안녕하세요. 이번에 소개할 논문은 멀티모달 LLM을 범용 멀티모달 임베딩 모델로 확장하려는 연구입니다. 최근 MLLM을 단순 생성 모델이 아닌 임베딩 모델로도 활용하는 연구가 많이 늘고 있습니다. 저도 비디오 리트리벌 연구에서 MLLM을 활용하는 방향을 고민하고 있던 중, 제가 구상하던 아이디어와 유사한 접근을 제안한 본 논문을 발견하게 되어 소개하게 되었습니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
멀티모달 임베딩 모델은 텍스트와 이미지, 오디오 등 다양한 모달리티의 데이터를 하나의 통합된 dense representation 공간에 정렬시키는 것을 목표로 합니다. 이를 통해 visual question answering, multimodal retrieval, compositional reasoning 등 다양한 다운스트림 태스크를 하나의 표현 공간에서 해결하려는 흐름이 이어지고 있습니다. 최근에는 이러한 통합 표현을 학습하는 방식 자체가 하나의 주요 연구 분야로 자리잡고 있으며, 점점 더 좋은 backbone과 학습 전략이 제안되고 있는 상황입니다.
한편, 최근 LLM은 MTEB와 같은 텍스트 임베딩 벤치마크에서 기존 encoder-only 모델 보다 좋은 성능을 보이며 representation learning의 새로운 가능성을 제시했습니다. 이를 시작으로 최근에는 Multimodal Large Language Models(MLLMs)를 활용해 범용 멀티모달 표현을 학습하려는 시도를 이어가고 있습니다.
대표적으로,
- E5-V는 MLLM의 언어 구성 요소를 sentence-pair contrastive learning으로 보강하여 cross-modal alignment를 개선하려 했고,
- VLM2Vec은 MMEB 벤치마크를 제안하며 기존 vision-language 모델을 임베딩 모델로 재활용하는 프레임워크를 제시했습니다.
- QQMM은 InfoNCE gradient를 분석하여 hard negative에 대한 gradient를 스케일링하는 전략을 도입했고,
- UniME는 LLM 기반 teacher를 활용한 2-stage knowledge distillation과 hard negative sampling 전략을 제안했습니다.
이러한 방법들은 모두 더 구분력 있는 임베딩을 만들기 위한 시도라고 볼 수 있습니다. 그러나 여기에도 여전히 중요한 한계가 존재합니다.
기존 방법들은 공통적으로 contrastive learning을 기반으로 임베딩을 학습하며, hard negative를 강조하긴 하지만, 후보 간의 세밀한 semantic 차이를 충분히 반영하지 못하고 있습니다. 대부분의 contrastive 학습은 여전히 one-positive vs many-negatives 구조를 따르며, 후보 간의 의미적 연속성을 고려하지 못한 채 이분법적으로 정답/오답을 구분합니다.
특히 실제 retrieval 환경에서는,
- 겉보기에는 유사하지만 미묘하게 다른 hard negative,
- 부분적으로는 맞지만 완전한 정답은 아닌 false negative,
가 혼재되어 있습니다.
그러나 기존 학습 방식에서는 이러한 차이를 정교하게 반영하지 못하며, raw embedding 자체만으로는 hard negative와 false negative를 안정적으로 구분하기 어려운 경우가 많습니다. 결국 문제의 핵심은 후보들 사이의 의미적 차이를 어떻게 더 세밀하게 반영할 것인가에 달려있습니다.
이 문제를 해결하기 위해, 본 논문에서는 UniME-V2를 제안합니다. 핵심 아이디어는 MLLM의 이해 능력을 단순 생성이 아닌 판단자(Judge)로 활용하는 것입니다. 구체적으로는 다음과 같은 흐름을 따릅니다.
- 먼저 global retrieval을 통해 잠재적 hard negative 집합을 구성합니다.
- 이후 MLLM-as-a-Judge를 활용하여 query-candidate 쌍의 semantic alignment를 평가하고, 의미적 매칭 점수를 생성합니다.
