안녕하세요, 서른세 번째 X-Review입니다. 이번 논문은 2023년도 CVPR에 올라온 Pooling Revisited: Your Receptive Filed is Suboptimal입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
Computer vision을 포함한 다른 분야에서 DNN은 전례없는 성공을 이뤘지만, 여전히 최적의 네트워크 구조를 설계하는 것은 어려운 문제로 남아있습니다. 여러 handcrafted model들이 좋은 성능을 보이는 것은 맞지만, 최적의 신경망 아키텍처를 자동으로 알아내고자 하는 연구도 있어왔습니다. 하지만, handcrafted 아키텍처들은 최적의 구조가 아닌 경우가 많으며 일반화 능력이 떨어진다는 단점이 있으며, 또 최적의 신경망 아키텍처를 자동으로 알아내고자 하는 neural architecture search 기반의 접근 방식들은 학습 비용이 엄청나게 필요했으며 search space가 제한되어 있기에 개선 효과가 미미하다는 단점이 존재합니다.
지금까지 convolution, 정규화, 활성 함수 등 등 ,, 신경망에 적용할 수 있는 효율적인 것들에 대해 연구가 되어 왔는데 pooling 연산은 그다지 주목을 받지 못했습니다. Pooling 연산이 local feature를 aggregate하는데 있어 단순하면서 효과적임에도 불구하고 말이죠.
Receptive field의 크기나 모양은 굉장히 중요한데, receptive field가 너무 작으면 크기가 큰 객체를 효과적으로 인식하지 못할 수도 있을 수도 있고 그 반대인 receptive field가 너무 큰 경우에는 작은 객체를 인식하지 못할 수도 있기 때문입니다. 이 Receptive field는 모델의 깊이나, convolution 종류, stride 등에 따라 결정되게 됩니다.
이 효율적인 Receptive field를 설계하기 위해서 deformable conv 등과 같이 일반 convolution을 변형한 것들이나, multi-resolution branch같은 아키텍처가 사용되기도 하죠. 하지만 이런 접근 방식은 사람이 직접 정교하게 설계해야 하는 하이퍼파라미터 혹은 시간이 많이 걸린다는 단점이 있는 neural architecture search에 의존하게 됩니다.
본 논문에서는 human-engineered 아키텍처의 suboptimality를 줄이기 위해서, 즉 최적의 아키텍처를 위해 Dynamically Optimized Pooling operation(DynOPool)을 제안합니다. 이 DynOPool은 말 그대로 동적으로 최적화할 수 있는 풀링 연산을 의미하는데요, 이 DynOPool은 기존 모델에서의 여러 resizing operation을 대체할 수 있는 모듈입니다. 정리하자면, 이 제안된 모듈 DynOPool은 학습 데이터셋에 대해 최적의 receptive field의 scale factor를 찾고, 이를 통해 네트워크의 중간 feature map을 적절한 크기와 모양으로 조정하는 역할을 하는 것입니다. 이를 사용한다면 pooling이나 stride의 하이퍼파라미터를 튜닝할 필요가 없겠죠.
본 논문의 contribution은 다음과 같습니다.
- 본 논문은 미리 사전에 설정한 하이퍼파라미터에 의존하는 neural network에서 기존 scaling operation의 한계를 해결함.
- 중간 feature map의 최적의 scale factor와 최적의 receptive field를 찾는 학습 가능한 모듈 DynOPool을 제안함.
- 제안하는 DynOPool을 사용한 모델이 기존 아키텍처보다 우수한 성능을 보임.
2. Motivation
영상 내의 정보는 여러 locality에 분산되어 있습니다. CNN은 kernel을 사용하여 다양한 크기의 pattern을 학습하는데, semantic하게 의미있는 패턴의 크기와 모양은 영상마다 상이하기 때문에 적잘한 receptive field를 사용하는 것이 무척 중요합니다. 하지만 최적의 receptive field를 찾는 연구는 활발히 이뤄지지 않았으며, neural architecture search라고 하는 receptive field 크기를 간접적으로 학습하는 등의 연구가 진행되긴 하였지만, adaptive한 feature map을 사용하는 것에 대한 연구는 거의 없습니다. 본 2장 motivation 부분에서는 receptive field의 크기와 모양을 고정한 기존의 receptive field가 왜 최적이 아닌지 설명하고, CIFAR100에서 VGG16을 사용한 toy experiment를 통해 DynOPool이 이 문제를 어떻게 다루는지 설명하도록 하겠습니다.
