안녕하세요. 이번 주 X-Review에서 소개해드릴 논문은 24년도 AAAI에 게재된 <Towards Balanced Alignment: Modal-Enhanced Semantic Modeling for Video Moment Retrieval> 입니다. 본 논문은 제가 요즘 관심갖고 리뷰하고있는 Video Moment Retrieval(VMR) task를 수행합니다. 정확하진 않지만 제 기억상으로는 당시 학회 참석했을 때 찾아갔었는데, 중국인 참석자들과 계속 대화하고있거나 나중에 또 가보면 저자가 없어 얘기를 나눠보지 못했었던 것 같네요.

리뷰 바로 시작하겠습니다.
1. Introduction
Video Moment Retrieval(VMR)은 untrimmed video 내에서 사용자가 입력하는 텍스트 쿼리와 의미론적으로 상응하는 구간을 찾아내는 task입니다. 21년도 NeurIPS에 게재된 Moment-DETR이라는 방법론이 QVHighlights 데이터셋을 제안하며 Moment Retrieval(MR)과 Highlight Detection(HD)이라는 task를 하나의 모델로 동시에 수행한 첫 번째 모델이었습니다. 이후 등장한 Moment-DETR의 다양한 후속연구인 DETR 기반 방법론들이 자연스럽게 두 task를 동시에 수행하며 이러한 흐름이 이어지는듯 했지만, 일부 DETR 기반 모델로 MR만을 수행하는 방법론들이 여럿 등장하였습니다. 오늘 리뷰하고자 하는 논문도 HD은 수행하지 않고 MR만 수행하는 논문 중 하나입니다.
우선 본 방법론의 이름을 MESM(Modal-Enhanced Semantic Modeling)이라 칭하겠습니다. 이제 저자가 지적하는 기존 방법론들의 문제점을 살펴보겠습니다.
당연한 이야기일 수 있지만, MR을 잘 수행하기 위해서 모델은 비디오와 텍스트 쿼리 각 모달에 대한 이해뿐만 아니라 이를 바탕으로 두 모달을 잘 align할 수 있어야 합니다. 이건 모두가 알고있기 때문에 기존 방법론들도 두 모달의 feature를 DETR의 Transformer encoder-decoder 구조의 입력으로 주기 전 얼마나 정렬을 잘 맞춰주는지에 집중하고 있는 상황입니다.
당연히 기존 방법론들과 같이 두 모달의 feature를 잘 정렬해주는것이 중요하지만, 저자가 지적하는 문제의 포인트는 바로 두 모달 사이에 존재하는 불균형 문제입니다. 여기서 이야기하는 불균형이란, 한 모달의 데이터의 개수가 다른 모달의 데이터 개수보다 적은 상황을 의미하는 것은 아니고, 의미론적인 불균형을 말하는 것입니다. 일반적으로 충분한 길이를 갖는 비디오에서는 다양한 사건과 배경, 물체 등등이 복합적으로 등장하는데, 이를 설명하는 텍스트 쿼리는 몇 개의 단어로 이루어진 단 하나의 문장이기 때문에 비디오를 모두 설명하기에는 부족하다는 의미입니다.
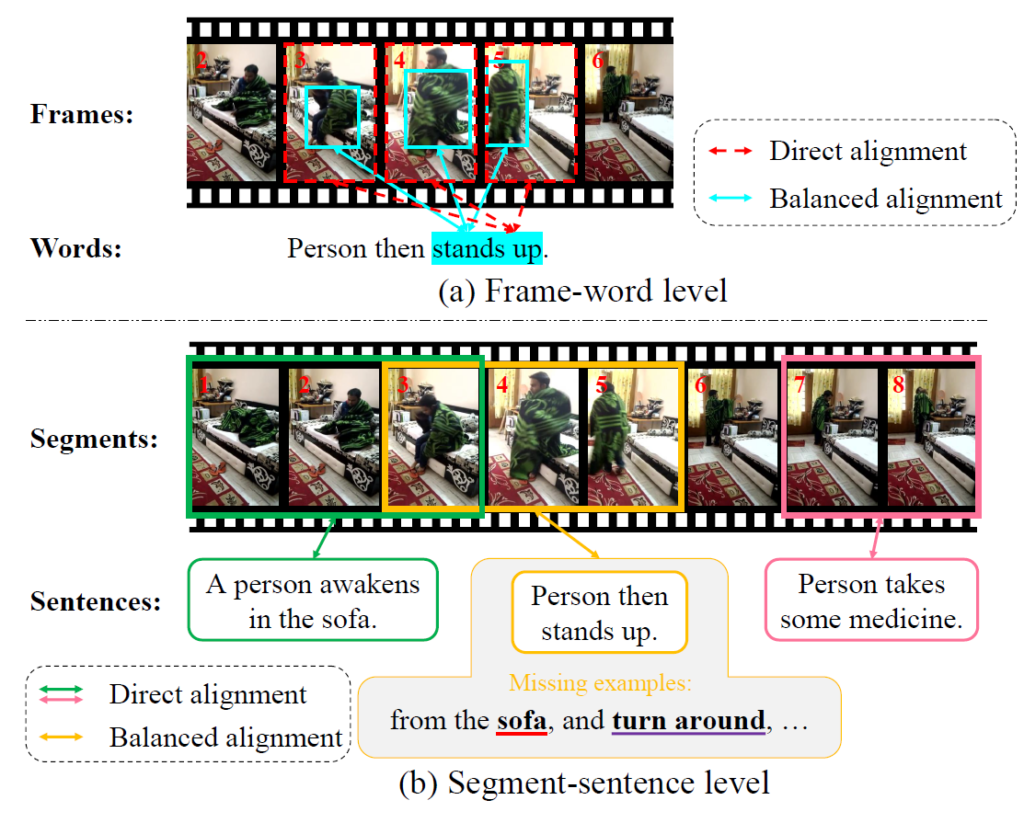
위 그림 1을 통해 저자가 이야기하는 두 모달 간 의미론적 불균형을 살펴볼 수 있는데, 먼저 그림 1은 (a) Frame-word level과 (b) Segment-sentence level로 나뉘어져 있습니다. (a), (b)와 같은 두 level에서 모두 불균형이 존재한다는 것인데요, (a)에서는 쿼리에 존재하는 단어인 ‘stands up’이 이에 상응하는 프레임 전체에서 발생하는게 아니라, 프레임 중에서도 공간 축 일부에서만 ‘stands up’ 동작이 발생하기에 수준이 안맞는다는 의미입니다. 하나의 프레임 내부에서도 단어와 일치하는 부분이 있고, 무관한 부분이 존재하기에 이를 고려하지 않고 모두 align 하는 것은 sub-optimal하다는 것이죠. 그래서 저자는 붉은 화살표 대신 형광 파란색 화살표와 같이 local하게 균형을 맞춰준 후 align을 진행하는 방법을 제안합니다.
