이번 리뷰는 지난주에 리뷰를 진행한 Monoloco의 Stereo 확장 버전에 해당합니다. 해당 논문의 핵심은 3차원 보행자 검출 시, 발생하는 스테레오 매칭의 한계로 발생하는 long tail 문제와 단안 카메라의 기하적 정보 부족으로 발생하는 한계를 단안과 양안 모두 이용하여 극복하는 방법을 제안합니다.
Intro
실제 자율주행 차량/로봇 보행자 회피 관점에서 생각한다면 차량과 달리 보행자는 특히 어려운 사례에서 더욱 강인해야한다는 것은 당연한 이야기입니다. 사람은 강체인 차량과 다양한 형태로 관찰될 수 있으며, 움직이는 방향도 차량에 비해 다채롭습니다. 특히 대부분의 교통사고는 주차된 차량이나, 인도 위의 물체에 가려졌다가 갑자기 튀어나와 발생하는 경우가 대다수 입니다. 이런 상황을 카메라를 이용하여 극복하기 위해 다중 카메라(e.g. 스테레오), 360도 카메라를 이용하여 넓은 FoV 가지도록하여 극복하는 방법을 사용합니다. 혹은 양안 카메라를 이용하여 깊이 정보를 보다 정확하게 추정하여 3차원 보행자 검출 정확도를 높여 가려진 보행자를 잘 찾는 것도 여러 방법 중 하나 입니다. 이러한 사유로 자율 주행 연구 데이터 셋으로 유명한 KITTI 벤치마크에서 카메라 기반은 스테레오 매칭을 이용한 3차원 검출기가 연구의 주를 이루며, SOTA(카메라 기반)에 위치하고 있습니다.
해당 논문은 Introduction의 첫 문단에서 자극적인 주제를 꺼냅니다. 기존 KITTI 벤치마크에서 제안된 보행자에 대한 메트릭과 3차원 검출 방법론들은 보행자에 적합하지 않다고 주장합니다. 각 케이스에 대해 “평균적으로” 볼 겨우, 잘 수행되지만 어려운 케이스에서는 신뢰가 가능한지에 대해 문제를 제시합니다.
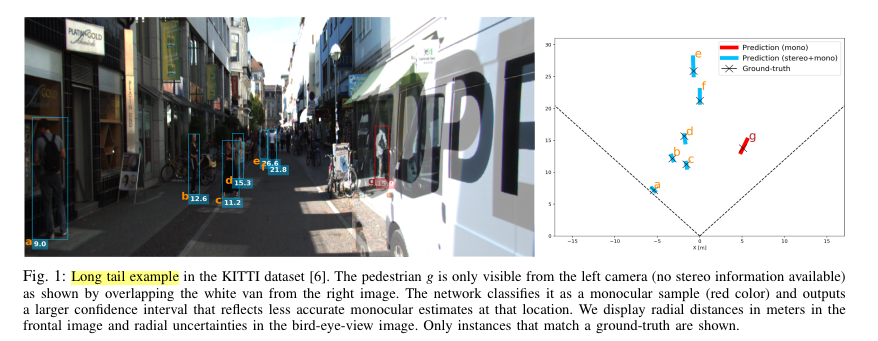
저자는 특히 스테레오에서 발생하는 문제에 집중하였습니다. 스테레오를 이용한 방법론들은 두 카메라의 시점이 겹치는 시점을 이용합니다. 이로 인해서 겹치지 않는 시점들을 손실하게 됩니다. 이는 MLPD에서도 다뤘죠. 저자는 추가로 Fig 1과 같은 케이스에 대해서도 이야기합니다. 겹치는 영역이지만 양안 카메라의 시점 차이로 보행자가 흰색 밴에 가려져 보이지 않는 문제가 발생하는 겁니다. 이럴 경우, 스테레오 매칭을 이용하여 깊이를 추정할 경우, 매칭되는 쌍이 없기 때문에, 깊이는 매우 큰 값을 가져 long tail이 발생하게 됩니다. 즉, task의 한계로 내부적 모호성이 발생하게 됩니다. 저자는 이런 문제를 단안 카메라를 추가적으로 이용하여 해결하는 방법을 제안합니다. (미리 이야기하자면, 단안으로도 예측하고 스테레오에 매칭 쌍이 없으면 단안을 사용한다는 겁니다.)
