안녕하세요, 요즘 SAR만 파다 보니 루즈해지기도 해서 마침 ICML conference 참가 신청도 했겠다 어떤 논문들이 있는지 찾아보았는데, adaptive frame sampling이라는 말에 끌려 이 논문을 읽어보게 되었습니다. 이전에 video understanding 논문을 읽었을 때, 자주 사용하는 sampling 전략은 1 FPS sampling, uniform sampling이 대표적이었는데 전자는 비디오가 길어졌을 때의 메모리 한계 문제, 후자는 중요 정보 손실 가능성이 문제가 되는 것으로 알고 있었습니다. adaptive frame sampling은 필요한 정보만 샘플링함으로써 위의 두 가지 문제를 해결할 수 있기 때문에 저자들은 어떻게 이것을 구현했는지 알아보겠습니다.
Introduction
VLM(Vision Language Model)의 video understanding 능력에 대한 중요성이 대두되는 상황에서, Long Video Understanding은 여전히 동시에 처리할 수 있는 프레임 개수가 제한적이라는 점에서 주요 난제라고 합니다. 때문에 기존 연구들은 보통 수많은 비디오 프레임들 중 일부를 sampling하는 전략을 사용합니다.
- uniform sampling : 비디오의 내용과 관계없이 고정된 간격으로 프레임을 선택하는 방법으로, 샘플링된 프레임들 사이에 중요한 사건이 발생했을 때에 대한 리스크를 가집니다.
- Adaptive Keyframe Sampling : 시각적 다양성 또는 쿼리와의 관련성을 기반으로 keyframe을 선정하는 방법입니다. 하지만 single-pass로 진행하기 때문에 초기에 선택한 프레임이 “잘못 뽑은” 경우라도 이를 수정하거나 다시 고를 수 없다는 것이 문제점입니다.
- Agent-Based : iterative하게 정보를 모을 수 있지만, 텍스트 기반 LLM이 visual tools를 지휘하는 구조이기 때문에 프레임의 텍스트 캡션만 가지고 LLM이 모든 결정을 내리게 됩니다. 따라서 텍스트만으로는 불가능한 fine-grained한 시각적 단서를 포착하기 어렵습니다. (정보 병목 Information Bottleneck)
저자들은 위와 같은 정보 병목을 해결하고자 VideoBrain이라는 end-to-end framework를 제안합니다. 상당히 이 end-to-end를 강조하고 있는데, Agent-based가 vision tool로 frame sampling 및 description 후 LLM에 전달해서 결정을 수행하는 흐름과 다르게, VideoBrain은 VLM이 자체적으로 학습된 sampling policy를 통해 adaptive한 frame sampling을 수행합니다. VideoBrain은 현재의 sampled frames를 분석하고 이 정보가 QA answering에 충분한 지를 추론합니다. 이때 모델이 현재 정보가 answering에 불충분하다고 판단되면 두 가지 sampling agents 중 하나를 호출해서 추가적인 sampling을 수행합니다. 첫 번째 agent는 CLIP-based agent로 비디오 전반에 걸쳐 시간적 위치에 관계없이 특정 visual content를 담은 의미적 검색(semantic retrieval)을 수행합니다. 다른 하나는 Uniform agent 로 특정 시간대에서 dense하게 uniform sampling해서 시간적인 속성을 최대한 보존하여 sequential한 문제에 대응할 수 있도록 합니다.
이때 모델은 위 두 agent를 언제 어떻게 호출해야 하는지를 학습하게 되는데, 학습은 supervised fine-tuning에서 behavior-aware reward 기반 강화 학습으로 이어지는 Two Stage 학습 과정으로 진행됩니다. 이런 agentic VLMs 학습의 핵심 과제는 “reward hacking”을 어떻게 방지할 것이냐 인데, reward hacking이란 보상을 최대화하기 위해 agent를 무분별하게 호출하는 것을 뜻합니다. 초기에 랜덤으로 샘플링한 프레임이 정답을 추론하는 데 충분한 정보를 담고 있음에도 보상을 최대화하기 위해 agent를 호출하려고 할 수 있기 때문에 저자들은 behavior-aware reward function을 도입해서 이를 해결했습니다. 디테일을 간단하게 말하면, 초기 프레임으로 answering에 충분한 질문들(Direct question)에 대한 agent 호출은 막고, 진짜로 추가 정보가 필요한 질문들(Active Question)에 대한 agent 호출을 장려하는 방식입니다. 이때 “정말로 추가적인 정보가 필요한 질문인가, agent 호출이 이득이 되는가”를 분류하기 위해 classification pipeline을 사용해서 질문들을 Direct, Adaptive, Active로 분류합니다.
