안녕하세요 이번에 들고온 논문은 VLM 에서의 Token pruning 논문입니다.
다음연구로 VLM 에서의 visual token을 어떻게 잘 pruning 하거나 기존 방법론들을 분석해서 왜 잘되거나 잘 안되는지를 분석하고자 읽은 논문입니다. 아직 구체적인 방법론을 떠올리거나 하진 않고 데이터셋들 원복만 진행한 상황이라 크게 진척은 없네요 하하..
그럼 리뷰 시작하겠습니다.
Abstract
대형 Vision-Language Models (LVLMs) 는 일반적으로 텍스트 토큰보다 훨씬 많은 수의 시각 토큰을 포함하고 있으며, 이로 인해 상당한 계산 비용이 발생합니다.
다들 알고 있는 해당 문제점을 해결하기 위해서 최근 연구들이 언어 모델 내부에서 시각 토큰을 조기에 제거하는 방법을 제안해왔었습니다. (LLM 모델 내부의 decoder 단에서의 pruning). 기존 대부분의 방법들은 텍스트 토큰과 시각 토큰 간의 attention score를 활용하여, 어떤 시각 토큰이 중요한지를 판단합니다. 하지만 해당 연구에서는 먼저 언어 모델 내부의 visual-text attention을 분석하고, 이 값이 토큰 pruning을 위한 이상적인 지표가 아님을 밝혀냅니다.
이를 바탕으로 저자들은 VisPruner라는 새로운 토큰 pruning 방법을 제안합니다. 이 방법은 단순히 Decoder 단에서의 visual text attention이 아닌 CLIP 의 ViT에서의 시각적 정보 자체를 활용하여 토큰을 선택하는 방법입니다. ( 생각보다 방법론은 엄청 단순합니다. )
구체적으로 먼저 CLS와의 attention이 높은 visual patch들을 선택하고 이후 남은 토큰들 중에서 서로 유사한 토큰들은 제거하여 중복 정보를 줄입니다. 이를 통해 중요한 토큰은 유지하면서도, 서로 다른 정보를 담고 있는 토큰들을 최대한 보존하는 방식으로 전체 시각 정보를 유지합니다.

해당 figure는 기존 LLaVA의 의 응답 및, 24 년도 방법론인 FastV 와 Random, 그리고 저자의 방법론이 보는 Visual patch의 예시입니다. 언뜻봐도 FastV라는 방법론이 보는 visual patch 가 좀 이상하다는 생각이 들텐데 그 이유는 이후 Intro에서 설명하겠습니다.
Introduction
최근 대형 언어모델의 발전과 함께 이를 멀티모달로 확장한 VLM 에 대한 연구가 활발히 진행되고 있습니다. 이러한 VLM은 일반적으로 이미지 입력을 처리하는 visual encoder와 텍스트를 처리하는 language model 그리고 두 모달리티를 연결하는 alignment 모듈로 구성됩니다.
이러한 구조는 다양한 멀티모달 태스크에서 좋은 성능을 보이지만 위에서 언급했던 visual token의 개수가 텍스트 토큰에 비해서 훨씬 많다는 문제가 있습니다. 예를 들면 LLaVA-1.5 의 경우에는 ViT를 사용하여 576개의 visual token을 만들기 때문에 텍스트가 일반적으로 100토큰 이하로 구성되는 것을 감안하면 해상도가 더 높아지거나 비디오 입력이 들어오는 경우에는 이보다 훨씬 더 큰 용량을 차지하게 됩니다.
이러한 계산비용 문제를 해결하기 위해서 최근 LLM 모델들은 내부에서 Visual token을 초기에 제거하는 token pruning 방식을 채택했었습니다. 대표적으로 FastV는 language model 의 중간 layer에서 text token이 visual token에 주는 attention 값을 기준으로 중요도를 판단하고, attention 이 낮은 visual token 을 제거하는 방식으로 이해하면 됩니다. 이후 많은 연구들이 이와 유사하게 text-visual attention을 기반으로 token purning을 수행했다고 합니다.
하지만 본 논문에서는 이러한 text-visual attention이 실제로 token pruning을 하기에 적합한 기준이 아니라는 점을 지적합니다. Figure 1에서 보여준 FastV가 선택한 token들만 보더라도 text-visual attention 기반 방법은 이미지의 특정 위치에 편향된 토큰을 선택하는 경향이 있고, 이로 인해 중요한 시각 정보가 제거되는 문제가 발생한다고 합니다. (이후에 이 이유에 대해 attention shift 파트에서 다루겠습니다.)
