최근 TVR 페이퍼 모두 MLLM을 쓰는 추세인가 봅니다. 오늘은 2월에 올라온 Arxiv 페이퍼로, reranker를 개선시킨 Text-Video Retrieval 페이퍼를 리뷰해보겠습니다

- Venue: arxiv 2026
- Authors: Tyler Skow, Alexander Martin, Benjamin Van Durme, Rama Chellappa, Reno Kriz
- Affiliation: Johns Hopkins University, Human Language Technology Center of Excellence
- Title: RANKVIDEO: Reasoning Reranking for Text-to-Video Retrieval
- Code: GitHub
0. Background: Reranker?
Text-to-Video Retrieva라고 하면 보통은 query를 입력하면 데이터베이스 안의 비디오들 중 관련 있는 비디오를 찾아주는 문제입니다. 이때 가장 전형적인 방식은 query와 비디오를 각각 임베딩한 뒤, 유사도가 높은 비디오를 찾는 retriever이죠. 실제로 이 단계는 검색 시스템에서 매우 중요하고, 대규모 데이터베이스를 빠르게 훑으려면 이런 방식이 필수적기도 합니다.
그런데 retriever에는 한계가 있기도 합니다. 수십만 개 비디오 전체를 빠르게 검색해야 하다 보니, 각 비디오를 미리 하나의 representation으로 압축해두고 query와의 유사도만 계산하죠. 이 방식은 빠르다는 장점이 있지만, 실제로는 query와 비디오 사이의 관계를 아주 정교하게 비교하기 어려울 때도 있습니다.

가령 상단 그림처럼 노트르담 화재 당시의 긴급 대응 장면 을 찾고 싶은데, 어떤 비디오는 노트르담 화재 자체는 맞지만 실제로는 화재 이후 내부 피해 장면만 담고 있을 수 있죠. 이런 경우 retriever는 대충 관련 있어 보인다 생각하고 높은 점수를 줄 수 있지만, 사람이 보기에는 query의 핵심을 정확히 만족하지 못하죠
이를 개선하기 위해, reranker가 등장하였습니다. retriever가 먼저 ‘비슷한 후보를 추려주는 역할’을 한다면, reranker는 그 후보들 안에서 진짜로 더 관련 있는 것을 다시 정교하게 가려내는 역할을 하는 것입니다. 텍스트 검색에서는 이미 익숙한 구조이지만, 비디오 검색에서는 아직 이 reranking 단계가 본격적으로 연구된 경우가 많지는 않았다고 합니다. (없지는 않습니다) 리뷰하는 논문은 바로 이 reranker 를 개선한 연구라고 합니다.
1. Introduction
이런 배경에서 저자들이 집중한 문제는 Reranker입니다. 사실 1) Retrieval 2) Reranker를 사용하는 파이프라인은 텍스트 검색에서는 매우 일반적인 파이프라인이라고 합니다.
그럼 이미 잘 연구된 텍스트 검색의 Reranker를 뒷단에 사용하면 되지 않을까요? 저자는 그렇지 않다고 합니다. 텍스트 Reranker를 사용하려면 비디오를 캡션, 음성, OCR 텍스트 등으로 바꿔서 텍스트처럼 취급해야 하는데, 이렇게 하면 시각 정보나 오디오 정보가 누락될 수 있고, 애초에 그런 텍스트를 추출하는 비용도 클 수밖에 없죠. 즉, 텍스트만으로 rerank하면 비디오의 풍부한 정보를 다 활용하지 못하게 됩니다.

이를 해결하기 위해 저자들은 RANKVIDEO를 제안합니다. 이 모델은 query와 video를 함께 보고, 해당 비디오가 query와 관련 있는지 yes/no 형태로 판단하는 video-native reranker입니다. 핵심은 긴 reasoning 문장을 반드시 생성하지 않고, yes와 no의 logit 차이를 relevance score로 사용한다는 점이라고 하는데요. 즉, reasoning model의 장점을 가져오되 실제 reranking에는 더 효율적인 scoring 방식을 사용하는 것이죠
다만……… 저자들이 스스로 reasoning reranker라고 소개하긴 하지만, 실제 ranking score는 yes/no logit 차이에 기반하긴 합니다. 따라서 성능 향상의 핵심이 정말 reasoning인지, 아니면 잘 학습된 video-native relevance scorer인지에 대해서는 조금 살펴봐야할 것 같긴 합니다. 본격적인 리뷰 시작하겠습니다.
