이번 리뷰는 monodepth로부터 추출된 pseudo-lidar를 이용한 3차원 물체 검출을 제안한 방법론에 대해 다루고자 합니다. 솔직히 말씀드리자면 해당 논문의 신규성은 떨어지는 편이긴 합니다. 하지만 기존의 방법론들이 psuedo-lidar가 사전 학습된 depth 모델의 성능에 큰 영향을 받는다는 문제점과 이를 해소하기 위해 제안된 end-to-end 방법론들은 depth에 대한 GT를 활용한 지도학습을 수행하는 문제점을 해소하기 위해 비지도 학습 기반인 monodepth2를 베이스 모델로 활용한 성능을 리포팅합니다.
Intro
3차원 물체 검출은 모빌리티가 자율적으로 환경을 인식하여 작동하기 위해서는 필수적인 정보입니다. 3차원 물체 검출은 실제 세계로부터 물체의 기하학적 특징을 검출하여 물체의 3차원 위치 인식과 분류를 수행합니다. 실제 세계의 기하학적 정보를 습득하기 위한 대표적인 센서는 LiDAR를 들 수 있습니다. LiDAR는 빛을 쏘는 패시브와 쏘아진 빛이 물체로부터 반사되어 돌아온 빛을 수용하는 리시브로 구성되어 빛이 돌아오는 시간으로부터 거리 값을 측정합니다. 실제 세계에서의 거리값을 측정한 신뢰할 수 있는 정보이기에 많은 데이터 셋에서는 LiDAR 센서 데이터를 깊이 정보로 활용합니다. 또한 해당 정보를 활용하여 뛰어난 성능을 가진 3차원 물체 검출 연구들이 수행되어졌습니다.
LiDAR의 뛰어난 성능에도 불구하고 센서의 높은 가격으로 상용화에 어려움을 가진다는 문제점이 있습니다. 연구 커뮤니티에서는 비용 문제를 극복하기 위해 상대적으로 적은 가격을 가진 카메라를 이용한 3차원 물체 검출에 대한 연구가 활발히 진행되고 있습니다. 현재 카메라를 이용한 2차원 물체 검출의 높은 성능에도 불구하고 영상 정보는 실제 세계의 기하학적 정보가 영상 좌표계로 투영되어 소실되기 때문에 LiDAR 기반의 3차원 물체 검출 대비 낮은 성능을 보여준다는 문제점이 있었습니다.
그러던 와중 2019년에 개최된 CVPR에서 영상 기반의 깊이 추정 모델로부터 깊이 정보를 카메라 파라미터를 이용하여 실제 세계 좌표계에 투영한 Pusedo-LiDAR를 LiDAR 기반의 3차원 물체 검출을 수행함으로써, 이전 방법론 대비 높은 성능 개선을 보여주었습니다. 이후 기존 방법론의 문제점을 개선한 아류 방법론들이 많이 등장하며 점진적으로 성능 개선을 보여주고 있습니다.
대표적인 방법론으로 기존 방법론이 사전학습된 깊이 추정 모델을 활용함으로써 깊이 추정 모델 성능에 의존적인 문제점을 해소하고 대다수가 백그라운드인 영상 정보로부터 검출하고자 하는 물체에 집중하여 깊이 추론 성능을 향상시키기 위해 깊이 추정 모델과 3차원 물체 추정 모델을 결합한 end-to-end 방법론 E2E-PL이 있습니다.
이번 리뷰 논문은 E2E-PL의 장점을 계승하고자 E2E-PL을 베이스 모델로 구성합니다. 대다수의 영상 기반의 3차원 물체 검출 태스크에서는 스테레오를 이용하여 3차원 물체 검출을 수행합니다. 스테레오는 두 카메라의 거리, 베이스라인을 이용하여 절대 깊이를 추정할 수 있는 반면에 단안 영상은 실제 세계의 스케일을 측정할 수 있는 방법이 없기에 스케일 모호성 문제를 겪습니다. 그렇기에 단안 영상은 비교적 낮은 정확도로 단안만을 이용한 시도가 적었습니다. 저자는 이러한 문제점을 해결하기 위해 E2E-PL에 단안 기반의 깊이 추정 모델 Monodepth2를 활용합니다. 추가로 깊이 추정 모델을 학습하기 위해서는 결국 LiDAR를 활용한 GT depth를 이용하는 한계를 극복하기 위한 통찰력을 제공하기 위해서 비지도 학습(M)과 지도 학습(D), 두 가지(MD)를 모두 깊이 추정 모델에 적용한 성능을 리포팅합니다.