2.1. Asmmetrically Distributed Information
데이터셋은 도메인 특성으로 인해 본질적으로 정보 비대칭성이 있습니다. 예를 들자면, 바코드 이미지는 세로 방향으로는 동일한 값을 반복해서 갖고 있기 때문에 세로 방향으로는 정보가 별로 없습니다. 그래서 바코드 이미지 같은 경우 주로 가로 방향의 정보에 집중하는 것이 더 바람직하겠죠. 하지만 바코드와 같이 사전 정보가 있는 영상을 제외하면 대부분의 경우에는 이런 정보 비대칭성을 측정하기 어렵습니다. 또, 입력 영상 크기를 조절하는 전처리도 종종 정보 비대칭성 문제를 유발할 수 있습니다. 예를 들어, 이미지를 축소하거나 확대할 때 원래 이미지에 있는 정보가 왜곡거나 손실될 수 있다는 얘기입니다. 하지만, 사람이 직접 설계한 네트워크(human-designed) 같은 경우 이미지의 종횡비를 모델의 입력에 맞게 조절하는 것이 일반적이고, 일반적인 네트워크의 receptive field는 이런 영상 크기 조정을 처리하도록 설계되지 않았습니다. 즉,, 모델은 이미지 크기 조정 과정에서 생기는 정보 비대칭성을 다루지 않고 있다는 의미게 되겠죠 .

본 논문에서 제안하는 DynOPool 모듈의 가치를 입증하기 위해서 저자들은 CIFAR100의 영상을 수직 방향으로 두 배 늘리고 random crop하여 크기를 32×32로 만든 CIFAR-stretch라는 toy datset을 사용해 실험을 진행했습니다. Fig1-(a)를 보면 이 실험에서 DynOPool은 wide한 feature map을 사용하고 수평 방향에서 더 많은 정보를 추출하여 human-designed model보다 성능이 향상됐다는 결과를 보입니다. 노란색 바가 feature map의 height, 초록색 바가 width를 의미하는데 보시면 초록색 바인 width가 height보다 더 값이 큰 것을 볼 수 있죠.
2.2. Densely or Sparsely Distributed Information
최적의 모델을 설계하는데 있어서는 영상 정보의 locality도 고려를 해야 합니다. CNN은 영상으로부터 복잡한 표현을 학습하는 데 있어 local 정보를 단계적으로 aggregation함으로써 동작하는데, 이 local 정보는 각 영상의 특성에 엄청 의존적입니다. 예를 들자면, 영상이 흐릿해지면 작은 패턴(texture 같은거,,)들이 모두 사라지게 되겠죠. 이 경우에는 앞단 layer에서 receptive field를 키우고 global한 정보에 집중하는 것이 더 나은 결과를 낼 수 있습니다. 반면, 이미지에 texutre와 같은 class-specific한 정보가 많이 포함되어 있다면 local한 패턴이 더 중요할 수 있겠죠.
이 가설을 입증하기 위해서 저자는 추가로 CIFAR100 데이터셋을 두 가지로 변형하여 CIFAR-tile과 CIFAT-large를 구성하였습니다. CIFAR-tile같은 경우는 원본 이미지를 절반 크기로 downsampling하여 16×16 크기로 만든 다음에 이 downsampling한 영상을 4×4의 타일 형태로 재구성하였습니다. 또 CIFAR-large같은 경우는 downsampling한 영상을 64×64크기로 upsampling하였습니다.

실험 결과는 fig-(b), (c)에서 확인할 수 있습니다. 보시면 DynOPool을 사용한 본 논문의 모델이 human-designed model의 성능을 전부 능가하고 있습니다. bold 처리된 성능이 DynOPool을 사용하였을 때의 GMACs값과 accuracy 값이구요, 그 옆에 괄호 안에 들어있는 것이 기존 모델의 GMACs값과 accuracy 값입니다. 여기서 GMACs란, 딥러닝에서 모델의 computation cost를 측정하는데 사용되는 metric인데요,, 더 많은 GMACs를 필요로 할 수록 계산 비용이 더 높아지고 그로 인해 더 많은 resource와 시간이 필요하다고 보면 되겠습니다. 즉, 낮을수록 더 좋은 지표입니다.
무튼,, (b)의 CIFAR-tile과 (c)의 CIFAR-lare 두 데이터셋은 둘 다 크기가 16×16인 동일한 basic 이미지로 구성을 한 것인데도 불구하고, DynOPool에 의해 학습된 네트워크는 다른 형태를 갖고 있습니다. 먼저 (b) CIFAR-tile로 학습된 모델은 CIFAR large로 학습한 모델보다 앞 layer에서 보다 큰 feature map을 갖고 있습니다. 즉, 네트워크 초반부에서 작은 receptive field를 사용하도록 DynOPool이 조정한 것인데, 이는 tile로 구성된 object들이 매우 작기 때문입니다. 반면, CIFAR-large의 경우에는 입력 이미지가 작은 크기에서 확대된 것이기 때문에 초기 layer에서 큰 receptive field를 가지도록 DynOPool이 조정한 것입니다.