2. Method
이 논문의 방법론은 크게 두 부분으로 나눌 수 있을 것 같습니다. 먼저 (1) 학습용 query-video pair를 만드는 Data Synthesis 단계가 있고, 그 다음 (2) 이를 이용해 RANKVIDEO를 두 단계로 학습하는 과정이죠.
2-1. Data Synthesis
여기서 저자들이 굳이 데이터 합성을 진행한 이유는, 기존 video retrieval 데이터만으로는 real-world retrieval에서 필요한 reasoning-intensive한 query를 충분히 만들기 어렵다고 보았기 때문입니다. 다시말해, 기존 전형적인 TVR 데이터셋과는 다르게, 실제 검색처럼 헷갈리는 후보들 사이에서 정답을 가려야 하는 상황을 학습시키고 싶었던 것이죠
그럼 합성 데이터는 어떻게 만들었느냐?
먼저 비디오에서 텍스트 proxy를 만듭니다. 비디오 캡션은 Qwen3-Omni, 오디오는 Whisper, OCR은 multilingual OCR 시스템으로 추출하였다고 합니다. 그리고 이렇게 얻은 caption / audio / OCR / metadata / all information의 다섯 가지 버전을 reasoning text model(Qwen3-32B)에 넣어서 query를 생성합니다. 즉, 영상 내용을 텍스트 관점으로 여러 방식에서 요약한 뒤, 그걸 바탕으로 query를 합성하였다고 합니다.
합성 데이터 필터링
그런데 이렇게 만든 합성 query를 그대로 쓰면, 품질이 낮거나 너무 broad한 query가 섞일 수 있습니다. 그래서 저자들은 몇 단계 필터링을 수행하였습니다.
첫째, 정답 비디오가 1차 검색기 OMNIEMBED의 top-1000 안에도 안 들어오면 버리기
둘째, 가장 어려운 negative가 정답보다 점수가 2배 이상 높으면 버리기
셋째, reasoning teacher가 잘못 분류한 query-video pair도 제거
이를 통해, 정답 비디오가 first-stage retriever의 상위 후보 안에조차 들어오지 못하는 query, 혹은 hard negative가 정답보다 지나치게 높은 점수를 받는 query는 제거할 수 있었다고 합니다.
결과적으로 최종 데이터셋은 35,684 records, 그 안에 9,267개의 positive query-video pair와 26,258개의 negative pair를 만들었다고 합니다. 평균적으로 하나의 query당 약 3.85개의 candidate를 만들었습니다. 결국 이 과정을 통해, reranker가 배워야 할 어려운 구분 샘플을 만들 수 있었습니다.
2-2. Two-Stage Training
이렇게 준비한 데이터 위에서 RANKVIDEO는 두 단계로 학습됩니다. 하단 Figure 2의 왼쪽이 Stage 1, 오른쪽이 Stage 2에 해당합니다.
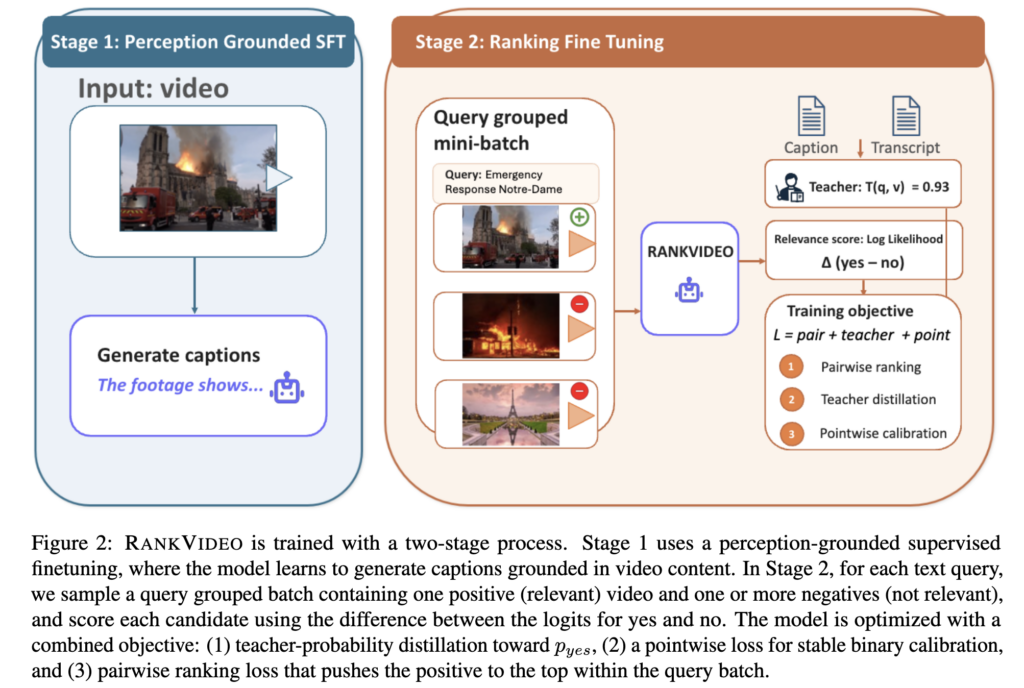
2-2-1. Stage 1: Perception Grounded SFT
먼저 Stage 1에서는 비디오를 보고 caption을 생성하도록 학습합니다.
