Intro
해당 논문은 navigation과 manipulation에 사용할 수 있는 효율적인 World Model을 만드는 것을 목표로 합니다. World Model은 잘 아시다시피 해당 모델이 주변 환경의 역동성을 시뮬레이션하여 미래를 예측하고, 이를 바탕으로 실제 행동을 계획할 수 있습니다.
하지만 기존의 world model들은 사진처럼 생생한 이미지를 생성하는 데 집중하느라, 단 한 장의 관측 이미지를 표현하는 데 수백 개의 잠재 토큰(latent tokens)을 사용하고 있어서 연산량이 상당히 소모되고, 이 때문에 실시간 추론을 수행하는 데 큰 어려움을 겪습니다. CVPR 2025에 게재된 Navigation World Model(NWM)이 그 예시로, 한 에피소드의 계획을 세우는 데 최대 3분이나 걸리는 등 실시간 제어가 불가능했습니다.
본 논문의 저자들은 이러한 문제를 해결하기 위해 다음과 같은 질문을 던집니다. 바로, “인간이 행동을 계획할 때 모든 픽셀을 기억하나? 그렇지 않다면, 영상의 토큰들에 대해 극단적인 압축이 오히려 planning 등에 더 유리할 수도 있지 않을까?”라는 가설입니다. 즉, 저자들은 시각적 디테일을 보존하는 대신, 의사결정에 꼭 필요한 의미론적(Semantic) 정보에만 집중하기로 했습니다.
저자들이 제안하는 CompACT 모델의 핵심은 다음과 같습니다.
- 저자들의 모델은 이미지를 단 8~16개의 토큰(약 128~256비트)으로 압축합니다. 이는 기존 SD-VAE 토크나이저가 사용하는 784개 토큰에 비해 상당히 큰 압축을 수행합니다.
- 조명이나 질감 같은 세부 사항은 planning을 수행하는데 있어 불필요하다고 판단하기에 버리고, 사물의 정체성과 공간 구조 같은 핵심 정보만 추출하기 위해 이미 학습된 비전 파운데이션 모델(DINOv3 등)을 인코더로 활용합니다.
- 압축된 8 (또는 16)개의 토큰을 condition으로 삼아, 압축 과정에서 손실된 디테일한 픽셀들은 pretrained AutoEncoder를 통해 다시 reconstruction 할 수 있도록 설계했습니다.
구체적인 방법론은 다음 Method Section에서 다뤄보도록 하겠습니다.
Method
우선, 저자들의 latent world model의 큰 과정은 아래와 같습니다.
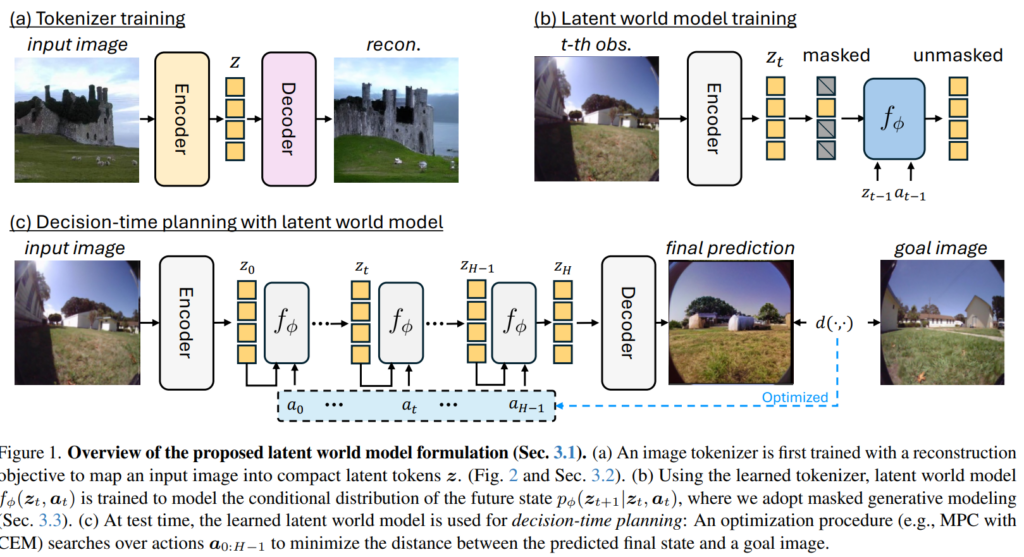
저자들의 방법론의 가장 큰 핵심은 영상의 핵심이 되는 시각적 토큰들만 압축해서 남기는 tokenizer를 만드는 것입니다(a). 이렇게 학습된 tokenizer를 통해서 저자들은 현재의 관측값들을 통해 미래의 관측값을 예측하는 latent world model을 학습합니다(b). 그리고 이렇게 학습된 latent world model은 예측된 목표 상태와 실제 목표 상태의 차이를 최소화하여 액션 값을 찾아나갑니다.
