안녕하세요, 이번 주 x-review는 Open-Helix 팀에서 VLA 모델을 ‘성능이 어떠냐’ 보다 ‘현실에 올릴 수 있는가’의 관점에서 다룬 논문을 소개하려고 합니다. 저자들은 로봇을 현실에 배치하려면 general한 mobile manipulation이 가능해야 하고, 지금의 VLA는 왜 불가능한지, 벤치마크는 어때야 하는지를 고찰하고 새로운 벤치마크를 제안했습니다. 그 고찰을 바탕으로 작지만 강한 VLA도 설계했는데요, 저자들은 작은 VLM 기반으로도 충분히 강인한 policy를 만들 수 있다고 보고있다고 합니다. 리뷰 시작하도록 하겠습니다.
Introduction
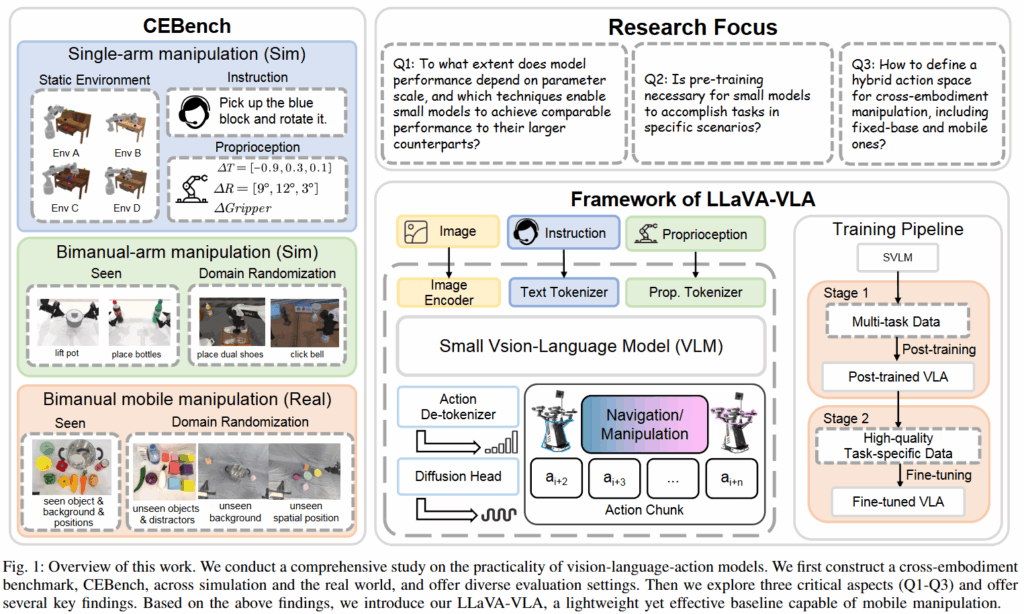
로봇 조작에서 실세계의 일반화를 이루는 것은 이제는 오래된 도전 과제가 됐습니다. 아직까지 이렇다 할 엄청난 연구는 등장하지 않았는데요, 저자들은 최근 VLA가 end-to-end로 멀티모달 입력을 받아 행동을 생성하는 일반 목적 로봇 에이전트로 자리 잡았음에도, 실제 로봇 시스템에 탑재되어 여기저기 배치되기에는 병목이 여전하다고 합니다. 저자들은 그 병목을 세 가지로 정의했습니다. 첫째, 기존 VLA는 파라미터가 B단위로 커서 모바일 플랫폼이나 소비자급 (보통 rtx 시리즈 말하는 것 같습니다) 디바이스 같은 자원 환경에서 배치가 어렵다고 합니다. 둘째로는 대규모 로봇 데이터로 광범위한 사전학습을 요구하는 경향이 많아서 학습 비용과 컴퓨팅 요구량이 과도한 것 또한 문제라고 합니다. 마지막으로는 고정된 base 중심의 manipulation 때문에 cross-embodiment 배치, 특히 현실에서 고려돼야 하는 mobile manipulation으로 확장되기 어렵다고 봤습니다. 이렇게만 쓰고 보니 generalist AI에서 말하는 “모델은 더 커져야 하고 더 많은 데이터를 수용해야한다” 와는 상반되는 이야기인 것 같습니다.