왜 먼저 captioning을 시키는가?
reranker가 잘 작동하려면, 우선 모델이 비디오 안의 객체, 행동, 사건 맥락을 제대로 읽을 수 있어야 하기 때문입니다. 만약 처음부터 relevant / not relevant만 판단하게 하면, 비디오를 충분히 이해하지 못한 상태에서 얕은 판단만 학습할 수 있습니다. 그래서 먼저 비디오를 보고 caption을 생성하는 학습을 시켜서, 비디오 perception 능력을 안정적으로 익힐 수 있다고 합니다.
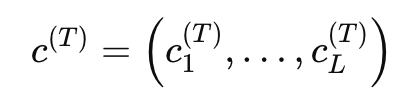
구체적으로는 비디오 v가 주어졌을 때, teacher가 생성한 caption token sequence c^{(T)} 를 정답으로 두고 그 likelihood를 최대화하도록 학습합니다. 즉, 이전까지의 정답 caption과 비디오를 보고 다음 token을 예측하는 일반적인 captioning 방식입니다. 아래 captioning likelihood 를 사용한 것이죠.
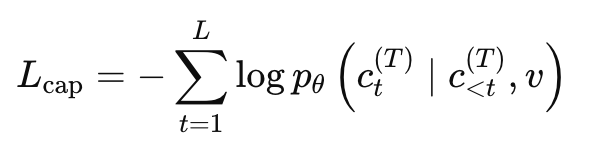
이 단계를 통해 모델은 비디오 안에 무엇이 보이고, 어떤 일이 벌어지고 있는지를 더 잘 표현할 수 있게 됩니다. 저자들은 이를 perception grounded initialization이라고 설명합니다
2-2-2. Stage 2: Ranking Finetuning
이제 본격적인 reranker를 학습하는 부분입니다.
모델은 <answer>yes/no</answer> 형태의 출력을 유도받지만, 실제 ranking에서는 긴 문장을 생성하지 않습니다. 대신 decision position에서의 yes와 no의 logit 차이만 뽑아 relevance score로 사용하옇다고 합니다.
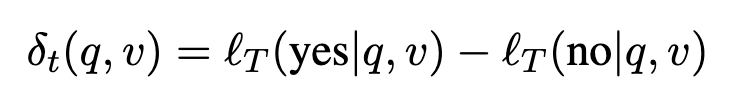
즉, score \delta_t{(q,v)} 가 클수록 yes 쪽이 더 강하므로 relevant할 가능성이 높고, 작을수록 irrelevant할 가능성이 높습니다. 이렇게 하면 reasoning 모델의 구조는 활용하되, 긴 추론 문장을 실제로 디코딩하지 않아도 되므로 inference가 훨씬 효율적입니다.
Hard Negative Mining
특히 이 stage 2에서는 쉬운 오답보다 정답과 매우 비슷해서 헷갈리는 오답, 즉 hard negative를 잘 누르는 것이 중요합니다. 이를 위해 저자들은 teacher 모델을 이용해 오답 후보를 세 가지로 나누었습니다.
- Trusted negative: 확실한 오답 (학습에 사용).
- Suspected positive: 정답일 가능성이 높은 오답 (False negative 위험이 커서 학습에서 아예 제거).
- Hard negative: 정답과 비슷해서 헷갈리는 오답 (학습에 사용).
위에 정리되어 있듯 suspected positives는 아예 버립니다. 왜냐하면 잘못 negative로 학습시키면 모델이 오염되기 때문입니다. 반면 trusted negatives와 hard negatives는 유지하는데, 특히 hard negative는 positive와 매우 비슷해서 reranking 오류를 많이 일으키므로, 이들을 학습에 넣는 것이 중요하다고 하네요.
