최근 LLMs(Large Language Models)을 활용해 다양한 테스크를 수행하기 위해 맞춤형 학습 방법을 제안하는 연구가 활발하게 진행되고 있습니다. LLMs은 대용량의 데이터를 학습하여 상식을 포함한 인간의 추론 능력과 같은 지능이 있다고 여겨지기 때문에, 다양한 분야에 활용하고자 하는 시도가 많습니다. 본 논문은 LLMs의 능력을 Video Summarization 에 활용하는 방법을 소개한 논문입니다. 자세한 리뷰는 아래에서 시작해보겠습니다.
Video Summarizaiton이란?
Video Summaraization은 영어 그대로 비디오를 요약하는 테스크입니다. 이때 요약하는 출력의 형태에 따라 비디오로 요약을 하는 Video-to-Video Summarization과 텍스트로 요약을 하는 Video-to-Text Summarization으로 나눌 수 있는데요, 본 논문에서는 Video-to-Video Summarization(이하 V2V)을 주된 테스크로 하고 있습니다.
최근 연구에서, V2V를 수행하는 일반적인 방식은 다음의 두 가지와 같습니다: 비디오 입력에 대하여 프레임별로 요약된 출력값의 포함 여부를 이진분류하는 방법, 비디오 입력에 대하여 프레임별로 중요도를 예측하여 예산에 맞게 요약될 프레임을 선택하는 방법. 본 논문은 요약된 프레임의 visual feature를 직접 생성하며, 중요도 예측 방법을 이용하여 평가하게 됩니다. 최근 연구에서는 비디오 입력으로 비디오를 요약하는 것 뿐 만 아니라, 오디오 등의 멀티모달리티 정보를 활용하여 맥락적인 정보를 반영한 요약을 하기위한 연구도 활발한데요, 본 연구도 오디오 정보를 활용하는 연구에 속합니다.
정리하면, 본 연구는 비디오와 오디오 정보를 활용하여 단순히 시각적인 중요도가 아닌 맥락을 이해했을 때 중요한 프레임에 대해 선별하는 video summarization을 수행하기 위한 방법을 제안합니다. 특히 LLM을 이용해 이를 해결하고자 하는데, 어떠한 고려를 해야하는지 아래의 내용으로 알아보겠습니다.
왜 Video Summarizaiton을 위한 LLMs 학습 설계가 필요한가?
여러분이 GPT 등을 활용해보시면 Text summarization은 상용화 될 만큼 자연스러운 성능으로 동작하고 있음을 확인할 수 있습니다. 그러나 Video Summarization은 그만큼 자연스럽지는 않습니다. LLMs을 video summarization에 직접적으로 활용하기 어렵게 하는 이러한 한계를 극복하기 위해, 본 논문은 text summarization 등으로 검증된 LLMs의 문맥 이해를 통한 정보 요약 능력을 video summarization에 어떻게 잘 끌어다 쓸 수 있을지에 대한 해결책을 제시합니다. 특히, 그 이유를 테스크 맞춤형으로 학습할 수 있는 대규모의 데이터셋의 부족과 Video Summarization을 수행하는 기존 모델 구조의 한계로 지적합니다. 위와 같은 분석에 따라 빠르게 데이터셋을 수집할 수 있는 프로세스와 이를 통해 습득한 데이터셋(LIVS-P/T)을 공개합니다. 또한 기존 모델의 구조를 변경하여 새로운 모델 구조를 제시합니다.
