안녕하세요, 쉰 아홉번째 X-Review입니다. 이번 논문은 2025년도 TPAMI에 올라온 Instruction-Guided Scene Text Recognition논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
Scene Text Recognition은 scene image내의 text를 읽어내는 task로, image 모달리티에서 text 모달리티로의 매핑을 학습해 character sequence를 prediction하는 멀티모달 task입니다. 지난 몇 년동안에는 parallel recognition이나 auto-regressive recognition과 같은 recognition 파이프라인을 통한 연구가 수행되어 왔는습니다.
최근에는 grounding dino나 sam과 같은 모델들이 자연어 지시를 함께 사용함으로써 fine grained한 visual content에 대한 모델의 이해를 가능하게 하고 있습니다. 한 예로, 카테고리 라벨 대신 자유로운 형식의 text를 학습에 사용함으로써 lion같은 일반적인 object가 아니라 left lion처럼 좀 더 구체적인 object를 이해할 수 있게 하는 것이죠.
본 논문의 저자는 마찬가지로 STR(Scene Text Recognition) 모델들도 text image에 대해 좀 더 fine-grained하게 이해하게 된다면 이점이 있을 것이라고 주장합니다. 하지만, 앞서 언급한 grounding dino, sam이 학습하는 natural한 image와 text image는 구성 요소 자체가 본질적으로 달라서 기존 instruction learning 방식들을 그대로 적용하기에는 여러 어려움이 있다고 하는데요. 구체적으로, natural image는 주로 물리적인 세상의 object나 scene을 담고 있어 자연어로 쉽게 묘사할 수 있는 반면에 text image는 대체로 단어 하나만을 담고 있어 이 자체로는 STR 모델에 충분한 semantic context를 주지 못하겠죠. 따라서, 이 STR task에 특화된 instruction 방식을 개발해야 합니다. 또한, mobile이나 edge computing 환경에서의 적용함으로 고려하여 좀 더 light한 모델을 개발하는데도 초점을 맞춰야 하죠.
본 논문에서는 STR task에 초점을 둔 instruction-learning 기반의 모델 IGTR(instruction-guided STR)을 제안합니다. 먼저 instruction 구성 측면에서 저자들은 character(문자)의 속성을 문자의 상태나, 빈도, 위치 같은 특성으로 정의를 하고, 이런 문자 속성이 text에 대한 모델의 이해를 돕는 핵심이라고 보았습니다. 이를 위해 두 가지 유형의 instruction을 설계했는데요. 첫 번째는 character의 속성을 예측하는 instruction으로, 아래 figure1에서 볼 수 있듯이 <condition, question, answer> 형식을 따릅니다.
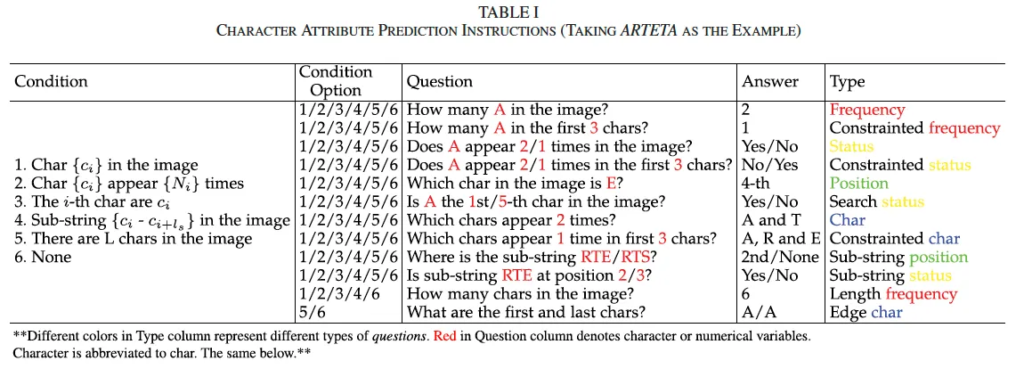
구체적으로 살펴보자면, condition 부분에는 이미 알고 있는 속성(예를 들어 이 단어 안에는 ‘e’가 들어 있음 등)이 들어가게 되며, question으로는 이 속성에 대한 구체적인 질문(예를 들어 ‘e’가 몇 번째 위치에 있는가?)이 들어가고, 마지막 answer로는 이 질문에 대한 정확한 답(예를 들어 세번 째)이 주어지게 됩니다. 이렇게 구성된 question-answer 쌍은 학습 데이터와 라벨 역할을 하게 되겠고, 모델이 단순 문자를 prediction하는 것에서 더 나아가 text image를 사람이 이해하는 것처럼 이해를 높일 수 있습니다.

