안녕하세요, 오늘의 X-Review에서는 24년도 CVPR에 게재된 논문 <Open-Vocabulary Video Anomaly Detection>을 소개해드리겠습니다. 논문의 제목이 task의 이름이기에 이 task를 최초로 제안한 논문입니다. 저자가 제안하는 Open-Vocabulary Video Anomaly Detection task는 비디오를 입력받아 프레임 단위의 Anomaly score를 출력해야 하며, 기존 Closed 환경에서는 이진 분류 형태로 이상/정상만을 분류했다면 Open-Vocabulary 환경에서는 이상/정상을 분류하되 이상인 경우 어떠한 이상 상황(절도, 폭행, 화재 등)인지까지 분류하는 task에 해당합니다. 저자에 따르면 본 연구가 최초로 Open-Vocabulary(OV) 환경에서 Video Anomaly Detection(VAD)을 수행하였다고 합니다.
사실 Anomaly detection은 정상/이상만을 분류하는 ‘이진 분류’로 알고있었는데, 대체 이게 어떻게 Open-Vocabulary로 넘어온다는 것인지 궁금하였습니다. 결과적으로 OVVAD는 비디오 내에서 학습한 적 없는 ‘이상 상황’을 프레임별로 분류하는 것으로, 비디오 내에서 사람의 ‘일반 행동’을 찾는 Open-Vocabulary Temporal Action Detection과 유사하되 찾고자하는 클래스가 ‘일반 행동’이 아닌 ‘이상 상황’ 범위에 속하는 것으로 이해해볼 수 있었습니다. (엄밀히 따지면 OVTAD는 구간의 mAP를 측정하고, OVVAD는 프레임 단위의 AUC를 측정하여 평가합니다.)

1. Introduction
VAD는 비디오에서의 이상 사건을 탐지해내야 하는 task로, 학계와 산업계 모두에서 큰 관심을 받고 있는 상황입니다. 특히나 수많은 인적, 시간적 자원을 수반하는 감시 도메인에서 이상 상황을 자동으로 탐지해준다는 것은 큰 효율성을 가져다줄 수 있습니다. 이러한 이유로 VAD는 학계에서도 지금까지 활발히 연구되어왔지만, 기존의 VAD는 학습하지 않는 이상 상황을 제대로 인지하지 못하고 있습니다.
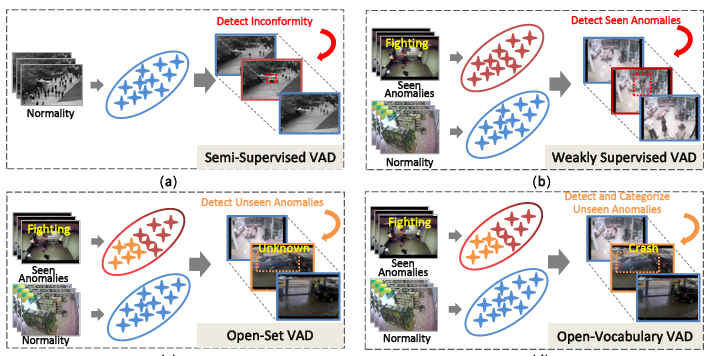
우선 그림 1에서 여러 환경의 VAD 종류를 살펴볼 수 있습니다. 기존의 VAD 연구는 두 갈래로 나뉘는데, 바로 Semi-Supervised(SS)와 Weakly-Supervised(WS) VAD입니다. 두 갈래의 기본적 차이는 바로 학습 때 이상 상황을 마주하냐인데, SS는 정상 비디오만을 학습 때 보고 임베딩 공간 상에서 그들의 분포 범위를 잘 구축해두어 테스트 시 들어오는 프레임이 해당 분포 내에 들어가냐를 기준으로 정상/이상을 구별하게 됩니다. 학습 중엔 여러 Self-supervised 기법을 통해 모델이 정상 비디오의 분포를 최대한 이해하도록 만들어준다고 합니다.