대규모 데이터셋 구축 방안
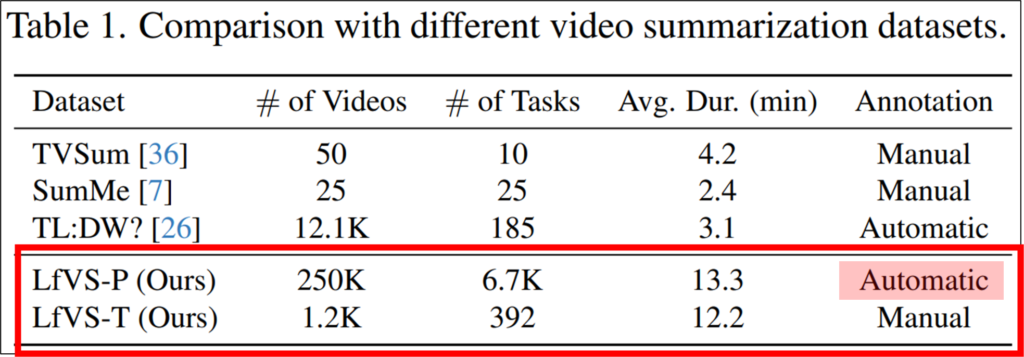
본 논문은 대규모 학습을 위한 데이터의 부족을 해결하기 위해 쉽게 데이터셋을 구축할 수 있는 방법과 해당 방법으로 구축한 데이터셋 LfVS-P, 그를 정제한 테스트 데이터셋인 LfVS-T를 제시합니다. 위의 Tabel1에서 확인할 수 있듯이 기존 학습데이터셋(TVSum, SumMe, TL:DW?)은 비디오의 갯수와 그 길이가 짧습니다. 본 논문은 이러한 한계를 극복하여 더욱 길고 다양한 비디오 데이터로 데이터셋을 구성했습니다.
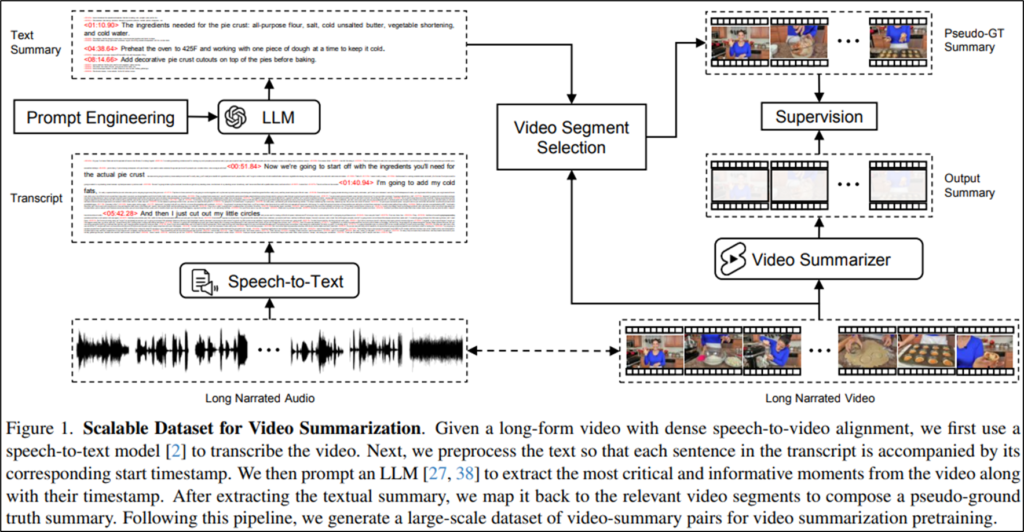
기존에 데이터셋의 규모적 한계가 있었던 이유는, ground truth 생성이 어려웠기 때문인데요, 사람이 직접 라벨링 하여 생성하기에 비용이 많이 발생할 뿐 만 아니라, 작업자에 따른 주관에 의해 일관성이 떨어지는 문제도 있었습니다. 본 논문은 Figure1과 같은 자동화된 요약인 Pseudo-ground truth(이하 pGT) 생성 방법을 통해 대규모의 Video summarization 학습 데이터셋을 구축하였습니다. pGT 생성 방법은 간단합니다.

먼저 비디오의 음성정보를 whisper 모델을 통해 text로 임베딩한 후, 아래의 GPT-3.5-16K를 활용하여 Prompt를 통해 텍스트 요약을 생성합니다. 이때, 두 도메인의 요약이 완벽히 매칭될 수 있도록, 요약된 내용을 재생성 하는 것이 아닌, extractive summary(Figure2의 2번 주의사항 참고)를 진행했습니다. 이후 비디오의 프레임을 CLIP을 통해 임베딩하여 GPT가 생성한 text summarization과 유사한 프레임을 선정해 pGT를 생성합니다. 즉, LLMs의 요약 능력을 통해 문맥을 고려한 video summarizaiton pGT를 생성한 것입니다.