두 번째는, text recognition을 위한 instruction으로 앞과 마찬가지로 <condition, question, answer> 형태를 따르는데, 여기서는 PR(parallel recognition)이나 AR(autoregressive recognition) 등과 같은 서로 다른 recognition 파이프라인을 시뮬레이션 할 수 있도록 설계된 것입니다. 구체적으로 PR 방식은 전체 단어를 한 번에 예측하는 것인데 table2의 첫번째 행(PR type)을 보시면 질문이 첫 번째부터 L 번째 문자는 무엇인가?라고 되어 있습니다. 마찬가지로 AR 방식은 문자를 순차적으로 prediction하는 것인데, question을 보면 i+1번째 문자는 무엇인가? 하는 식으로 구성되어 있죠. 이외에도 Type을 보면 Re-identification방식이라던지, extrapolating recognition과 같이 기존 연구에서는 잘 다뤄지지 않았던 방식까지 반영해 모델이 다양한 시나리오에 잘 적응할 수 있도록 하였습니다.
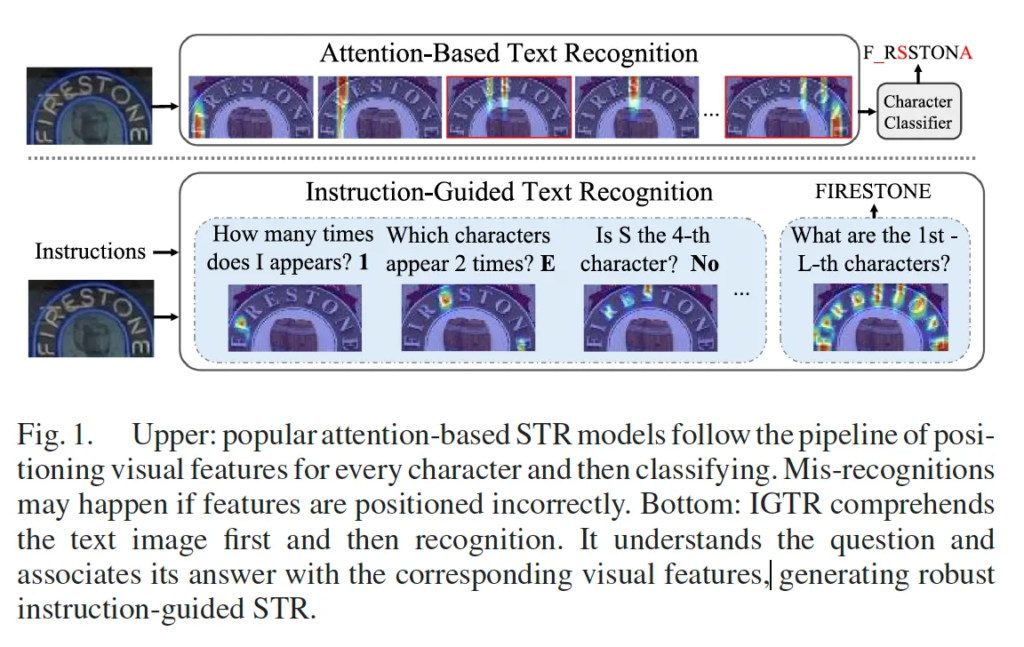
위 Fig1은 기존 attention based STR 모델과 본 논문에서 제안하는 instruction guide based STR을 빅하고 있습니다. 위에 부분이 attentio n based text recognition model인데, 이 모델들은 각 문자의 visual feature에 attention하도록 한 다음 이 해당 위치의 feature를 가지고 character classification을 수행하는데요, 그림에서 보이는 것과 같이 visual feature가 잘못 위치하게 되는 경우 오인식으로 이어질 수 있습니다. 반면에 본 논문에서 제안하는 instruction guide 기반 모델은 question-answer 기반으로 학습하기 때문에 문자의 속성을 학습하게 되고 text image를 더 잘 이해하기 때문에 훨씬 정확한 recognition을 가능하게 합니다.
또, 최근에는 LLaVA나 Monkeys와 같은 MLLM들도 OCR 관련 dataset으로 학습하거나 fine-tuning되어 STR 포함 다양한 task에서 좋은 성능을 보이고 있습니다. 다만, 이런 MLLM들은 parameter가 많고 computing resource도 많이 소모하게 되죠. 이런 점을 고려한 IGTR은 모델 크기가 24.1M에 불과하며 1080GPU에서 한 instance를 inference하는 데 4~10ms정도만 걸려 모바일이나 edge compuding환경에 좀 더 적합하다고 볼 수 있습니다. 이제 아래 method 단에서 제안된 모델에 대해 좀 더 자세히 살펴보도록 하겠습니다.
