
Abstract
로봇은 미래에 다양한 작업을 수행할 수 있을 것으로 기대가 되지만, 확장성이 떨어지는 physical robot 학습을 최소화하면서 학습 환경과 실제 환경의 간극을 어떻게 줄일 수 있을 지가 큰 문제로 남아있습니다. 저자들은 인터넷에 존재하는 수많은 실제 사람의 동영상을 통해 로봇 manipulation task를 학습하는 것이 좋은 해결책이 될 수 있을 것이라 봅니다. 따라서, 저자들은 in-the-wild의 단안 RGB human-video를 통해 3D Affordance를 학습하여, zero-shot으로 로봇 조작이 가능하도록 하는 프레임워크인 VidBot를 제안합니다. VidBot은 비디오에서 3차원의 손 trajectories와 같은 명시적인 representation을 추출하고, SfM 기술과 depth foundation 모델을 결합하여 embodiment와 무관하게 metric-scale 3D affordance를 재구성하도록 합니다. 또한, 픽셀 공간에서 coarse한 수준의 action을 예측한 뒤, 이를 조건으로 하여 테스트 시점의 제약을 반영하고 맥락을 고려한 상호작용을 plannning하는 diffusion 모델을 통해 세분화된 상호작용 trajectories을 생성하는 coarse-to-fine 방식의 affordance learning framework를 제안합니다. 이는 다양한 장면과 embodiment에 대한 일반화를 가능하게 하며 다양한 실험을 통해 zero-shot 세팅에서 13가지 작업에 대하여 기존 방식보다 뛰어난 성능을 보임을 입증하였으며, real-world 경에서 로봇 시스템이 원활하게 적용될 수 있음을 보였습니다. 무엇보다 VidBot은 사람의 영상을 로봇이 학습에 활용할 수 있다는 점에서 높은 확장성을 지닌다는 점이 큰 장점입니다.
Introduction
AI 기술의 발전으로 미래에 로봇이 스마트폰과 같은 개인화된 시스템으로 발전될 것으로 기대되고 있으나, 로봇의 구현 형태가 다양하고 새롭기 때문에 개방형 환경에서 임의의 다양한 작업을 수행하도록 하기에는 아직 어려움이 있습니다. SOTA 방식은 전문가의 수동 조작으로 수집한 데모로 Imitation learning을 수행하여 로봇의 poliocies를 학습하는 방식으로, 이러한 방식은 비용과 시간이 많이 소요되며, 노동 집약적인 작업으로, 최근 대규모로 robot manipulation 데이터를 수집하려는 노력이 이루어지고 있으나 embodiment와 task, 환경 조합의 다양성으로 인해 어려움이 있는 상황입니다.
해당 논문에서 저자들은 사람의 비디오를 이용하는 것이 가장 유망한 방식이라 보고 이에 대하여 논의합니다. 사람의 조작 비디오는 이미 다양한 환경에서 다양한 작업을 촬영한 비디오가 대규모로 web상에 존재하기 때문으로, 일부 연구들은 human-to-robot 방식으로 스킬을 전이하기 위한 연구를 수행하였으나, 고정된 카메라 시점과 장면, depth 센서, 모션캡쳐 시스템 등이 필요하다는 한계가 존재합니다. 이러한 제약으로 인해 장면, 조도, 시점 등의 사양성을 반영하지 못하는 in-lab 시스템으로 제한됩니다.