- 이 점수를 기반으로 hard negative를 정제함으로써 false negative의 간섭을 줄이고, 보다 다양하고 질 높은 negative를 확보합니다.
- 동시에 해당 점수를 soft label로 활용하여 similarity matrix가 semantic score distribution과 정렬되도록 학습합니다.
즉, 기존의 “정답 vs 오답” 구조에서, 후보 간 의미적 연속성을 반영하는 분포 정렬(distribution alignment) 방식으로 전환하는 것입니다. 추가적으로 저자는 UniME-V2-Reranker를 제안합니다. 이는 mining한 hard negative를 활용하여 pairwise와 listwise를 결합한 방식으로 학습된 reranking 모델입니다.
정리하자면, 본 논문의 contribution은 다음과 같습니다.
- MLLM-as-a-Judge를 활용하여 semantic alignment를 평가하고, 이를 기반으로 hard negative mining을 수행하는 새로운 파이프라인을 제안
- semantic matching score를 soft label로 활용하는 distribution alignment 기반 학습 프레임워크를 통해, 후보 간 의미 차이를 효과적으로 반영하는 UniME-V2를 제안
- pairwise + listwise 최적화를 결합한 UniME-V2-Reranker를 제안
- MMEB 및 다양한 retrieval 설정에서 광범위한 실험을 통해 평균 SOTA 성능을 입증
구체적인 설계와 학습 파이프라인은 방법론 파트에서 더 자세히 살펴보겠습니다.
2. Methodology
2.1 Task Definition
기존 CLIP은 모달리티마다 encoder를 사용하지만 본 논문에서는 MLLM의 unified architecture를 그대로 활용해 여러 모달리티의 임베딩을 추출합니다.
구체적으로, 하나의 query q와 후보 집합 Ωc={c1,…,cn}가 주어집니다. 이 후보들은 텍스트, 이미지, 혹은 interleaved image-text 데이터일 수 있습니다.
먼저 universal embedding 모델 Φemb이 query와 후보들을 임베딩 공간으로 인코딩합니다. 이후 cosine similarity 기반으로 상위 k개 후보 Ωk를 선택합니다.
그 다음, 검색 성능을 향상시키기 위해 reranker 모델 Φrank가 이 상위 k개 후보를 다시 정렬하여 최종 결과를 생성합니다. Ωk=Φrank(q,Ωk)
즉, 1차로 임베딩 기반 검색을 수행하고, 2차로 reranking을 통해 정확도를 높이는 구조입니다
2.2 MLLM-as-a-Judge for Hard Negatives Mining
기존 방법들에서는 대부분 in-batch hard negative mining을 사용합니다. 즉, query-candidate embedding similarity를 계산한 뒤 그 중 어려운 negative를 고르는 방식입니다.
하지만 여기에는 두 가지 한계가 있습니다.
- negative 다양성이 부족하다
- 임베딩 자체의 변별력이 충분하지 않아 false negative와 hard negative를 잘 구분하지 못한다
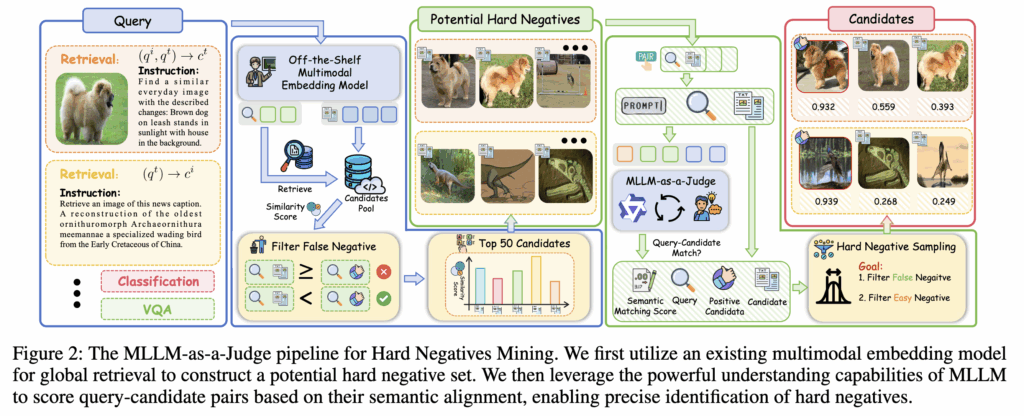
이러한 문제를 해결하기 위해 그림2에 나와 있는 것처럼 먼저 전역 검색(global retrieval)을 통해 잠재적 hard negative 집합을 구성합니다. 이후, MLLM을 활용하여 각 쿼리-후보 쌍의 의미적 정합성을 평가하고, soft semantic matching score를 생성합니다. 이 점수를 기반으로 hard negative를 정제함으로써 false negative의 영향을 줄이고, 다양하고 품질 높은 hard negative를 구성합니다.
