안녕하세요 이번주는 WAM을 소개하려고 합니다. 최근 로봇 파운데이션 모델들의 연구에서 로봇 데이터의 teleoperation 의존도를 낮추는 연구와 기존 데이터를 통해서 3차원 현실에서 작동하기 위한 모델 구조, pretraining 연구로 나뉘고 있는데요, 그 중 VLA 구조에서 벗어난 WAM을 다룬 연구를 가져왔습니다. 리뷰 시작하겠습니다.
Introduction

최근 Vision-Language-Action 모델은 VLM의 언어적·시각적 prior를 로봇 행동 생성에 연결하면서 다양한 물체와 언어 명령에 대해 의미론적 일반화를 보여주고 있습니다. 그러나 저자들이 보기에 기존 VLA의 일반화는 주로 “무엇을 집어야 하는가”, “어떤 객체가 지시 대상인가”와 같은 semantic grounding에 강하게 치우쳐져 있습다고 합니다. 실제로 VLA들은 VLM이 이해하는 방식으로 학습하기 때문에 언어를 학습하는 방식으로, 의미론적인 학습이 많이 된다고 합니다. 반대로 “그 행동을 물리적으로 어떻게 수행해야 하는가”, “새로운 환경에서 처음 보는 동작을 어떤 시간적 전개로 실행해야 하는가”에 대해서는 여전히 취약합니다. 예를 들어 VLA는 학습 중 본 pick and place류 행동을 다양한 객체에 적용하는 데는 어느 정도 성공할 수 있지만, 신발끈 풀기 처럼 학습 데이터에 거의 등장하지 않은 motion primitive가 요구되는 작업에서는 실패하기 쉽습니다. 저자들은 이 원인을 VLA가 주로 static image-text pretraining을 기반으로 출발하기 때문이라고 봅니다. VLM은 언어와 이미지의 의미적 대응을 잘 학습하지만, 물리 세계가 시간에 따라 어떻게 변화하는지에 대한 spatiotemporal prior는 충분히 갖고 있지 않기 때문입니다.
저자들은 이 문제를 해결하기 위해 World Action Model, WAM이라는 관점을 제안합니다. WAM은 observation과 언어 명령에서 action을 직접 예측하는 모델이 아니라, 미래의 visual world state와 action을 함께 예측하는 모델입니다. 이때 video는 단순한 보조 출력이 아니라, 세계가 앞으로 어떻게 변해야 하는지를 나타내는 dense representation입니다. 따라서 DreamZero의 핵심 철학은 action learning을 direct behavior cloning 문제가 아니라, predicted visual future와 motor command를 정렬하는 inverse dynamics 문제로 재정의하는 데 있습니다. 다시 말해, 모델은 먼저 “이 명령을 따르면 앞으로 장면이 어떻게 변해야 하는가”를 생성하고, 그 미래 변화에 맞는 action trajectory를 함께 생성합니다. 저자들은 figure 1과 같이 이를 통해 heterogeneous하고 non-repetitive한 robot data에서도 효과적으로 학습할 수 있고, 새로운 환경과 새로운 task에 대해 zero-shot generalization을 얻을 수 있으며, action label이 없는 사람 또는 다른 로봇의 video-only data까지 활용할 수 있다고합니다.
이렇게 WAM은 기존 VLA와 근본적으로 다른 철학을 갖습니다. VLA는 VLM의 semantic prior를 action head에 연결하는 것이 근본(?)입니다. 따라서 모델이 잘하는 것은 언어 명령의 의미를 해석하고, 학습된 action distribution 안에서 그 명령에 맞는 행동을 선택하는 것입니다. 반면 저자들이 말하길 DreamZero는 video diffusion backbone이 가진 physical dynamics prior를 action prediction과 결합합니다. 여기서 video prediction은 일종의 implicit visual planner 역할을 합니다. Action decoder는 그 visual plan을 실제 로봇의 motor command로 변환하는 implicit inverse dynamics model처럼 작동합니다. 이 때문에 DreamZero에서 policy performance는 단순히 action decoder의 성능이 아니라 video generation quality와 강하게 연결된다고 합니다. Generated video가 올바르면 action도 그 방향으로 잘 정렬되지만, generated video가 잘못된 계획을 만들면 실제 실행도 그 잘못된 visual plan을 따라갑니다.
핵심은 다량의 데이터를 통해 배운는 내용이 새로운 task에 대해 zero-shot으로 대응하기 위해서는 모델이 언어 명령을 이해하는 것만으로는 부족하고, 그 명령이 실제 물리 세계에서 어떤 미래 상태 변화를 만들어야 하는지에 대한 backbone이 필요하다고 합니다. 저자들은 이를 WAN 2.1 14B image-to-video diffusion model 을 통해서 해결해보려고 했다고 합니다. (Inference에만 H100 두장이 필요하네요,,) DreamZero는 web-scale video prior를 image-text가 아닌 action과 정렬했다는 것이 핵심 차이이고, 이 차이가 저자들이 DreamZero가 WAM을 통해 기존 VLA보다 더 강한 unseen motion generalization을 주장하는 핵심 근거입니다.

