
1. Introduction
여러 프롬프트를 사용하는 SAM은 대표적인 VFM으로서 genaralization 능력을 갖추었다고 평가받고 있습니다. 그러나 SAM은 billon 단위의 대규모 RGB 이미지 마스크만으로 학습되어 다른 비전 센서 모달리티를 다루는데는 어려움이 발생합니다. 그래서 여러 센서를 상호보완적으로 사용하는 멀티 모달 데이터의 사용이 증가하는 현재 SAM의 적용이 제한적이게 되죠. 복잡하고 dynamic하게 변하는 실제 환경에서 다양한 센서를 활용하여 인지 분야의 강인성을 향상시키기 위해서는 SAM을 RGB 카메라 이상의 범위로 확장하는 것이 중요할 것 입니다.
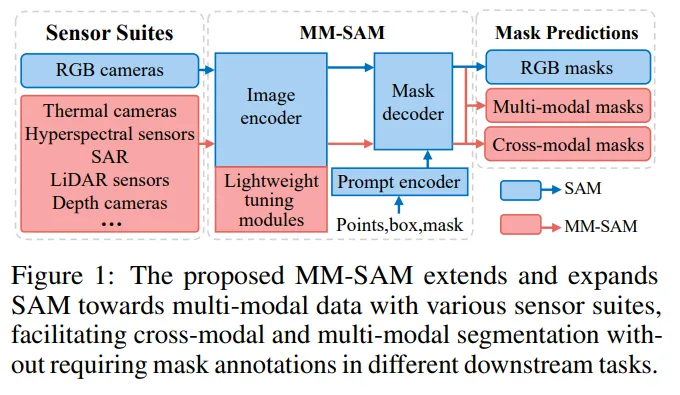
이를 위해 본 논문에서는 다양한 비전 센서에서 취득한 멀티 모달리티의 데이터를 SAM에 활용할 수 있도록 확장한 Multi-Modal SAM을 제안합니다. 위의 Fig.1을 보면 ligtweight한 모듈을 통해 사전학습된 SAM을 tuning하여, 각각의 센서 모달리티를 위한 cross-modal segmentation과 센서 융합을 통한 멀티 모달리티 segmentation을 수행할 수 있도록 하였습니다. 이러한 멀티 모달리티 데이터 활용을 위해 MM-SAM에서는 SAM을 아래와 같이 해결하였다고 합니다.
- cross-sensor heterogeneous 데이터에 SAM 적용
- 본 논문에서는 SAM의 이미지 인코더에 모달리티별 패치 임베딩 모듈과 파라미터 튜닝을 추가하여 각 센서의 feature을 추출할 수 있는 Unsupervised Cross-Modal Transfer (UCMT) 모듈을 설계하였습니다.
- UCMT는 기존 SAM의 이미지 인코더의 latent space 내에서 센서 간에 통합된 하나의 representation을 위한 embedding unification loss가 포함되어 있습니다. 이를 통해 변하지 않는 기존 SAM의 프롬프트 인코더와 마스크 디코더와의 호환이 가능해집니다.
- 간단하고 lightweight한 UCMT를 통해 MM-SAM이 각 모달리티 데이터에 대해서 RGB 이미지에서와 같이 뛰어난 segmentation이 가능해졌다고 합니다.
2. 센서 fusion을 위한 SAM 활용
- 저자는 멀티 모달 임베딩에서의 adaptive한 센서 fusion을 위해 경량화된 selective fusion 게이트를 가진 Weakly-supervised Multi-Modal Fusion (WMMF)을 설계하였습니다.