이러한 특성들은 모든 visual token을 사용할 때는 큰 문제가 되지 않지만, pruning 기준으로 사용될 경우 성능 저하를 유발하게 됩니다. (저자의 주장이지만 제가 분석하기로는 LLM 이 토큰을 이해하는 방식이 attention score가 높은 곳을 위주로 이해한다기 보다 전체적인 문맥을 얼마나 훑어볼지를 보고 다음 토큰을 예측해서 이렇게 주장한 것 같습니다. 다만 실제로 attention shift 문제가 llm decoder에 안좋은 영향을 주고 있을지는 training free 방식으로는 분석하기 쉽지 않을 것 같습니다.)
이러한 분석을 바탕으로 저자들은 VisPruner라는 새로운 token pruning 방법론을 제안합니다. 이 방법은 기존처럼 text-visual attention을 사용하는 것이 아니라 visual encoder에서 얻은 정보를 기반으로 중요한 토큰을 먼저 선택하고, 이후 남은 토큰들 중에서 서로 유사한 토큰을 제거하여 중복을 줄이는 방식입니다. 이를 통해 중요한 정보와 다양한 정보를 동시에 유지하면서 token 수를 줄일 수 있습니다.
또한 VisPruner는 language model 내부가 아니라 입력 단계에서 pruning을 수행하기 때문에, 다양한 VLM 구조에 쉽게 적용할 수 있으며 기존의 attention 최적화 기법과도 호환된다고 합니다.
Text-visual Attention investigation
기존 token pruning 방식들이 사용하는 text-visual attention이 실제로 좋은 기준이 맞는지를 분석하고 기존의 attention 방식이 실제로 중요한 visual token 정보를 반영하지 않을 수 있다는 점을 지적하고, 이를 분석을 통해 두 가지 현상으로 설명합니다.
Text-Visual Attention Shift
첫 번째로, Text-visual attention 에는 위치에 따른 편향이 존재합니다.
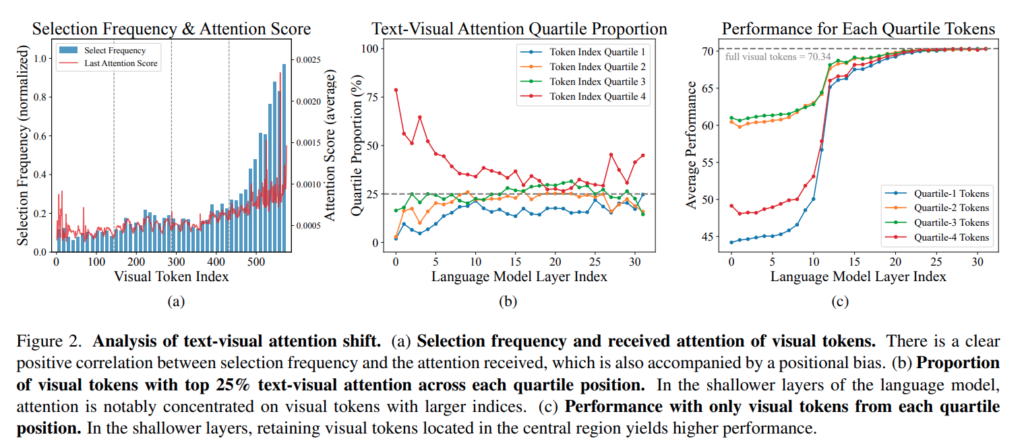
Figure 2를 보면 attention이 높은 visual token들이 특정 위치에 몰리는 경향이 나타납니다. 특히 language model의 입력 구조에서 텍스트 토큰이 이미지 토큰 뒤에 위치하기 때문에 텍스트 토큰은 상대적으로 가까운 위치에 있는 visual token에 더 높은 attention을 주게 됩니다.
이러한 현상은 Rotary Positional Embedding (RoPE) 에 의해 발생하며 결과적으로 이미지의 특정 영역, 특히 뒤쪽에 위치한 토큰들이 과도하게 강조됩니다. (이로 인해 위에 보았던 FastV의 아래쪽 visual token들이 많이 살아남게 되는 것입니다.) 이는 (b)의 결과를 보면 알 수 있습니다.
하지만 실제로 중요한 정보들은 이러한 위치와 반드시 일치하지 않습니다. Figure 2(C) 의 실험에서는 위치별로 토큰을 나누어 성능을 비교했을 때, 중앙 영역의 토큰이 더 높은 성능을 보이는 것으로 나타납니다. 즉 attention이 높은 토큰이 반드시 중요한 정보를 담고 있는 것은 아니며, 이러한 위치 편향은 pruning 시 성능 저하를 유발할 수 있습니다.