Main contribution은 위와 같이 14B WAM을 만들고 잘 쓸 수 있도록 만들어서 오픈소스 했고, 심지어 X embodiment 또한 30분 분량의 작은 데이터로 해낸다고 합니다. 아래와 같은 task들에 대해서 zero-shot으로 일반화가 가능했다고 하네요. 저자가 말한것을 들어보면 사실 전부 다 완벽히 수행하진 못하지만, 마치 GPT-2가 처음 나왔을 때 이거저거 물어보면 그럴싸한 답변을 주었듯 로봇을 끌고다니며 이런저런 일을 시켜보니 정말 그럴듯한 액션들을 보여주었다고 합니다.

Related Works
기존 foundation model 기반 로봇 연구들은 pretrained LLM이나 VLM을 high-level planner로 사용하고, 그 결과를 별도의 low-level policy나 controller가 실행하는 modular system을 많이 사용했습니다. 이러한 방식은 high-level reasoning과 task decomposition에는 강하지만, 이미 준비된 low-level skill library와 안정적인 interface가 필요하다고 합니다. 또한 planning, perception, low-level control이 분리되어 있기 때문에 각 모듈의 작은 오류가 누적될 수 있다고 합니다.
또한 저자들은 VLA의 pretraining source가 대부분 static image-text data라는 점을 문제로 봅니다. VLA는 VLM으로부터 object recognition, language following, semantic association 능력은 물려받지만, 물리적 상호작용이 시간에 따라 어떻게 전개되는지에 대한 prior는 상대적으로 약합니다. 그래서 object-level generalization은 가능해도, 완전히 새로운 skill이나 환경 변화에 대한 generalization이 제한된다고 합니다. 저자들은 그렇기 때문에 기존 VLA가 환경 일반화를 얻기 위해서는 수많은 환경에서 동일한 작업을 수행하며 human teleoperation data를 수집하거나, task 일반화를 위해 거대한 motion primitive library를 만들어야 한다고 지적합니다.
저자들은 video model 기반 robot policy를 위 한계들을 보완할 수 있는 방법으로 가져왔습니다. 이전 연구들은 video generation model을 이용해 robot trajectory를 합성하거나, generated video에서 inverse dynamics model을 통해 action을 추출하거나, optical flow 또는 point tracking을 dense correspondence로 사용했습니다. 또 다른 연구 흐름은 human video를 생성하거나 추적한 뒤, 이를 policy training에 활용하려고 했습니다. 이 런 연구들의 핵심은 video model이 단순히 이미지를 생성하는 모델이 아니라, 시간적 변화와 물리적 상호작용에 대한 prior를 갖고 있다는 점입니다. 저자들은 그런 능력을 action prediction에 직접 연결했다고 보시면 됩니다.
저자들은 JEPA나 point방식의 world model들도 굵직한 연구들로 자리매김 해서 그런지 해당 부류의 World Model들도 언급했스빈다. JEPA나 Dreamer류의 latent-space world model은 pixel이 아니라 abstract latent space에서 future state를 예측하고 이는 계산 효율적이고 예측하기 어려운 세부 정보를 버릴 수 있다는 장점이 있지만, 대체로 p(s_{t+1}|s_t, a_t) 형태의 forward dynamics를 모델링하기 때문에 policy로 사용한다고 했을 때는 test time에 goal-conditioned planning이나 search를 통해 action trajectory를 찾아야 하는 단점이 있다고 저격했습니다. 또 point cloud world model인 PointWorld류 접근도 scene dynamics를 3D point flow로 예측하고 MPC와 결합할 수 있지만, 마찬가지로 inference 시점에 MPPI sampling 같은 명시적 최적화가 필요하다는 점을 한계로 짚으며 world 예측과 action 예측을 동시에 closed loop로 진행하는 구조의 강점을 어필했습니다.
Method
DreamZero의 모델 구조는 pretrained video diffusion model을 최소한의 추가 모듈로 robot policy로 확장하는 형태입니다. Backbone은 Wan2.1-I2V-14B-480P image-to-video diffusion model입니다. 입력은 Video, Action, Language입니다. Visual context는 VAE를 통해 latent로 encoding되고, language instruction은 text encoder를 거치며, proprioceptive state는 state encoder를 통해 모델 내부 표현으로 변환됩니다. 이 입력들이 autoregressive DiT backbone으로 들어가고, 최종적으로 future video frame과 action이 각각 별도의 decoder를 통해 예측됩니다. 다중 카메라 view가 있는 경우 backbone architecture를 바꾸지 않고 여러 view를 하나의 frame으로 concatenate해서 쓴다고 합니다. 이는 pretrained video model의 구조적 prior와 generalization 능력을 최대한 보존하기 위한 설계입니다.