반면 WS는 유사한 이야기일 수 있지만 학습 중 정상/이상 비디오를 모두 보는 이진 분류에 해당합니다. 여기서 이 방식이 Weakly인 이유는 비디오 단위의 라벨이 주어지기 때문입니다. 정상 비디오엔 모두 정상 프레임들만 등장하고, 이상으로 라벨링된 비디오에는 정상 구간/이상 구간이 혼재되어있지만 이상 구간에 대한 정확한 timestamp는 주어지지 않는다는 이야기입니다. 여기선 일반적인 WS 상황에서 많이 활용되는 Multiple Instance Learning 기법이나 Top-K 프레임 활용 기법이 많이 사용되어왔다고 합니다.
위와 같은 두 가지 갈래가 지금까지 크게 발전해오며 학계의 벤치마크에서 높은 성능을 달성한 것은 맞지만, 저자는 여전히 이 모델들이 새로운 이상 상황에 대응하지 못한다는 점을 지적합니다. 이 점을 극복하기 위해 비교적 최근에는 Open-set VAD 방법론이 등장하였는데, 이는 Open-world 환경과 유사하게 학습한 적은 없지만 무언가 이상 상황이 발생하였다 정도로만 모델이 예측하게 됩니다. 즉, 학습하지 않았더라도 이상 상황을 탐지해낼 순 있지만, 그에 대한 의미론적 이해는 부족하여 무슨 상황인진 몰라 ‘Unknown’ 클래스로 분류하게 되는 것입니다. 저자는 여기까지 말씀드린 기존 VAD의 두 갈래와 Open-set 모두 real-world에 적용하기엔 환경상 아직 한계점이 명확하다고 주장합니다.
위와 같은 단점을 보완하고자 저자는 OVVAD 방법론을 제안하게 됩니다. 최근 거대 사전학습 기반의 지식을 갖춘 VLM들이 크게 발전하고 많은 downstream task들에 적용되고 있는데, 저자도 이 흐름에 올라타 VAD를 Open-Vocabulary 환경에서 수행해보고자 하는 것입니다. OVVAD는 기존 연구 갈래와 다르게 학습하지 않았으나 발생한 이상 상황에 대한 풍부한 정보를 줄 수 있다는 장점이 있습니다. 단순 ‘이상 상황’이라고 결과를 출력하는 것이 아니라 실제로 어떤 이상 상황인지 알려줄 수 있다는 의미입니다. 또한 학습하지 않은 클래스를 찾는 것에만 집중하는 것이 아니라 당연히 학습한 이상 상황의 지식 또한 잊어서는 안됩니다.
저자는 먼저 OVVAD를 두 가지 sub-task로 쪼갭니다. 첫 번째는 class-agnostic detection, 두 번째는 class-specific categorization입니다. 마치 2-stage detector처럼 이벤트 상황을 먼저 탐지한 뒤 추후 그 구간이 어떤 이상 상황인지 세부적으로 분류하는 것이죠.
먼저 첫 번째 단계인 class-agnostic detection을 위해 저자는 두 가지 모듈을 제안합니다. 첫 번째는 모델 파라미터를 추가하지 않는 것과 다름없는 weight-free temporal adapter (TA) 모듈이고, 두 번째는 LLM을 통해 추출한 텍스트 정보와 시각적 정보를 엮어줄 semantic knowledge injection (SKI) 모듈입니다.
다음으로 두 번째 단계인 class-specific categorization을 위해 CLIP에서의 방식과 동일한 텍스트-비디오 유사도 측정을 진행하고, 추가적으로 novel anomalies에 대응하기 위한 novel anomaly synthesis (NAS) 모듈도 제안합니다. 위와 같은 방식을 적용해 UCF-Crime, XD-Violence, UBnormal 데이터셋에서 좋은 성능을 달성했다고 합니다. 자세한 내용은 그리 복잡하지 않으며, 방법론에서 자세히 알아보도록 하겠습니다.