2. Method
잠깐 앞서 intro에서 언급한 부분을 정리하자면, 본 제안된 방법론은 크게 두 부분으로 구성됐었습니다. instruction 구성 및 샘플링하는 부분과 IGTR 아키텍처 부분이었죠. 여기서 instruction은 문자의 속성을 예측하는 부분과 recognition용 instruction이 있었고 둘 다 <condition, question, answer> triplet 형태로 구성됩니다. 동시에 IGTR 구조는 경량화에 초점을 둔다고 했었고, light한 instruction encoder, cross-model feature fusion 모듈, multi-task answer head로 구성됩니다. 먼저 이 중 instruction 구성 및 샘플링 하는 부분에 대해 살펴보도록 하겠습니다.
2.1. Instruction Construction and Sampling
여기서는 앞서 짧게 소개드렸던 table1에 대해 구체적으로 설명드리고자 합니다. Table1의 맨 오른쪽에 Type부분을 보면 answer 종류에 따라 총 네가지의 서로 다른 색으로 구분이 되고 있는데요. 보시면 character, frequency, position, status로 분류가 되고 있습니다. 구체적으로 character status(cs)는 그 특정 문자의 존재 여부에 관한 것이구요. character frequency(cf)는 특정 문자가 얼마나 있는지에 대한 것이며, contrainted character frequency(cf_{cons})는 제한된 경우에서의 빈도, 예를 들어 앞에서 세 글자 안에서의 특정 문자 수같은 경우입니다. 또한 position character(pc)는 이름에서도 유추가능하듯이 i번째 위치에 있는 문자이며, sub-string(ss)은 특정 길이의 부분 문자열을 의미합니다.
한 예로 살펴보자면 “ARTETA”라는 text가 주어지게 되고 제한 조건(contraint)이 앞 3글자, 부분 문자열(sub-string) 길이가 3이라고 한다면 문자 속성 집합은 아래와 같이 표현될 수 있습니다.

각 요소는 대괄호로 표현되며, question과 answer 둘로 구성되어 있습니다. 예를 들어 cs의 [A, 1]에서 A가 question이고 1이 answer입니다.
본 논문에서는 보통 이렇게 쓰이는 <qestion, answer> 형식을 <condition, question, answer> triplet으로 확장하는 방식을 제안하고 있습니다. 여기서 condition은 모델에게 속성 몇을 알려주는 것으로 예를 들어 [[E,1], [R,1], [S,0]], [[E,1],[T,2]], [[0,A], [2,T], [5,A]]라면 각각 존재하는 문자(cs), 등장하는 빈도(cf), 위치 속성(pc)에 대한 부분집합으로, 앞에서부터 보면 이미지에 E와 R은 존재하지만 S는 존재하지 않는다, 문자 T는 2번 E는 1번 등장한다, 이미지에서 1/3/6번째 문자는 A/T/A다가 되겠습니다. 이후, 남은 부분집합을 가지고 question과 answer를 만들 수 있겠죠.
이러한 triplet 구조로 인해 instruction을 보다 다양하게 만들 수 있다고 합니다. 특히 이 instruction을 생성할 때는 단순 한두 triplet만 만드는 것이 아닌 한 이미지에 대한 모든 속성들을 condition/question/answer로 랜덤으로 분할하면서 조합 가능한 최대의 수까지 고려하여 생성하도록 하였습니다.
2.2. IGTR Architecture and Learning
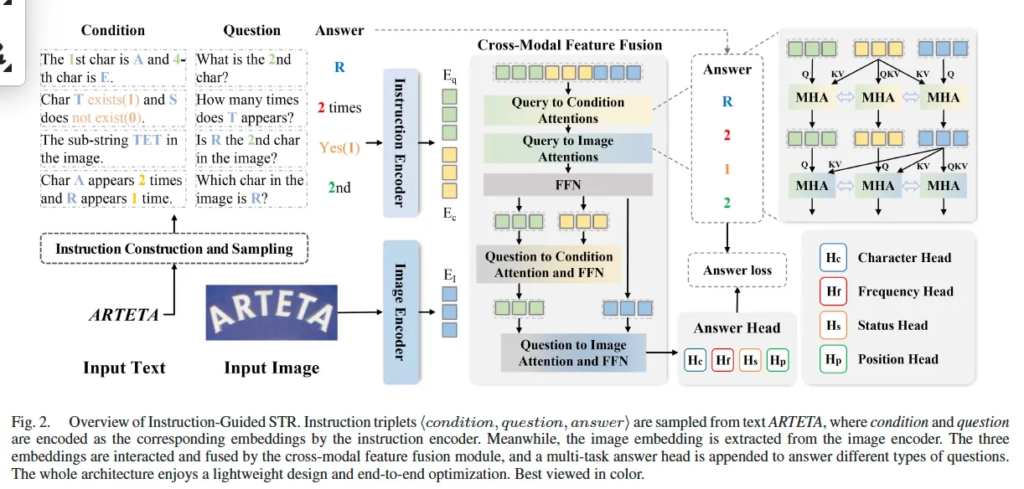
다음으로 본 논문에서 제안된 IGTR 모델의 구조에 대해 살펴보도록 하겠습니다. 위 Fig2를 참고하시면 되는데요, 먼저 sampling된 instruction들은(그림 좌측) instruction encoder로 들어가게 되어 condition과 qeustion embedding으로 나오게 됩니다. 동시에 image encoder는 ‘ARTETA’라는 text가 적힌 영상을 받아 image embedding을 추출하게 됩니다. 이렇게 생성된 세 embedding들은 cross-model feature fusion 모듈(그림 가운데)로 들어가 answer과 관련된 cross model feature를 학습하게 됩니다. 이후 이 embedding들은 multi-task answer head로 넘어가게 되는데, 이 head에서 최종적으로 prediction하는 answer 유형을 총 4가지로 그림을 보시면 H_c, H_f, H_s, H_p라고 적혀져 있는데, 각각 character head, frequency head, status head, position head입니다.