다음으로 아래의 (b)에서는 Segment-sentence level에서의 불균형을 의미합니다. 총 3개의 구간 각각에 대한 쿼리가 붙어있는 상황입니다. 노란색 구간을 설명하는 텍스트 쿼리는 ‘Person then stands up’이지만, 실제 구간을 살펴보면 알 수 있는 조금 더 세밀한 정보인 ‘from the sofa’는 텍스트 쿼리에서 설명하고있지 않습니다. 또한, 노란색 구간 중 마지막인 5번 프레임에서는 앞선 동작에 이어 ‘turn around’ 동작이 발생하고 있는데 이러한 동작도 기존 텍스트 쿼리에서는 아예 배제되어있는 상황입니다. 위와 같은 문제뿐만 아니라 annotator의 주관성에 의한 여러 문제도 존재하는데, 이렇게 불균형적인 문제점들을 총체적으로 고려해주지 않고 바로 align하는 것은 최적의 표현력을 만들어내기 어렵다고 이야기합니다. 사실 말이 모달리티간 의미론적 불균형이지, 넓게 봤을 땐 다른 논문들과 동일하게 DETR의 encoder를 태우기 전 여러 모듈을 거쳐 feature-enhancement를 수행하는 방법론 중 하나라고 생각하시면 좋을 것 같습니다.
저자는 위 문제를 해결하기 위해 3개 모듈로 구성된 방법론 MESM을 제안합니다. 첫 번째는 Frame-word level MESM, 두 번째는 Segment-sentence level MESM, 마지막은 Modality Aligner입니다.
먼저 첫 번째 문제인 Frame-word level의 불균형을 해결하기 위해, 비디오 feature를 enhance 해줍니다. 여기서 enhance 해준다는 것을 조금 더 구체적으로 설명하자면, 비디오에서 텍스트 쿼리와 관련 없는 부분의 영향력은 줄이고, 유관한 부분의 표현력을 살려 비디오의 redundancy를 최소화하는게 목표라는 것입니다. 이를 위해 Cross-attention layer를 활용하는데, 가중치를 공유하는 layer를 하나 두고 한 번은 (비디오, 텍스트, 텍스트)를 입력으로 주는 cross-attention 수행, 한 번은 텍스트의 일부를 가린 뒤 (일부 가려진 텍스트, 비디오, 비디오)를 입력으로 주고 cross-attention을 수행하여 가려진 단어를 맞추는 Masked Language Modeling(MLM)을 진행합니다. 대략적인 컨셉은 이렇고, 자세한 구조와 효과는 방법론에서 다시 알아보겠습니다.
다음으로 Segment-sentence level의 불균형을 해결하기 위해 주어진 텍스트 쿼리의 complementary token을 활용하여 feature를 enhance 해줍니다. 앞선 그림 1-(b)에서 지적한 부분이, 주요 객체나 상황이 비디오 구간 내에는 존재하지만 텍스트 쿼리에는 표현되어있지 않다는 점이었습니다. 저자는 이 문제를 다루고자 주변 비디오 구간과 텍스트 쿼리들을 참고하여 쿼리를 재작성하는 방식을 제안합니다. 물론 feature-level에서 재작성하는 것이고 이 과정에서 complementary token 개념을 활용하게 됩니다. Complementary token은 다른 논문에서 사용됐던 용어는 아니고, 저자가 이 모듈을 구상하면서 붙인 이름이라고 생각하시면 됩니다. 아무래도 기존의 텍스트 쿼리의 부족함을 보완하거나 대체한다는 의미에서 complement라는 단어를 선택한 것이라고 생각됩니다.
마지막으로 Modality Aligner라고 해서 추가적인 모듈을 제안하는 줄 알았는데, 논문을 읽어보니 그냥 불균형이 해결된 두 모달의 feature를 받아 cross-attention을 수행해주는 것이었습니다.
여기까지의 설명이 길었는데 이를 요약하자면 MR을 수행하기 위해 먼저 alignment를 필수적으로 진행해야 하는데, 이 때 두 모달 간 의미론적 불균형이 존재하는 상황이니 제안하는 모듈을 통해 불균형을 먼저 해소한 뒤 align을 수행하자는 것이 저자의 아이디어 인 것입니다.
이제 본 논문의 contribution을 정리한 뒤 방법론으로 넘어가보도록 하겠습니다.
Contribution
- We are the first to analyze the modality imbalance problem in MR from both the frame-word and segment-sentence levels.
- To alleviate the modality imbalance problem, we propose a novel framework MESM to model the enhanced semantic information from two levels, balancing the alignment to bridge the modality gap.
- Extensive experimental results demonstrate the effectiveness of the proposed method.
2. Proposed Method
2.1 Overview
먼저 notation과 전반적인 파이프라인을 설명드린 뒤 자세한 모듈별 소개로 넘어가겠습니다.
Problem Formulation.
