안녕하세요, 서른아홉 번째 X-Review입니다. 이번 논문은 2024년도 CVPR에 게재된 Bridging the Gap Between End-to-End and Two-Step Text Spotting입니다. 바로 시작하도록 하겠습니다.
Text spotting이란 영상 내에 있는 텍스트를 읽는 task를 의미합니다. 이 Text spotting은 크게 text detection 단계와 text recognition 단계로 구성이 되어 있는데요, 영상이 입력으로 들어왔을 때 텍스트를 먼저 검출을 하고, 그 텍스트가 존재한다고 검출한 부분에 대해서 어떤 문자인지 인식하는 식으로 동작하는 것이라고 생각하면 될 것 같습니다.
전통적인 2단계 기반의 text spotting은 detection과 recognition을 각각 독립적인 두 개의 모델을 사용하는 식이였는데요, 최근에는 이 detection과 recognition을 한번에 end-to-end로 학습하는 프레임워크 중심으로 연구가 되고 있습니다. 이는, 각각 detection과 recognition 모델을 따로 학습해서 spotting을 한다는 것이 sub-optimal할 수 있다는 점과 detection에서 발생한 에러가 recognition에 누적이 될 수 있다는 점을 해결하기 위해서였습니다. 이런 end-to-end 접근 방식에서 text detector는 RoI를 통해 text가 존재할 법한 feature들을 추출해내며, 이 추출되는 feature는 recognition과 공유하는 backbone으로 부터 생성됩니다.
이런 end-to-end text spotting이 계속 연구되면서 발전해왔지만, 실제 application 측면에서는 여전히 2단계의 text spotting이 선호되고 있다고 하는데요, 그 이유로는 2-스텝 방식에 내재되어 있는 높은 모듈성 때문입니다. 구체적으로, detection 부분을 좀 더 성능을 높이고 싶다면, detection 모델에 대한 데이터셋만을 준비하면 된거나 새로운 모델로 갈아끼우면 되는 것처럼, 독립적인 개발 및 유지가 가능하다는 점입니다.

위 Fig 1을 통해 modulity의 장점을 좀 더 살펴보도록 하겠습니다. (a)가 기존 2-step text spotting을 나타내고 있는데, 기존 모델에서 detector만 새로 갈아끼우고 싶다면 새 detector만 학습하면 되기에 102시간이 걸린다고 적혀 있습니다. 반면에, end-to-end spotting 방식(b)는 전체 모듈을 다 학습해야 하기 때문에 272시간이 소요됩니다. 또, 학습 데이터를 늘려서 detection 성능을 향상시키고자 한다면 bbox만 라벨링해야하는 것이 아니라, box내의 text가 어떤 text인지 recognition 어노테이션까지 필요하기 때문에 2-step 방식보다 cost가 더 크겠습니다.
본 논문에서는 modulity를 유지하면서 동시에 앞서 2-step 방식의 단점이라고 언급했던 에러 축적이나 sub-optimal 문제를 해결하고자 Bridging Text Spotting이라고 하는 새로운 text spotting 패러다임을 제안을 하고 있습니다. 이 Bridging Text Spotting은 미리 잘 학습된 detector와 recognizier들을 freeze하여 두 모델이 사전에 얻은 능력..을 그대로 유지할 수 있도록 하였으며, Bridge라고 하는 것을 제안을 하여 이 freeze한 detector와 recognizier를 통합해 학습할 수 있도록 하였습니다. 추가로 freeze한 detector와 recognizer에 adapter를 도입하여 보다 효율적으로 학습할 수 있도록 하였습니다.
Fig1의 (c)가 본 논문에서 제안한 Bridging Text Spotting을 보여주고 있는데요, 보시면 새로운 detection 모델로 바꿔끼운다고 가정했을 때 detection모델만 학습한 후, bridge를 학습하면 되기 때문에 총 104시간이 걸리며 성능도 (a), (b)에 비해 가장 높은 것을 확인할 수 있습니다.
본 논문의 contribution을 정리하자면 아래와 같습니다.
- 본 논문에서는 새로운 text spotting 패러다임인 Bridging Text spotting을 제안하며, 이는 기존 2-step spotting 기법이 에러를 축적하고, 완전히 최적화되지 않는다는 문제를 해결한다.
- Bridge를 제안하여, 미리 사전에 잘 학습된 detector와 recognizer를 end-to-end로 잘 최적화 시키게 한다.
