안녕하세요 4번째 X-review입니다. 이번에는 새로운 결의 논문을 가져왔는데요. Visual Prompt Tuning입니다.
Visual Prompt Tuning(이하 VPT)에 대해 조금 더 자세히 설명을 해보자면 LLM에서 prompt를 이용해 전체적인 방향을 tuning하는 것처럼 ViT계열에서는 일부 token을 통해 backbone(freezed)을 원하는 방향으로 조절하는 방식입니다. 예를 들어, pre-trained ViT를 segmentation task에 적용하려면, 물체의 경계 부분에 집중해야합니다. 하지만 pretrained-ViT는 경계보단 object-centric한 경향이 있습니다. 그러나 잘 학습된 visual token을 넣어주면, pre-trained의 가중치를 하나도 바꾸지 않아도, segmentation에 적합하게 feature embedding을 뽑을 수 있습니다.
VPT를 처음 제시한 건 “[ECCV 2022] Visual Prompt Tuning”라는 기념비적인 논문입니다. 그리고 오늘 리뷰하려는 논문을 이런 visual prompt를 단순히 CLS token처럼 1d로 배치하는 것이 아닌 2d로 배치하는 방식을 제시한 논문입니다. 저도 VPT를 접하면서 왜 2d로 안하지?라는 생각이 들어서 찾다보니 이 논문이 있어서 가져오게 되었습니다. 다만 해당 논문은 26.03.07. 기준으로 인용수가 39기 때문에 현재 활발히 연구되고 있는 방법론은 아닙니다. 일단 시작해보겠습니다.
Introduction
저자는 pre-trained Vision Model을 adapt(tuning)하는 방법론의 역사에 대해 소개를 먼저 합니다.
PEFT(Parameter-efficient fine-tuning)는 적은 수의 parameter만 학습시켜서 좋은 성능을 내게 해주는 방법론입니다. NLP쪽에서 시작했고 ViT까지 성공적으로 이식되었습니다. 그 다음으로는 위에서 얘기한 VPT(Visual Prompt Tuning)입니다. 저자는 VPT가 “vision prompts are expected to distill the relevant knowledge from the pre-trained model”이라고 얘기하였습니다. 즉, vision prompt를 통해 pretrained의 관련 있는 지식만 쏙 뽑아 올 수 있다고 얘기합니다.
그리고 당연히 이제 VPT의 limitation을 얘기합니다. 크게 2개입니다
- image의 spatial relation을 담지 못한다 (1-dimention이기 때문에)
- 모든 visual prompt가 비슷한 역할만을 한다(unable to conduct individual prompting)
이를 해결하기 위해 SA^{2}VP의 해결책은 아래와 같습니다
- image token map을 2D spatial space로 align시키겠다.
- 이를 통해, spatial한 정보 + individual prompting in a fine-grained manner
- siamese dual-pathway 구조를 통해서, spatially-aligned cross attention operation을 제안
Approach
1. Preliminaries
VPT의 역할에 대해 다시 잡고 들어갑니다. VPT는 downstream task를 위해 relevant한 knowledge를 mining하는게 목적입니다. 단순 Prompt 추가만 하기 때문에 little overhead로 달성합니다.
그리고 이전의 Sequential(1d) visual prompt tuning의 수식을 한번 설명하고 들어갑니다.
ViT를 통과하기 전 image를 patch화 시킨 token들을 \mathbf{E} \in \mathbb{R}^{N \times d}
Visual Prompt(parameterized token embeddings)를 \mathbf{P} \in \mathbb{R}^{p \times d}
pre-trained vision model을 \mathcal{F}_M
이라하면, downstream task를 위한 prediction은 아래와 같습니다.
\mathbf{O} = \mathcal{F}_M([\mathbf{P}, \mathbf{E}]).
Visual Prompt \mathbf{P}가 CLS token처럼 patch tokens들 앞에 붙어서 들어간다고 생각하면 편할 것 같습니다.
여기서 중요한 점은 \mathcal{F}_M은 freeze되어 있고, \mathbf{P}와 downstream head만 learnable합니다.