(1) Potential Hard Negative Set
그럼 그림2 과정을 더 자세하게 설명드리면 먼저 global retrieval을 수행합니다.
이는 VLM2Vec을 사용해 query와 모든 candidate에 대해 embedding을 만들고, 상위 50개를 가져옵니다.
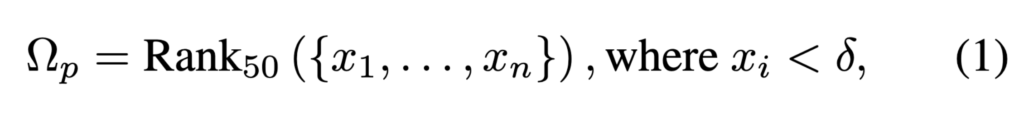
이때 similarity threshold δ를 적용해 너무 유사한 후보(positive에 가까운 false negative)를 일부 걸러냅니다. 이렇게 얻은 집합이 potential hard negative set Ωp입니다.
(2) Semantic Matching Score
hard negative 집합 Ωp가 구성된 이후, MLLM을 Judge로 활용하여 각 쿼리-후보 쌍의 의미적 정합성 점수를 계산합니다.
사용되는 프롬프트는 다음과 같습니다:

이후 Yes 토큰의 logit (ey)과 No 토큰의 logit (en)을 이용해 semantic matching score를 계산합니다.
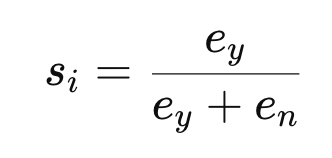
이를 통해 각 쿼리-후보 쌍에 대해 의미적 정합성 점수 S={s1,…,sm}를 얻습니다.
(3) Hard Negative Sampling
이제 semantic matching score를 이용하여 hard negative를 정제합니다. false negative는 해당 점수가 임계값 α=σq,ct−β를 초과하는 경우 제거합니다. 여기서 ct는 positive 샘플이며, β=0.01은 마진을 조절하는 하이퍼파라미터입니다.
이후 다양성을 유지하기 위해 5-step 간격의 cyclical sampling 전략을 적용합니다. 만약 정제된 후보가 10개 미만일 경우, 최소 10개를 맞추기 위해 중복을 허용하고 조건을 만족하는 후보가 하나도 없는 경우에는, 초기 50개 중에서 랜덤으로 10개를 선택하고 각 후보의 semantic score를 1.0으로 설정합니다.
최종적으로 각 쿼리 q에 대해 hard negative 집합 Ωh={c1,…,ck}과 그에 대응하는 semantic matching score Sh를 얻습니다.
2.3 MLLM Judgment Based Training Framework
이제 이 semantic score를 어떻게 학습에 활용하는지 보겠습니다. 기존 연구들은 one-to-one 매핑에 기반한 contrastive 학습을 사용하며, 이는 다양한 negative 간의 세밀한 차이를 학습하는 데 한계가 있습니다. 이를 해결하기 위해 저자는 semantic matching score를 soft label로 활용하는 distribution alignment 기반 학습 프레임워크를 제안합니다.
