
안녕하세요, 이번에는 새로운 BOP challenge 벤치마크 데이터셋이 나와 리뷰를 해보았습니다.
지금은 comming soon으로 표기가 되어있습니다. Meta에서 만든 데이터셋이고, 2024년부터 tracking 테스크에 대해서도 평가가 가능하도록 만들어진 데이터셋이라고 합니다. 현재 6D pose estimation 문제를 해결한 방법론은 model-base/model-free로 나누어져 문제를 풀고 있습니다. model-base는 3D CAD 모델이 있으므로 물체에 대한 3D 모델 정보를 통해 학습 및 평가를 진행하게 되고, model-free 같은 경우 3D 모델이 없으니, reconstruction/tracking을 통해 물체에 대한 3D mesh를 얻는 방식으로 진행됩니다.
리뷰 시작하겠습니다.
Introduction
저희는 손을 사용하여 다른 사람과 소통하고, 사물과 상호작용도 하고 사물을 잡기 위해 도구라는 사물을 활용합니다. 인간이 사물을 조작할 수 있는 손재주는 다른 종들과 비교할 수 없을 정도로 뛰어나죠. 또한 이를 통해 인류는 진화할 수 있었다고 봐도 과언이 아닙니다. 따라서, 손과 물체의 상호작용은 자연스럽게 컴퓨터 비전을 비롯한 다양한 연구 분야에서 상당한 관심을 받아왔는데요.
vision-based의 기술을 이용하여 손과 물체의 3D motion, shape, contact 정보를 어떻게 하면 자동으로 이해를 한다면 어떻게 접목을 시킬 수 있을까요? 예를 들어, 고압배전반 같은 경우 사람이 직접 지금까지 투입이 되어 작업을 수행하지만 감전이 되어 목숨을 잃는 일도 있습니다. 사람 대신 로봇이 이러한 작업을 대신 수행할 수 있다고 하면, 손과 물체 간 상호작용을 수행하는 숙련된 기술자로부터 먼저 하는 방법에 대해 recording하고, 이를 토대로 경험이 없거나 부족한 로봇이 인간으로부터 기술을 전수할 수도 있겠네요. 즉, 인간이 할 수 있는 기술을 로봇에게 유사하게 이전하여 즉석에서 학습할 수 있는 자율 로봇을 통해 임무를 수행할 수 있습니다. 최근 구글 딥마인드에서 개발한 AutoRT를 보면 충분히 가능하다고 봅니다. 설령 현재는 불가능할지라도 조만간은 가능하지 않을까 합니다. 최근에는 인간과 사물간의 상호작용을 예시로 유명한 애플의 비전프로와 같이 물리적인 표면을 가상 키보드로 바꾸어 AR/VR 사용자가 입력을 할 수 있도록 하는 기능을 제공하고 있죠. 하지만 저자는 이러한 손과 물체의 상호작용을 이해하는 기존의 방법은 정확도/속도 측면에서 어플리케이션을 안정적으로 작동하기에는 충분하지 않다고 지적합니다.


따라서 이번 HOT3D 데이터셋을 통해 손과 물체의 상호작용에 대한 컴퓨터 비전 연구를 가속화하기 위해 3차원상에서 손과 물체를 tracking 하는 방법을 학습하고 평가할 수 있도록 제공합니다. 해당 데이터셋에는 150만개 이상의 multi-view 프레임이 포함된 833분 이상의 시퀀스 영상들이 포함 되어 있으며 해당 영상에는 19명의 피험자가 33개의 다양한 물체와 상호작용하는 모습을 담고 있습니다. 다양한 시나리오로 구성하여 다양한 환경에서 영상들을 취득합니다. HOT3D는 Meta에서 출시한 두 개의 head-mounted 기기들로부터 recording 되는데요. 보급형 AI glasses인 Project Aria,와 VR 기기인 Quest3를 사용합니다. marker 기반의 모션 캡처 시스템을 사용하여 취득한 정보를 통해 물체에 대한 6D pose와, 손에 대한 pose를 annotation 합니다. 해당 데이터셋은 3D 스캐너를 통해 물체에 대한 3D 모델을 생성하여 사용합니다. 또한 HOT3D는 주로 3차원 공간에서 손과 물체를 tracking 하는 방법을 학습하고 평가하기 위한 것에 초점을 맞춘 데이터셋입니다. 만약, model-free(3D 모델이 없음) 상황에서 물체에 대한 tracking을 수행하기 위해 각 물체에서 서로 다른 view를 보여주는 onboarding sequence를 제공합니다.