Contributions
- VideoBrain 프레임워크 및 듀얼 에이전트 제안: 반복적인 추론을 통해 adaptive frame sampling을 수행할 수 있는 End-to-end 학습 프레임워크인 VideoBrain을 제안했습니다. 여기에는 ‘CLIP based semantic retrieval agent’와 ‘uniform temporal sampling agent’라는 두 가지 상호보완적인 sampling agents가 포함됩니다.
- 보상 해킹 방지를 위한 새로운 보상 함수 설계: reward hacking 문제를 근본적으로 방지하기 위해 novel한 behavior-aware reward function와 데이터 분류 파이프라인을 도입했습니다. 이를 통해 모델은 추가적인 시각 정보가 진짜 필요한 복잡한 질문에만 에이전트를 호출하고, 단순한 질문은 불필요한 샘플링 없이 바로 대답하도록 스스로 행동을 조절하게 됩니다.
- 4개의 LVU 벤치마크 실험 결과, 베이스라인 모델보다 프레임을 30~40%나 적게 사용하면서도 오히려 3.5%~9.0% 향상된 정확도를 달성했습니다. Short form에서도 우수한 일반화 성능을 보였으며, 다양한 ablation을 통해 모델의 각 component가 가진 효과를 검증했습니다.
Method
저자들이 제안한 VideoBrain은 end-to-end trainable framework로 VLM이 학습된 sampling policy를 통해 동적으로 시각 정보를 취득하도록 합니다. main components는 두 가지로,
- During Inference : adaptive frame sampling 위한 멀티 에이전트 구조
- During Training : sampling agent를 언제 어떻게 불러올지 학습시키기 위해 behavior-aware rewards 기반 학습 파이프라인 적용
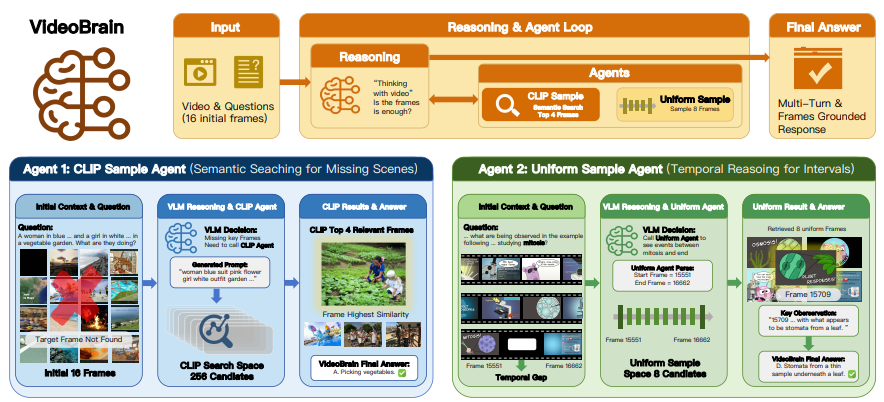
Multi-Agent Architecture
처음에는 uniform sampling된 초기 N_0 개의 프레임을 가지고 iterative한 reasoning loop에 돌입합니다. 목적은 비디오(V)와 질문(Q)이 주어졌을 때, answer accuracy를 최대화하는 최적의 frame subset를 선택하는 것입니다.