Hard Negative 에 대한 내용을 간단하게 분석한 것 같아 이 부분은 좀 흥미롭게 읽었습니다. 결국 이 과정의 목적은 단순한 이진 분류가 아니라, 실제 reranking에서 문제가 되는 어려운 오답을 중심으로 학습하는 것입니다.
Loss
Stage 2에서는 하나의 loss만 쓰지 않고, 세 가지 loss를 함께 사용합니다. 이유는 단순합니다. 이 논문이 풀고 싶은 문제는 yes/no 분류가 아니라, 같은 query 안에서 정답 비디오를 더 위로 올리는 reranking이기 때문입니다.
1) Pairwise ranking loss
같은 query 안에서 정답 비디오(p_{+})가 오답보다 더 높은 점수를 받도록 강제하는 역할을 합니다.
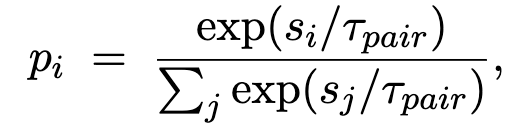
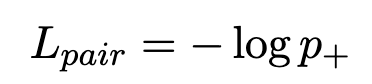
즉, “이 query에서는 정답이 top으로 올라와야 한다”는 ranking 목적을 직접 반영하는 Loss 라고 합니다. softmax를 query batch 내부에서 계산해서 positive probability를 높이도록 하죠
2) Teacher probability distillation
teacher가 주는 soft relevance confidence를 따라가게 하여, 더 부드럽고 보정된 점수를 학습하도록 돕습니다.
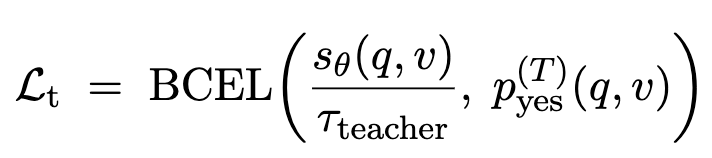
중요한 점은 teacher가 binary label만 주는 것이 아니라 얼마나 확신하는지까지 반영한 확률을 준다는 점입니다. 그래서 student는 단순 0/1보다 더 부드럽고 calibrated한 supervision을 받을 수 있습니다.
3) Pointwise loss
각 query-video pair를 개별적으로 relevant / not relevant로 분류하는 loss입니다. class imbalance를 안정화하고, noisy negative를 감안하기 위해 negative target을 0이 아니라 0.1처럼 soften (\tilde{y})해서 사용하였다고 합니다. 즉, negative를 너무 강하게 멀어지지 않도록 설계했습니다.
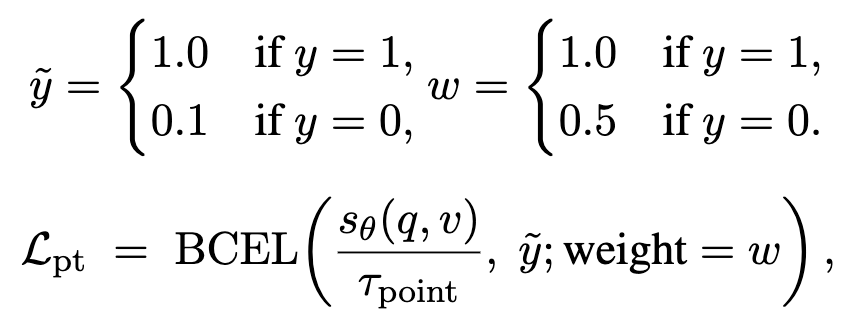
최종적으로는 pairwise + teacher distillation + pointwise 이 세 가지를 합친 weighted sum을 사용합니다.
방법론 정리
정리하면, 이 논문의 Method는 (1) 어려운 retrieval 상황을 반영한 데이터를 만들고, (2) 먼저 비디오 이해 능력을 익힌 뒤, (3) hard negative 중심의 ranking-aware objective로 reranker를 학습하는 구조로 이해할 수 있습니다.
