이번에 소개드릴 논문은 CVPR2023에 게재된 Optical Flow 관련 논문입니다.
Intro
Optical Flow Estimation task에 대해서 간략하게 먼저 소개드리면, 해당 task는 두 연속된 frame에 대하여 pixel level로 상관관계를 계산하는 task입니다. 즉 t 시간 frame과 t+1 시간에 대한 frame 영상에 대해서 시간 흐름에 따라 영상 내 픽셀들이 얼만큼 움직였는지를 x,y에 대한 방향 벡터로 예측하는 것을 의미합니다. (그림1 참조)

이러한 Optical Flow는 영상 내 동적인 물체에 대한 움직임을 잘 표현하기 때문에 비디오 기반 연구 분야(e.g., action recognition, video inpainting, video frame interpolation 등)에서 많이 활용하는 것 같습니다. 물론 image registration 분야에서도 충분히 활용할 수 있고 stereo image를 입력으로 넣게 되면 depth를 추론하는 모델로도 활용할 수 있지요.
이러한 Optical Flow Estimation 방법론들은 주로 GT 데이터를 활용한 supervised learning 기반으로 학습합니다. 물론 self-supervised monocular depth estimation 방법론들처럼 GT 없이 영상만으로 학습하는 방법들도 2년 전까지는 몇몇 있는 것 같습니다만.. 지금은 잘 못 봤습니다.
그만큼 GT를 활용한 지도학습 기반 방식이 Optical Flow 분야의 주를 이루고 있는데, 사실 그림1을 보시면 아시겠지만 Optical Flow는 상당히 GT를 구하기 힘든 task 중 하나입니다. 그 힘들고 어렵다던 Segmentation 마저도 한장의 영상에 대해 의미론적인 부분에 대한 class만을 label로 부여하면 되지만, Optical Flow의 경우에는 두 장의 영상에 대해서 얼만큼 움직였는지에 대한 방향 벡터를 부여해야하니 사람이 손으로 작업하기가 거의 불가능에 가깝습니다.(픽셀 레벨로 대응점을 매칭한다고 보면 됨.)
그래서 Optical Flow 방법론들은 모델 학습을 위해 합성 데이터를 활용합니다. 가장 대표적으로 Flying Chairs와 FlyThings3D 데이터 셋이 있는데, 데이터 셋 이름만 들어보면 왜 저렇게 이름을 지었을까.. 라는 생각이 드실 수 있습니다. 하지만 실제로 그림2 예시를 보시면 이것보다 이름을 잘 지을 수 없다 라고 생각이 드실 겁니다.

그냥 배경 이미지에 의자 영상을 붙여넣기한 영상입니다. 보다 구체적으로는 FlyingChairs 데이터 셋을 만들 때 Flickr 데이터 셋 중 city, landscape, mountain 카테고리에서 영상을 가져와 background로 사용하였고, publicly available 3D chair model을 foreground로 사용하여 만들었다고 합니다. 따라서 해당 데이터 셋은 뷰 포인트에 따른 대상의 외형 변화와 밝기 값 등이 온전히 고려되지 않아 단순한 데이터 셋이라고 보시면 됩니다.
그 다음에 Flytings3D 데이터 셋 역시 비슷하게 의자 외에도 다양한 사물들이 foreground로 나타나는 데이터 셋인데, 제가 알기로 Flying Chairs와 달리 시점 변화에 따른 객체의 밝기나 외형이 다양하게 변화되어 조금 더 어려운? 데이터 셋이라고 합니다.
아무튼 이러한 Flying 데이터 셋들로 먼저 모델을 학습한 후, 이후에 target 도메인에 대하여 fine-tuning을 하는 식으로 최종적인 optical flow 모델을 생성하게 됩니다.(Sintel(애니메이션) or KITTI 주행 데이터 셋)
지금까지 optical flow task에서 학습을 어떤식으로 진행하는지에 대해 간략하게 소개를 드렸습니다. 논문 리뷰로 바로 넘어가지고 않고 이렇게 task 자체에 대한 설명을 드린 이유는 본 논문이 이러한 optical flow의 학습 방식에 대해 현 문제를 지적하고 새로운 방식을 제안하기 때문에 이해를 돕고자 기존 방식을 설명드린 것입니다.
우선 논문에서 제안하는 학습 방식에 대해서 다루기 전에, 논문에서 많은 영감을 얻었다는 Geometric Image Matching(GIM) task에 대해서 설명하고 가겠습니다. GIM task란 제가 지난 주에 리뷰했던 LoFTR 논문에서 풀고자 하는 문제와 동일한 것으로 서로 다른 시점으로 촬영된 두 영상에 대한 correspondence point를 찾고 matching을 수행하는 task를 의미합니다.

GIM task 역시 두 장의 이미지에 대하여 대응관계를 계산하는 분야이기 때문에, Optical Flow와 매우 비슷한 목적이라고 볼 수 있겠습니다. 다만 Optical Flow의 경우에는 픽셀 레벨로 모든 관계를 정의하고자 하는 반면에 GIM은 interesting point에 대하여 대응 관계를 계산하려고 하는? 어찌보면 조금 더 쉬운 task라고 볼 수도 있겠습니다.(물론 LoFTR 논문 리뷰에서도 말씀드렸다시피, 요즘은 keypoint 추출은 스킵하고 dense level에서의 descirptor 추출 및 matching으로 바로 넘어가는 추세라고 합니다.)