학습 방법론 소개
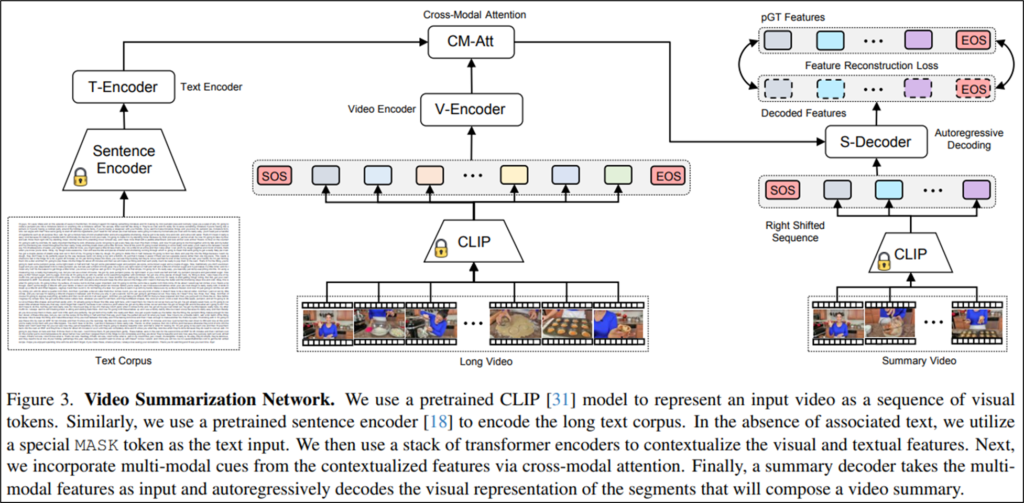
본 논문이 제시하는 구조는 지도학습 구조로, 오디오 도메인 정보인 Text corpus와 비전 도메인 정보인 Long Video의 임베딩을 CM-Att로 결합하여 S-Decoder의 입력으로 합니다. 해당 입력에 대한 출력(y^)이 Summary Video(pGT)에 대한 임베딩(y)과 같아지도록 수식1과 같이 제곱오차로 학습하게 됩니다.

위 구조(Figure3)에서 집중해야할 부분은 S-Decoder입니다. 본 논문은 기존 Video summarization 모델이 구조가 요약을 모든 프레임에 대해 병렬적으로 수행하여 이미 요약에 포함된 프레임을 중복적으로 중요한 프레임으로 선출하는 한계가 존재한다고 밝혔습니다. 이러한 한계를 개선하기 위해 요약된 결과를 생성할 때 이미 요약된 프레임의 정보를 고려하는 autoregressive 구조를 설계했습니다. (수식2 참조)

autoregressive 구조 다음으로 집중해야할 제안점은 Cross-Modal Attention(Figure3의 CM-Att)입니다. 본 논문은 단순히 시각적인 중요도가 아닌 맥락적으로 중요한 프레임을 선출하기 위해 audio 정보를 통해 생성한 text corpus와 frame feature를 잘 결합하는 attention 구조를 제안했습니다. 특히 frame feature(수식3의 x^)를 query, text corpus feature(수식3의 s^)를 key, value로 하여 attention mechanism(수식3)으로 두 feature를 결합했습니다.
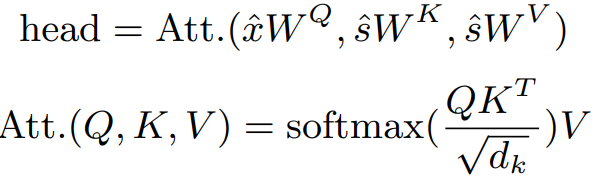
그 외의 구현사항으로, 비디오는 1fps(1초당 1프레임)으로 추출되었으며 CLIP 인코더를 통해 임베딩 되었습니다. 이후 각 프레임에 문맥적 정보를 포함하기 위해 학습 가능한 V-Encoder를 추가하여 최종적인 비전 도메인 임베딩 x^를 설계했습니다.

오디오 정보를 통한 텍스트 도메인도 유사합니다. Whisper 모델을 통해 오디오를 텍스트로 표현한 후, sentences 단위*로 text feature를 생성합니다. 이때 각 sentences 단위로 SOTA 모델인 SRoBERTa를 통해 임베딩 하였으며, 문맥적 정보를 강화하기 위해 학습 가능한 T-Encoder 구조를 추가하여 최종적인 텍스트 도메인 임베딩 x^를 설계했습니다.