우선 논문 자체가 world model을 타겟으로 하고 있으니 world model의 기본적인 과정에 대해서 알아보겠습니다. World model의 본질은 현재의 관측치 o_{t} 와 행동 a_{t} 가 주어졌을 때, 미래의 관측치 o_{t+1} 에 대한 확률 분포를 예측하는 것입니다. 이를 수식으로 나타내면 다음과 같습니다.
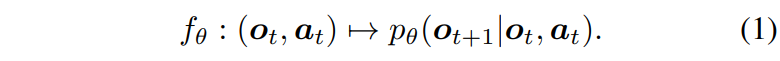
여기서 입력 데이터는 관측치(비디오 프레임) O=[o_{0},o_{1},…,o_{T}] 와 행동 시퀀스 A=[a_{0},a_{1},…,a_{T}] 로 구성됩니다. 저자들이 수식에서는 단순히 t 프레임만 표기했지만 실제 구현 시 모델은 단순히 현재 시점뿐만 아니라 과거 7개의 관측치와 행동 이력을 맥락(Context)으로 참조합니다. 그리고 현실 세계의 역학은 본질적으로 불확실하고 부분적으로만 관측 가능하기 때문에, world model은 결정론적인 결과(deterministic prediction)가 아닌 확률 분포(stochastic distribution)를 생성해야 합니다.
영상은 수많은 픽셀들로 구성되어 있어 이러한 픽셀 공간에서 직접 생성 모델을 돌리는 것은 연산 비용이 매우 큽니다. 따라서 저자들은 이미지를 저차원의 잠재 토큰 z \in \mathbb{R}^{N \times D} 으로 변환하여 처리합니다.
이때 이미지를 잠재 토큰으로 바꾸는 인코더 \mathcal{E} 와 다시 이미지로 복원하는 디코더 \mathcal{D} 로 구성된 autoencoder 방식을 채택하며, 다음과 같은 재구성 손실 함수를 통해 학습됩니다 \mathcal{L}_{recon}=||o-\mathcal{D}(\mathcal{E}(o))||{2}^{2} .
결과적으로 Latent World Model f_{\phi} 는 다음과 같이 정의됩니다.
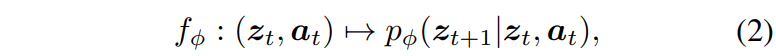
latent z를 구성하는 토큰 개수 N 은 연산 복잡도를 결정하는 핵심 요소입니다. 어텐션 기반 구조에서는 비용이 N 의 제곱에 비례하기 때문에, N 을 작게 유지하는 것이 효율적인 world model의 추론에서 가장 중요합니다.
위의 과정을 통해 학습된 세계 모델을 활용하여 목표 이미지 o_{goal} 에 도달하기 위한 최적의 행동 시퀀스 {a_{t}} 를 찾는 과정은 다음과 같습니다. 우선 현재 관측치를 인코딩하여 z_{0} = \mathcal{E}(o_{0}) 을 얻고 후보 행동 시퀀스를 생성합니다. 이후 미래 상태를 예측하기 위해 세계 모델을 반복적으로 실행하는 rollout 과정을 수행합니다.
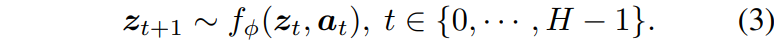
이렇게 H까지의 플래닝을 마무리하였다면, 예측된 최종 상태 \hat{o}{H} = \mathcal{D}(z{H}) 와 목표 관측치 o_{goal} 사이의 거리(Cost)를 측정합니다. C(a) = d(\hat{o}{H}, o{goal})
여기서 d는 거리를 측정하는 함수로 단순히 L1, L2와 같은 함수를 써도 되고, 영상의 퀄리티를 평가하는 SSIM이나 LPIPS를 사용해도 됩니다. 최종적으로, 샘플링 기반 방법이나 경사하강법을 통해 비용을 최소화하는 최적의 행동 a^{*} 를 찾습니다 ( a^{*} = \arg \min_{a} C(a) ). 예시에서는 distance를 계산할 때 world model이 reconstruction한 image에서의 비교를 수행했지만 빠른 추론 속도를 위해 latent space에서 직접 d(z_{H}, z_{goal}) 를 측정할 수 있다고 합니다.
CompACT tokenizer
그럼 본격적으로 저자들이 제안하는 tokenizer가 어떻게 구성이 되고 학습이 되는지 알아보도록 하겠습니다.