3. Proposed Method
이제 제안된 DynOPool을 디테일하게 살펴보도록 하겠습니다.
3.1. Dynamically Optimized Pooling (DynOPool)
DynOPool은 학습 가능한 크기 조정 모듈로써 feature map x_{in} ∈ R^{H_{in} \times W_{in}}이 입력으로 들어왔을 때 크기가 조정된 x_{out} ∈ R^{H_{out} \times W_{out}}을 출력해냅니다.
3.1.1. Design of DynOPool
먼저, DynOPool을 어떻게 설계했는지에 대해 살펴봅시다… 먼저 DynOPool은 식 1과 같이 input feature map x_{in}를 H_{out} \times W_{out} grid로 나누게 됩니다.
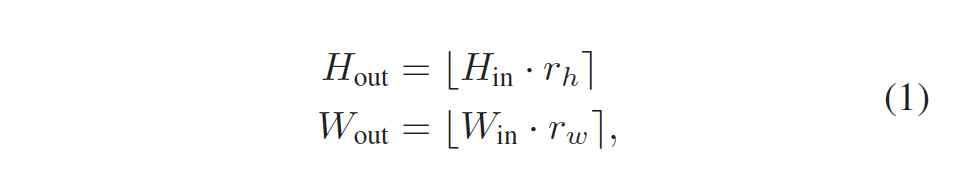
여기서 r_h, r_w는 각각 높이와 너비에 대한 scale factor를 나타내며, [ . ]는 반올림 연산을 나타냅니다. 예를 들어 x_{in}의 좌상단 좌표가 (-1, -1), 우하단 좌표가 (1, 1)으로 정규화된 좌표라고 해본다면 output feature map에서 grid cell의 크기는 입력 feature map의 크기를 H_{out}, W_{out}로 나눈 만큼의 크기를 가질 것이기 때문에 각 grid cell의 크기는 2/H_{out} x 2/W_{out}이 되겠죠. (입력 feature map 크기가 2×2라서)
그 다음 각 grid cell의 센터 점 p = (p_h, p_w)점을 중심으로 한 grid cell에서 네 개의 query point를 정의합니다.
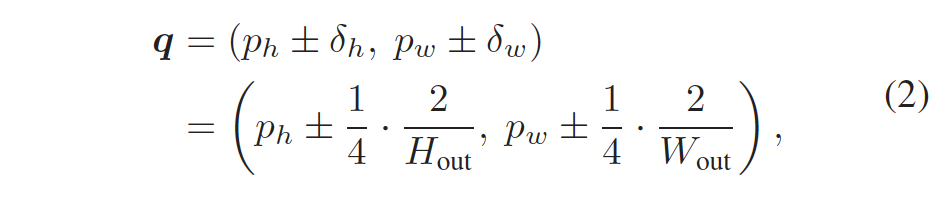
네 개의 쿼리 포인트는 위 식2와 같이 정의되는데요, δ = (δh, δw) 는 p로부터의 displacement를 의미합니다. 다시 말해 이 쿼리 포인트들은 각 grid cell의 네 방향으로 일정한 거리만큼 이동한 위치입니다. 이 쿼리 포인트들의 위치는 scale factor r에 의해 결정되며, 입력 feature map x_{in}에서 가장 가까운 grid cell들로부터 bilinear interpolation을 통해 결정됩니다.
마지막으로, DynOPool은 네 개의 쿼리 포인트에서 얻은 feature 벡터들을 aggregation하여 output feature map x_{out}의 각 grid cell로 반환합니다. 이때 aggregation로는 max-pooling을 사용하였습니다.