TinyVLA, MiniVLA, NORA, SmolVLA 와 같은 lightweight VLA들이 이미 있었지만, 저자들은 경량화만 생각하는게 아니라 경량 설계가 어떻게 큰 모델들과 비빌 수 있는지, 사전학습이 VLA에서 정말 필수인지, mobile platform까지 포함하는 통합된 action space가 어떻게 정의되어야 하는지에 대한 체계적인 검증이 부족했었다고 합니다. 무엇보다 이들 중 mobile manipulation을 수행할 수 있는 모델은 없다고 하빈다.
정리하자면 저자들은 연구를 진행하면서 크게 세 가지 research focus를 가지고 진행했습니다.
Q1. 모델 성능이 파라미터에 의존하는 부분은 어떤 요소들인가?
Q2. specific scenario에서 동작하는 작은 모델에도 pre-training이 필수적일까?
Q3. fixed-base와 mobile manipulation을 아우르는 cross-embodiment manipulation을 위한 action space는 어떻게 정의해야할까?저자들은 위 질문들에 답하기 위해 CEBench라는 cross-embodiment 벤치마크를 실험적으로 정리한 다음, 결론들을 근거로 LLaVA-VLA라는 baseline을 구축했습니다. 하나씩 살펴보도록 하겠습니다.
CEBench
기존의 벤치마크들은 mobile, sim, real, domain randomization등 각 수요에 맞게 다 개별적으로 존재했는데요, 저자들은 현실에서의 실용적인 수요를 생각해서 이들을 전부 포함하는 벤치마크를 정의해야 한다고 합니다. 따라서 single arm manipulation에는 CALVIN을 그대로 가져오고, bimanual은 Sapien 기반의 RoboTwin을 가져왔다고 합니다. 여기에 더불어 cobot-magic 로봇을 사용해 현실 벤치마크를 구성했다고 합니다. Task의 경우 접시 쌓기, 버튼을 눌러 종치기, target container에 야채 두기, 두 팔로 pot 들어올리기 입니다. Task는 비교적으로 간단한 task들로 구성된 것 같습니다. Mobile manipulation의 평가를 위해서는 멀리 있는 bottle 가져오기, 멀리있는 drawer 열기로 구성했다고 합니다. 이 때 Robotwin의 seen 환경에서의 평가에서 끝나지 않고, 다양한 domain randomization을 추가했다고 합니다. 이를 현실에서도 재현하기 위해 다양한 물체 위치나 방해물들을 활용해서 벤치마크를 구성했다고 합니다. 베이스라인으로는 ACT, DP, Tiny VLA, RDT를 사용했습니다. 저자들은 LLaVA-VLA를 제안하고 해당 벤치마크 내에서 Fig1의 research focus에 집중해 다양한 study를 진행했습니다.

LLaVA-VLA
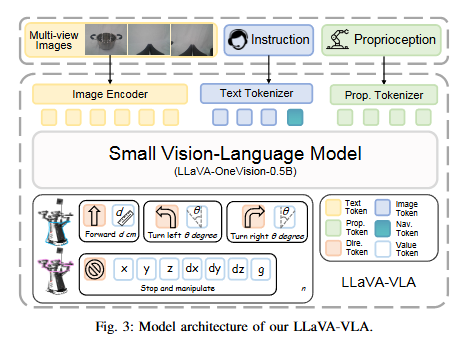
저자들이 제안한 lightweight VLA인데요, 기본적으로 LLaVA-OneVision-0.5B를 베이스로 합니다. 특이한 점이라면 Instruction Tokenizer에 Navigation 토큰을 따로 쓰는것과 multiview Images를 처리하는 방식이 각각 인코딩 후 concat하는게 아니라 합친 채로 넣어주는 것, 또 output 토큰을 어느 방향으로 어떻게 움직여야 하는지, 멈춘 뒤 manipulating에 필요한 action값들은 어떻게 되는지가 나뉘어진 mobile manipulation을 고려한 설계가 되어있습니다. Direction과 Action으로 나뉘어져있습니다. 자세한 설계 구조는 이후에 조금 더 다루도록 하겠습니다.
Key Findings
저자들은 LLaVA-VLA를 제안하고, CEBench 내의 실험을 통해 실제 로봇에 탑재할 실용성이 있는 작은 모델들에 대해서 분석적인 내용을 담았습니다.