앞서 소개드렸다시피, world model의 planning 추론 속도의 병목은 바로 잠재 토큰의 개수 $N$입니다. 기존 토크나이저들은 이미지를 수백 개의 토큰으로 인코딩하여 자동 회귀적 롤아웃 속도를 현저히 떨어뜨린다고 하며, 이러한 문제를 해결하기 위해 저자들이 제안한 CompACT 토크나이저는 이미지를 단 8개 또는 16개의 이산 토큰으로 압축하고 연속적인 잠재 공간에서 필요한 반복적 디노이징 과정을 생략하여 효율성을 극대화하였다고 합니다.
Semantic encoding via frozen features
인코더인 \mathcal{E}_{compact} : \mathbb{R}^{H \times W \times 3} \to {1, \dots, K}^N 는 픽셀 단위의 복원보다는 planning 수립에 초점을 맞춘 의미론적 정보를 보존하는 데 집중합니다. 이를 위해 저자들은 질감이나 조명 같은 저수준 디테일을 이미 추상화한 사전 학습된 DINOv3 비전 엔코더를 채택했습니다.
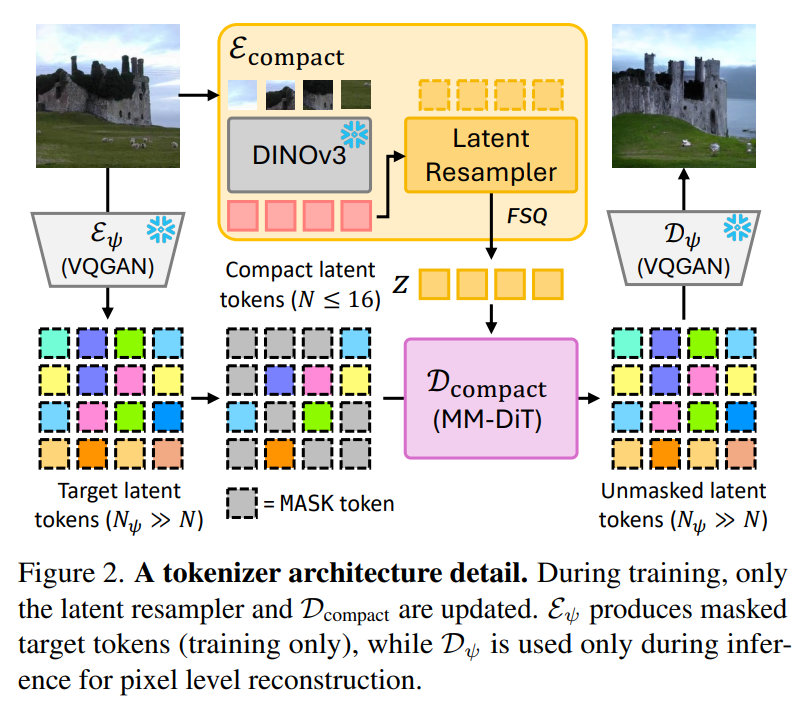
구체적으로, 입력 이미지는 고정된 DINOv3를 통해 패치 표현으로 추출되며, 초기 잠재 토큰 z^0 \in \mathbb{R}^{N \times D} 은 트랜스포머 디코더로 구성된 Latent Resampler 내에서 학습 가능한 쿼리(Query)로 작동하여 이 패치 토큰들에 어텐션을 수행합니다. 이 교차 어텐션 과정을 통해 모델은 객체의 정체성, 공간적 레이아웃, 장면 구조와 같은 고수준의 의미론적 단서만을 선택적으로 추출하게 됩니다. 결과적으로, 리샘플러의 출력은 최종적으로 Finite Scalar Quantization(FSQ)를 통해 이산적인 잠재 토큰 z \in {1, \dots, K}^N 으로 변환됩니다.
Generative Decoding
단 16개 이하의 토큰으로부터 직접 픽셀을 복원하는 것은 정보의 병목으로 인해 결정론적인 회복이 불가능한 Ill-posed problem이 됩니다. 저자들은 이를 해결하기 위해 압축 해제를 조건부 생성 작업으로 전환하는 생성적 디코딩(Generative Decoding) 전략을 도입했습니다.
디코더인 \mathcal{D}{compact} : {1, \dots, K}^N \to {1, \dots, K\psi}^{N_\psi} 는 Compact Encoder의 output인 압축 토큰 $z$를 조건으로 사용하여, 수백 개의 토큰( N_\psi \gg N )으로 구성된 타겟 토크나이저(MaskGIT의 VQGAN)의 잠재 토큰 시퀀스 $z^\psi$를 생성하도록 학습됩니다.
