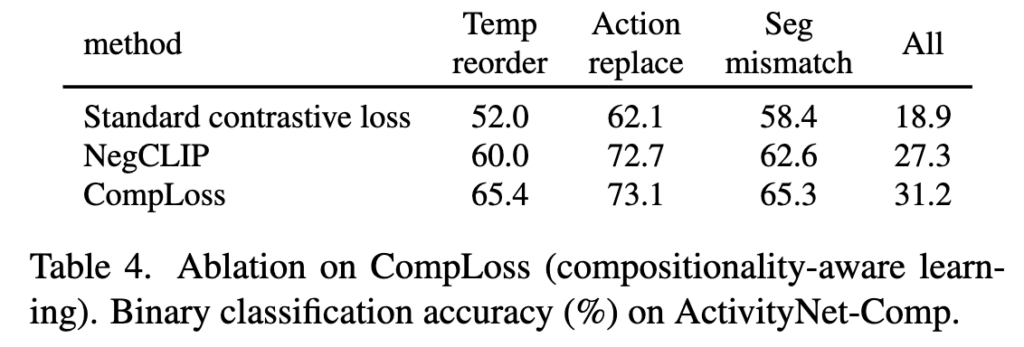
Table 4에서 standard contrastive loss, NegCLIP, CompLoss를 비교한 결과입니다. 재밌는 점은 NegCLIP보다도 CompLoss가 낫다는 것입니다. 다시 말해 ‘negative를 더 넣는 것’만으로는 부족하고, negative 사이의 hierarchy를 반영하는 설계가 도움이 된다는 해석이 가능하나고 주장하네요.
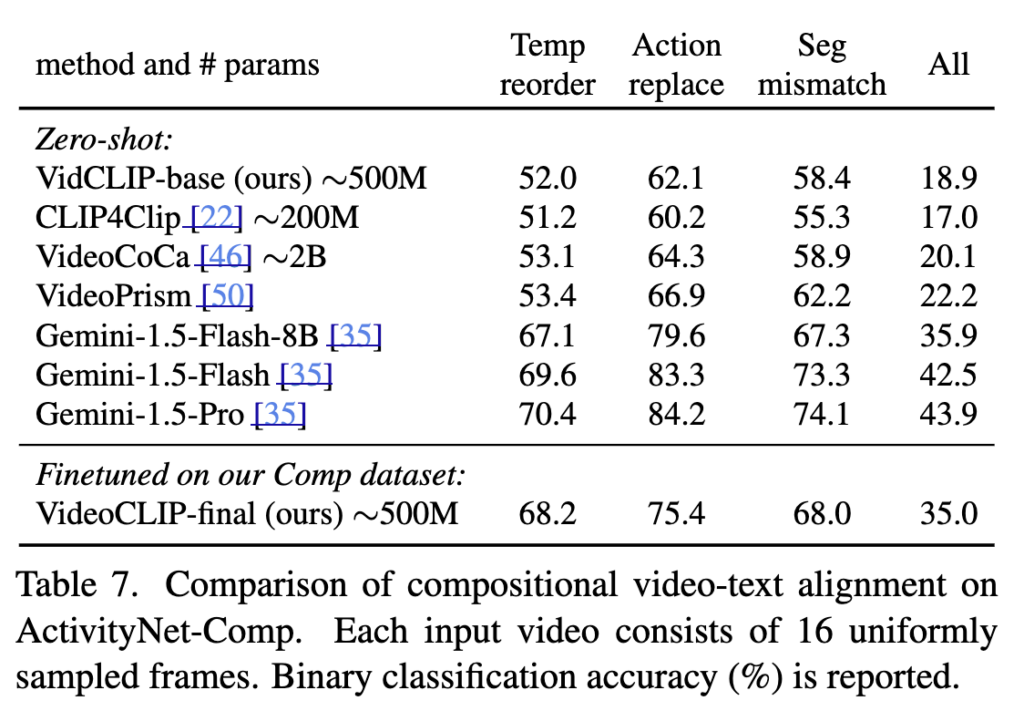
다음으로 LMM과 비교한 결과를 Table 7에서 확인하 수 있는데요. ActivityNet-Comp 데이터셋 기준, 저자들의 finetuned VidCLIP-final은 all 35.0 로 다른 zero-shot LMM Gemini보다는 조금 떨어지긴 하네요
저자는 이 결과를 통해 두 가지를 알 수 있었다고 합니다.