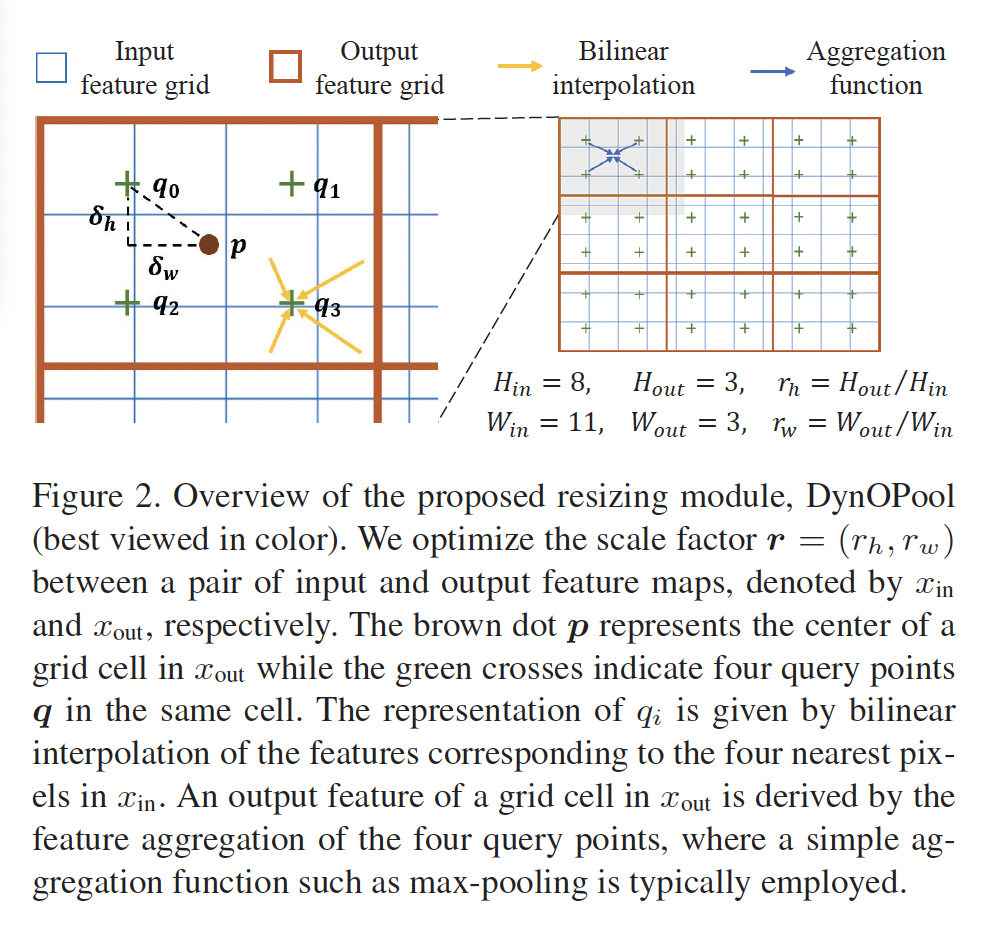
그림을 통해 다시 정리하자면, 파란색 사각형이 input feature map grid cell이구, 갈색 사각형이 output feature map grid cell입니다. 본 DynOPool은 input feature map과 output feature map 사이의 scale factor인 r(r_h, r_w)를 최적화 하는 것이 목적입니다. 각각의 output feature map의 grid cell(갈색 사각형)은 각각의 input feature map(파란색 사각형)에 대응하는 네 개의 query point를 갖고 있습니다. 그림에서 초록색 십자가가 이에 해당합니다. 이 query point는 각 output grid cell의 센터점인 p를 기준으로 bilinear interpolation을 사용해 계산한 것입니다. 마지막으로 output feature map의 각 grid cell은 이 네 개의 query point로부터 얻어지는 feature를 aggregation(max pooling)하여 얻게 됩니다.
DynOPool은 결국 scale factor r을 최적화한다고 했었는데요, 결국 이 r을 최적화한다는 것이 네 개의 query point q의 위치를 최적화한다는 의미가 됩니다. 즉, scale factor r을 조정함으로써 query point 위치가 최적화되어서 input feature map으로부터 효과적인 정보를 추출할 수 있게 됩니다. 또, DynOPool은 최적화된 scale factor r을 사용해서 최적의 resolution을 갖는 중간 feature map을 얻을 수 있다는 이점이 있어서 deep layer에서 다른 operation(stride, activation function과 같은)의 영향을 받지 않고도 receptive field의 크기 모양을 adaptive하게 조정할 수 있습니다.
3.1.2. Optimization
DynOPool을 optimization하기 위해서는 식(1), (2)가 미분 가능해야 겠지만, [.]인 반올림 연산이 미분 가능하지 않습니다. 이 문제를 해결하기 위해 저자는 미분 가능한 quantization 트릭을 사용했으며, 반올림 함수를 아래 식 (3), (4)와 같이 재정의하였습니다.
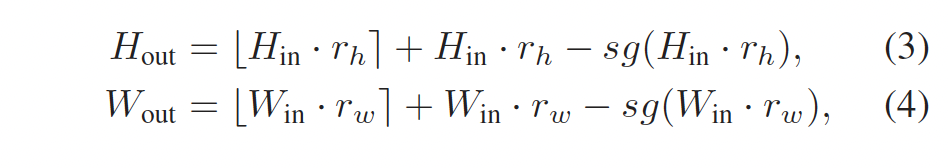
여기서 *sg(.)*는 gradient를 stop하는 연산자로(stop gradient operator)입니다. 위 식을 사용한다면 이산 값인 H_{in} . r_h와 W_{in} . r_w를 feedforward할 수 있으며, 동시에 이에 대한 continus한 근사 함수를 통해 역전파할 수 있습니다.