Text-Visual Attention Dispersion
두 번째로, attention 분포 자체가 중요도를 구분하기 어려운 형태를 보입니다.
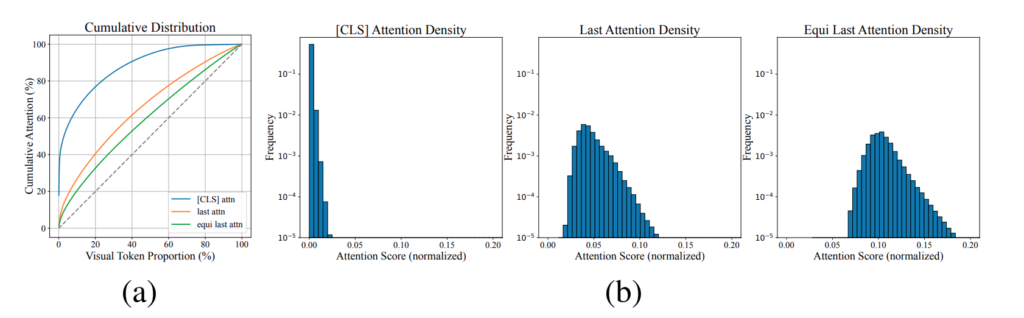
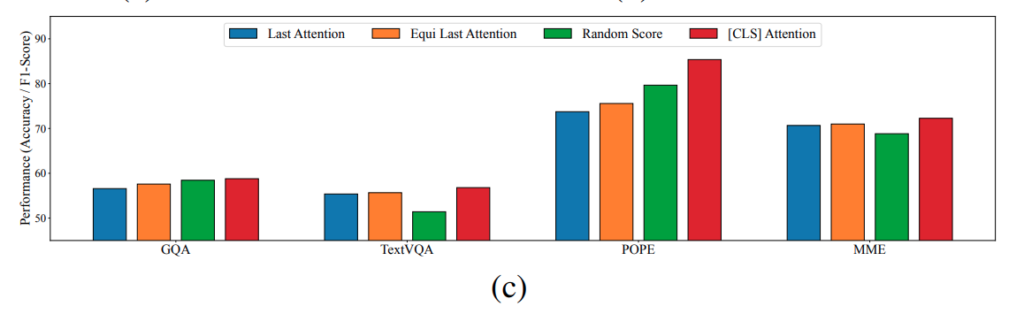
Figure 3에서 확인할 수 있듯이, text-visual attention은 특정 토큰에 집중되지 않고 전체 토큰에 걸쳐 비교적으로 고르게 분포하는 경향을 가집니다. 이는 attention 값이 높은 일부 토큰에 집중하는 것이 아니라, 여러 토큰에 분산되어 나타난다는 의미이며, 이러한 분포는 실제로 중요한 토큰을 선택하기 어렵게 만듭니다.
Figure 3 (a)를 보면 [CLS] attention은 일부 토큰에 집중되어 있는 반면 (저자 방법론), text-visual attention은 훨씬 넓게 퍼져있습니다. 그리고 해당 문제를 attention bias 를 없애면 되지 않나? 라고 생각하여 저자들이 equi last attention을 정의합니다. 이건 모든 Visual token에 동일한 positional embedding을 적용한 attention으로 앞서 언급한 positional bias를 제거했다고 생각하면 됩니다.
저자들은 저렇게 positional bias 를 제거하더라도 attention 분포가 거의 uniform하게 퍼져있다는 것을 발견했고, 이러한 분포로는 attention score로써 중요한 토큰을 고르기 어렵다고 판단하여 Visual-Text attention 의 정보를 살리기 어렵다고 판단합니다.
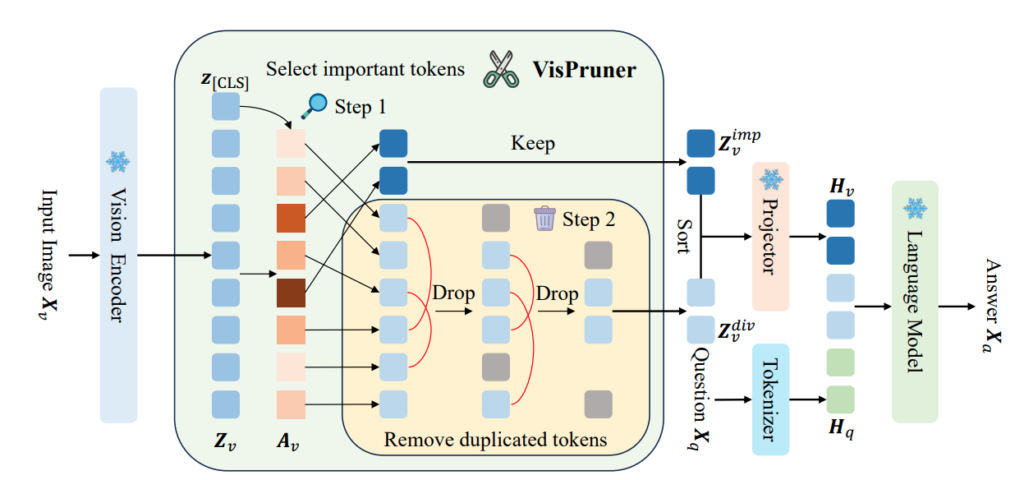
앞에서 attention 분석을 통해 text-visual attention이 pruing 기준으로 적절하지 않다는 것을 확인했기 때문에 저자는 visual 정보를 직접 활용하는 pruning 방식인 VisPruner를 제안합니다.