2. Methods
Problem Statement.
OVVAD의 학습은 WSVAD와 유사한 환경에서 이루어집니다. 즉 정상/이상 비디오를 모두 활용하되, 프레임 단위의 라벨은 주어지지 않습니다. 학습 샘플 \mathcal{X} = \{x_{i}\}_{i=1}^{N+A}가 주어졌을 때, \mathcal{X}_{n}은 N개의 normal 비디오들, \mathcal{X}_{a}는 A개의 abnormal 비디오들을 의미합니다. 이상 상황 비디오 샘플들 \mathcal{X}_{a}는 각각의 라벨 y_{i}를 갖습니다. 학습 중 보게 될 이상 상황 라벨 y_{i} \in{} C_{base}이며, 평가 시에는 처음 보는 이상 상황 라벨 C_{novel}도 등장하게 됩니다. OVVAD의 목적은 학습 샘플 \mathcal{X}를 잘 학습하여 평가 시 C_{base}, C_{novel} 모두 잘 탐지해내는 것입니다.
2.1 Overall Framework
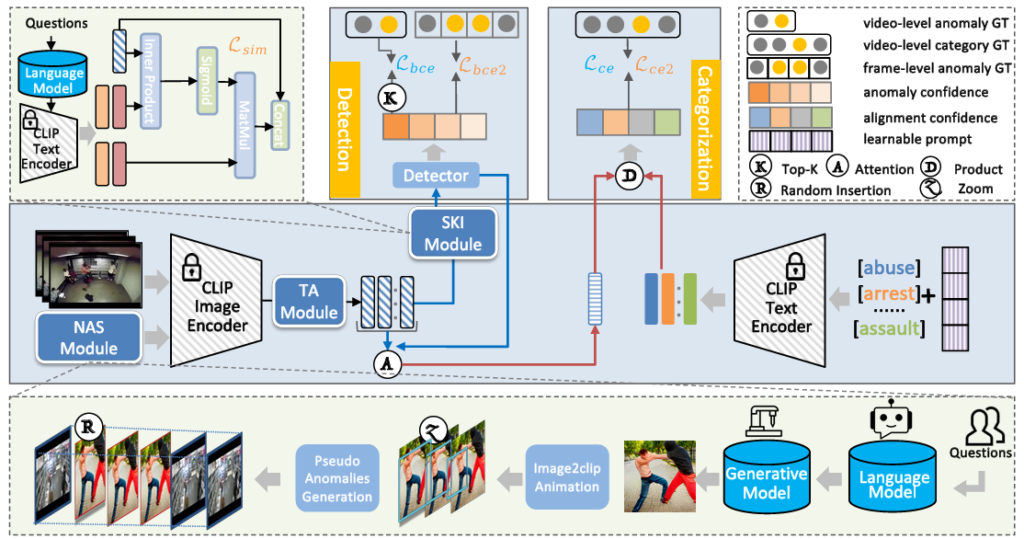
우선 그림 2는 저자가 제안하는 방법론의 전체 프레임워크입니다. 가운데 파란색 줄이 메인 프레임워크이며 앞서 설명드린대로 TA 모듈, SKI 모듈, 왼쪽엔 NAS 모듈이 붙어있는 것을 볼 수 있습니다. 윗 줄에는 SKI 모듈의 구조, class-agnostic detection과 class-specific categorization이 나타나있고, 아랫줄에는 NAS 모듈의 흐름이 그려져있습니다.
학습하지 않은 상황에 대한 탐지를 진행하기 위해 CLIP 모델의 특징을 추출해 활용합니다. CLIP Image Encoder \Phi{}_{CLIP-v}로부터 n \times{} c 형태의 특징 x_{f}를 추출합니다. 여기서 n, c는 각각 프레임 개수, 특징 차원 수를 의미합니다. 이후엔 x_{f}를 TA 모듈, SKI 모듈, detector에 입력해 프레임 별 anomaly score p를 얻게 됩니다.