3. Experiment
3-1. 실험 세팅
평가는 MULTIVENT 2.0 test set에서 진행하였습니다. 전체 비디오 수는 109,800개입니다. 먼저 1차 retrieval이 top-1000 candidates를 뽑고, 그중 top-100을 reranker가 다시 재정렬하는 식입니다. 평가 지표는 R@10/20/50/100과 nDCG@10/20/50/100입니다. (높은 값일수록 좋습니다)
Retrieval로는 OMNIEMBED를 메인으로 쓰고, 추가로 MMMORRF, CLIP, LanguageBind, Video-ColBERT 등도 실험에 사용하였다고 합니다. 아무래도 특정 Retrieval에만 작동하는 것이 아니라는 일반화를 보여주기 위함이겠죠. baseline reranker로는 text-based reasoning reranker인 REASONRANK, 그리고 여러 Qwen3-VL 변형(QVL-I, QVL-T, QVL-R)을 비교하였습니다. 저자의 RANKVIDEO는 QWEN3-VL-8B-INSTRUCT를 기반으로 초기화되었다고 하네요
3-2. Main Result
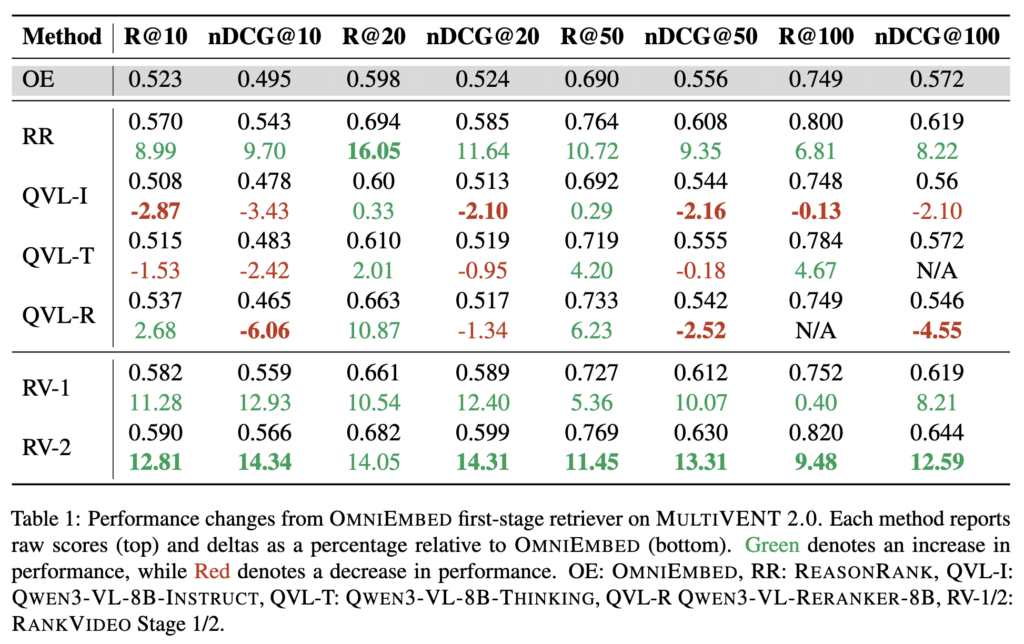
RANKVIDEO stage 2(RV-2)가 거의 모든 metric에서 가장 좋은 결과를 보였습니다. OMNIEMBED 단독 대비 nDCG@10 기준으로 약 14.34% 상대적으로 향상되었습니다. 또한 stage 1만 적용한 RV-1도 이미 strong한 개선을 보여줍니다. 즉, perception-grounded pretraining 자체도 효과가 있습니다.
흥미로운 점은 다른 video-native baseline들이 오히려 성능을 못 올리거나 떨어뜨리는 경우가 있다는 것입니다. 특히 zero-shot QVL-I, QVL-T는 query-video relevance를 정확히 판단하지 못했고, QVL-R은 실제 real-world retrieval setting에서는 성능이 많이 하락했습니다. 반면 REASONRANK는 어느 정도 성능을 올리지만, RANKVIDEO보다는 약합니다.
이를 통해 저자가 말하고자 하는 것은 아래와 같은 세 가지라고 하는데요
첫째, 일반 vision-language model이나 reasoning model을 zero-shot으로 그대로 reranker처럼 쓰는 것은 잘 안 된다. 둘째, 텍스트로만 rerank하는 것보다 비디오 자체를 보는 video-native reranking이 더 낫다. 셋째, MSRVTT 같은 다소 단순한 retrieval task에 맞춰진 reranker는 real-world retrieval로 잘 일반화되지 않는다.