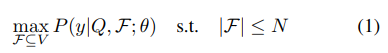
reasoning loop의 한 사이클은 다음과 같습니다. 만약 reasoning했을 때, 정답을 도출하기에 정보가 충분하고 판단되면 그대로 최종 정답을 출력합니다. 만약 정보가 충분하지 않다면 이때 sampling agent를 호출하고 추가적인 frame을 취득합니다. 이러한 reasoning loop는 최대 k번 까지 진행한다고 하며, default setting은 5번입니다.
output format도 간단하게 정리하고 넘어가겠습니다.
- Intermediate reasoning(현재 정보가 answering에 불충분)
<thinking>...</thinking>+<tool call>{...}</tool call>: 어떤 sampling agent를 불러올 지와 그것의 파라미터를 명시 - Sufficient Info (현재 정보 충분)
<thinking>...</thinking>+<answer>{...}<answer>
CLIP Sample Agent
이제 두 가지 sampling agent에 대한 소개를 드리겠습니다. CLIP Sample Agent는 비디오 전체에 걸쳐 시각적으로 관련 있는 프레임들을 찾아내기 위해 semantic retrieval을 수행합니다. 입력으로 start_frame,end_frame,prompt가 입력됩니다. 먼저 start_frame & end_frame 즉 비디오 내에서 검색을 수행할 시간 범위가 지정됩니다. 해당 구간 안에서 uniform하게 m개(128/256)를 샘플링한 뒤, prompt는 비디오 안에서 찾고자 하는 대상이나 장면에 대한 텍스트 설명으로 이 text prompt embedding과 샘플링했던 m개의 프레임 사이의 CLIP 유사도 점수가 높은 top n(default: 4) 개의 프레임을 반환합니다. 자세한 알고리즘은 아래와 같습니다.

Uniform Sample Agent
명시된 비디오 클립(특정 구간)에서 시간적으로 dense한 sampling을 수행합니다. start_frame과 end_frame 이 주어지면 해당 구간에서 uniform sampling된 n개 프레임을 반환합니다 (default: 8). CLIP sample agent와 달리 temporal structure를 보존하여 sequence 문제에 유리하며, 여기서의 uniform sampling은 정해진 시간 구간 안에서 일정한 간격으로 프레임들을 고르게 뽑기 때문에 특정 내용에 치우치지 않고 그 구간 안에서 일어난 모든 상황의 흐름을 빠짐없이 파악할 수 있게 해줍니다.
어떤 질문은 비디오 전체에서 특정 장면을 딱 짚어내야 하고(CLIP 필요), 어떤 질문은 특정 구간의 흐름을 자세히 관찰해야 합니다(Uniform 필요). VideoBrain은 이처럼 “시각적 내용 찾기”와 “시간적 흐름 이해하기”라는 두 가지 서로 다른 요구사항을 두 에이전트를 적절히 골라 써서 상호보완적으로 커버되도록 설계되었습니다.
Data Selection and Classification
VideoBrain은 모델이 무지성으로 에이전트를 호출하는 ‘reward hacking’을 방지하기 위해, 본격적인 학습에 앞서 전체 데이터를 난이도별로 세밀하게 분류하는 작업을 거칩니다.
데이터 분류의 핵심은 scale과 환경이 다른 두 가지 모델을 활용하는 Two-Model Joint Selection에 있습니다. 먼저 16개의 초기 프레임만 보고 에이전트 없이 직관적으로 답을 내는 Base Model과, 자유롭게 에이전트를 호출해 영상을 탐색할 수 있는 강력한 Teacher Model이 동일한 문제를 풉니다. 실험 세팅 상 Base Model은 Qwen3-VL-8B, Teacher Model은 Qwen3-VL-235B 라고 하네요. 저자들은 이 두 모델의 정답 여부를 대조함으로써 해당 문제가 정말로 에이전트를 통한 추가 탐색이 필요한 문제인지 가려냅니다.
평가 결과에 따라 전체 데이터는 세 가지 카테고리로 나뉩니다. 첫 번째는 Direct입니다. 두 모델이 모두 정답을 맞춘 경우로, 처음 주어진 16개의 프레임 안에 이미 정답의 단서가 충분하여 굳이 에이전트를 부를 필요가 없는 쉬운 문제를 뜻합니다.