일부 연구 흐름은 풍부한 장면 정보가 있는 사람의 비디오를 활용하여 로봇의 조작 학습을 수행하고자 시각적 표현에 대한 학습에 집중하였습니다., 그러나 사전학습된 모델을 fine-tuning하기 위해 새로운 데모마다 새로운 환경에서 작업 별로 수동 조작 데이터를 수집해야 하므로 사람에 의존적이라는 한계가 있습니다. 최근에는 agent-agnostic한 상호작용 trajectories를 명시적으로 추출하는 연구도 진행되었으나, 이렇게 추출된 모션은 픽셀 공간에서 2D 벡터로 단순화되어 로봇에 직접 적용하기에는 어려움이 있습니다. 따라서, 저자들은 2D 이미지 평면에 국한된 시각적 표현이나 픽셀 수준의 행동 단서를 넘어서, 3D affordance(접촉 지점과 공간 인식을 포함한 상호작용 trajectories)가 다양한 embodiments를 통합하여 로봇이 행동을 인식하고 해석하는 데 핵심적이라고 주장합니다. 그러나 일상적인 사람 비디오로부터 일반적인 3D affordance 정보를 추출하는 것은 여전히 어려운 문제로 남아있습니다.
해당 논문은 대규모의 unlabeled human video로부터 zero-shot robot learning이 가능하도록 하는 것을 목표로 하며, 다음 2가지 질문을 핵심으로 다룹니다.: (1) raw한 RGB human video로부터 어떻게 3D actionable한 지식을 추출할 수 있을지? (2) 이렇게 추출한 지식을 새로운 환경과 새로운 로봇에 안정적으로 zero-shot 방식으로 전이하기 위해서는 어떻게 해야할 지? (1)에 대한 해결로, 저자들은 SfM과 gradient 기반 최적화를 활용하여 실제 영상에서 3D 손 궤적을 추출하는 파이프라인을 제안합니다. 이 파이프라인은 학습된 monocular depth와 기하학적 제약을 결합해 시간적으로 일관된 metric-scale 재구성을 가능하게 하며, 이를 통해 agent-agnostic한 3D affordance 표현으로 contact point와 부드러운 손 trajectories를 복원할 수 있습니다. 또한, (2)를 위해 다양한 학습 데이터에서 풍부한 action을 학습하기 위해 coarse-to-fine 방식의 학습 방식을 도입합니다. coarse한 예측 단계에서 픽셀로부터 high-level의 action을 인식하고, 이후 fine한 예측 단계에서 diffusion 모델에 앞선 단계에서 예측한 결과를 조건으로 이용하여 세분화된 상호작용 trajectories를 생성합니다. 저자들은 test-time 제약 조건을 반영한 미분 가능한 비용 함수를 도입하여 diffusion 기반 sampling을 가이드로 활용하여 상호작용의 타당성과 일반화 가능성을 높이고 최적의 계획을 선택하도록 유도합니다.
저자들은 VidBot 프레임워크를 평가하기 위해 시뮬레이션과 real-world에서 다양한 실험을 진행하였으며, 2D human video만을 활용한 3D affordance 모델이 베이스라인 방식을 능가하는 것을 실험적으로 보였습니다. 또한, 다양한 다운스트림 작업에서 모델이 작동 가능함을 입증하였으며, 제안한 방식이 빠르게 수렴하는 것도 확인하였습니다.
Method
0. Problem Definition
저자들은 이미지 \mathbf{\tilde{I}}와 Depth센서나 foundation model로 구한 metric-scale depth \mathbf{\tilde{D}}로 이루어진 RGB-D프레임과 함께 지시문 \mathcal{l}이 주어졌을 때, contact point \mathbf{c}와 interaction trajectories \mathbf{\tau}로 구성된 affordance \mathbf{a}를 예측하는 것을 목표로 합니다. \mathbf{a}=\{c,\tau\} = \pi(\{\mathbf{\tilde{I},\tilde{D}}\}) 이때, \mathbf{c} \in \mathbb{R}^{N_c⨉3}에서 N_c는 contact point 수, \mathbf{\tau} \in \mathbb{R}^{H⨉3}에서 H는 trajectory 수를 의미합니다.
1. 3D Affordance Acquisition from Human video
저자들은 먼저 사람의 영상으로부터 로봇의 3D affordance 학습을 위해, 움직이는 단안 카메라로 촬영된 각 프레임의 pose를 알 수 없는 3D hand trajectories를 추출하는 파이프라인을 제안합니다.