Method
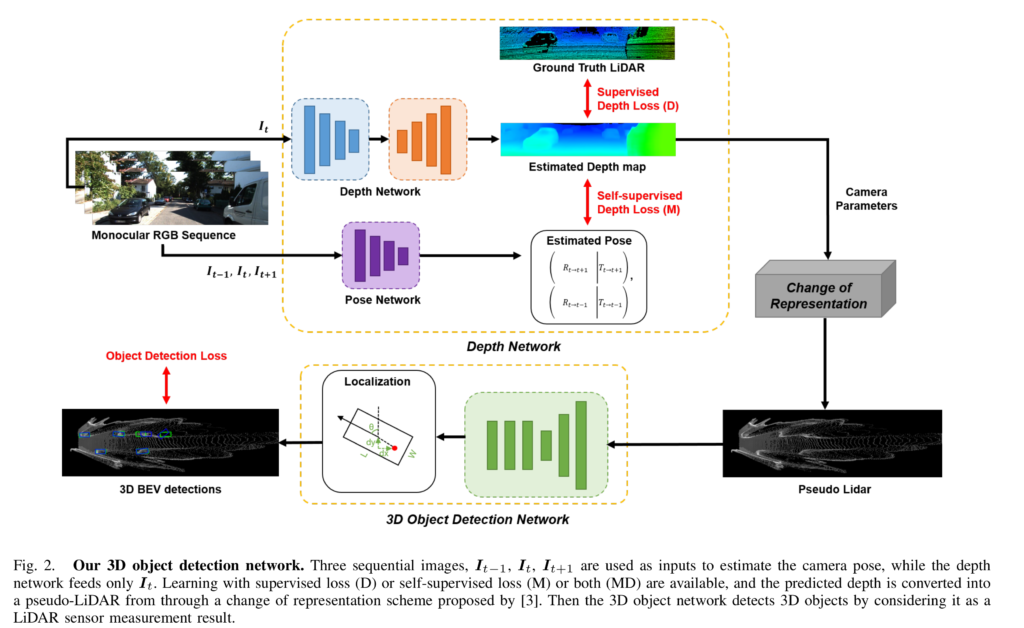
Overview
해당 방법론의 아키텍쳐 구조는 위의 Fig 2와 같습니다. 해당 모델은 단안 시퀀스 영상들을 입력으로 받아 MonoDepth2로부터 깊이 정보를 추론합니다. 추론된 깊이 정보는 카메라 파라미터를 이용하여 실제 세계에 투영된 Pseudo-LiDAR를 생성합니다. 생성된 Psuedo-LiDAR는 LiDAR 기반의 3차원 물체 검출 (BEV) 모델 PIXOR를 통해 3차원 물체 검출을 수행합니다. 학습은 E2E-PL에서 제안된 학습 기법에 따라 Change of Representation을 통해 카메라 기하학으로 변환된 Pseudo-LiDAR에서 깊이 추론 모델로 gradient를 전달함으로써 학습을 진행합니다.
Scale-aware Depth Estimation
단안 기반의 깊이 추정은 두 카메라의 거리 정보를 가진 스테레오와는 달리 실제 세계에 대한 정보 없이 추론을 진행하기 때문에 스케일 모호성 문제를 가집니다. 저자는 이러한 문제를 해결하기 위해서 아래의 수식 1을 이용합니다.
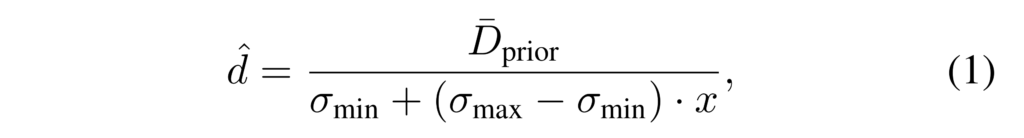
\sigma_{min}, \sigma_{max} 는 각각 디스패리티의 최소, 최대에 해당합니다. \bar{D_{prior}} 는 사전 정의된 scale factor에 해당하며, x는 [0, 1] 범위를 가진 깊이 추정 모델의 예측값에 해당합니다. 수식 1은 추정한 깊이 정보를 정의된 디스패리티의 범위로 제약을 두면서 베이스라인 대비 제한된 디스패리티를 가진 스테레오와 유사하게 만듦으로써 효율적인 학습이 가능하게 만듭니다.