N_{v}개의 프레임으로 이루어진 비디오 V=\{f_{i}\}_{i=1}^{N_{v}}와 N_{w}개의 단어로 구성된 텍스트 쿼리 Q^{\dagger{}} = \{w_{i}^{\dagger{}}\}_{i=1}^{N_{w}}가 쌍으로 주어집니다. 이렇게 쌍이 주어졌을 때 MR의 목표는 가장 적합한 상응 구간 \hat{m} = (\hat{t_{s}}, \hat{t_{e}})를 찾는 것입니다. 이때 \hat{t_{s}}, \hat{t_{e}}는 각각 구간의 시작점과 끝점을 의미합니다.
Pipeline.
아래 그림 2는 저자가 제안하는 방법론 MESM의 전반적인 pipeline을 나타내고 있습니다.
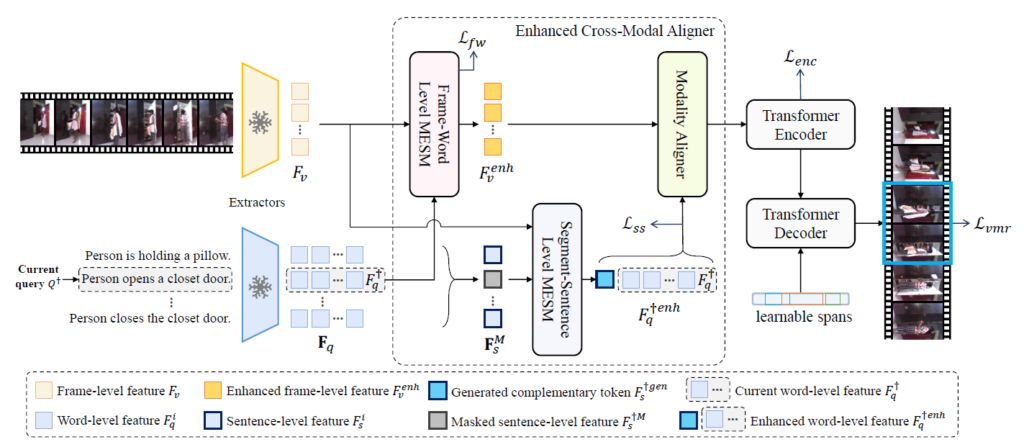
큰 흐름을 먼저 살펴보시면, 그림 왼쪽에서 비디오와 텍스트의 feature를 추출한 후부터 오른쪽에 위치한 Transformer encoder-decoder 구조에 태우기 전까지 여러 submodule들을 거치는 것을 알 수 있습니다. 이 3개의 submodule들은 ECMA (Enhanced Cross-Modal Aligner)라는 하나의 모듈로 엮어서 불리며 세부적으로는 분홍색의 Frame-Word Level MESM, 파란색의 Segment-Sentence Level MESM, 연두색의 Modality Aligner로 구성됩니다. 다시 되짚고 넘어가자면 중간에 위치한 ECMA의 역할은 Transformer encoder-decoder 구조에서 alignment를 수행하기 전 두 모달 간 의미론적 불균형을 해소하는 것이었습니다.
이제 한 단계씩 방법론을 설명드리겠습니다.
2.2 Feature Extractors
데이터셋마다 비디오, 텍스트의 feature를 추출할 backbone network가 달라집니다. 이는 학계의 기존 룰을 따르기 위한 것으로 비디오는 SlowFast+CLIP 또는 VGG, C3D 등의 백본을 활용합니다. 텍스트는 CLIP, GloVe 등을 사용합니다. 이렇게 서로 다른 네트워크에서 뽑은 feature들은 차원이 다르기 때문에 각 모달만의 MLP를 태워 동일한 D차원으로 맞춰주게 됩니다.
하나의 비디오를 V라고 하면, V 내 구간들에 상응하는 K개의 텍스트 쿼리들은 Q=\{Q^{i}|i=1, \cdots{}, K\}로 표현합니다. V의 feature는 F_{v} \in{} \mathbb{R}^{L_{v} \times{} D}로 표현할 수 있고, 텍스트 쿼리 Q의 feature는 F_{q} = \{F_{q}^{i} \in{} \mathbb{R}^{L_{w} \times{} D}|i=1, \cdots{}, K\}와 같이 표현할 수 있습니다. L_{v}, L_{w}는 각 모달리티의 feature 길이입니다.
총 K개의 텍스트 쿼리 중 현재 찾고자하는 구간의 텍스트 쿼리를 Q^{\dagger{}}로 표시합니다. 이에 따라 F_{v}–F_{q}^{\dagger{}}는 feature-level에서의 현재 구간을 찾고자하는 한 쌍에 대한 notation이라고 볼 수 있습니다.
2.3 Enhanced Cross-Modal Aligner
3개의 submodule로 구성되는 모듈 ECMA에 대한 절입니다. 앞서 말씀드린 3개의 submodule들은 이제부터 FW-MESM (Frame-Word level MESM), SS-MESM (Segment-Sentence level MESM), MA (Modality Aligner)라고 줄여서 칭하겠습니다.
FW-MESM (Frame-Word Level MESM).
FW-MESM의 목적은 비디오 모달의 표현력을 개선하는 것이며 이를 위해 현재 보고있는 텍스트 쿼리와 관련 있는 부분은 강조하고, 무관하거나 redundant한 부분은 suppress 하는 역할을 수행합니다. 이를 위해 저자는 cross-attention layer를 활용합니다. 하지만 단순하게 비디오와 텍스트의 cross-attention을 수행한다고해서 이러한 효과를 기대하긴 어렵겠죠. 그래서 하나의 cross-attention layer로 Masked Language Modeling (MLM) task까지 한 번에 수행하여 프레임에 대한 fine-grained level의 구별력을 갖추도록 유도해줍니다. 마스킹된 단어를 cross-attention layer가 직접 reconstruction하며 프레임의 세부 레벨에서 해당 단어의 역할이나 의미를 알아서 깨우치게 될 것이고, 이렇게 학습한 layer의 가중치 그대로 비디오 feature를 추출해주는 것이죠.
