안녕하세요. 이번 리뷰의 태그는 “semantic segmentation”, “prototype”입니다. 명료한 제목처럼 본 논문에선 이전 semantic segmentation 태스크의 prototype이 활용되어온 방향과, 그들의 단점으로 부터 새로운 prototype 학습 방식을 제안합니다. 아마도, 익히들 해당 태스크의 방법론의 정의쯤은 잘 아시리라 생각이 들어 편하게 읽어보실 수 있지만, 읽다보면 segmentation에 대해 잘 모르고 있구나 (저는 그렇게 느꼈습니다), prototype에 대해 만만히 생각하였구나 (저 또한 그렇게 생각했었습니다)를 알게될 수도 있지 않을까, 그렇기에 연구의 흐름을 놓치지 않는 것이 중요하구나를 다시 한 번 상기시킬 수도 있다고 생각합니다. 그럼, 시작하겠습니다.
Introduction
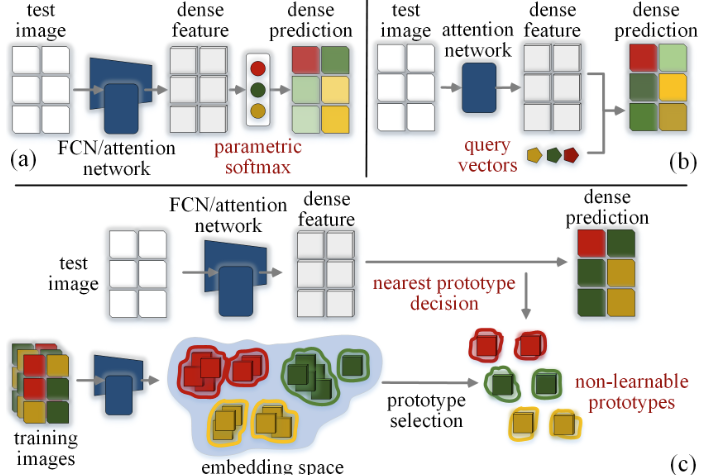
semantic segmentation이 발전해오며, 저자는 state-of-the-art 방법을 두 갈래로 나누었습니다. 그 중 하나는 FCN (Fully Convolutional Network)을 기반으로 하는 방법-(1)으로, 해당 방법은 CNN 기반으로 convolution(encoder)과 deconvolution(decoder)을 통과하여 각 픽셀들에 대해 (학습되는)parametric softmax와 곱하여 특정 클래스로 분류합니다. 또 다른 하나는 Transformer의 attention 기반의 방법론으로, mask decoding 방식을 따라 패치 토큰으로부터 추출한 임베딩의 softmax distribution, 즉 클래스에 대한 분포를 예측하는 방식으로, 이들은 대게 non-FCN 모델이라고도 불립니다. 이 때 Transformer 기반 방법론의 또 다른 하나는 위 Figure의 (b)에 해당하는 pixel-query 전략을 활용합니다. pixel-query 전략은 learnable 벡터 집합을 쿼리로 두어 이 쿼리를 학습함을 목표로 하며, 해당 쿼리는 segmentation mask의 예측에 대한 임베딩으로 활용됩니다. 이러한 learnable 쿼리를 활용하는 전제는 해당 쿼리 벡터가 클래스의 속성들을 잘 포착할 수 있도록 학습함을 기대합니다. 여태의 두 FCN/non-FCN에 대한 위의 설명은, segmentation 태스크에 대한 그 흐름을 함께하지 않았다면 이해하기 굉장히 어렵습니다. 이를 위해 적어도 제가 이해한 바에 따라 위 내용을 풀어 설명드리고자, 어려우셨다면 아래의 “Existing Semantic Segmentation Models as Parametric Prototype Learning”을 읽은 이후 다시 도입부를 읽으심을 추천드립니다.
저자는 FCN/non-FCN의 두 가지 서로 다른 mask decoding 전략에 대해, 다음의 의문점을 제기합니다.
- “what are the relation and difference between them?”: 그 두 전략 사이의 연관성/차이점에 대한 의문
- “If the learnable query vectors indeed implicitly capture some intrinsic properties of data, is there any better way to achieve this?”: (Transformer의 learnable 쿼리 벡터를 사용하는 pixel-query 전략에 대해) 그 쿼리 벡터가 정말로 데이터(클래스)의 속성을 잘 포착하도록 학습된다면, 그 이상으로 좋은 성능을 보이기 위한 추가적인 방안에 대한 의문
위 두 의문에 대해 고민하고, 특히 두 번째의 의문점에 대한 답을 내린다면, 최신식의 segmentation 모델 디자인에 새로운 요소를 불어 넣을 수 있다는 생각 아래, 저자는 prototype에 대해 조금 다른 시야에서 바라보고자 합니다. prototype, 우리에게 굉장히 직관적인 요소입니다. 아주 쉬운 classification 태스크에서의 prototype을 한 번 생각해봅시다. 쉬운 예시와 설명을 위해, ImageNet에서 분류를 생각하면 좋을 것 같습니다 (주로 한 이미지에서 하나의 객체가 중심적으로 등장하기 때문이죠).
ImageNet 분류 시, 일반적으로 CNN으로부터 추출한 Feature Map은 HxWxD의 형태입니다. 이제 Feature Map을 요리조리(Flatten, Projection, …)하는 과정을 통해, 음, 예를 들어 아주 쉽게는 H*W*D차원의 임베딩으로 만들 수 있습니다. 이제 H*W*D를 특정 D로 Projection하는 Linear layer를 통과하여 256차원의 벡터로 만들었다고 생각해보겠습니다. prototype이란 이 때, K*D(256) (이 때 K는 클래스 수)의 형태로 학습되어 형성되었다고 합시다. 이제 그 둘을 곱하면, K개의 클래스에 대한 확률을 얻을 수 있습니다. 해당 확률로 우리는 어떤 클래스인지를 구분할 수 있습니다. 이를 보자면, prototype은 어떤 한 클래스를 구분할 수 있는 대표적인 분포로 볼 수 있습니다.