++ x 값을 제외한 모든 값들은 데이터 셋에 따라 바뀌는 하이퍼 파라미터에 해당합니다.
Change of Representation
해당 섹션에서는 카메라 파라미터로 변환된 PL을 어떻게 gradient를 전달할 수 있게 하는지에 대해 설명합니다. 해당 방법은 E2E-PL에서 제안된 학습 기법에 해당합니다. 저자는 E2E-PL에서 제안된 방법 중 soft-quantization을 이용합니다. Soft-qunatization은 PL을 voxel로 변화한 정보에 대해 그래디언트를 전달하는 기법에 해당합니다.
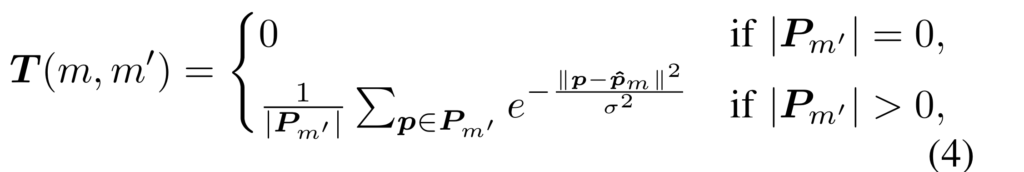
해당 기법은 수식 4와 같은 구성을 가진 기법이며, 해당 논문에서 제안된 기법이 아니기에 자세한 내용을 다루지는 않을 예정입니다. 자세한 내용은 추후 리뷰할 E2E-PL을 참고하시길 바랍니다. 간단하게 설명드리자면, 사전 정의된 voxel의 빈에 PL이 포함 여부에 따라 0과 1로 구분 짓던 기존의 방법론에서 그래디언트 정보를 부여하기 위해서 주변의 빈값과의 분산 정보를 포함한 기법이라고 생각하시면 됩니다. 이를 통해 PL 정보가 해당해야하는 빈에서는 낮은 그래디언트를 가지고 포함되지 말아야하는 빈에서는 높은 그래디언트를 부여하여 멀어지게 하도록 하여 기하학적으로도 의미가 있는 학습 그래디언트를 부여합니다.
Loss fucntion
해당 논문에서는 3차원 물체 검출인 경우, LiDAR 기반의 물체 검출인 PIXOR에 대한 3차원 물체 검출 손실 함수와 깊이 추정 모델을 학습하기 위한 monodepth2에서 제안된 비지도 학습 로스와 GT 깊이 정보를 활용한 지도 학습 로스, 비지도 학습과 지도 학습 로스를 결합한 로스를 사용한 성능을 리포팅합니다.
++ 각 로스는 새롭게 제안된 로스가 아닌 베이스 모델에서 제안된 손실 함수를 그대로 사용하기 떄문에 자세한 내용은 다루지 않도록 하겠습니다.
Experiment
실험 파트에서는 KITTI에서의 3차원 물체 검출 성능과 기존 Monodepth2와의 깊이 추론 성능 비교 실험을 구성 됩니다.