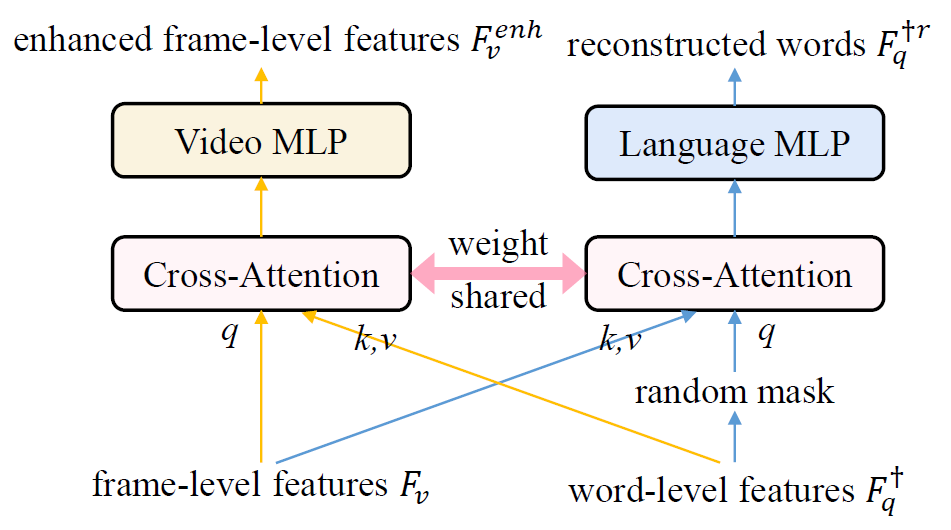
말로만 설명하면 어려우니 그림과 수식을 통해 알아보겠습니다. 위 그림 3은 FW-MESM의 구조도입니다.
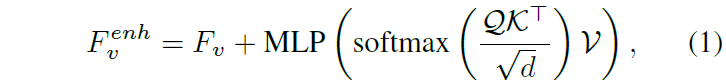
최종적으로는 cross-attention을 위 수식 (1)과 같이 수행하여 enhanced video feature F_{v}^{enh}를 얻는 것이 목적이며, 이 때 cross-attention 입력으로 들어가는 값들 각각은 아래와 같이 만들어줍니다.
- \mathcal{Q} = W^{q}F_{v}
- \mathcal{K} = W^{k}F_{q}^{\dagger{}}
- \mathcal{V} = W^{v}F_{q}^{\dagger{}}
방금 설명드린 cross-attention 과정은 위 그림 3에서 노란색 화살표 흐름에 해당합니다.
여기서 F_{v}^{enh}의 표현력을 저자의 의도에 맞게 좀 더 증대하고자 MLM task를 보조적으로 도입합니다. 우선 현재 텍스트 쿼리 F_{q}^{\dagger{}}의 단어들을 랜덤으로 1/3 마스킹하여 F_{q}^{\dagger{}m}을 만들어줍니다. 이를 활용해 이번에는 cross-attention의 query 모달리티를 바꿔 아래와 같이 입력을 만들어줍니다.
- \mathcal{Q}^{*} = W^{q}F_{q}^{\dagger{}m}
- \mathcal{K}^{*} = W^{k}F_{v}
- \mathcal{V}^{*} = W^{v}F_{v}
이후 이 입력들을 수식 (1)과 똑같이 앞서와 동일한 cross-attention layer에 주어 얻은 출력은, 비디오의 프레임 정보를 기반으로 reconstruct된 텍스트 쿼리 feature라 볼 수 있습니다. 이를 F_{q}^{\dagger{}r} \in{} \mathbb{R}^{L_{w} \times{} D}로 표현합니다. 이 과정은 위 그림 3에서 파란색 화살표 흐름에 해당합니다.
이후엔 \mathbb{R}^{L_{w} \times{} D} shape의 feature를 MLP에 태워 차원을 vocabulary size N_{\text{vocab}}으로 변경해준 뒤 해당 축으로 softmax를 취해 reconstruct된 단어가 실제 어떤 단어로 mapping 되는지에 대한 확률 분포 P(F_{q}^{\dagger{}r}) \in{} \mathbb{R}^{L_{w} \times{} N_{\text{vocab}}}을 얻을 수 있습니다.
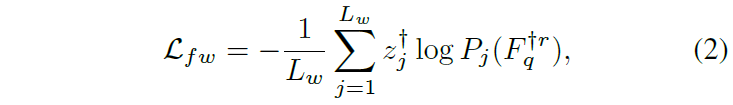
마스킹 하기 전의 온전한 문장을 저희가 알고있으니 이를 라벨 z_{j}^{\dagger{}}로 두고 CE loss를 계산할 수 있습니다. 이는 위 수식 (2)의 \mathcal{L}_{fw}와 같습니다.
Enhanced video feature F_{v}^{enh}를 얻는 layer와 MLM을 수행하는 layer가 동일하기 때문에 이론적으로 F_{v}^{enh}는 문장 내 단어들의 의미와 역할을 인지하고 이에 따라 프레임의 중요도를 측정하여 추출된 feature라고 볼 수 있습니다.
SS-MESM (Segment-Sentence Level MESM).
앞서 FW-MESM에서 비디오 feature를 enhance해주었다면 본 항에서 소개하는 SS-MESM은 텍스트 쿼리 feature의 표현력을 향상시키는 모듈입니다.
한 비디오에 대한 텍스트 쿼리의 feature F_{q}는 K개의 텍스트 쿼리들로 구성되어 있습니다. 여기선 Sentence 단위의 표현력을 다루기 때문에 K개의 문장 각각을 단어축으로 단순히 평균내어 D차원의 sentence-level feature F_{s}^{i} = \frac{1}{L_{w}}\Sigma{}_{j=1}^{L_{w}}(F_{q}^{i})_{j}를 얻습니다.
이후 K개의 문장 중 현재 찾아야하는 구간의 텍스트 쿼리 문장 feature는 F_{s}^{\dagger{}}라 칭할 수 있고, 이를 D차원의 learnable token F_{s}^{\dagger{}M}으로 대체하여 지워버립니다. 현재 문장 F_{s}^{\dagger{}}를 F_{s}^{\dagger{}M}로 대체하면 전체 문장의 집합 F_{s}^{M} = \{F_{s}^{1}, \cdots{}, F_{s}^{\dagger{}M}, \cdots{}, F_{s}^{K}\} \in{} \mathbb{R}^{K \times{} D}로 표현할 수 있습니다.