아무튼 Optical Flow와 GIM은 서로 비슷한 부분이 매우 많습니다. 두 영상 사이에 대응관계를 계산해야하다보니, 대응관계를 계산하기 어려운 상황들이 모두 비슷합니다.(두 영상 사이에 시차가 크게 벌어지는 large displacement, occlusion, textureless region 등)
하지만 한가지 고려해볼 점은 GIM의 경우 보통 두 영상이 서로 정적인 상태에서 촬영되었기에 빠르게 움직이는 동적인 물체 등이 나타날 확률이 적고 따라서 외형의 변화가 심하지 않다고 합니다. 그리고 Large Displacement 상황도 적다고 합니다(제가 알기론 optical flow가 훨씬 더 연속적인 프레임이라서 large displacement가 적은걸로 아는데.. 이 부분은 저자가 왜 그렇게 생각했는지 모르겠네요?). 반면에 Optical Flow는 비디오 시퀀스와 같이 동적인 이미지에서 추론하고 학습한다는 느낌이 강하기 때문에 객체들의 외형 변환이 더 심하게 나타나며 따라서 optical flow 데이터 셋들은 GIM 보다 학습이 더 어렵다고 합니다.
그래서 저자는 기존의 Optical Flow 기반 방법론들의 학습 framework 전에 먼저 정적인 장면들로 구성된 GIM 데이터 셋으로 사전학습을 수행함으로써 Optical Flow 모델이 보다 더 학습이 잘되도록 해야 한다고 주장합니다. 이에 대하여 조금 더 구체적인 설명은 드리면, 기존의 Optical Flow 방법론들은 위에서도 설명드렸다시피 합성 데이터 셋으로 먼저 학습한다고 말씀을 드렸는데, 이러한 합성 데이터 셋(Flying Chairs + FlyThings3D)을 한번에 섞어서 학습하는 것이 아닌 난이도 순서대로 차례로 학습합니다.(즉 쉬운 데이터 셋부터 학습하여 점차 어렵게 학습하는 curriculum learning 방식)
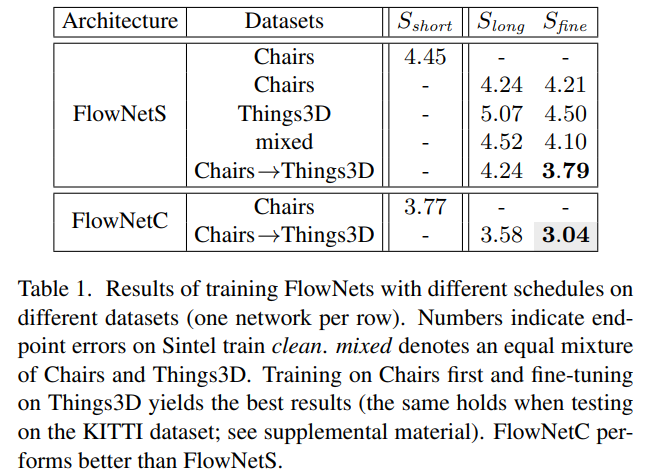
이는 2017년 FlowNet2.0에서 모델을 학습시킬 때 데이터 셋을 mixing 시켜서 학습하는 것보다 순서대로 학습시키는 방식이 더 좋은 성능을 보여주었기 때문에, 그 이후로 모든 방법론들이 flownet2.0과 동일한 학습 방식을 채택하고 있습니다.
하지만 6년이라는 시간이 흐른 지금, 본 논문의 저자는 이러한 학습 방식을 보완하여 Flying Chairs로 optical flow를 학습하기 이전에 먼저 GIM task 용 데이터 셋으로 사전학습을 하자는 것이죠. 이는 FlyingChairs가 Optical flow 데이터 셋들과 비교하여 단순하고 쉬운 데이터 셋으로 보이지만 GIM 데이터 셋과 비교하면 여전히 모델이 학습하기 힘들고 어려운 데이터 셋이라고 합니다.(지도학습 주제에 모델 학습이 어렵네 마네 하는 모습이 상당히 깜찍하네요. self-supervised learning 기반 연구를 해봐야 정신차리지)
다행히도 GIM 기반 데이터 셋은 두 카메라의 pose 정보와 Depth 정보를 GT로 활용할 수 있기 때문에 Optical Flow보다 훨씬 더 쉽게 GT를 구하고 데이터 셋을 모을 수 있어서 방대한 양의 real data로 모델을 학습시킬 수 있다고 합니다. (다른 분야에선 camera pose와 depth GT도 cost가 많이 든다고 지적하는데, 아무래도 Optical Flow는 GT 구하는게 너무 힘들다보니 이런식의 표현이 설득력 있게 느껴지는 것이 아닐까 합니다.)