그리고 저자는 또 다시 이러한 sequential한 1d 방식은 spatial relation을 학습하지 못하고, 모든 prompt가 same role을 한다는 점을 강조합니다.
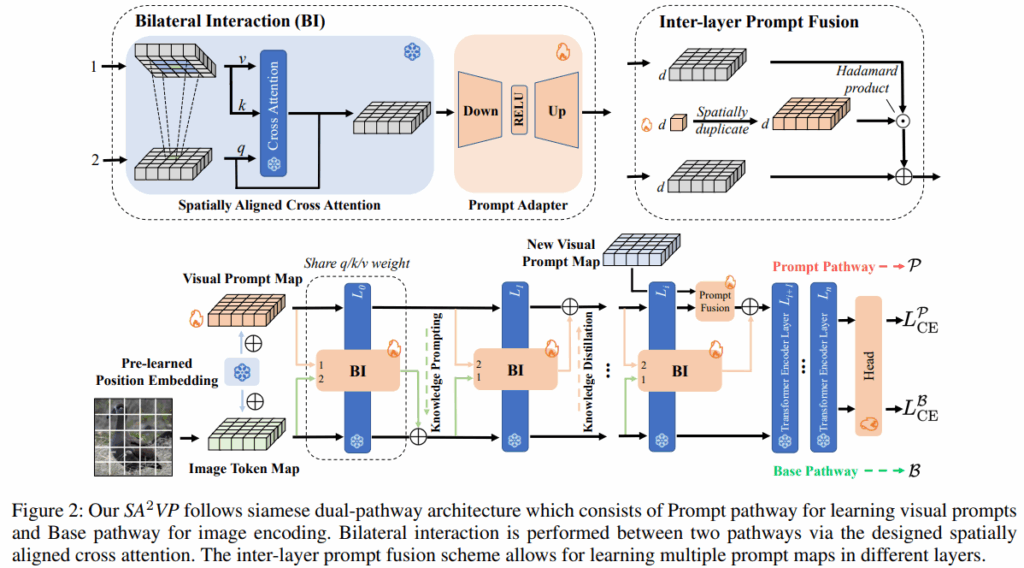
2. Spatially Aligned-and-Adapted Visual Prompt
a. Siamese Dual-Pathway Architecture
저자는 Figure 2. 아래부분과 같이 Siamese network를 설계했습니다.
가중치를 공유하는 두 개의 pathway \mathcal{P}(Prompt) \mathcal{B} (Base)가 있습니다.
Prompt pathway \mathcal{P}는 Base pathway \mathcal{B}로 부터 task와 관련 있는 정보를 distill 받습니다.
b. Spatial-Structure-Preserved Prompt Map
기존에 sequential한게 1d로 prompt를 설계하던 이전과 다르게, SA^{2}VP는 spatially aligned된 2d prompt map을 사용합니다. 2D visual prompt map은, image token map과 같은 크기(or scaled)된 형태입니다. 그리고 2D visual prompt map에도 image token map과 같은 positional embedding을 더해줍니다. 이를 통해 2D visual prompt map이 image token map와 spatially aligned될 수 있습니다.
c. Bilateral Interaction by Spatially-Aligned bidirectional Cross Attention
이 부분은 그래서 siamese network들이 어떻게 정보를 교환하는가에 대한 대목입니다. Figure 2.에 Bilateral interaction(BI) 모듈을 봐주세요. 한번은 Visual prompt map이 query가 되어 Image token map과 cross attention하고, 다음은 Image token map이 Query가 되어 Visual prompt map과 cross attention하는 양방향 interaction입니다. 그리고 독특한 부분이 하나 있는데, Cross attention을 수행할 때 local하게 진행합니다.