1-1. Data preparation
언어 description \mathcal{l}과 color 이미지 \{\mathbf{\hat{I}_0}, ..., \mathbf{\hat{I}_T}\}가 주어졌을 때, 먼저 이미지에 SfM(structure from motion)을 적용하여 world 좌표계를 기준으로, 카메라의 내부 파라미터 \mathbf{K}, 프레임별 scale을 모르는 pose \{\mathbf{T_{WC_0}}, ..., \mathbf{T_{WC_T}}\}, sparse landmarks \{\mathbf{_W l_0}, ..., \mathbf{_W l_{N_l}}\}를 추출합니다. 또한, metric depth foundation model(여기서는 depth anything 모델을 사용한 것으로 보입니다.)을 이용하여 각 프레임의 dense depth \{\mathbf{\hat{D}_0}, ..., \mathbf{\hat{D}_T}\}를 구합니다. hand-object 모델과 segmentation을 이용하여 각 프레임에서 사람의 손 mask \{\mathbf{M_0^h}, ..., \mathbf{M_T^h}\}와 손과 접촉한 물체에 대한 mask \{\mathbf{M_0^o}, ..., \mathbf{M_T^o}\}를 구한 뒤, 인페인팅 모델을 이용하여 손을 지운 이미지 \{\mathbf{\hat{I}_0}, ..., \mathbf{\hat{I}_T}\}를 생성합니다.
1-2. Consistent Pose Optimization
카메라 pose를 metric-scale로 보정하기 위해, 모든 프레임에 대한 global scale s_g를 최적화합니다. 구체적으로, sparse landmark를 각 이미지 평면으로 투영한 뒤, 카메라 내부 파라미터와 pose를 이용하여 아래의 식 (1)을 최소화합니다.
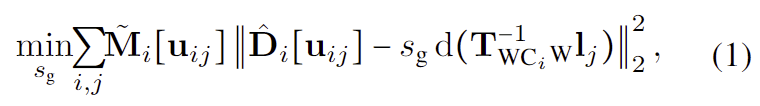
- \mathbf{\tilde{M}}_i = ¬(\mathbf{M^h}_i ⋃ \mathbf{M^o}_i): 손과 물체 영역을 제외한 영역
- \mathbf{u}_{ij}: 카메라 i의 j번째 랜드마크의 픽셀 좌표
- d( \cdot ): 해당 포인트의 3D depth를 의미
즉, 식(1)은 손과 object가 아닌 영역에 대해서 추정한 depth값과 실제 3D Point 사이의 차이를 최소화 하는 방식으로 s_g를 조정하는 것입니다.
이후 모든 프레임의 카메라 pose \mathbf{T_{WC_i}} \in \mathcal{T}와 스케일 파라미터 s_i \in \mathcal{S}를 조정하여 동적인 손과 object로 인한 SfM reconstruction error를 보정하고 동시에 식(2)를 최적화하여 프레임 사이의 depth 예측값을 더 일관성 있게 만듭니다:
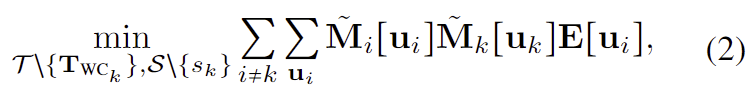
- k: 다른 프레임의 영상과 겹치는 시야가 가장 큰 기준 프레임의 인덱스를 의미함
- \mathbf{E}[\mathbf{u}_i] 로, 카메라 프레임 i와 k 사이의 depth-consistent re-projection error를 의미
- \mathbf{u}_k: 프레임 k에서 \mathbf{u}_i에 대응되는 픽셀
즉, 손과 object를 제외한 영역에서 3D point가 일관적인 위치에 매핑되어있는 지를 측정하는 식으로, 프레임 i에서 예측된 3D point를 기준 프레임인 k 좌표계로 변환한 결과가 프레임 k에서 추정한 동일 지점의 3D point와 얼마나 가까운지를 측정하는 것 입니다.