그럼 논문에서 제안하는 contribution에 대해 간략히 요약하고 방법론으로 들어가보도록 하겠습니다.
- 해당 논문은 기존의 Optical Flow pipeline을 새롭게 재정의합니다. 즉 GIM task를 새로 사전 학습시켜서 optical flow task에 더 좋은 성능을 낼 수 있도록 합니다.
- 논문에서는 새로운 matching-based optical flow estimation module(MatchFlow)을 제안합니다. 해당 모듈은 두 영상 사이에 4D correlation volume을 계산하기 위한 모듈이며, ResNet16/8과 self/cross -Quadtree attention block으로 구성이 되어 있습니다. 이러한 MatchFlow 모듈은 GIM dataset으로 사전 학습을 하기 때문에 이후의 optical flow dataset의 curriculum learning을 더 효과적으로 수행할 수 있다고 합니다.
- GIM task의 방대한 real data로 학습을 수행하였기 때문에, 제안하는 MatchFlow는 장면 내 consistent motion에 강건하게 특징을 추출할 수 있으며, appearance 변화, occlusion, large displacement와 같은 두 테스크(optical flow와 GIM)에서 모두 발생할 수 있는 어려운 상황들을 해결할 수 있다고 합니다.
Method
Pipeline Overview
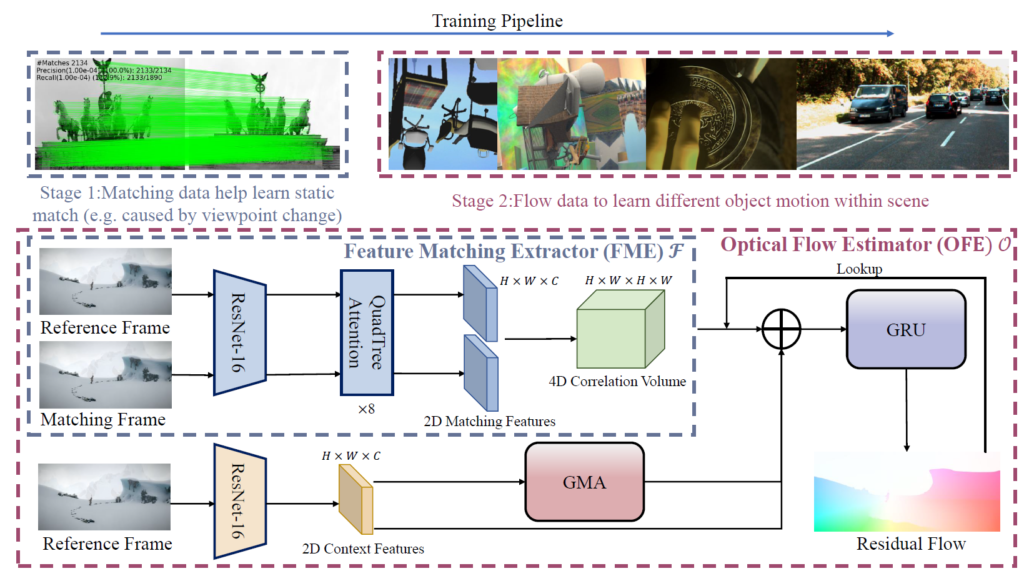
일단 모델의 전반적인 framework은 그림4에서 확인하실 수 있습니다. 대략적으로는 Feature Matching Extractor(FME)(( \mathcal{F} )) 모듈이 하나 존재하고 있고, 그 다음에 Optical Flow Estimator(OFE)(( \mathcal{O} )가 존재하는 것을 볼 수 있습니다. 여기서 OFE는 GMA와 GRU라는 모듈이 각각 존재하는데, GRU는 20년도 즈음에 제안된 RAFT라는 optical flow 방법론의 핵심 구조로 본격적인 flow estimation을 하는 모듈로 이해하시면 될 것 같습니다.
또한 GMA의 경우에는 Global Motion Aggregation Module의 약자로 영상 문맥의 self-similarity를 추출하여 occluded region에 대한 optical flow의 성능을 향상시키는 모듈이라고 합니다. 다시 말해, GRU와 GMA는 기존 optical flow 방법론의 모듈들이며 이때 GRU는 flow estimation을 직접적으로 수행하는 모듈, GMA는 flow map의 성능을 보완해주는 보조 모듈로 이해하시면 좋을 것 같습니다.
그리고 저자가 제안하는 핵심 부분은 FME 파트로 FME 내부는 영상의 특징을 추출하는 Resnet16, 그리고 추출된 특징으로부터 QuadTree Attention이라고 하는 모듈이 존재합니다. 이 QuadTree Attention을 통과해서 나온 2d matching features들을 채널축으로 내적하여 4D correlation volume을 계산하여 OFE 파트의 입력으로 사용됩니다. 여기서 중요한 점은 FME 파트는 optical flow 뿐만 아니라 GIM dataset으로 사전학습이 진행되는 부분이기도 합니다.
