안녕하세요, 오늘은 ICLR 2024 Spotlight 논문인 CLIPself를 리뷰해 보려고 합니다. object detection 논문인 만큼 아마 많은 분들이 흥미롭게 읽을 수 있는 논문이지 않으까 싶네요. CLIP이 이미지 분류 성능에서 탁월한 성능을 보이지만, Object Detection이나 Segmentation 같은 dense prediction에 적용할 경우 국소적인 영역을 잘 인식하지 못하는 문제점이 있었습니다. 저자들은 이를 region-text pairs로 새로 학습하는 대신 ‘스스로 학습하는’ CLIPself라는 학습 방법론을 제안합니다.
Introduction
기존 일반적인 객체 탐지(Object Detection), 분할(Segmentation) 등의 Dense prediction task는 학습 때 사용된 카테고리의 객체만 인식할 수 있었지만, 현실에 존재하는 시각적 개념들은 무한하기 때문에 학습 데이터셋에서 보지 못한 객체까지 찾아내는 Open vocabulary 객체 탐지/분할 task가 연구되었습니다. 기존 Open vocabulary 연구들은 CLIP의 엄청난 zero shot 이미지 분류 성능에 영감을 받았지만, CLIP을 OVOD에 적용하기 위해서는 ‘이미지 전체’를 보던 능력을 ‘국소 영역(local region)’을 보는 능력으로 변환될 수 있게 해야 했습니다.
저자들은 CLIP의 region-language align 능력을 평가하기 위해 두 가지 실험을 진행했습니다. 비교를 위해 CLIP vision encoder는 CNN / ViT backbone 버전을 사용합니다.
- Image Crop : 객체가 있는 region을 crop한 이미지로 분류 수행
- Dense Feature : 원본 이미지를 인코딩해서 얻은 피처맵에서 region representation 추출 후 분류(자세한 방법은 Method의 Image Crop vs. Dense Feature 참고)
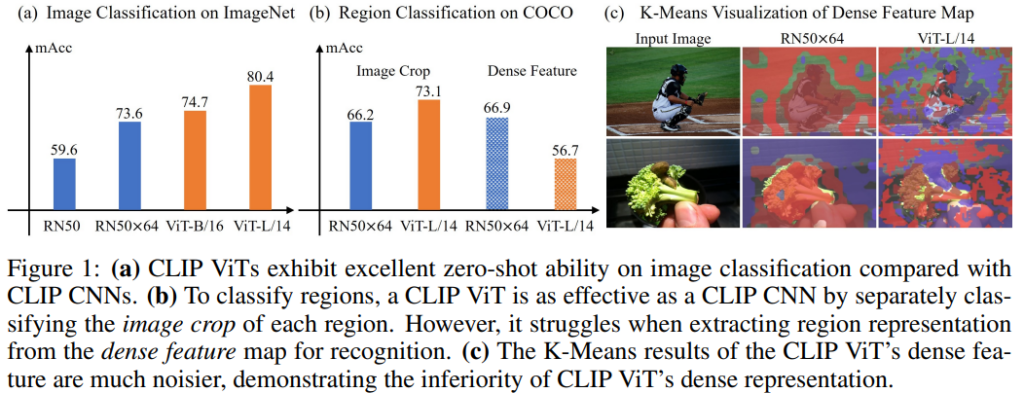
실험 결과, ViT 기반 CLIP은 CNN 기반보다 원본 이미지에 대한 분류 성능은 탁월하지만, dense feature를 가지고 localize까지 해내는 능력은 부족했습니다. (Fig 1. b) 쉽게 말하면, ViT 기반 CLIP은 feature를 보고 객체가 어디 있는지 찾고 분류까지 해내는 능력이 CLIP CNN보다도 떨어졌습니다. 저자들은 ViT가 이렇게 dense prediction에 더 약한 이유는 CNN과 달리 local inductive bias가 부족해서 피처맵의 각 지점이 global한 정보를 담으려고 하기 때문이라고 분석했습니다.