전체 구조는 크게 두 가지로 나뉩니다.
- 먼저 VIsual encoder의 attentiono을 이용해서 중요한 토큰을 일부 선택
- 이후 남은 토큰들 중에서 서로 유사한 토큰들을 제거하여 다양한 토큰을 추가로 유지합니다.
이 두 가지를 사용해서 token을 많이 줄이면서도 성능을 유지하는 구조입니다.
Attention-based Important Tokens
이미지 자체는 중복 정보가 많기 때문에 attention을 이용해서 중요한 token을 고르는 접근 자체는 맞는 방향입니다.
다만 문제는 language model 내부 attention은 shfit/dispersion 문제가 있어서 사용하지 못하고 저자처럼 visual encoder의 attention을 사용하게 됩니다.
중요 토큰을 고르는 방식은 매우 간단한데, [CLS] token이 가지고 있는 patch들을 바라보는 attention matrix를 활용하여 선택하게 되고, SigLIP 처럼 CLS가 없는 경우에는 모든 token 이 서로 주는 attention을 평균내어 CLS 토큰처럼 활용한다고 합니다.
Similarity-based Diverse Tokens
여기서 끝내면 문제가 하나 생긴다고 합니다. visual encoder attention 은 보통 foreground에 집중되므로 객체 중심의 토큰이 남고 배경 정보는 날아갈 가능성이 큽니다. 그래서 저자들은 두 번째 단계를 추가하여 diverse token들을 추가로 남깁니다.
방법은 매우 간단한데, 남은 토큰들 중에서 token 들끼리의 cosine similarity를 계산하고 서로 가장 비슷한 토큰부터 제거합니다. 즉 중복되는 정보는 제거하고 서로 다른 정보를 가진 토큰을 남기는 방식입니다.
이 과정을 반복해서 최종적으로 나머지 토큰들을 얻게 됩니다.
Inference with Visual Pruning
위에서 얻은 중요한 토큰 및 다양한 토큰을 활용하여 원래 patch 순서대로 다시 정렬한 뒤 multimodal project를 통과시켜서 language model 에 넣게됩니다.
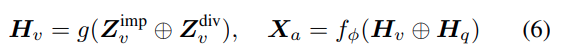
Experiments
먼저 실험은 이미지기반 데이터셋 10개와 video QA 기반 데이터셋 4개를 사용합니다. 이미지쪽은 LLava에서도 자주 사용하는 VQAv2, GQA, VizWiz, SQA 등등을 사용하고 video쪽은 TGIF-QA, MSVD-QA, MSRVTT-QA 등을 사용합니다.
모델은 LLaVA-1.5 와 LLaVA-NeXT(고해상도) 및 Video-LLaVA와 Qwen-VL, InternVL, 같은 다양한 구조에서 적용합니다.