이제 최적화할 수 있게 되었지만, scale factor r을 학습하는 과정에서 추가적인 문제가 남아 있습니다. 식 (2)에서 볼 수 있듯이 scale factor r은 displacement 함수인 δ에 의존하고 있습니다. 하지만, r_h, r_w 둘 중 하나가 작을 때, r에 대한 gradient는 안정적이지 않다고 합니다. 이는 gradient가 아래 식 5와 같이 r^2_h나 r^2_w에 반비례하기 때문이라고 하는데요,
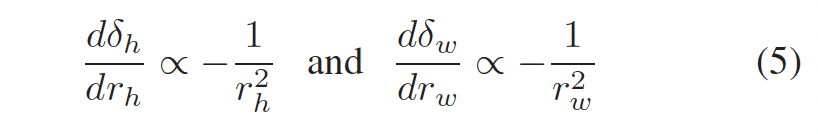
이런 gradient explosion은 학습 도중 x_{out}의 resolution를 크게 변화시킬 수 있기 때문에 본 논문에서는 scale factor r을 다음과 같이 다시 파라미터화하였습니다.
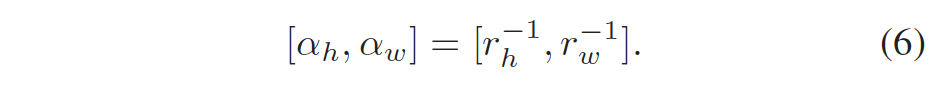
즉, r의 역함수를 α로 두고 r대신 α를 최적화함으로써 학습 과정을 안정화시킨 것으로 보면 되겠습니다.

위 그림3을 통해 최적화 과정을 다시 살펴보겠습니다. 그림에서 빨간색 파선이 backward gradient구요, 검정색 실전이 forward, sg가 stop gradient입니다. forward pass에서는 이산화 값인 [latex]H_{in} . r_h[/latex]가 사용되지만, backward pass에서는 이산화 값 [latex]H_{in} . r_h[/latex]에 대응되는 연속적인 값 (H_{in} . r_h)가 사용되게 되며 이 값이 α에 graidnet를 흘려보내게 됩니다. 그림에는 height에 대한 flow만 나와있지만 width도 동일하게 진행됩니다.
3.2. Constraints for Model Complexity
추가로 저자는 모델 complexity에 대한 제약 조건을 두었는데요, DynOPool은 가끔 모델의 성능을 극대화하기 위해서 큰 scale factor를 사용해 중간 feature map의 resolution을 엄청 키우게 됩다고 합니다. 그래서 computation cost에 대한 제약을 두고 모델의 크기를 줄이기 위해서 추가적인 손실 함수인 L_{GMAC_s}를 도입하였습니다.
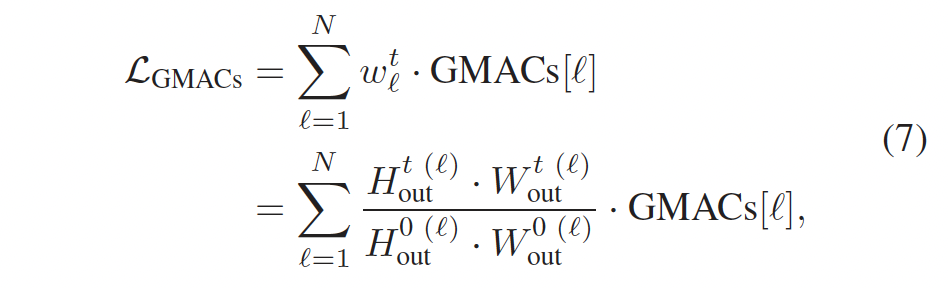
이 손실함수는 각 iteration에서 각 layer 별로 GMACs 의 가중 합으로 계산됩니다. GMACs는 앞에서 한번 언급했었는데, 간단히 다시 말하자면 딥러닝에서 모델의 computation cost를 측정하는데 사용되는 metric입니다.
식 7에서 N은 모델 내의 전체 layer 수이고, GMACs[l]은 initial state에서 l번째 layer의 GMACs count를 나타내며, w^t_l는 각 layer에서 초기 상태 (H^{0(l)}_{out}, W^{0(l)}_{out})와 현재 iteration t에서의 (H^{t(l)}_{out}, W^{t(l)}_{out})의 feature map 크기의 비율입니다.
이렇게 정의된 L_{GMACs}는 모델이 학습 중에 scale factor r이 변경됨에 따라 computation cost가 얼마나 증가하는지를 반영한다고 보시면 되는데, 이를 통해 모델의 complexity를 제어할 수 있게 됩니다.
3.3. Loss
다음으로 전체 loss에 대해 살펴보자면 방금 설명드린 GMACs loss와 task의 loss를 선형 결합하는 것으로 구성됩니다. task loss라 함은 classification, segmentation 등등의 task의 기존 loss를 의미합니다.