1-3. Affordance Extraction
각 프레임의 손 중심점을 구하고 이를 정제된 pose와 scale을 활용하여 첫번째 프레임으로 변환하여 상호작용 trajectory \hat{\tau}를 계산합니다. 이후, 첫 번째 프레임의 손 point를 균일하게 downsampling하여 contact points \hat{\mathbf{c}}를 구하고, 마지막 프레임에서 target point \hat{\mathbf{g}}를 구해 affordance model의 중간 예측을 학습할 때 사용합니다.
모델 입력으로는 언어 description \mathcal{l}과 인페인팅 된 이미지 \mathbf{\tilde{I}_0}, 그에 대한 depth \mathbf{\tilde{D}_0}와, 객체 마스크를 이용하여 crop한 뒤 인페인팅한 object 이미지 \mathbf{\tilde{I}^o_0}가 사용됩니다. 파이프라인을 검증하기 위해 EpicKitchens-100 비디오 데이터셋과 그에 대한 SfM 결과를 제공하는 EpicFields를 이용하며, 아래의 Fig. 2를 통해 예시를 확인하실 수 있습니다.

2. Coarse-to-Fine Affordance Learning
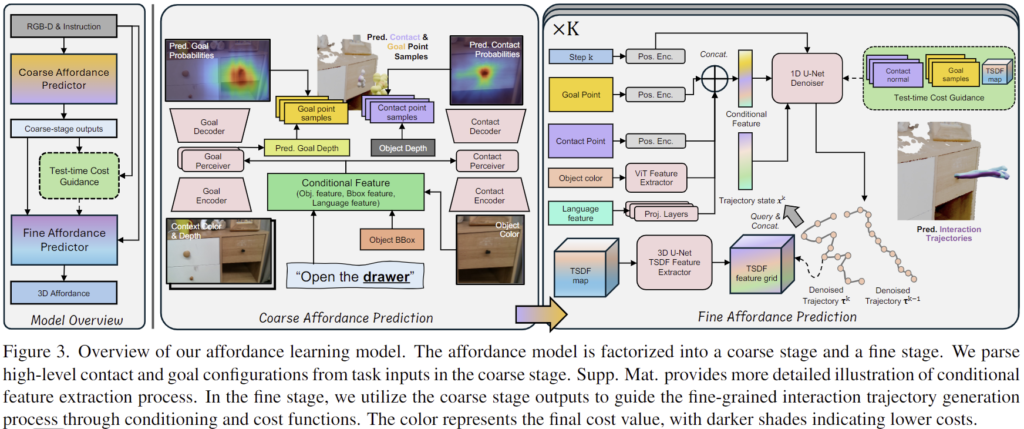
Fig. 3은 해당 논문에서 제안한 affordance model로, 모델 설계 시 다음 두가지 요소를 핵심으로 고려합니다.
- 사람의 행동 분포를 잘 반영해야 함 (데이터 기반 학습)
- 테스트 시점의 맥락 및 embodiment 차이를 고려해야 함 (로봇 적용 가능성 고려)
먼저 첫 번째 요소를 해결하기 위해 저자들은 affordance 예측 모델 \pi를 coarse 모델 \pi_c와 fine 모델 \pi_f로 분해합니다. coares 모델에서는 RGB-D 영상과 언어 description을 기반으로 하여 목표 지점 \mathbf{g}과 contact point \mathbf{c}를 예측하도록 합니다.: \{ \mathbf{g, c} \} = \pi_c(\{\mathbf{\tilde{I}, \tilde{D} }\}, \mathcal{l}), \mathbf{a}_c = \{\mathbf{g,c}\}. 이후 fine 모델을 통해 \mathbf{a}_c와 입력 데이터를 이용하여 low-level의 trajectories \tau = \pi(\{\mathbf{\tilde{I}, \tilde{D} }\}, \mathcal{l}, \mathbf{a}_c)를 생성합니다.