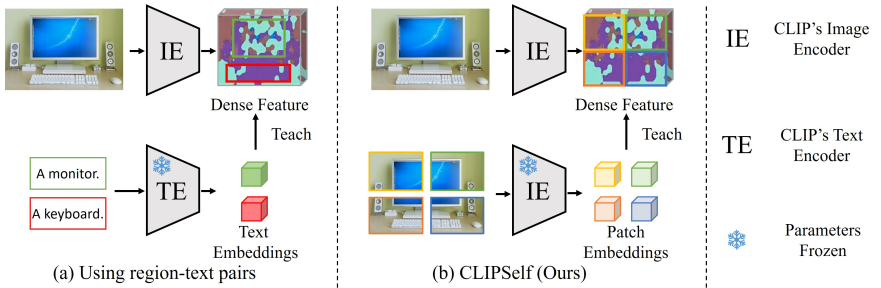
CLIP ViT를 dense prediciton에 활용할 수 있는 가장 직관적인 방법은 CLIP에서 이미지-텍스트 쌍으로 대조 학습을 했듯이, region-text 쌍으로 모델을 fine tuning하는 것인데 이 방법은 annotation 부담이 굉장히 큽니다. 다른 기존 연구(RegionCLIP)에서는, 이미지 캡션에서 단어를 뽑아 region과 매칭시키는 pseudo-label을 사용했지만, 매칭 자체가 부정확하며 노이즈가 섞일 수 있다는 단점이 있었습니다. 따라서 저자들은 Fig 1의 image crop vs dense feature 실험에서 확인한 바를 가지고, image crop을 dense featured의 detection 능력을 강화하게끔 teacher 역할로 사용하는 self-distillation 기법인 CLIPSelf 방법론을 제안합니다. 이미지를 m x n의 grid patch로 자른 뒤, 각 패치를 인코딩해서 얻은 패치 별 feature map과, 전체 이미지를 인코딩 해서 얻은 dense feature map의 (같은 위치의) region representation 간의 코사인 유사도를 최대화하도록 학습시킵니다. (Fig 2. b 참고)
CLIPSelf는 Open Vocabulary Object Detection 의 OV-COCO, OV-LVIS 벤치마크에서 SOTA를 달성했으며, segmenation 모델에 CLIPSelf을 적용했을 때도 큰 폭의 성능 향상을 보였다고 합니다
Methods
Image Representation V.S. Dense Representation
일반적인 이미지 표현과 논문에서 말하는 “dense representation”을 비교 및 정의하고, Intro에서 언급했던 image crop vs dense representation 비교 실험 결과를 분석하는 파트입니다. 우선 image representation과 dense representation을 정의해보겠습니다.
- CLIP’s image representation ViT
논문을 보신 분들은 알고 계실 만한 내용인데, 오리지널 ViT는 원본 이미지를 patch sequence로 나누고, 시퀀스 맨 앞의 cls token를 넣은 뒤 각 패치/토큰 간 self attention을 수행합니다. 최종적으로 업데이트된 cls token은 이미지 전체를 대표하는 임베딩 벡터로서 분류 작업에 사용됩니다. - CLIP’s dense representation
CLIP ViT에서 2D dense feature map을 추출하기 위해 마지막 residual attention block을 다음과 같이 수정해서 사용합니다. 사실상 self attention 적용만 제외했다고 보시면 됩니다.
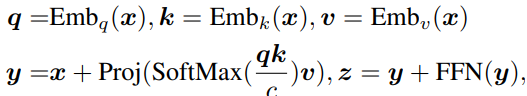
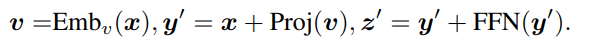
기존과는 반대로 CLS token을 버리고, 나머지 image patch embeddings sequence를 2D로 reshape해서 피처맵 \mathcal{X}_{dense} 를 생성합니다. 이후 객체 탐지를 위해 \mathcal{X}_{dense} 위에서 RoIAlign, mask pooling 등의 기법으로 box의 representation을 추출합니다.
저자들은 COCO 데이터셋을 가져와서 (Intro에서 언급했던) Image Crop(원본 이미지에서 box 영역을 잘라내서 입력)과 Dense Feature(피처맵을 먼저 뽑고 객체 영역 표현 추출)의 region 분류 성능을 측정하는 실험을 진행했습니다. 결과는 Image Crop이 dense feature보다 region 분류 성능이 훨씬 좋았습니다.
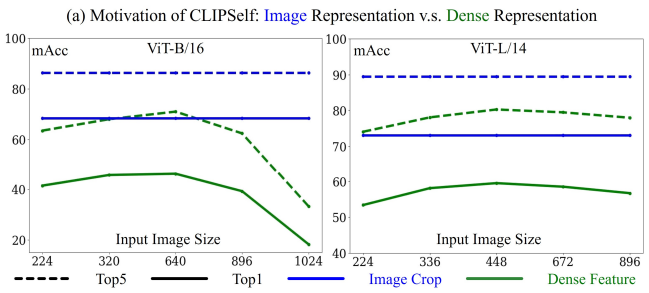
또한 Dense feature는 입력 이미지의 해상도를 키우면서 진행해도 (보통의 직관과는 달리) 성능이 오르지 않는 경향을 보였습니다. 고해상도가 필수인 객체 탐지/분할 task에서는 치명적인 경향성인데, 저자들은 여기서 dense feature map에서 추출된 region representation이 그에 대응되는 image crop과 align 시켜보면 어떨까라는 아이디어를 떠올립니다.