문제 정의는 joint video-action prediction입니다. DreamZero는 language instruction c, 현재 proprioceptive state q_l, 그리고 과거 visual observation o_{0:l}이 주어졌을 때, 미래 video o_{l:l+H}와 action a_{l:l+H}를 함께 예측합니다. H가 정해진 horizon입니다. 여기서 핵심은 위 (1)식이 두개로 나뉘어져 있듯 과거 관측과 언어 명령으로부터 미래 video를 예측하는 autoregressive video prediction와 그 미래 observation sequence에 맞는 action을 예측하는 inverse dynamics model로 나누어졌다는 것입니다. 다만 이 두 부분을 별도의 video prediction model과 별도의 IDM으로 나누지 않고 flow matching objective로 한번에 학습합니다. 저자들은 이 구조가 video와 action 사이의 alignment를 더 강하게 만든다고 합니다. Training은 각 chunk에 대해 clean video latent와 normalized action에 gaussian noise를 섞어 noisy video latent와 noisy action을 만들고, 모델은 clean vector와 noise vector 사이의 velocity를 예측합니다. 이 때 video와 action이 같은 denoising timestep을 공유합니다. 각 chunk 안의 모든 frame은 같은 timestep을 공유하지만, chunk마다 timestep은 독립적으로 샘플링됩니다. 모델이 학습할 때 clean previous chunks를 context로 보고, noisy current chunk를 denoise하도록 학습되는데, 이 구조는 LLM이 이전 token context를 보고 다음 token을 예측하는 방식과 유사하게, variable-length trajectory 학습을 가능하게 한다고 합니다.
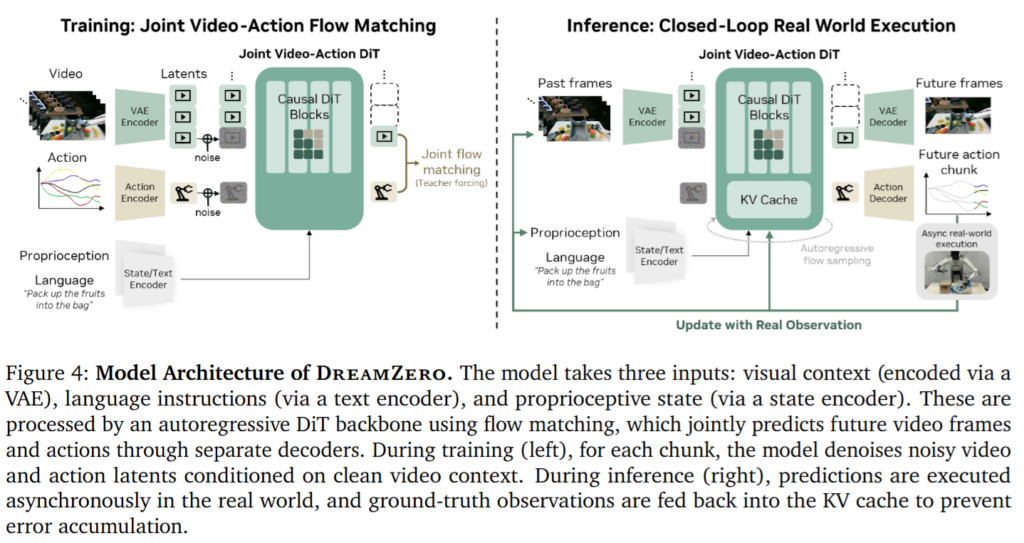
또 해당 모델은 autoregressive인데, 저자들은 DreamZero에서 autoregressive architecture를 선택한 이유는 단순히 빠른 inference 때문이 아니라고 합니다. 저자들은 autoregressive structure가 WAM에서 video, action, language alignment를 유지하는 데 더 적합하다고 합니다.