위 과정을 수식적으로 표현하면, 입력으로 들어오는 이미지를 I_{1}, I_{2} 라고 하였을 때, ( \mathcal{F} )를 통해서 4D correlation map C를 계산합니다. 그리고 이 C를 ( \mathcal{O} )의 입력으로 넣어서 최종적으로 픽셀 별 displacement 값을 의미하는 flow field( f^{1}, f^{2} )를 계산하게 됩니다.
Geometric Image Matching Pre-training
Intro에서도 소개드린 것처럼, flownet2를 시작으로 대부분의 optical flow 방법론들은 합성데이터셋을 순서대로 학습 후 target dataset으로 fine-tuning하는 과정을 거친다고 했었습니다. 여기서 FlyingChairs 데이터 셋은 약 2만2천장, Flyingthings3D는 8만8천 장으로 구성되어 있어 대략적으로 11만장 정도의 데이터 셋으로 사전학습을 하는 것이죠.
하지만 결국 이 두 데이터 셋은 합성 데이터 셋이기 때문에, real data와 거리감이 확실히 존재합니다. 더 나아가, FlyingChair 데이터 셋의 경우에는 데이터를 생성할 때 background image와 foreground image를 합성할 때, 서로 다른 객체들 사이에 혹은 배경과 전경 사이에 모션이 일정하게끔 고려하여 만들지 못하였다고 합니다. 이러한 관점에서, 저자는 FlyingChair 데이터 셋이 simple한 motion으로 구성된 가장 쉬운 데이터 셋인가?라는 의문을 제기합니다.
따라서 저자는 모델 학습에 사용할 가장 단순하고 쉬운 데이터 셋으로 GIM task의 데이터 셋들을 활용할 수 있다고 적극 주장합니다. GIM은 두 장면 자체가 매우 일정하게 구성되어 있기 때문에 motion 자체가 매우 단순하다고 볼 수 있다는 것입니다. 게다가 GIM dataset은 다양한 displacement와 appearance 변화로 구성된 방대한 양의 real-data이기 때문에 모델의 generalization 성능에도 도움이 줄 수 있다는 것이죠.(물론 새로운 데이터 셋들로 fine-tuning하는 과정에서 기존의 정보들이 얼만큼 남아있을지 의문이긴 합니다.)
다만 한가지 문제점으로, GIM 데이터 셋은 결국은 GIM task에 초점을 맞추어 구성된 데이터 셋이기 때문에 오직 두 영상 사이에 non-occluded region에 대해서만 대응관계를 GT로 보유하고 있습니다. 그리고 그 마저도 pixel level의 dense한 수준이 아닌 sparse한 수준이죠.
따라서 저자는 optical flow estimation 전체 모델에 대해서 GIM 데이터 셋을 학습하는 것이 아닌, 두 영상 사이에 대응관계를 계산해야하는(즉, correlation map을 만들어야만 하는) Feature Matching Extractor에 대해서만 GIM 데이터 셋으로 학습을 진행하였다고 합니다. sparse한 GT 값을 가지고 두 영상 사이에 대응관계를 정의하고 대응관계를 잘 보아야하는 FME 파이프라인이 학습을 하는 것이죠.
FME은 그림4에서도 확인할 수 있다시피 ResNet과 Quad Tree block으로 구성이 되어 있다고 합니다. ResNet이야 영상의 특징을 추출하는 추출기로 사용했다고 보고 넘어가면 될 것 같고, QuadTree? block이라는 명칭이 조금 생소한데 쉽게 얘기하면 Transformer 구조의 attention module이라고 생각하시면 될 것 같습니다.
조금 더 구체적으로 QuadTree block은 작년 ICLR2022에 게재된 논문으로 쉽게 말해 Transformer의 기존 self-attention 방식은 영상의 해상도에 대해 제곱에 해당하는 연산량을 잡아먹게 되니, 이러한 연산 증가량을 linear하게 만들기 위해 새롭게 제안된 transformer 구조라고 합니다.
연산량을 줄이기 위한 quadformer의 대략적인 컨셉은 기존의 single-scale의 토큰과 달리 pyramid 형식으로 multi-scale token을 만든 뒤 coarse-to-fine 형식으로 각 스케일별로 attention을 수행한다고 합니다. 이때 각각의 스케일 레벨 별로 top-K개의 token을 선정하면 다음 레벨의 토큰 맵에서는 이전에 선정된 top-k개와 관련 있는 영역에 대해서만 attention 연산이 이루어진다고 합니다.
즉 Coarse 레벨에서 high score를 계산하고, 그 중에서 스코어가 높은 영역들(top-k) 내에 또 미들 스코어로 쪼개서 attention 연산 및 스코어 계산하고, 그 다음 top-k에 대해서 또 골라서 fine-level의 attention을 수행하는 coarse-to-fine 형식의 attention 이라고 보시면 될 것 같습니다.
