안녕하세요 오늘 리뷰할 논문은 Visual Place Recognition에서 현재 SOTA를 달성하고 있는 Towards Implicit Aggregation(이하 ImAge)입니다. 논문의 제목에서도 Transformer Era에서의 Place Recognition이라고 달아둘 정도로 아주 깔끔하면서 높은 성능을 보이는 방법론입니다.
Introduction
Visual Place Recognition(VPR)은 query place image를 보고 가장 유사한 geo-tagged database로부터 retrival하는 task입니다. 이를 위해서는 사진을 global feature로 요약하여 저장할 수 있어야합니다. 이를 위해 고전적인 aggregation 방법(e.g. VLAD)부터 시작해서, Net-VLAD, GeM, SALAD등 다양한 aggregation 방법론이 나왔습니다.
이러한 방법들은 공통적으로 backbone을 backbone-plus-aggregator VPR입니다. 즉, backbone을 통과해서 나온 feature embedding을 aggregation 기법을 이용해서, 하나의 global feature를 담은 descriptor로 요약하는 방법입니다. 저자는 CNN의 era에서는 이것이 표준이였다고 얘기합니다.
하지만 이러한 two-stage 과정은
첫번째로 구조적으로 복잡하고, 불필요합니다.
두번째로, backbone feature를 한번의 과정을 통해 aggregation하므로, refinement할 기회가 없습니다.
이러한 문제점을 언급하면서, 저자는 새로운 방법론 ImAge를 제안합니다.
contrivution은 아래와 같습니다
- backbone을 수정하거나, extra aggregator가 필요없는 implicit method를 제안
- learnable token을 이용하는 방법론이기에, learnable token의 효율적 초기화 방법 제안
- 다른 방법론과 비교하여 SOTA를 달성
Related Work
Transformer에서의 additional token을 사용하는 방법론에 대해 소개합니다.
BERT부터 시작하여, special token을 transformer의 token sequence에 넣는 것은 다양한 분야에서 효과를 보였습니다. 저자는 이러한 방식을 3가지로 더 자세히 구분합니다.
1. Output-oriented tokens는 patch tokens들로부터 정보를 모으는 learnable anchors입니다. BERT나 ViT에서의 CLS token들이 여기에 속합니다.
2. Prompt Tokens의 역할을 하는 방식. 소수의 prompt token들이 잘 학습된 transformer 모델을 마치 text prompt처럼 미세하게 방향을 바꿔주는 역할을 합니다.
3. Memory tokens act as registers that hold intermediate states during sequential processing steps, tracing their roots to neural memory architectures.
내용이 복잡해 원문 그대로 들고왔습니다. 설명해보겠습니다.
Memory token이 register처럼 작동한다고 얘기합니다. DINOv2에서의 사례에서 ViT가 저장공가니 부족해지니 배경에 해당하는 token에 global semantics를 몰아넣는 경우가 보였습니다. 이를 위해, register라고 불리는 memory token들을 넣어줘서 global context를 위한 extra storage를 줬더니 artifact를 해결할 수 있었습니다.
그래서 저자는 3개의 방식 다 영향을 받았지만, 그중 1번 Output-oriented token에 가장 유사한 방법을 택했습니다. learnable token을 삽입하고, 마지막에 다 버려버리는 3번 방식과 달리. 1번처럼 그것 자체를 descriptor로 사용합니다.