두번째 요소를 해결하기 위해 저자들은 test 시점에 장면에 대한 정보와 embodiment를 고려한 비용함수들을 통합하여 fine 모델에 가이드로 제공하므로써 더 적절한 trajectories를 생성할 수 있도록 합니다. 최종적으로 해당 모델을 통해 contact point \mathbf{c}와 상호작용 trajectories \tau를 출력하게 됩니다.
2-1. Coarse Affordance Prediction
먼저, 해당 과정을 통해 이미지 공간에서 대략적으로 action과 관련된 정보를 추출하게 됩니다. 위의 Fig. 3에서 확인할 수 있듯이 기존 open-set object detector를 이용하여 관심 물체에 대해 crop된 RGB-D 이미지를 취득합니다. 해당 모델은 목표 지점을 예측하는 \pi_c^{goal}과 contact point를 예측하는 \pi_c^{cont} 네트워크 2가지로 이루어집니다.
목표 지점을 예측하는 \pi_c^{goal} 네트워크는 context RGB 영상(물체에 대하여 crop되지 않은 영상)과 대상 물체의 중앙 depth 값으로 채워진 깊이 영상을 함께 입력으로 이용하며, 목표 지점에 대한 heat map과 목표 지점의 depth 정보를 예측합니다. \pi_c^{goal}의 visual encoder로부터 추출된 global context feature z^{goal}은 언어 description에 CLIP을 적용하여 추출한 z_{\mathcal{l}}, RoI Pooling을 통해 추출된 객체 중심의 feature z^{goal}_o, 객체에 대한 Bbox 정보를 MLP로 구한 positional feature z^{goal}_b로 이루어진 conditional feature z^{goal}_c = \{ z^{goal}_o, z^{goal}_b, z_\mathcal{l} \}와 함께 Perceiver 모델로 입력되어 여러 self-attention과 cross-attention 블록을 거쳐 condition feature와 연관된 영역에 집중하도록 융합하고, 융합된 feature는 transformer encoder와 MLP 레이어를 통과화여 global depth를 예측하고, visual decoder로 전달되어 픽셀별로 목표 지점일 확률을 예측하게 됩니다.
contact 지점을 예측하는 \pi_c^{cont} 네트워크는 object 영역이 crop된 이미지를 입력으로 받아 contact point에 대한 heat map과 depth를 추정하는 것을 목표로 합니다. \pi_c^{cont}의 visual encoder로부터 추출된 object contact feature z^{cont}는 언어 description에 대한 feature z_{\mathcal{l}}만을 결합에 사용하며, contact point의 dpeth를 예측합니다. 최종적으로 두 heat map들로부터 샘플링된 픽셀 좌표들을 내부 파라미터를 이용하여 3D 좌표로 올려 coarse affordance output인 목표 지점 \mathbf{g}와 contact point \mathbf{c}를 얻게 됩니다.
2-2. Fine Affordance Prediction
fine affordance model은 목표 지점과 contact point에 따라 세분화된 상호작용 trajectories를 추정하게 되며, 이 과정에는 conditional diffusion을 이용합니다. 먼저 두 heat map에서 확률이 가장 높은 점들을 \mathbf{\bar{g}, \bar{c}}구하고, object가 crop되어있는 이미지를 ViT를 통과시켜 object feature embedding z^{fine}_o를 구합니다. 이 feature는 z_\mathcal{l}를 transformer encoder와 MLP를 통과시켜 얻은 feature, 목표 지점과 contact point에 대한 positional encoding된 features와 함께 하나의 conditional embedding \mathbf{o}로 구성합니다.