먼저 쿼리 q와 후보 집합 Ωc={ct,c1,…,ck}를 MLLM에 입력하고, 마지막 토큰을 임베딩으로 추출합니다.
- 쿼리 임베딩: eq
- 후보 임베딩: Ec={ec+,ec1−,…,eck−}
이후 임베딩 기반 유사도 분포는 다음과 같이 계산됩니다:
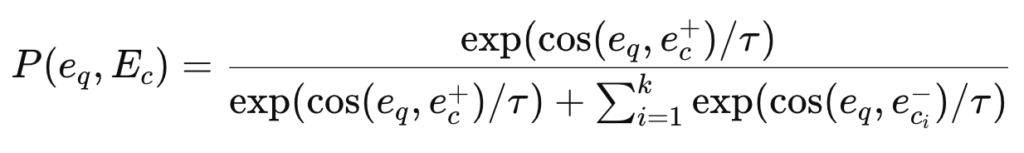
그리고 semantic score 기반 분포는 다음과 같습니다:
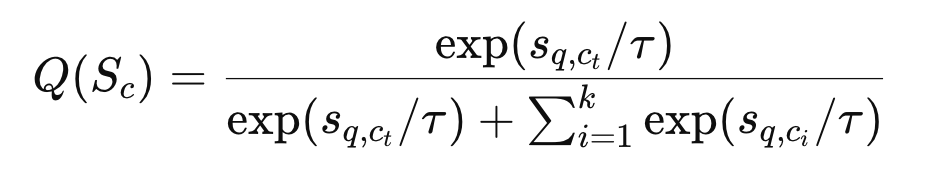
이제 두 분포 간 차이를 줄이기 위해 KL divergence의 대칭 형태인 JS divergence를 사용합니다. 최종 loss는 다음과 같습니다:
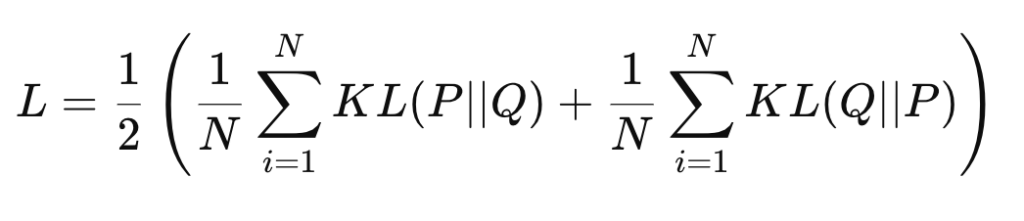
UniME-V2-Reranker
다음으로 reranker 학습 방식에 대해 설명드리겠습니다. reranker는 Pairwise와 Listwise두 가지 방식으로 학습합니다.
먼저 Pairwise 학습에서는 쿼리 q와 positive ct, hardest negative ch를 각각 조합하여, positive에는 YES, negative에는 NO를 출력하도록 학습합니다.
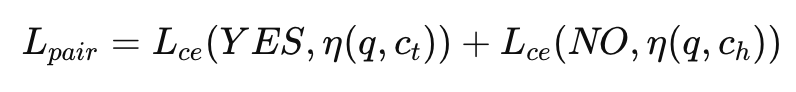
그리고 Listwise 학습에서는 hard negative 중 상위 x개를 선택하고, 정답 후보를 랜덤 위치에 삽입한 뒤 그 위치를 맞추도록 학습합니다.
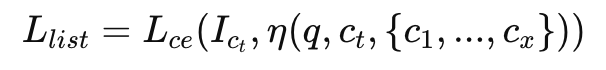
그리고 최종 loss는 두 loss의 합으로 구성이됩니다.
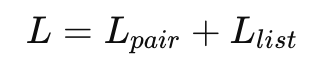
Inference Pipeline
마지막으로 추론 시에는 UniME-V2와 UniME-V2-Reranker를 결합하여 사용합니다.
- UniME-V2로 쿼리와 후보를 임베딩하고 cosine similarity 기반으로 상위 10개 후보를 검색
- UniME-V2-Reranker가 다음 프롬프트에 따라 이 후보들을 다시 정렬:

이를 통해 최종 검색 결과를 추출하게 됩니다.