- 기존 2step spotting 방식보다 높은 성능 달성
2. Methodology
2.1. Overall Architecture
전반적인 아키텍처는 fig2에서 확인할 수 있습니다. 먼저, 독립적으로 사전에 잘 학습된
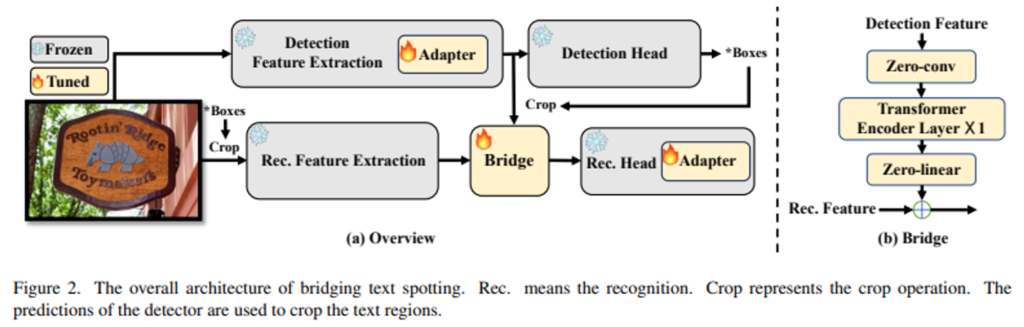
전반적인 아키텍처는 fig2에서 확인할 수 있습니다. 먼저, 독립적으로 사전에 잘 학습된 detector와 recognizier를 사용하고 있습니다. 이런 독립적인 개발 및 학습은 필요에 따라 각 모듈의 데이터셋과 구조를 유연하게 조정할 수 있다는 장점을 갖는다고 합니다. 이후, 이 detector와 recognizier 둘 다의 파라미터를 freeze하여 사전에 학습해서 얻은 capability를 보존하도록 하였습니다.
먼저 scene text 영상이 들어오게 되면 학습된 detector의 입력으로 들어간 후 텍스트가 존재한다고 판단되는 위치를 내뱉게 되며, 이 detector의 결과 즉 text의 위치 좌표를 이용해 detection backbone으로부터 생성된 feature에서 해당되는 feature만을 crop하게 되구요, 동시에 입력 영상에 대해서도 그 위치를 crop해내게 됩니다. 이 입력 영상에 대해 crop한 영상 C_i는 recognition backbone으로 들어가게 되고 이 backbone으로부터 추출된 feature와 이전에 detection feature로부터 crop한 feature C_f둘이 Bridge 입력으로 들어가게 됩니다. 이후, Bridge에서 output으로 나온 feature가 recognition head로 들어가고 최종적으로 text를 인식하게 됩니다.
추가로, Adapter가 detection 특징 추출 부분과 recognition head부분에 도입이 되었는데요, 이는 detector와 recognizer를 freeze해 놓은 상태에서 효율적으로 end-to-end 최적화가 가능하다고 합니다.
2.2. Bridge
이제, 저자가 제안한 Bridge에 대해서 살펴보도록 하겠습니다. 이 Bridge는 잘 학습된 detector와 recognizier를 연결하는 역할을 하기 위해 제안되었습니다. 위에서 언급했듯이 사전에 학습된 detector와 recognizer의 parameter를 freeze하여 이미 획득한 능력을 보존하게 됩니다. R(; θ_{rb})가 파라미터 θ_{rb}를 갖는 recognizer의 backbone이고, R(; θ_{rh})가 파라미터 θ_{rh}를 갖는 recognizier의 head라고 가정을 해봅시다. 마찬가지로 D(;θ_{db})와 θ_{dh})가 각각 detection backbone, head라고 가정할 때 입력 영상 I가 주어지면 detection 프로세스는 다음과 같습니다.
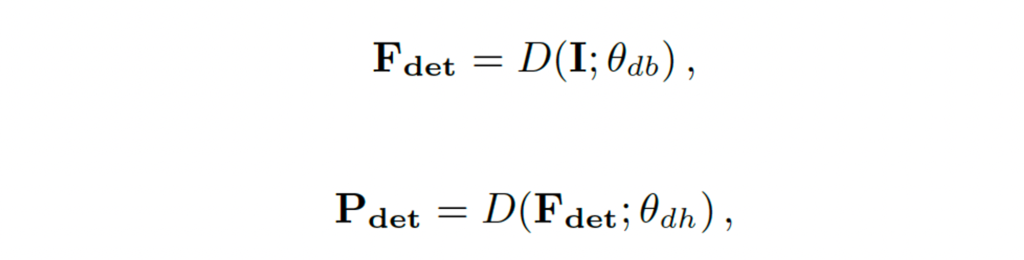
F_{det}은 detection backbone을 통해 생성된 feature가 되겠구요, P_{det}는 최종적으로 detector가 내뱉은 prediction이 되겠습니다.