이렇게 구성된 conditional embedding을 trajectory 추론시 공간 정보를 고려하도록 통합하기 위해 3D U-Net을 이용해 RGB-D 정보로부터 획득한 TSDF map \mathbf{U}에서 C-차원의 latent feature를 인코딩하고, denoising된 trajectories \tau^k에서 각 point들에 대한 공간적 feature \mathbf{f}^k \in \mathbb{R}^{H⨉C}를 계산합니다. \tau^k와 \mathbf{f}^k는 concat하여 fine affordance 모델 \pi_f에 입력됩니다. 여기서 \pi_f는 각 단계 k에서 노이즈가 없는 trajectory \bar{\tau}^0를 예측합니다.
3. Cost-Guided Trajectory Generation
목표 지점 \mathbf{\bar{g}}에 오차가 있을 수 있으므로, 저자들은 여러 목표 지점들을 사용하여 더 다양하고 강력한 예측을 수행하고자 하였습니다. 그러나 서로 다른 목표 지점을 sampling 하기 위해서는 affordance model을 여러번 연산해야하므로 비효율적입니다. 따라서 ,저자들은 multi-goal conditioning을 cost fuction으로 도입하여 test시에 trajectory에 guide를 제공할 수 있도록 하였습니다. multi-goal cost function은 아래의 식으로 정의가 되며, 이는 여러 후보 goal point 중 trajectory의 끝 점과 가 달라질 때 마다 trajectories의 최종 point와의 오차가 최소인 경우의 오차 제곱을 구하는 것 입니다.
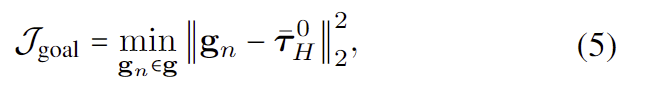
- \bar{\tau}^0_H: trajectorie의 끝 점
- \mathbf{g}_n: n번째 goal point
추가로, 저자들은 충돌 회피와 접촉하는 물체 표면과 법선 방향이 되도록 하기 위한 추가적인 가이드 \mathcal{J}_{collision}과 \mathcal{J}_{normal}를 정의하였습니다.
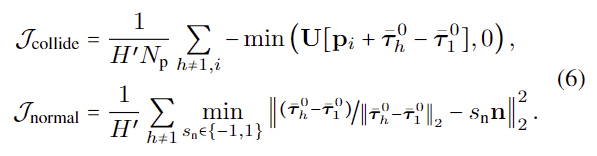
- N_p: 에이전트의 손과 물체의 표면에서 샘플링하는 point 수
- \mathbf{p}_i: 샘플링 된 각 point
- \mathbf{n}: contact point로부터 계산된 법선 벡터
- 여기서, trajectorie의 시작점은 최적화지 않으므로 H'=H-1로 정의합니다
최종적으로 test 시 guidance는 가중합된 형태로 정의가 됩니다.
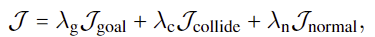
denoising 단계에서 reconstruction guidance를 적용하여 \mathcal{J}에 대한 \tau^k의 기울기를 이용하여 예측된 trajectories \bar{\tau}^0를 조정하여 guided trajectory \tau^0를 구합니다.
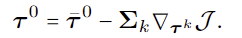
이러한 guidance를 도입하므로써, trajectories는 fine affordance model을 통한 많은 forward pass 없이도 goal 분포를 더 잘 포착할 수 있고, 새로운 embodiment 형태와 unseen 객체의 구조적 특성까지 고려할 수 있어 충돌 없이 작업을 위한 trajectories를 생성할 수 있으며, 이를 전체 downstream planning으로 통합할 수 있습니다. 또한, 각 trajectory에 대한 최종 cost \mathcal{J}는 에이전트가 최적의 계획을 수립할 수 있도록 하는 유용한 기준이 됩니다.
Experimetns
저자들은 실험을 통해 (1) zero-shot 로봇 manipulation 작업에서 여러 강력한 베이스라인보다 뛰어난 성능을 달성하였으며, (2) 최적의 성능을 보장하기 위해서는 coarse affordance prediction과 test-time cost-guidance가 모두 중요하고, (3) 여러 다운스트림 로봇 학습에서 성능 향상이 가능하며 (4) 실제 로봇 시스템에 원활하게 배포할 수 있음을 보이고자 하였습니다.