3. Experiments and Results
3.1 Implementation
먼저 실험 세팅을 간단히 살펴보겠습니다.
Hard negative 후보를 구성하기 위해, 저자들은 VLM2Vec (Qwen2-VL-7B 기반)으로 쿼리와 후보의 임베딩을 추출합니다. 이후 semantic matching score는 Qwen2.5-VL-7B를 Judge로 사용해 생성합니다. 그리고 UniME-V2는 Qwen2-VL, LLaVA-OneVision 두 가지 MLLM 백본을 사용하여 학습합니다.
3.2 Main Results
Multi-Modal Retrieval
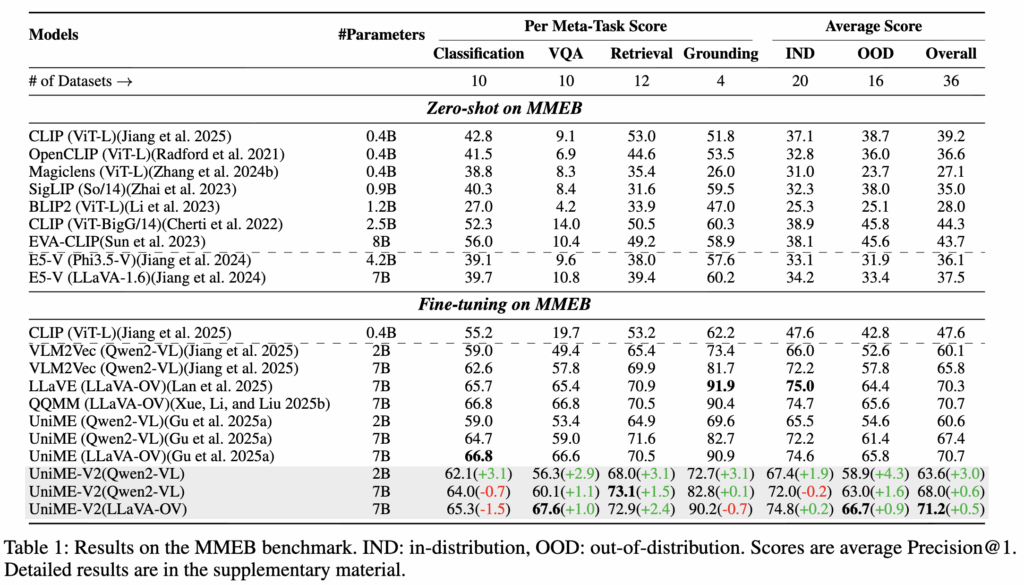
표 1은 UniME-V2를 기존 베이스라인 모델들과 비교한 멀티모달 검색 성능 결과입니다. 전반적으로 UniME-V2는 다양한 foundation 모델 위에서 일관되게 성능 향상을 보이고 있습니다. 특히 Qwen2-VL-2B와 7B 기반에서는 각각 VLM2Vec 대비 3.5%, 2.2%의 개선을 달성했습니다.
LLaVA-OneVision 기반 실험에서도 QQMM, LLaVE, UniME 같은 기존 SOTA 모델 대비 0.5%–0.9% 정도 더 높은 성능을 기록하고 있습니다.