쉬운 방식으로 설명하고자 하였으나, 위의 문단을 다시 읽어보니 오히려 입문자들에겐 어렵게 읽혔을 수도 있겠네요. 더 쉽게, K-means clustering은 우리가 아주 잘 아니, K-means clustering으로 돌아가보겠습니다. 클래스에 대한 임베딩으로부터 생성된 t-SNE를 떠올려보죠. 어떤 임베딩 공간 내, 동그라미/세모/네모, 또는 다른 색상 등으로 각 클래스들이 모여져있고, 흩어져 있습니다. 아래는 한 블로그에서 가져 온 MNIST에 대한 t-SNE입니다. 저 다른 색상들은 각각 0,1,2, …, 9를 의미하겠죠. 즉, 우리는 특정 클래스에 대한 Feature는 그들끼리 서로 잘 모여져 있음을 이미 알고 있습니다. 이 때 그들을 대표하는 하나의 중심을 선택하는 과정과, 서로 다른 무리끼리는 분리할 수 있는 작업의 대표격이 K-means clustering입니다. 만약 아래 그림의 맨 위, 연두색에서 중심을 하나 선택한다면, 이제 새로운 이미지에 대해 저들과 동일한 방식으로 임베딩을 추출한 다음, 어느 중심과 거리 (L2, cosine similarity)가 가까운지만 연산하면, 어떤 클래스로 분류할 수 있을지도 알 수 있습니다. 이 때 중심을 곧 prototype으로 부를 수 있습니다.
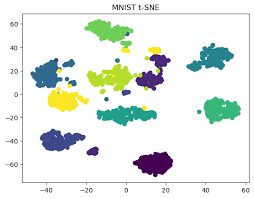
prototype에 대해 잘 아시는 분들은 너무나도 당연한 설명일 수 있겠네요. 그저 다시 한 번 상기해보기 위함입니다. segmentation 태스크에서는? 더 쉬운 일입니다. 추상적으로 H*W*D로 Projection한다던지를 생각해볼 필요도 없습니다. 특히나, semantic segmentation에선 이미지의 모든 픽셀을 어떤 한 클래스로 분류해야합니다. 그럼, 한 픽셀은 D차원의 벡터를 가지고 있겠죠. 그런 이후 prototype의 임베딩 공간으로 투영하는 학습된 Project layer에 통과시키고 나면, 위의 MNIST와 같이 각 픽셀들에 대해 “얼마나 prototype과 가까운지”를 기준 삼아 분류할 수 있습니다. 이러한 관점에서, 위에서 언급한 FCN/non-FCN의 방법론은 그들의 방법론 내 세부 차이를 제외하고 하나의 거대한 카테고리, “parametric models, based on learnable prototype”으로 묶일 수 있습니다. C개의 semantic class를 분류하는 FCN의 가중치 벡터 / non-FCN의 쿼리 벡터는 모두 C개의 prototype을 직접적으로 학습한다고 볼 수 있습니다.
이제, 두 번째 의문점은 다음의, 조금 더 근본적인 의문점으로도 볼 수 있습니다. 결국 쿼리 벡터 또한 C개의 클래스 별 프로토타입을 직접적으로 학습하는 방식이다 보니, 3. “what are the limitations of this learnable prototype based parametric paradigm?: parametric(FCN/non-FCN) 패러다임에서 learnable prototype의 한계 / 4. “How to address these limitations?”: 이를 극복하는 방식. 즉, 저자는 이 의문들로부터 다음의 말을 암시하네요. “기존 learnable prototype의 한계와 이를 극복하면, 어떤 semantic segmentation 방법이든 그들이 조금 더 좋은 성능을 보일 수 있게끔 한다. 그러므로, prototype에 대해 새로운 시각이 필요하며, 이는 아마도 learnable에서부터 시작된다”.
다시, 3번의 “learnable prototype의 한계”에 대해, 저자는 세 가지의 한계점을 설명합니다.
- 일반적으로 클래스 당 하나의 prototype만 학습되므로 클래스 내(intra-class)의 다양함(분산)을 설명하기엔 충분치 않습니다.
– prototype의 학습은 parametric 방식으로 학습되며, 이 학습 방식은 prototype의 대표성을 설명하기엔 약합니다. - HxWxD의 텐서를 HxWxC의 semantic mask로 매핑하기 위해선, 결국 그들을 잇는 DxC의 파라미터를 필요로 합니다.
– 이는 일반성에 방해됩니다. 이 때의 일반성은, 결국 large-vocabulary의 상황인 클래스 수가 증가하면 증가할 수록, 그 파라미터 수가 선형적으로 증가한다는 의미입니다. 800개의 클래스에 512차원이면, 0.4M의 prototype 학습을 위한 파라미터를 필요로 합니다. - 일반적으로 학습 시, cross-entropy는 intra-class와 inter-class 간의 상대적 거리만 최적화됩니다.
– 이는 픽셀과 prototype의 실제 거리, 즉 intra-class compactness(실제로 동일한 클래스끼리 얼마나 뭉쳐져 있는지)는 무시되게끔 학습됩니다.
이제 다시, 4번의 “How to address these limitations?”에 대해, 저자는 learnable이 아닌 “non-learnable prototype” segmentation 프레임워크를 제안합니다. 모델 디자인을 위해 저자의 방법은 픽셀 임베딩 공간 내에서 sub-class center의 집합을 prototype으로 명시적으로 설정함에 있습니다. 3번 의문점의 1번 한계점, 하나의 prototype만으로 학습된다는 한계를 극복하기 위함으로 보이며, 예를 들어 “person”의 prototype이라 한다면 “person”에 대해 “머리”, “몸”, “다리”, “팔” 등으로 분류될 sub-class의 집합으로 prototype을 둔다는 의미로 해석될 수 있습니다. 이 때 각 픽셀은 추가적인 learnable 파라미터 없이 가장 가까운 prototype과 동일한 클래스로 예측됩니다. 즉 학습 없이 여러 sub-class의 집합을 두어 그 집합의 중심과 가장 가까운 클래스로 예측시킨다는 의미입니다. 학습 중에는 몇몇의 제약 조건으로 최적화되는데, 이 때 앞선 3번 의문점의 3번 한계, intra-class compactness, 또는 inter-class separation(예측 정확도에 관여)과 같이 알려진 inductive bias를 최적화 기준으로 제시하여 예측 정확도만 최적화하는게 아닌 임베딩 공간 전체의 형태를 최적의 형태로 구성함을 목표로 합니다. 최적화 방법이 활용된다는 점인데, 이 때문에 실제 방법론의 수식들을 보면 바로 머리가 어질어질합니다.