Instruction encoder
각각에 대해 좀 더 살펴보자면, 먼저 instruction encoder는 각 instruction의 feature를 추출하는 역할을 합니다. 기존 다른 연구들에서는 pre-trained text encoder를 사용해 instruction feature를 추출했지만, 이는 computing resource가 많이 필요하게 된다는 단점이 있습니다. 반면에 본 논문에서는 좀 더 lightweight한 encoder를 설계해 사용하고자 하였습니다.
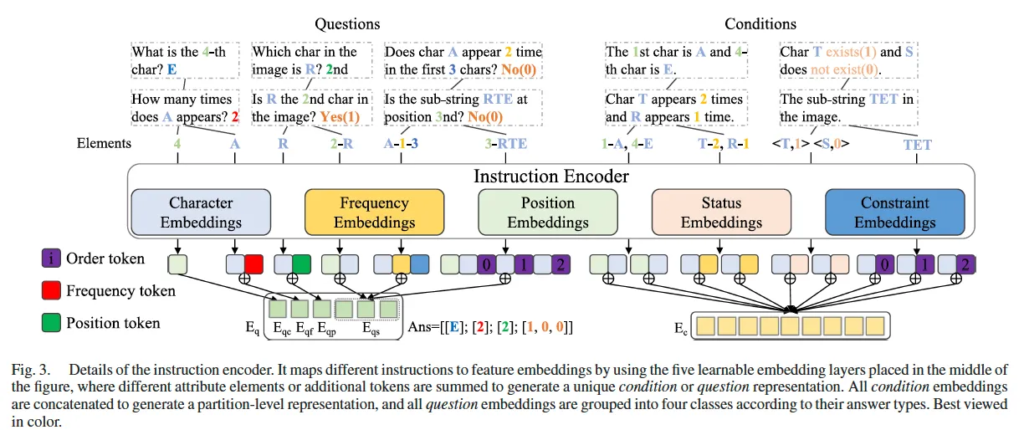
구체적으로 설명하자면, 위 Fig3을 보시면 되는데요. character의 속성은 character, frequency, position, status, contrasint로 구성된 다섯 개의 요소로 이루어져 있다고 하였습니다. instruction encoder는 이 5개의 learnable한 embedding layer로 이루어져 있습니다. 하나씩 살펴보자면 character embedding같은 경우는 R^{C \times D}로 C는 전체 문자 크기(알파벳만이라고 하면 26개니까 c=26)고, D는 embedding 차원입니다. Frequency embedding은 R^{F \times D}로 여기서 F는 최대 등장 빈도가 되겠죠. 나머지도,, 다 언급하지는 않겠지만 이런 식입니다.
이제 구체적으로 embedding을 어떻게 만드는지에 대해 설명드리자면, 먼저 속성을 index 번호로 바꿨는데요. 예를 들어 A라고 하면 Character embedding의 0번째 index. 빈도 2회라고 하면 frequency embedding의 1번째 index, 4번째 위치라고 하면 position embeding의 3번째 index 이런 식으로 말이죠.
이때 단일 속성은 그 embedding을 그대로 사용했는데, 가령 4번째 문자가 무엇이냐는 질문일 때는 position embedding의 3번째 index값만을 사용한다고 보면 됩니다. 그 외에 다중 속성인 경우에는 각 embedding을 합했는데요. 예로, 첫 번째 문자는 A다라는 instruction일 때는 Position embedding[0] + character embedding[0]으로 사용하였습니다. 또, substring question은 substring 각 문자 embedding에 order token을 추가하였고, 마찬가지로 position, frequency question은 각 token을 추가하였습니다.