첫째, 이 benchmark가 꽤 어렵다는 점이죠. 강한 LMM도 60~80대 disruption accuracy는 나오지만, 다소 엄격한 all-comprehensive는 40대 초반 수준에 불과합니다. 다시 말해 아직 완전히 해결된 문제가 아니라는 것이죠
둘째, LMM은 특히 action replacement에 강했습니다. Gemini-1.5-Pro는 action 84.2로 매우 높은 반면 저자들의 VidCLIP-final은 75.4입니다. 그러나ㅅ temporal reordering이나 segment mismatch처럼 시간 민감한 영역에서는 저자 방법도 꽤 경쟁력이 있었다고 합니다. 특히 8B 모델보다 robust하다고 논문에서는 말하네요.
따라서 대형 생성형 멀티모달 모델은 semantic knowledge가 강하고, 저자 방법은 compositional training 덕분에 temporal robustness를 더 도움이 되는 구조라고 정리할 수 있겠네요
Visualization

마지막으로 baseline과 final 모델의 confidence 비교를 보여드리겠습니다. positive A와 여러 negative(B,C,D,E)를 비교할 때, VidCLIP-final이 대체로 더 높은 confidence로 positive를 고른것을 알 수 있었습니다. 예를 들어 temp-reorder에 대해 0.46 → 0.73으로 크게 좋아졌네요. 즉, 정성적으로도 compositional robustness가 개선되었음을 확인할 수 있습니다
5. Conclusion
제가 열심히 리뷰했지만, 이 논문이 전달하고자 하는 핵심 메시지는 결국 다음과 같이 정리할 수 있을 것 같습니다. Video-text alignment는 단순한 global semantic matching만으로는 부족하고, multi-event sequence에서 temporal/compositional coherence를 별도로 다루어야 한다. 실제로 이 논문은 앞 사건과 뒤 사건의 순서, 부분 구간과 부분 문장의 대응 관계, 그리고 긴 문맥 속 multi-event coherence까지 평가 대상으로 끌어왔다는 점에서 의미가 있어 보였습니다.
막연하게 비디오에서도 compositionality를 더 정교하게 다루는 연구가 필요하다고 생각하고 있었는데, 역시 관련된 시도가 이미 존재했네요. 특히 이전 compositional benchmark들이 비교적 짧고 단발적인 이벤트 중심이었다면, 이 논문은 실제 비디오처럼 여러 사건이 연속적으로 이어지는 서사를 다루었다는 점에서 나름 의미 있는 방향이라고 느껴졌습니다.
다만 읽으면서 조금 아쉬운 점도 있었습니다. 먼저 negative sample이 전반적으로 텍스트 중심의 hard negative에 가깝다는 점입니다. 물론 segment mismatch는 video crop까지 함께 들어가지만, temp-reorder나 action-replace는 결국 텍스트를 변형하는 방식이기 때문에, 모델이 정말 비디오 자체의 복잡한 시간적 reasoning을 학습한 것인지, 아니면 텍스트 coherence를 잘 감지한 것인지가 다소 섞여 있을 수 있어 보였습니다.
또 하나는 LLM이 생성한 hard negative를 검증하는 automatic validation 방식입니다. 논문에서는 word overlap 기반의 precision, recall 기준으로 필터링하는데, 구현이 간단하고 명확하다는 장점은 있지만, semantic fidelity를 충분히 보장하는 방식으로 보기에는 조금 단순하다는 생각이 들었습니다. 즉 lexical overlap은 확인할 수 있어도, 의미 수준에서 정말 적절한 negative인지까지는 충분히 검증하지 못할 수 있겠다는 아쉬움이 남았습니다.
그럼 리뷰는 여기서 마치도록 하겠습니다.