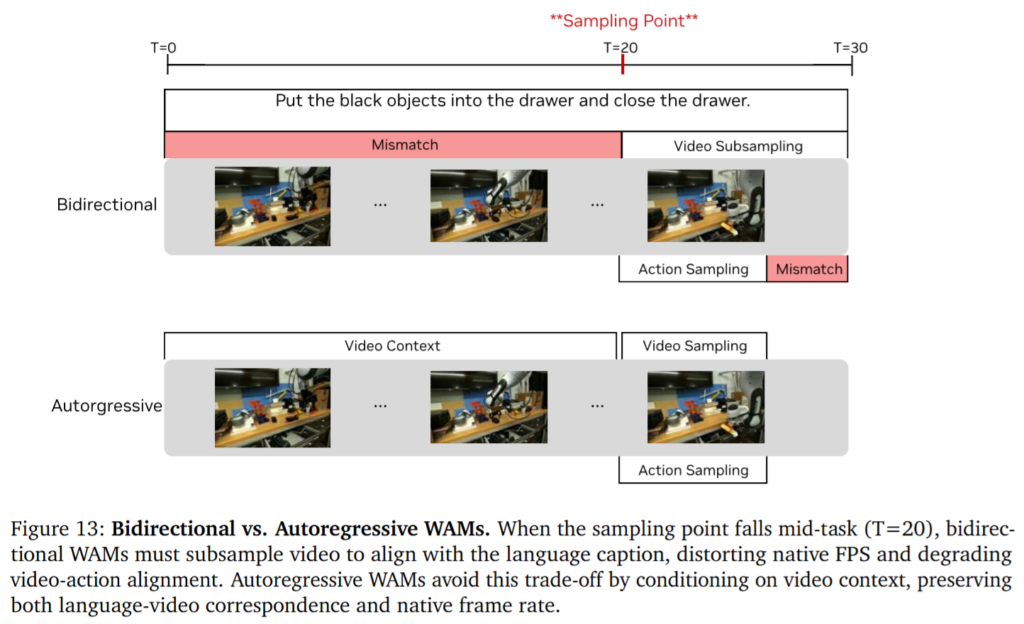
위 figure 13처럼 Bidirectional diffusion은 fixed-length sequence를 처리해야 하므로 긴 horizon을 다루기 위해 video subsampling이 필요해질 수 있습니다. 그런데 robot control에서는 frame과 action의 temporal alignment가 중요하기 때문에 native FPS를 왜곡하면 action supervision이 흐려진다고 합니다. 반면 저자들의 말에 의하면 autoregressive generation은 KV cache를 활용해 긴 context를 처리할 수 있고, native frame rate를 유지한 채 다음 chunk를 생성할 수 있다고 합니다. Bidirectional WAM은 전체 sequence를 한 번에 denoise하는 장점이 있지만, robot control에서 실시간으로 들어오는 observation과 action chunk를 정렬하기 어렵기 때문에 autoregressive 구조를 선택했다고 합니다.
Inference도 현실적인 문제를 해결하기 위해 Async 구조와 real 영상을 과거 context로 사용하는 방법을 채택했다고 합니다. 일반적인 autoregressive video generation은 생성된 frame을 다음 생성의 context로 사용하기 때문에 오류가 누적되는데, 저자들은 closed-loop robot setting에서의 real 영상을 이용해 이 문제를 해결했다고 합니다. 하나의 action chunk를 실행한 뒤, 실제 로봇 카메라에서 얻은 ground-truth observation을 다시 VAE로 encoding하고, 이를 KV cache에 넣어 predicted video를 대체한다고 합니다. 즉, 모델은 미래를 예측하지만, 다음 시점에서는 실제 세계가 제공한 관측으로 context를 갱신하면서 autoregressive generation의 효율성과 visual history 활용 능력을 유지하면서도, video generation에서 나타나는 compounding error를 줄일 수 있었다고 합니다.

위 figure 14를 보면 Training에서는 noisy current chunk가 clean previous chunks를 볼 수 있도록 masking하고, inference에서는 real observation으로 KV cache를 업데이트해 다음 chunk 생성의 context로 사용합니다. Training과 Test에 대한 알고리즘은 아래와 같습니다. 아래에서 말씀드린 내용을 확인할 수 있스빈다.

Inference 시에 real-time execution도 저자들이 집중한 부분이라고 합니다. 14B video diffusion model을 그대로 robot policy로 사용하면 action chunk 하나를 생성하는 데 H100 두장으로 약 5.7초가 걸렸다고 합니다. 병목은 16 diffusion steps, 14B DiT backbone의 계산량, 그리고 inference가 끝날 때까지 robot execution이 막히는 sequential control 구조라고 합니다. 저자들인 이 문제를 해결하기 위해서 asynchronous closed-loop execution을 사용합니다. 로봇은 현재 action chunk를 실행하는 동안, 최신 observation을 기반으로 다음 action chunk를 병렬로 생성합니다. 이러면 30Hz control frequency에서 48 step action horizon을 사용하므로 하나의 chunk는 1.6초를 커버합니다. 따라서 inference가 1.6초안에 끝나야 아무런 끊김이 없는 구조입니다. 저자들은 행동 이후 200ms 안에 다음 inference가 끝나도록 설계했다고 합니다. 5.7초에서 4초 정도를 단축하는 그림입니다. 이를 위해 system level optimization과 implement level optimization을 했습니다.
System-level optimization은 CFG parallelism과 DiT caching를 사용했습니다. Classifier-free guidance는 conditional forward와 unconditional forward가 필요하므로 이를 두 GPU에 분산해 per-step latency를 줄였고, DiT caching은 flow matching에서 연속 denoising step 사이의 velocity direction이 일관적이라는 점을 이용해 successive velocity의 cosine similarity가 threshold를 넘으면 DiT forward를 다시 계산하지 않고 cached velocity를 재사용하여 effective DiT step을 줄였다고 합니다. (그렇다고 하네요..)