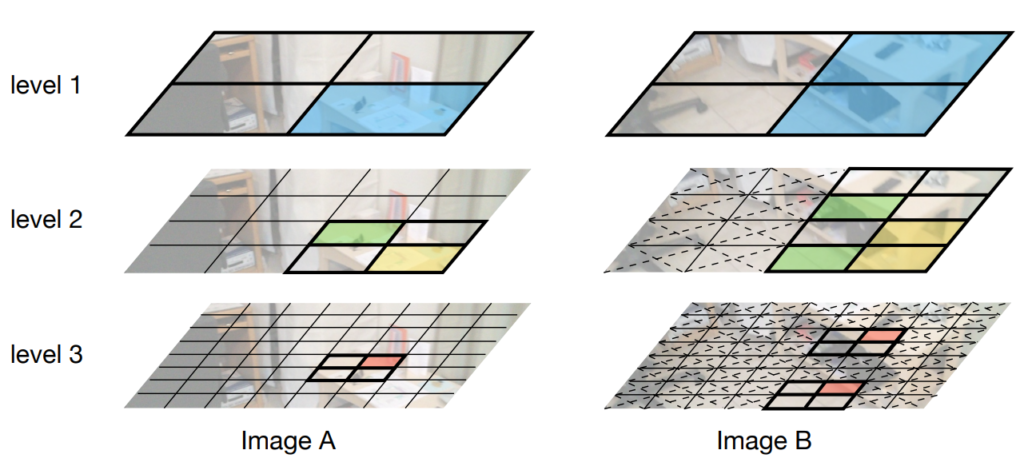
아무튼 이러한 QuadTree Attention block을 MatchFlow 논문의 저자는 그대로 활용했기 때문에 사실 별다른 QuadTree에 대한 설명을 논문에서 언급하지는 않고 있습니다. 그냥 Resnet16에서 나온 feature map을 QuadTree 기반 attention module에 N번 태우고(이때 Self/Cross attention을 모두 수행) 그렇게 타고 나온 feature map에 대해서 4D Correlation volume을 계산하게 됩니다.
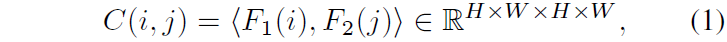
참고로 위에 식에서 F_{1}, F_{2} 는 각각 image1와 image2에서 resnet16을 통해 추출한 feature map을 의미하고, 꺽세 괄호는 Channel 축에 대해서 행렬곱 내적을 했다는 의미로 풀이됩니다. 저 특징맵들이 모두 원본 해상도의 1/8 해상도의 H,W 스케일을 지니고 특징맵이다보니 D 채널을 지니고 있기 때문이죠.
Pretraining Loss
그러면 이 GIM 데이터 셋으로 모델을 어떻게 사전학습을 시킬 수 있을까요? 논문에서는 단순히 loss를 계산하기 위해서 4D correlation map에 대해 dual-softmax 연산을 수행하였다고 합니다. 이렇게 dual-softmax 연산을 수행하게 되면 대응관계에 대한 matching probability( \matchcal{P}_{c} )를 계산할 수 있기 때문이죠.
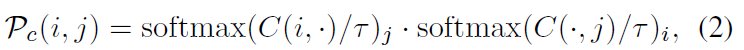
참고로 저기서 softmax 연산에 들어가는 temperature parameter 값은 0.1로 들어간다고 합니다. 참고로 모델 학습에 사용할 GT correspondence matching 값은 실제 깊이 정보와 두 영상 사이에 카메라 pose 값을 이용해서 구할 수 있으며, Correlation volume이 1/8 스케일이기 때문에 GT 매칭 결과도 1/8 수준으로 줄였다고 합니다.
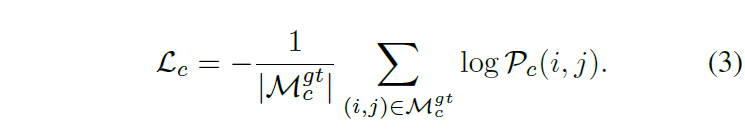
사실 이러한 loss 계산 방식은 제가 지난 주에 리뷰한 LoFTR 논문의 방식과 동일하기 때문에 해당 학습 방식 및 dual-softmax에 관련한 부분은 지난 주 리뷰를 참고부탁드립니다.
Optical Flow Refinement
이렇게 GIM 데이터 셋으로 FME 파트를 학습을 시켰다면 그 다음에는 이전의 방법론들과 동일하게 optical flow 데이터 셋으로 학습을 진행하면 됩니다. 결국 이 논문에서 제안하는 방식은 따로 없고… 결국 기존 방법론들의 짬뽕이라서 따로 설명드릴게 없네요. 그냥 GT가지고 optcai flow 네트워크들을 학습시키는 과정이고 loss function은 다음을 사용했다고 합니다.
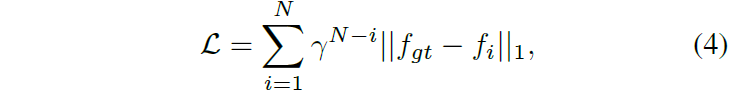
여기서 i=1~N까지의 의미는 해당 방법론이 RAFT의 GRU 모듈을 활용했기 때문인데, 요약하면 RAFT 방법론을 시작으로 optical flow의 잔차를 N번 추론해서 refinement하는 방법들이 대세를 이루고 있었습니다. 본 논문도 RAFT의 GRU 모듈을 기반으로 flow map을 추론하기 때문에 N번 계산 각각에 대해 flow map의 잔차를 GT와 비교한다고 생각하시면 될 것 같습니다.