이후에는 F_{s}^{M}을 query, F_{v}를 key, value로 두고 cross-attention을 수행합니다. 앞선 MLM 전략의 문장 level 버전이라고 생각해주시면 되는데, 저희가 리뷰 초반 정의했던 “라벨링되어있는 텍스트 쿼리는 비디오 구간을 전부 담기에 부족하다”는 단점을 보완하고자 비디오와 비디오 내 텍스트 쿼리들을 참고하여 feature-level에서 현재 쿼리를 재작성하는 과정이라고 볼 수 있습니다.
이렇게 재작성 또는 재생성된 쿼리는 다음과 같이 표현할 수 있습니다.
- F_{s}^{gen} = \{F_{s}^{1gen}, \cdots{}, F_{s}^{\dagger{}gen}, \cdots{}, F_{s}^{Kgen}\} \in{} \mathbb{R}^{K \times{} D}
재생성된 현재 쿼리F_{s}^{\dagger{}gen}은 기존 텍스트 쿼리 정보를 보완한다는 의미에서 complementary token이라고도 이야기하고 있습니다. 하지만 기존 텍스트 쿼리의 정보를 모두 버리고 비디오 feature와 다른 텍스트 쿼리만을 활용해 재생성하기엔 부족함이 있습니다. 그래서 재생성된 텍스트 쿼리와 기존 텍스트 쿼리를 concat하여 enhanced word-level feature F_{q}^{\dagger{}enh} = [F_{s}^{\dagger{}gen}, F_{q}^{\dagger{}}] \in{} \mathbb{R}^{(L_{w}+1) \times{} D}를 만들어주고, 이를 좀 더 명시적으로 모델링해주고자 비디오 내 GT 구간과 contrastive learning 하는 데에 사용합니다.
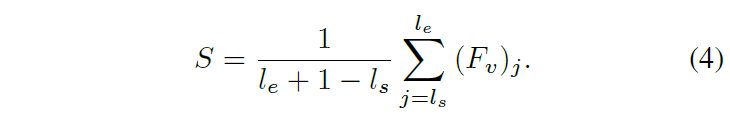
우선 supervision을 줄 정답 구간의 segment-level feature S \in{} \mathbb{R}^{D}는 위 수식 (4)와 같이 구간의 모든 frame-level feature를 평균내어 정의됩니다. 이를 활용해 F_{q}^{\dagger{}enh}가 좀 더 실제 GT구간에 부합할 수 있도록 학습합니다.
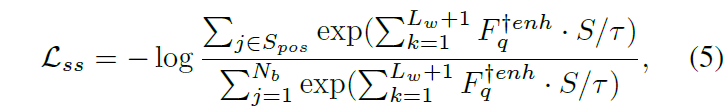
이 학습은 위 수식 (5)의 \mathcal{L}_{ss}를 통해 이루어지며 기본적으로 앞서 뽑은 F_{q}^{\dagger{}enh}와 S_{pos} 간 유사도는 크게, pos가 아닌 다른 샘플들과의 유사도는 작아지도록 학습합니다. 여기서 N_{b}는 배치사이즈이며 S_{pos}는 비디오 내 라벨링 되어있는 구간들 중 현재 보고있는 구간과의 IoU가 0.9 이상인 구간들을 모아둔 집합에 해당합니다. 비디오 내 인접 구간은 의미론적으로 동일하다는 가정 아래에 S_{pos}를 구축하는 것입니다.
위와 같이 cross-attention 및 contrastive learning을 통해 비디오와 다른 텍스트 쿼리들을 고려하여 재작성된 텍스트 쿼리 F_{q}^{\dagger{}enh}를 얻을 수 있었습니다.
MA (Modality Aligner).
FW-MESM에서 표현력이 향상된 video feature F_{v}^{enh}와 SS-MESM에서 표현력이 향상된 text feature F_{q}^{\dagger{}enh}를 획득하였다면 MA에서는 F_{v}^{enh}를 query, F_{q}^{\dagger{}enh}를 key, value로 두고 cross-attention을 한 번 수행함으로써 interaction과 alignment를 일부 진행하여 최종적으로 balance가 맞춰진 feature F \in{} \mathbb{R}^{L_{v} \times{} D}를 얻을 수 있습니다.
2.4 Transformer Encoder-Decoder
MA까지 거쳐 얻은 feature F는 Encoder에 입력되어 self-attention을 거쳐 F_{enc}를 출력합니다. Moment-DETR과 같이 MR과 HD를 같이 하던 연구들은 F_{enc} 값을 이용해 HD을 수행했었는데요, 저자는 HD을 수행하진 않지만 가지고 있는 temporal annotation을 활용해 학습 loss를 하나 붙여줍니다. 이는 아래 수식 (6)과 같습니다.
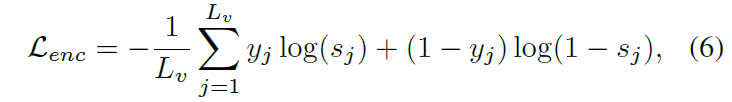
F_{enc}를 MLP에 태워 s \in{} \mathbb{R}^{L_{v}}로 만들어주고 이를 비디오 프레임별 구간 상응 score로 볼 수 있기에 실제 GT 라벨 y_{j}와 BCE loss를 학습하는 \mathcal{L}_{enc}를 붙여줍니다.
이후에는 기존 연구인 QD-DETR과 동일하게 Decoder에 moment token과 F_{enc}를 입력으로 주고 cross-attention을 수행해 최종 예측 구간을 만들어냅니다. 이렇게 생성한 구간에 대한 MR loss는 아래 수식 (7)과 같으며, 최종적으로 학습에 사용하는 전체 loss는 아래 수식 (8)과 같습니다. 수식 (7)의 loss는 기존 연구와 동일하게 사용되었기 때문에 설명하지 않도록 하겠습니다.