* sentences 단위: 프래임 n/k개를 묶어서 하나의 sentences를 구성

실험 및 검증
본 논문은 제안한 데이터셋과 새로운 구조에 대한 검증을 위해 다양한 실험을 진행했습니다. 먼저 제시한 문제를 해결한 최종 구조인 대규모 자동생성 데이터(LfVS-P)를 통해 제시한 구조(Ours)를 학습한 방법을 기존 Sota 모델들과 비교하였습니다. 비교 결과(Table2) 모든 평가지표에서 우수한 성능을 달성하여 성능이 실제로 개선되었음을 확인할 수 있었습니다.
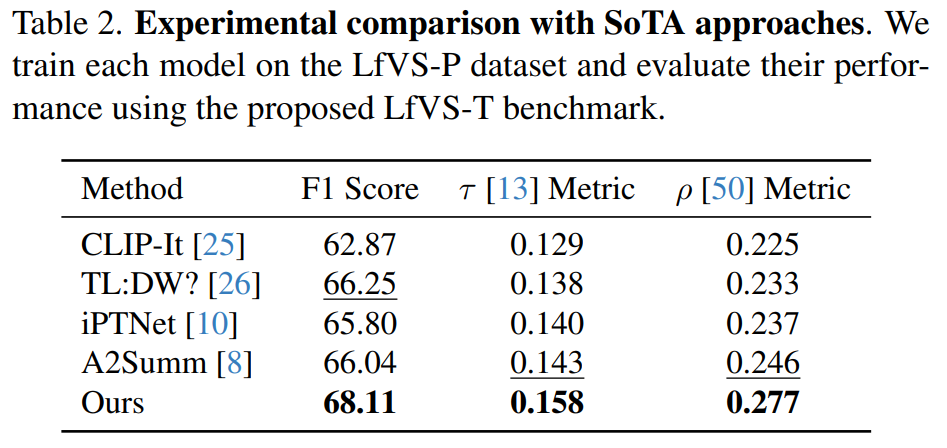
다음으로 새로운 구조가 제시한 데이터셋 뿐 만 아니라 기존의 데이터셋에서도 잘 동작하는 지 Table3에서 검증을 수행했습니다. 실험 결과로 τ Metric과 ρ Metric에서 지속적으로 비교 방법론 대비 높은 성능을 보이며, 기존 요약된 정보를 고려하는 autoregressive 방식의 구조가 실제로 성능 개선에 효과적임을 보였습니다.
또한 cross-dataset 실험을 통해 LfVS-P를 통해 대규모로 사전학습을 수행하였을 때, 타겟 데이터셋에 대해 추가학습을 하지 않더라도 우수한 성능을 보이며, fine-tuning 까지 진행한다면 가장 높은 성능을 달성할 수 있음을 보였습니다. 즉 제안된 대규모 데이터셋으로 사전학습 하는것이 테스크 수행 성능을 향상시키는데 도움이 되었음을 확인할 수 있습니다.