두 번째는 Adaptive입니다. Base Model은 틀렸지만, Teacher Model이 에이전트를 쓰지 않고 정답을 맞춘 케이스입니다. 즉, 초기 화면에 단서가 있었으나 소형 모델의 시각 인지 한계로 놓친 문제입니다. 전체 데이터에서 차지하는 비중이 작으며, 학습 시 특정 탐색 전략을 강제하지 않고 유연하게 둡니다.
마지막은 Active입니다. Base Model이 틀리고 Teacher Model이 에이전트를 써서 정답을 맞추거나 아예 둘 다 틀린 경우입니다. 이는 초기 프레임만으로는 절대 풀 수 없으며, 모델이 반드시 능동적으로 에이전트를 호출해 추가적인 시각 정보를 찾아와야만 해결할 수 있는 복잡한 문제에 해당합니다.
한편, 정보가 적은 베이스 모델은 우연히 정답을 맞췄는데 비디오를 더 샅샅이 뒤져본 교사 모델이 오히려 오답을 내는 모순적인 상황도 발생할 수 있습니다. 저자들은 이를 데이터 자체의 오류나 노이즈로 간주하고 훈련 과정에서 아예 제외하는Anomaly Filtering 과정을 거쳐 학습의 질을 높였습니다.
Training
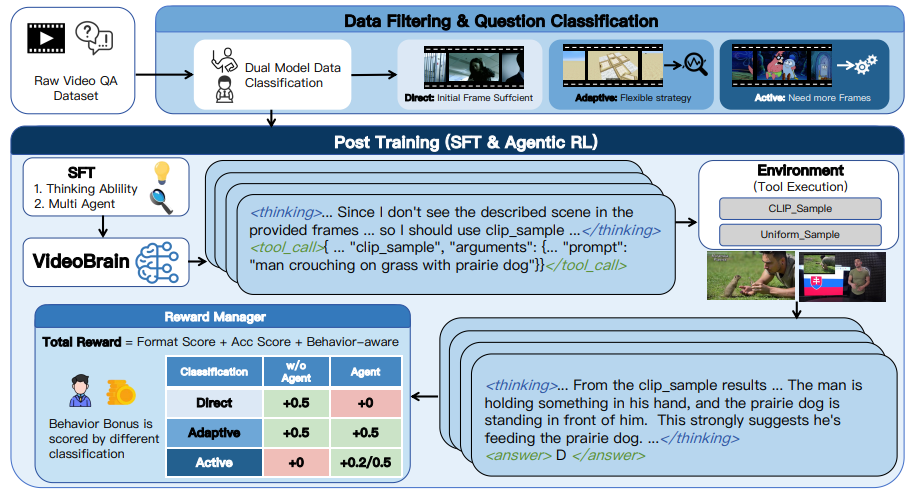
VideoBrain의 훈련 과정은 Base Model이 에이전트로서의 기본 행동 양식을 익히는 SFT(supervised Fine-tuning) 단계와, 최적의 툴 사용 전략을 스스로 깨우치는 강화학습(RL) 단계로 나뉩니다.
Base Model은 이미 기본적인 시각 이해 능력을 갖추고 있으므로, 방대한 데이터를 쏟아붓기보다는 소량의 고품질 데이터를 활용해 올바른 행동 방식을 주입하는 데 집중합니다. 학습 데이터로는 강력한 성능을 가진 Teacher Model(Qwen3-VL-235B)이 문제를 해결하며 남긴 사고 과정(Trajectories)과 툴 호출 기록을 정답지로 활용합니다. 이때 Base Model이 초기 프레임만으로 쉽게 맞출 수 있는 쉬운 ‘Direct’ 문제는 배제하고, 풀지 못했던 ‘Adaptive’ 및 ‘Active’ 데이터만 선별하여 집중적으로 학습시킵니다. 또한 에이전트를 호출한 케이스와 호출하지 않은 케이스를 모두 보여주어 균형 잡힌 학습을 유도합니다.