HOT3D dataset
833 minutes of recordings

HOT3D 데이터셋은 기존 데이터셋들과 다르게 데이터셋 촬영을 특이하게 진행을 하게 되는데요. 최근들어 많이 개발 연구되고 있는 가상현실 기기를 사용합니다. Meta에서 출시된 기기 Project Aria, Quest3를 사용합니다. 둘 다 들을 사용하여 recording을 진행함으로써 multi-view로 구성된 이미지를 자체적으로 얻을 수 있습니다. Aria의 recording에는 하나의 RGB(1408×1408), 두 개의 monochrome(640×480)으로 구성된 영상들로 구성이 되고, RGB는 없이 두 개의 monochrome(1280×1024)으로만 구성이 된다고 합니다. 하지만, Quest3 같은 경우 영상을 보시면 MR은 결국 현실+가상의 조합이기 때문에 RGB 센서가 필수라고 생각이 들어 RGB 센서 존재 유무에 대해 찾아보았습니다. RGB 센서를 쓰기는 하는데 해상도가 400백만 픽셀의 RGB 카메라가 존재한다는 말이 있긴 하지만, 출처가 불분명하여 정확하지가 않네요. 그리고 여기서 말하는 monochrome은 그림(2) 아래에 나와있는 것과 같이 grayscale 영상을 의미합니다. 녹화는 30FPS로 진행하였으며 Aria로 부터 얻은 SLAM 정보를 통해 각 뷰포인트에 대한 포인트 클라우드 정보도 포함시킬 수 있다고 합니다. 또한, 제목을 보면 알 수 있듯이, 30FPS로 833분이나 녹화를 진행하면 약 1.5M장 정도 확보할 수 있을 정도이니 엄청 많네요.
3D mesh models of 33 objects

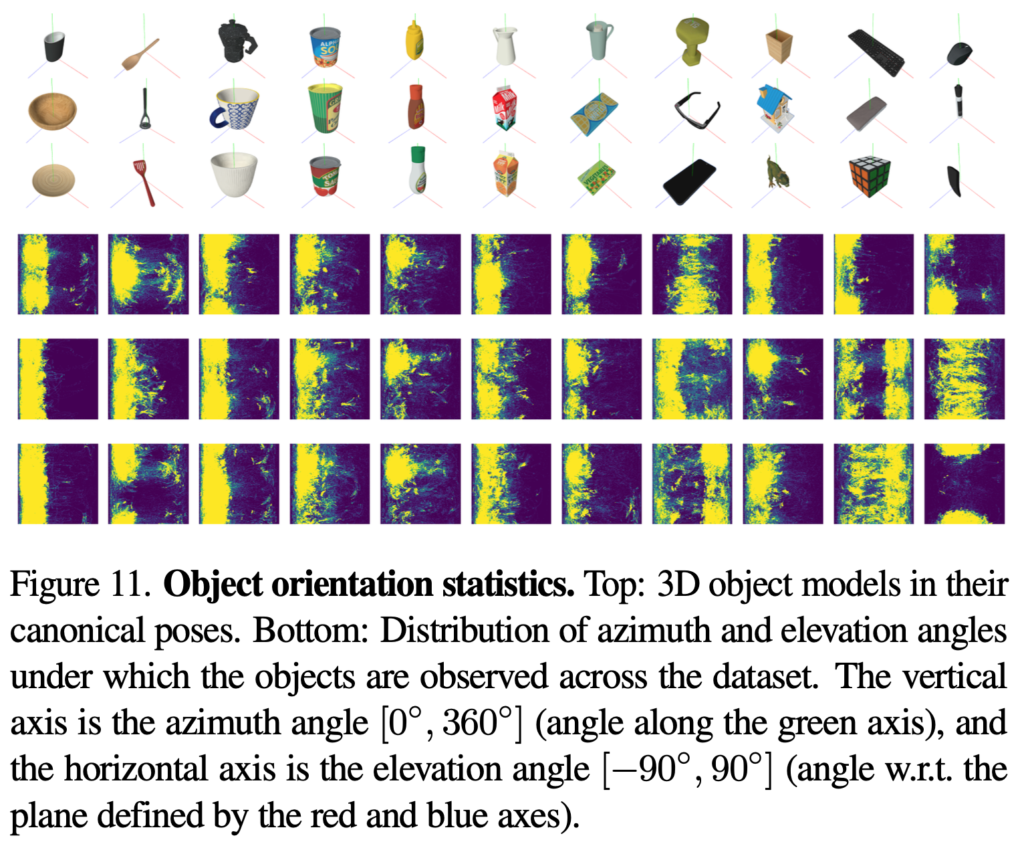