3-3. Score Distribution Shift
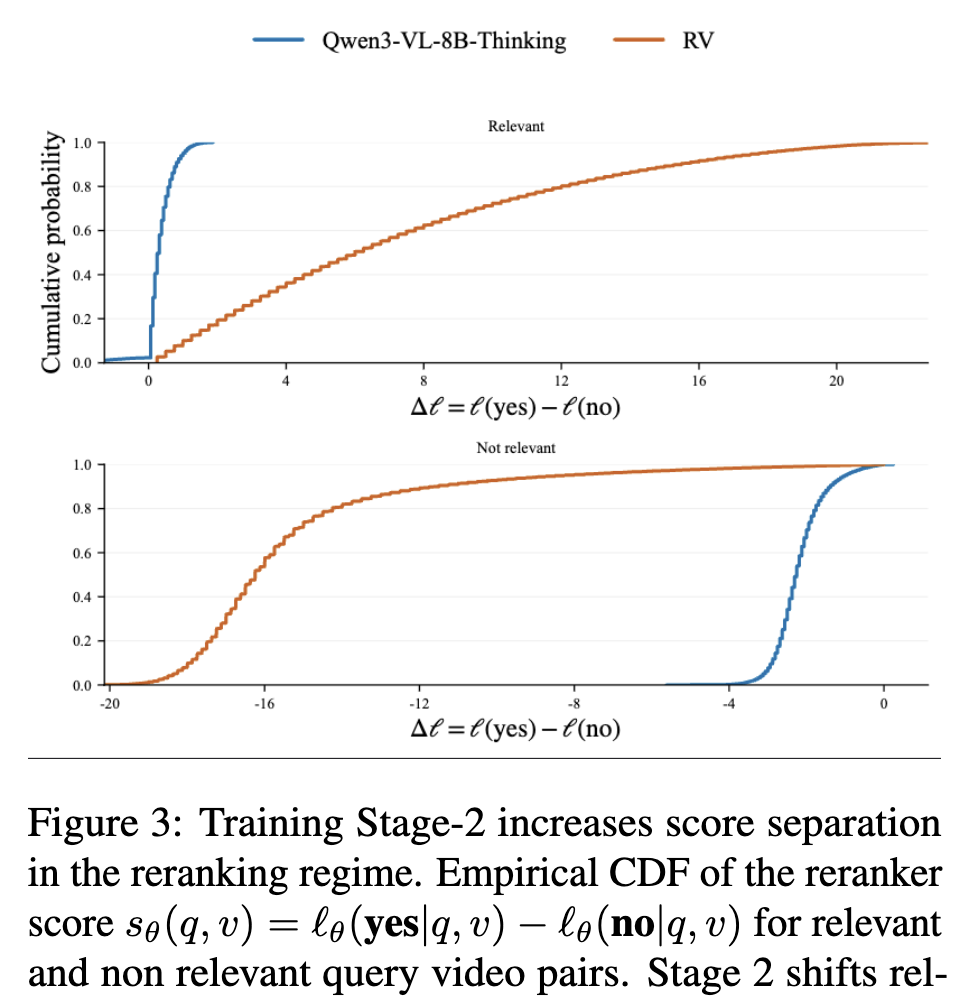
Figure 3는 stage 2가 실제로 점수 분포를 어떻게 바꾸는지 보여주는 결과입니다. relevant pair는 더 큰 positive margin 쪽으로, non-relevant pair는 더 negative한 쪽으로 이동한 것을 볼 수 있는데요. 다시말해, positive와 negative의 score distribution이 더 잘 분리됩니다.
이건 단순 accuracy 개선된 것 그 이상을 의미한다고 합니다. reranking에서는 특히 hard negative가 높은 점수를 받아 정답을 멀어지게 하는 문제가 다소 치명적인데, stage 2 학습이 그 hard negative들의 점수를 더 낮춰서, top ranks에서 정답이 올라오도록 도와준 것이죠. 즉, 이 논문은 “분류를 잘하는 것”보다 “랭킹에 맞는 score separation을 만드는 것”이 중요하다고 보여줍니다.