이 SFT 과정을 통해 모델은 두 가지 핵심 능력을 기릅니다. 첫째는 추론 능력(Reasoning Ability)으로, 현재 눈앞의 시각 정보만으로 질문에 답하기 충분한지, 단서가 부족해 툴을 써야 하는지 스스로 분석하고 판단하게 됩니다. 둘째는 Tool Usage Ability입니다. 여기에는 원하는 장면을 정확히 찾기 위한 CLIP 에이전트의 효과적인 검색어(prompt) 작성법, 흐름을 촘촘히 파악하기 위한 Uniform 에이전트의 적절한 시간 구간(start_frame, end_frame) 지정법, 그리고 논문이 규정한 출력 형식(<thinking>, <tool_call>, <answer>)을 엄격하게 지키는 방법이 포함됩니다.
SFT로 기본기를 다진 후에는 GRPO(Group Relative Policy Optimization) 알고리즘을 도입하여 강화학습(RL)을 진행합니다. GRPO는 별도의 Critic(가치 평가) 모델을 두지 않아 메모리를 절약하면서도 그룹 내 상대적 비교를 통해 효율적으로 학습할 수 있는 방식입니다. 하나의 질문 q에 대해 모델이 여러 개의 서로 다른 추론 경로 G개를 생성하면, 이 그룹 내에서 각 경로가 받은 보상의 평균과 표준편차를 이용해 상대적 우위인 이점(Advantage, A_i)을 계산합니다. 목적 함수는 다음과 같이 정의됩니다.
\mathcal{F}_{GRPO}(\theta)=\mathbb{E}\left[\frac{1}{G}\sum_{i=1}^{G}\min(\rho_{i}A_{i}, \text{clip}(\rho_{i}, 1-\epsilon, 1+\epsilon)A_{i}) - \beta \mathbb{D}_{KL}(\pi_{\theta}||\pi_{ref})\right]여기서 \rho_i는 현재 정책(\pi_\theta)과 이전 정책(\pi_{old})의 확률 비율을 의미하며, KL 발산(\mathbb{D}_{KL}) 규제 항을 추가하여 모델이 SFT 단계에서 확립한 기본 틀(\pi_{ref})에서 너무 크게 벗어나 망가지는 것을 방지합니다.
이 강화학습 단계에서는 SFT와 달리 Direct, Adaptive, Active 모든 카테고리의 데이터를 경험하게 됩니다. 모델은 이 과정을 거치며 어떤 상황에서 에이전트를 부르는 것이 보상을 극대화하는 이득이고, 언제 부르는 것이 비효율적인 손해인지 스스로 깨달으며 최적의 탐색 정책을 완성해 나갑니다.
Reward Design
강화학습 과정에서 모델이 에이전트를 무분별하게 호출하며 보상만 챙기려는 Reward Hacking을 방지하기 위해, VideoBrain은 세 가지 평가 요소가 결합된 정교한 보상 함수를 도입했습니다. 총 보상은 다음과 같은 수식으로 계산됩니다.
R = \mathbb{I}_{format} \cdot (R_{format} + R_{accuracy} + R_{behavior})
가장 먼저 \mathbb{I}{format}과 R{format}은 모델의 출력 형식을 엄격하게 통제하는 Hard Constraint 역할을 합니다. 모델이 <thinking>, <tool_call>, <answer> 태그 쌍을 올바르게 사용하고, 툴 호출 시 유효한 JSON 형식을 지켰으며, 똑같은 조건으로 중복 탐색을 하지 않았다면 \mathbb{I}_{format}이 1이 되어 최소한의 기본 점수인 0.05점(R_{format})을 확보하게 됩니다. 반면 이 규칙 중 하나라도 어길 경우, 뒤에 이어질 정답 여부와 무관하게 전체 보상은 0점 처리됩니다.