Key Findings 1: Small VLAs can achieve performance comparable to their large-scale counterparts.
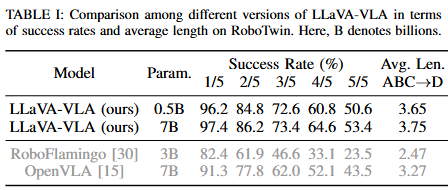
저자들은 Key Findings 1(F1)에서 성능이 파라미터 규모에 꼭 비례하지는 않으며 작은 VLA도 큰 모델과 견줄만한 성능을 낼 수 있다고 주장했습니다. Table 1을 보면 0.5B와 7B 모델을 직접 비교했을 때 엄청난 성능차이가 없는것은 물론이고 기존의 OpenVLA나 RoboFlamingo 보다 우수한 성능을 볼 수 있습니다. 이를 바탕으로 F2~F4에서 LLaVA-VLA의 design choice에 대해서 이야기합니다.
Key Findings 2: Multi-view images are critical as they enable stereoscopic perception of 3D space, and containing multi-view information in 1 image is an effective way
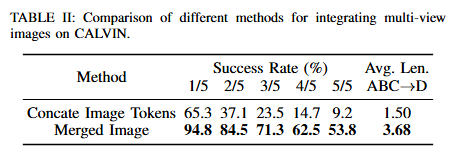
저자들은 F2에서 멀티뷰 입력이 manipulation에서 3D 공간 이해를 가능하게 하는 핵심이며, 특히 멀티뷰를 넣는 방식이 성능을 좌우한다고 주장했습니다. 저자들은 third-person view가 전역 컨텍스트를 제공하고 first-person view가 object-to-gripper의 정밀한 위치 단서를 제공하며, 두 관점이 함께 있을 때 disparity 정보가 생겨 3차원 장면 이해에 유리하다고 합니다. 이건 다른 논문에서는 이런 경우 wrist cam쪽에 과도하게 의존한다고 했던거 같은데 이미지 처리 방법이 달라서 이점을 본 것일 수도 있을 것 같습니다. 저자들은 기존과 같이 view 별로 이미지를 각각 인코딩하고 토큰을 concat하면 토큰 수가 과도해질 뿐 만 아니라 성능이 떨어진다고 합니다. 대신 first/third 이미지를 세로로 붙여 하나의 이미지로 만들어 입력하는 방식을 사용했습니다. Merged Image에서 성능이 훨씬 좋은것을 확인할 수 있습니다.
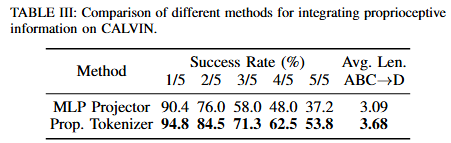
Key Findings 3: Proprioception is critical as it improves understanding of physical states, and tokenizing proprioception works better than encoding them by linear layers.
F3은 proprioception이 물리적인 이해와 행동 연속성 유지에 필수이며, 이를 단순 MLP로 인코딩하는 것보다 토큰화했을 때 성능이 더 오른다는 것입니다. 저자들은 일반적으로 proprioception을 MLP로 임베딩하는 방식이 쓰이지만, proprioception tokenizer를 통해 토큰 시퀀스로 변환하고, 이를 action de-tokenizer의 inverse로 생각할 수 있고, 이로 인해 VLM의 language modeling 능력을 더 직접적으로 활용할 수 있다고 합니다. Table 3을 보면 tokenizer 방식을 사용했을 때 성능이 좋은것을 확인할 수 있습니다
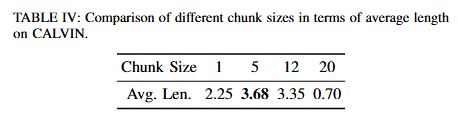
Key Findings 4: Action chunking is critical as it strengthens the model’s planning capability and action stability
F4에서는 action chunking이 planning 능력과 temporal coherence를 강화하는 핵심 설계라는 것을 확인했다고 합니다. 저자들은 action chunk를 예측하게 학습하면 chunk 자체가 모델 내부에서 planning을 위한 단서로 사용되면서 long horizon 작업에서 안정적이라고 합니다. 다만 table4를 보면 알 수 있듯 chunk 단위가 길어지면 오히려 성능이 하락하는 모습을 볼 수 있었습니다. 이건 모델 크기와 연관이 있는지 좀 궁금한데 언급은 없었습니다.