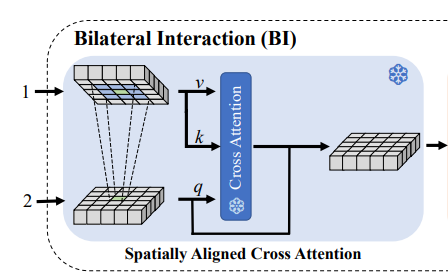
query token은 cross attention할 때, 대응되는 상대 위치에 c \times c 크기의 window하고만 cross attention을 진행합니다. c는 하이퍼파라미터입니다.
d. Prompt Adapter
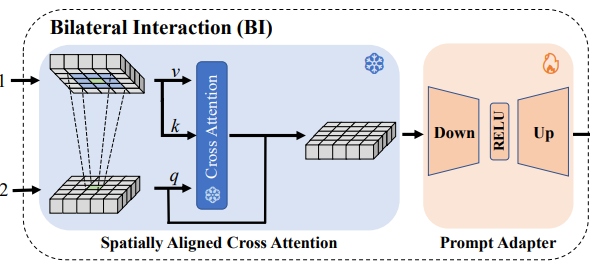
그렇게 BI를 통과한 feature embedding을 learnable Prompt Adapter 뽑아낸 feautre를 downstream task에 맞게 다듬어줍니다.
e. Inter-layer Prompt Fusion
이전 논문인 VPT에서는 shallow-VPT와 deep-VPT라는게 존재했습니다.
shallow-VPT는 처음 한번만 Visual Prompt를 넣어주는 것이고,
deep-VPT는 매 layer마다 Visual Prompt를 새로 넣어주는 방식입니다.
이 논문의 저자는 경험적으로 0, 4, 8 layer에 Visual Prompt Map을 넣는게 성능이 좋다는걸 알아냈습니다.
그러나 다른 layer의 Visual Prompt Map을 그냥 넣어준다면, 성능 드랍이 발생하기에 Inter-layer Prompt Fusion이라는 걸 제안합니다.
예를 들어 0, 4, 8 layer에서 새로 Visual Prompt Map을 구해서 넣어준다고 해봅시다.
그러면 0 layer에서는 문제 없이 진행가능합니다. 그러나 4 layer에서 갑자기 새로 구한 Visual Prompt Map을 그냥 기존 Visual Prompt Map과 더해준다면 Scale도 다른 두개를 너무 naive하게 더해주어 문제가 생깁니다.
그래서 먼저 새로운 Visual Prompt Map의 각 채널에 Scaling Vector \mathbf{e} \in \mathbb{R}^d를 곱해줍니다. 저자는 이때 Hadmard product를 한다고 하는데, 이것은 element-wise Multiplication입니다. 그리고 이 결과를 원래의 Visual Prompt Map과 더해줍니다.
f. Prompt Learning
마지막입니다. loss 부분입니다.
이 저자는 image classification을 pre-training이자 downstream task로 정했습니다(다른 데이터셋)
inference때는 Base pathway만 사용합니다. 그렇기에 Base pathway의 prediction에 Cross Entropy를 적용하여 loss를 흘려줍니다. 하지만, Prompt pathway에도 똑같이 Cross Entropy를 적용하여 loss를 흘려줍니다.
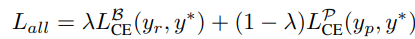
(y_{p}, y_{r}은 각각 Prompt, Base pathway의 prediction, y^{*}는 GT)
Experiments
Datasets
3가지 benchmark에 대해 image classification 실험을 진행했습니다 (FGVC, HTA, VTAB-1k)
이중 VTAB-1k는 독특하게 three groups of task가 있는데,
1. ‘Natural’ object를 일반 카메라로 잡은 이미지
2. 의료장비나 위성사진 같은 ‘Specialized’ 이미지
3. Counting이나 distance perception과 같은 ‘Structed’ 이미지
로 다양한 task가 있습니다.