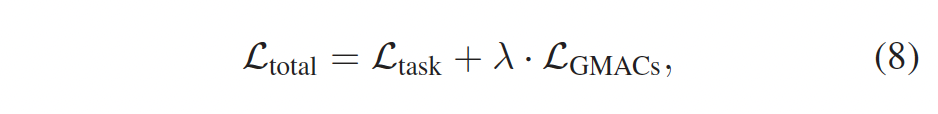
이를 통해 모델은 중간 feature map의 resolution을 최적으로 만들면서 학습할 수 있으며, 이를 통해 성능을 극대화할 수 있게 됩니다. 추가로 GMACs를 통해 학습 중에 모델의 복잡성도 동시에 고려할 수 있게 되겠죠.
3.4. Versatility of DynOPool
마지막으로 DynOPool의 Versatility(범용성)에 대해 살펴보도록 하겠습니다. 어떤 모델이든 상관없이 적용 가능한 특성을 갖고 있기 때문에 본 논문에서 제안도니 DynOPool은 네트워크 내의 모든 종류의 resizing operator를 대체하여 사용될 수 있습니다.
최적화되는 scale factor r을 적용한 모델과 하이퍼파라미터 튜닝에 의존하는 기존 방법론들을 비교하기 위해 기존 네트워크에서 모든 종료의 resizing operator를 DynOpool로 대체하였습니다. 이때 마지막 average pooling layer는 제외하구 max pooling과 같은 모든 풀링은 DynOPool로 대체하였다고 하는데, 왜 마지막 average pooling은 제외한 것지는 잘 모르겠네요 . . . . 또, strided convolution은 일반 바닐라 conv + DynOPool로 대체하였다고 합니다.
이 DynOPool은 사전에 정의한 downsampling, upsamplilng, pooling ratio에 의존하는 기존 방법론들과는 달리, feature map의 scale을 조정할 때 scale factor 및 pooling ratio에 제약이 없습니다.
4. Experiments
이제 실험 섹션에 대해 살펴보겠습니다. 실험은 Classification과 semantic segmentation task에 대해서 수행됐는데요. 우선 classification. task로는 3개의 데이터셋(FGVC-Aircraft, CIFAR100, ImageNet) 과 세 타입의 네트워크(VGG16, ResNet50, MobileNetv2)를 사용하여 평가하였습니다. 본 DynOPool 모듈을 사용한 모델과, 원본 human-designed 모델 그리고 Shape Adaptor에 대한 성능 비교를 하였으며, 평가지표로는 accuracy와 GMACs를 사용하였습니다. 또 semantic segmentation task에 대한 실험으로는 PascalVOC 데이터셋을 사용하였습니다.
4.1. Comparison with Human-Designed Model
4.1.1. Main results
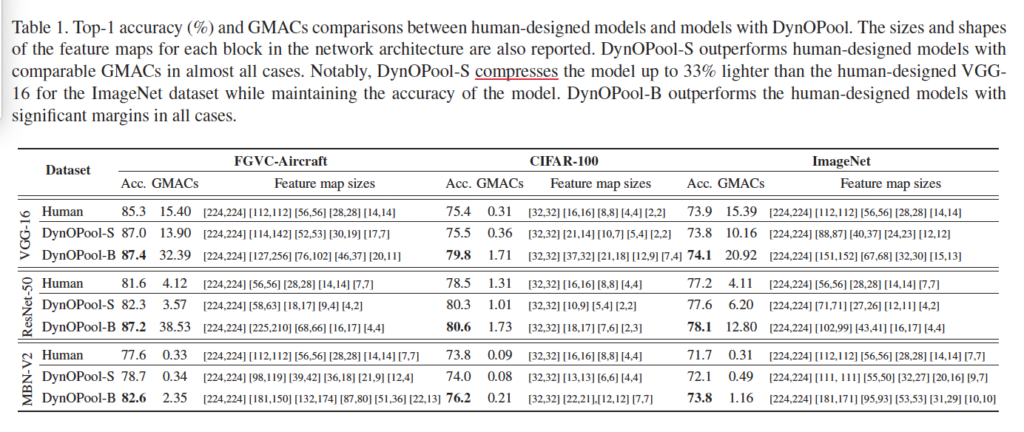
위 표1은 DynOPool의 성능을 GMACs와 accuracy metric으로 평가한 표입니다. human이라고 되어 있는 모델은 기존 네트워크를 나타내며, DynOPool-S는 DynOPool 모듈을 사용한 것인데 human이 설계한 모델과 유사한 computation cost를 갖는 모델로 GMACs를 최대한 human 모델과 유사하게 해서 accuracy를 비교하려고 한 것이라고 보면 됩니다. 또, DynOPool-B는 주로 정확도를 위해 학습된 모델입니다. 표1을 보면 DynOPool-S는 human 모델과 accuracy가 거의 동일하거나, 더 적은 GMACs를 갖으면서 더 높은 성능을 보이고, DynOPool-B는 모든 네트워크에 대해 human accuracy보다 더 높은 성능을 보입니다.