이후 프레임 단위의 feature를 엮어 video-level feature를 만들고, 사전 정의된 클래스들의 text feature와 유사도를 구해 분류를 수행하게 됩니다. 추가적으로 novel한 이상 상황에 더욱 잘 대응하기 위해 LLM 및 Image Generator (DALL-E)를 활용해 데이터를 합성해 학습하는 과정도 있습니다. 이제 각 모듈에서 일어나는 일들에 대해 간단하게 살펴보겠습니다.
2.2 Temporal Adapter (TA) Module
CLIP을 활용하는 대부분의 비디오 모델이 그렇듯, 부족한 temporal 정보를 채워줄 어댑터를 하나 붙여서 사용합니다. TA 모듈이 바로 그러한 역할이며, 저자는 최소한의 파라미터만을 활용해 시간적 정보를 효과적으로 잡아낼 수 있는 구조를 제안합니다. 시간적 정보를 잘 잡도록 트랜스포머 구조 자체를 변형한 모델들도 많지만, 그보다 효율성을 중시하며 정말 간단한 레이어만을 추가합니다. 더욱이 변형된 트랜스포머 구조는 novel category에 전혀 대응하지 못해 안좋은 성능을 보였다고 하네요.
저자의 표현에 따르면 제안하는 TA 모듈은 nearly weight-free temporal adapter로, 아래 수식과 같습니다.
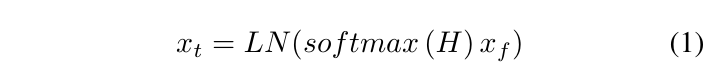
Graph convolution network와 유사하게 동작하는데, 수식에서 H가 바로 프레임 간의 인접 행렬이기 때문입니다. 인접 행렬은 아래 수식과 같이 프레임 간의 시간적 거리를 고려해 결정됩니다.
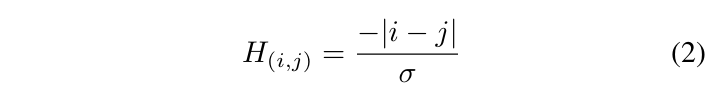
수식 2에서 \sigma{}는 하이퍼파라미터이고 i, j는 비디오에서의 프레임 인덱스를 의미합니다. 결국 TA 모듈에서의 파라미터는 LayerNormalization에 관여하는 파라미터밖에 없기에, 저자의 주장대로 거의 파라미터가 없다고 볼 수 있습니다. 시간적 인접성에 따라 프레임 간 관계에 attention을 준다고 볼 수 있는것이죠.
2.3 Semantic Knowledge Injection (SKI) Module
사람은 ‘불이 났다’라는 것을 인지하기 위해, 직접 ‘불’을 보지 않고 연기와 냄새 정보를 활용할 수 있습니다. SKI 모듈도 마찬가지로 특정 이상 상황을 파악하기 위해 이상 상황과 동반되는 여러 주변 정보를 활용할 수 있도록 만들어준다면 더욱 좋은 탐지 성능을 보여줄 것입니다.
SKI 모듈은 위와 같은 배경을 바탕으로 visual detection을 도울 수 있는 semantic knowledge를 모델에게 주입해주는 역할을 합니다. 추가적인 semantic knowledge는 ChatGPT와 같은 LLM으로부터 추출해줍니다.
- Common scenarios: street, park, shopping hall, walking, running, working, etc.
- Anomaly scenarios: explosion, burst, firelight, etc.
위 단어는 각각 정상/이상에 해당하는 단어이고, M_{prior}라고 칭합니다. 이를 각 상황에 맞는 단어를 추가적으로 설명해달라는 프롬프트를 던져 LLM으로부터 문장을 추출해내고, CLIP의 text encoder로부터 각 문장의 feature F_{text}를 아래 수식과 같이 얻어줍니다. LLM이 각 상황에 대해 내뱉은 출력 예시를 같이 보여줬으면 더 와닿았을텐데 그 부분이 없어 아쉽네요.