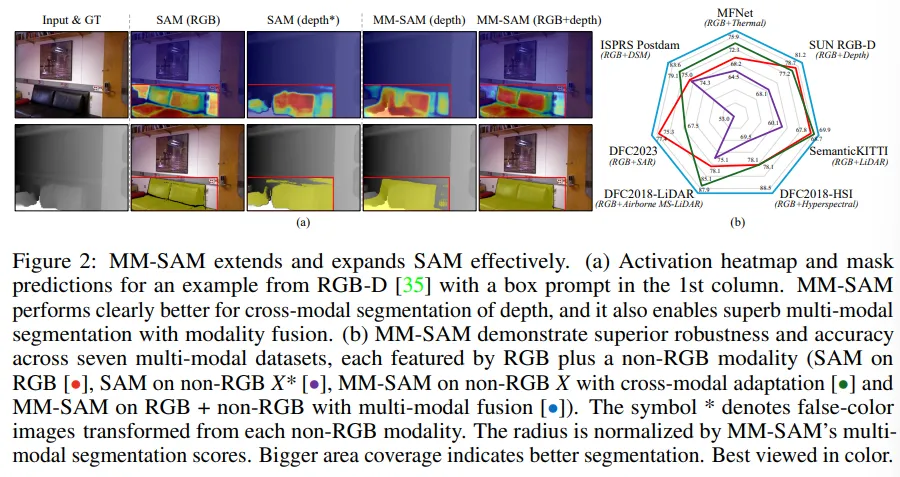
- Fig.2를 보면, seletive fusion 게이트는 복잡하고 dynamic한 환경에서 센서 fusion을 하여 개별적인 모달리티만을 사용하였을 때 보다 segmentation의 강인성과 정확도를 향상시킬 수 있었습니다.
3. 다양한 센서에 대한 라벨 효율적인 SAM adaptation
- MM-SAM은 adaptation을 위한 마스크 annotation이 필요하지 않은데요, 특히 UCMT는 센서마다의 라벨이 없는 데이터를 그대로 활용하지만 WMMF는 pseudo 라벨링을 적용하여 주어진 프롬프트로 fusion gate를 학습하게 됩니다.
추가적으로 MM-SAM은 일반화되고 다양한 adaptation 파이프라인 역할을 하면서 여러 센서에서 cross-modal 및 multi-modal segmentation에 대한 좋은 성능을 보여주고 있습니다.
2. Methodology
2.1. Preliminaries
Sensor Suites with Modality Pairs
sensor suite는 여러 센서를 하나로 구성한 센서팩을 의미하며, 다양한 모달리티의 데이터를 취득할 수 있습니다. 본 논문에서는 여러 센서 중에서도 RGB 카메라와 LiDAR 센서 그리고 열화상 카메라와 같은 비전 센서에 초점을 맞추었다고 합니다. 하나의 센서팩으로 취득한 멀티 모달리티의 데이터는 페어한 쌍으로 이루어지게 되는데, 동기화 여부에 따라 두 가지 유형으로 나뉘게 됩니다. 첫번째로는 Time-synchronized suites로 통합 플랫폼 안에서 여러 센서에 대한 캘리브레이션을 진행하여 동시에 데이터를 수집할 수 있고, 두번째는 Time-asynchronous suites는 서로 다른 플랫폼에서 취득하는 시간과 disparity가 다르지만 기하학적인 좌표를 통해 align된 데이터를 취득하는 센서팩이 있습니다. 이러한 내용을 활용한 데이터셋에 대해서는 section 3.1.에서 더 자세하게 다룬다고 하네요.
2.2. MM-SAM
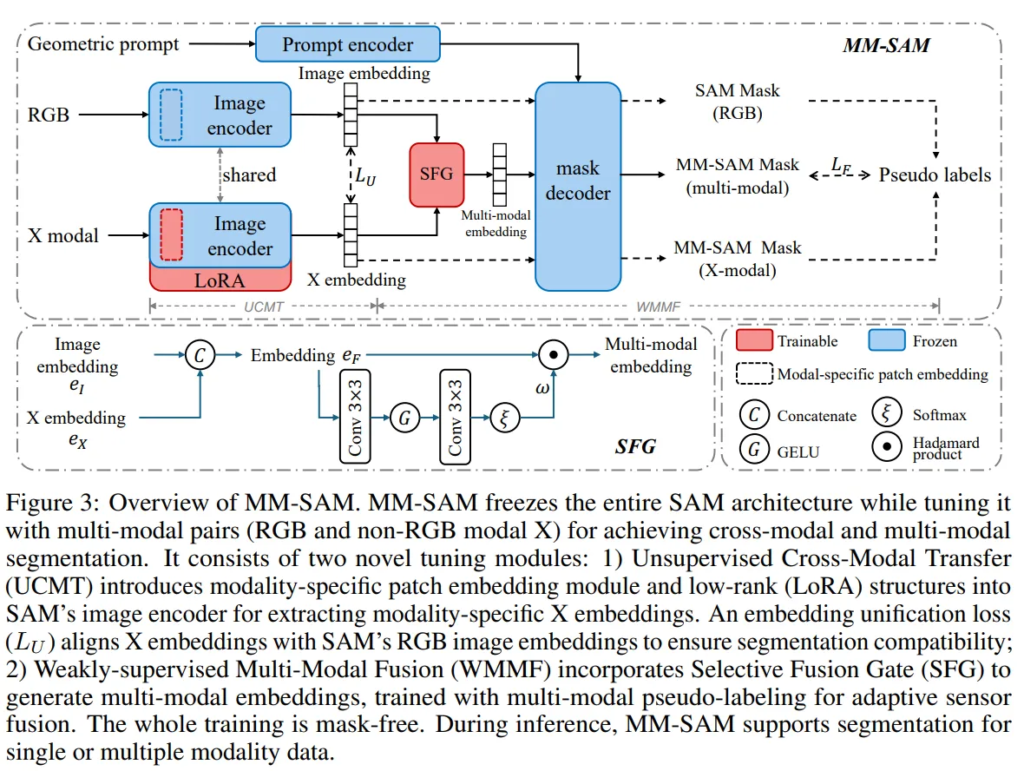