여기서 VQGAN의 사전학습된 Encoder Feature를 VQ GAN의 Decoder에 제공하면 바로 reconstruction이 되기 때문에 compact Decoder가 올바르게 학습을 하지 못하므로, 학습 과정에서는 타겟 토크나이저의 잠재 토큰 중 일부를 무작위로 마스킹하고, 디코더가 압축 토큰 $z$와 남은 토큰들을 참조하여 마스킹된 부분 $M(z^\psi)$을 복구하는 Masked Feature Modeling 방식을 채택합니다. 따라서,. 토크나이저의 학습 목적 함수는 다음과 같은 음의 로그 가능도를 최소화하는 것입니다.
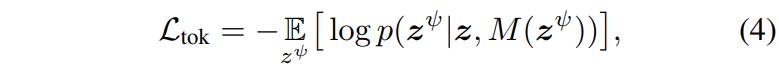
추론 시 \mathcal{D}{compact} 는 완전히 마스킹된 시퀀스에서 시작하여 예측 신뢰도에 따라 점진적으로 토큰을 채워 나가는 반복적 언마스킹 과정을 거칩니다. 최종적인 이미지 재구성은 타겟 디코더를 통해 \hat{o} = (\mathcal{D}\psi \circ \mathcal{D}{compact} \circ \mathcal{E}{compact})(o) 와 같은 경로로 완성됩니다. 이러한 설계로 CompACT는 매우 적은 수의 토큰으로도 계획에 필요한 핵심 의미를 보존할 수 있다고 하며, 생성 모델의 힘을 빌려 이 의미와 일치하는 그럴듯한 고주준의 시각적 디테일을 합성해낼 수 있습니다. 참고로 저자들이 사용한 Compact Decoder \mathcal{D}{compact} 의 구조는 아래와 같습니다.
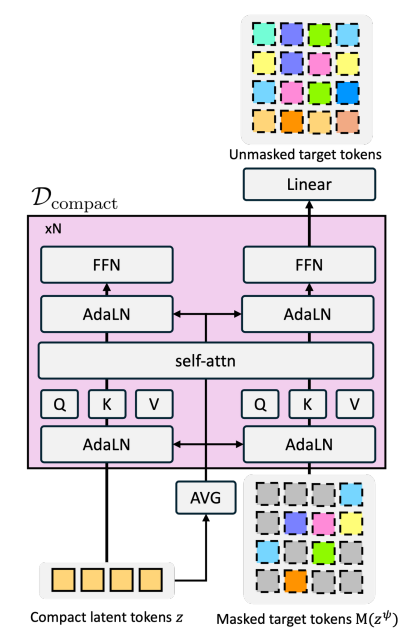
저자들이 직접 제안한 구조는 아니며 multi-modal input에 강인한 DiT 구조의 변형(MM-DiT)를 채택하였다고 합니다.
World model in CompACT latent space
앞선 학습을 통해 CompACT 토크나이저를 잘 만들었다면, world model f_{\phi} 는 이제 N \le 16 인 극도로 작은 개수의 이산 잠재 공간에서 직접 학습될 수 있습니다. 학습 데이터셋의 모든 관측치는 먼저 인코더를 통해 잠재 토큰 z_{t} = \mathcal{E}{compact}(o{t}) 로 변환됩니다. 이 단계에서의 핵심 목적 함수는 Masked Generative Modeling을 채택하여 미래 상태 z_{t+1} 의 조건부 분포를 모델링하는 것이며, 다음과 같은 세계 모델 손실 함수를 최소화하도록 훈련됩니다.
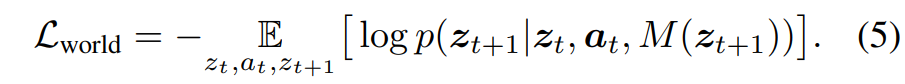
이러한 방식의 가장 큰 장점은 계획 단계에서의 압도적인 연산 효율성입니다. 모델 기반 제어(MPC)를 수행하는 동안 시점당 단 8개 혹은 16개의 토큰만으로 롤아웃을 수행할 수 있기 때문에, 기존에 수백 개의 토큰을 사용할 때 겪었던 어텐션 연산의 토큰 수 제곱에 해당하는 연산 병목 현상을 크게 해소하고 실시간성에 가까운 planning latency를 달성하게 됩니다.