Expeirments
일단 평가용 데이터 셋으로는 애니메이션 데이터 셋인 Sintel과 주행데이터셋인 KITTI 데이터 셋으로 많이들 평가를 합니다. 해당 데이터셋들에 대한 정량적 결과 비교 표는 아래와 같습니다.
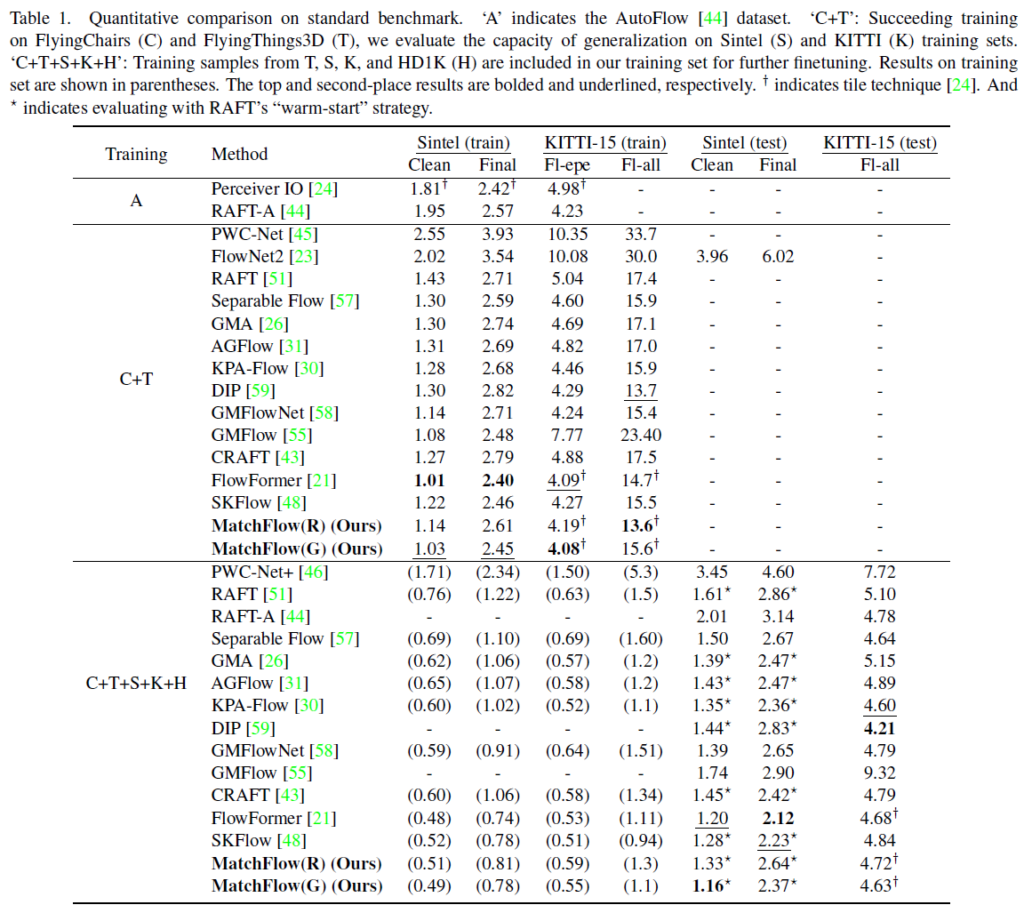
먼저 Sintel 데이터 셋에 대한 결과부터 살펴보시죠. MatchFlow가 본 논문에서 제안하는 방법론이며 옆에 (R)은 Global Motion Aggregation Module이 존재하지 않을 때, (G)는 GMA 모듈이 존재할 때의 성능을 의미합니다.
제안하는 방법론이 Sintel 데이터 셋에서(C+T)데이터 셋 기준 FlowFormer 다음으로 2번째의 좋은 성능을 보여주고 있는 것을 볼 수 있습니다. 비록 최신 논문들 중에서 가장 좋다!는 아니지만 지금 MatchFlow 방법론은 예전 방법론들인 GMA와 RAFT의 모듈들을 조합하여 구성된 모델인데 GMA와 RAFT 방법론 대비 20% 넘는 성능 향상을 보여주고 있습니다.
또한 C+T+S+K+H의 학습 조합에서는 Sintel Test 데이터 셋(clean)에서 flowformer를 제치고 가장 좋은 성능을 보여주고 있습니다.(반면에 Final에서는 성능이 좀 많이 부족하네요?)
KITTI 데이터 셋의 경우에도 마찬가지로 MatchFlow가 자신들의 base 모델인 GMA, RAFT보다 좋은 성능을 보여주고 있으며, 이는 GIM 데이터 셋으로의 사전학습이 나름대로 성공적이라고 볼 수 있을 것 같습니다.