제안하는 방식에는 세 이점이 있습니다.
- 각 클래스들은 하나가 아닌, sub-class로 이루어진 prototype의 집합들로 명시되며, 바로 위 문단에서 설명한 바와 같이 intra-class에 대한 다양성 및 inter-class, 클래스 간의 특징 분별을 잘 포착할 수 있습니다. 또한, 이전과 동일하지만 살짝 다르게, 각 픽셀은 직관적으로 임베딩 공간 내에서 가장 가까운 클래스(sub-class)의 중심을 참조 삼아 실제 클래스를 예측할 수 있습니다. 이상적으로 이는, 바로 특정 클래스가 아닌 sub-class의 참조로부터 진행되므로 sub-class의 prototype (“person”의 prototype 중 K번째)으로부터 “왜 해당 픽셀이 어떤 클래스인지”를 설명할 수 있으므로, 해석력을 높입니다.
- 위 3번 의문점의 2번은 명시적으로 나와있지 않았으나, 사실 잘 생각해보면 제안하는 방식이 prototype에 대한 파라미터가 더 이상 클래스의 수에 따라 증가되지 않습니다. 이는 곧 “non-parametric”이기 때문이며, large-vocabulary 상황에서도 메모리 증가 없이 효율적으로 동작할 수 있습니다.
- prototype 기반의 metric learning에서 최적화를 통해, 픽셀 임베딩 공간은 잘 구성될 수 있습니다. 이는 곧, 성능에도 영향을 미칩니다.
그럼 우선, 현존하는 parametric prototype learning에 대해 자세히(수식적으로) 살펴보겠습니다.
Existing Semantic Segmentation Models as Parametric Prototype Learning
서론부에서 소개한 FCN/non-FCN의 두 mask decoding 전략에 대해 살펴본 후, 저자의 최초 의문점 “1: what are the relation and difference between them?”: 그 두 전략 사이의 연관성/차이점에 대한 의문”에 대해 저자의 의견을 담아보겠습니다.
Parametric Softmax Projection
FCN과 non-FCN에서도 attention 기반의 segmentation 모델은 해당 전략을 취합니다. 그 둘은 보통 1) Encoder가 dense visual feature extraction을 담당하며, 2) Classifier (Projection head)는 픽셀에 대한 feature를, semantic label space로 투영시켜 예측하도록 학습합니다. 이 과정을 다음 하나의 수식으로 나타낼 수 있습니다.
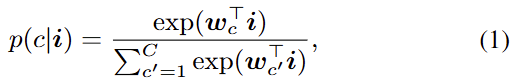
p(c|i) \in [0,1] 은 픽셀 임베딩 i 에 대해 클래스 c로 분류될 확률을 의미합니다. 위 수식은 결국 softmax 함수로, Encoder를 통과한 (Classifier 이전의 Feature map은 HxWxD의 형태) HxW의 각 픽셀은 D차원으로, 이 D차원을 W = [w_1, ..., w_c] \in \mathbb{R}^{C \times D} 의 Linear layer에 통과시켜 클래스(C)에 대한 벡터로 변환시키며, 그 때의 확률을 위 softmax 수식으로 나타낸 것입니다. 그럼 우리는 저 D차원을 C로 변환하는 W 가 곧 Learnable projection layer임을 눈치챌 수 있습니다.
Parametric Pixel-Query
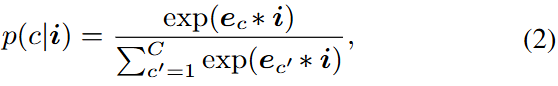
앞서 소개 해드린 바와 같이 attention 기반의 segmentation 모델 중, 조금 더 Transformer같은 방법도 있습니다. 위의 Softmax projection 과정과 유사히 픽셀 임베딩 i 와, 학습되는 클래스 개수 (C)개의 쿼리 벡터 E = [e_1, ..., e_C] \in \mathbb{R}^{C \times D} 의 내적 연산을 통해 위 수식 (2)의 확률을 구합니다. 이 때 Softmax projection과 유사한 방식이므로 혼동이 올 수 있습니다. 결국 행렬 곱이든, 내적 연산이든 W, E 는 각 클래스마다 존재하는 하나의 값으로 표현되기 때문이죠. “같은 것 아니야?”라는 의구심이 있지만, Softmax projection의 W 는 학습하며 각 클래스들로 잘 변환해주는 값, Pixel-query의 E 는 역시 각 클래스들로 잘 변환해주는 값이지만, 쿼리 벡터이므로 그 값들이 의미를 담은 attention 연산으로부터 학습된다는 개념적 차이가 존재합니다.
Prototype-based Classification
Prototype 기반 분류는, KNN과 같은 전통적인 머신러닝 기법에서 부터 지금까지 클래스를 대표하는 요소(prototype)로 부터 해당 요소를 참조하도록 (거리 계산 등)하여 특정 이미지를 분류할 수 있는, 잘 알려진 방법입니다.
m번째 클래스( \{ c_{p_m} \in \{ 1, ..., C \} \}_m )를 대표하는 prototype을 \{ p_m \}^{M}_{m=1} 라고 정합니다. 픽셀 임베딩 i 에 대해, 예측은 i 와 prototype \{ p_m \}_{m} 을 비교합니다. 이 때의 비교는 거리 계산, 유사도 등을 의미하며, 하나의 prototype의 클래스로 최종 예측됩니다.
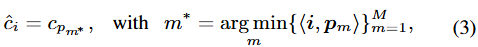
이를 표현한 위 수식은, \langle i, p_m \rangle 으로 표현된 거리 (일반적으로 L2 distance)가 최소가 되는 prototype m^{*} 을 정한 후, 해당 prototype의 클래스로 예측하는 과정이 서술되어 있습니다. 위 MNIST의 예시로 prototype에 대해 설명하는 부분에서 “이러한 관점에서, 위에서 언급한 FCN/non-FCN의 방법론은 그들의 방법론 내 세부 차이를 제외하고 하나의 거대한 카테고리, “parametric models, based on learnable prototype”으로 묶일 수 있습니다.”와 같이 설명 드렸습니다. 즉, 위 수식 중 수식-(1)과 수식-(2)는 픽셀 임베딩을 특정 클래스로 분류한다는 측면에서 prototype의 방법으로 풀 수 있으며, 그렇기에 두 수식을 하나의 아래 수식으로 표현할 수 있습니다.