세계 모델의 구체적인 아키텍처는 이산 시퀀스 분포를 모델링할 수 있는 어떤 형태든 가능하지만, 논문에서는 작업의 특성에 따라 두 가지 프레임워크를 탐구합니다. 먼저 Navigation 작업에서는 과거의 잠재 상태 시퀀스 {z_{t-\tau}, \dots, z_{t}} 와 행동 {a_{t-\tau}, \dots, a_{t}} 가 주어졌을 때 다음 프레임 z_{t+1} 을 예측하는 Autoregressive 구조의 DiT 기반 아키텍처를 사용합니다. 반면 Manipulation 작업에서는 여러 미래 프레임 {z_{t+1}, \dots, z_{t+K}} 을 동시에 예측하는 Block-causal transformer를 고안하여 병렬적인 비디오 생성을 가능케 했습니다.
특히 행동 조건화(Action conditioning)를 강화하기 위해 학습 도중 과거 히스토리 윈도우의 잠재 토큰들을 무작위로 마스킹하는 기법을 적용했는데, 이는 디퓨전 포싱(Diffusion Forcing)의 이산적 변형으로 해석될 수 있다고 저자들은 주장합니다. 이러한 훈련 방식은 모델이 부분적으로 오염되거나 손실된 맥락 정보 하에서도 강건한 시공간적 의존성을 학습하게 하며, 추가적인 연산 비용 없이도 계획의 정확도를 현저히 향상시키는 결과를 낳았다고 하네요.
Experiments
Task conductive. CompACT의 성능을 다각도로 검증하기 위해 연구진은 크게 두 가지 핵심 축을 설정했습니다. 첫 번째는 토크나이저 자체의 Reconstruction 품질을 평가하는 것이고, 두 번째는 Navigation 및 Manipulation 작업에서 행동 조건부 세계 모델로서의 계획 효과를 확인하는 것입니다. 이러한 평가 방식을 통해 극단적인 압축이 계획에 필수적인 정보를 보존하면서도 연산 효율성을 극대화할 수 있다는 본 논문의 핵심 가설?을 평가하고자 합니다. 구체적인 평가 task는 image reconstruction, goal-conditioned visual navigation, 그리고 action-conditioned video prediction이라는 세 가지 영역을 다룹니다.
Dataset. 토크나이저 학습에는 ImageNet-1K를 사용했으며, world model 학습을 위해서는 navigation 데이터셋인 RECON, SCAND, HuRoN과 로봇 조작 데이터셋인 RoboNet을 동원했습니다. 특히 비교 대상이 되는 베이스라인 모델들의 경우 기존 sota world model인 NWM에서 사용하는 784개의 연속적 토큰을 가진 SD-VAE와, 최근 등장한 가변 길이 이산 토크나이저인 FlexTok(16 및 64 토큰 설정)을 대조군으로 삼아 CompACT의 압축 효율과 성능을 정밀하게 비교했습니다.
Metric. reconstruction에 대한 평가는 rFID와 Inception Score(IS)로 판단하며, navigation tasks는 계획된 궤적이 실제와 얼마나 일치하는지를 나타내는 절대 궤적 오차(ATE)와 상대 포즈 오차(RPE)로 측정합니다. 저자들은 Action-relevancy를 평가하기 위해서, Inverse Dynamics Model (IDM)을 활용하여 잠재 토큰에서 행동 정보를 얼마나 잘 추출할 수 있는지 L1 오차와 결정계수인 R^2 를 통해 정량화했습니다.
또한 비디오 예측 실험에서는 생성된 프레임으로부터 행동을 얼마나 정확히 복원할 수 있는지를 나타내는 Action Prediction Error(APE)를 사용하여 모델의 역학 이해도를 평가했습니다. 마지막으로 연산 효율성의 척도로 모델 예측 제어(MPC) 중 발생하는 Planning Latency를 측정하여 실시간 추론 가능성을 평가하였습니다.
Tokenizer evaluation and ablations
그럼 우선 tokenizer의 성능에 대한 실험들부터 살펴보겠습니다. 우선 ImageNet 검증 세트를 활용한 image reconstruction 성능 평가에서 CompACT는 매우 높은 압축을 진행하였음을 감안할 때, 최신 토크나이저들과 대등한 수준의 정량 지표를 기록하였다고 저자들은 주장합니다 (표1 참고).