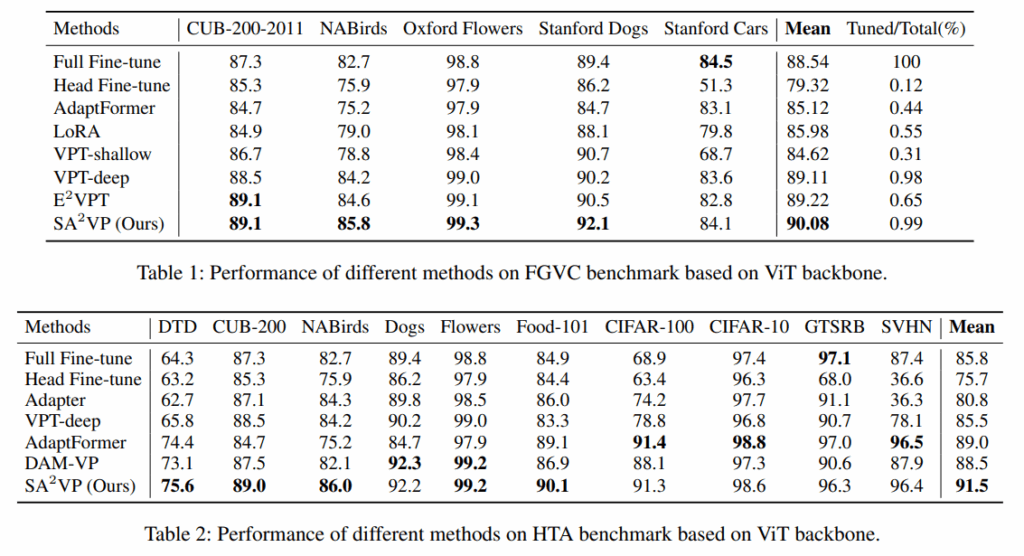
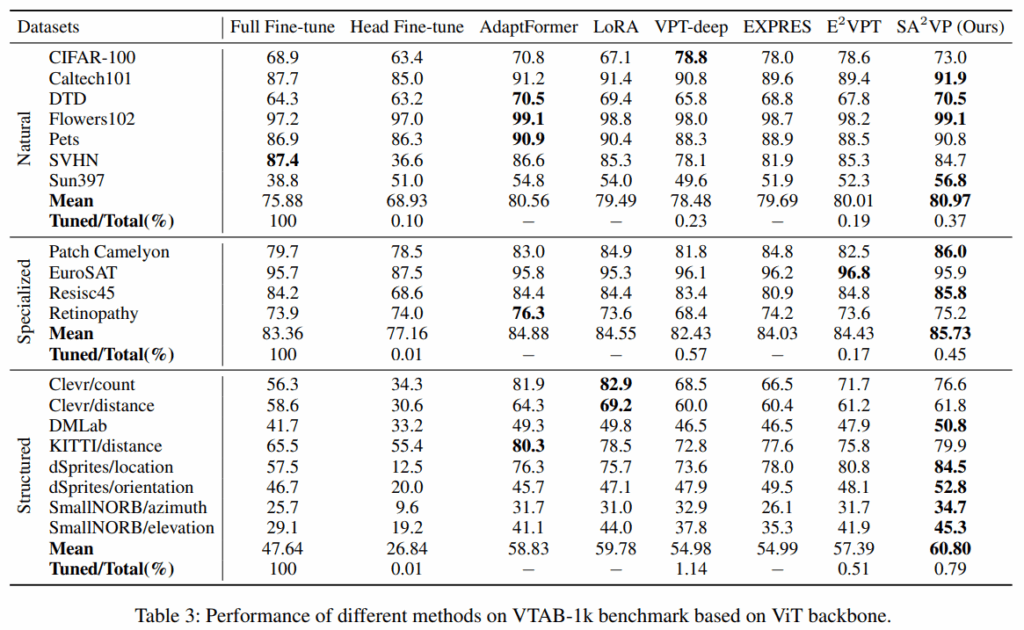
benchmark별로 보면 FVGC와 HTA에서는 대부분 높은 margin으로 기존 방법론을 이기는 것을 볼 수 있습니다.
그리고 VTAB-1k에서도 SOTA를 찍었음을 볼 수 있습니다. 특히 ‘Structured’ group은 다른 두 그룹보다 횔씬 어렵움에도 높은 성능을 보인다는 점에서 저자의 방법론이 강건하다는 점을 확인할 수 있습니다. 특히 sequential(1d)로 VPT를 하는 VPT-deep과의 차이가 큰다는 점에서 structure한 feature를 잘 뽑아낸다고 볼 수 있습니다.
