오늘은 preference-aware 논문을 가져와봤습니다. preference-aware는 로봇이 사람의 선호하는 바를 인지하고 이를 action에 반영하는 논문이라고 보시면 되겠습니다. 사람과 로봇의 introduction이 흥미가 있어 읽어봤습니다. 그럼 리뷰 시작하겠습니다.
1. Introduction
개인화된 집안일을 하는 로봇이 왜 어려울까요? 냉장고에 장 본 물건을 넣는 일은 사람에게는 쉬워 보이지만 로봇에게는 두 가지를 동시에 풀어야 하는 문제입니다. 하나는 사용자가 어디에 무엇을 두고 싶어 하는지, 즉 사용자의 선호를 인지해야 하며, 다른 하나는 냉장고 안에 실제로 그 물건을 둘 수 있는지, 즉 환경 제약을 인지해야 합니다. 예를 들어 사용자가 과일을 위 칸에 두는 것을 좋아해도, 위 칸이 이미 꽉 차 있으면 로봇은 다른 실행 가능한 위치를 찾아야 하는거죠.
본 논문에서 말하는 organization task는 단순히 물건을 넣는다가 아닌데요. 로봇은 물건을 놓을 위치를 고를 때 사용자가 좋아하는 위치를 고려해야 하고, 동시에 냉장고 벽이나 이미 들어 있는 물건과 충돌하지 않아야 합니다. 또 다른 물건을 넘어뜨리는 행동도 피해야 하죠. 그래서 저자는 해당 문제는 preference learning과 task planning이 함께 필요함을 언급합니다.
LLM은 사용자가 원하는 바를 자연어로 설명하게 좋은 인터페이스이지만, 모든 세부 규칙을 말로 설명하는 것은 사용자에게 귀찮고 어렵게 다가갈 수 있습니다. 그리고 사용자가 자기의 선호를 정확히 문장으로 정리하지 못할 수도 있습니다. 그래서 저자는 사용자가 직접 몇 번 물건을 놓는지 보여주는 시연에 주목했는데요.
시연은 자연어로 하나하나 세부사항을 적는 것보다 사용자에게 더 쉽게 다가가는데, 단순히 자는 “이렇게 정리하면 돼”라고 보여주면 됩니다. 그러면 VLM이 visual demonstration에서 전후 state와 action을 뽑아낼 수 있습니다.
하지만 여기서 첫 번째 어려움이 생기는데요. 하나의 demonstration은 여러 preference로 해석될 수 있다는 것입니다. 사용자가 사과를 위 칸에 놓았다고 해보겠습니다. 로봇은 이것을 “과일은 위 칸에 둔다”로 해석할 수도 있고, “빨간 물건은 위 칸에 둔다”로 해석할 수도 있고, “둥근 물건은 위 칸에 둔다”로 해석할 수도 있습니다. 굉장히 모호하죠. 지금 본 demonstration에서는 이 해석들이 모두 맞아 보일 수 있지만, 새로운 물건이 들어오면 문제가 되죠. 예를 들어 참치캔을 들 수 있을 것 같습니다. 참치캔은 둥글지만 과일은 아닙니죠. 이때 어떤 규칙을 따라야 하는지 모르면 로봇의 plan이 틀릴 수 있습니다.
두 번째 어려움은 preference가 맞아도 실행 가능성은 보장되지 않는다는 점입니다. 사용자가 “파인애플과 피망을 아래 칸 왼쪽에 둔다”는 preference를 갖고 있다고 해봅시다. 해당 규칙은 사용자 마음에는 맞지만, 아래 칸 왼쪽 공간이 좁으면 두 물건이 동시에 들어가지 않죠. LLM이 preference만 보고 “둘 다 아래 칸 왼쪽에 놓자”고 plan을 만들면 실제 로봇은 collision을 일으키거나 물건을 놓을 수 없습니다. 저자는 이런 단순한 변환을 open-loop plan이라고 보는데요. 즉 한 번 plan을 만들고 environment feedback을 받지 않는 방식을 말합니다.
여기서 저자는 생각한 것이, 그러면 open-loop를 쓰지말고, closed-loop, 즉, 사용자와 환경 양쪽에 대해 닫힌 루프를 쓰자고 생각한 것이죠. 사용자쪽 loop는 로봇이 어떤 preference가 진짜인지 모를때 질문 합니다. 환경쪽 loop는 world model이 해당 위치에 물건을 놓으면 collision이 나는가?를 검사합니다. 그러면 그 feedback을 바탕으로 plan을 다시 고치게 됩니다.