CLIPSelf
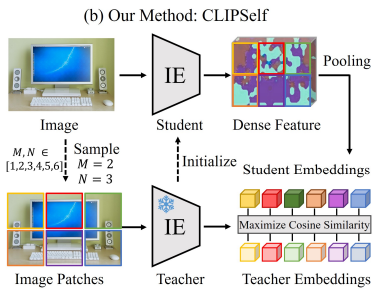
CLIPSelf는 원본 이미지의 dense feature의 각 영역을 image patch별 representation으로 강화시키는 finetuning 방법론입니다. Teacher는 original CLIP Image Encoder(Frozen)으로, Image Patch를 입력받아 패치별 표현 임베딩을 출력합니다. Student는 Teacher의 가중치, 즉 원본 CLIP Image Encoder의 가중치로 초기화된 후 파인튜닝되며, 전체 이미지를 통과시켜 dense feature map을 추출하고, patch 위치별 dense representation을 추출합니다. 이미지 Split은 단순히 m x n 의 grid로 자르며, 실험 결과로는 총 6개의 패치(M=6)로 자른다고 합니다. multi-scale 학습을 위해 iteration마다 m x n 의 m,n은 [1,M] 범위에서 선택되는데, 예를 들어 M=6이라면 1×6,2×3,3×2,6×1 의 split 경우의 수 중 하나를 선택한다는 것입니다. 기존 연구로는 Region Proposal Network를 사용해서 객체가 있을만한 영역만 확인한 연구도 있었으나 ‘물체 Thing”에만 집중하게 되는 데 반해, CLIPSelf 방식은 배경까지 효과적으로 학습하게 된다는 장점이 있습니다. Student가 뽑은 구역별 region representation과 Teacher가 뽑은 patch별 embedding 사이의 코사인 유사도를 최대화하도록 Loss를 구성하여 학습을 진행합니다.
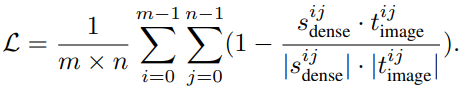
Application to OVOD
segmentation도 다루긴 했으나, detection에 대해서만 다루겠습니다. OVOD에 적용 시, frozen CLIP ViT 위에 Two-stage detector를 얹어 detector head만 학습시킨 뒤, freeze했던 백본을 finetuned CLIPSelf backbone으로 교체합니다. 추가로, 객체 탐지는 foreground 객체를 찾는 것을 목적으로 하기 때문에, 예외적으로 디폴트 방식인 grid patch 대신 region proposal 사용 방식도 옵션으로 남겨둔다고 합니다.
Experiments
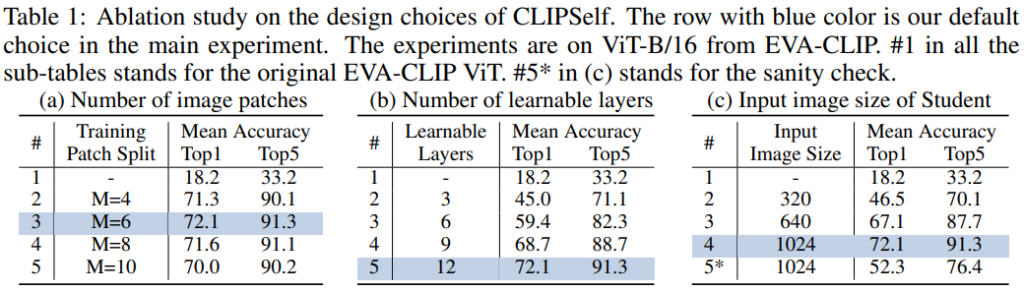
먼저 ablation입니다. (a) patch를 몇 개로 자를 지(method figure의 M), (b) student에서 학습시킬 attention layer의 개수, (c) student 입력 이미지 size 에 대해서 최적의 값이 무엇인지 찾아보았고 파란색 하이라이트 부분과 같이 결정되었습니다. 참고로 (c)의 5*는 sanity check인데, 입력 이미지 size를 키울수록 성능이 좋아지는 것이 고해상도 이미지의 덕분인지, CLIPSelf 덕분인지 확인하기 위해 image-level supervision 실험을 진행해본 것으로, 성능이 낮은 것이 확인되어 CLIPSelf의 Self-distillation의 영향으로 성능이 향상되었다는 것을 증명했습니다.