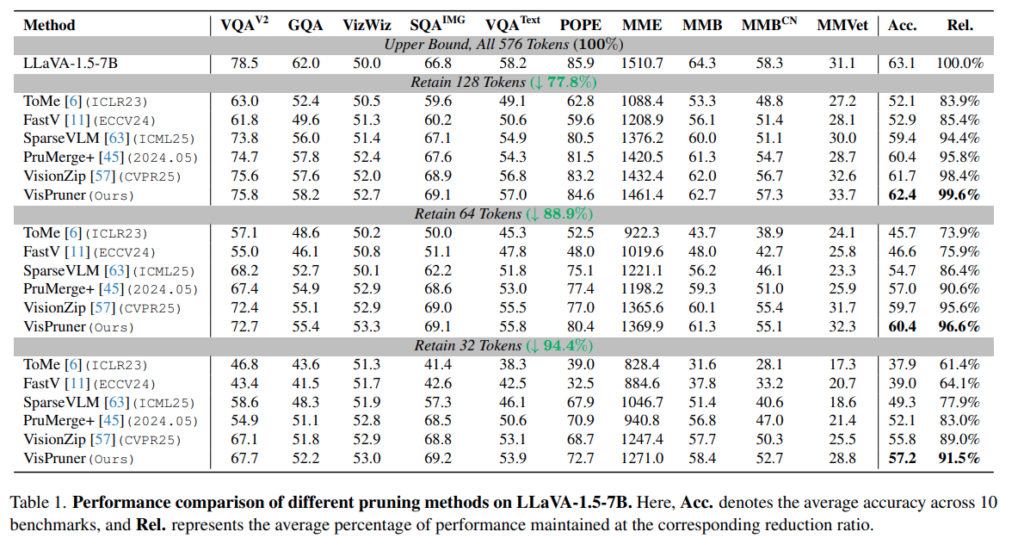
가장 기본 결과는 LLaVA-1.5 기준입니다. 다른 논문들은 보통 256개의 token 결과부터 보여주는데 해당 방법은 128, 64, 32로 94퍼센트까지 극단적으로 token을 줄인 모습을 보여줍니다. (VizionZIp이나 PruMerge와 같은 방법론들은 256,128,64 개를 리포팅했습니다.)
64개까지 줄이더라도 성능감소가 3.4퍼센트정도 생기며 94퍼센트의 극단적인 token pruning에도 91.5%성능을 유지함을 보입니다.
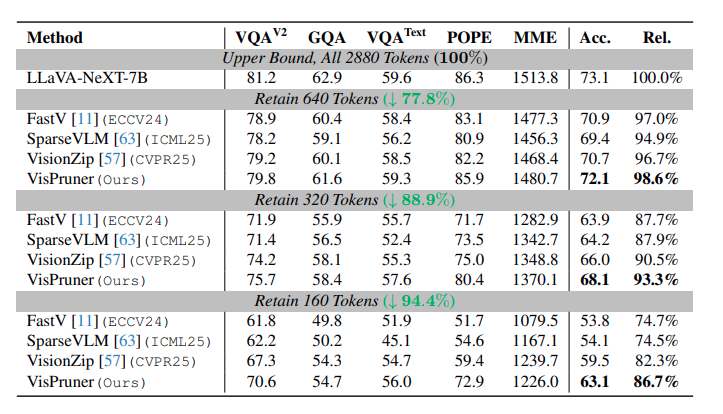
가장 기본 결과는 LLaVA-1.5 기준입니다. 다른 논문들은 보통 256개의 token 결과부터 보여주는데 해당 방법은 128, 64, 32로 94퍼센트까지 극단적으로 token을 줄인 모습을 보여줍니다. (VizionZIp이나 PruMerge와 같은 방법론들은 256,128,64 개를 리포팅했습니다.)
64개까지 줄이더라도 성능감소가 3.4퍼센트정도 생기며 94퍼센트의 극단적인 token pruning에도 91.5%성능을 유지함을 보입니다.
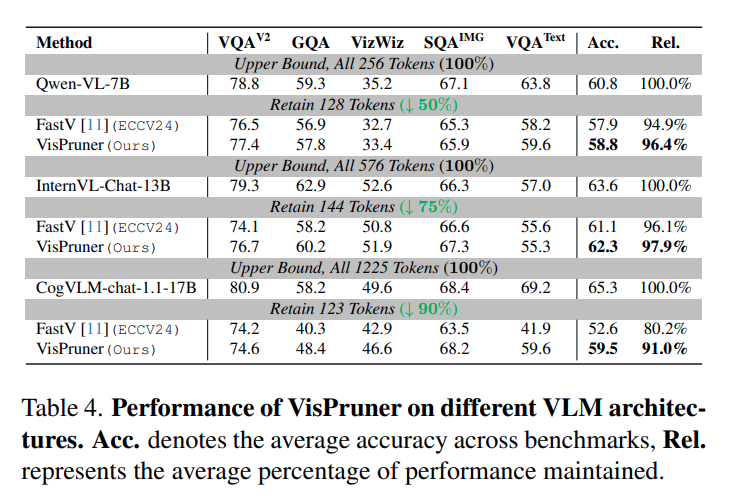
다양한 모델들, Qwen-VL 및 InternVL 등에서도 FastV에 비해 많이 개선된 성능을 보입니다. 현재 VisionZip 이나 다른 논문들을 읽어보진 않아서 해당 성능들이 리포팅 되어있는지는 모르겠지만 확인해봐야할 요소인 것 같습니다. (VisionZip도 저자의 방법론과 거의 유사한 CLS 기반의 attention score를 메인으로 사용합니다.)