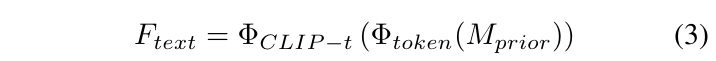
이제 텍스트 feature F_{text}를 프레임별 feature와 융합해줘야 합니다. 이는 F_{text}와 수식 1에서 얻은 프레임 feature x_{t}의 유사도를 기반으로 아래 수식과 같이 수행됩니다. 참고로 F_{text}는 freeze된 CLIP text encoder로부터 얻은 feature이기에, 학습가능한 prompt를 붙여 사용하게 됩니다.
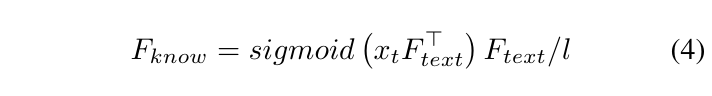
위 수식 (4)와 같이 추가 문장 정보와 비디오 프레임 feature 간 유사도를 기반으로 attention을 한 번 주고, 이렇게 텍스트 정보가 고려된 visual feature F_{text}를 x_{t}와 concat하여 binary detector로 넘겨주게 됩니다. 이 binary detector에서 class-agnostic detection을 위한 anomaly score가 나오게 되는 것입니다.
2.4 Novel Anomaly Synthesis (NAS) Module
본 방법론에서 활용하는 CLIP이 아무리 대용량 데이터셋으로 학습되었다고 해도, 처음보는 이상 상황을 비디오 프레임에서 완전히 이해하기엔 부족함이 있습니다. 저자는 이 점을 보완하고자 novel anomaly 상황에 대한 pseudo training data를 생성하고 학습하는 방식을 NAS 모듈에서 제안합니다.
먼저 사전 정의된 프롬프트 “generate ten shorted scene descriptions about {Fighting} in real world”와 같은prompt_{gen}을 만들어둡니다. 이를 마찬가지로 ChatGPT와 같은 LLM에 입력해 다양한 설명을 얻어냅니다. 예시에서 Fighting은 학습 때 보지 못한 이상 상황의 예시이겠죠. 이후 LLM으로부터 설명을 얻었다면 해당 설명을 DALL-E와 같은 Image generator 모델에 입력해 합성 데이터 V_{gen}을 만들어냅니다. 여기서 V_{gen}은 활용한 모델에 따라 이미지가 될 수도 있고, 짧은 비디오가 될 수도 있습니다.
다음으로 이미지에 center crop을 다양한 비율로 적용한 뒤 모두 동일 사이즈로 resize한 후 이어붙여 비디오 \mathcal{V}_{nas}를 만들어냅니다. 마치 비디오에서 한 장면을 zoom in / zoom out한 것과 같은 효과를 누리는 것이죠. 최종적으로는 학습 데이터에 존재하는 정상 비디오 중간에 임의로 끼워넣으면 정상/이상에 대한 라벨을 만들 수 있고, 이를 학습 데이터 삼아 fine-tune을 진행합니다. 초기에 \mathcal{X}로 학습을 마친 모델을 추가적으로 학습하게 되는 것입니다.
3. Experiments
3.1 Datasets
모델의 평가는 UCF-Crime, XD-Violence, UBnormal 데이터셋에 대해 진행되었습니다. 각 데이터셋마다 이상 상황 카테고리의 일부만을 학습하고, novel로 남겨진 나머지 카테고리는 평가 때 바로 추론할 수 있는지 살펴보게 됩니다. 평가지표로 UCF-Crime, UBnormal은 AUC-ROC, XD-Violence는 AUC-PR을 측정합니다.