Results
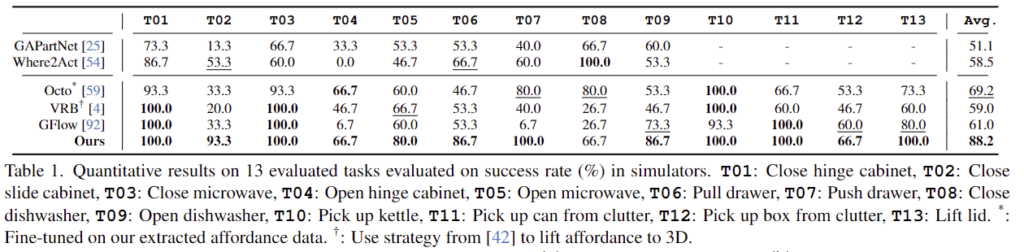
먼저 기존 연구들을 간략히 설명드리자면, 위의 GAPartNet과 Where2Act는 시뮬레이션 데이터로 학습되었으며, Octo는 대규모 teleoperation 데이터, VRB, GFlow와 Ours는 human video로 학습된 모델 입니다. 저자들은 해당 실험을 통해 평균 88.2%의 높은 성공률을 달성하였으며, 2번째로 높은 Octo에 비해 약 20% 개선이 이루어졌음을 어필합니다.
Ablation Study
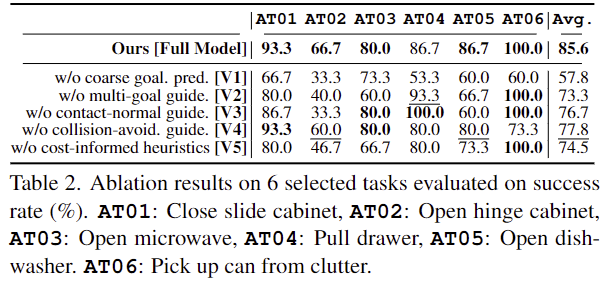
표 2는 저자들이 제안한 설계에 대한 효과를 검증하기 위한 것으로, V1은 단순히 fine trajectories prediction만이 있으며, V2~V4는 guidance마다 효과를 검증하기 위한 실험입니다. V5는 최종 guidance cost를 이용하는 대신 임의의 trajectorie를 이용한 실험 결과입니다. V1을 통해 85.6% → 57.8%로 성능이 크게 저하되는 것을 확인할 수 있으며, 이를 통해 직접적으로 세분화된 trajectories를 예측하는 것이 어렵다는 것을 확인할 수 있습니다. V2~V4를 통해 저자들은 multi-goal guidance가 가장 큰 성능 개선을 이루었음을 확인하였으며, V5를 통해 최종 guidance cost가 최적의 plan을 생성하는 데 큰 영향을 줄 수 있음을 확인하였습니다.
Real Robot Experiments

실제 모바일 로봇 플랫폼인 Hello Robot Stretch 3과 Boston Dynamics Spot에 대해 저자들의 프레임워크가 적용 가능한지 실험을 진행합니다. 두 로봇은 RGB-D 카메라가 구축되어있으며, 조작에 대한 언어 지시를 받았을 때 이에 대한 작업을 수행하도록 하였습니다. 작업은 서랍 밀기, 캐비닛 열기, 휴지 뽑기와 같은 가사일로, 전체적으로 로봇은 55번의실험에서 80%의 성공률을 달성하여 embodiment-agnostic한 특성과 zero-shot으로 전이가 가능함을 입증하였습니다. (프로젝트 페이지에서 데모 영상으로 확인해주세요.)