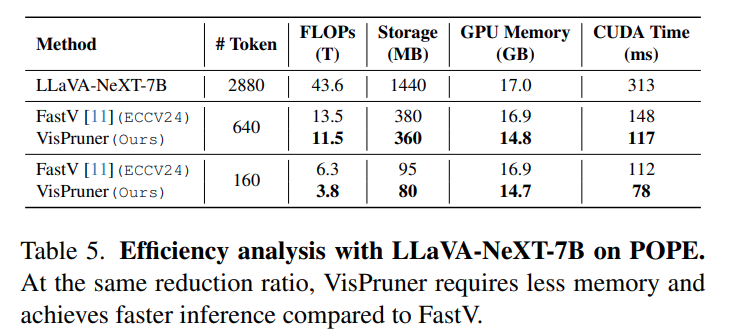
아무래도 Token Pruning이라면 efficiency를 보기 때문에 필수로 들어가는 FLOPs 및 memory, latency등의 Table입니다. 해당 지표도 FastV와의 비교에서 모두 앞섬을 확인할 수 있습니다.
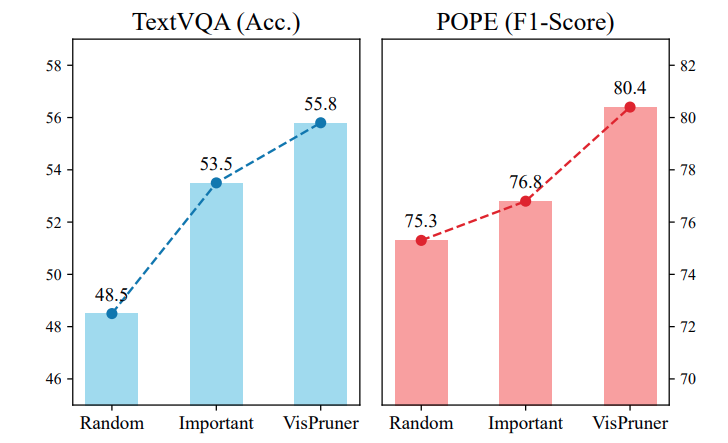
해당 실험은 위에서 언급한 important 토큰과 diverse 토큰중 순차적으로 더해가며 적용했을때의 성능 차이입니다. Important는 선택된 모든 토큰이 CLS 기반의 attention score 기준이며, VisPruner방식은 절반은 Important에서 나머지 절반은 Diverse 버전에서 골랐다고 생각하시면 됩니다. 아무래도 sparse한 주변 정보들도 최종 답변을 내는데 좋은 영향을 주는 것이 자연스럽고 또한 성능도 올랐기에 납득할 자료인 것 같습니다.
Conclusion
저자는 기존 방법론들이 가지는 문제점을 정량적으로나 이론적으로 잘 분석하여 LLM 단에서가 아닌 Text agnosticg 하게 ViT의 attention score만으로 pruning 하는 방법론을 제안합니다. 방법론이 매우 간단함에도 SOTA를 달성하기도 했고 분석이 깔끔해서 좋은 학회에 붙은 것 같습니다. 다만 해당 task 에서 사용하는 데이터셋들이 기본적으로 너무 쉬운 질문들이기도 하고 질문에 따라 봐야하는 영역이 달라지는 task나 영상에서의 복잡한 질문까지 해당 방법론을 이끌어 가기에는 무리가 있지 않을까 생각합니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 잘 읽었습니다.
설명해주신 방법이 유사한 토큰을 제거하는 과정이 기존 방법 대비 특징인 것으로 이해했습니다.
그러나 상단 Figure에서 FastV와의 비교 예시에서 제안된 vispruner의 경우 공간적으로는 유사해보이는 토큰이 FastV대비 더 많이 살아남았다고 생각합니다.
유사한 토큰을 제거하는 접근법이 잘못된(문장의 앞 뒤 부분, 전역적 정보) 영역과 맵핑되는 토큰을 마스킹하고 결과적으로 조금 더 특징적인 정보가 많이 살아남았다고 이해하면 될까요?
감사합니다.
안녕하세요 유진님 좋은답글 감사합니다.
우선 저자가 제안한 방식은 question을 참조하지 않습니다. 따라서 유사한 토큰을 제거할때는 문장기반이 아닌 ViT의 [CLS]토큰이 바라보는 patch weight들중에서 고르게 됩니다. Important 토큰들로 지정된 애들이 아닌, 즉 (전체 토큰 – important 토큰) 남겨진 token들중에서 배경적 정보를 살려주기 위해 retain 하는 과정을 거치는데, 배경은 겹치는 내용이 많을테니 중복제거를 한 후 살아남은 token들을 합쳐주는 방식으로 이해하면 될 것같습니다.