설명이 난해하긴 하지만, 방금 설명드린게 다 Fig3에 들어있는데. 하나만 예로 보자면,, 맨 왼쪽에 “How many times does A appears? 2”라는 question answer가 있는데, 여기서 A는 5개의 요소 중 character embedding에 해당하므로 character embedding의 0번째 index를 뽑아와 frequency token을 더하는 식으로 embedding이 생성되겠습니다.
이런 설계로 인해 IGTR은 복잡한 question과 condition들을 attribute 단위로 표현하면서도,, 계산 측면에서 효율성을 높이면서 모델이 다양한 유형의 질문에 자연스럽게 대응할 수 있도록 하였다고 볼 수 있습니다.
Cross-modal feature fusion
다음은 이 instruction embedding과 image embedding과의 cross modal feature fusion 부분입니다. 보통은 instruction embedding을 query로 image embedding을 key, value로 사용해 cross attention을 통해 image feature에서 관련 정보를 뽑아내곤 하는데요. 본 논문에서는 instruction이 단순 질문(question)만 포함하는 게 아니라 condition(모델에게 알려주는 정보)과 question이 같이 있다보니 이 condition, question, image embedding이 모두 상호작용 할 수 있는 새 모듈이 필요합니다. 이 모듈은 총 네 번의 cross attention으로 구성됩니다.
첫 번째는 query to condition attention으로, condition embedding E_c을 key로 사용하고 나머지 자기자신 포함 셋을 query로 두고 multi-head attention을 수행합니다. 두 번째로는 query to image attention으로 image embedding E_I를 key, value로 나머지를 query로 사용해 MHA를 수행합니다. 이렇게 하면 세 모달리티가 image로부터 정보를 얻을 수 있겠죠.
이 과정은 Fig2의 Cross modal feature fusion부분에 그려져 있습니다. 우상단 부분에서 볼 수 있듯이 이 MHA 모듈은 모두 파라미터를 공유하도록 되어 있어 좀 더 lightweight하다고 볼 수 있습니다.
세 번째로는 두번째 단계에서 나온 question embedding을 query로 condition embedding을 key, value로 사용한 MHA를 수행. 네 번째 단계로는 세 번째 단계에서 나온 question embedding을 query로, image embedding을 key, value로 사용하여 MHA를 수행하게 됩니다.
이런 과정을 통해 question embedding은 condition과 image에서 더 fine-grained한 feature를 추출하게 되면서 최종적으로 answer-related cross-model embedding을 얻게 됩니다.
2.3. Text Recognition With Instruction
모델 학습 과정에서 IGTR은 table1의 attribute prediction instruction과 table2의 recognition instruction을 함께 사용합니다. 이때 속성을 예측하는 지시문의 경우에는 IGTR이 character level의 fine-grained한 feature와 문자 간의 관계를 학습하도록 함으로써 text에 대한 이해를 돕는 역할을 하구요. Recognition instruction은 각기 다른 recognition 파이프라인을 학습해서 IGTR이 실제 text recogition 방식을 습득하도록 한 것입니다.
학습이 끝나고 추론 단게에서는 IGTR이 table2에 정의되어 있는 PR이라던지 AR혹은 RI, ER 중 하나의 instruction을 선택해 text recognition을 수행하게 됩니다. 각 방식이 본 논문에서는 크게 중요하지는 않아,,, 자세히 설명드리지는 않았습니다만 아래 FIg4를 통해 각 방식이 어떤 식으로 동작하는지에 대해 살펴볼 수 있습니다.