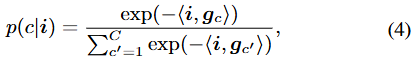
Softmax 확률 값에서, 픽셀 임베딩과 Learnable projection layer, W, E 는 이제 exp(- \langle i, g_c \rangle) 로 표현되었으며, 이 때 각 클래스 c에 대해 prototype g_c 을 학습한다는 동일한 측면에서 parametric model로 묶일 수 있습니다. 의문점 1에서 두 방법의 연관성(동일한 점)에 대한 답변이 되었습니다.
두 방법의 차이점은 아주 단순합니다. Softmax projection 방식은 학습한 softmax layer( W )의 class weights 만을 활용하지만, Pixel-query 방식은 decoder에서 쿼리를 cross-attention에 통과시켜 서로 다른 class 간의 정보를 교환할 수 있다는 근본적인 차이점입니다.
이제 FCN/non-FCN을 하나의 parametric prototype learning으로 정의한 후, 해당 방법의 문제점을 살펴보겠습니다. 우선, prototype을 선택하는 방식입니다. Prototype은 그 의미대로 클래스를 대표해야 합니다. 그러나, 현존의 방식은 prototype을 각 클래스마다 단순히 하나를 선택하므로, 위에서 말했듯 한 클래스 내의 다양성을 모델링하기 어렵습니다. 더욱이, prototype의 대표성을 고려하지 않은 채, 학습 방식은 단순히 parametric learning에 기대어 학습합니다. 두 번째는 또한 앞서 말한 클래스가 증가함에 따라 더 많은 prototype projection을 위한 파라미터가 필요하단 점입니다. 800개의 클래스에서 512 차원의 projection layer는 0.4M의 파라미터 증가를, 만약 클래스가 10배 늘어난다면, 4M의 파라미터를, 결국 현실 세계의 모든 클래스를 모델링 하기에는 파라미터 증가에 한계를 보입니다. 마지막 세 번째로는 또한 위에서 말한 바와 같이 현존의 방식에서 이 projection layer를 학습하는 방식은 cross-entropy loss로, pixel마다 예측을 하여 손실을 정하나, 이 방법은 클래스 내 요소들의 분포가 얼마나 밀집하게 뭉쳐져 있는지 (intra-class compactness)에 대해 고려하지 않는다는 점입니다. 이로 인해 segmentation feature 간의 차별성이 약해지며, 성능에서 더 큰 발전 가능성을 해치게 됩니다. 그렇다면 이제, 저자가 제안하는 non-learnable prototype의 방식을 살펴보겠습니다.
Non-Learnable Prototype based Nonparametric Semantic Segmentation
이제, 어지러운 수식이 등장할 차례입니다. 어지러운 수식은 역시 해당 방식을 최적화를 기반으로 모델링 하였기 때문에, 우리가 익숙하진 않습니다. 본 방법의 핵심은 non-learnable prototype을, 하나가 아닌 여러 개로 두는 방식입니다.
Non-Learnable Prototype based Pixel Classification
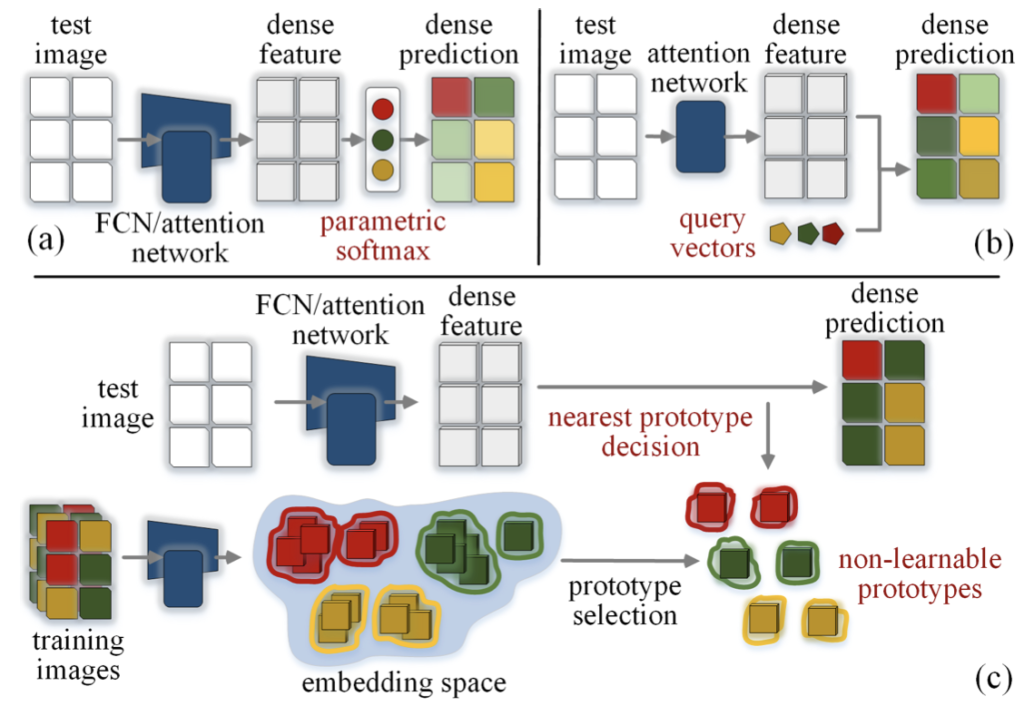
Pixel 별 클래스(C)에 대한 분류를 위해, 이전의 방식 (FCN/non-FCN)은 수식-(1) 또는 수식-(2)와 같이 class-weight 또는 쿼리 벡터를 학습하도록 유도됩니다. 이에 반해 저자는 non-learnable prototype을 CK개 둡니다 ( \{p_{c,k} \in \mathbb{R}^{D} \}^{C,K}_{c,k=1}). 즉, 한 클래스에 대해 K개의 sub-class center가 존재한다는 의미입니다. 이 K개의 sub-class center는 학습 이미지의 픽셀 샘플로부터 구해지며, 이 떄 위 그림-(c)와 같이 임베딩 공간을 구성시키는 학습 도중의 online-clustering이 이루어집니다. 하지만 염두할 점은 이 online-clustering은 어떠한 파라미터를 요구하진 않는 일입니다. 단순히 K개의 sub-class center를 두는 방식만으로도, 한 클래스 내의 다양성을 모델링할 수 있습니다. FCN과 non-FCN을 하나의 parametric prototype으로 모델링한 수식-(3),(4)와 유사한 방식으로 다음의 수식으로 표현할 수 있습니다.