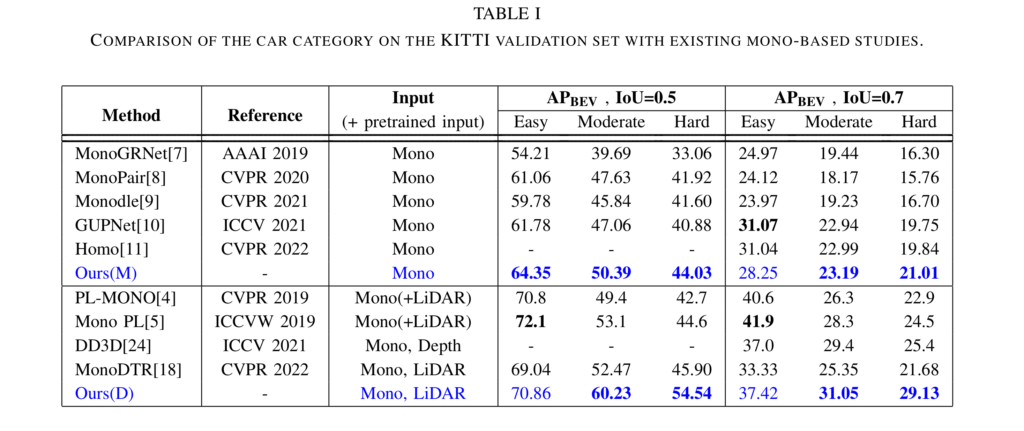
Tab 1은 3차원 물체 검출 성능에 대한 결과입니다. M은 깊이 정보의 GT인 LiDAR를 활용하지 않은 깊이 추론 모델에 대한 비지도 학습에 대한 결과이며, D는 깊이 정보 GT를 활용하여 깊이 추론 모델을 학습한 지도 학습에 대한 결과 입니다. 매우 단순한 모델 구조임에도 불구하고 모든 결과에서 높은 성능을 보여주는 결과를 보이고 있습니다.
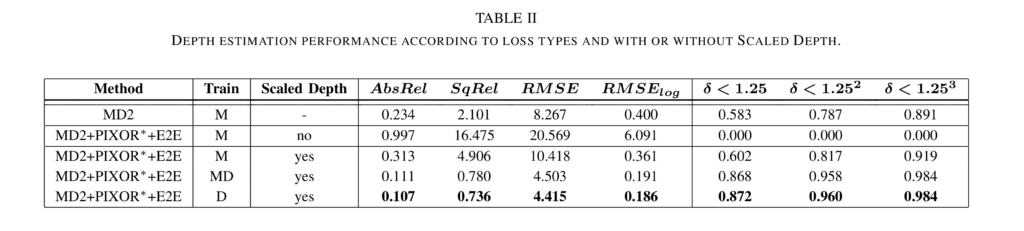
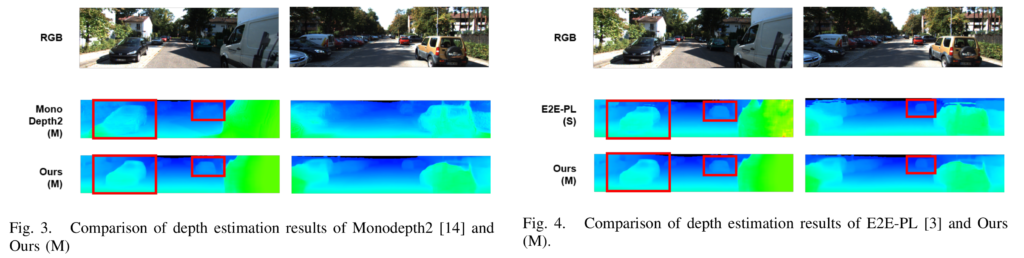
Tab 2/Fig 3/Fig 4는 베이스 모델(MD2=Monodepth2) 대비 지도 학습과 비지도 학습, 지도 학습과 비지도 학습 로스를 결합한 모델에서의 깊이 추론 성능 비교 결과/깊이 추론에 대한 비지도 학습에서의 정성적 결과/깊이 추론에 대한 지도 학습에서의 정성적 결과에 해당합니다. 정성/정량적 결과 모두 베이스라인 대비 나아진 결과를 보여줍니다. 이러한 결과가 나온 이유는 영상의 대부분은 측정에 중요한 물체 대비 백그라운드의 영역이 매우 높은 문제가 있으나, 물체 검출에 대한 손실 함수를 전달함으로써 중요하게 봐야할 물체에 대해 보다 집중하기 떄문에 베이스라인 대비 좋아진 결과를 보여줍니다.
————-
해당 논문의 신규성은 많이 떨어지긴 합니다. 하지만 기존 PL 방법론에서는 카메라 기반이라고 하지만 학습에서는 LiDAR 정보에 의존적인 문제점이 있었습니다. LIDAR의 의존성을 줄이기 위해 비지도 학습 기반의 깊이 추로 모델을 활용한 점에 있어 이후 연구에 있어 통찰을 줄 수 있다는 생각에 리뷰를 하게되었습니다.
Supervised loss 도 보이는 것 같은데 그럼 self-supervised 가 아닌거 같습니다. 제가 잘못 이해한걸까요?