Methodology
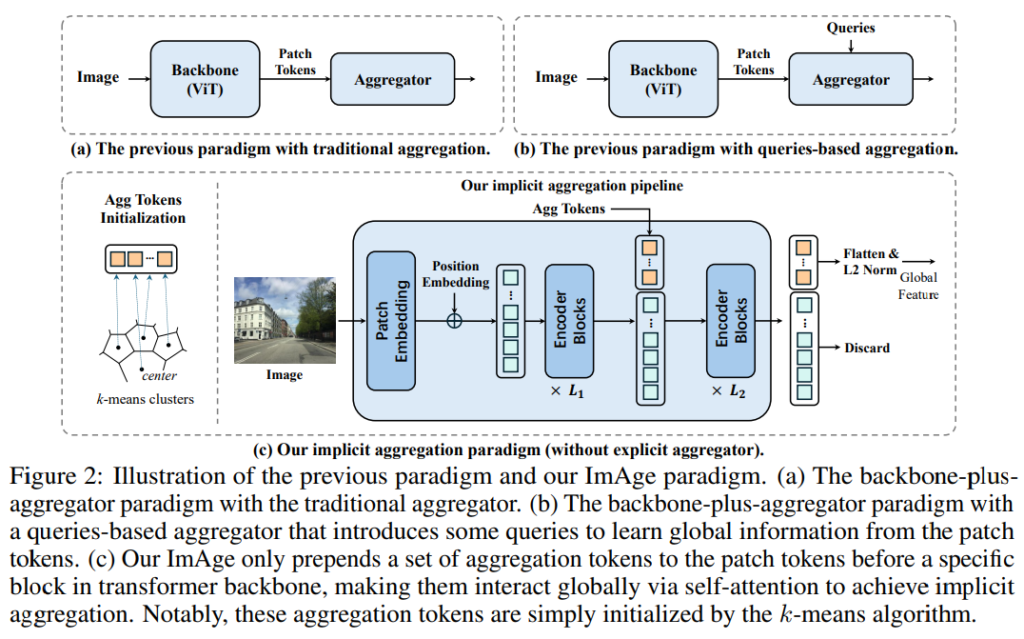
그래서 본격적으로 어떻게 learnable token을 이용하여 VPR을 하는지 설명하겠습니다.
Figure 2. (c).에서 보듯이, 일반적인 ViT를 L1까지의 진행하다가, agg token(learnable token)을 넣어줍니다. 그리고 나머지 layer를 통과시켜서 agg token이 VPR에 적합한 정보를 흡수하도록 합니다.
그렇게 나온 agg token을 flatten하고 L2 norm을 취해, descriptor로 사용하는 아주 간단한 방법론입니다.
저자는 이러한 Agg token을 삽입하는 방식이 agg token과 patch token이 cross attention + agg token들 끼리 self attention을 모두 한다고 얘기합니다.
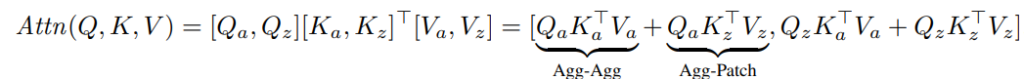
The Insertion Strategy of Aggregation Tokens
위에서 agg token을 삽입할 때, L1 layer를 지난 이후에 넣는다고 했습니다. 이 L1 layer는 결과적으로 8번째 layer지만, 왜 8번째 layer에 넣어야하는지 실험적 그리고 이론적으로 분석했습니다.
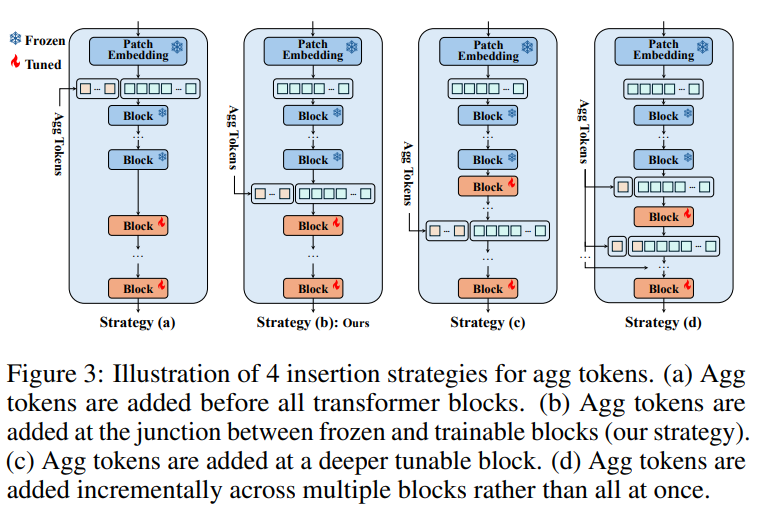
먼저 Strategy(a)입니다. 처음에 이미지를 patch화한 이후에 같이 넣어주는 방식입니다.
이 방식은 두가지 이유로 별로라고 얘기합니다.