Short & Long Caption Cross-Modal Retrieval
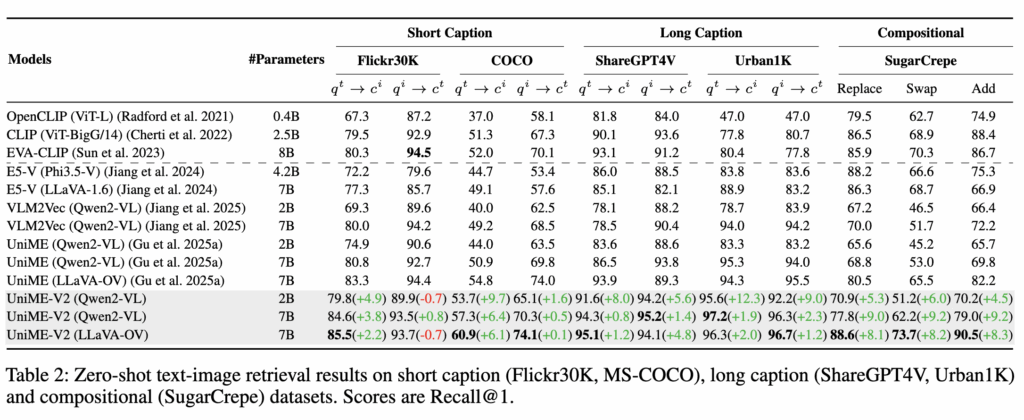
다음은 제로샷 설정에서 크로스모달 검색 성능도 함께 평가하고 있습니다. 짧은 캡션 기반 데이터셋(Flickr30K, MS-COCO)에서는 image-to-text 검색에서 UniME 대비 2.2%–9.7%의 성능 향상을 보였습니다. 반면 text-to-image에서는 성능 차이가 크지 않습니다. 저자들은 그 이유로 두 가지를 들고 있습니다.
- MMEB 학습 세트에서 text-to-image 데이터 비중이 상대적으로 적고
- 짧은 캡션 자체가 담고 있는 semantic 정보가 제한적이기 때문
즉, 모델의 한계라기보다는 학습 분포와 데이터 특성의 영향이라고 해석할 수 있습니다.
반면 긴 캡션 기반 검색(ShareGPT4V, Urban1K)에서는 확실한 개선을 보입니다. 이는 UniME-V2가 후보 간 세밀한 의미 차이를 더 잘 구분한다는 점과 연결됩니다. 캡션이 길수록 semantic 정보가 풍부해지는데, 이때 distribution alignment 기반 학습이 더 큰 개선을 보이는 것으로 저자는 해석하고 있습니다.
Reranking Comparison
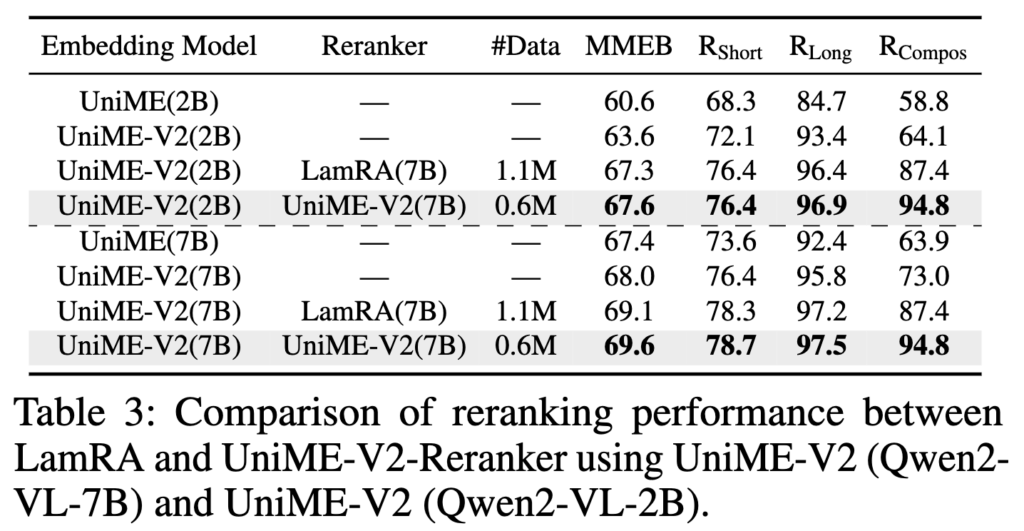
표 3은 LamRA와 UniME-V2-Reranker의 비교입니다. 실험에서는 동일한 베이스(Qwen2.5-VL-7B), 동일한 학습 파라미터를 사용해 비교했습니다. 결과에서는 UniME-V2-Reranker가 절반의 데이터만 사용하면서도 LamRA보다 일관되게 높은 성능을 보인다고 합니다. 이는 단순히 reranking 구조의 차이보다는, 학습 단계에서 이미 MLLM 기반 semantic score로 hard negative를 정제해두었기 때문에 reranker가 더 질 좋은 학습 신호를 받았기 때문으로 저자는 해석하고 있습니다.