3-4. w/ Other Retrieval Model
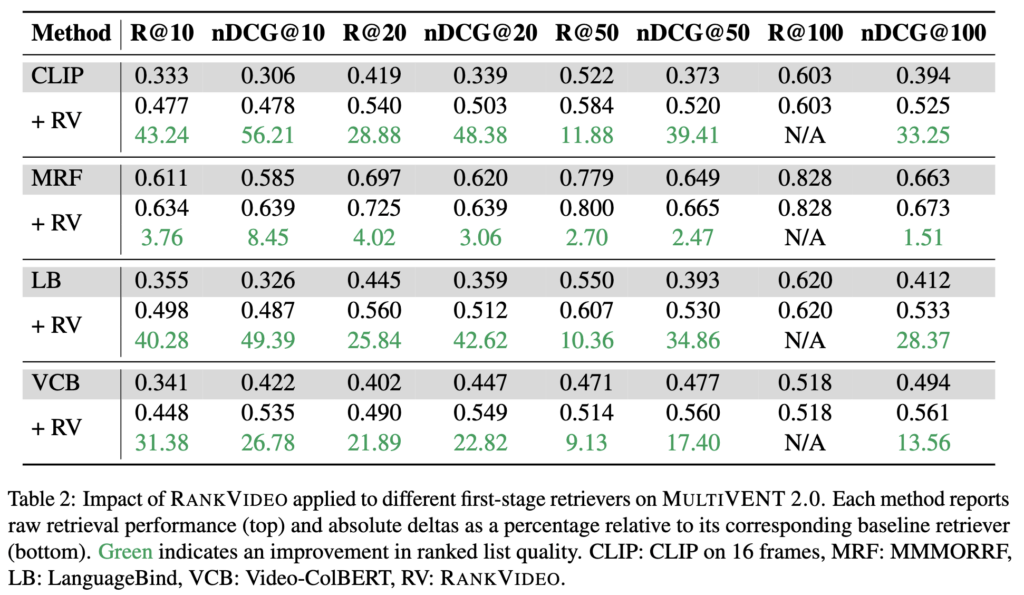
Table 2를 보면 RANKVIDEO는 OMNIEMBED뿐 아니라 CLIP, MMMORRF, LanguageBind, Video-ColBERT 위에서도 일관되게 향상된 성능을 확인할 수 있습니다. 특히 Retrieval의 성능이 낮을 수록, Reranker 로 인한 성능 개선 폭이 컸습니다. 예를 들어 CLIP이나 LanguageBind에서는 nDCG@10이 크게 증가하였죠
이를 통해, RANKVIDEO는 특정 1차 검색기에만 맞는 것이 아니라 범용적인 second-stage reranker처럼 작동합니다. 그리고 1차 검색기가 조금 약하더라도, 2차 reranker가 충분히 보완해줄 수 있다고도 얘기할 수 있죠
3-5. Efficiency and Dynamic Reasoning
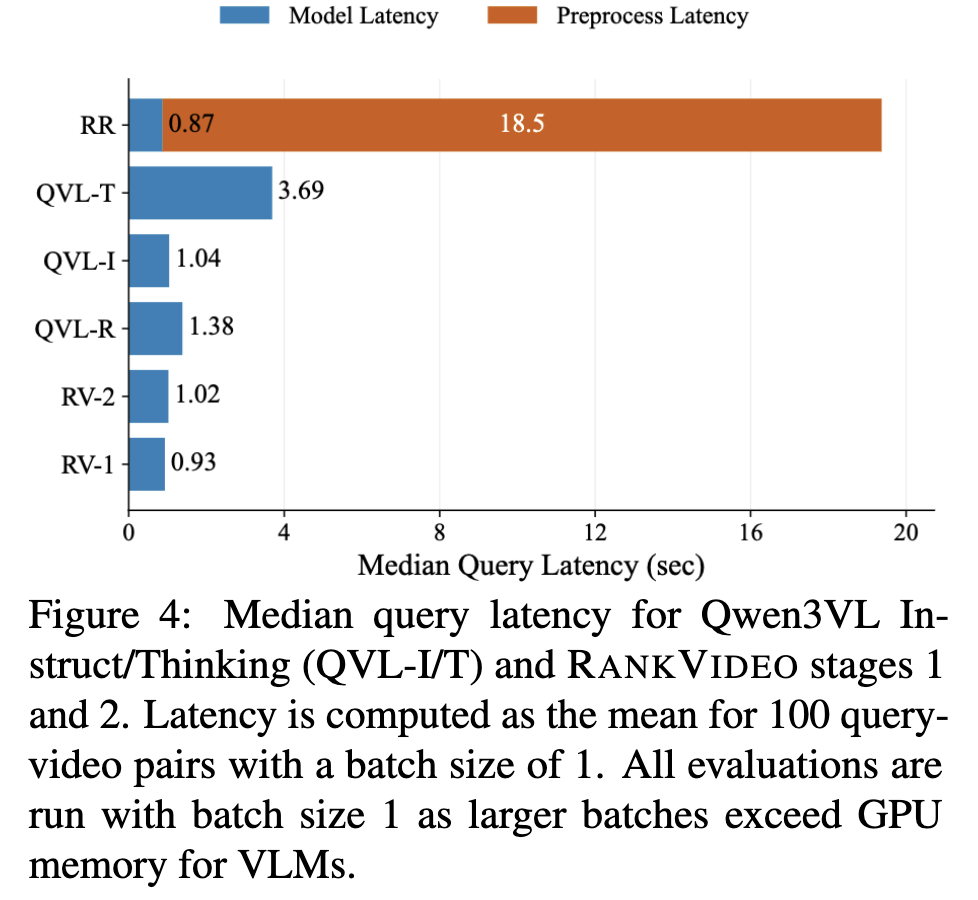
Figure 4는 latency 비교입니다. RANKVIDEO stage 2는 Qwen3-VL-Thinking보다 훨씬 빠른데요. 이유는 간단합니다. QVL-T는 매 query-video pair마다 긴 reasoning trace를 생성하는 반면, RANKVIDEO는 yes/no logit 차이만으로 점수를 계산하기 때문입니다. REASONRANK와 비교해도 inference 시에는 비디오 프레임만 사용하므로, 캡션 생성 같은 expensive preprocessing이 필요 없습니다.
4. Conclusion
지금까지 Reranker에 대한 논문을 리뷰해보았습니다. 제가 생각했을 때 해당 연구의 가장 큰 장점은 문제 설정이 제법 현실적이라는 점입니다. TVR이라고 한다면 MSRVTT 같은 전통적인 caption 기반의 데이터셋을 사용하는데 그게 아니라, MULTIVENT 2.0처럼 real-world retrieval에 더 가까운 setting에서 reranking을 다뤘다는 점이죠.