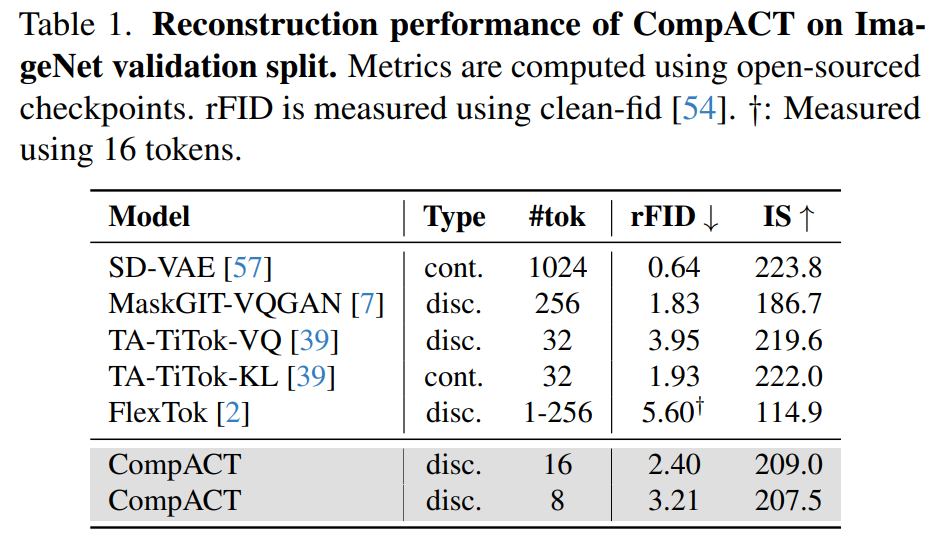
구체적으로 16개의 토큰을 사용하는 CompACT는 rFID 2.40을 기록하며, 이는 256개의 토큰을 사용하는 타겟 토크나이저(MaskGIT-VQGAN, rFID 1.83)와 비교하였을 때 16배 더 적은 양의 토큰을 사용했다는 점에서 경쟁력 있는 복원력을 나타난다고 합니다.
흥미로운 점은 인셉션 점수(IS) 면에서 CompACT(209.0)가 타겟 토크나이저(186.7)를 앞질렀다는 것인데, 이는 CompACT의 의미론적 인코더가 픽셀 위주의 복원보다 인지적으로 더 중요한 특징들을 잘 보존하고 있음을 시사합니다.
다음은 tokenizer에 대한 ablation study입니다.

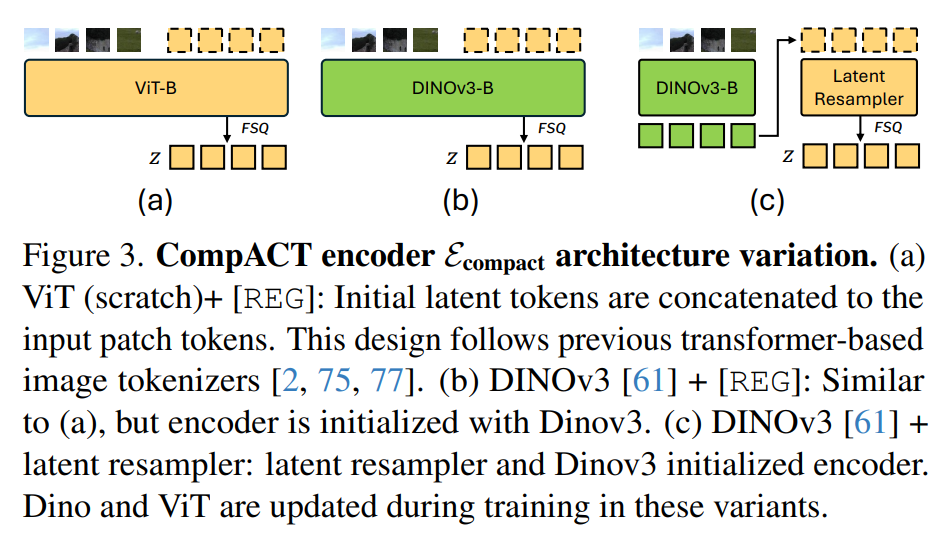
저자들은 인코더 아키텍처를 세 가지 변이(ViT-B를 각각 스크래치 학습, DINOv3 파인튜닝, DINOV3와 리샘플러 모두 학습, DINOv3 고정된 특징+리샘플러 학습)로 나누어 실험을 진행하였다고 합니다. 우선 DINOv3와 latent resampler를 전체 파인튜닝했을 때 rFID 가 5.22로 오히려 크게 악화되는 현상을 발견했습니다.
이는 파인튜닝 과정에서 모델의 표현이 reconstruction 위주의 저수준 특징으로 치우치면서, 생성적 디코딩에 필수적인 고수준 의미 정보가 손실되기 때문인 것으로 저자들은 분석합니다. 또한 생성적 디코딩 대신 단일 단계의 피드포워드 디코더를 사용할 경우 rFID 가 28.80으로 오르는 등 심각한 성능 저하가 발생했습니다. 저자들은 해당 결과를 통해 압축된 토큰이 담고 있는 추상적인 의미로부터 세밀한 시각적 디테일을 ‘상상’해내는 \mathcal{D}_{compact} 의 역할이 중요함을 주장합니다.