3. Experiments
3.1. Ablation
Instruction variants
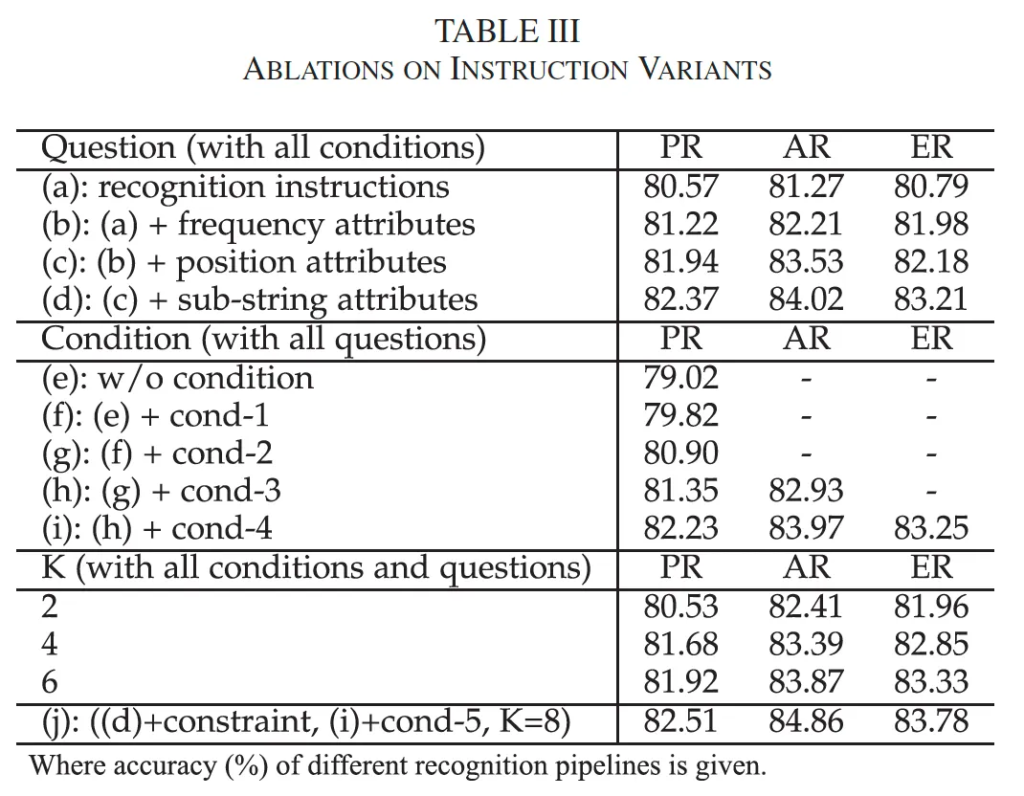
이제 실험 부분 살펴보도록 하겠습니다. 저자들은 IGTR의 instruction을 다양하게 변형해가면서, 또 CMFF와 모델 확장성에 대한 ablation study를 수행했습니다. 먼저 instruction 변형에 대한 실험으로 위 table2를 보시면 됩니다. 보시면, PR, AR, ER instruction만 사용해 학습한 IGTR-PR, IGTR-AR, IGTR-ER 모델을 비교하고 있습니다. 먼저 (a)에서는 recognition instruction만 사용했지만, 그 아래로 속성 관련 question을 점진적으로 추가하면서 세 모델 모두 유사한 정확도 향상의 경향을 보입니다. 이는 문자의 속성에 대한 모델의 이해가 인식 성능 향상에 기여한다고 볼 수 있겠죠. 특히 맨 아래 행 (j)에서 전체 instruction을 사용할 때의 경우를 보면 아무것도 적용하지 않은 (a) 대비 PR, AR, ER 각각이 약 2%, 3.6%, 3% 향상되었습니다.
유사하게도 (e)~(i)를 보면, condition을 점진적으로 추가하고 있는데 여기서 cond-3, cond-4를 더해야 AR과 ER이 모두 가능한 것으로 보입니다. 즉, condition이 단순 정확도를 높일 뿐만 아니라 다양한 recognition 파이프라인을 가능하게 한다는 점을 시사하고 있는 것 같네요.
CMFF components
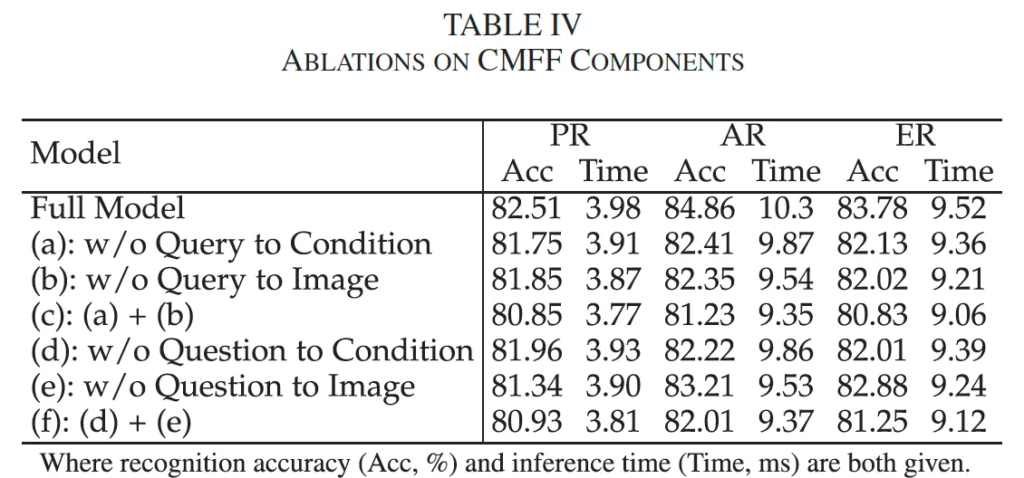
다음으로는 CMFF 모듈에 대한 실험입니다. CMFF는 모달리티 간의 상호작용을 위해 네 단계의 cross attention으로 구성이 되었었죠. 본 실험에서는 각 단계를 제거하면서 성능 변화를 살펴보았습니다. table4를 보시면, 어느 단계를 없애든 정확도가 감소한느 것을 볼 수 있는데요. 예를 들어 query to condition이나 query to image 단계를 모두 없앤다면 PR, AR, ER에서 약 1.6, 3.6, 3% 성능이 하락함을 보입니다. 마찬가지로 question to condition과 question to image 단계를 제거했을 때도 동일 양상을 보입니다. 또, 맨 윗행에 Full일 때의 추론 속도는 약 4ms, 10ms, 9.5ms로 나와있는데, cross attention을 없앤다고 해도 속도 개선 측면에서 차이가 미미한 것으로 보아 효율성 측면에서도 좋다고 볼 수 있죠.