중요 token – [CLS] & [patch] 유사도 ⬆️
배경 token – (전체 token – 중요 token) 중복 정보 sim 기반 제거
감사합니다.
안녕하세요 인택님 리뷰 잘 읽었습니다~!!
한가지 궁금한 점이 있는데 문제로 언급해 주셨던 Attention Shift라는 이 위치 편향이 Rotary Positional Embedding (RoPE) 에 의해 발생한다고 하셨는데, 이게 단순히 포지셔널 인코딩으로 발생하는 좀 일반적인 위치편향 문제인건지 아니면 텍스트 토큰과 비주얼 토큰이 결합되면서 나타나는 현상인지 궁금합니다.
(동일한 구조에서 RoPE대신 뭐 다른 positional encoding을 사용할경우에도 유사한 shift현상이 나타나는지요!)
또한 혹시 비디오 쪽으로 본다면 frame level pruning과 token level pruning이 어떻게 상호작용 하는지도 궁금합니다!
안녕하세요 찬미님 좋은답글 감사합니다.
RoPE 에 의한 위치 편향은 일반적인 포지셔널 인코딩에 의해 생기는 것은 아니고, 후자로 언급해주신 텍스트 토큰과 비주얼 토큰이 결합되면서 나타나는 현상으로 이해해도 될 것 같습니다. 간단하게는 기존에는 절대적인 좌표값을 변화시켰다면 해당 RoPE는 회전행렬의 특성을 사용하게 되면서 상대적인 거리를 인지할 수 있게 변했는데, 토큰들의 상대적인 거리를 인지할 수 있다는 뜻은 이미지토큰의 마지막 부분들과 이어질 question 토큰들의 앞부분 (혹은 뒷부분일지라도) 과의 상대거리가 가까운 것을 인지한다는 것입니다. 더 구체적으로 분석한 논문을 읽어보지 않아 더 이야기하는 것은 제 단순 주장일 것 같아서 질문해주시면 답하겠습니다.
동일한 구조에서 RoPE대신 다른 positional encoding을 사용하면 그 인코딩 방식의 특성대로 다른 현상이 나타날 것입니다. 2D RoPE나 여러가지 변형들이 연구되어오긴 했지만 그 방식의 단점이 연구된지는 모르겠네요..
마지막으로 frame level pruning 과 token level pruning의 상호작용 부분은 pruning 전략에 따라 다를 것 같아 좀 더 구체적인 질문을 주시면 답변해드리겠습니다!
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
Fig2(b) 그래프에 질문이 있는데, 그림에 나와잇는 4개의 선들은 비주얼 토큰들을 4등분하고 이를 텍스트와 Attention score를 계산한 것을 보여주는 표인가요?
그렇다면 빨간색 선이 비주얼 토큰 중 뒤쪽에 있는 녀석들이고 이들이 텍스트 토큰과 더 가까워서 Attention score가 높게 나온다는 것을 보여주는 그림 같은데, 초기 레이어에서만 유독 점수가 더 높게 나는 이유가 무엇인지 궁금합니다.
감사합니다.
안녕하세요 의철님 좋은 답글 감사합니다.
이건 해당 논문에서 직접적으로 언급한다기보다 제가 이전에 발표했던 VLM 내부적으로 이미지들의 정보가 언제 text 정보와 섞이는지 layer 별로 분석한 논문으로 대답할 수 있을 것 같습니다.
해당 (c) 그림은 llm 모델의 어느시점에서 해당 4개중 1개의 Quartile 부분만 남기고 다 버릴지를 결정한건데, 아직 정보가 섞이기 이전인 초기 layer에서는 Quartile 하나만 넣어주면 당연히 성능이 낮고, 객체가 존재할 확률이 높은 2,3 Quartile 이 확률적으로 성능이 상대적으로 높게 나온 것입니다. 다만 위에 제가 언급한 논문에서 주장했듯이 VLM 내부적으로는 중간 layer에서 이미지 정보가 text 정보와 교환이 일어난다는 것을 증명하듯 해당 (c)에서도 중간 layer 이후로는 pruning을 진행하더라도 성능 drop이 적게 일어남을 확인할 수 있습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다!
VLM의 token pruning이라면 visual token에서 최대한 text와 관련있는 token을 뽑는게 맞지 않나? 하는 생각이 들었는데, text를 아예 사용하지 않고도 좋은 성능을 보였다는 점이 흥미롭네요. 다만 복잡한 질문에서는 성능이 떨어질 수밖에 없지 않나 싶습니다.