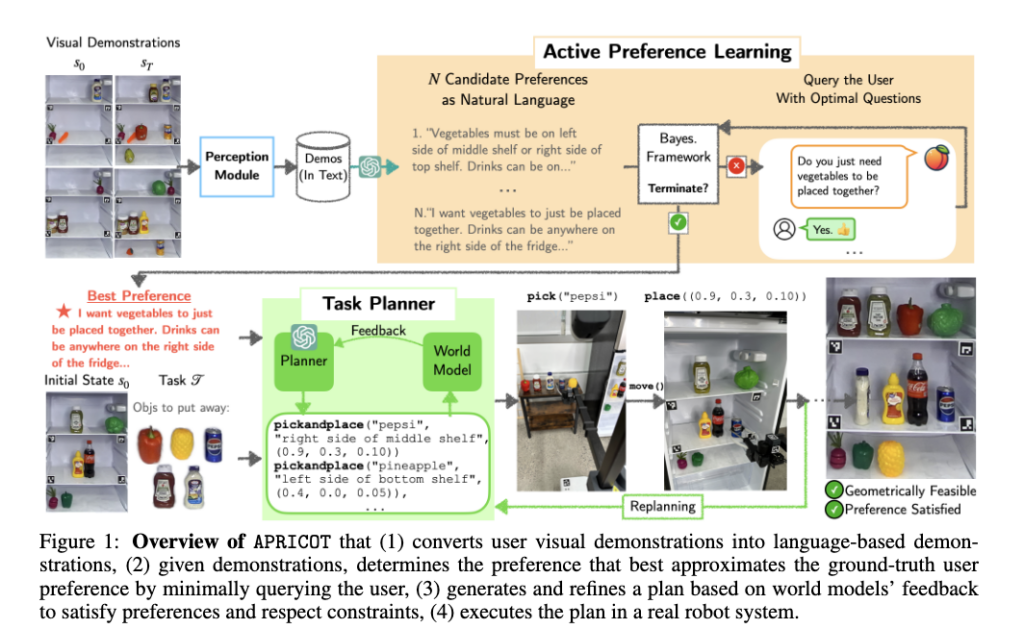
해당 flow는 Figure 1을 통해 확인할 수 있습니다. 본 논문에서 제안한 APRICOT(Active Preference Learning with Constraint-Aware Task Planner)는 4단계를 거치는데요. 1) visual demonstration을 기반으로 언어 기반의 demonstratation으로 변경 -> 2) demonstration만으로 preference가 애매할 때 사용자에게 최소한의 질문을 해서 GT에 가까운 preference를 찾기 -> 3) world model의 feedback을 받아 preference를 만족하면서 constraint를 지키는 plan 만들기 -> 4) 최종적으로 실제 로봇에서 plan 실행시키기로 이뤄져있습니다.
본 논문의 contribution은 다음과 같이 정리할 수 있습니다.
- 적은 demonstration과 적은 online user-queryin으로 preference를 배우는 LLM 기반 Bayesian active preference learning 방법론을 제안함
- user preference와 enviromental constatint를 함께 만족하는 constraint-aware task planner를 실제 로봇 시스템에 구현함
- 50개의 GT preference와 100개의 테스트 케이스, 9개의 실제 로봇 시나리오로 평가함
2. Problem Formulation
논문 저자는 냉장고 정리를 마르코프 의사결정 과정(MDP)로 표현하였는데요. MDP는 현재 state를 보고 action을 고르면 다음 state가 되는 것이라 보시면 되겠습니다.
state는 $s \in S$로 표시합니다. 여기서 $s$는 물건들과 그 위치의 집합을 의미합니다. action은 $a \in A$로 표시하고, 논문에서는 high-level action인 pickandplace(obj name, xyz loc)를 사용합니다.
plan은 $\xi = \{s_0, a_0, \ldots, s_T, a_T\}$로 표시하는데요. initial state $s_0$에서 시작해서 action $a_0$를 하고, 다음 state로 가고, 이런 과정을 시간 $T$까지 반복한 전체 기록을 의미합니다. reward function $R(\xi,\theta)$는 plan $\xi$가 preference $\theta$를 얼마나 만족하는지 평가합니다. 여기서 $\theta$는 냉장고 정리 규칙을 설명하는 자연어 문장으로 표현할 수 있습니다.