MM-SAM의 가장 큰 목적은 SAM이 다른 모달리티 데이터에 대해서도 segmentation 할 수 있도록 이미지 인코더를 변형하는 것 입니다. 그러기 위해서는 adaptive 이미지 인코더가 모달리티별 임베딩을 효과적으로 인코딩하고, cross-modal segmentation을 위해 SAM의 프롬프트 인코더, 마스크 디코더와 잘 통합될 수 있어야 합니다. 이를 위해 본 논문에서는 RGB가 아닌 모달리티의 임베딩을 pair한 RGB 이미지 임베딩 공간과 align을 맞추어 SAM의 이미지 인코더가 latent space 안에서 센서 모달리티 간에 통일된 representatation으 가질 수 있도록 합니다. 이러한 방식은 3가지 장점이 있다고 주장하는데요, 1) 프롬프트 인코더와 마스크 디코더는 변경하지 않고 이미지 인코더만 변형하여 SAM의 기존 구조에서 파라미터가 추가되는 것을 최소화하였습니다. 2) 다른 모달리티 간에 기존 RGB 이미지와 같이 large scale의 학습 데이터를 확보하는 것이 거의 불가능하기 때문에 billion 단위의 RGB 마스크로 사전학습된 SAM의 이미지 인코더를 잘 활용하게 됩니다. 마지막으로 3) 센서 모달리티 간에 통합된 임베딩 공간을 형성함으로써 멀티 모달리티 fusion을 최대한 간단하게 수행할 수 있습니다.
이러한 장점을 가진 MM-SAM의 전체적인 파이프라인은 Fig.3과 같습니다. freeze된 SAM 구조를 베이스로 한 MM-SAM은 두 가지 주요 모듈이 있는데요, 바로 cross-modal segmentation을 위한 UCMT, 그리고 multi-modal segmentation을 위한 WMMF로 구성되어 있습니다.
2.2.1. Cross-Modal Segmentation with UCMT
Fig.3을 다시 보면, 센서 모달리티가 (I, X) 형태로 들어오는데, 여기서 I는 RGB 이미지를 나타내고, X는 다른 모달리티 데이터를 의미합니다. SAM이 RGB 이미지를 처리하는 방식과 유사하게 X는 reoslution이 동일한 고정된 크기의 패치로 우선 나눕니다. X를 처리하기 위해 ViT 구조의 시작 부분에 learnable 패치 임베딩 모듈을 도입하여 칩력 채널을 X와 일치하도록 조정하는 동시에 출력 채널은 RGB 이미지용 SAM의 원래 패치 임베딩 모듈과 일치하도록 구성합니다. 또한 백본 네트워크에 효율적인 fine tuning 구조를 추가하여 X의 모달리티별 feature을 adaptive하게 인코딩할 수 있도록 하였습니다.
일단 (l,X)가 임베딩 e_I, e_X로 인코딩되면, UCMT는 여기서 unsupervised 임베딩 공간 통합을 통해 learnable한 파라미터를 최적화하게 됩니다.