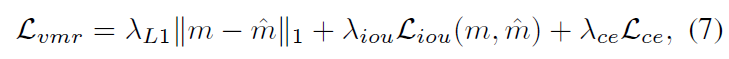
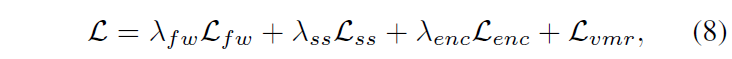
이제 실험 결과들을 살펴보러 넘어가겠습니다.
3. Experiments
3.1 Experimental Settings
MESM에 대한 벤치마크는 Charades-STA, TACoS, QVHighlights, Charades-CG 데이터셋에 대해 진행되었습니다. Charades-CG는 기존 Charades-STA에 존재하는 분포 편향을 해소하며 제안된 기존의 데이터셋입니다. 이에 대해 높은 성능을 보이는 경우 다른 모델들보다 일반성이 높다고 볼 수 있습니다.
평가지표는 기존 연구들과 동일하게 Recall1@\mu{}, mAP@\mu{}, mIoU, \text{mAP}_{avg}를 측정합니다. 여기서 \mu{}는 positive sample이라 간주할 IoU의 threshold이며, \text{mAP}_{avg}는 IoU 구간 [0.5:0.05:0.95]에서의 평균 mAP입니다.
각 데이터셋에 대해 사용한 feature는 실험 표 부분에서 말씀드리겠습니다.
방법론 전체적으로 cross-attention이 너무 많아 연산량에 대해 살펴볼 필요가 있었는데, 정량적인 연산량을 리포팅하고 있진 않지만 layer는 2개, 차원은 256이라고 하여 나름 작은 모델을 선택한 것으로 보입니다.
3.2 Performance Comparisons
Charades-STA & TACoS
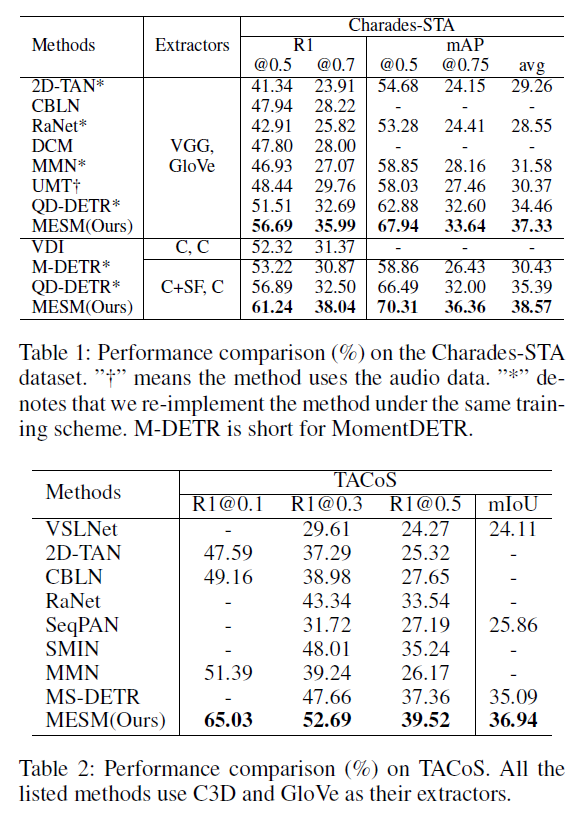
표 1, 2는 각각 Charades-STA, TACoS 데이터셋 에 대한 벤치마크 성능입니다. Extractor 열은 사용한 feature 백본 네트워크를 의미하며 C는 CLIP, SF는 비디오 백본 SlowFast를 의미합니다. 먼저 Charades-STA 데이터셋에 대해서, 높은 0.7 IoU에서 구조가 비슷한 방법론인 QD-DETR보다 5.5% 이상 향상된 것이 굉장히 인상깊습니다. 물론 QD-DETR은 MR과 HD를 동시에 수행하는 Multi-task 방법론이기 때문에 이에 적합한 QVHighlights에서 높은 성능을 보여주고 있긴 합니다. 그래도 성능 향상 폭이 엄청 크네요.
일반적으로 각 모달별로 추출한 VGG, GloVe feature보단 두 모달 간 align이 맞춰진 CLIP feature를 쓰는 것이 높은 성능을 보여주긴 하지만, CLIP을 쓴 QD-DETR보다도 MESM의 성능이 높은 것으로 보아 확실히 모달 간 balance를 맞춰주는 것이 유효했다는 것을 알 수 있습니다. 표 2의 TACoS 데이터셋에 대해서도 높은 성능을 보여주고 있습니다.
QVHighlights
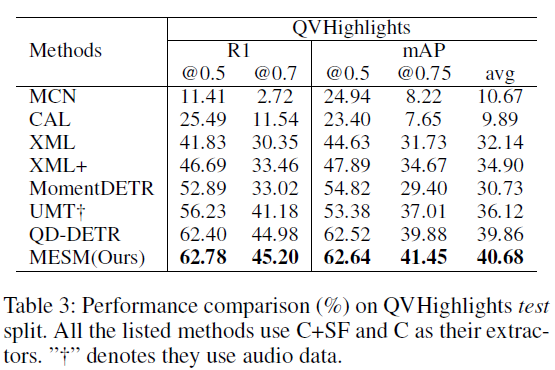
위 표 3은 QVHighlights 데이터셋에서의 MR 성능입니다. 앞서 언급한대로 Charades-STA 등등의 데이터셋에서보다 성능 향상 폭이 굉장히 적긴 합니다. 앞서긴 하지만 둘의 성능이 거의 유사하다고 볼 수 있고, 방법론 상으로 그만한 이유가 있긴 합니다. SS-MESM은 한 비디오 내 존재하는 여러 텍스트 쿼리간 관계를 활용해 complementary token을 구축하는데, QVHighlights는 비디오 하나당 어노테이션 되어있는 텍스트 쿼리가 1개라 다른 텍스트 쿼리들과의 관계를 고려할 수 없게된다는 단점이 존재합니다. 그런 이유에서인지 다른 데이터셋에 비해 MESM의 성능 향상 폭이 적은 상황입니다.