$\theta^*$는 latent ground-truth preference를 의미합니다. 즉 사용자의 진짜 마음속 규칙이라 생각하시면 되는데요. 로봇은 $\theta^*$를 직접 볼 수 없고 demonstration과 query를 통해 추정합니다. $R(\xi,\theta)$는 LLM이 계산하며 plan 안의 물건 배치 중 몇 퍼센트가 preference $\theta$를 만족하는지 출력합니다.
environmental constraint는 $C(\xi)=0/1$로 표시합니다. world model이 object placement가 collision을 만드는지 보고 geometric constraint을 계산하는데요. 식 (1)의 목표는 다음과 같습니다.
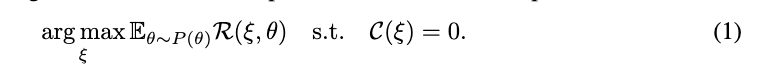
이 식은 가능한 계획plan $\xi$들 중에서, preference prior P(\theta) 아래의 expected reward가 가장 큰 plan을 고르되, 반드시 constraint $C(\xi)=0$을 만족하라고 표현할 수 있습니다.
preference prior $P(\theta)$를 배우기 위해 demonstration 집합 $D$를 사용합니다. demonstrated plan을 $\xi_D \in D$라고 할 때, 논문은 $P(\theta|\xi_D) \propto \exp(R(\xi_D,\theta)) $형태의 Boltzmann distribution을 사용하는데요. 쉽게 말하면, 어떤 preference $\theta$가 사용자의 demonstration $\xi_D$를 잘 설명하면 $R(\xi_D,\theta)$가 높고, 그러면 그 preference의 확률도 높아진다고 이해할 수 있습니다.
여러 demonstration이 있으면 $P(\theta|D)=\prod_{\xi_D \in D}P(\theta|\xi_D)$로 prior를 구성합니다. 여기서 저자가 가정하는 것이 있는데요. 이 prior가 ground-truth preference $\theta^*$를 포함하거나, 적어도 $\theta^*$와 value-equivalent한 preference를 포함해야 한다는 것입니다.
3. Approach
APRICOT의 접근 방식은 세 단계인데요.
첫째, visual user demonstration을 language-based로 바꾸고, 사용자에게 최소한의 질문을 해서 preference를 배웁니다.
둘째, preference를 만족하면서 environmental constraint을 지키는 plan을 만듭니다.
셋째, 실제 mobile manipulator이동 조작 로봇에서 실행합니다.
3.1 Active Preference Learning
Active Preference Learning 모듈은 visual demonstration을 입력으로 받아 VLM을 통해 language-based demonstration D로 바꿉니다. 목표는 ground-truth user preference에 가까운 preference를 출력하는 것입니다.
해당 모듈은 세 부분으로 구성되는데요.
첫째, Propose Candidate Preferences는 demonstration과 일관된 candidate preference를 만듭니다.
둘째, Determine Whether to Query가 지금 prior만으로 충분한지 판단합니다.
셋째, Select and Ask the Optimal Question은 uncertainty를 가장 많이 줄일 질문question을 고르고 사용자 답변을 기반으로 prior를 업데이트 합니다.
3.1.1 Propose Candidate Preferences
preference는 자연어이기 때문에 continuous density function로 직접 관리하기 어려운데요. 그래서 APRICOT은 N개의 candidate preference $\{\theta_i\}_{i=1}^{N}$를 $R(\xi_D,\theta_i)=1,\ \forall \xi_D \in D,\ i=1,\ldots,N$과 같이 샘플링합니다. 또한, candidate preference N개를 얻으면 $P(\theta_i)=\frac{1}{N}$를 통해 처음에는 모두 같은 확률로 둡니다. 이렇게 두는 이유는 처음에는 어떤 candidate preference가 진짜인지 모르기 때문에 모두 똑같이 믿도록 설정하는 것입니다. 근데 새로운 initial condition $s_0$와 task $T$가 주어지면, 모든 candidate preference를 동시에 만족하는 plan $\xi$가 없을 수 있습니다. 그래서 APRICOT은 사용자에게 active querying를 합니다.