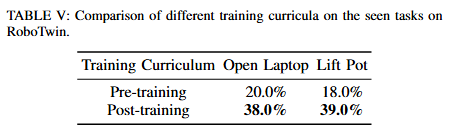
Key Findings 5: Cross-embodiment large-scale pretraining is not essential. Post-training on in-domain multi-task data is sufficient to establish the mapping from vision and language to action
F5에서는 cross-embodiment 대규모 로봇 pre-training은 본질적으로 필수가 아니며, downstream 도메인의 in-domain multi task 데이터로 post-training을 수행한 뒤 task specific한 데이터로 finetuning하는 2 stage 커리큘럼만으로도 vision,language와 action의 매핑을 충분히 학습할 수 있었다고 합니다. 저자들은 cross-embodiment pre-training이 사이사이 껴있는 저품질 샘플과 action space 불일치 때문에 효과가 제한적이고, domain-specific 데이터가 시뮬레이션이든 현실이든 상대적으로 고품질 데모로 구성되기 때문에 멀티태스크 다양성을 확보해 post training을 해야한다고 합니다.
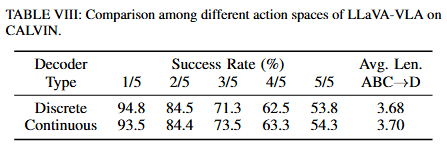
Key Findings 6: Continuous action space in the diffusion head is not indispensable. With action chunking, discrete actions can achieve comparable performance.
F6에서는 action 생성하는 diffusion head의 continuous한 액션 공간이 필수는 아니며, action chunking이 결합되면 discrete action으로 tokenize 해도 괜찮았다고 합니다. 저자들은 많은 VLA가 diffusion head로 정밀하고 continuous한 action을 생성하지만, 이 설계가 모델의 autoregressive한 성질을 훼손해 VLM과 결합할 때 스케일링을 제한할 수 있다고 합니다. Table8에서 실험 내용을 확인할 수 있습니다.
Key Findings 7: Fine-grained action tokenization does not lead to high performance
F7에서는 더 나아가 action tokenization을 fine-grained 하게 만드는 것이 반드시 성능 향상으로 이어지지 않으며, 오히려 더 큰 action space를 맞추기 위한 학습 복잡도가 증가해 효율과 일반화가 떨어질 수 있다고 합니다. 저자들은 직관적으로 생각했을 때 bin 수를 늘리면 작은 차이를 더 잘 포착할 것 같지만, 실제로는 모델이 더 큰 분류 공간을 학습해야 해서 오히려 일반화 쪽에서는 성능이 더 낮았다고 합니다. 실용적인 관점에서는 Table 9를 통해서 bin numbers가 낮은것이 좋은 것 같스빈다.
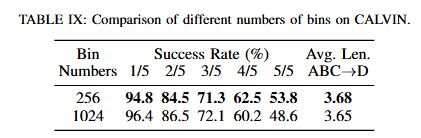
Key Findings 8: The unified action space can be realized through a combination of direction token and value token.
F8에서는 mobile manipulation을 위해 navigation과 manipulation을 하나의 VLA 모델이 한 번에 수행한다고 할 때, 이를 위해 direction token + value token 조합으로 navigation을 예측해야 한다고 주장했습니다. 저자들은 navigation을 manipulation과 같은 방식으로 토큰화하려는 직관적 접근을 먼저 시도했지만, 조작 단계에서 로봇이 멈춰있지 않고 갑자기 이동하는 불안전한 모습을 관찰할 수 있었다고 합니다. 따라서 저자들은 navigation 출력 자체를 direction token(forward, turn left, turn right, stop)과 그 뒤의 value token(진행 거리 또는 회전 각도)으로 설계하고, 조작 안정성을 위해 direction이 stop일 때는 manipulation을 위한 value token들을 그 뒤에 이어 붙이는 방식으로 구현했다고 합니다. 또 instruction 뒤에 navigation 토큰을 따로 추가해 navigation이 필요한 task인지 아닌지에 대한 신호를 모델에게 주었다고 합니다. Manipulation 하는 도중에 움직이지 않는 안정성이 부여돼서 Table 10과 같이 성능이 좋아졌다고 합니다.