Scalability of IGTR
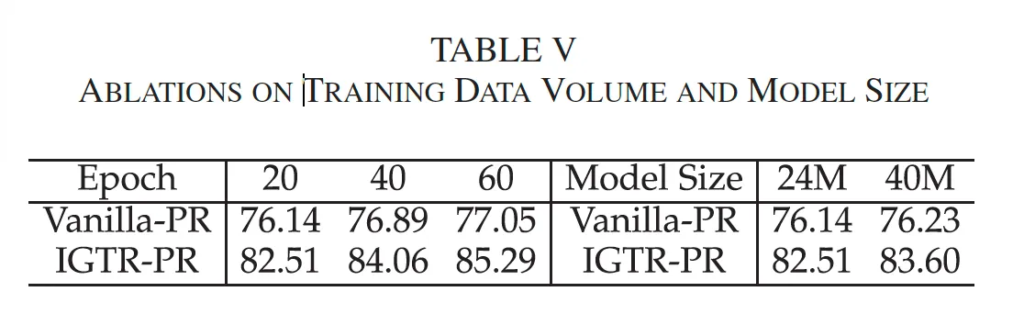
마지막으로 IGTR의 확장성을 평가하기 위해 학습 데이터 양과 모델 크기에 대한 실험을 수행하였습니다. 위 Table5를 보시면 Vanilla-PR과 IGTR-PR을 비교하고 있는데 여기서 vanilla-PR은 table2에서 PR instruction만 사용해 학습한 모델입니다. 먼저, 서로 다른 epoch에서의 비교를 보면 IGTR-PR은 20epoch에서 60epoch으로 늘렸을 때 2.8% 정도의 성능 향상을 보였습니다. 반면 vanilla의 경우는 1%가 안되는 성능 향상을 보였죠. 이는,, 각 epoch에서 속성 prediction instruction을 샘플링해 학습 데이터가 늘어났기 때문으로 볼 수 있겠습니다. 오른쪽에 백본을 통해 모델 크기를 늘렸을 때에 대한 정확도 차이도 비슷한 양상을 보이는데요. 이는 속성 prediction instruction의 다양함이 백본 크기에 대한 성능 향상을 가져온다고 해석해볼 수 있습니다.
3.2. Comparison With State-of-the-Art
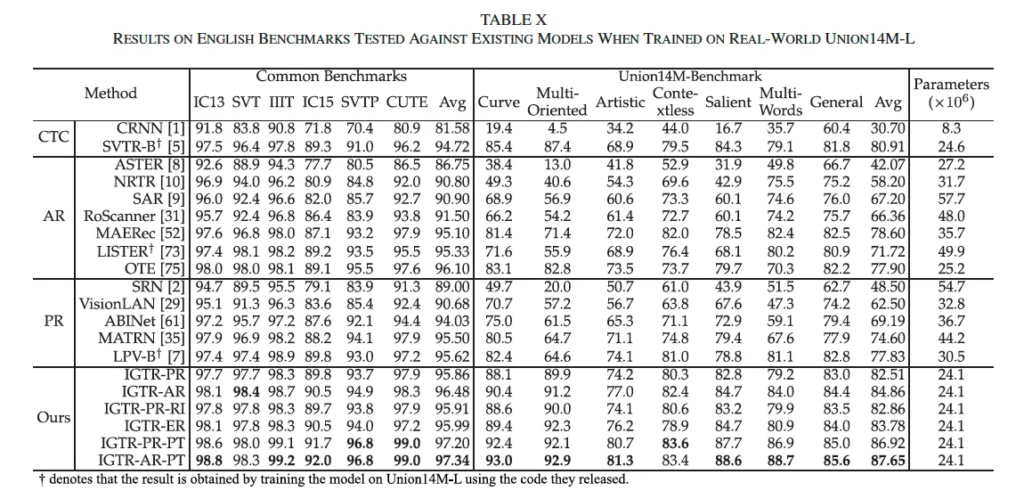
다음으로 Union14M 벤치마크 결과입니다. 표의 오른쪽 부분에 있는게 Union14M 벤치마크인데, 모든 부분에서 가장 좋은 성능을 보이고 있습니다. 특히 여러 IGTR 모델들 중에 synthetic 데이터로 사전학습하고 real data로 fine-tuning을 함께 한 IGTR-PR-PT와 IGTR-AR-PT 모델이 가장 좋은 성능을 보이고 있습니다. 특히 IGTR-AR-PT의 경우에는 기존 sota모델인 LPV-B와 비교했을 때 Common dataset에서 평균 2.6% Union 벤치마크에서 약 6.7%라는 큰 정확도 차이를 보이면서 instruction guided 학습에 대한 유효성을 입증하였습니다.