Method
모델 자체는 매우 간단합니다. 저번주에 발표한 monoloco의 방법에서 몇 가지만 달라집니다.
Input. 먼저 사전 학습된 Pose Estimation 모델인 PifPaf로부터 예측된 left-right 영상에서 보행자들을 입력 값으로 사용합니다. 입력으로 사용하기 전에, 각 보행자의 keypoint는 카메라 정보에 오버피팅 되지 않도록 내부 카메라 파라미터로 정규화되어집니다. 두 키포인트 쌍은 수식 1과 같이
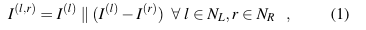
추가되어져 입력 값으로 사용됩니다. Left-right 영상 속 보행자들은 왼쪽 영상을 기준으로 “all-vs-all”로 input pair를 생성합니다. 추후, Instance-based Stereo Matching(ISM)을 통해 매칭 쌍 유무를 판단하며, 매칭이 있는 경우, true pair. 없는 경우, false pair로 구분되어집니다.
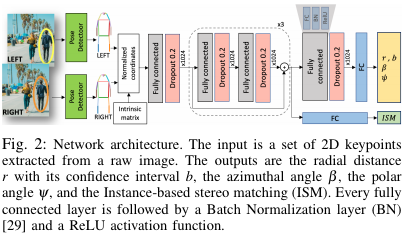
Output. 이전과 연구와 유사하게 위치 정보와 aleatoric uncertatinty인 b를 출력값으로 사용합니다. 달라진 점은 (x, y)로 부터 생기는 깊이 정보의 모호성을 줄이기 위해 구면 좌표계로 변경하여 깊이를 추정합니다. train phase에서는 radial distance r, azimuthal angle β, and polar angle ψ에 해당하는 구면 좌표계를 출력값으로 사용합니다. 또한 pair 쌍 여부(이진)를 예측합니다. Inference phase에서는 r, b만 예측하게 됩니다.
Architecture. Fig 2와 동일한 구조와 동일하게 몇개의 FC로 구성됩니다. 각 FC는 Batch-Normalization, residual connections, dropout, ReLU로 구성되어 있습니다.
Loss. 이전 연구와 동일하게 라플라스 분포의 negative log-likelihood loss와 aleatoric uncertatinty b를 위한 L1 loss를 추가합니다. 여기에 추가적으로 매칭 쌍을 맞추도록 하기 위한 binary cross-entropy loss를 이용합니다.
Knowledge Injection. 해당 부분이 이전 연구에서 발전된 부분에 해당합니다. 이전 연구에서는 사람의 키 높이에 대한 정보와 단안 카메라를 이용한 깊이 추정의 한계를 task error를 증명하면서, 키 높이의 분포도를 이용하는 것이 유용하다는 것을 증명하였습니다. 하지만 가정할 때, 분포도는 성인 남성과 성인 여성에 대한 키 분포에 대한 정보만 이용하였기에 키가 작은 어린 아이와 키가 매우 큰 사람이 등장할 경우, 노이즈로 받아 들여 상이한 값이 나오는 문제가 있었습니다. 저자는 이러한 문제를 해결하기 위해 추가적인 augmentation을 제안합니다. [1.2, 2]에 대한 uniform distribution을 생성하고, 이에 대한 triangle similarity를 이용하여 가상의 키포인트를 생성합니다. 이때, 우리는 깊이 혹은 디스패리티만 고정함으로써 정확한 디스패리티 혹은 깊이를 생성할 수 있습니다. 그렇기에 왼쪽, 오른쪽에 대한 [1.2 2]에 해당하는 보행자의 가상의 키포인트를 생성할 수 있게 됩니다. 이를 통해 한정된 보행자 키 분포도를 다양한 키 분포를 확장 시킴으로써, 데이터 셋에 내부적으로 가진 한계를 극복합니다.