Implementation-level optimization으로는 torch.compile, CUDA Graphs, cuDNN attention backend, scheduler operation의 GPU migration, Blackwell architecture에서의 NVFP4 quantization을 사용했다고 합니다. QKV, Softmax, LayerNorm, RoPE 같은 연산들은 FP16으로 유지했다고 합니다.
Model-level optimization같은 경우는 video와 action이 같은 timestep에서 denoise되도록 학습되지만 inference 때 빠르게 하기 위해 inference step을 4 이하 또는 1 step까지 줄이는 방법으로 갔다고 합니다. 이 때 training에서는 video와 action의 noise level이 같았지만, few-step inference에서는 action이 noisy visual context를 보고 clean action을 예측해야 하는 train-test mismatch가 발생하는데, DreamZero-Flash는 이를 해결하기 위해 video timestep과 action timestep을 분리했다고 합니다. Action timestep은 uniform하게 유지하고, video timestep은 high-noise video state 쪽으로 bias했다고 합니다. 그 결과 모델은 noisy visual context에서도 clean action을 예측하는 법을 학습하고 DreamZero-Flash 1-step은 전체 inference 시의 성공률의 74%를 유지하면서 150ms latency를 달성했다고 합니다.
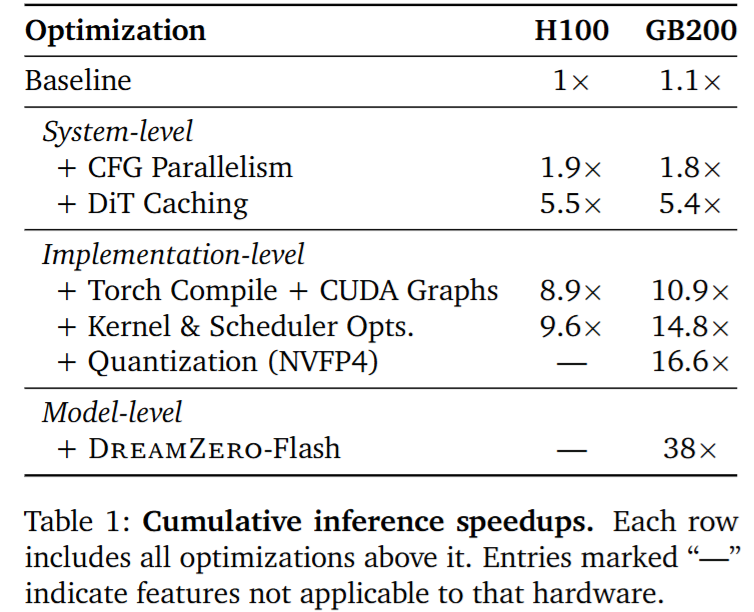
다음과 같이 위에서 말한 내용들로 극한으로 깎아서 5.7초 걸리던 latency를 150ms 까지 줄였다고 합니다.
Experiments
Pretraining은 아래와 같이 다양한 skill들이 포함된 데이터를 500시간 정도 모아서 진행했다고 합니다. 특이한 점은 에피소드마다 평균 42개의 subtask를 포함시켜 long horizon의 데이터를 취득했고, 에피소드별로 다 같은 데이터를 취득하지 않고 굉장히 다양하게 취득하되, 같은 subtask를 기존 VLA 데이터처럼 반복하며 취득하지는 않았다고 합니다. 기존 WAN2.1 14B를 LoRA finetuning 했다고 하빈다.