1. 초기 transformer layer는 weak feature를 담고 있기에, 불필요한 정보를 모읍니다.
2. agg token은 학습을 해야하기에, 이 방식은 transformer의 모든 layer에 대한 gradient graph를 들고 있어야합니다. 학습 관점에서 엄청나게 무거워집니다.
채택된 Strategy(b)입니다. 최근의 DINOv2를 backbone으로 사용하는 VPR 방법론(e.g. SALAD, superVLAD)들은 뒷단 4개의 layer만 unfreeze하고 학습시켜줍니다. 그렇기에, 4개를 통과하기 전에 agg token을 삽입해줍니다. 앞단의 layer들은 얼어있기에 굉장히 일반적인 feature를 뽑는 반면, VPR을 위해 학습된 4개의 layer는 VPR에 적합한 정보들을 뽑아냅니다. 그렇기에 4개의 layer에서 정보를 모으면 더 VPR에 적합한 정보들만 추출이 가능합니다.
Strategy(c)는 (b)에서의 이유로 안좋은 이유가 설명됩니다. VPR을 위한 layer를 최대한 많이 거쳐서 정보를 흡수하는 것이 성능이 더 좋다고합니다.
Strategy(d)는 agg token을 특정 layer부터 서서히 삽입하는 방식입니다. 이 방식은 더 적은 self-attention을 거치므로 refinement의 기회가 더 적어서 성능이 낮았다고 주장합니다.
The Initialization of Aggregation Tokens
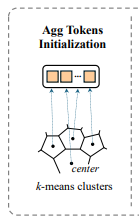
그렇다면 이 agg token을 어떻게 초기화해야할까요? 저자들은 그 정답을 NetVLAD에서 얻었습니다.
NetVLAD는 k개의 cluster center을 학습을 통해 결정합니다. 저자들은 ImAge의 본질은 각 agg token들이 unique한 category에 대한 표현력을 가지는 것이기에 이것이 군집의 중심을 찾는 NetVLAD와 유사하다고 봤습니다.
그래서 초기화 방법은 모든 이미지를 Freezed backbone을 통과시킨 후, 각 패치별로 k-means cluster를 돌립니다. 이를 통해, K개의 시작점을 얻어낼 수 있었습니다.
Experiments
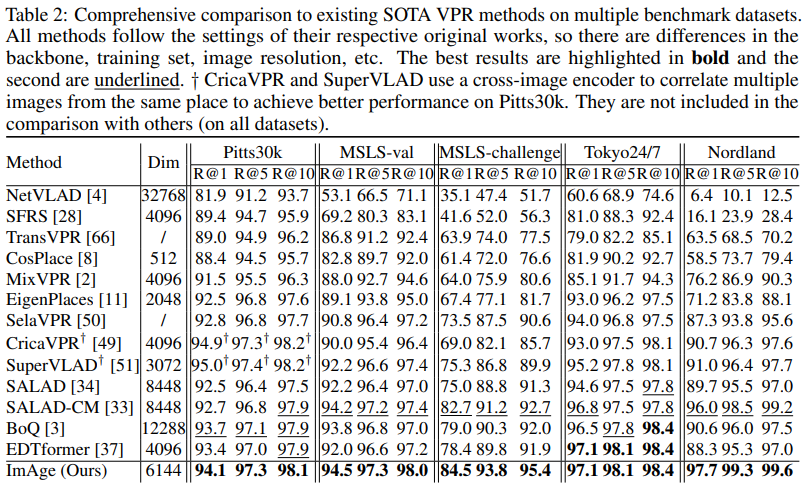
Table2는 상당히 흥미로운 표입니다. 일반적으로 backbone과 여러 세팅을 맞추고 비교한 표를 먼저 보여주는 반면, Table2는 다른 방법론의 세팅을 그대로 실험을 돌려서 비교한 표입니다. 그럼에도 ImAge가 모든 dataset에서 SOTA를 달성했고, 어려운 dataset인 Nordland에서는 상당한 성능향상을 보였습니다.
이 표를 통해서 하고 싶은 말은, 어떤 방법을 가져오더라도, 심지어 backbone이 더 무겁더라도 우리 방법론이 압도적이라는 자신감이 보이는 것 같습니다.