Charades-CG
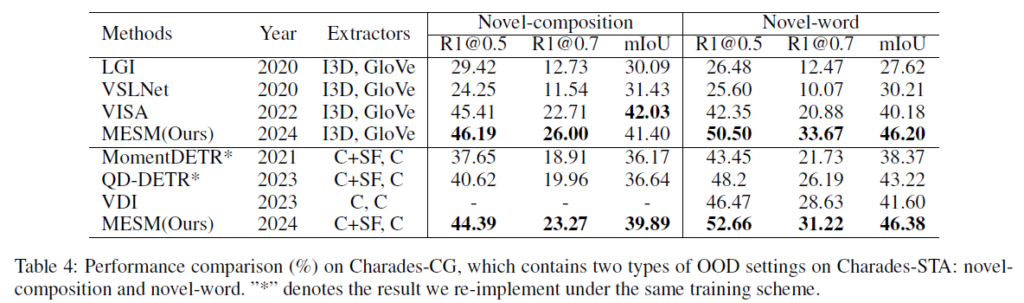
표 4는 Charades-CG 데이터셋에 대한 벤치마크 표입니다. 앞서 말씀드린 대로 Charades-CG는 일반화 성능을 측정하기 좋은 데이터셋인데, 열에 나타나있는 Novel-composition은 문장 내 포함되어있는 composition, 즉 명사-동사, 동사-부사, 명사-명사 등의 구성을 새롭게 구축한 split이고, Novel-word는 학습 때 보지 못한 의미가 유사한 새로운 단어들을 테스트 때 보여주며 잘 대응하는지 평가하는 split입니다. 아래 그림을 참고하시면 좋을 것 같습니다.

다시 성능을 보면 표 3에서 살펴본 QVHighlights에서보다 QD-DETR과 성능 격차가 더 많이 벌어진 것을 볼 수 있습니다. 아무래도 FW-MESM에서 masking된 문장을 복원하는 과정에서 CLIP의 knowledge를 빌려 새로운 단어나 composition에 대해서도 강인하게 동작할 수 있도록 학습을 했기 때문에 이와 같은 결과가 나왔다는 생각이 듭니다.
3.3 Ablation Study
Main Ablation.
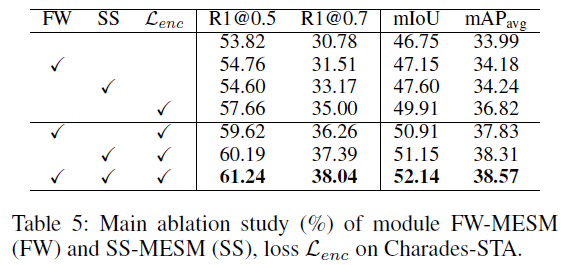
표 5는 메인 ablation study로 모듈 별 ablation 성능입니다. 가장 높은 성능 향상을 보여주는 단일 모듈은 /mathcal{L}_{enc}인데요, 저자들만의 novel한 아이디어는 아니고 HD을 같이 수행하는 논문들은 기본적으로 학습하는 loss에 해당합니다. 제안하는 모듈보다 기존에 사용되던 loss가 더 큰 성능 향상폭을 보여주고 있네요. 다만 해당 loss와 함께 학습하는 경우 FW-MESM과 SS-MESM이 시너지를 보이며 성능이 많이 올라가는 것을 알 수 있습니다.
The Weight-Shared MLM.
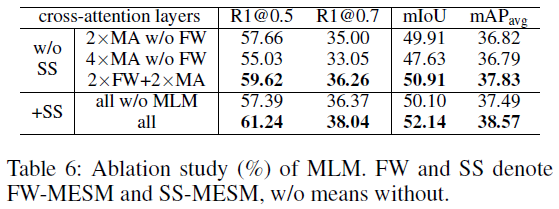
방법론 내의 FW-MESM과 SS-MESM, MA는 모두 cross-attention layer로 구성됩니다. 표 6은 모듈의 layer에 대한 ablation을 보여주고 있습니다. 표의 첫 행은 FW, SS를 모두 활용하지 않고 2개 layer로 구성된 MA만 적용했을 때의 베이스라인 성능입니다. 1행과 2행을 비교해보니 효율성 때문에 layer 개수를 줄인 것은 아니고, 성능 차이가 있었던 것으로 보이네요. 결국에는 3행의 성능인 2개 layer로 구성된 FW를 MA와 함께 써주는 것이 SS-MESM이 없을 때에는 가장 높은 성능을 달성하고 있습니다.
이후 MLM 없이 SS-MESM만 추가했을 때 성능이 떨어지게 됩니다. 저자가 이 이유를 분석하고 있지는 않지만, MLM을 적용해줌으로써 확실히 단어에 대한 고려가 된 비디오 feature가 생성되고 있다는 것은 알 수 있습니다.
이상으로 리뷰 마치겠습니다.
좋은 리뷰 감사합니다.
Intro 에서 각 요소별 문제정의, 그리고 method 에서 이어지는 각 요소별 해결책들이 매핑이 잘 되어서 이해가 수월했습니다.
FW-MESM 관련 질문이 조금 있습니다.
1. FW-MESM 의 도입 이유에 대해 제가 이해한 바로는 ‘프레임 중에서도 공간 축 일부에서만 ‘stands up’ 동작이 발생’ 하기 때문에, 즉 다시 말하면 특정 하나의 프레임 내의 HxW 전체에 대해 모든 영역이 stands up 을 나타내는 것이 아니라 일부 공간 (ex. 50×100) 에 대해서만 stands up 을 나타내므로 뭔가 balance를 위한 후처리를 설계해야한다.. 인데 맞나요 ??