3.1.2 Determine Whether To Query
APRICOT은 query를 계속하지 않습니다. 먼저 현재 prior P(\theta)만으로 충분한지 확인한다. 이를 위해 candidate plan library $\Xi$를 만듭니다. 각 candidate preference $\theta_i$에 대해 task planner가 그 preference를 가장 잘 만족하는 plan $\xi_i$를 만듭니다. 그러면 $\Xi=\{\xi_i\}_{i=1}^{N}$가 됩니다.
그 다음 disadvantage function $DISADV(\xi_j,\theta_i)$를 정의합니다.
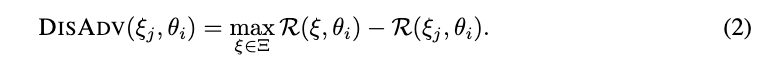
위의 식은 preference $\theta_i $입장에서 plan $\xi_j$가 candidate plan 중 best plan에 비해 얼마나 손해인지를 나타내는데요. 만약 $\xi_j$가 $\theta_i$에 대해 최고 reward를 받으면 DISADV는 0에 가깝게 됩니다. 반대로 $\theta_i$가 중요하게 여기는 배치를 못 맞추면 $DISADV$가 커지게 됩니다.
질문을 멈추는 terminating condition은 다음고 같습니다.
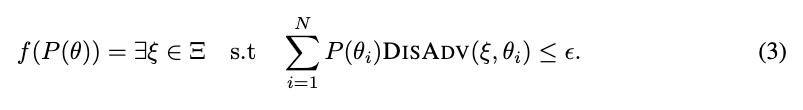
어떤 $plan \xi$ 하나가 모든 candidate preference에 대해 평균적으로 큰 손해가 없으면 질문을 멈춘다는 것을 의미합니다. 여기서 $P(\theta_i)$는 해당 candidate preference를 얼마나 믿는지이고 $\epsilon$은 threshold를 의미합니다. 논문은 $\epsilon=0.07$을 사용했다고 하네요. 이 조건이 참이면 APRICOT은 더 묻지 않고 해당 plan과 그 plan을 만든 preference를 선택합니다.
3.1.3 Select and Ask Optimal Query
query가 필요하다고 판단되면 APRICOT은 가장 정보가 큰 question을 고르는데요. 사용자는 yes/no로 답한다고 가정합니다. question을 q, answer을 $o\in\{yes,no\}$라고 한다. 논문은 information gain을 최대화하는 question을 고릅니다.
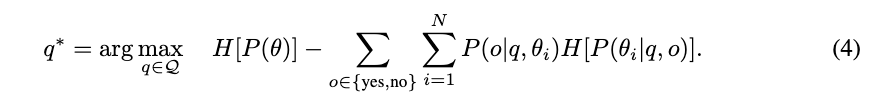
H는 entropy로, candidate preference들 사이에서 얼마나 헷갈리는지를 나타낸다. 여기서 Q는 LLM이 만든 candidate question 집합을 의미합니다. APRICOT은 각 preference pair $(\theta_i,\theta_j)$에 대해 M개의 question을 만들고, 이를 모아 Q를 구성합니다.
사용자가 특정 preference \theta_i를 가진다고 가정했을 때 question q에 yes라고 답할 확률은 Bradley-Terry Model을 사용해 계산하는데요. 식은 다음과 같습니다.
$P(o|q,\theta_i)=\sigma(P^{\text{roleplay}}(o=yes|q,\theta_i)-P^{\text{roleplay}}(o=no|q,\theta_i))$
$P^{\text{roleplay}}$는 LLM이 “나는 preference \theta_i를 가진 사용자다”라고 역할극을 하며 답을 추정하는 값을 의미합니다. 이후에는 사용자 답변을 받으면 posterior를 업데이트합니다.
$P(\theta_i|q,o)=\frac{P(o|q,\theta_i)P(\theta_i)}{P(o,q)}$
3.2 Preference and Geometric Constraint Aware Task Planner
Task planner는 초기 condition $s_0, task T, preference \theta_i$를 받아 plan $\xi_i$를 출력합니다. 목표는 R(\xi_i,\theta_i)를 크게 만들고 동시에 $C(\xi_i)=0$을 만족하는 것입니다.
첫 단계는 semantic plan을 만드는 것입니다. semantic plan은 pickandplace("apricot", "top shelf")처럼 “무엇을 어느 의미적 위치(semantic location)에 둘지”를 말합니다.