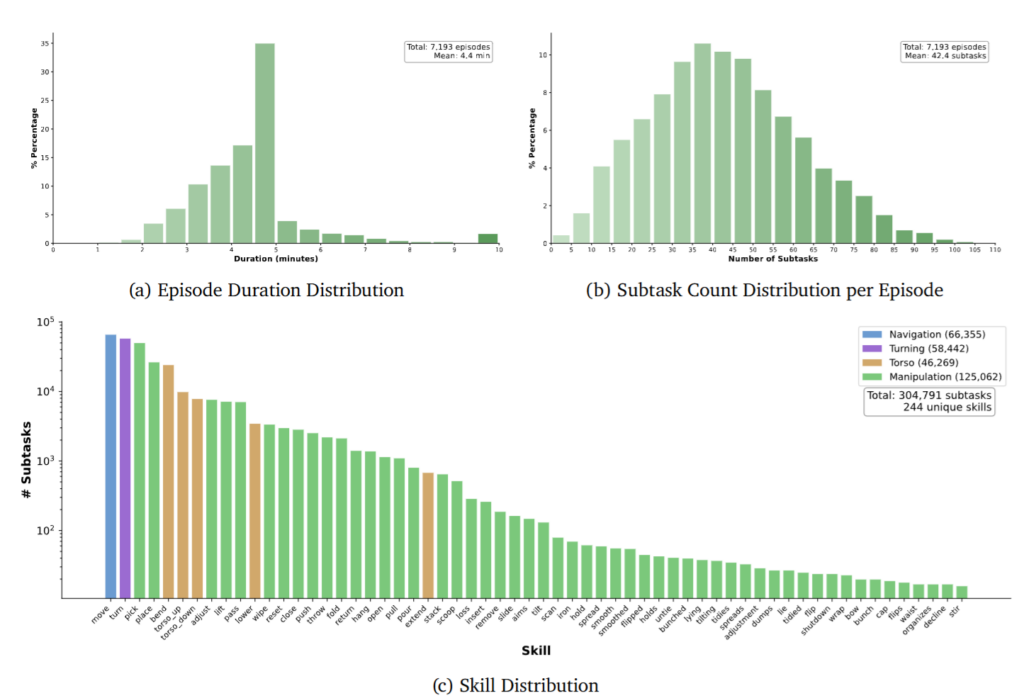
Evaluation protocol은 unseen task의 경우 pretraining시에 애초에 존재하지 않았던 task를 평가하고, seen task는 pretraining distribution에 존재하는 motion-object category를 바꿔서 진행했다고 합니다. 예를 들어 학습에서 빨간 셔츠를 접었다면, 평가에서 크기와 색이 다른 검은 셔츠를 접는 것은 seen task로 분류됩니다. 반면 양말 접기처럼 필요한 motion 자체가 다르면 unseen task로 분류합니다. 기본적으로 VLA 입장에서는 unseen task, unseen object를 가지고 실험했습니다. Post training의 경우 해당 task에 대해 10시간~30시간 정도의 데이터를 추가로수집해 post training한 이후 새로운 테이블 높이, object종류, 위치를 가지고 OOD에 대한 평가를 실험했습니다.
Seen task는 pick-and-place, stacking, wiping, folding 등 10개로 구성되며, task당 8 rollouts를 4대 로봇과 다른 환경·물체에서 수행합니다. Unseen task는 ironing, painting, pulling cart, cube stacking, hat removal, shoelace untying 등 학습에 없던 10개 task로 구성됩니다.

Results
첫 번째 실험은 main result이고, 반복적이지 않은 다양한 데이터로부터 policy가 얼마나 잘 학습되냐?에 대한 냉용입니다. DreamZero는 seen task에서도 unseen environment와 unseen object 조건에서 VLA들 보다 훠씬 뛰어난 결과를 보여줍니다. VLA는 object 쪽으로 reach는 하지만 정확한 contact와 manipulation에 실패하는 반면, DreamZero는 정밀한 action이 가능했다고 합니다.