본 논문의 저자가 강조하는 부분은, 파라미터 수를 적게 늘리면서도 feature map의 크기와 모양을 번경해 성능을 크게 향상시켰다는 점입니다. 이렇게 하기 위해서는 NAS(Network Architecture Search)를 사용해야 하는데, 이 NAS의 경우에는 많은 크기의 resizing layer와 information asymmetry를 고려해야 하기 때문에 큰 search space를 필요로 하기 때문에 GPU가 몇십개나 필요하다는 단점이 있습니다. 하지만 DynOPool은 이러한 문제를 해결하고, 과한 searching 작업 없이 최적화된 네트워크를 알아낼 수 있습니다.
또 흥미로운 점은 FGVC-Aircraft 데이터셋에 대한 결과를 보면, DynOPool-S 모델이 초기 layer에서 넓은 feature map을 갖지만 deep layer에서는 height가 큰 feature map을 갖고 있습니다. 이 FGVC-Aircraft 데이터셋에 대해서는 DynOPool이 적용된 모델이 local한 패턴을 분석할 때 수평 방향의 정보에 더 집중함을 의미하겠습니다. 결과적으로 기존의 feature map 크기를 사람이 직접 설계한 모델보다 더 적은 compuation cost를 들이며 더 높은 성능을 보입니다.
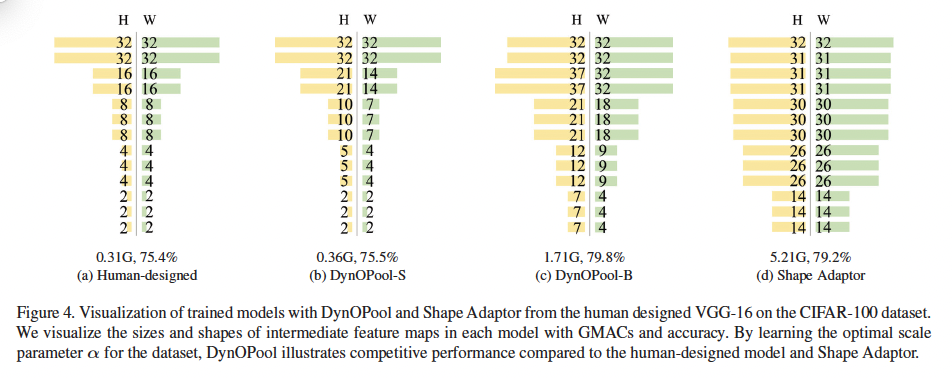
위 figure4는 사람이 설계한 모델과 DynOPool-S/B, Shape Adaptor의 feature map 크기를 시각화한 결과입니다. fig4 (b), (c)에서 볼 수 있듯이 DynOPool-S/B는 정사각형 feature map을 사용하지 않습니다. 즉, 데이터 특성에 맞게 feature map shape을 변경한 것입니다. DynOPool-B는 첫번째 pooling layer이후에도 feature map 크기를 증가시켰는데, 이는 human이 설계한 모델 대비 4.4%의 성능 향상을 보였습니다.