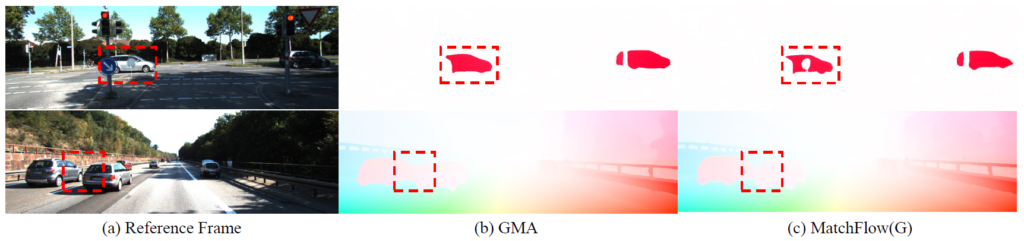
또한 그림 6에서 GMA는 차 앞에 동그란 표지판이 가리고 있음에도 불구하고 표지판을 무시한 채 차의 온전한 모양에 대하여 flow map을 계산하거나(첫번째 행), 두 차가 떨어져있음에도 불구하고 두 차의 flow map 영역을 이어서 예측하는 등(2번째 행)의 모습을 보이지만, 제안하는 방법론은 이러한 작은 물체, boundary에 대해서도 정밀한 예측을 수행했다는 평입니다.
Ablation Study
다음은 ablation study에 대해서 살펴보겠습니다.
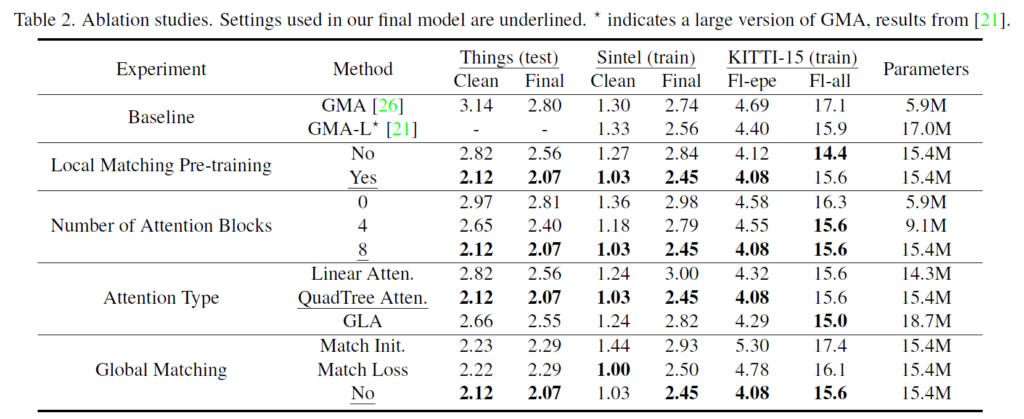
먼저 baseline은 GMA 방법론이고, 여기서 “Local Matching Pre-training”이 GIM 데이터 셋으로 사전학습하는 단계를 의미합니다. 여기서 No라고 표기된 부분은 일단 GIM 데이터 셋으로 사전 학습은 전혀 하지 않았지만, Feature Matching Extractor 부분에서 QuadTree attention block을 활용한 상황이기 때문에 baseline 대비 Tinghs, Sintel, KITTI에서 좋은 성능을 보여주는 모습입니다. 즉 두 영상 사이에 대응관계를 고려할 때 transformer 기반 attention이 큰 도움이 된다고 볼 수 있겠네요.
그리고 Local Matching Pre-training이 yes 인 경우에는 사전학습을 수행하였기 때문에 Things, Sintel에서 매우 큰 성능 향상을 보여주고 있습니다. 반면에 KITTI에서는 성능 향상이 그리 크지는 않았으며 오히려 F1-all 메트릭에서는 사전학습을 안하는 것이 더 좋은 성능을 보여주는 결과도 보이네요. 이 부분은 조금 아쉽게 느껴집니다.
그 다음 실험으로는 Number of Attention Block 관련 실험입니다. 즉 attention block을 몇개를 넣었을 때 가장 좋은지를 나타내는 것인데, 확실히 다다익선이라고 attention block의 개수를 더 키울수록 성능에 유의미한 결과를 나타내는 모습입니다. 여기서 한가지 아쉬운 점은 8개 그 이상도 한번 정도는 보여주면 좋았을 것 같은데, 아무래도 학습 GPU가 부족해서 8개까지만 한 것이 아닐까 싶습니다.
Attention 방식 역시도 LoFTR에서도 활용했던 Linear Attention과 Global-Local-Attention(GLA)와 비교를 해보았는데 결과적으로 QuadTree Attention이 가장 좋았다고 합니다.
Paramters, Timing, and GPU Memory
다음은 모델의 크기 및 학습/추론 속도와 메모리 등을 비교한 표입니다.