Format Reward를 통과한 뒤 부여되는 Accuracy Reward($R_{accuracy}$)는 LLM Judge를 통해 채점됩니다. 객관식은 Qwen-Flash를 이용해 정답 유무를 0 또는 1로 엄격하게 평가하고, 주관식은 DeepSeek-V3.2를 활용하여 정답과의 의미적 유사도를 0부터 1 사이의 연속적인 점수로 산출합니다.
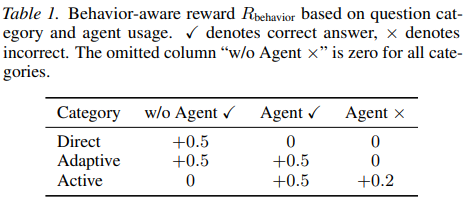
본 보상 체계의 핵심은 앞서 분류한 질문의 난이도에 따라 피드백이 다르게 들어가는 behavior-aware reward($R_{behavior}$)에 있습니다.
초기 16 프레임만으로 충분히 풀 수 있는 쉬운 ‘Direct’ 문제의 경우, 모델이 굳이 에이전트를 호출했다면 정답을 맞히더라도 행동 보상을 0점 처리합니다. 이를 통해 모델은 불필요한 연산을 줄이고 최소한의 프레임만으로 빠르게 답을 내는 효율성을 배우게 됩니다.
반대로 반드시 추가 탐색이 필요한 Active 문제는 난이도가 매우 높아 정답을 맞히기 어렵고,이로 인해 잦은 오답으로 보상이 sparse해지면 모델이 위축되어 에이전트 호출 자체를 기피할 수 있습니다. 저자들은 이를 막기 위해 Active 문제에서는 비록 최종 오답을 내더라도 에이전트를 적절히 호출해 탐색을 시도했다면 +0.2점의 partial Reward을 지급하도록 설계했습니다. 결과적으로 모델은 쉬운 문제에서는 자원을 아끼고, 어려운 문제에서는 실패를 두려워하지 않고 적극적으로 단서를 쫓는 최적의 policy를 완성하게 됩니다.
Experiments
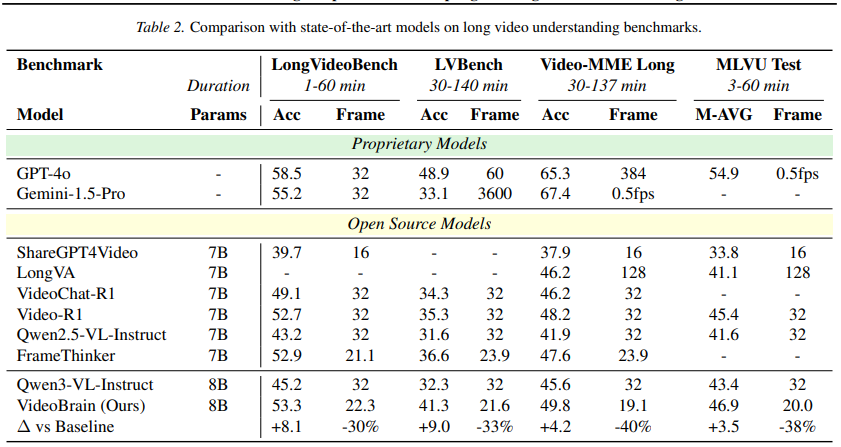
VideoBrain은 베이스라인 모델인 Qwen3 VL 8B Instruct 대비 모든 벤치마크에서 “더 적은 프레임만 사용하고도 더 높은 성능”을 기록했습니다. 저자들은 무조건 프레임을 많이 채워 넣는 것이 아닌 adaptive sampling이 계산 비용을 극적으로 아끼면서도 이해도를 높일 수 있음을 보였다고 합니다.
또한 FrameThinker 등의 기존 강화학습 기반 모델들은 uniform sampling만 반복하여 fine-grained한 탐색을 시도했지만 VideoBrain은 dual-agent와 behavior aware reward를 통해 reward hacking을 차단하여 이들보다 높은 성능을 기록할 수 있었다고 분석합니다.