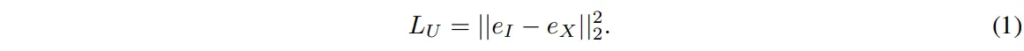
L_U를 최소화하는 방식으로 학습하면 X 모달리티 임베딩이 SAM의 이미지 인코더에서 설정된 RGB 이미지 임베딩 공간과 유사하게 align이 맞춰집니다. 이러한 alignment는 RGB 이외의 다른 모달리티와 SAM의 프롬프트 인코더 및 마스크 디코더와의 호환성을 유지하고 SAM의 segmentation 파이프라인에 원활하게 합쳐질 수 있는 역할을 합니다.
2.2.2. Multi-Modal Segmentation with WMMF
다음으로 WMMF는 UCMT와 유사하게 이미지 인코더의 출력 임베딩 공간에서 동작하는 모듈로, 여러 센서 모달리티의 데이터를 fusion하여 임베딩 공간을 생성합니다. 가장 중요한 것은 모든 입력 센서 모달리티에 따라 패치별로 가중치를 다르게 생성하여 pair된 임베딩의 가중치를 fusion하는 것이 가능하다는 점 입니다. 이를 통해 다양한 환경에서 adaptive한 센서 fusion과 multi-modal segmentation이 가능해집니다. Fig.3을 보면, WMMF는 fusion을 위한 selective fusion gate(SFG)와 mask-free 학습을 위한 multi-modal pseudo-labeling 과정으로 이루어져 있습니다.
Selective Fusion Gate (SFG)
e_I와 e_X를 가지고 새로운 임베딩 e_F을 생성하고 이를 2개의 convolution layer + softmax로 구성된 가중치 필터로 전달하게 됩니다. 전달하고 나서의 output은 결국 가중치 w를 적용한 것이고, 임베딩 e_F의 패치별 weighted average하여 식(2)처럼 multi-modal 임베딩 \hat{e}_F를 생성하는 것이죠.
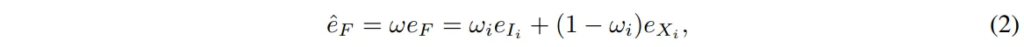
- i : 패치 인덱스
이렇게 생성한 \hat{e}_F는 SAM의 프롬프트 임베딩과 합쳐져서 마스크 디코더에 함께 제공되어 refine된 예측 마스크 \hat{M}_F를 얻을 수 있습니다.
Multi-Modal Pseudo Labeling
그 다음은 pseudo labeling인데요, supervised 학습은 간단하지만 다들 아시다시피 cost가 많이 들게 되니 이를 해결하기 위해, 본 논문에서 pseudo labeling을 설계한 것 입니다.
먼저 프롬프트가 주어지면, RGB와 다른 모달리티 데이터로부터 각 두 개의 단일 모달리티 예측 마스크 M_I와 M_X를 생성합니다. 그 다음 이 두 예측을 fusion하여 refine된 예측 마스크 M_F를 만들게 됩니다.
pair한 모달리티의 패치에서 가장 확실하다고 예측된 패치를 선택하여 M_F를 만들고, 이를 SFG 학습을 위해 pseudo GT로 사용하는 것 입니다.
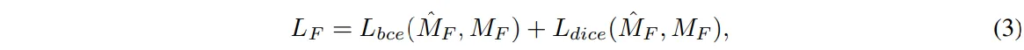
- \mathcal{L}_{bce} : BCE loss
- \mathcal{L}_{dice} : dice loss
MM-SAM의 전체 fine tuning을 하는데 있어서 사용하는 loss를 정의하면 식(4)와 같습니다.
Expanding MM-SAM to Include More Sensor Modalities
위의 과정까지는 simplicity를 위해 두 가지 모달리티가 들어올 때의 경우에 초점을 맞췄지만 MM-SAM은 그보다 더 많은 모달리티에 대해 fusion 가중치를 생성하기 위해 SGF를 확장하여 추가적인 모달리티를 통합할 수가 있습니다. 이는 실험 섹션에서 증명하였다고 하네요.