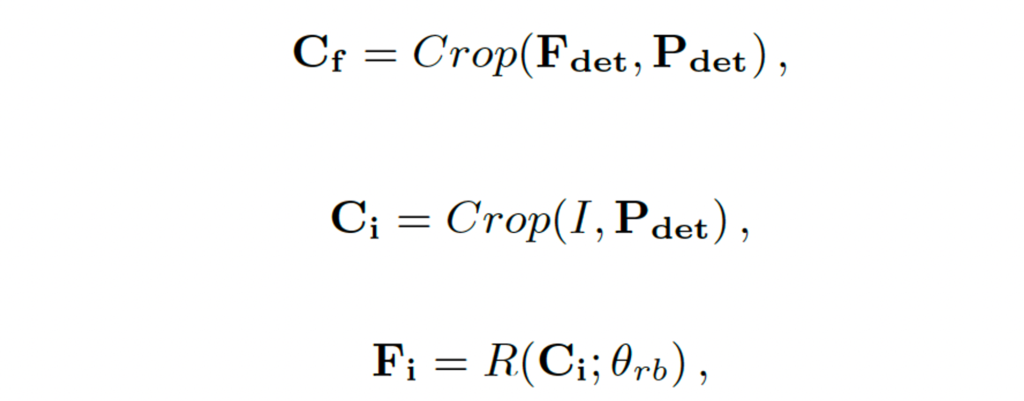
이후의 과정은 위에 식과 같은데, 간단한 부분이라 요약하자면, detection feature에서 예측된 bounding box 좌표 부분을 crop한 것을 C_f라고 하고, 원본 영상에서도 동일한 좌표 부분을 crop한 다음, 이 crop한 영상을 recognition backbone에 태워 얻어낸 feature가 F_i입니다. 이 F_i와 C_f가 bridge의 입력으로 같이 들어가게 되는 것입니다.
저자는 이 bridge를 구성하는 convolution과 linear layer를 모두 0으로 초기화했다고 합니다. (weight, bias를 0으로 초기화)
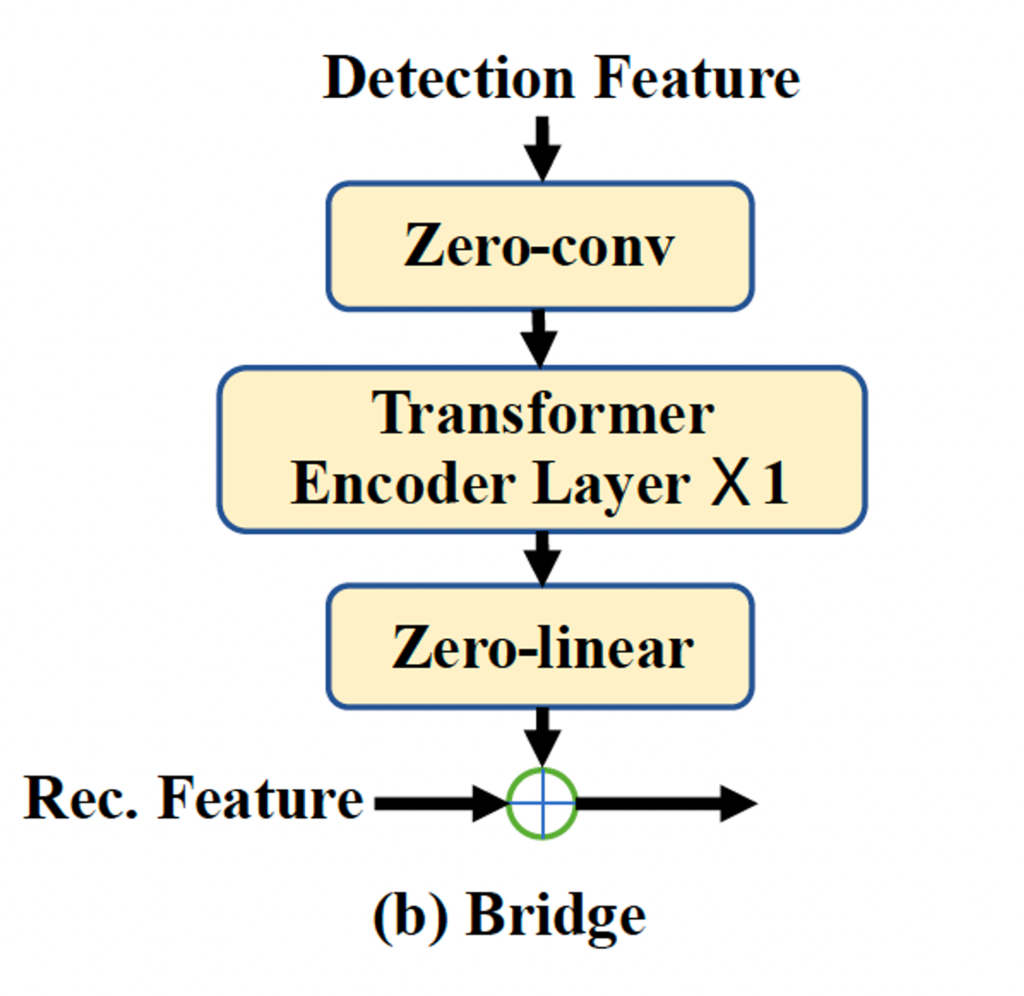
Bridge의 구성은 Fig2의 오른쪽 부분에서 살펴볼 수 있습니다. 보시면 정말 간단하게 detection feature를 입력으로 넣어서 zero-conv → transformer 인코더 레이어 → zero-linear 순으로 태운 후 recognition feature와 더하는 식으로 구성되어 있습니다.