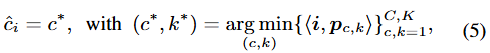
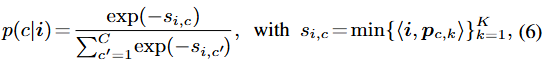
수식-(5)는 수식-(3)과 동일하게, 단일 C가 아닌 K개의 집합으로 이루어진 클래스 C에 대해, 픽셀 임베딩과의 거리가 최소인 조합을 찾습니다. 이 때의 거리(metric)은 negative cosine similarity, ( \langle i, p \rangle = -i^{T}p)로 정의합니다. 최소가 되는 픽셀-클래스 거리 s_i,c 를 통해, 수식 6의 픽셀 임베딩 i가 클래스 c일 확률 p(c|i) \in [0,1] 을 구합니다. 이후, 해당 확률을 토대로 cross-entropy loss를 다음 수식-(7)로 정의할 수 있습니다.
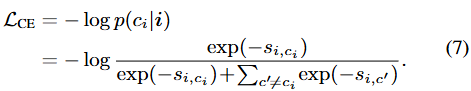
위 cross-entropy loss에는 K에 대한 접근이 포함되어 있으므로, 저자는 위의 손실 함수가 픽셀 i를 해당하는 클래스의 가장 가까운 K번째 prototype으로 가깝게 한다고 설명합니다. 그렇게 함으로써, c_i 는 관련 없는 클래스 ( c^{'} \neq c_i )에 대해 더 멀어질 수 있습니다. 하지만, 최적화의 입장에서 이 방식은 다음의 두 이유로 충분치 않습니다.
첫 번째로, 위 loss는 pixel-class 간의 거리만을 고려합니다. 즉, pixel과 prototype의 관계성에 대한 모델링이 불충분합니다. 두 번째로, pixel-class 거리는 전체 클래스에 대해 normalized되는데, 위 loss는 intra-lcass와 inter-class에 대한 상대적 관계성만을 최적화할 뿐, 실제로 pixel과 class에 대한 거리 (cosine distance)를 정규화하진 않습니다. 이 말이 어려울 수 있는데, 예를 들자면 픽셀 i에 대해 intra-class의 거리가 다른 inter-class 거리보다 비교적 작다면, 위 loss는 작으므로 실제로의 intra-class 거리는 여전히 클 수 있습니다. 해당 문제를 극복하고자 하는 저자의 노력을, online-clustering 방식과 함께 살펴보겠습니다.
Within-Class Online Clustering
저자는 동일한 클래스 내의 학습 픽셀 샘플을 해당 클래스의 prototype 집합으로 할당하며, prototype은 해당 할당을 통해 업데이트됩니다. 전통적으로 클러스터링은, 모델에게 intra-class의 차별적인 패턴을 학습하도록 유도하지만, instance 특유의 디테일은 버리게 됩니다. 그 instance 마다의 디테일을 위해 저자는 sub-cluster(K)의 center를 prototype으로 지정한 것입니다. offline clustering, 학습 전체 데이터에 대해 클러스터링을 진행하는 해당 방식에 비해 학습 배치에 대해 진행하는 online clustering은 대용량의 학습 데이터에 대해서도 대응할 수 있으며, 클러스터링 시에는 다음의 수식들로 최적화됩니다.
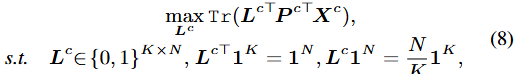
클래스 c( c_{i_n} = c )에 속하는 학습 배치 내의 pixel \mathcal{I}^{c} = \{ i_n \}^{N}_{n=1} 에 대해, 목표는 해당 픽셀을 클래스 c의 K prototype \{ p_{c,k} \}^{K}_{k=1} 에 잘 매핑함에 있습니다. 이 pixel-to-prototype 매핑을 수식-(8)의 L^{c} = [l_{i_n}]^{N}_{n=1} \in \{ 0, 1\}^{K \times N} 로 표현하며, [l_{i_n,k}]^{K}_{k=1} \in \{0, 1\}^{K} 은 K prototype의 pixel ( i_n )의 one-hot 벡터에 해당됩니다. 즉, 쉽게 L 은 픽셀이 어떤 프로토타입에 해당되었는지를 나타냅니다. 따라서, L^{c} 을 최적화함은 결국 픽셀 임베딩과 prototype 간의 유사성을 클래스 c( c_{i_n} = c )에 속하는 학습 배치 내의 pixel \mathcal{I}^{c} = \{ i_n \}^{N}_{n=1} 에 대해, 목표는 해당 픽셀을 클래스 c의 K prototype \{ p_{c,k} \}^{K}_{k=1} 에 잘 매핑함에 있습니다. 이 pixel-to-prototype 매핑을 수식-(8)의 L^{c} = [l_{i_n}]^{N}_{n=1} \in \{ 0, 1\}^{K \times N} 로 표현하며, [l_{i_n,k}]^{K}_{k=1} \in \{0, 1\}^{K} 은 K prototype의 pixel ( i_n )의 one-hot 벡터에 해당됩니다. 즉, 쉽게 L 은 픽셀이 어떤 프로토타입에 해당되었는지를 나타냅니다. 따라서, L^{c} 을 최적화함은 결국 픽셀 임베딩( X^{c} )과 prototype( P^{c} ) 간의 유사성을 최대화한다는 의미입니다. 이제는 L^{c} 를 최적화하는 과정에 대해서만 살펴보면 되겠습니다 (어렵습니다).