2.2.3. Training and Inference
학습 중에는 사전학습된 SAM 파라미터는 freeze하고, 새로 추가된 learnable 파라미터만 두 단계에 걸쳐서 업데이트 됩니다. UCMT 학습이 pair한 모달리티가 이미지 인코더의 입력으로 들어가서 진행되고, WMMF에서 제공된 프롬프트를 통해 SFG만 업데이트 되게 됩니다.
inference 시에는 MM-SAM은 단일 모달/multi 모달 데이터인 경우에 대해서 모두 segmentation이 가능합니다. cross modal segmentation의 경우, 이미지 인코더에서 인코딩된 X 모달리티에 대한 임베딩은 마스크 예측을 위한 프롬프트와 함께 마스크 디코더로 직접 입력으로 들어가게 됩니다. multi modal segmentation은 SFG가 다양한 모달리티의 임베딩을 fusion하여 이미지 인코더의 최종 임베딩을 생성하게 됩니다.
저자는 여기서 MM-SAM에 대해 두 가지 카테고리로 나누어 주목할만한 특성을 정리하고 있습니다.
Remark (Efficiency)
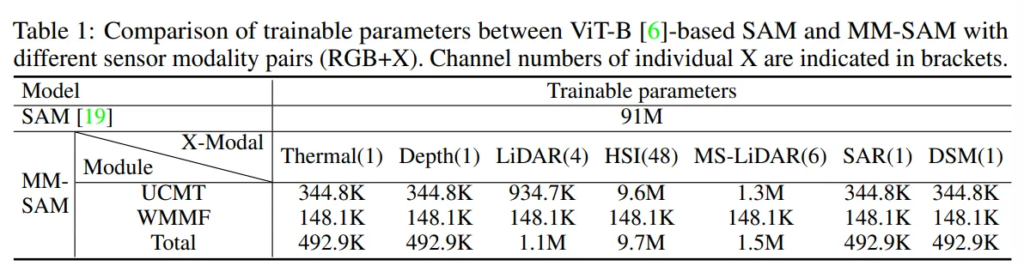
- Parameter Efficiency
- Tab.1을 보면, 다양한 데이터 모달리티에 대해서 SAM과 MM-SAM의 learnable 파라미터를 비교한 것인데, MM-SAM이 최대한 제한적으로 파라미터를 추가한 것을 확인할 수 있습니다.
- Label Efficiency
- MM-SAM의 전체 tuning 과정에서는 마스크 어노테이션이 필요하지 않습니다. UCMT는 라벨이 없는 모달리티 데이터 쌍만 가지고 unsupervised 방식으로 동작하며, WMMF는 마스크 어노테이션이 아닌 프롬프트만을 사용하여 weakly supervised 방식으로 동작하게 되죠.
Remark (Insights)
저자가 말하길, 센서의 종류에 따른 VFM 연구를 수행한 것은 본 논문이 처음이라고 합니다. 그 과정에서 얻은 Insight를 공유하고자 한다는데요,
- MM-SAM은 SAM의 이미지 인코더의 latent space를 센서 모달리티 간에 공유가 가능하다는 가능성을 보여주고 있습니다.
- 공유된 latent space는 센서 fusion을 가능하게 하고, 이에 MM-SAM은 다양한 센서 모달리티의 임베딩에 adaptive하게 가중치를 부여하여 segmentation의 능력을 향상시킬 수 있었습니다.
- MM-SAM은 굉장히 일반화된 프레임워크이기 때문에 다양한 센서 타입에 적용할 수 있고, VFM과 센서 fusion 연구에 추가적인 길을 제시하고 있다고 합니다.
3. Experiments
3.1. Experiments Setup
데이터셋은 앞선 Premilinaries에서 이야기한대로 time-synchronized suites와 time-asynchronous suites 이렇게 두 가지 범위 안에 있는 센서에 대해서 평가하였다고 합니다.
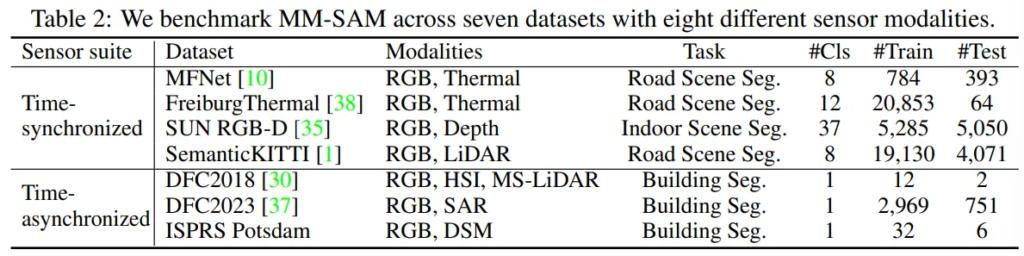
Tab.2를 보면, depth map, 열화상, 라이다, MS-LiDAR, HSI, SAR 등등 .. 저희가 익히 아는 비전 센서 뿐만 아니라 정말 다양한 RGB가 아닌 모달리티를 포함하는 7가지 데이터셋에서 평가하였습니다.