둘째 단계는 geometric plan으로 바꾸는 것입니다. world model 냉장고의 3D point cloud와 물건들의 3D bounding box를 가지고 있는데요. 이를 task planner가 semantic location을 3차원 좌표 범위로 바꾸고, beam search로 가능한 좌표를 찾습니다. 각 node는 어떤 물건의 후보 XYZ placement coordinate를 의미합니다.
셋째 단계는 reflect and refine입니다. APRICOT은 Reflexion 스타일 프롬프트를 사용해 $R(\xi_i,\theta_i)$와 $C(\xi_i)$의 feedback을LLM planner에게 줍니다. 예를 들어 파인애플과 피망을 아래 칸 왼쪽에 모두 놓으면 preference는 만족하지만 충돌이 난다는 feedback을 주면, LLM planner는 피망을 위 칸 오른쪽으로 옮기는 식으로 plan을 고치게 됩니다.
3.3 Execution on a Real Mobile Manipulator
실제 로봇 시스템은 perception과 execution policy를 추가로 사용합니다.
Perception 시스템은 이미지를 보고, object를 찾고, 각 물건의 semantic location을 보는데요. 냉장고에 나올 수 있는 식료품 목록, 냉장고를 보는 static camera, 선반 위치를 찾기 위한 ArUco tag를 가정합니다. Object detector는 Grounding-DINO를 사용했다고 합니다.
Execution policy는 high-level action pickandplace(<obj>, <xyz loc>)를 낮은 수준의 skill로 바꾼다. pick(<obj>)와 place(<xyz loc>)는 low-dimensional simulator에서 강화학습으로 학습한 policy를 사용합니다. move()는 단순한 경로 계획기(path planner)를 사용하고, 시스템은 각 high-level action을 끝낼 때마다 plan \xi_i를 다시 생성하여 환경 변화에 반응합니다.
4. Experiments
4.1 Active Preference Learning Experiment
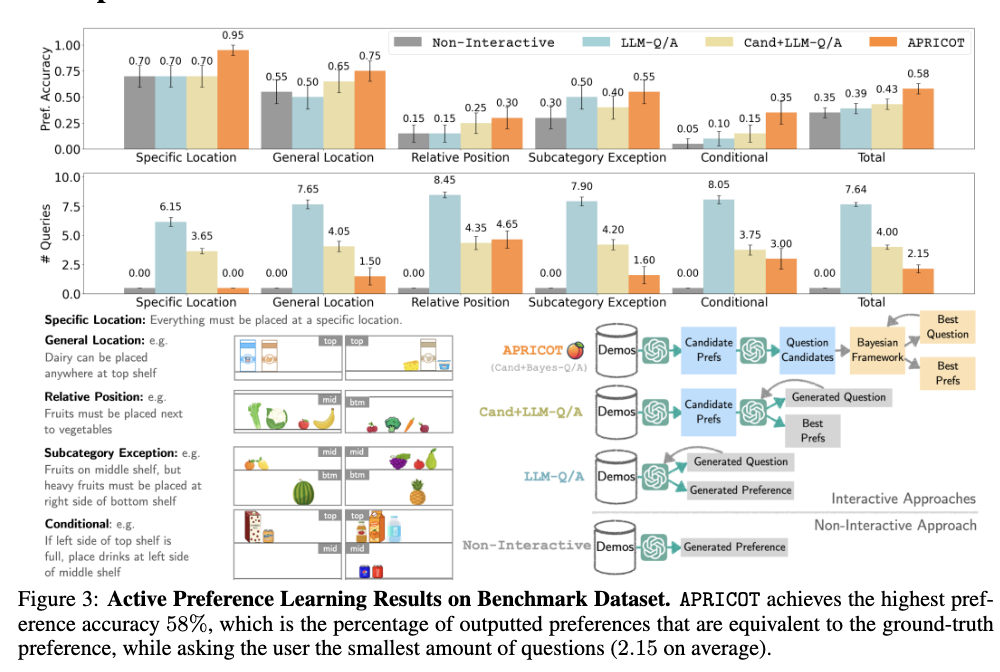
첫 번째 실험은 APRICOT의 preference inference 능력을 봅니다. 데이터셋은 100개 테스트 케이스로 구성되며, 각 케이스에는 ground-truth preference, 2개의 demonstration, 그리고 새로운 테스트 상황이 있습니다.
baseline은 크게 두 종류로 구성되는데요. Non-Interactive은 사용자에게 질문 하지 않고 demonstration만 사용합니다. LLM-Q/A와 Cand+LLM-Q/A는 사용자에게 질문 하지만, 질문 선택과 종료 판단을 LLM에 더 맡기는 버전이라 생각하시면 됩니다. APRICOT은 candidate preference를 만들고, information gain이 큰 질문을 골라 사용자에게 묻는 방식이라는 점에서 다른 부분을 가집니다.