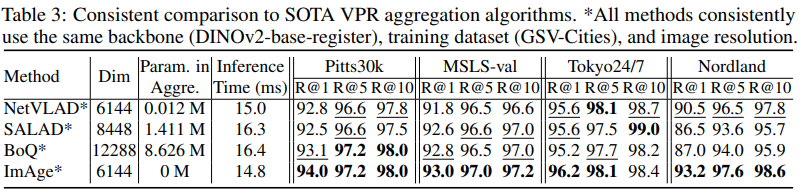
Table3는 backbone과 학습 데이터셋, 해상도를 맞추고 fair한 비교를 한 table입니다. 성능도 역시 대부분의 지표에서 높은 것을 확인할 수 있습니다. 또 주목할만한 점은 Aggregation을 backbone에서 진행하기 때문에 추가적인 parameter가 필요없고, 이로 인해 Inference Time이 다른 방법보다 빠른 것도 확인이 가능합니다.

Figure 4를 통해서는 ImAge가 extreme scenes에 대해 high robustness를 보이는 것을 확인할 수 있습니다.
Ablation Studies
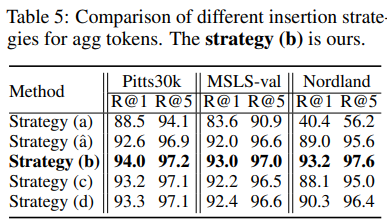
Table 5는 위에서 얘기한 agg token 삽입 위치에 따른 비교입니다. (a), (b), (c), (d)는 다 위에서 설명을 했지만, (\hat{a})은 backbone의 모든 layer를 unfreeze 후 학습시킨 것입니다.
Strategy (a)는 유독 성능드랍이 심했고, 다른 방법론들은 Pitts30k과 MSLS-val에서는 약간의 성능 하락이였지만 어려운 Nordland에서는 큰 폭의 성능드랍이 있었습니다.
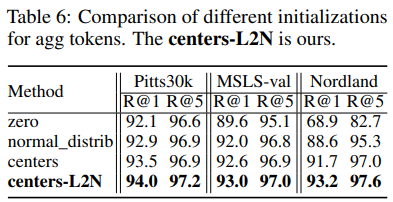
다음은 초기화 방법에 따른 비교입니다.
zero 초기화는 학습 초반에 agg token들이 유사하게 학습이 되어 학습에 방해가 된다고 합니다. 반면에 normal init은 더 좋은 inducitve bias를 제공하고, agg token들에게 약간의 random성을 부여합니다. 하지만, 둘 다 저자가 제안한 k-means cluster기반 초기화보다 낮은 성능을 보이고, 추가적으로 L2-norm을 사용한 방법이 조금 더 나은 성능을 보였습니다.
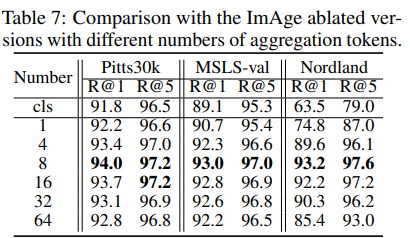
마지막으로 agg token의 개수입니다. 바로 이전의 유사한 방법론인 Bag of Quries(BoQ)에서는 64개를 사용했습니다. 그렇기에 저자도 64까지 비교 실험을 해봤지만, 개수가 많아질수록 명확한 성능 드랍을 관찰했습니다. 이는 token이 많아질수록 self-attention에 큰 영향을 미치기 때문이라고 분석했습니다. 그래서 저자들이 실험을 통해 찾은 최적의 token 개수는 8개입니다.
안녕하세요 정우님
리뷰 감사합니다!
제안하는 방법이 별도의 aggregator없이 transformer안에 넣은 aggregator 토큰 자체가 장소 특징을 모아 최종 descriptor가 되게한다는 것이 핵심이라고 이해했습니다.
한가지 궁금한 점이 있는데 실험에서 table3의 설명에 저자들이 제안한 방법이 추론 시간이 더 빠르다고 설명해주셨는데 이게 별도의 Aggregator가 없기 때문인건지 아니면 descriptor차원이나 aggregator 토큰수 같은 설정 차이의 영향도 같이 반영된 결과인건지 궁금합니다!