3.2. Segmentation Results
3.2.1. Time-Synchronized Sensor Suites

Tab.3은 시간 동기화가 된 센서에 대해서 SAM과 MM-SAM의 segmentation 결과를 보여주고 있습니다. MM-SAM은 멀티 모달 뿐만 아니라 RGB 외 모달리티에 대해서 single 모달로도 평가합니다. SAM 같은 경우는 비RGB 모달리티보다 RGB 이미지에서 훨씬 더 높은 성능을 보여주고 있는데요, 반대로 MM-SAM은 동일한 비RGB 모달리티에 대해서 SAM보다 훨씬 개선된 성능을 보이는 것을 확인할 수 있습니다.
특히 MFNet과 SemanticKITTI에서 열화상 이미지와 라이다 포인트 클라우드에 대한 실험 결과는 SAM의 RGB 이미지 결과보다도 좋은 성능을 보이며 비RGB 센서를 잘 활용하는 모델을 설계하였을 때 도드라지는 비RGB 센서의 강점을 강조하고 있습니다.
또한 single 모달리티만 단독으로 사용할 때 보다 fusion에서 더 높은 성능을 보이며, 동기화가 된 센서를 사용하여 fusion하였을 때의 robust함을 보여주고 있습니다.
3.2.2. Time-Asynchronous Sensor Suites
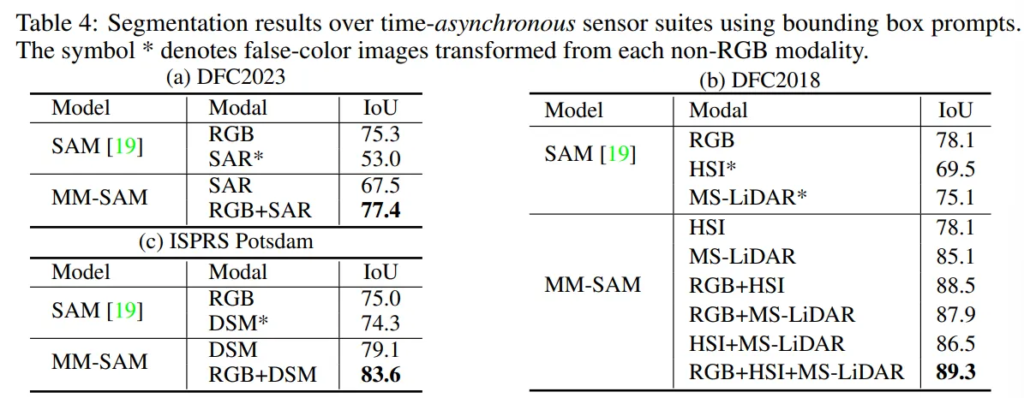
이번엔 시간 동기화된 센서보다 좀 더 까다롭다고 볼 수 있는 비동기식 센서에 대한 평가 결과 입니다. 센서가 스캐닝 하는 각도와 resolution에 서로 시간 간격이 있어 모달리티 간에 alignment가 맞지 않는 데이터셋에 대해 평가하였다고 합니다.
특히 Tab.4(b)는 비동기식 3개의 센서가 포함된 데이터에 대해서 실험하였는데요, 3개 센서의 모든 조합에서 안정적인 segmentation 성능을 보이고 있습니다. 특히 세 가지 모달리티를 모두 합쳤을 때 두 개의 모달리티만 사용한 경우, single 모달리티를 사용한 경우의 결과를 모두 뛰어넘는 성능을 보이는 것을 확인할 수 잇습니다.
이를 통해 MM-SAM의 모달리티 확장성을 강조하고 있고, 추가적인 센서를 더 사용하면서 일반화 능력을 갖출 수 있음을 입증하고 있습니다.