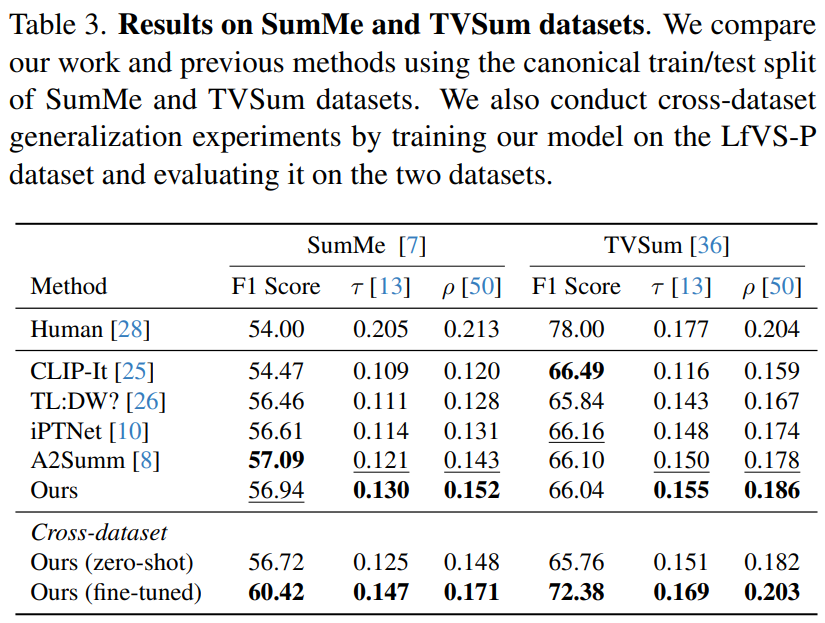
마지막으로, 제안한 모델의 구조에 대해 Ablation studies를 진행한 결과는 Table 4와 같습니다. 본 실험 결과를 통해 Text와 Video 도메인 모두에서 CLIP이나 SRoBERTa와 같은 foundation model의 출력값을 그대로 사용하지 않고 encoder를 도입하는 것이 효과적이였음을 확인할 수 있으며, 특히 Cross-Attention 구조를 통해 audio 정보를 vision 정보에 임베딩하는 것이 효과적이였음을 확인할 수 있습니다.
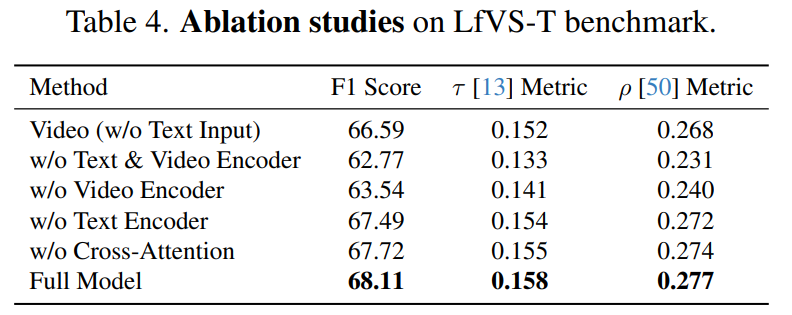
그 외에도 본 논문은 Table5의 실험적 분석을 통해 다양한 인사이트를 제공합니다. 먼저 본 논문이 개선한 contribution 중 하나인 autoregressive 구조가 테스크 성능 향상에 매우 효과적이였음을 Problem formulation 실험으로 보였습니다. 비교군인 classification은 Figure3의 decoder를 classification layer로 변경하여 프레임에 대해 요약에 포함 여부를 이진분류하도록 학습한 결과입니다.
다음으로 데이터셋의 규모적 중요성을 Dataset Scale 실험으로 보였으며, 규모와 성능의 상관관계가 매우 컸음을 확인할 수 있습니다. 또한 모든 데이터셋을 활용한 학습 성능이 기존 데이터셋 벤치마크를 활용한 학습 성능보다 높음을 통해 데이터셋에 포함된 노이즈보다 규모 확장을 통해 데이터셋 다양성을 높이는 것이 중요함을 알 수 있었습니다.
마지막으로 데이터셋 구축에 있어서, pseudo ground truth(pGT)를 생성하는 LLM의 성능과 video summarization 성능의 연관관계를 LLM 실험을 통해 보였습니다. 이때 50K의 데이터셋을 활용했으며, 본 논문에서 최종적으로 활용한 LLM 모델(GPT-4.5-16K)을 기준으로 LLM 모델의 성능이 좋아짐에 따라 video summarization의 최종 성능 또한 개선됨을 보이며 LLM 연구의 발전에 따라 제안하는 자동화된 데이터셋 구축 방안으로 성능 개선이 가능함을 보였습니다.
이상으로 LLM을 통해 video summarization 문제를 해결하는 방법에 대해 알아보았습니다. 특히 기존 연구의 문제점을 해결한 구조로 높은 성능을 달성하며 각 구조의 효과를 실험을 통해 잘 분석한 논문이였습니다. 특히 자동화된 데이터셋 구축 방법을 공개한 것이 인상적이였습니다. 물론 성능 향상에는 모델의 구조적 측면보다 대용량의 데이터셋의 영향이 큰 것 같아 아쉬우나, 현실적으로 문제를 해결하는 방안인 듯 하네요. 감사합니다.