detection 및 semantic/panptic segmentation에서 성능 향상을 확인했으며, 정성적으로 dense representation을 확인했을 때 기존에는 피처맵이 굉장히 noisy했던 것과 달리 CLIPSelf에서는 객체의 윤곽에 따라 같은 객체끼리 깔끔하게 묶어낸 모습을 보여줍니다.
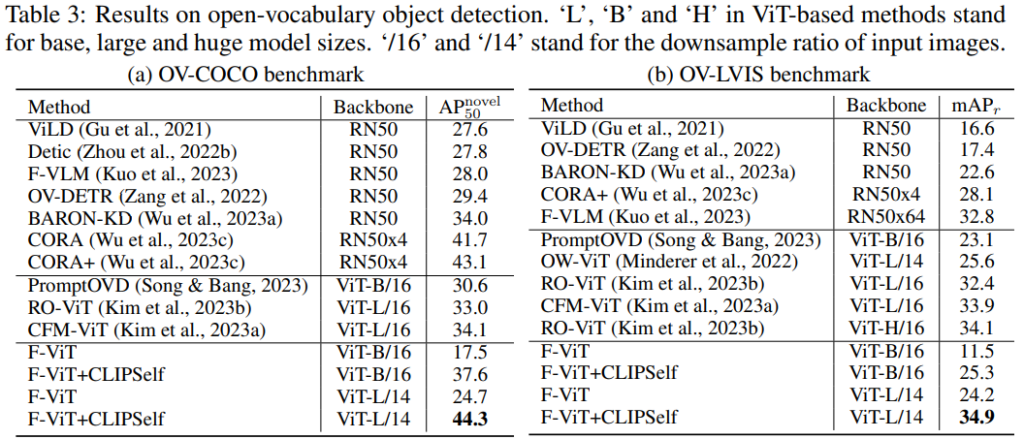
Table 3는 OVOD에 대한 실험 결과표로 CLIP ViT 기반 방법론과 CLIP CNN 기반 방법론들의 성능을 보여주는데, F-ViT : 17.5 → F-ViT + CLIPSelf : 37.6으로 self-distillation을 통한 상당한 성능 향상을 확인했습니다. OV-LVIS 에서 RO-ViT는 ViT-H/16이라는 거대 백본을 사용한 성능보다 F-ViT+CLIPself 성능이 근소하게 높다(34.1→34.9)는 결과도 CLIPSelf의 엄청난 효율성을 방증합니다.
Conclusion
본 논문은 ViT 기반 CLIP 모델이 dense prediction task에서 dense representation이 겪는 한계를 심층적으로 분석하고, annotation 비용이 큰 region-text pairs 데이터에 의존하지 않고 모델 스스로 특징을 align시키며 self-distill하는 CLIPSelf를 제안하였습니다. CLIPSelf는 OVOD, Open Vocabulary Segmentation 벤치마크에서 SOTA를 달성했으며, align의 개선만으로도 dense prediction 성능을 끌어올릴 수 있다는 것을 증명했습니다.
방법론만 본다면 굉장히 단순해 보이는데, 특히 self distillation을 통해 annotation 부담을 완화했다는 것이 엄청난 메리트로 느껴지는 것 같습니다. 제가 한 가지 신기했던 부분은, table 1의 image patch ablation 실험에서 split하는 패치 개수가 많을수록 더 세밀한 정보까지 담는 것이 가능해져 더 성능이 좋아지는 것 아닐까라는 생각이 들었는데, 나름 M=6이라는 최적값이 있었다! 며 끝내고 추가 분석 내용이 없어 아쉬(?)웠네요. 긴 글 읽어주셔서 감사합니다!
안녕하세요 재윤님 좋은 글 감사합니다.
내용에 빠진점이 크게 없는 것 같은데 질문이 하나 있습니다.
마지막에 언급해주신 M=6이라는 최적의 패치 개수가, 큰 해상도의 이미지가 아니라서 그런 결과가 나왔을 수 있는데, 전처리 과정에서의 resize가 아니더라도 최초 input 데이터의 해상도가 달라진다면 최적의 patch가 달라질 수 있다고 생각하는지 궁금합니다.
감사합니다.
안녕하세요 인택님, 좋은 질문 감사합니다.
논문에서는 memory cost로 인해 입력 이미지 해상도를 1024×1024로 고정했고, 그때의 최적 패치 개수가 6개였습니다. 따라서 만약 입력 이미지 해상도가 더 키울 수 있다면, 제 예상으로는 패치 개수를 늘려야 배경/객체 학습이 원활하게 될 것 같습니다. 단 논문의 ablation 실험처럼, 역시 최적의 패치 개수가 존재할 것이라고 생각합니다.