3.3 Analysis
Ablation on Different Components
다음은 Ablation 결과입니다.
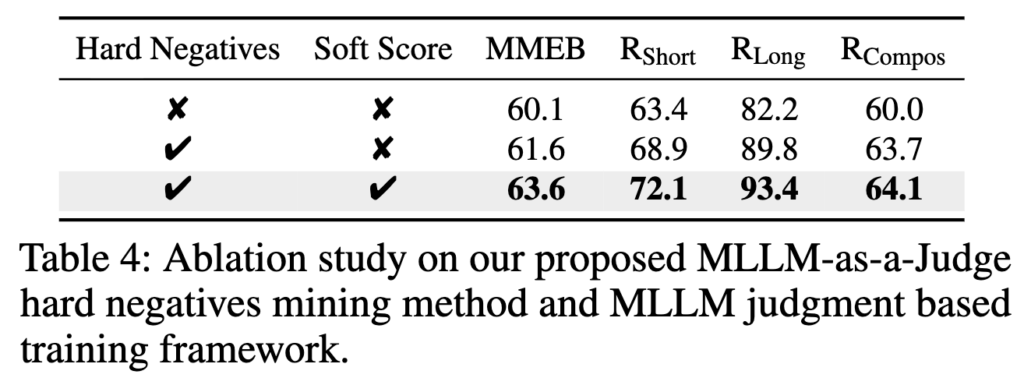
표 4에서는 UniME-V2의 구성 요소에 대한 어블레이션 결과를 보여주고 있습니다. 여기서는 Qwen2-VL-2B를 기반으로,
- MLLM-as-a-Judge 기반 hard negative mining
- MLLM judgment 기반 distribution alignment 학습
이 두 요소의 효과를 각각 분리해 분석합니다.
먼저 기존의 direct contrastive learning과 비교하면, 제안한 hard negative mining만 추가해도 성능이 전반적으로 상승합니다. 특히 long retrieval에서 개선 폭이 큰데, 이는 단순 거리 기반 negative 선택 대신 semantic score를 활용한 정제가 긴 문맥에서 더 효과적으로 작동한다는 것으로 볼 수 있습니다.
여기에 MLLM judgment 기반 학습 프레임워크를 추가하면 성능이 더 올라갑니다. 이는 단순히 hard negative를 더 잘 고르는 데서 끝나는 것이 아니라, 그 semantic score를 분포 정렬(distribution alignment) 형태로 학습에 직접 반영했다는 점으로 후보 간의 미세한 의미 차이를 embedding 공간에 구조적으로 반영했을때 성능이 향상된다는 것을 알 수 있습니다.
Ablation on Different MLLM-based Judges
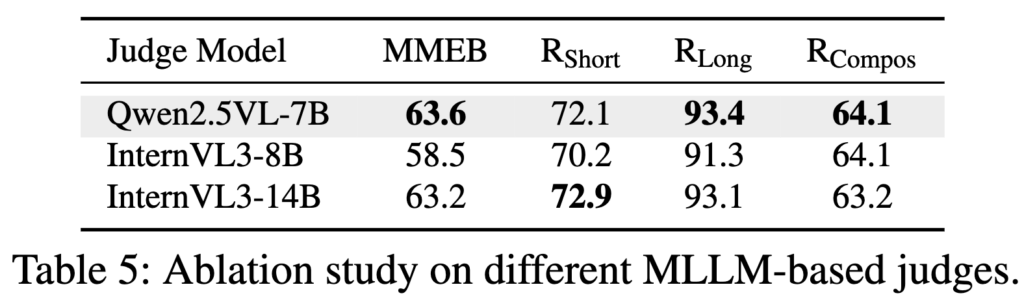
표 5에서는 Judge로 사용하는 MLLM의 성능 차이를 분석합니다. Qwen2.5-VL-7B, InternVL3-8B, InternVL3-14B를 비교했을 때, 동일한 설정에서 Qwen2.5-VL이 가장 높은 성능을 보입니다. InternVL3-14B는 8B보다 개선되지만, 여전히 Qwen2.5-7B보다 약간 낮은 성능을 보입니다. 저자들은 이를 SFT 단계에서 사용된 instruction 데이터 분포 차이 때문이라고 설명하고 있습니다.