Evaluation with ‘Swin Transformer’ backbone
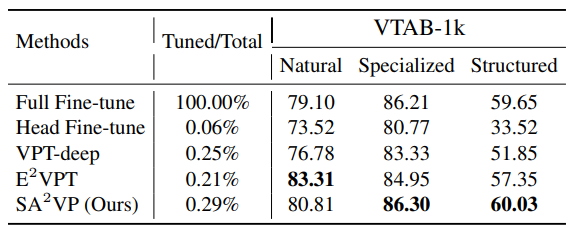
저자는 Swin Transformer를 backbone으로 사용했을 때에 어려운 VTAB-1k ‘structured’ 부문에서 2/3개를 SOTA를 달성했고, 또 VPT-deep(1d VPT)보다 모든 부분에서 좋은 성능을 보이는 것을 큰 장점이라고 주장합니다.
뭔가 전체적으로 논문에서 좋아졌다~라는 글은 많은데 왜 이래서 좋아졌다라는 주장이 조금 부족한 것 같습니다.
Ablation Study
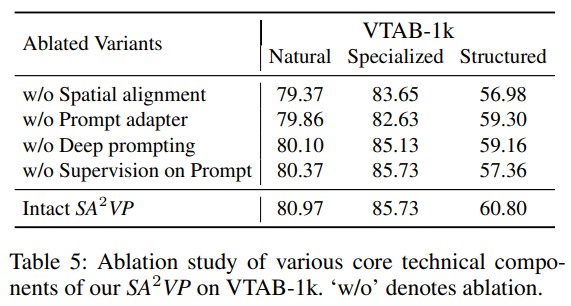
1. Effect of spatially aligned prompting
가장 중요한 ablation이라고 생각합니다. 2d VPT의 필요성을 증명하는 부분입니다.
Spatial alignment를 뺐을 때, Structured 부분에서 많은 성능 드랍이 일어나는 것을 볼 수 있습니다.
확실히 Natural과 같이 structure가 중요하지 않은 부분에서는 성능이 비슷한 점에서 이 방법론의 강점은 기하학적 관계를 파악하는 것임을 확인할 수 있습니다.
2. Effect of Prompt Adapter
저자는 Visual prompt가 pre-trained에서 relevant information을 뽑아내고,
adapter가 pre-trained과 downstream task간의 feature gap을 채워준다고 주장합니다.
그렇기에 adapter의 유무가 성능 차이를 갈랐다고 얘기합니다.
3. Deep prompting mode vs shallow prompting mode
아까 스쳐가듯 얘기했던, 맨 앞에만 Visual prompt를 넣어주기 vs 다양한 layer에서 넣어주기 입니다.
Conclusion
저자는 기존 VPT의 limitation으로 얘기한
1. spatially correspondence가 없던 것을 2D prompt map aligning을 통해 해결했고
2. fine-grained manner(window 기반 cross attention)을 통해, 각 visual prompt를 individual하게 만들어주었습니다.
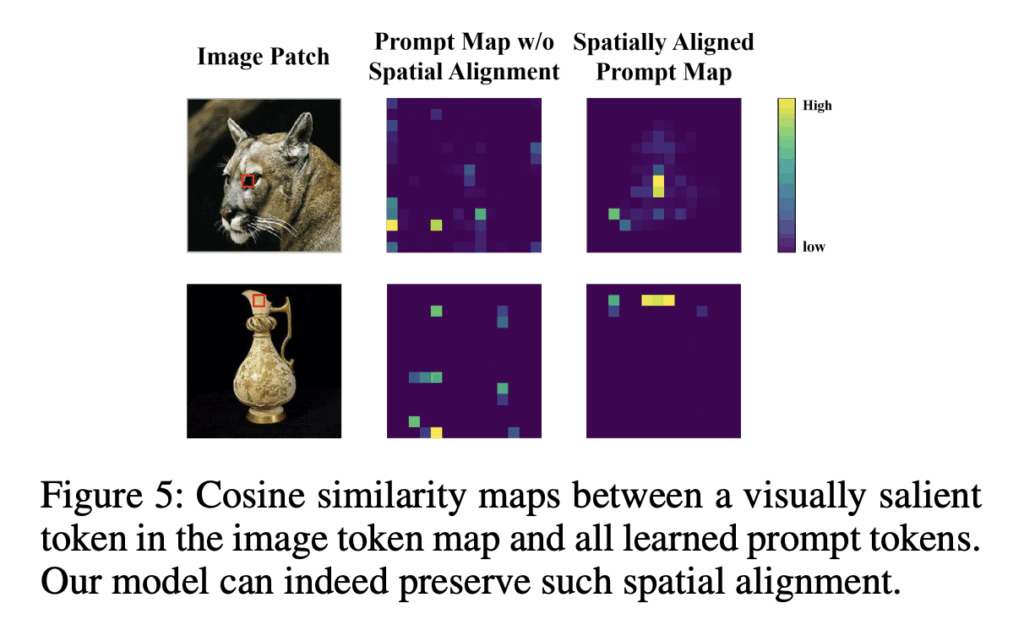
마지막으로 Figure 5.를 통해, cosine similarity를 비교한 부분을 보면, 더 spatial alignment에 집중하는 모습을 볼 수 있습니다.