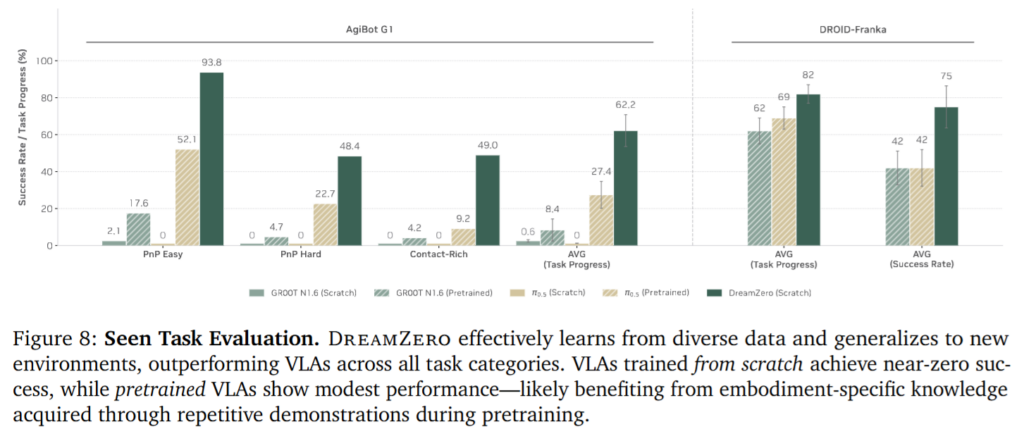
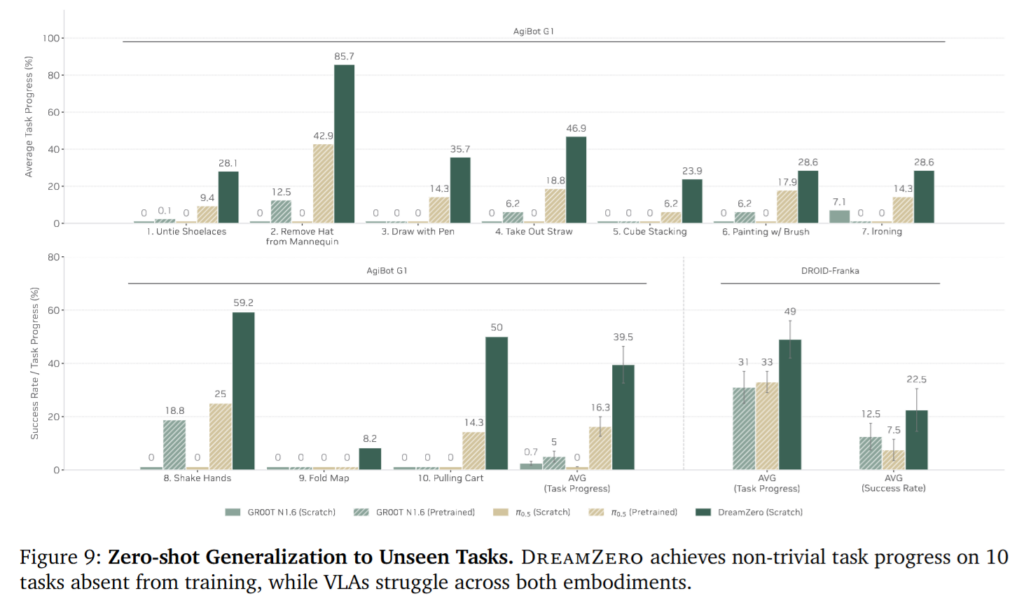
Unseen task에 대해서도 VLA는 대부분 pick-and-place류 행동에 치우쳐 새로운 motion을 제대로 수행하지 못했지만, DreamZero는 hat removal, shake hands 같은 새로운 동작에서도 의미 있는 성능을 보였다고 합니다. 이게 사실상 VLA의 한계와 WAM의 핵심을 제일 잘 보여주는 것 같습니다.
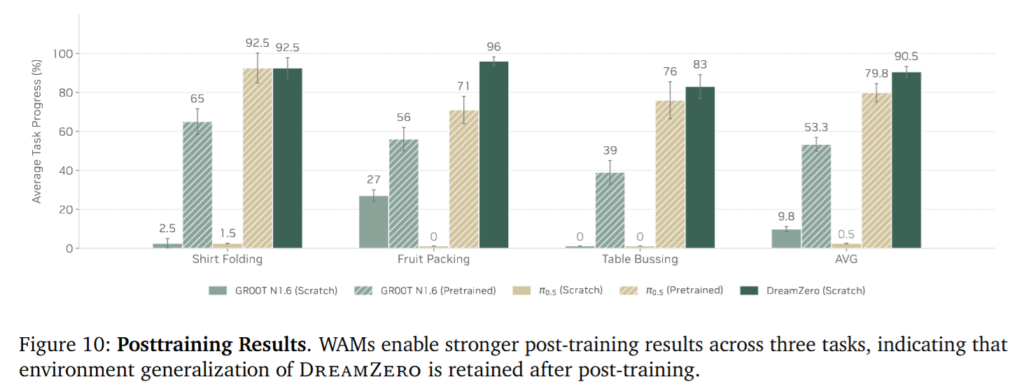
DreamZero는 shirt folding, fruit packing, table bussing post-training 이후에도 기존 VLA보다 높은 성능을 달성했습니다. 중요한 점은 평가가 여전히 unseen environment에서 수행되었다는 것입니다. DreamZero가 task-specific fine-tuning을 해도 환경 일반화를 잃지 않고, video world prior를 유지한 상태에서 downstream task 성능을 높일 수 있다는 것이 증명된 실험입니다.
DreamZero는 다른 embodiment의 video-only data만 추가해도 unseen task 성능이 향상되었다고 합니다. Baseline보다 human video, YAM robot video를 추가하면 성능이 향상되는 것을 볼 수 있습니. 핵심은 action label 없이도 visual demonstration이 world model의 task dynamics 학습 신호로 작동한다는 점입니다.