수식-(8)을 다시 살펴보면, Tr(대각합) 내의 요소들은 픽셀 임베딩과 prototype의 행렬곱으로 K \times N 형태의 행렬을 얻으며, 이는 곧 prototype과 픽셀 간의 유사도를 나타낸 행렬로 볼 수 있습니다. 그 유사도와 매핑식 L^{c} 의 대각합을 연산하며, 이 때 s.t의 L^{c^T}1^{K} = 1^{N}, L^{c}1^{N} = \frac{N}{K}1^{K} 의 두 제약 조건을 활용합니다. 전자의 제약 조건은 unique assignment contraint(단일 할당 제약)로, 이는 각 픽셀이 오직 하나의 prototype에 할당되도록 합니다. 후자의 제약 조건은 equipartition constraint(균등 할당 제약)로, 이는 K 프로토타입이 동일하게 \frac{N}{K} 의 픽셀을 할당받도록 유도합니다. 해당 제약 조건은 K 프로토타입에 모든(혹은 많은) 픽셀이 집중되면, 클러스터링의 품질이 떨어지기 때문입니다. 이 두 제약 조건은, 단순히 수식-(8)의 행렬 곱으로만 L^c 를 최적화할 때의 함정, trivial solution을 방지합니다. 대각합이 최대가 되도록 하기 위해 모델은 단순히 모든 픽셀을 하나의 prototype에 할당하기만 하면 되기 때문이죠. 수식은 단순히 하되, 해당 수식으로부터 제약 조건을 거는, 흔히들 사용된 방식입니다.
이번엔 더 어렵습니다. 수식-(8)을 풀기 위해, 저자는 L^{c} 를 transportation polytope의 요소로 만듭니다. 위 용어를 한국어로 찾아봐도 잘 나오지 않지만 transportation, 음 한 번쯤 DETR 관련 논문을 보셨다면 보셨을 운송 최적 관점의 방식입니다. 아래 수식-(9)로 나타냅니다.
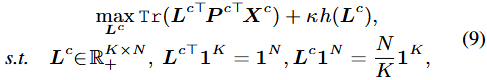
우리가 운송 최적화 방식까진 이해하긴 어렵습니다. 어찌되었든, 수식-(8)에서 추가된 부분은 kh(L^c) 입니다. h(L^c) 는 h(L^c) = \sum_{n,k} -l_{i_{n,k}} logl_{i_{n,k}} , 즉 entropy로 파라미터 k에 곱해져 분포의 smoothness를 측정합니다. 결국 이 부분은 행렬 L^c 의 분포가 얼마나 잘 분산된 상태인지를 측정하여, 값이 크다면 픽셀 할당이 균등한 상태(목표)임을 의미합니다. 이러한 regularization term을 이용해, 수식-(9)는 다음으로 풀 수 있습니다.
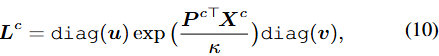
정말 엄청난 수식들입니다. 슬슬 지쳐가네요. 위 수식-(10)은 최종으로 L^c 를 풀기 위한 수식입니다. 해당 수식은 또 처음 들어보는, Sinkhorn-Knopp interation(싱크-놉프 반복법)으로 u, v 라는 renoramlization vector에 대해 해당 반복법을 활용하는데, 이 반복법은 몇 번의 행렬에 대한 연산 ( exp() )으로 픽셀 간의 유사도를 확률 분포로 변환시켜 연산하도록 유도합니다.
최종적으로, online clustering은 GPU 환경에서 수행되어 matrix multiplication만으로 끝나므로 (K-means등과는 달리), offline에 비해 10K의 픽셀을 10개의 prototype으로 분류하는데 단순히 2.5ms의 시간만을 필요로 합니다.
Pixel-Prototype Contrastive Learning
확률 분포로 변환된 할당 행렬 L^c 로 인해, 픽셀 임베딩에 대한 prototype 할당이 마쳤다고 합시다. 해당 prototype 할당 이후 예측에 대한 loss function을 구성해야 하는데, 이때의 loss란 prototype 할당의 사후 확률을 최대화하는 것으로 해석할 수 있습니다 (수식-(10)으로 픽셀 간 유사도는 확률 분포로 변화되었음을 유의하시길 바랍니다). 이는, pixel-prototype contrastive learning 전략으로 loss를 정의할 수 있으며 수식-(7)에서 설명한 단순한 cross-entropy loss만의 한계를 해결할 수 있습니다.
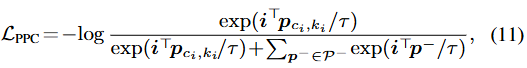
\mathcal{L}_{PPC} 는 픽셀 임베딩과 prototype 간의 contrastive learning으로, 할당된 positive prototype에 대해 유사해지고 다른 관련 없는 negative(CK-1개) prototype( p^{-} )에 대해 멀어지도록 합니다. 엄청난 양의 negative pixel과의 metric-learning을 하는 이전의 방법에 비하면, 본 방식은 오직 CK개의 prototype과의 contrast 연산만을 진행하므로, computational cost에서도 유의미한 효과를 보입니다.
Pixel-Prototype Distance Optimization
수식-(7),(11)의 \mathcal{L}_{ce}, \mathcal{L}_{PPC} 는 inter-class/-cluster의 차별성을 모델링하지만, intra-cluster의 다양성에 대해서는 고려가 부족합니다. pixel feature들이 동일한 K prototype에 압축적으로 모여있진 않을 수 있다는 의미입니다. 따라서, 아주 단순한 loss를 추가하며 이는 compactness-aware loss로 정의됩니다. 이 loss는 단순히 regularization을 통해, 임베딩 픽셀과 할당된 prototype간의 거리를 최소화하도록 유도합니다. 그렇다면 해당 prototype 내 다양한 픽셀들은 조금 더 쫀쫀하게 prototype으로 모여들겠죠. 이는 아주 단순히 다음의 수식-(12)로 표현됩니다.
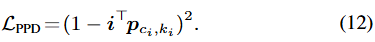
Network Learning and Prototype Update
저자의 방식은 non-parametric 접근법으로, 픽셀 임베딩 공간을 바로 최적화 하도록 유도됩니다. 따라서, feature extractor (encoder)의 파라미터는 SGD를 통해 학습되며, 전체 학습 픽셀 샘플에 대해 다음의 segmentation loss (수식-(7),(11),(12))의 합으로 표현됩니다.