좋은 리뷰 감사합니다. 궁금한 점 댓글 몇 가지 남겨두겠습니다.
1. text summarization을 기반으로 유사한 프레임을 CLIP 임베딩으로 찾는 방식은 사실 매우 직관적인데, CLIP의 편향성이나 특정 장면 선택에 미치는 영향을 보정하기 위한 설계가 있었는지 궁금합니다.
2. LLM의 성능이 높아질수록 pGT의 퀄리티가 좋아진다고 하셨는데, 혹시 이에 대해 정량적 분석(예: pGT와 human annotation의 유사도 측정 등)을 통해 직접적으로 확인한 실험은 있었을까요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
질문해주신 내용에 대해 순차적으로 답변 드리겠습니다.
1. 우선 CLIP의 편향성 등에 대한 우려와 이에 대한 보정은 본 논문에서 다루지 않았습니다. 이는 CLIP 등의 VLM 모델이 개선된다면 본 연구에서 더욱 성능 향상이 있을 수 있음을 의미합니다.
2. pGT의 퀄리티 자체를 평가하지는 않았지만, Table5의 LLM(50K) 실험을 통해 LLM의 성능을 높일경우 해당 데이터셋으로 학습한 결과가 더 좋음을 확인할 수 있습니다.
감사합니다.
안녕하세요 유진님 좋은 리뷰감사합니다.
본문의 방법론과 관련해 질문이 있습니다. Autoregressive 방식은 지금까지의 선택들을 기반으로, 다음에 무엇을 선택할지를 결정하는 방식으로 이해했습니다. 그렇다면 다음 선택을 할 때, 이전에 선택된 프레임들이 어떤 방식으로 영향을 주는지 설명해주실 수 있을까요?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
우선 수식2를 보시면 t-1시점 까지의 pGT 정보가 t시점의 summarized video frame 예측에 사용됩니다.
해당 수식의 S-Decoder는 트렌스포머의 decoder 구조로 시퀀스 정보 예측에 주로 사용되는 구조입니다.
이러한 구조를 활용해 이미 선별되어야 했던 ground truth(pGT) 정보를 활용해 현재 시점(t)의 프레임을 예측하는 것입니다.
적절한 답변인지 모르겠네요. 필요시 추가질문 부탁드립니다.
감사합니다.
최근 비디오를 적용해서 LLM에 녹이는 방법에 관심이 있어 리뷰를 보게 되었습니다.
아쉽게도 LLM으로 학습 데이터를 만드는 논문이였네요.
LLM을 이용해서 pGT를 만드는 것이 인상 깊었습니다.
근데… 읽다보니.. pGT를 이용해 학습하는 거면 별도의 장치 없으면 pGT가 upper일 것 같은데 말임다.
fig 5를 보면 LLM을 이용한 기법보다 더 좋은 성능을 보이는데 이게 어떻게 가능한건지 이해가 안갑니다.
설명 부탁드립니다!
안녕하세요, 리뷰 읽어주셔서 감사합니다.
중요한 부분을 말씀해주셨습니다.
pGT를 만드는 과정 자체가 Video summarization을 생성하는 방법이 아니냐는 말씀이신데, 해당 자동화 프로세스와 video summarization의 차이점은 나레이션의 필수적 필요 여부입니다.
자동화 프로세스는 LLMs의 text summarization 능력 활용을 위해 나래이션이 필수적이지만, 일반적인 video summarization은 해당 정보가 누락되더라도 동작할 수 있어야 합니다.
둘째로, pGT에는 노이즈가 존재합니다. 즉 해당 성능이 upper라는 보장이 없습니다.
그러나 노이즈를 포함하더라도 데이터셋 자체의 크기를 scaling up 했을 때, 학습한 video summarization 모델의 성능이 개선됨을 Tabel 5의 Dataset scale 실험을 통해 확인할 수 있습니다.
감사합니다.
안녕하세요 유진님, 세미나를 듣고 어느정도 편하게 이해하게 되었습니다.
세미나때는 미처 질문정리를 못해서 질문드리자면 기존 방식의 문제점 중 long tail 문제가 있던 방식을 버리고 autoregressive 방식을 사용했다고 하였는데, 생기는 장점말고 단점은 없는건가요?