3.3. Discusion and Analysis
Visual Analysis of Selective Fusion Gate (SFG)

멀티 모달리티의 입력에 따라 SFG가 여러 센서의 가중치를 adaptive하게 조절하는 방식을 Fig.4와 같이 정성적으로 나타내어 분석하였다고 합니다.
해당 데이터에서 자동차의 상향등으로 인해 빛이 발생하여 RGB 이미지에서 자동차를 segmentation하는 것이 어려운데요, 열화상 이미지는 가시광선의 영향을 받지 않기 때문에 SFG는 이 영역의 열화상 이미지에 대해서 훨씬 더 높은 가중치를 부여하고 RGB 이미지에서는 낮은 가중치를 부여하게 되는 것 입니다.
이러한 adaptive한 가중치 부여를 통해 보다 정확한 segmentation이 가능해지며, real world에서 발생할 수 있는 여러 상황을 고려하였을 때 각 모달리티의 강점을 효과적으로 활용하여 segmentation의 강인성을 향상시킬 수 있다는 것을 보여줍니다.
안녕하세요, 손건화 연구원님. 좋은 리뷰 감사합니다.
RGB 컬러 데이터로 사전학습한 SAM으로 다른 모달리티를 처리할 수 있도록 인코더를 변형했다는 점과, 이것이 잘 동작된다는 점이 흥미롭네요.
질문이 있습니다. 수식 1에서는 X 모달리티의 임베딩을 RGB와 유사하게 align하기 위해서 L2 loss를 사용하는 것으로 보이는데요, 각 modality마다 RGB와 다른 특성을 가지고 있고 RGB와의 특성이 얼마나 다른지도 차이가 있을텐데, 각 모달리티를 RGB와 Align을 맞추면 각 모달리티만의 특성을 잃어버리지는 않는지, 또 각 모달리티를 align하는데 잘 안되는 부분은 없었는지(특정 모달리티는 잘 안됐다던가) 궁금합니다. 혹시 이와 관련된(ablation이라던지) 추가적인 분석이 있었나요?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
말씀하신 것처럼 모달리티 간의 특성이 달라서 단순 정렬이 모달리티 정보를 손상시킬 수도 있습니다. 그래서 해결하고자 제안한게 UCMT 모듈 안에서 modal-specific patch embedding과 LoRA 기반의 transformer tuning을 통해 X 모달리티의 고유한 특성을 먼저 잘 인코딩 한 다음에, 그 표현력을 RGB latent spce로 가져오는 방식을 사용한 것 입니다.
말씀하신 실험은 ablation에는 없고 appendix에서 여러 loss에 대한 실험을 진행하는데요, loss에 따라서는 성능이 크게 차이가 없고 저자는 이러한 결과에 대해 alignment 방식이 특정 모달리티의 표현력을 크게 해치지 않는다는 것을 간접적으로나마 보여줄 수 있는 결과라고 분석하고 있습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
논문에서 시간 동기화가 되지 않아 align이 맞지 않는 데이터에도 잘 동작한다는 것을 어필하고 있다 생각하는데요, 실험적 결과 말고 방법론적으로 이런 align이 맞지 않는 데이터를 위해 추가적인 모듈을 설계하거나 그러진 않았나요 ? 물론 UCMT 모듈에서 L_U를 통해 RGB 이미지 임베딩 공간과 최대한 유사하게 align이 맞도록 한다고 설명되어있긴 하지만 이는 align이 맞춰진 데이터셋에서도 동일하게 동작하는 부분이라는 생각이 듭니다.. !
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
넵 말씀하신 것처럼 alignment가 맞지 않는 상황에서도 잘 작동한다는 걸 어필하지만 그걸 위한 별도의 모듈을 설계한다거나 하진 않았습니다.
대신 X 모달리티와 SAM의 RGB latent 공간으로 alignment를 맞추는 L_U loss를 통해서 feature level에서 어느 정도는 align을 보장할 수 있도록 설계하긴 했습니다. 하지만 방법론 자체가 alignment 맞지 않는 상황에 특화되어 설계되었다기보다는 추가적인 과정 없이도 misalignment를 견딜 수 있는 구조라는 것을 어필한게 아닐까 합니다.
감사합니다.