그림(2)에 나와있는 그림은 33개의 물체에 대한 3D 모델을 렌더링하여 캡처한 이미지입니다. 물체에 대한 3D 모델을 생성하기 위해 3D 스캐너를 사용하였으며, 이를 통해 양질의 mesh를 생성할 수 있었으며, 이러한 mesh로 렌더링하기에도 용이하다고 합니다. 물체들의 구성은 다양한 모양, 크기, 어포던스를 가지는 household, office 환경을 타겟으로 한 물체로 되어 있다고 합니다.
19 diverse subjects
기존의 데이터셋과 다른점은 이번 섹션인데요. 물체뿐만 아니라, 사람의 손에 대한 pose 정보도 포함하는 데이터셋이므로 활용도가 무궁무진할 것으로 보입니다. 사람마다 손의 모양이나 젓가락을 사용하는 것으로 예를 들면, 손으로 같은 일을 하더라도 다르게 하는 경우가 있습니다. 이러한 다양성들이 존재하므로 대기업 Meta 답게 다양한 국적을 가진 19명의 피험자들을 모집하여 각 피험자들의 손을 3D 스캐너로 스캔하여 이러한 detection에서도 coco format이 있듯이, hand pose에 대한 UemTrack, MANO라는 format이 존재하므로 이러한 format에 맞춰주었다고 합니다.
(참고로 UemTrack이 좀 더 정확한 정보를 가지고 있고, MANO는 표준이라고 합니다.)
4 everyday scenarios
앞 섹션에서 참여한 피험자들은 이제 물건을 집어들고 물체를 관찰하고 다시 물체를 내려놓는 간단한 시나리오를 inspection scenario로 하는 등으로 action을 정의하고 부엌, 사무실, 거실에서 일반적으로 할 법한 action들을 수행하도록 요청하였고 이때 피험자들은 녹화를 진행할 때 최대 6개의 물체와 상호작용을 해야한다고 하네요. 또 다시 한 번 데이터셋의 다양성을 주고자 조명조건, 가구 배치 등을 계속 무작위로 배치하여 진행하였다고 합니다. 이렇게 최대 425개의 녹화 파일을 얻을 수 있었다고 하며 각 녹화 파일은 약 2분 정도로 구성이 된다고 합니다.