정윤서 연구원님. 좋은 리뷰 감사합니다. Table 10번에 보면 Common benchmark와 Union14M 벤치마크에 다양한 요소들이 있는데요, Common benchmark에서 IC13, SVT, IIIT, IC15 등이 여러 요소에 대한 평가인것으로 보이는데, 어떤 것을 기준으로 나누는지 알려주시면 감사하겠습니다
안녕하세요. 댓글 감사합니다.
언급해주신 IC13, SVT, IIIT, IC15는 각각 다른 데이터셋입니다.
IC13, SVT, IIIT는 대부분 수평이나 약간 기울어진 텍스트만을 담고 있는 비교적 단순한 데이터셋이구요.
IC15, SVTP는 각도나, text가 좀 왜곡되어 있다던지 앞서 언급한 데이터셋보다 좀 더 챌린지한 벤치마크이며,
CUTE같은 경우는 아예 곡선 텍스트에 초점을 맞춘 벤치마크입니다.
안녕하세요 윤서님 좋은 리뷰 감사합니다!
IGTR에서 사용되는 condition은 inference 할 때에도 입력으로 주어지는지 아니면 training 시에만 모델 학습을 돕는 어떠한 시그널로만 사용되는지 궁금합니다!
만약 condition이 inference 시에도 필요하다면 실제 응용 측면에서 사전에 condition 정보를 수집하거나 지정해야 하므로 모델 활용이 제한될 수 있겠다는 생각이 들었습니다!
감사합니다!
댓글 감사합니다.
inference에서도 마찬가지로 condition이 들어가게 됩니다. 구체적으로 Fig4 부분 설명할 때 언급했었는데요.
Infer시에는 AR, PR, ER 등의 방식중 하나를 선택하게 되는데 예시도 AR을 보시면 순차적으로 앞에서부터 문자를 예측해 나가며 첫 번째 단어를 예측할 때는 condition이 없다가 그 이후부터는 그 앞 문자들은 ~~이다 . 라고 이전에 예측해낸 결과를 바탕으로 condition이 들어가는 것을 볼 수 있습니다.
안녕하세요!
되게 신선한 접근 방법인 것 같네요. 흥미롭게 잘 읽었습니다.
질문이 하나 있습니다! condition, question, answer 이렇게 3개가 하나의 조합을 이룬다고 설명해주셨는데요 condition 이라는 게 question 과는 달리 Answer이 따라오지는 않지만 question 처럼 text image에 대한 정보를 주는 역할을 한다고 생각했어요 그것 말고 question과는 다른 condition 만의 어떤 역할이 있을까요? 리뷰 본문에 2.3 부분에서 recognition instruction을 사용할 때는 condition 과 question에 대한 매칭이 정해져 있는 것 같단 생각이 드는데요 attribute prediction instruction 사용 시에는 그럴 것 같지는 않아서 어떤 관계를 갖는지가 궁금합니다! 텍스트 이미지에 대한 정보를 더 주는 거라고 보면 되는걸까요?
안녕하세요. 댓글 감사합니다.
1. 말 그대로 condition은 사전에 image에 대한 부가 정보를 주는 것으로 보심 되겠습니다. question이 예를 들어 이미지에 A가 몇 번 들어가 있니? 가 된다면 condition은 B 라는 문자가 image안에 포함되어 있다. 는 instruction이고 이에 대한 어떤 output을 기대하는 것이 아닌 모델이 answer를 내는데 도움이 되는 조건을 주는 것이라고 보면 됩니다.
2. Attribute prediction instruction이 1번 답에서 예를 든 condition 경우에 해당할 것 같습니다. 즉, 모델에게 주는 정보가 직접적으로 question과 연관있는건 아니고 여러 question과 조합해서 학습 데이터의 다양성을 높이는 요소로 볼 수 있겠죠.