최종적으로 bridge는 아래 식으로 수식화해볼 수 있습니다.
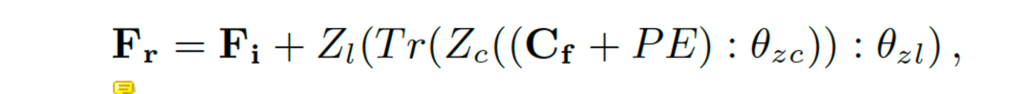
F_r이 bridge의 output을 의미하구요, Z_c, Zl은 zero로 초기화된 convolution, linear layer를 각각 의미합니다. Tr는 transformer encoder입니다.
초기 학습 단계에서 Bridge의 weight와 bias 파라미터가 다 0으로 초기화되었기 때문에 위 식에 있는 변수인 Z_l, Z_c는 둘 다 0의 값을 갖겠죠. 그로 인해 맨 처음 학습에서 Bridge의 output F_r는 F_i가 됩니다. (F_i는 입력 영상을 detector가 예측한 좌표 이용해 crop해서 recognition backbone 태워 추출한 feature임)
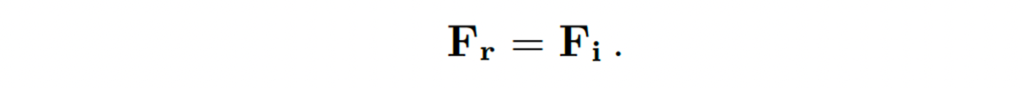
이러한 방식을 통해, recognition head가 초기 학습 단계에서 갑작스럽게 더해진 feature에 의해 방해받지 않을수 있다고 합니다. 비록, convolution과 lienar layer의 weight bias가 0으로 초기화되었지만 gradient는 0이 아니게 됩니다. gradient 계산 식은 아래 수식과 같습니다.
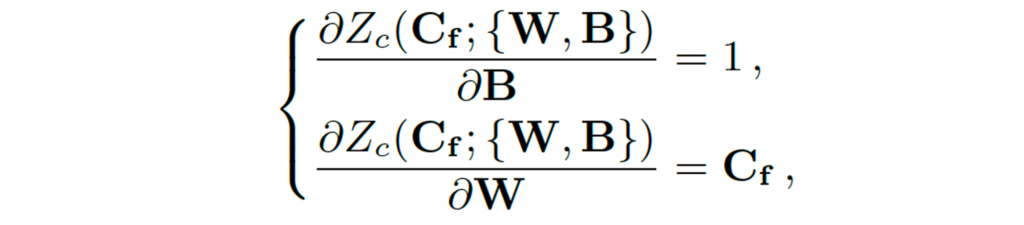
학습함에 따라서 convolution, linear layer의 weight와 bias값이 점차 조정되면서 recognition head에 적합한 형태로 된다고 하네요.
2.3. Adapter
추가로 저자는 detector와 recognizier 간의 시너지 효과를 높이기 위해 모델을 fine-tuning할 때 Adapter를 사용하였습니다.
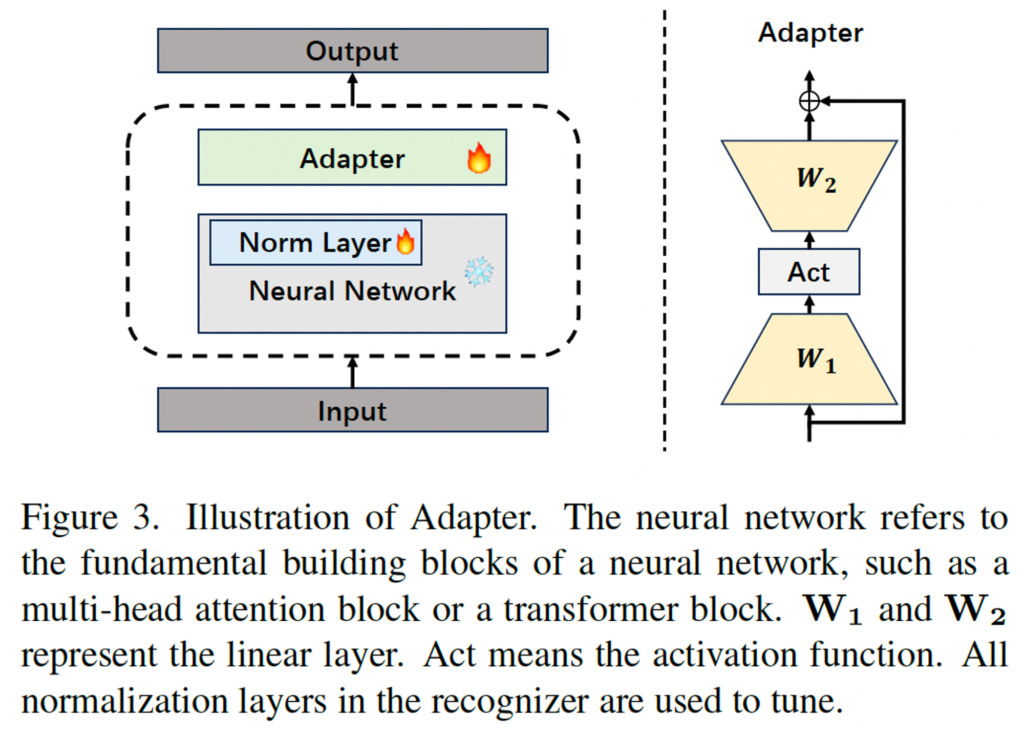
Adapter 구조는 위 그림3을 참고하시면 됩니다. 보시면 norm layer를 제외한 네트워크는 freeze된 상태로 유지되고 있으며, Adapter 자체 구조는 오른쪽 부분을 참고하면 되는데 두 개의 linear layer와 가운데 활성 함수로 구성되어 있습니다. 식으로 나타내자면 아래와 같습니다.