Figure 3를 통해서 결과를 확인할 수 있는데요. APRICOT이 가장 높은 preference accuracy를 얻은 것을 확인할 수 있습니다. APRICOT은 58.0%를 달성했고, Non-Interactive는 35.0%의 가장 낮은 성능을, LLM-Q/A는 39.0%, Cand+LLM-Q/A는 43.0%로 그나마 높지만 APRICOT보다는 낮은 성능을 보인 것을 알 수 있습니다. 또한 APRICOT은 평균 2.15개의 쿼리만 사용했다고 하는데, 더 많이 질문하는 것이 아니라 더 중요한 쿼리를 고르는 방식으로 성능을 높임을 알 수 있습니다.
4.2 Real robot experiments
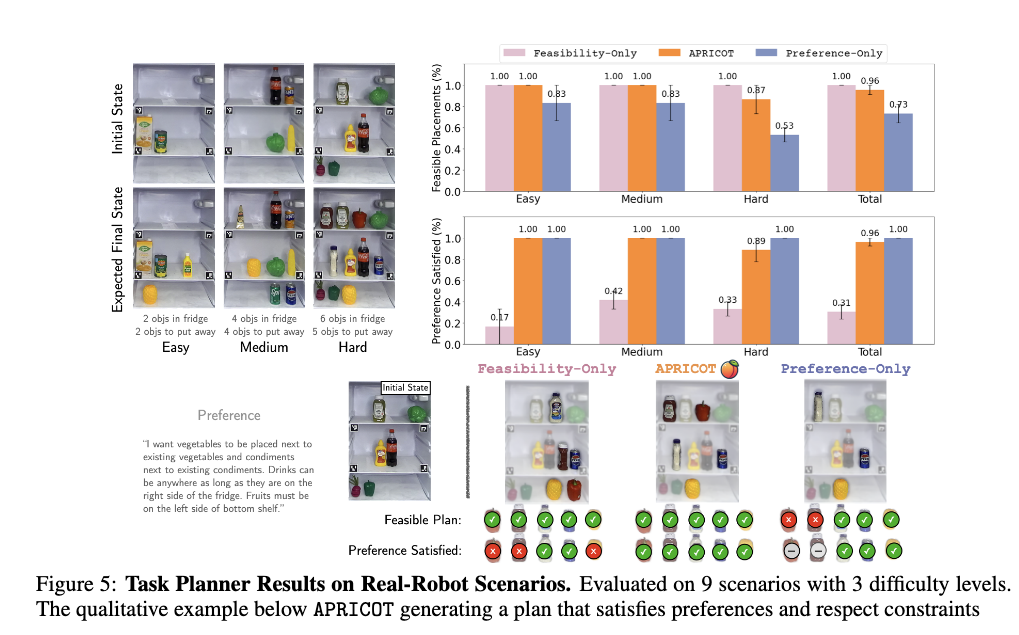
두 번째 실험은 APRICOT이 real robot environment에서도preference와 constraint을 함께 만족할 수 있는지 봅니다. 평가는 두 가지를 보는데요. 첫째, 물건을 충돌 없이 놓을 수 있는가. 둘째, 물건이 사용자의 preference에 맞게 놓였는가입니다.
Figure 5를 통해서 그 결과를 확인할 수 있는데요. APRICOT이 Hard case에서도 feasible plan 96.0%, preference satisfied 89.0%를 유지했다는 것을 볼 수 있습니다. 이는 APRICOT이 단순히 “사용자가 좋아하는 위치”만 고르는 것이 아니라, world model의 feedback을 사용해 실제로 가능한 위치를 다시 찾아 높은 성능을 유지함을 알 수 있습니다.
이렇게 APRICOT 논문 리뷰를 마쳐보도록 하겠습니다. preference-aware 논문은 처음인데 단순히 조작 성공률에 그치는 것이 아니라 사용자의 선호를 동시에 고려한다는 것에서 매력을 느낀 분야인 것 같습니다. 감사합니다.