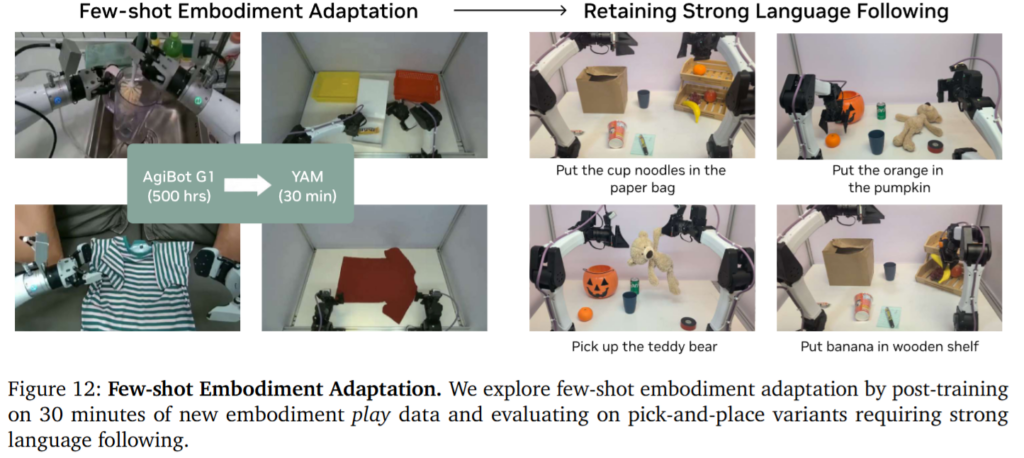
그러다 보니 아래 처럼 새로운 embodiment에 적응할때도 30분의 embodiment specific한 데이터로 새로운 로봇팔에 적응할 수 있다고 합니다. 위 실험과 더불어 motion 자체의 temporal하고 물리적인 이해가 pretraining때 제대로 이루어졌는가?에 대한 답이 되는 실험이라고 생각하면 될 것 같스빈다.
아래는 저자들의 model optimization에 대한 실험입니다. Denoising step을 1로 줄였을 때 기존의 dream zero보다 action과 video 생성을 decoupling 한 dreamzero-flash가 같은 inference speed를 가지고 74%의 task progress를 보이는 것을 알 수 있습니다.

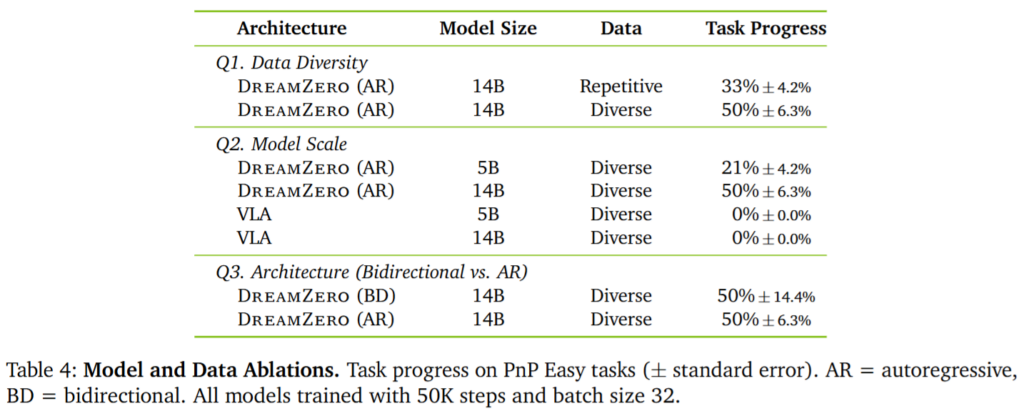
Ablation 결과를 보면 같은 500시간의 학습데이터를 수집해도 repetitive data로 학습한 policy는 33% task progress를 보였고, diverse data로 학습한 DreamZero는 50%를 보였습니다. 단순히 많은 반복 demonstration보다 다양한 state-action correspondence이 중요한 것을 볼 수 있습니다.
또 model scale에 따른 성능 변화도 볼 수 있습니다. 5B 모델로 학습했을 때 보다 14B 모델을 썼을 때 task progress가 올라가는 모습을 보였습니다. 반면 VLA는 5B와 14B 모두 diverse data setting에서 학습을 할 수 없었다고 합니다. 단순히 모델 크기를 키우는 것만으로는 VLA가 diverse robot data를 활용하지 못하는 것을 증명한는 실험이라고 볼 수 있겠습니다.
Architecture ablation에서는 bidirectional과 autoregressive가 평균 task progress에서는 비슷했지만, autoregressive가 더 부드러운 motion과 더 빠른 inference를 보였다고 합니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
저자들이 video prediction branch에 대한 ablation 실험을 따로 다루고 있는지 궁금합니다.
실제 policy 성능이 좋아진 이유가 video generation이 물리적 미래를 잘 예측했기 때문인건지 아니면 large scale diffusion backbone과 action decoder의 scale 효과 때문인지가 궁금합니다.
감사합니다.
안녕하세요 우현님 댓글 감사합니다.
video prediction branch 자체를 제거하거나 비활성화한 ablation은 따로 제시된 것이 없습니다. WAM은 성능이 14B > 5B 인데 반해 VLA 모델은 14B까지 큰 모델을 만들어도 여전히 학습이 불가능하다는 실험을 통해서 간접적으로(?) 보여준 실험이 아닐까 싶습니다.
다만 WAM의 핵심은 video generation이 워낙 물리적인 변화를 잘 담아내니, 그 영상을 통해 action을 역으로 만들어내자는 inverse dynamics 문제를 푸는 것이라 근본적으로 설계는 우현님이 말씀하진 video generation의 물리적 미래 예측에 기반합니다.