안녕하세요 재윤님 좋은 리뷰 감사합니다.
둘러보던 중 익숙한 CLIP이라는 키워드가 있어 리뷰를 읽게 되었는데, 질문이 있어 댓글 남깁니다.
먼저, CLIP encoder에서 나온 각 dencse features는 어떤 방향으로 학습하게 되는지 궁금합니다. self-distillation을 통해 teacher의 patch embedding과의 유사도가 높도록 학습한다고 하셨는데, 이것이 CLIP encoder를 거쳐 나온 embedding에 근사하도록 하는 것이 어떤 목적을 가지는 지 명확하게 납득이 되지 않는 것 같습니다 (제가 CLIP에 대해 깊은 지식이 없어서 일 수도 있습니다.)
추가적으로, Table 1에서 c의 경우 이미지 크기에 따른 성능 향상에 대한 분석에서 궁금한 점이 있습니다.
실험 결과에서, image-level supervised로 실험한 결과가 성능이 낮은 것이 왜 이미지 크기에 따른 성능이 self-distillation 때문인지 쉽게 이해가 되지 않습니다. self-distillation의 dense feature가 이미지 해상도에 영향을 받지 않는데, self-distillation이 모델에 어떤 영향을 주어, table1-(c) 와 같은 경향성을 보이는 지 궁금합니다.
감사합니다!
안녕하세요 희승님, 좋은 질문 감사합니다.
1) 전체 이미지와 이미지 패치를 CLIP Image Encoder에 넣을 때의 차이점부터 설명드리겠습니다. 전체 이미지를 인코딩하게 되면 각 output token sequence의 각 패치가 이미지 전역적인 정보를 담게 됩니다. 이미지 내 패치 주변의 국소 영역 정보를 담고 있지 않은 것이죠. 이미지 분류 테스크에서는 이 점이 문제가 되지 않지만, local한 정보가 중요한 detection task에서는 이 점이 문제가 되기 때문에 CLIPself에서는 ‘이미지 패치’를 인코딩했을 때 출력되는 CLS imbedding을 국소 영역 학습 목적으로 사용합니다. 학습 대상인 student는 cls embedding을 제외한 나머지 토큰 시퀀스의 2D grid 형태(피처맵)로, teacher의 각 패치 영역 표현과, 그에 대응되는 student의 피처맵 패치 영역 표현이 닮도록 contrastive learning을 진행합니다. 쉽게 말하면 CLIP의 이미지-텍스트 대조학습하듯이 CLIPself에서는 “이미지 패치의 피처맵’과 “피처맵의 패치”의 유사도가 높아지도록 대조학습을 진행한다고 생각하시면 될 것 같습니다. 결국 student의 각 피처맵 패치가 국소 정보를 담을 수 있게 teacher의 패치별 표현을 보고 배우게 된다는 흐름입니다.
2. sanity check를 진행한 목적과 결과 분석에 대한 질문으로 이해하였습니다. 아무래도 입력 이미지 사이즈를 키울수록 더 많은 정보를 사용하는 꼴이기 때문에 일반적으로 탐지 성능은 올라갈 것입니다. 그래서 저자들은 성능 향상의 원인이 고해상도 이미지 덕인지, 자신들의 self-distillation 덕인지 살펴보기 위해 기존 CLIP처럼 이미지-텍스트 대조학습시킨 결과와 비교했습니다(=image level supervision). 같은 고해상도 이미지를 입력했음에도 성능 차이가 발생했다는 것은 기존 CLIP처럼 이미지 전역적인 정보만 담긴 표현을 그대로 사용하는 대신 self-distillation으로 local 정보까지 담아야 detection 성능이 높아진다는 점을 방증합니다.
안녕하세요 재윤님, 리뷰 잘 읽었습니다. 궁금한 부분이 있어서 질문 남겨 놓습니다.
Dense representation 추출 시 마지막 residual attention block에서 self-attention을 제외했는데, 마지막 block이 아닌 다른 block을 수정하는 방식과의 비교도 있었는지 궁금합니다.
안녕하세요 성민님, 좋은 질문 감사합니다.
마지막 블록에 self-attention을 제거하는 방법은 MaskCLIP이라는 이전 연구에서 마지막 레이어의 self-attention을 제외시키면 dense feature가 잘 보존된다는 사실을 증명했기 때문에 그대로 가져다 쓴 세팅이라 다른 블록을 수정하는 방식을 실험하지는 않았습니다. 감사합니다.