Qualitative Results
마지막으로 정성적 결과를 보고 마무리 하겠습니다.
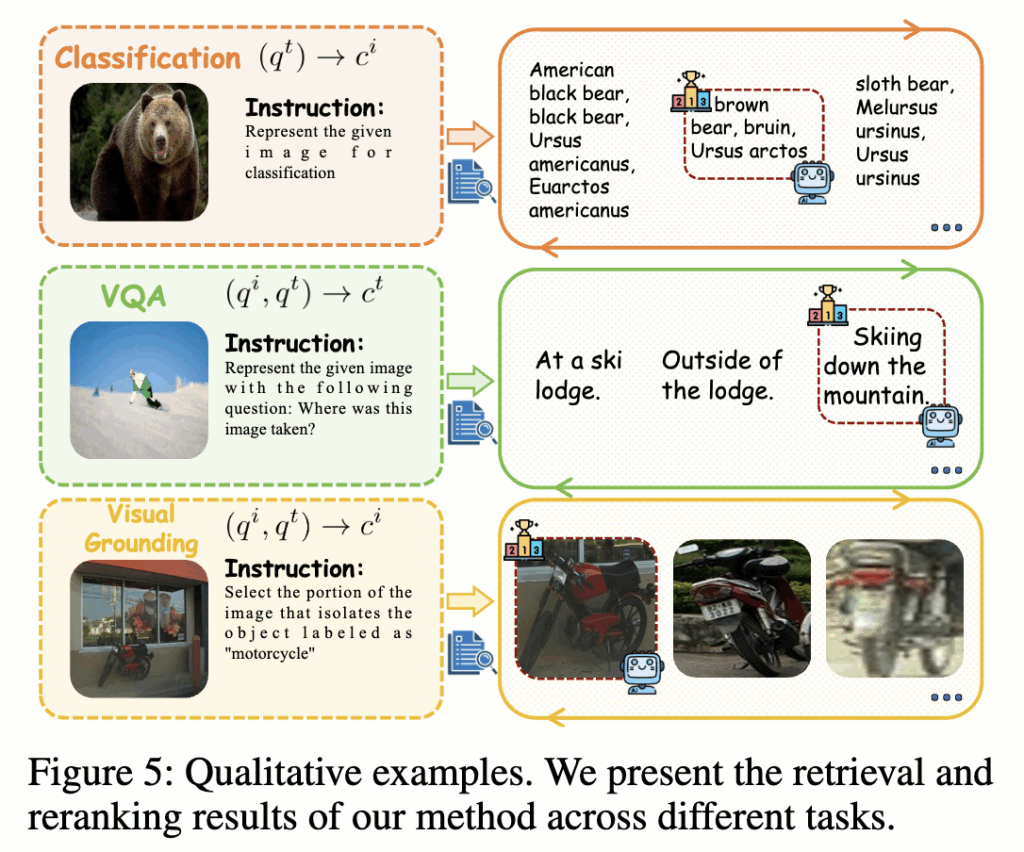
UniME-V2의 retrieval 결과와, UniME-V2-Reranker가 재정렬한 Top-1 후보를 시각화한 모습입니다. 예시에서 “black bear”와 “brown bear”처럼 의미적으로 유사하지만 구분이 필요한 후보들을 모두 상위로 가져온 뒤, reranker가 “brown bear”를 최종 선택하는 모습을 볼 수 있습니다.