3.2 Comparison with State-of-the-Arts
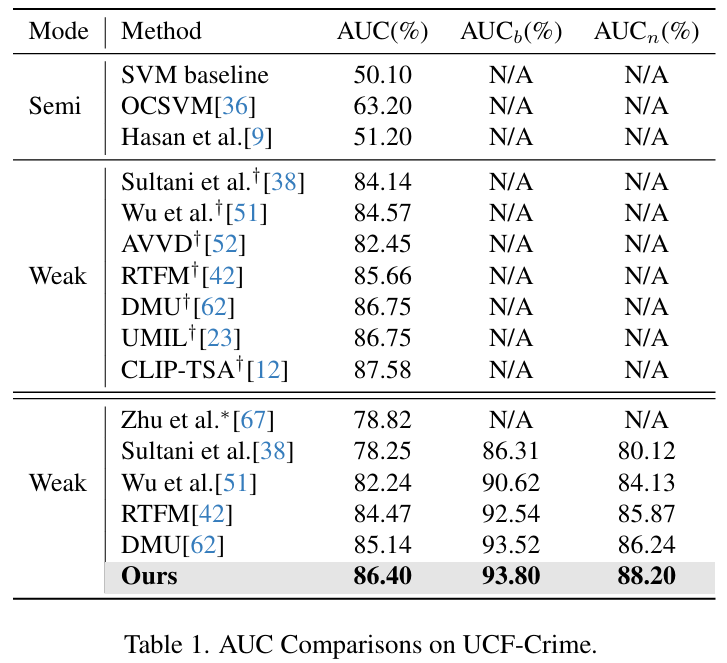
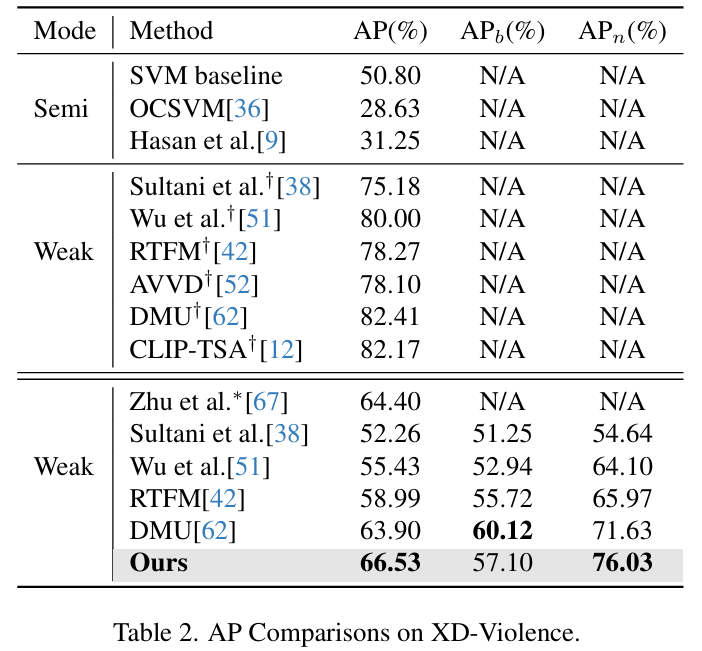
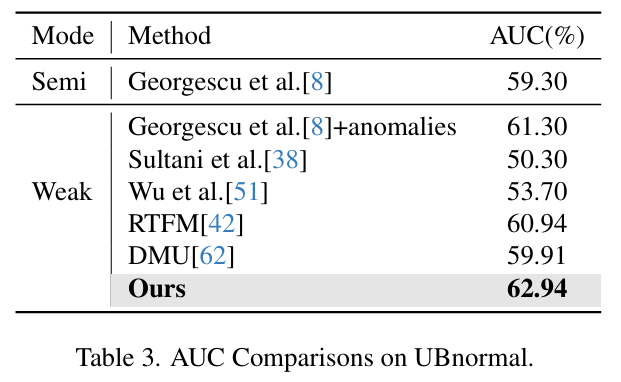
표 1, 2, 3은 각 데이터셋에서의 벤치마킹 결과를 나타냅니다. 우선 표에서 \dagger{} 표시되어있는 성능은 novel 이상 상황까지 포함하여 학습했을 때의 성능을 나타냅니다. 저자의 방법론은 OV 환경이니 당연히 novel 상황은 학습에서 제외된 성능입니다.