Experiment
실험 부분에 앞서 저자는 KITTI 벤치마크에서 제안한 메트릭의 한계를 지적하며, 새로운 메트릭을 제안합니다. KITTI의 보행자의 바운딩 박스의 평균 크기는 60, 75cm에 해당한다고 합니다. 이는 오차 18cm만 발생하여도 IoU 0.5를 넘기게 됨으로써, 사람에게는 맞지 않게 엄격한 기준이라고 주장합니다. 또한 easy(1240)와 hard(300)로 easy case에 대해 매우 과소평가되어 선정되었다고 합니다. 그렇기에 저자는 박스가 아닌 박스의 중심 위치를 이용한 측정값을 이용하며, 상대적 error가 5%인 경우를 임계값을 이용하자고 제안(RALP, Relative Average Localization Precision)합니다. 이는 20m에서 1m의 오차를 가진 것으로 충분히 안정성이 보장된 경우라고 주장합니다. 추가로 Long tali 문제를 파악하기에 적합한 ALE(Average Localization Error)를 이용할 것을 제안합니다.
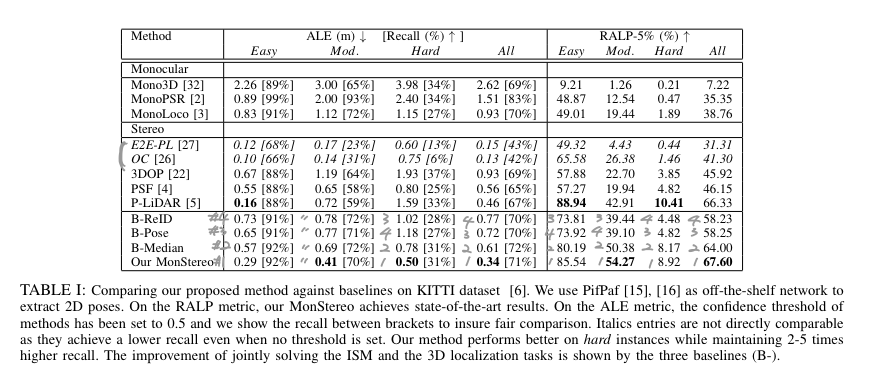
Table 1의 실험 결과를 유심히 보시면 재밌는 부분이 있습니다. 일단 저자는 제안한 방법론이 단안/스테레오 3차원 보행자 검출기에서 SOTA라고 이야기합니다. 보시면 E2E-PL과 OC는 현재도 2021 기준에서도 다섯 손가락 안(카메라 기준)에 들어가는 방법론에 해당합니다. 그에 걸맞게 ALE가 굉장히 낮은 것을 확인 할 수 있습니다. 근데 Recall을 보시면 각각 [68, 23, 13, 43], [66, 31, 6, 42]로 실제로 찾아낸 박스의 비율이 난이도에 따라 매우 낮아지는 것을 볼 수 있습니다. 그렇기에 저자는 보행자 검출기에서는 recall이 낮은 건 적합하지 않다고 이야기 하며, 오차에 대한 성능을 비교하는 것이 의미가 적다고 주장합니다. 그렇기에 두 방법론에 대한 비교에서 제외하였다고 합니다.
++ 저자의 주장이 타당하다고 생각합니다. 괜히 KAIST에서 MR을 이용하는 게 아니니깐요.
모든 성능을 비교하였을 때, SOTA를 달성하였으며, long tail 문제도 해결하였으며, 위치 추정 정확도도 다른 방법에 비해 높은 성능을 보여줍니다.
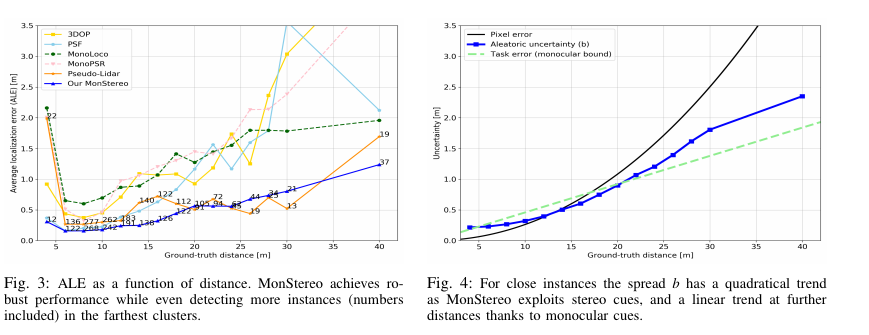
Fig 4를 먼저 보시면, 제안한 모델이 스테레오의 한계인 pixel error와 단안의 한계인 task error의 장단점을(가까운 곳은 스테레오, 먼곳은 단안) 잘 조합하여 성능을 보이는 것을 확인 할 수 있습니다.