안녕하세요 찬미님 질문 감사합니다.
답변을 드리자면, 얘기하신 3요소 전부 영향을 미쳤습니다.
ImAge 역시, self attention과정에서 k개의 agg token이 있다면 NxN 연산을 (N+k)x(N+k)로 늘립니다.
하지만 논문이 최종적으로 채택한 token의 수는 8개 밖에 되지 않으므로 아주 미미한 연산량을 증가시킵니다.
그렇기에 외부 aggregator도 없고, 차원도 낮은 편이고, 토큰수도 적기에 가장 빠른 속도를 냈다고 보면 될 것 같습니다.
안녕하세요, 정우님. 좋은 리뷰 감사합니다.
리뷰를 읽으면서 궁금한 점은 agg token을 early stage부터 넣어서 계속 전달하면, LSTM처럼 long-term memory 역할을 할 수도 있을 것 같은데, 이런 방식이 성능이 안 좋은 이유가 단순히 low-level feature 때문인지 궁금합니다.
이런 생각이 Transformer에서는 오히려 더 불리한 방법인가요?
리뷰 감사합니다.
안녕하세요 기현님 질문 감사합니다.
네 low-level feature인 이유가 가장 큽니다.
또한 초기 layer에 token을 넣는 것은 attention의 흐름을 바꾸기도 합니다.
visual prompt tuning쪽 방법론이 초기에 token을 넣어 attention을 흐름을 제어하는데, agg token도 attention의 흐름을 불필요하게 바꾸게 될 가능성이 역시 높습니다.
감사합니다.
안녕하세요 정우님, 좋은 리뷰 감사합니다.
모든 이미지를 Freezed backbone을 통과시킨 후, 각 패치별로 k-means cluster를 돌린다고 하셨는데, 대규모 VPR 데이터셋 전체를 대상으로 패치 단위의 K-means clustering을 수행하는 것을 엄청난 컴퓨팅 리소스를 요구할 것 같습니다. 논문에서는 이 큰 연산량을 어떻게 해결했는지 궁금합니다.
안녕하세요 재윤님 질문 감사합니다.
저자는 이제 구현 디테일에서, 사실 모든 patch를 k-means한 것은 아니고. 이미지 별로 랜덤하게 100개씩 뽑는 방식을 취했다고 얘기합니다.
그리고 최대 이미지 개수 제한도 두어서, 실제로 모든 이미지에 대한 k-means를 적용하진 않았습니다.
랜덤 샘플링 방식으로 일부만 이용하여 k-means clustering을 진행했습니다.
감사합니다.
안녕하세요 정우님 좋은 리뷰 감사합니다.
결과적으로 ImAge가 별도의 aggregator 없이도 더 좋은 성능을 내는데 여기서 기존의 NetVLAD, GeM, SALAD 같은 방식들이 여전히 필요한 경우는 어떤 경우인지가 궁금합니다. 예를들어 데이터 규모 작거나 백본이 다이노가 아닌 경우 혹은 가벼운 모델인 경우에는 아직 여전히 필요한 건지 궁금합니다. ImAge가 구조적으로 더 단순하고 성능도 좋다면 기존 외부 aggregation 방식은 앞으로 대체되는 흐름인건지가 궁금했습니다. 여전히 외부 aggregator가 더 유리한 조건이 있을지 궁금하네요 허허 감사합니다.
안녕하세요 우현님 질문 감사합니다.
저는 논문의 부제로도 나와있듯이, transformer backbone이라면 ImAge의 방법론이 어떤 aggregator보다 우세하고 보고 있습니다.
반면, CNN 기반의 backbone들은 ImAge의 방법론을 적용할 수 없기에 강제적으로 외부 aggregation 방법을 택해야합니다.
다만 아쉬운점은 저자는 DINOv2로만 실험을 진행했기에, 다른 경량 transformer backbone에서도 ImAge가 우월할지는 증명된바는 없으나, 저는 우월할 것이라고 생각합니다.
현재로서는 ImAge를 넘어서는 SOTA 방법론이 나오지 않아서, transformer backbone이라면 내부 aggregation을 택하지 않을 이유가 없을 것 같습니다. 감사합니다.