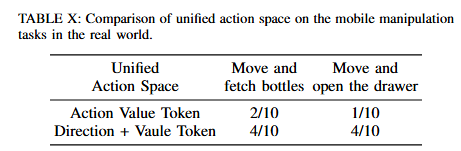
Evaluation
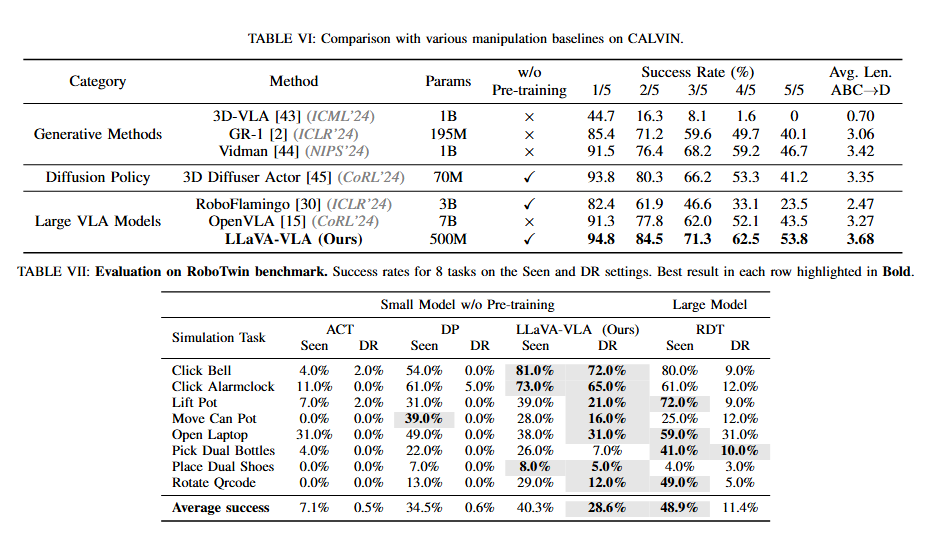
저자들은 LLaVA-VLA를 아래 table 6,7과 같이 비교했는데, single arm 세팅에서 CALVIN을 사용했을 때 0.5B의 파라미터인 모델로 robot data pretraining 없이 아래와 같은 성능을 확인 할 수 있었다고 합니다. 해당 결과들로부터 light model이 복잡한 architeture나 complex한 training이 필요한 모델들 보다 나음을 확인했다고 합니다.
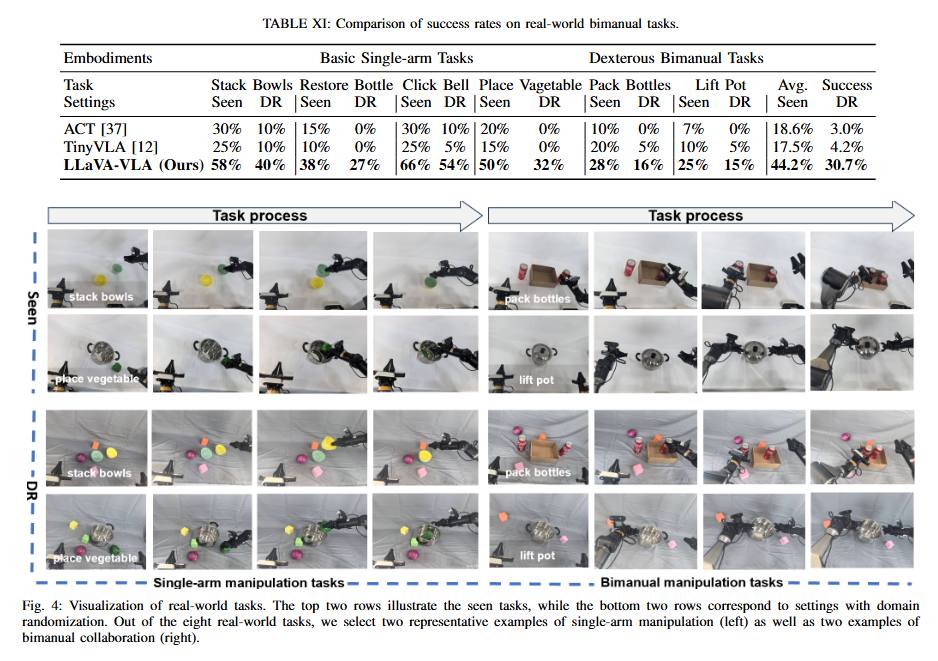
Real world manipulation에서도 ACT, Tiny VLA보다 훨씬 더 뛰어난 성능을 보임을 확인할 수 있었습니다. 특히 mobile manipulation task로 평가했기 때문에 navigation에서 어려움을 보이는 ACT나 Tiny VLA와 달리 안정적인 모습을 보였다고 합니다.