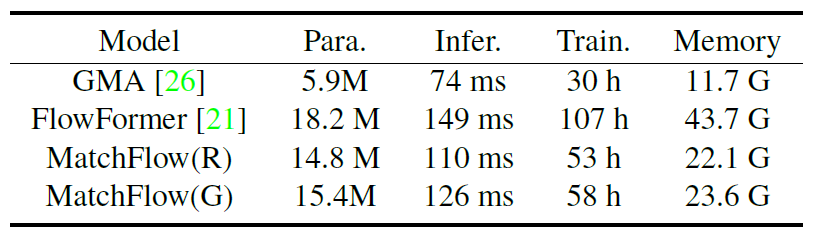
아무래도 해당 표를 보여주는 이유는 FlowFormer가 계속해서 좋은 성능을 보여주었기 때문에 이에 대해 FlowFormer가 매우 무겁고 학습이 오래걸린다는 모델인걸 설명하기 위해 가져온 표가 아닐까 합니다.
그래서 해당 방법론의 베이스라인이었던 GMA도 함께 표기한 모습입니다. GMA의 경우에는 파라미터 수도 적고 따라서 추론 속도 및 학습 시간도 거의 MatchFlow와 2배 차이가 나게 됩니다.
MatchFlow의 경우에는 QuadTree Attention block으로 인해서 파라미터 수도 3배 가까이 늘어나고 학습 속도 및 추론 속도도 절반 가까이 증가하는 모습인데, QuadTree로 인한 성능 향상이 뚜렷하다는 점에서 어쩔 수 없는 추론 속도의 희생으로 보입니다. 한편 FlowFormer는 파라미터 수는 MatchFlow와 비슷한데 추론속도가 149ms로 거의 1초에 7장 처리하는 속도를 보여 매우 느린 축에 속합니다.
그리고 모델 학습시에도 2배치 사이즈로 43.7G나 먹는 바람에 학습에 많은 양의 GPU가 필요하다는 점이 있겠으며 학습 시간도 107시간으로 모델 학습 한번 하는데 4일이 넘는 시간이 걸리는 모습입니다. 이런 점에서 미루어보면 MatchFlow가 FlowFormer보다는 성능이 조금 부족하지만 학습 메모리 및 속도가 정확도 성능 대비 큰 차이가 난다고 볼 수 있겠습니다.
결론
사실 처음 읽었을 때는 QuadTree attention block도 본인들이 제안하는 방법론도 아닐 뿐더러, 그저 GIM task의 데이터 셋으로 사전 학습하는 것 말고는 새롭게 제안한 기법들이 없는 것 같아서 아쉬운 생각이 많이 들었는데, 논문에 실험도 꼼꼼하게 진행하고 디테일들을 많이 남긴 것 같아서 리뷰어들의 만족감을 사지 않았을까 합니다.(원래 이게 리뷰어들의 궁금한 점을 많이 해결해주면 리뷰어들이 좋아하거든요.)
이 논문을 보면서 드는 생각이 Optical Flow에서 현재 SOTA라고 나온 논문들(22~23년도 기준)이 대부분 속도가 많이 느리고 무거운 것으로 보여집니다. A6000에서 평가했는데 Matchflow도 126ms 나오는거면… 실시간 추론성이 많이 떨어져보이긴 해서 이 부분을 해결하면서 성능을 유지할 수만 있다면 좋은 논문을 쓸 수 있지 않을까 합니다.
안녕하세요. 신정민 연구원님.
좋은 리뷰 감사합니다. 덕분에 비디오 연구에서 자주 마주하면서도 어떻게 생성되는지, 어떤 어려움이 있는지 잘 몰랐던 optical flow의 생성 과정과 한계, 최근 연구를 알 수 있었습니다.
이 논문을 요약하자면, optical flow generation과 유사한 GIM task를 통해 optical flow 생성 모델을 합성 데이터셋이 아닌 데이터로 사전학습시켜 성능을 향상하자는 것으로 이해하였습니다.
이는 기존 방법들과는 상당히 다른 방법으로 보이는데, 이렇게 각기 다른 방법으로 생성된 optical flow를 같은 모델에 사용했을때 뭔가 차이가 발생할지 의견을 여쭙고 싶습니다. (예를 들어, flowformer가 만든 optical flow로 학습된 모델에 이 모델이 만든 flow를 입력)
추가로, 제가 아직 안목이 부족하여 이 논문이 다른 논문 대비 리뷰어에게 좋은 인상을 줄 수 있는 점을 잘 느끼지 못하였는데, 리뷰어가 좋아할 만한 부분을 짚어주시면 제 논문 분석력 향상과 작성에 큰 도움이 될 것 같습니다.
감사합니다?
댓글 감사합니다.
첫번째 질문은 대면으로 얘기를 나눴으니 넘어가겠습니다.
두번째 질문으로는 제가 x리뷰에 내용을 모두 담지는 않았지만, 사실 논문에서는 Sintel 뿐만 아니라 KITTI 데이터 셋에 대해서도 ablation study를 진행하고 있고, 그 외에 데이터 셋 별로 발생할 수 있는 inference 관련된 세팅들에 대해서도 자세히 리포팅 및 세팅에 따른 성능을 테이블로 보여주고 있습니다. 즉 리뷰어들이 궁금할법한(특히 관련된 분야를 연구하는 연구자라면 궁금할법한) 다양한 실험들을 선제적으로 진행함으로써 리뷰어들이 궁금할 요소들을 해소해주는 것처럼 보여서, 리뷰어들이 좋아할법하다라고 표현하였습니다.