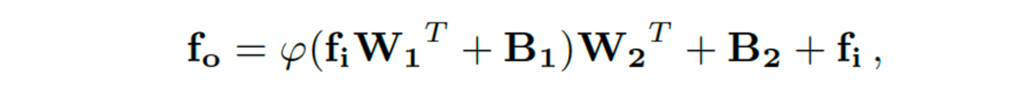
- W1, W2 : linear layer의 weight
- B1, B2 : linear layer의 bias
- f_i, f_o : Adapter의 input, output
2.4. Optimization
학습을 위해 detector와 recognizer의 본래 loss를 사용하였습니다.
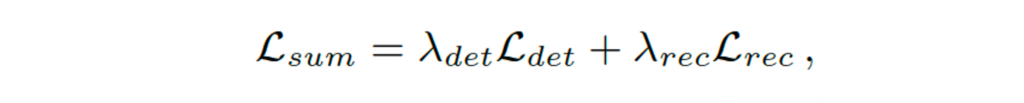
위 식과 같이 최종 loss는 이 둘을 가중합한 것이며, 저 가중치들은 둘 다 1로 설정되었습니다.
3. Experiments
본 논문에서는 사전 학습된 detector로 DPText-DETR을 사용하였고, recognizer로는 DiG를 사용하여서 DG-Bridge Spotter라고 명명하였습니다.
3.1. Comparison with State-of-the-art Methods
실험은 ICDAR2014 데이터셋과, Total-Text, CTW 1500 데이터셋에 대해 수행되었습니다.
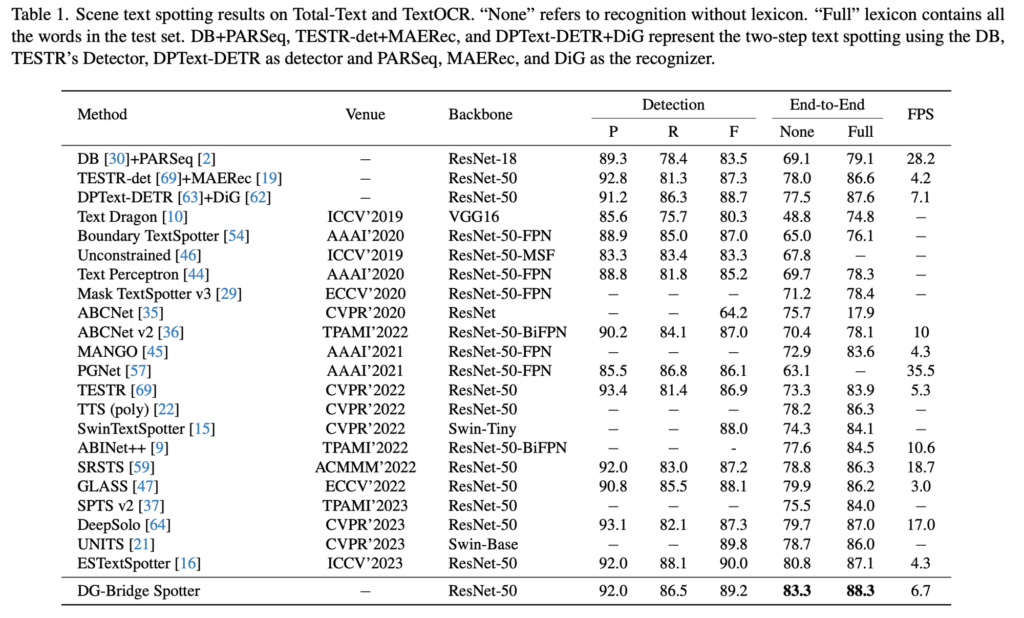
먼저 Total-Text에 대한 실험 결과입니다. 평가는 각각 detection 성능과 end-to-end로 recognition까지 했을때가 리포팅 되어 있으며, detection 평가 지표로 precision, recall, f1-score를 사용하였습니다. end-to-end 평가지표로 None, Full이라고 써져있는데 이는 각각 lexicon을 사용하지 않았을 때의 성능과 사용했을 때의 성능입니다. lexicon이란 평가하고자 하는 데이터셋에 포함된 text들이 들어있는 단어장이라고 생각하면 되는데, 예를 들어 lexicon을 사용해서 평가하는 Full의 경우에는 모델이 recognition한 text를 가지고 lexicon 내에서 가장 유사한 것을 찾아서 최종 예측으로 삼는 것이라고 보면 되겠습니다. Table1을 통해 실험 결과를 살펴보면, Full일때보다 lexicon을 사용하지 않는 None 상태에서 다른 방법론들보다 성능이 더 높은 것을 확인할 수 있습니다.