안녕하세요 좋은 리뷰 감사합니다
제가 생각하는 sfm은 고정된 한 씬에 대해서 멀티뷰의 이미지를 가지고 재구성 할 수 있다고 알고있는데요, 지금처럼 비디오의 계속해서 변하는 프레임을 대상으로 sfm을 적용했을 때는 어떤 결과가 나오기를
기대하고 진행하는 것인지 궁금합니다.
그리고 sparse landmark라는게 정확히 무엇을 의미하고 사용하는 목적이 무엇인가요 ?? 이미지마다라고 표현해주셨는데 유저마다 임의로 이미지에서 정할 수 있는것인지 아니면 사전 정의되어 있는 것인가요 ??
감사합니다
질문 감사합니다.
저자들은 정적이지 않은 영상에 대한 SfM을 수행하므로, 이에 대해 식(2)를 통해 보정하고자 하였습니다. 해당 식은 손과 물체를 제거한 영역에서 3D Point가 일치하는지를 측정하는 것으로, 해당 식을 통해 보정하는 것 입니다. 어찌보면 의도했다기보다 이는 3D reconstruction을 수행하려다보니 따라온 한계에 해당하고 이를 보완한 것으로 이해하였습니다.
정확히 논문에서 언급하고 있지는 않지만 여기서 의미하는 sparse landmark는 SfM에서 구한 landmark를 의미하는 것으로 보입니다.
어려운 논문인데 리뷰 작성해주셔서 감사합니다.
몇가지 질문 남기고 가겠습니다.
Q1. 수식 1에서 랜드마크는 SfM 수행 시 추출되는 visual feature인가요?
Q2. 2-1과 2-2에서 사용하는 loss는 무엇인가요? 뭘 보고 학습하는 건지 궁금합니다.
Q3. 2-2에서 tau와 f에 붙는 k의 의미는 무엇인가요?
Q4. 수식 5와 6에 대해서 이해해보려고 했는데… 어려운 것 같네요. 설명 한번만 부탁드려도 될지… 하하…
질문 감사합니다.
A1: 네 말씀하신대로 SfM에서 추출된 landmark를 의미하는 것으로 보입니다.
A2: 우선 2-1은 goal point에 대한 heatmap과 depth값, contact point에 대한 heatmap을 예측하게 됩니다. 2-1 과정에 대한 loss도 2가지로 이루어집니다. 먼저 goal point에 대한 loss로, GT target point에 대하여 가우시안을 적용한 뒤 BCE loss를 구하고, goal point에 대한 depth 예측값과 정답 값에 대한 L2 loss를 구합니다. 추가로 하나의 보조 term이 있는데, 이는 supplement에 있다고 하는데, 열심히.. 찾아봤지만 찾지 못하였습니다… 또한, contact point에 대한 loss는 GT contact point에 대하여 가우시안을 적용한 뒤 예측한 heatmap과 BCE loss를 구하고, 마찬가지로 보조 term을 함께 loss로 이용합니다.
2-2의 경우는 trajectorie에 대하여 L2 loss를 이용합니다.
A3: tau와 f에 붙는 k는 diffusion에서 k번째 step을 의미합니다.
A4: 식(5)는 여러 goal과 그에 대한 diffusion의 예측 결과가 있을 때, 가장 오차가 작은 goal과 그에 대한 trajectory를 이용한다는 것 입니다.
식(6)도 이러한 측면으로 제안된 것 으로, J_collide는 trajectory 상의 모든 지점에서 손이나 물체가 TSDF map을 기준으로 환경과 충돌하지 않도록 하는 식 입니다. TSDF 값이 음수일 경우 장애물 내부를 의미하므로 충돌이 일어난 상황이고 이를 이용하여 가이드를 제공하는 것 입니다. J_normal은 trajectory 방향이 물체 표면의 법선 방향과 일치하도록 하는 것 입니다. 이는 물체를 잘 잡을 수 있도록 물체 표면에 수직한 방향으로 그리퍼가 들어오도록 가이드를 제공한 것으로 이해하였습니다.