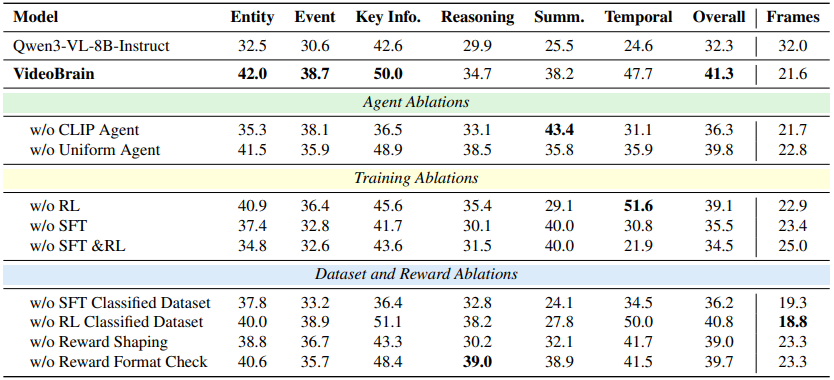
LVBench로 진행한 Ablation 실험 결과 보면서 마무리하겠습니다.
1. Agent Ablation
가장 눈에 띄는 결과는 Dual-Agent 시스템에서 의미 기반 검색을 담당하는 CLIP agent를 제거했을 때 나타납니다. 전체 정확도가 41.3%에서 36.3%로 가장 크게 하락했으며, 특정 대상을 찾아야 하는 Entity나 Temporal 문제 유형에서 특히 취약한 모습을 보였습니다. 이는 타겟 정보가 영상의 어디에 등장할지 예측할 수 없는 긴 비디오 환경에서, 단순한 시간순 탐색만으로는 한계가 명확하며 비디오 전체를 가로지르는 시각적 검색이 필수적임을 증명합니다. 반대로 시간적 흐름을 촘촘히 훑어주는 Uniform agent를 제거했을 때도 성능 하락(39.8%)이 발생하여, 두 에이전트가 단독으로 쓰일 때보다 상호보완적으로 작동할 때 시너지가 극대화됨을 증명했습니다.
2. Training Ablation
SFT를 건너뛰고 강화학습만 단독으로 진행할 경우, 모델의 보상 수렴 속도가 느려지고 분산이 커지며 최종 성능이 35.5%까지 떨어졌습니다. 모델에게 에이전트를 언제 호출하고 프롬프트를 어떻게 작성해야 하는지에 대한 최소한의 가이드라인(Cold-start)을 먼저 쥐여주지 않으면 효율적인 탐색 policy를 학습하기 어렵기 때문입니다. 반대로 RL 과정을 생략해도 최종 성능(39.1%)의 고점에 도달하지 못해, SFT로 기본기를 다진 후 시행착오(RL)를 거쳐 최적의 policy를 스스로 깨우치게 만드는 two stage training이 매우 유효했음을 보여줍니다.
3. Reward Ablation
reward hacking을 막기 위해 도입된, 문제의 난이도에 따라 보상을 다르게 설정했던 reward shaping을 제거했을 때 정확도가 39%로 하락했습니다. 이 경우 모델은 쉬운 문제에서도 보상을 더 받기 위해 불필요하게 agent를 호출하거나 어려운 문제에서는 보상 획득을 포기하고 탐색을 멈추는 등의 패턴을 보였다고 합니다. 즉 난이도별 보상 설계가 프레임워크의 안정성을 유지하는 핵심임을 반증했습니다.
안녕하세요 재윤님 좋은 글 감사합니다.
전체적으로 읽었을때 성능이 크게 향상된 것처럼 보이네요. 다만 궁금한게 reward hacking을 방지하기 위해 data sampling을 저자의 방식으로 설정한게 이해는 되는데, 저게 정말로 reward hacking을 전부 막을 수 있을지 궁금합니다. 그러니까 agent가 필요한 문제만 샘플링하여 학습시키는 행위가 agent가 필요없는 동영상이 들어왔을때 agent를 실제로 호출하지 않는게 보장되는건지 궁금합니다.
감사합니다.