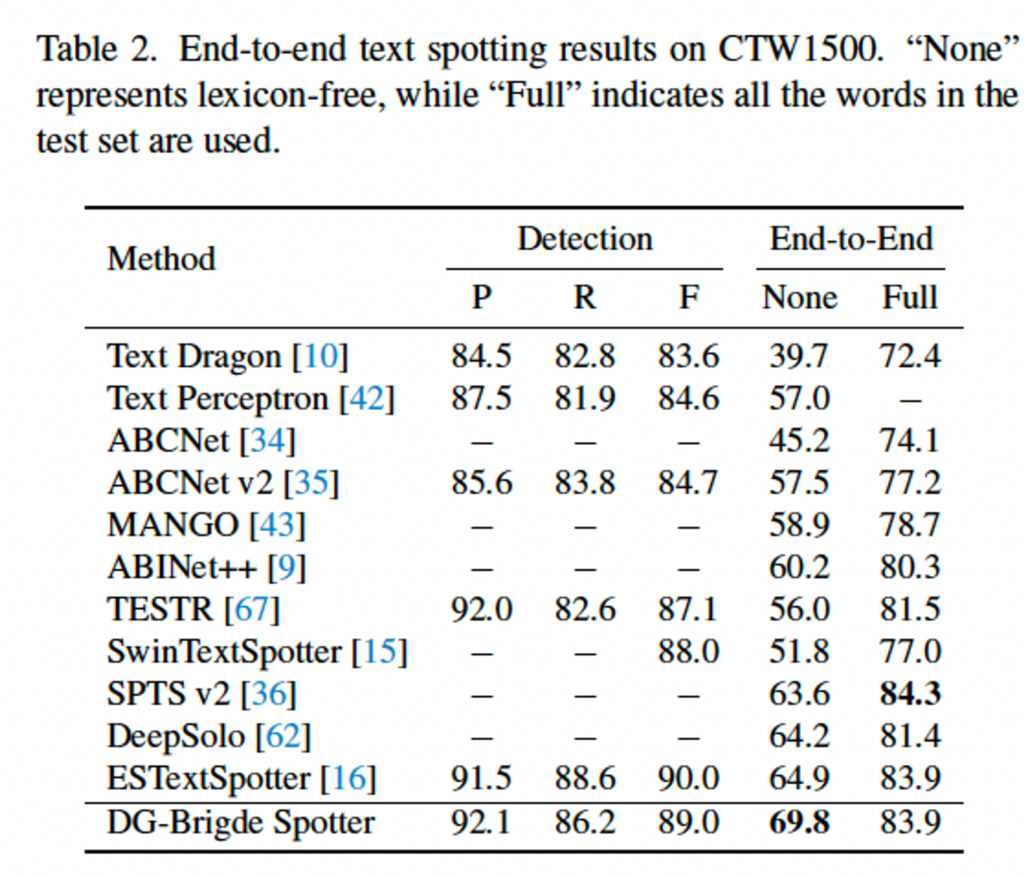
다음은 CTW1500 데이터셋에 대한 실험 결과입니다. Table2에서 볼 수 있듯이 None 평가지표에서 ESTextSpotter보다 4.9% 성능 향상을 보여 SOTA를 달성하였습니다. 반면, Full에서는 비슷하거나, 더 낮은 성능을 보였는데요. 저자는 이런 결과에 대해 ‘None’의 경우에 본 방법론은 baseline에서 잘못된 결과를 정확하게 인식해 더 높은 성능을 보인다고 합니다. 즉, detection 결과가 조금 잘못됐더라도 recognition을 다른 모델보다 정확하게 한 다는 의미로 보면 되겠습니다. 보통 이렇게 Full보다 None 성능이 좀 떨어지는 이유는 text 내의 소수의 문자가 잘못 인식되기 때문인데요, lexicon이 존재하는 이유도 이를 보정하기 위해서 입니다. 하지만 저자는 실제 real world에서는 lexicon은 일반적으로 존재하지 않다는 점을 지적하면서 None 성능을 어필하고 있습니다.