++ Pixel error는 스테레오 매칭의 한계를 볼 수 있습니다. 픽셀간 차이(disparity)를 구하는 방법의 한계로 먼 거리에 있을수록 disparity는 작아지게 됩니다. KITTI를 예를 든다면, 40m에서 1 픽셀은 4.5m의 error를 내포하게 됩니다. 이러한 사유로 스테레오 매칭은 먼거리에 위치할 수 록 에러 값이 이차식 형태로 커지게 됩니다.
Fig 3를 통해 다른 방법론보다 다양한 깊이에서 좋은 성능을 가진 것을 볼 수 있습니다.
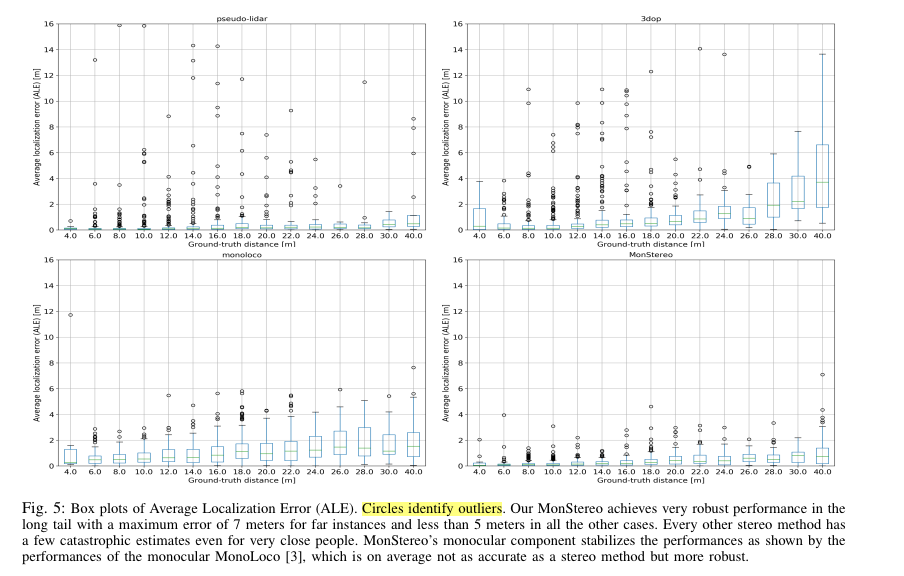
Fig 5는 스테레오의 문제점인 long tail을 해결 했는가에 대해 보여주는 결과 입니다.
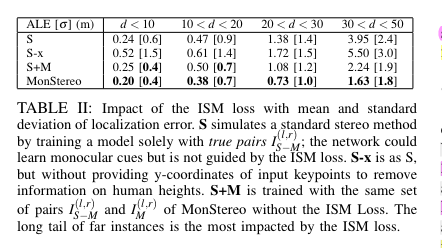
ISM에 대한 Ablation Study. 스테레오의 long tail 문제를 단안을 이용하는 것이 도움이 된다는 것을 증명한다.

Knowledge Injection에 대한 ablation study. 키 분포가 다채로워지면서 Recall에서 큰 성능 향상을 보여준다.
=================================================
해당 논문의 가장 큰 장점은 3차원 보행자 검출에 영상이 입력이 아니기에 영상 도메인에 상관없이 포즈 값 추론이 가능하다면 보행자의 포즈값을 보행자의 특징값으로 이용하다는 점이다. 즉, 컬러-열화상과 같이 영상 도메인이 달라도 가능하다는 이야기이다. 문제는 열화상에서 키포인트 검출이 잘되는냐가 포인트인데, 카이스트와 포테닛 데이터 셋에 실험해본 결과 어느정도 잘나오고, 카이스트 데이터 셋으로 확장하여 포즈 모델 학습하고 포테닛에 적용할 예정임다. 기대가 됩니다. ++ bbox 도 키포인트 값이 있고, 키포인트 값에 나아가는 방향에 대해서도 예측을 하니깐 충분히 그릴 수 있을 거 같다는 기대감이 있음.