CompACT의 잠재 토큰이 무엇을 학습했는지 시각화한 결과는 위와 같습니다. 위의 그림은 잠재 리샘플러의 어텐션 맵이 강조하는 영역을 시각화한 것으로, 각 압축 토큰이 이미지 내에서 의미론적으로 일관된 특정 영역에 집중하고 있음을 알 수 있습니다
예를 들어 ImageNet에서는 특정 동물 객체에, 항법 데이터셋인 RECON에서는 건물과 같은 구조적 요소에, 그리고 RoboNet에서는 로봇의 End-effector와 조작 대상에 토큰이 할당됩니다. 결국 CompACT는 정보를 이미지 전체에 균일하게 분산시키는 대신, 의사 결정에 중요한 핵심 ‘객체’ 단위로 토큰을 할당함으로써 계획 수립에 최적화된 잠재 공간을 형성하게 됨을 보여준다고 합니다.
Modular latents benefit planning.
저자들은 CompACT의 잠재 토큰이 장면의 구성 요소를 모듈별로 포착한다는 점을 검증하기 위해 두 프레임 사이의 잠재 토큰에서 행동을 예측하는 역역학 모델(IDM)을 훈련했습니다. 실험 결과, CompACT는 단 16개의 토큰만 사용하고도 256개의 토큰을 사용하는 타겟 토크나이저(MaskGIT-VQGAN)보다 더 높은 결정계수( R^2 )인 0.716을 기록하며 우수한 행동 복원력을 보여주었습니다.

더 적은 양의 토큰만을 사용함에도 불구하고 유사하거나 더 높은 성능을 보여준 이유에 대하여, 저자들은 CompACT가 이미지의 모든 픽셀을 공평하게 다루는 대신, 로봇의 말단 장치나 조작 대상처럼 행동과 직결된 ‘움직이는 객체’에 토큰을 우선적으로 할당하여 역학 정보의 밀도를 높였기 때문이라고 주장합니다.
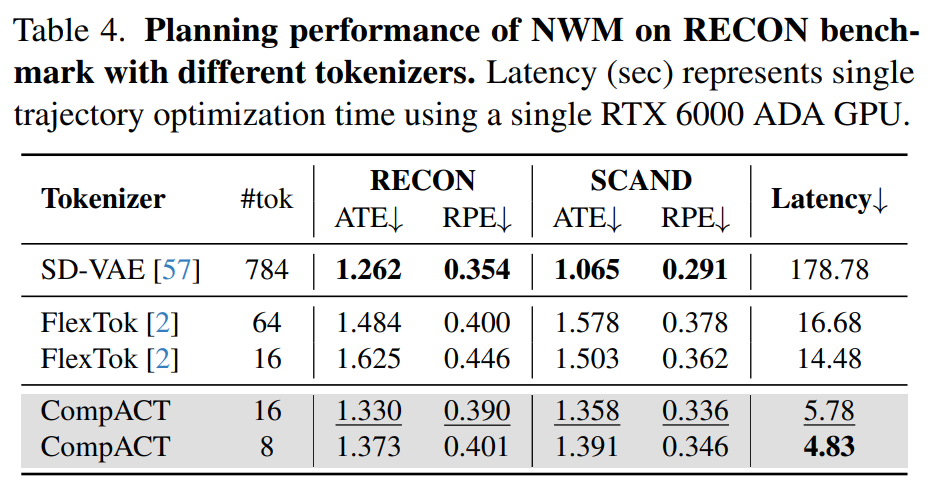
네비게이션에 관한 성능 표는 위의 표4에서 확인이 가능합니다. 784개의 토큰을 사용하는 기존 SD-VAE 기반 world model (NWM)과 비교했을 때, CompACT는 계획 정확도(ATE/RPE) 면에서 대등한 수준을 유지하면서도 latenc를 약 40배 단축시켰습니다.
구체적으로 SD-VAE가 한 에피소드의 경로를 찾는 데 178.78초가 걸린 반면, CompACT(16토큰)는 단 5.78초 만에 동일한 작업을 수행했습니다. 특히 비용 함수를 픽셀 공간이 아닌 잠재 공간에서 직접 계산할 경우, SD-VAE 대비 최대 80배의 속도 향상을 달성하며 실시간 제어의 가능성을 열었습니다.