아래는 benchmark 데이터셋의 일부입니다

안녕하세요 정우님, 좋은 리뷰 감사합니다.
visual prompt tuning 방법론에 대해서 잘 몰랐는데, 2d visual prompt tuning이란 것도 있네요 신기합니다. 방법론의 how to를 중점으로 다뤄주신 것 같은데, 실험과 철학적인 관점에서 좀 궁금한 부분이 있습니다.
1. 우선 실험에서의 평가지표와 평가 태스크가 뭔가요..? 데이터셋 찾아보니 classification인가 해서요
2. 위의 1번 질문이 맞다면 정우님이 intro를 들어가기에 앞서서, 기존 pretrained-ViT encoder가 object-centric하게만 feature embedding을 뽑던 걸, VPT방식을 통해 segmentation task 에 적합하게 feature embedding을 뽑을 수 있다고 하신 게, 실험파트까지 다 읽고 나서도 사실 완벽히 납득은 가지 않았는데요…
실험이 거의 classification 태스크인 것 같은데, segmentation이나 detection 쪽 다운스트림 태스크로 Visual prompt가 실제로 spatial한 정보를 잘 전달하는지 검증하는 실험은 왜 하지 않았을 지 궁금하네요. 그런 다운스트림 태스크에서 실험을 하지 않았다면 다른 정성적인 결과는 없었나요? 예를 들어 local한 영역에 attention이 더 잘 모이더라~ 하는 그런 결과랄까
3. 정우님이 이 2d VPT를 downstream task에 활용하실 생각이 있으신 건가요?
안녕하세요 재찬님 댓글 감사합니다.
1. 일단 위 논문에서의 task는 classification이 맞습니다.
2. 위 방법론은 backbone에 adapting하는 방법론이기 때문에, 모든 downstream task에 사용가능하다고 생각합니다. 다만 저자가 classification에 대해서만 reporting한 이유는 근간이 되는 VPT 논문이 classification에 대해서만 성능 보고를 했고, 또 VTAB-1k(structured)를 통해 논문의 강점인 spatial한 관계를 드러낼 수 있기 때문으로 보입니다.
그리고 정성적 분석이 마지막 figure에 있었는데 제가 생략했습니다. 본문 마지막에 추가했습니다.
3. 현재 VPR task의 SOTA(ImAge)가 1d VPT를 응용한 방법론입니다. 하지만 해당 방법론의 장점이자 단점은 공간적 정보를 다 버린다는 점입니다. 공간적 정보를 버려서 view-agnostic한 feature를 뽑을 수 있는 장점이 있는 반면, 당연히 공간적 정보가 날라간다는 단점이 있습니다. 그래서 이 2d VPT를 통해, 좀 다르게 접근할 수 있지 않을까~ 라는 생각으로 들고 왔습니다.
감사합니다.
안녕하세요 정우님 좋은 리뷰 감사합니다.
단순한 궁금증인데 2D prompt map이 단순히 1D에 비해 prompt capa가 늘어나서 성능이 좋아진건지 아니면 진짜 spatial한 관계를 더 잘 반영해서인지가 궁금해서 답글드립니다! 혹시 논문에서는 prompt 수를 비슷하게 맞춘 1D prompt와의 비교가 있었는지 궁금합니다. 감사합니다.