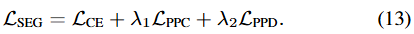
그런데, non-learnable prototype( p_{c,k} )는 말 그대로 non-learnable이므로 SGD로 학습되지 않습니다. 해당하는 픽셀 임베딩 샘플의 중심으로 연산됩니다. 그렇기에, 당연히도 prototype은 지속적으로 online clustering을 통해 업데이트 되어야합니다. 이 업데이트는, 이전의 prototype 업데이트 방식과 동일합니다.
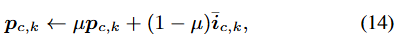
학습 픽셀 임베딩의 평균 벡터로부터, 새로운 prototype을 정의하게 됩니다. 이런 식으로 잘 업데이트 된 prototype은 아래 Figure의 결과를 획득할 수 있습니다. 잘 보시면, 사람이나 자동차에 대해서(클래스 수는 2), K=3의 prototype으로 clustering을 진행시켜 시각화해본다면, 각각 다른 부분 (머리,몸통, 다리 / 자동차의 상부,중부,하부)으로 pixel clustering이 아주 잘~된 모습을 확인할 수 있습니다. 역시 아무리 수식이 14개로 설명되더라도, 아직 저는 아래 Figure 하나를 보면서 본 논문의 핵심을 이해하기 더 편합니다 (수식 이해하느라 ChatGPT를 너무 많이 괴롭혔습니다). 이제 아주 간단한 실험 몇 개를 보고 마무리해보죠. 벌써 17000자나 썼네요.

Experiments
학습 및 평가를 위한 dataset은 전형적인 ADE20K, Cityscapes, COCO-Stuff를 활용하였습니다. 이 때 ADE20K는 150개의 category를 가지고 있어, 기존의 방식대로라면 150개의 prototype에 512의 차원을 곱하면 음.. 대략적으로 0.7M 정도의 하이퍼파라미터가 필요하겠습니다. 아, 가장 중요한 점으로 실험에서 K는 10으로 설정되었습니다. 즉, 한 카테고리(prototype)에 대해 10개의 세부 카테고리로 분류됩니다. 베이스라인 네트워크로는 FCN 기반에서 FCN, HRNet이 활용되었으며 attention 기반의 네트워크에서는 Swin과 SegFormer을 활용하였습니다. 평가 매트릭으로는 아주 전통적인 mIoU를 활용하여 평가합니다.
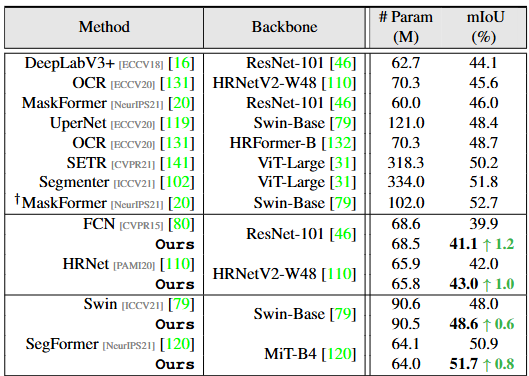
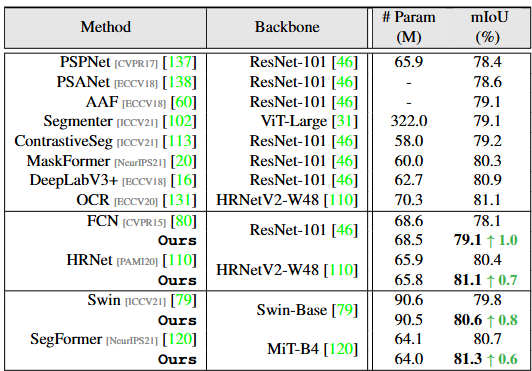
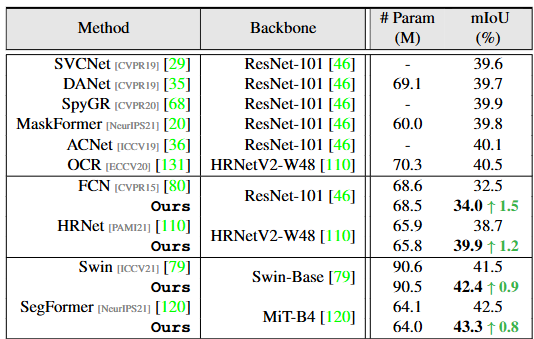
위 세 dataset에서의 평가 표를 통해 고무적인 것은, 본 방법론을 잘 이해하셨다면 아시겠지만, 저자가 제안한 방식은 “새로운 네트워크”가 아닙니다. 단순히 Prototype을 어떻게 구성하고, 어떻게 최적화 해야 하는가에 대한 접근입니다. 그렇기에 해당 접근은 위에서 활용된 베이스라인 네트워크에 어디서든 가져다 붙일 수 있습니다. 그렇게 가져다 붙였을 때, 모든 실험 dataset과 모든 베이스라인 네트워크에서 보통 1% 내외의 성능 향상을 보입니다. 굉장히 일반적으로 활용될 수 있는 방법론이란 소리죠.

SegFormer, ADE20K의 실험에서 (음, 실험 파트에서 ADE20K는 150개의 클래스라고 했는데, 이렇게 보니까 아마 150개의 클래스가 벤치마크 평가에선 활용되고, long-tailed 분포로 다른 클래스들도 존재하는듯합니다. 설명이 없네요) 리포팅된, parametric과 nonparametric(ours)에서 클래스 증가에 따른 파라미터 차이와 성능 차이를 볼 수 있습니다. 이 표에서 확인할 수 있는 내용은, 단 하나의 prototype (K=1)일지언정 non-parametric이 더 효율적이며, 일반적으로 1개/10개의 prototype을 둔다면 parametric 방식에서는 클래스 수의 증가에 따라 아주 선형적으로 파라미터 개수가 증가합니다. 이에 비해, nonparametric은 당연하게도, 전혀 클래스 수가 늘어나더라도 파라미터의 증가가 전혀 없습니다.