놀라운 점은 UCF-Crime에서 저자의 방법론이 novel 클래스는 제외하고 학습했음에도 모든 샘플을 다 쓴 기존 방법론들과 유사한 성능을 보여준다는 점입니다. 근데 제가 생각했을 때 기존 방법론들도 분류 대신 CLIP 모델 feature의 유사도를 측정하는 경우 novel 성능도 꽤 나오기 때문에, 기본적으로 UCF-Crime 데이터셋의 난이도가 낮은 것이 아닌지.. 의심이 가긴 합니다. 나머지 데이터셋에선 저자의 방법론이 novel 클래스에 타 모델들보다 효과적으로 대응하고 있는 모습을 볼 수 있습니다.
3.3 Ablation Studies
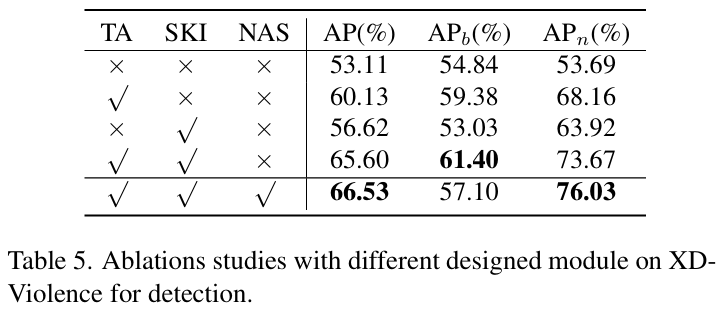
표 5는 XD-Violence 데이터셋에서의 모듈별 ablation 성능을 보여주고 있습니다. 우선 굉장히 적은 파라미터만을 포함했던 TA 모듈이 과연 어느 정도의 효과를 보여줄지 궁금했었는데, 성능 향상폭이 엄청나네요. SKI 모듈은 단독적으로 사용되었을 때 상대적으로 novel에 대한 성능 향상만 불러오고, base에 대한 성능은 오히려 떨어뜨리고 있는데, TA 모듈은 그러한 구분 없이 큰 폭의 성능을 높여준다는 점이 놀랍습니다.
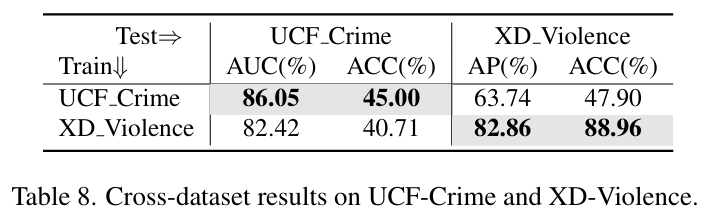
마지막으로 표 8은 학습/평가 데이터셋을 다르게 했을 때, 즉 cross-dataset 성능에 대해 보여주고 있습니다. UCF-Crime과 XDViolence 데이터셋을 교차해가며 학습을 진행하였습니다. 표 8을 통해 알 수 있는 점은 우선 모델이 학습 데이터셋과 동일한 데이터셋으로 평가하는 경우 우수한 성능을 보여준다는 점입니다.