예를들어 병렬적으로 처리가 안돼서 생기는 문제점 같은것이 있나 궁금합니다.
감사합니다.
안녕하세요 인택님 댓글 감사합니다.
늦게 답변을 달아 죄송하다는 말씀을 드리며, 병렬적 생성에 비해 autoregressive 방식이 갖는 문제점에 대해 논문에서는 언급이 되어있지는 않습니다. 또한 최근 연구중 일부(Video-T1[1])는 프레임단위로 결과를 생성하는 방식이 한번에 모든 결과를 생성하는 것에 비해 통제가능성이 높기때문에 활용하기도 합니다.
다만 최근 연구중에서는 병렬적 구조의 self-attention등을 충분히 활용하여 전체 context를 더욱 잘 학습하도록 설계한 방법도 많으며, 실제 비교는 해보지 않았지만, 결과물 생성의 속도 측면에서 병렬적 생성이 더 이득을 보지 않을까 생각됩니다(이는…. 제 생각이므로 검토가 필요합니다)
Reference
[1] Video-T1: Test-Time Scaling for Video Generation (https://arxiv.org/pdf/2503.18942)
X리뷰 링크: http://server.rcv.sejong.ac.kr:8080/2025/04/21/arxiv-2025-video-t1-test-time-scaling-for-video-generation/
추가로 질문이 있다면 언제든지 말씀해주세요.
감사합니다.
안녕하세요 유진님! 좋은 리뷰와 좋은 세미나 감사합니다!
저한테는 너무 낯선 개념이 많았지만 유진님께서 설명을 잘 해주셔서 어느정도 이해할 수 있었던 것 같았습니다!
그 중에서 단순히 들었던 의문점에서 질문하고자 합니다!
제가 이해한 바로는 Whisper -> GPT-> CLIP 매칭이라는 과정을 통해 요약 프레임을 선택한다고 이해하였습니다.
이 과정이 사람이 만든 GT와 얼마나 일치하는지 정량적 혹은 정성적으로 평가한 결과는 있는지 궁금합니다!
왜냐하면 LLM이 문맥을 이해하는 방식과 실제 영상 요약에 적합한 기준이 있을 것 같은데 이 부분에 대해서 일치한다고 볼 수 있을까에 대한 생각이 들었습니다! 혹시나 제가 잘못 이해하고 답글을 드린 것이라면 이 부분에 대해서도 피드백 주시면 감사할 것 같습니다!
안녕하세요 우현님 댓글 감사합니다.
늦게 답변을 달아 죄송하다는 말씀을 드리며, 요약프레임 생성에 대해 이해하신 순서가 맞습니다.
다만 자동 생성한 GT에 대해 정량적, 정성적 평가는 따로 존재하지 않으며, 제안하는 데이터셋에 일부 노이즈가 존재할 수 있다는 뉘앙스는 존재합니다. (5.3절의 “The automatic dataset curation pipeline can introduce noise, affecting the robustness of a model when trained on a small-scale dataset.”)
즉, 노이즈가 존재할 수 있으나, 그럼에도 large-scale data라는 컨셉이 성능 개선에 효과적이므로, 제안하는 자동화된 데이터 생성방식이 유의미하다는 뜻입니다.
추가로 질문이 있다면 언제든지 말씀해주세요.
감사합니다.
안녕하세요 유진님 리뷰감사합니다 🙂
유진님께서 간간히 말씀해주시던 비디오 요약에 대해서 좀더 직관적으로 어떻게 흘러가는건지 궁금했는데 덕분에 조금은 알게되는 것 같습니다!
읽다가 궁금한 부분이 생겨서 질문 드립니다.
데이터셋 구축방안에서 사람이 직접 라벨링 하는게 아니라 LLM을 이용하여 pGT를 자동화로 생성하여 라벨링된 대규모 데이터셋을 구축하였다고 이해했는데(제대로 이해한게 맞을까요?!),
여기서 질문은 사람이 라벨링 하는것은 주관에 따른 일관성이 떨어질수도 있는 단점이 있다면 생성된 pGT에 대한 신뢰는 어떻게 판단하는지 궁금합니다 !
감사합니다~!