Ground-truth annotations

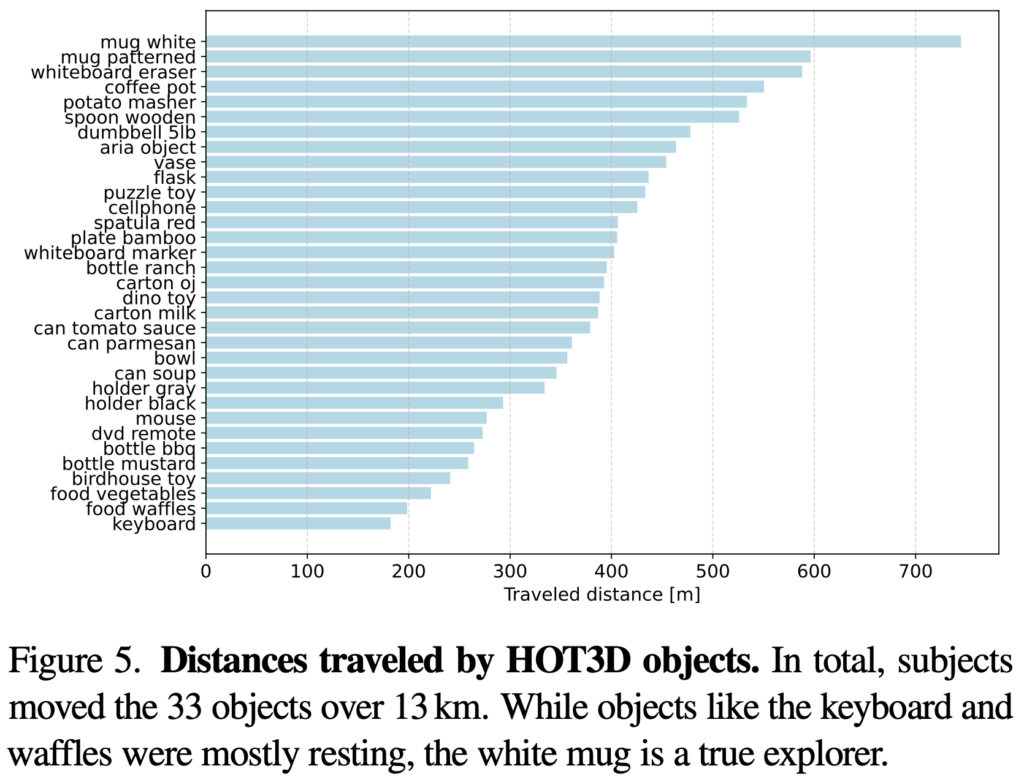
그림(4)는 모션 캡처를 위한 실험 환경입니다. OptiTrack을 사용하여 물체에 대한 motion capture를 진행하는 걸로 보이고, 환경 구성마저 규모가 장난아니긴 하네요. 해당 영상을 보시면 좀 더 이해가 잘 될 것으로 보입니다. 위 실험 환경으로부터 취득된 이미지 데이터로부터 손과 물체에 대한 프레임 당 GT pose 정보를 annotation 하게 됩니다. 손에 대한 pose는 앞서 언급한 UmeTrack, MANO foramt으로 표현하고, 물체와 손목에 대한 pose는 저희가 잘 아는 6D pose format으로 표현합니다. 일부 프레임에 annotation 정보가 누락이 된다거나 pose 정보가 정확하지 않을 수 있기 때문에 모든 파일을 사람이 직접 검수를 진행하여 그렇게 걸러서 전체 데이터셋이 150만장 → 116만장으로 줄었지만 모든 프레임에 대한 annotation이 다 달려있는 최종적인 데이터셋을 구성하였다고 합니다. 제가 거른다고 표현을 하긴 했지만 그렇다고 버리지 않고 해당 프레임들은 unsupervison으로도 유용하게 사용할 수 있도록 모든 150만개의 프레임을 공개하였다고 합니다. 그림(5)는 시나리오로 설정된 action을 수행했을 때에 대한 물체별 이동거리를 나타내고, 그림(11)은 GT pose를 나타냅니다. 둘 다 OptiTrack 카메라를 통해 얻은 전체적인 통계로 보이네요.
Training and test splits
HOT3D 데이터셋의 train/test 셋을 나누는 기준은 subject인 피험자의 손을 기준으로 나눕니다. 13개의 subject에 대한 녹화 영상(1M, multi-view), 6개의 subject(0.5M, multi-view)를 각각 train/test 셋으로 사용하며 이때 GT pose는 학습 때에는 제공하지만, test set에는 제공하지 않습니다. 이는 BOP 공개 데이터셋에서 사용하는 전용 평가 서버에서만 접근을 할 수 있다고 합니다. 기존의 공개된 BOP 코어 데이터셋 중에서도 ITODD, HB도 동일하게 test 셋을 제공하지 않습니다.