안녕하세요 인택님, 좋은 질문 감사합니다.
agent가 필요한 문제만 샘플링해서 학습시키는 방식은 SFT 단계에서만 모델이 agent를 부르는 능력(tool use ability)을 학습하는 기본기 다지기 같은 목적으로 진행되고, 강화학습 단계에서 reward 설계 상 answering에 필요한 단서가 충분할 때 agent를 호출하면 보상을 0점으로 처리했기 때문에 결과적으로 모델은 이미 정보가 충분한 상황에서 호출을 억제하는 방식으로 reward hacking을 방지하게 됩니다.
안녕하세요 재윤님, 좋은 리뷰 감사합니다.
저도 ICML 참관하게 되어, ICML 논문을 읽어보려고 했는데, 재윤님이 마침 리뷰를 작성해주셔서 읽게되었습니다!
간단한 질문 몇개만 댓글로 남기겠습니다.!
먼저 introduction에서 uniform sampling의 단점으로, sampling된 frame 사이에 중요한 사건이 담긴 frame이 있는 경우 큰 risk를 가진다고 하였는데, VideoBrain에서 사용하는 agent 모두 uniform sampling 방식을 기본으로 하는 것 같습니다. 그렇다면 동일한 문제가 아직 남아있는 것이 아닌지 의문이 듭니다. RL을 통해, 시작 frame과 종료 frame의 위치를 특정해주었기 때문에, 기존의 uniform 방식보다 중요한 frame을 놓치지 않을 수 있었던 것일까요?
두번째로, agent를 사용하는 것이 inference time에 영향을 주지는 않는지, frame수를 baseline에 비해서 적게 사용했으나, agent를 사용하므로써 전체적 시간 효율은 비슷하지 않을까라는 단순한 생각이 들어서 질문드립니다.!
감사합니다.
안녕하세요 희승님, 좋은 질문 감사합니다.
1) 여전히 uniform sampling으로 초기 샘플링을 한다는 점에서 충분히 그러한 의문을 가지실 수 있을 것 같습니다. VideoBrain에서는 기존 uniform sampling의 정보 손실 가능성을 iterative한 sampling을 통한 정보 보충으로 해결했고, uniform agent의 경우 강화학습을 통해 VLM이 알아서 특정 시간대를 특정하고 uniform sampling을 하는데 보통 순서 정보 인지가 중요한 문제에 쓰이기 때문에, uniform sampling된 프레임들이 충분한 시각 정보를 제공하게 됩니다.
2) 말씀대로 iterative한 agent 호출로 인한 latency가 발생하는 것은 맞습니다. 하지만 제 생각에 VideoBrain의 목표는 시간 효율성보다는 문제 해결에 도움이 되는 최소한의 프레임들만 샘플링함으로써 연산 비용 측면에서의 이점을 가져가는 것이고, 해당 모델은 심지어 이미 문제를 푸는 데 필요한 정보가 충분하면 이른 시점에 호출 iteration을 중단함으로써 빠른 추론 속도까지 챙길 수 있을 것 같습니다.
안녕하세요 재윤님, 좋은 리뷰 잘 읽었습니다. 궁금한 부분이 있어서 질문 남겨 놓습니다.
Direct, Adaptive, Active 분류 자체에서 오류가 발생하면 모델 성능에 영향이 클 것 같은데, Base Model과 Teacher Model을 변경했을 때의 Ablation이나 해당 내용에 대한 언급이 있었는지 궁금합니다.
감사합니다.
안녕하세요 성민님, 좋은 질문 감사합니다.
Base Model과 Teacher Model을 변경했을 때의 Ablation이나, 분류 오류에 대한 직접적인 언급은 포함되어 있지 않았습니다. 다만 논문에서는 분류된 데이터셋 자체를 강조하며, 분류 과정 없이 전체 데이터를 SFT나 RL에 사용했을 때 성능이 유의미하게 하락한다는 실험 결과 정도만 제시했습니다. 말씀대로 분류 성능이 얼마 정도 되는지는 분석 결과를 추가로 제시했어야할 부분으로 보입니다.