3.2. Ablation Studies
Ablation Study of The Bridge & the Adapter
Bridge와 Adapter의 효과를 입증하기 위해 total-text에 대해 ablation study를 수행한 결과는 아래 table4에서 확인할 수 있습니다.
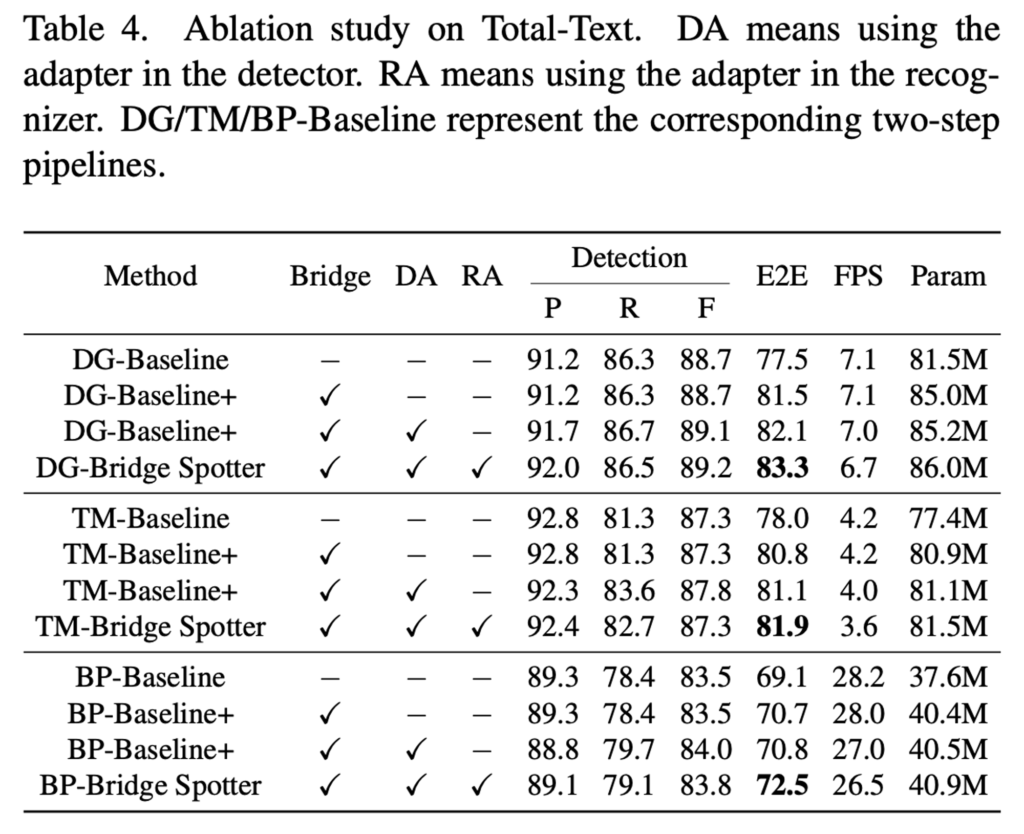
표에서 DA, RA가 각각 detection adapter, recognition adapter에 해당합니다. 또, 위에 성능 비교한 표에서 보인 모델은 DG-Baseline인데, 이 표에서 함께 보이는 TM-Baseline이나 BP-Baseline은 다른 detector와 recognizer를 사용한 것으로 각 모델의 한 글자씩을 따와 명한 것입니다. 먼저 baseline에서 bridge를 추가한 경우를 살펴보면 세 모델 전부에서 성능향상이 있었으며 DG-Baseline의 경우에는 4.0% 정도의 성능 향상이 있었습니다. 이를 보아 Bridge를 도입한 것이 성공적으로 detection feature와 recognition feature를 합친 것으로 볼 수 있겠습니다. 추가로 DA와 RA를 각각 추가하면 조금씩 성능향상이 되는 것을 볼 수 있습니다.
Ablation Study of the Zero-initialized Weight in Bridge
다음으로 bridge를 구성하고 있는 convolution과 linear layer의 초기 weight를 0으로 초기화한 것에 대한 ablation study입니다. 실험은 0으로 초기화한 것과, 가우시안 초기화했을 때를 비교하는데요, 변인통제를 위해 본 실험에서는 adapter를 제거한 상태로 수행되었습니다.