Curated clips
위 섹션에서 train/test 셋은 전체 이미지에 대해 train/test를 나누었지만 아무래도 몇분짜리 영상을 매번 평가하는 것은 비효율적이죠. 그래서 BOP Challenge에서 제공하는 데이터셋들과 같이 벤치마킹을 위해서 curation 과정을 진행하여 좀 더 짧은 영상 클립(5초)으로 구성하여 벤치마킹 데이터를 제공합니다. 여기에는 모든 물체/손에 대한 GT pose 정보를 가지고 있으며 검수도 모두 완료된 데이터들이며 해당 클립 영상들을 BOP Challenge 벤치마크 데이터셋으로 제공하게 됩니다.
Object-onborading sequences
HOT3D 데이터셋의 벤치마크 타겟 중 하나인 model-free인 unseen 6D localization 테스크를 수행하려면 마찬가지로 onborading 과정이 필요하게 되는데요. HOT3D는 각 물체에서 가능한 모든 view를 보여주는 두 가지 유형의 시퀀스를 제공합니다.
(1) 물체가 책상 위에 똑바로 서 있거나 뒤집혀 있는 정적 물체를 보여주는 시퀀스
→ NeRF와 유사한 3D reconstruction task에 적합
(2) 손으로 조작하는 물체를 보여주는 시퀀스
→ BundleSDF와 같은 tracking task에 적합
→ AR/VR 어플리케이션에 적합
두 가지 유형은 각각 존재하는 특징은 위와 같이 정리될 수 있습니다. 추가적으로 물체에 대한 GT pose는 정적 시퀀스의 모든 프레임에 대해 제공되지만 동적 시퀀스 같은 경우는 초기 pose만 주어집니다. 정적인 경우에는 SfM(Structure from Motion) 과정을 통해 pose를 쉽게 얻을 수 있는 반면, 동적인 경우에는 pose를 얻기 어렵기 때문입니다. 동적 시퀀스에 대한 첫 번째 프레임의 GT pose 정보는 결국 6DoF 물체를 tracking 결과를 평가하는 데 필요한 표준 물체 공간을 정의하기 위해 제공한다고 보면 되겠습니다. 어떻게 보면 해당 tracking task는 SLAM과 유사하다고 생각이 드네요.
Conclusion
이번에는 Meta에서 제공하는 벤치마크 데이터셋인 HOT3D에 대해 살펴보았습니다.
기존 데이터셋들과 차별점은 Mixed Reality 기기들을 사용하여 데이터셋을 촬영합니다. 시나리오로 정의된 action들을 피험자들이 수행하는 것을 recording하여 각 시퀀스에 존재하는 프레임 내에 존재하는 손, 손목, 물체들에 대해 GT pose를 제공합니다. 해당 데이터셋은 최근 떠오르는 reconstruction 방법론을 적용하여 문제를 해결하기에 적합하고, 어플리케이션 측면에서 보았을 때 활용도가 매우 높을 것으로 보입니다.
이상으로 리뷰 마치겠습니다.
감사하겠습니다.
좋은 리뷰 감사합니다.
기존의 데이터 셋과는 다르게 AI glasses와 VR 기기를 이용하여 데이터 셋을 취득하였다는 점이 광장히 독특하다는 생각이 듭니다. 이러한 기기를 사용한 이유는 사람의 시야에서 데이터를 촬영하기 위한 것으로 보이는 데, 카메라와 객체가 모두 동적으로 변할 경우에 추가로 고려해야 할 사항은 없을까요??
동적인 시퀀스에서 초기 이미지에만 Pose 정보를 제공한다고 하셨는데, 그럼 동적인 시퀀스에 대한 6D Pose Estimation은 평가가 불가능한 것인가요??
안녕하세요, 리뷰 읽어주셔서 감사합니다.
추측이지만 물체마다 OptiTrack 카메라를 통해 움직인 동적인 정보를 알고 있으므로 각 물체마다의 pose를 알게 될 것으로 보여 동적 상황에 대비하기 위해 해당 과정을 거치지 않았나 라고 보고 있습니다.
init pose를 제공함으로써 시퀀스마다 변하는 정도에 따라 다음 프레임에서의 pose 정보를 제공하게 되므로 평가도 가능할 것으로 보입니다.
감사합니다.