그와 동시에 해당 논문이 좀 아쉬운 부분은 실험 벤치마크가 주로 MULTIVENT 2.0 중심이라서, 전통적인 TVR 벤치마크나 다른 real-world 데이터셋에서의 일반성이 얼마나 강한지 더 보고 싶다는 생각은 듭니다. 다만 저자들의 초점 자체가 “contrived benchmark보다 real-world benchmark가 더 중요하다”는 쪽이긴 하지만……. 예,…
그리고 또 하나는 synthetic query 비중이 꽤 크다는 점입니다. 논문에 따르면 최종 학습 데이터에서 human-written query는 1,361개, synthetic query는 7,906개입니다. 즉, 성능 향상의 일부가 synthetic data design에 많이 의존할 수 있습니다. 이 synthetic query가 다른 domain으로 얼마나 잘 일반화되는지는 또 확인해봐야할 것 같습니다
이 외에 논문에서 밝힌 한계는 바로 계산 비용 문제인데요. 사실 multi-video inference나 listwise reranking을 하고 싶어도 메모리와 연산량이 너무 커서 이번에는 못 했다고 합니다. 실제로 pairwise objective를 학습하는 데도 8장의 80GB A100을 썼다는 걸 보면… 비디오 reranker가 그동안 왜 연구가 많이 되지 않았는지를 간접적으로나마 알 수 있는 부분 같네요. 그럼 리뷰 마치겠습니다
안녕하세요 주영님 좋은 리뷰 잘 읽었습니다
설명해주신 방법에서 yes/no라는 이진분류를 통해 (문장 reasoning 결과로 ranking을 산출하는 것 대비) 오류의 발생 가능성이 적은 접근법을 사용한것이 흥미롭습니다. 다만 궁금한 점은 이러한 접근법이 새로운 접근법은 아닌것 같은데,, 혹시 해당 분야에 첫 도입한것이 본 논문의 제시점 중 하나일까요?
감사합니다
좋은 질문 감사합니다.
말씀하신 Yes/No 기반의 relevance scoring 자체는 완전히 새로운 방식이라기 보다는, 이미 텍스트 reranking이나 최근 멀티모달 reranker에서도 유사한 방식이 사용된 적이 있습니다.
따라서 그렇다보니, 그 기법 자체가 해당 연구의 novelty가 되기는 어렵고, 비디오를 위한 data synthesis의 2-stage traning, hard negative 중심 학습까지 하나의 framework로 구성한 점에 있다고 보는게 더 적절해보이긴 합니다.