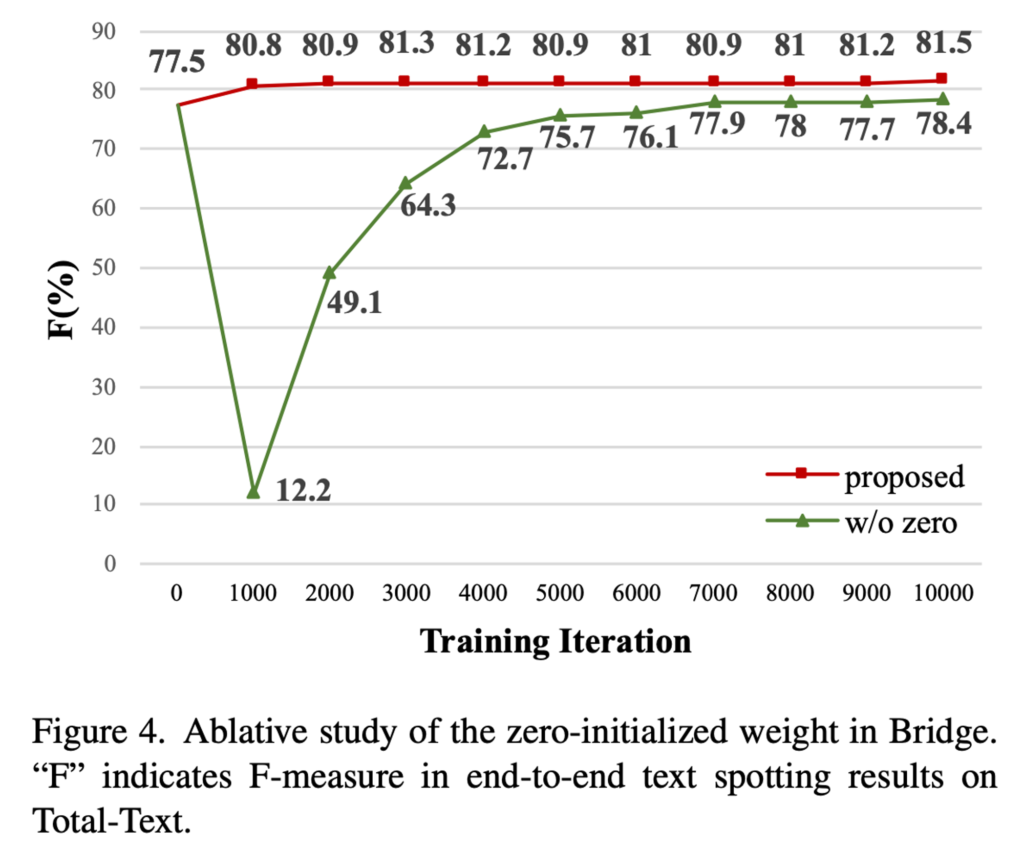
결과는 위 그림 4에 나와 있습니다. 보시면 Bridge내에서 zero 초기화를 했을 때가 빨간색 라인인데요, 초록색 라인보다 학습 초기에도 빠르게 적응하는 것을 확인할 수 있습니다. 최종적으로 77.5%에서 81.5%로 성능향상을 하는 것에 반해 가우시안 초기화를 사용하면 초기에 recognition head의 학습이 방해되어서 최종적으로 77.5%에서 78.4%로 약간의 성능 향상만 보였습니다.

DG-bridge Spotter의 정성적 결과 확인하며 마무리하도록 하겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
논문에서 제안하는 Bridge의 구조가 굉장히 단순해보이는데, 이렇게 구성하게 된 이유가 언급이 되어 있는지 궁금합니다. Conv와 linear 사이의 transformer encoder layer 개수와 같은 bridge 구조에 대한 ablation study가 존재하나요?
또 제안된 모델이 Full이 아닌 None에 대해 성능 향상이 더 큰 폭으로 일어난 이유가 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
bridge 모듈 구조의 transformer layer에 관련한 ablation study가 존재합니다. 0, 1, 3, 6개로 달리하여 실험해본 결과 0개 즉 bridge를 사용하지 않은 경우보다 1, 3, 6개의 transformer encoder로 구성된 bridge를 넣은 모델의 성능이 다 높게 나왔으며 그 중 1개를 사용한 경우의 e2e가 가장 높게 나와 이를 최종 선택하였다고 합니다.
또 제안된 모델이 full이 아닌 none에 대해 성능 향상이 더 큰 폭으로 일어난 이유는,,, full의 경우 lexicon을 사용하여 마치 모델의 prediction에 대해 추가적으로 classification을 수행하는 것이다보니, 조금 정확하게 예측하지 않다고 lexicon 내에서 유사한 단어를 잘 찾으면서 성능이 none보다 기본적으로 높게 되는데 none의 경우 기본적으로 모든 text를 잘 맞춰야하다보니 기본적으로 detection 성능에 크게 의존하게 됩니다. 그래서 단순히 bridging-spotting모델이 좀 더 recognition을 잘 할 수 있도록 detection 결과가 잘 나왔다고 보면 되겠습니다. .