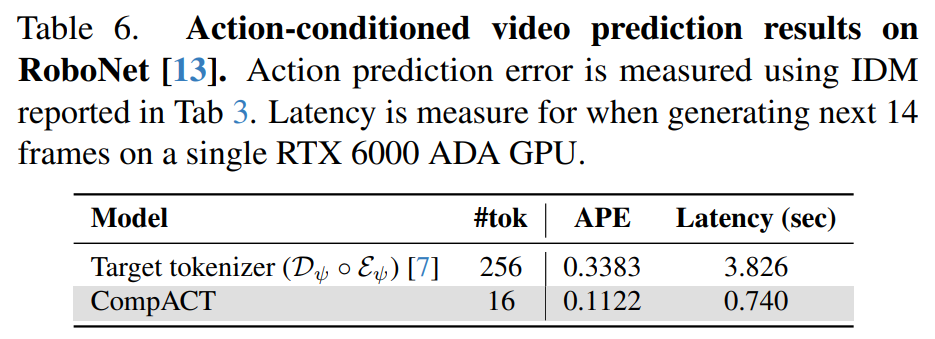
로봇 조작(Manipulation) 성능을 평가하는 비디오 예측 실험에서도 CompACT이 빠르고 효율적인 모습을 보여주는데, 아래 표를 살펴보시면 RoboNet 데이터셋에서 CompACT는 256개 토큰을 사용하는 베이스라인 대비 행동 예측 오차(APE)를 3배나 낮추었으며, 프레임 생성 속도는 5.2배 더 빨랐습니다.
아래 정성적 결과에서도 CompACT 기반 세계 모델은 행동 지시에 따른 로봇 팔의 움직임을 일관성 있게 유지한 반면, 타겟 토크나이저 기반 모델은 행동과 무관한 프레임을 생성하는 등 역학 이해도가 떨어지는 모습을 보였습니다.

마지막으로, 아래 설계 선택에 대한 ablation study를 통해 저자들은 세 가지 핵심 성공 요인을 정리했습니다.
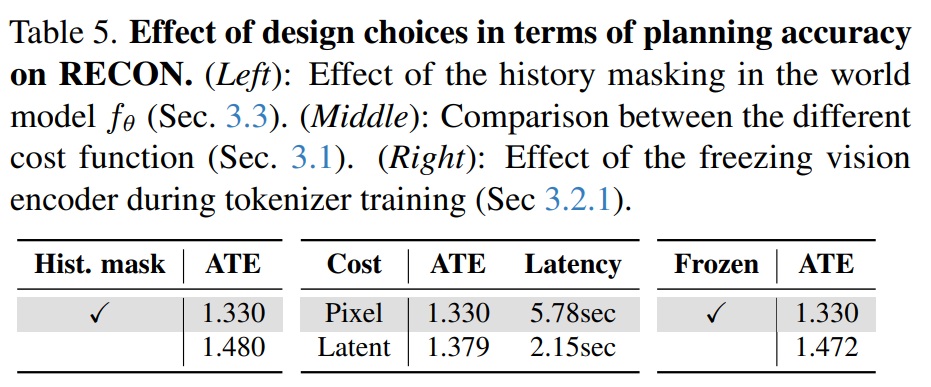
첫째, 세계 모델 학습 시 히스토리 마스킹을 적용하는 것이 시간적 의존성을 학습하는 데 도움을 주어 정확도를 높였다고 합니다. 둘째, 픽셀 단위의 복잡한 연산 없이 FSQ의 기하학적 구조를 이용한 잠재 공간 거리 계산이 오차 값은 미미하면서도 추론 속도는 크게 개선시켰다고 합니다. 셋째, 인코더 학습 시 비전 파운데이션 모델을 고정한 상태로 유지하는 것이 계획에 필수적인 의미 정보를 보존하는 데 결정적인 역할을 했습니다. 3번째 결과는 앞서 reconstruction에 대한 ablation study에서도 확인했다시피, DINOv3를 fine-tuning 할 경우 future state에 대한 reconstruction objective에 모델의 표현력이 이동되기 때문에 planning을 위한 고수준의 의미론적 정보들이 손실될 수 있다고 주장합니다.
Conclusion
본 논문의 주저자 분이 KAIST 포닥을 하고 계시는 분인데 연구를 참 잘하시는 분인 듯 합니다. 그리고 논문의 컨셉인 “행동 계획에는 사진 같은 정밀함보다 추상화된 의미의 파악이 더 중요하다” 부분이 누구나 한번쯤은 생각해볼 법한 부분들이라고 생각하는데 이를 여러 SOTA 방법론들의 모델 구조와 학습 방식을 잘 채택하여서 의도한대로 결과를 보였다는 점에서 인상깊었습니다. 해당 논문이 CVPR에 게재되는지라 main paper에 담지 못한 많은 내용들을 supple에서 담고 있으니 관심있으신 분들은 한번 supple까지 읽어보시는 것을 추천드립니다.