Text-visual attention shift에서 RoPE로 인해 뒤쪽에 위치한 토큰들이 강조된다고 하셨는데, 제가 잘 몰라서 이 부분이 잘 이해가 가지 않습니다. text와 visual 토큰 간에 어쩔 수 없이 발생하는 현상인가요? text 토큰을 사용하지 않는 방법 말고 해결할 수 있는 방법이 아예 없는 것인지 궁금합니다.
감사합니다.
안녕하세요 예은님 좋은 답글 감사합니다.
우선 첫번째 질문에 대한 생각은 저도 동의하는 부분입니다.
질문이 어려워지거나 비디오의 길이가 길어질수록 text agnostic한 방식의 성능은 한계가 있을거라 생각합니다.
다만 질문을 신경쓰는 시점이 LLM decoder 단이라면 multi turn 대화 방식에서는 불리한 점이 있어 장단점이 있습니다.
두번째 질문에 대한 답변으로는 위에 찬미님한테 답변했듯이 RoPE의 도입 효과로 상대거리를 인지할 수 있는Encoding 방식이라는 것인데, [System] [Image] [Text] 토큰 순서대로 token 이 들어가게 되면 Image 의 하단부 패치들이 상대적 거리가 Text 토큰들과 더 가깝기 때문에 attention 이 높아지는 경향성이 생긴다는 주장입니다. (RoPE의 방식은 embedding vector 자체의 절대값이 아닌 각도를 바꿔주는 방식이므로 상대거리가 멀수록 내적값이 작아집니다.) 다만 해당 논문의 appendix에 존재하는 layer 별 attention 분포결과중 [System] 토큰과[Image] 의 attention 분포, 그리고 [Image] 토큰과 [Text] 의 attention 분포가 비슷하게 나타나는데 다른 현상들과 맞물려 생기는 것으로 보이고 제가 더 분석한 점은 따로 없습니다. (완벽히 이해가 되지는 않네요..)
결과적으로 질문주신 Text 토큰을 사용하지 않는 방법 말고 해결할 수 있는 방법은 VLM 전용 Positional Encoding 방식을 만들거나 해야할 것 같습니다. 그리고 LLM decoder의 generator 토큰은 결과적으로 모든 token 들을 참조하여 다음 token 을 생성해내는 방식이라 attention shfit 문제를 꼭 해결해야하는 문제인지는 확답할 수 없을 것 같습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
Similarity-based Diverse Tokens 부분에서 간단한 의문이 하나 들었습니다.
attention이 높은 토크들은 주로 foreground니 살아남은 token중, cos sim을 통해 중복을 제거하는 과정으로 이해가 됐습니다. 그런데 그렇다면, 이미 attention기반에서 background는 거의 다 잘려나갔을 것이기에 배경정보를 왜 살리는 과정인지 궁금합니다.
감사합니다.
안녕하세요 정우님 좋은 답글 감사합니다.
우선 제가 글을 구체적으로 작성하지 않은 문제로 오해하신 것 같습니다만, foreground로 살아남은 token 중에서 cos sim 을 통해 중복을 제거하는 것이 아닌, foreground를 선택하고 남은 토큰들 중에서 retain 할 토큰들을 선별하는 작업입니다. 논문에서 사실 명백히 선언되어있는 것은 아니고 코드를 보고 확신을 가지게 되었습니다.
해당 방식이라면 background를 살리는 의도가 충분히 납득될거라 생각합니다!
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
비디오 쪽 결과를 보면서 든 의문인데 이미지에서는 CLS attention 기반 스코어 높은 토큰들이 중요하긴 하지만 비디오에서는 시간에 따라 변하는 단서가 더 중요할 수 있을 것 같은데 여기서 마다 독립적으로 중요한 토큰을 뽑는 방식이 실제 비디오 이해에서 필요한 연속된 움직임나 temporal 축에 대한 관계를 충분히 보존하는지 궁금합니다. 감사합니다.
안녕하세요 우현님 좋은 답글 감사합니다.
직접 뽑아본 것은 아니지만, CLS attention을 활용하더라도 충분히 temporal 축에 대한 관계를 보존할 수 있을 것 같긴 합니다. 이유는 CLS 토큰 자체가 전체 프레임의 semantic 한 정보를 압축하고 있기 때문에, 프레임이 바뀌더라도 비슷한 장면이라면 CLS 토큰 기반의 attention 이 높은 패치들이 비슷하게 살아남아 temporal 한 정보들이 유지될 것 같습니다.
실제로 video dataset에 대한 성능이 보존되는 것으로도 보존한다고 이해할 수 있습니다.
감사합니다.