Conclusion
VLA를 실용적인 측면에서 다뤄준 연구이고, 그 과정에서 작은 모델임에도 불구하고 다양한 이점이 있는 모델도 제안이 되었는데, 실제로 다른 환경 강인성이나 큰 모델과의 본질적인 차이, 기타 등등 다루어주지 않은 점에 대해서도 직접 경험해보며 인사이트가 더 쌓여야 할 것 같습니다. 특히 mobile manipulation과 합쳤을 때 데이터 취득을 어떻게 하는지부터 각종 디테일들이 좀 빠져있어서 코드 가지고 이것저것 시도해봐야겠다는 생각이 들기도 했습니다. 아직은 잘 모르겠지만 여기저기 개선점도 많지 않을까?라는 생각이 들기도 하네요
안녕허새요 영규님 좋은 리뷰 감사합니다.
mobile manipulation을 위해 direction token + value token을 쓰는 것 같은데
여기서 value token(진행 거리 또는 회전 각도)의 역할이 forward / left / right / stop로 단순화된 direction 토큰에 더해 미세 위치조정 같은 세밀한 제어를 담당하게되는 것으로 이해해도 되나요? 아니면 다른 개념인건지 궁금합니다.
그리고 이건 논문이랑 상관없는 질문일 수도 있을 거 같은데 보통 real-world benchmark의 데이터 수집 방식과 학습 데이터 규모가 얼마나 되는지 궁금합니다! 특히 mobile manipulation은 fixed-base보다 데이터 수집 비용이 훨씬 클거 같은데 어느 정도의 demo 수집으로 이 정도 성능이 나오는지 궁금합니다.
감사합니다.
안녕하세요 우현님 댓글 감사합니다.
첫 질문은 이해한 방식이 맞습니다. 해당 논문은 task specific한 학습을 진행하기 때문에 하나의 task에 대해서 50~200개 정도의 데모를 수집합니다.
Mobile manipulation같은 경우는 real-world benchmark보다는 대부분 시뮬레이션 환경을 사용합니다. 아마 같은 세트 재현이 힘들기 떄문이 아닐까.. 싶습니다. 시뮬레이션의 데모는 좀 메인 벤치마크 (robocasa)기준 1600시간정도 됩니다
안녕하세요 영규님! 좋은 리뷰 감사합니다.
몇가지 질문이 있어서 답글 남깁니다!
(1) Evaluation 부분에서 robot data pretraining이 없다는 것은 fine-tuning하지 않았다는 의미인가요?
(2) ACT나 TinyVLA처럼 mobile manipulation에 특화되지 않은 VLA와 비교하는 것이 의미가 있는 비교인가요?
(3) 글을 읽다 보니 이 모델은 어떻게 보면 task에 overfitting한 결과를 보일 것 같은데 이것과 관련된 내용은 없었나요?
감사합니다!
안녕하세요 인하님 댓글 감사합니다.
(1) pretraining 절차 없이 scratch 부터 학습했다고 보시면 됩니다.
(2) 저자들의 설계와 다른 기존의 모델들에 데이터 형식만 준 경우와 비교했다고 보시면 됩니다. 저자들의 mobile manipulation 토큰 설계가 유의미하다는 것을 뒷받침하는 실험입니다.
(3) 저자들이 말하는 rethinking the practicality of VLA에서는 왜 굳이 general 해야하나?의 문제정의도 있기 떄문에 한 task만 잘하고 해당 task만 학습한 것이 맞습니다. 저자들은 큰 모델보다 작은 모델이 더 나을 수 있는 세팅이 있고 그게 실용적이라고 주장합니다