2. 그게 맞다면 HxW 의 전체 공간 중 ‘stands up’을 의미하는 부분에는 높은 가중치를, 그렇지 않은 부분에 대해서는 낮은 가중치를 부여해야 하는건데 이를 위해 MLM기법을 도입한 듯 합니다. FW-MESM의 전체 동작과정에 대해서는 알겠는데, 음 우선… Frame level feature F_v와 word level feature F_q 를 동일 cross-attention layer에 태워도 되나요? 뭔가 사전 과정에서 F_v와 F_q 를 동일한 space로 보내는(?) 무엇인가가 없는 거 같은데..
(아 마지막에 보니 clip 워딩이 등장하네요. clip image/text encoder를 사용한 것이라 동일 space 겠네요? ㅎ)
3. 음 그렇다면, ‘stands up’ 이라는 동사를 masking 해서 reconstruction 하는 것이 좀 더 이와 관련된 정보를 강화하고 attention 을 부여하는 관점에 있어서 더 좋은 효과를 보일 거 같다는 직관적인 생각이 드는데, 본 논문에선 1/3 비율로 random masking 을 수행하네요? 이에 대한 저자의 코멘트나 추가 언급은 있나요? 아니면 보통 masking은 랜덤으로 수행하니,,. 그냥 별 말이 없었나요?
감사합니다!
안녕하세요. 좋은 질문 감사합니다.
1. 우선 FW-MESM과 관련해서 저자가 Introduction에서 한 이야기는 말씀해주신 내용이 맞습니다. 이를 해결하기 위해서 FW-MESM이 한 프레임 내 부분적인 영역만을 명시적으로 다뤄주는 역할을 하진 않습니다. 하지만 Masked Language Modeling을 통해 단어 간 구별력을 갖춘 cross-attention layer로 비디오 feature를 enhance함으로써 프레임 단위로, 즉 텍스트 쿼리 기준으로 프레임 간 중요도를 학습하여 그러한 역할을 간접적으로 대신한다고 볼 수 있습니다. 기존 연구는 단순히 cross-attention만을 수행하여 텍스트를 고려한 비디오 feature를 만들고 있었다면, MLM을 통해 어느정도 가이드를 준 것이 contribution이라고 생각합니다.
2. 리뷰에 담진 않았지만 그 부분에 대해서도 저자가 Related work에서 밝히고 있었습니다. 서로 다른 모달의 feature를 하나의 모델로 다룰 수 있는지에 대해서였는데, 기존 연구들이 Self-attention에 대해서는 cross-modality를 입력받아도 잘 다룰 수 있다는 것을 입증했다고 하고, 본 연구에서는 이를 cross-attention으로 연장했다고 이야기하고 있습니다. 결론적인 이야기지만 성능을 보았을 때 잘 동작하는 것으로 보이네요.
3. 본 논문에서는 별 이야기 없이 문장의 1/3을 랜덤으로 마스킹하고 reconstruction에 사용합니다. 말씀해주신 내용에 대해 저도 이전에 궁금하였었는데, 그 당시 읽게된 논문에 따르면 동사나 명사와 같이 사람 입장에서 중요한 부분만을 마스킹했을 때보다 전체를 대상으로 랜덤 마스킹을 하는게 더 성능이 좋다고 하였었습니다. 본 논문에서도 그러한 결과를 참고하여 따라간 것으로 생각됩니다.
감사합니다.
안녕하세요. 김현우연구원님,
좋은 리뷰 감사합니다.
MR 테스크에서 두 모달 사이에 존재하는 불균형을 문제를 해결해야하는 이유와 그 과정에 대해서 명확하게 서술해주셔서 이해하는데 많은 도움이 되었습니다.
(1) SS-MESH에서 sentence 단위의 표현력을 다루기 때문에 K개의 문장 각각을 단어축으로 평균내어 D차원의 sentece-level feature를 얻었다고 하셨는데, 해당 부분이 잘 이해가 가지 않습니다. K구간의 영상에 대한 텍스트쿼리 문장에서 같은 위치에 있는 단어끼리 평균을 취한 것 인가요??
(2) 정말로 개인적인 궁금증입니다만, 그림1-(b)의 3번 Frame이 초록색 박스 segment와 노란색 박스 segment에 공통되게 들어가서 모델링이 되는데, 이렇게 하나의 frame이 두 텍스트 쿼리에 공통되게 존재한다면 MR관점에서 “A person awakens in the sofa”와 “Person then stand up”이라는 문장 중에 어떤 텍스트 쿼리의 moment로 반환이 되나요? 이렇게 겹치는 구간에 대해서 학습하는 데 문제는 없나요?
감사합니다!
안녕하세요, 좋은 질문 감사합니다.
(1) 문장 feature를 만드는 과정에 대해 설명드리겠습니다. 우선 문장의 길이가 각각 서로 다르지만 이를 tokenize하고 잘라 L_{w}개의 동일한 길이로 만들어주는데, L_{w}개 토큰이 각각 D차원을 갖기에 하나의 문장은 L_{w} * D 차원을 갖게 되고, 이러한 문장이 한 비디오마다 K개씩이니 한 비디오에 대한 문장 feature는 K * L_{w} * D가 됩니다. 말씀해주신대로 문장 수준의 feature를 얻기 위해, L_{w} 축으로 평균내어 K * D 차원의 feature로 만들어주는 것입니다.
(2) Inference 시 한 비디오 내에 K개의 문장이 존재한다면, 각 문장에 대한 구간을 찾아내는 방식으로 모델이 동작합니다. 그래서 비디오를 구성하는 클립이 K개의 문장 중 어디에 상응하는지 찾는 것이 아니라, 반대로 비디오와 문장 쌍이 던져졌을 때 그 구간을 찾아내는 개념이라고 생각하시면 이해가 되실겁니다. 따라서 학습 시 하나의 프레임이 두 구간에 모두 속해있더라도 첫 번째 구간에서는 첫 번째 문장에 대한 상응 부분에 집중하고, 두 번째 구간에서는 두 번째 문장에 대한 상응 부분을 집중적으로 보게 될 것입니다.