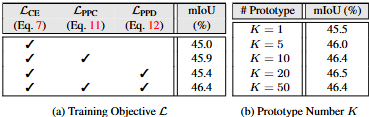
마지막으로 살펴볼 ablation은 loss function에 따른 ablation (이는 loss function 자체의 역할을 잘 이해하셨다면 그 성능 증가의 이유에 대해 충분히 이해됩니다)으로, 살펴볼 점은 prototype K의 증가에 따른 성능 향상 정도입니다. 이 K가 으미하는 바는 하나의 클래스에 대해서도 얼마나 많은 “세부 요소”들을 정함이 중요한지로, 일반적으로 10개정도부턴 크게 성능 증가가 없습니다. 즉, 하나의 클래스를 여태 K=1로 단일 prototype으로 바라보았지만, 논문의 제목처럼 “Rethinking prototype view”, 이제는 하나의 클래스가 가진 instance-specific 요소들을 고려하여 K개의 prototype으로 정의함이 성능 향상에 일조합니다. 오랜만에 각 수식까지 자세히 읽은 논문인만큼, 어렵습니다. 다만, 그 뜻을 잘 이해하면 정말 도움이될만한 아주 일반적인 방법론임에는 분명합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
한 prototype에 대해 K개의 set으로 정의하고 나면 해석력이 높아진다고 하였는데, 그럼 해당 방법을 통해 왜 K개, 그러니까,, 실제로 중간에 나온 Figure과 같이 왜 머리/몸통/다리로 나뉘어졌는지에 대한 해석도 가능할까요 ?!
감사합니다.
안녕하세요.
질문으로 K개의 set으로 구성된 prototype에 대한 해석력의 관점을 질문해주셨는데, 좋은 질문입니다만, 여기서는 힘듭니다. 해당 관점은 아래 석준님이 질문하신 내용과 같이 “자동차의 클래스가 세단/SUV 등으로 묶이도록 의도하였다면” 그 자체로 해석력을 나타내겠죠.
하지만, 해당 online-clustering은 학습 픽셀을 임의의 집합 내 하나로 매핑시키는 과정입니다. 이 때 사람이라면 서로 다른 사람이라도 동일한, 머리, 몸통, 팔, 다리 등이 묶일 수 있겠죠. 하지만 왜 그렇게 묶였느냐?에 대한 답변은 XAI의 관점으로 파고들어야 한다고 생각합니다.
좋은 리뷰 감사합니다. 수식이…매우 어렵네요.
수식 8에 대한 간단한 질문이 있습니다. pixel과 proto 사이의 행렬 곱을 통해 proto-pixel 사이의 유사도 matrix인 K×N 을 각 class 별(1~c) 로 구하는 과정은 알겠습니다.
픽셀 임베딩과 prototype의 행렬곱으로 K × N K×N 형태의 행렬을 얻으며, 이는 곧 prototype과 픽셀 간의 유사도를 나타낸 행렬로 볼 수 있습니다. 이게 P^ {cT}X^ {c} 인거 같은데… 매핑식(?) L^ c{T}가 의미하는 바와 대각합을 수행하는 이유에 대해 한번만 더 설명해 주십쇼..ㅎ
그리고 시각화 결과를 보기 전 저는 intra class 를 잘 모델링 했다길래 차 내의 종류를 잘 구분하는 줄 알았습니다. 가령 1번 prototype은 세단을, 2번 prototype은 SUV 로 예측한다던지요.. 그런데 결과를 보니 하나의 instance 를 여러 proto로 나눠서 예측하는 양상을 보이네요. 저자가 의도/설계한 바와 동일한가요?
감사합니다.
안녕하세요.
매핑식 (L^c{T})이 의미하는 바는 픽셀 i가 어떤 prototype CK중 하나에 할당되어야할 지를 매핑시켜주는, 아주 쉽게는 FCN/non-FCN에서의 learnable weights vector와 유사한 의미로 해석하시면 됩니다. 대각합(Tr) 내의 요소들을 행렬곱하면 class x class (NxN)의 shape이 나오게 됩니다. 즉, 대각 요소들은 각 prototype 별 유사도를 의미하며, 이 요소들이 최대가 되어야한다는 의미입니다. 자기 자신과의 유사도가 최대가 되어야만, prototype 간 쫀쫀히 묶일 수 있겠습니다. 그러나 이 유사도를 결정하는 요소에 매핑식 L이 포함되어 있으므로, 이 L을 최적화해야한다는 새로운 수식을 풀게됩니다.
두 번째 질문으로 시각화 관련 질문을 주셨는데요, 엄밀히 말하면 석준님이 말하는 것 처럼 “car”에 대해 세단, SUV등으로 묶이는게 더 최적이라 생각할 수도 있지만, 각 클래스에 대한 세부 집합 K의 길이는 현재 불변적입니다. 즉, 그렇게 “car”에 대해 세단/SUV 등으로 나눈다면 K=10이 적을 수도 있겠죠. 반면, 사람 클래스에 대해선 K=10이 많을 수도 있습니다. 그렇기에, 각 객체들의 세부 인스턴스 (세단 \in 자동차) 보다, 그냥 해당 자동차라는 클래스에 대해 K개의 유사한 영역 등을 표현할 수 있는 세부 집합으로 묶은 것입니다. 그러니, 결과에서 하나의 instance를 여러 prototype으로 나눠서 예측하는 양상이 저자가 의도한 바와 동일합니다.
이상인 연구원님, 좋은 리뷰 감사합니다.
평소 prototype을 활용하는 방식이 intra-class의 분포를 충분히 반영할 수 없다는 점은 생각해 본 적이 없었는데 해당 부분에 집중하여 잘 개선시킨 방법인 것 같습니다.
리뷰를 읽다가 약간 헷갈리는 부분이 있어 질문 남깁니다. 제안 방법이 prototype에 대한 파라미터가 더 이상 클래스의 수에 따라 증가되지 않는다는 부분입니다.
class 수가 늘면 이에 따라 class들을 구성하는 sub-class의 수도 늘어날 것으로 생각되는데, 왜 prototype에 대한 파라미터가 더 이상 클래스의 수에 따라 증가되지 않는 것인지 잘 모르겠네요.. 해당 부분에 대해서 조금 더 설명해주시면 감사하겠습니다.