다음으로 모델이 XD 학습, UCF 평가하는 경우 UCF 학습-평가할 때보다 성능이 많이 떨어지지 않는다는 점을 알 수 있습니다. 그러나 반대의 경우엔 성능이 많이 떨어지는데, 저자는 이에 대해 두 경우 모두 우수한 성능을 보여주기에 generalization 성능이 좋다고 이야기하고 있습니다. 제 생각엔 후자의 경우는 성능이 많이 떨어진 것 같아 UCF 데이터셋이 너무 쉬운 것이 아닌가 싶긴 한데, 아직 이 task의 데이터셋에 대해서는 자세히 몰라 추후에 더 알아보도록 하겠습니다.
4. Conclusion
본 논문이 24년도 CVPR에 게재되며 이제 막 OVVAD의 시대가 오는 것 같습니다. 굉장히 가벼운 모델링(TA 모듈, learnable prompt)만으로 높은 generalization 성능을 달성하였지만 아직 결과에 대한 설명 가능성은 많이 떨어진다고 생각됩니다. 더욱 최근에는 학습 없이 Multimodal LLM 모델을 활용해 처음 보는 이상 상황에 대해서도 현재 어떠한 상황이고 왜 그렇게 판단했는지까지 출력해주는 방법론들도 나오고 있습니다. 다만 그러한 방법론들은 computational cost가 너무 크다는 단점이 있는데, 지금 이 두 방식의 장점만을 적절히 취할 수 있는 방향으로 연구가 나아가야 한다고 생각합니다. 이상으로 리뷰 마치겠습니다.
안녕하세요, 김현우 연구원님. 좋은 리뷰 감사합니다.
흥미로운 연구 주제네요. VLM의 지식을 빌려 학습때 보지 못한 anomaly 상황을 프레임 단위로 어떤 상황인지를 판단하며 탐지하는 것으로 이해했습니다. 먼저 anomaly로 판단되는 프레임을 선별한 다음 각 프레임을 open-vocabulary로 어떤 상황인지 탐지하게 되네요.
리뷰 읽다 보니 제가 video쪽을 잘 몰라서 생긴 궁금증이 있습니다.
CLIP을 사용하여 video-level feature를 만드는 부분인데요, temporal adapter에서 어떻게 temporal 정보를 잡아내고(프레임 간 인접 행렬로 어떻게 동작하는지), 이를 CLIP에 접목하여 temporal 정보를 추출하는지 잘 와닿지가 않습니다. 이 부분 간단하게라도 설명해주실 수 있으실까요?
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
비디오 쪽에서의 anomaly detection은 처음 접해보는 것 같아서 그럴 수도 있는데,
검출해야 하는 anomaly 상황이라는 것이 정확히 어떻게 정의된 것인가요 ??
한 상황에 대한 비디오 프레임 사이에 전혀 관련없는 프레임이 들어가도 anomaly가 될 수 있을테고 같은 상황 안에서도 이상 물체나 상황을 검출할 수 있을 것 같은데 초점을 맞추고 있는 anomaly 현상이 어떤 것인지 설명해주시면 감사하겠습니다.
감사합니다.
안녕하세요 김현우 연구원님 좋은 리뷰 감사합니다.
2.3 Semantic Knowledge Injection (SKI) Module 에서 추가적인 정보를 제공하기 위해, “추가적인 semantic knowledge는 ChatGPT와 같은 LLM으로부터 추출”하였다고 했는데, 리뷰에서 말씀하신 것처럼 LLM으로 생성한 문장의 예시가 궁금하네요.. 생성하기 위한 프롬프트를 논문에 제시하나요?
그리고 보통 LLM으로 생성할 경우 노이즈가 포함될 수 있어 필터링하는 과정을 거치던데 해당 논문에 그런 절차가 있는지 궁금합니다.
안녕하세요 현우님 리뷰 감사합니다.
Anomaly Detection을 위해 두 단계로 분류한 이유가 학습을 잘 하기 위해서인가요? 카테고리화 하는것에 어려움이 있어서 그런게 아니라면 카테고리화 한 다음에 그 카테고리가 Anomal 한 상황인지 아닌지 구분하는 방법과의 차이점이 궁금합니다!!