4.1.2. Trade-off between accuracy and GMACs
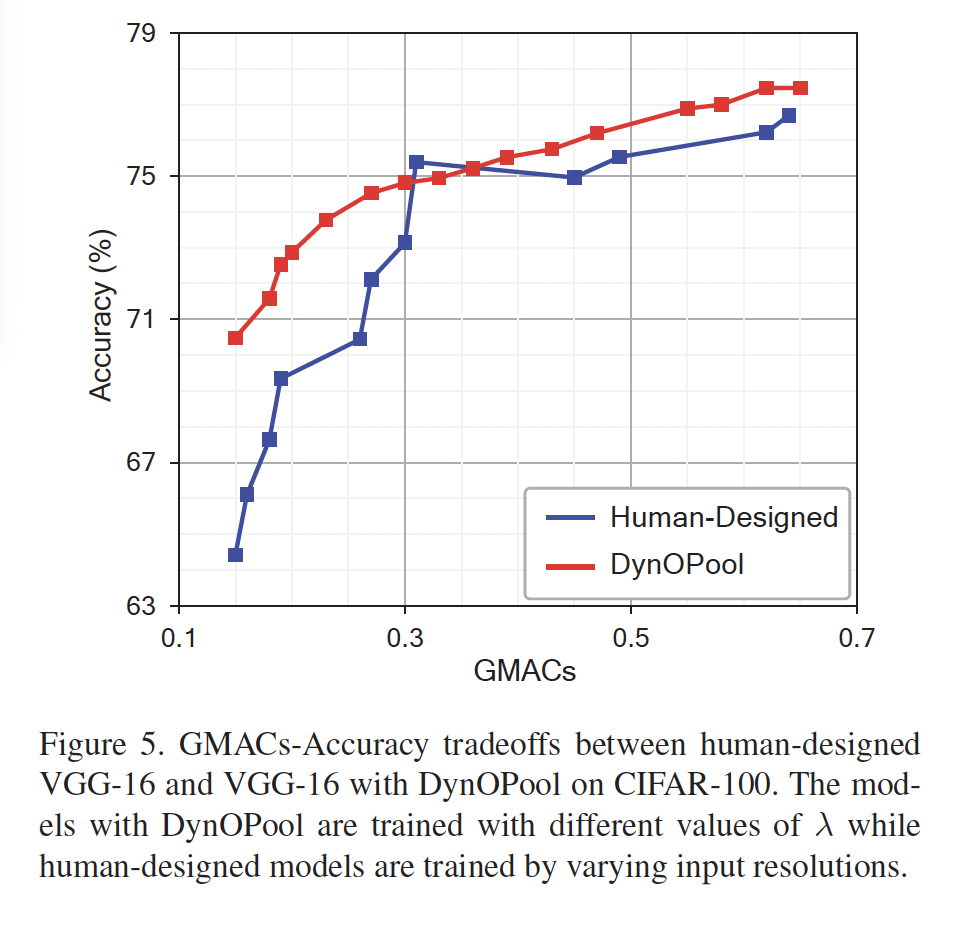
위 fig5느 DynOPool과 human이 설계한 모델인 VGG16의 GMACs-Accuracy tradeoff를 나타내는 그래프입니다. 보시면, DynOPool은 사람이 설계한 모델보다 acc-GMACs 사이 tradeoff가 VGG16보다 나은 것을 보여주는데, 특히 GMAC가 작을 때 훨씬 더 성능이 좋습니다.
4.2. Comparison with Shape Adaptor
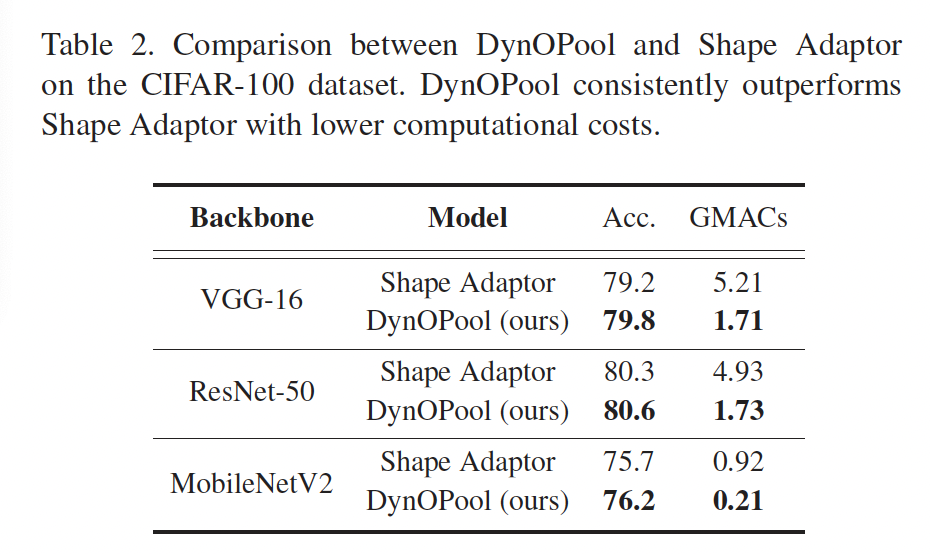
위 table2는 DynOPool과 Shape Adaptor간의 accuracy와 GMACs에 대한 결과를 보여줍니다. DynOPool과 Shape Adaptor 두 알고리즘 모두 학습 가능한 resizing 모듈을 도입해 최적의 feature map 크기를 찾는 것을 목표로 하는데요, DynOPool은 accuracy와 GMACs 측면 둘 다에서 Shape Adaptor보다 우수합니다. 이런 결과에 대해서 저자는 Shape Adaptor는 두 가지의 사전에 정의된 후보 크기 scale의 linear interpolation을 통해 feature map 크기를 결정하게 되는데, 이렇게 하면 선택된 size scale 사이에서 생성된 feature들이 실제로 최적의 feature가 아닐 수 있기 때문에 모델의 성능이 저하될 수 있다고 합니다. 하지만 이와 달리 DynOPool은 single scale factor r을 사용해서 feature map 크기를 조정하기 때문에 더 안정적으로 최적화할 수 있다고 하네욥.
4.3. Semantic Segmentation Results
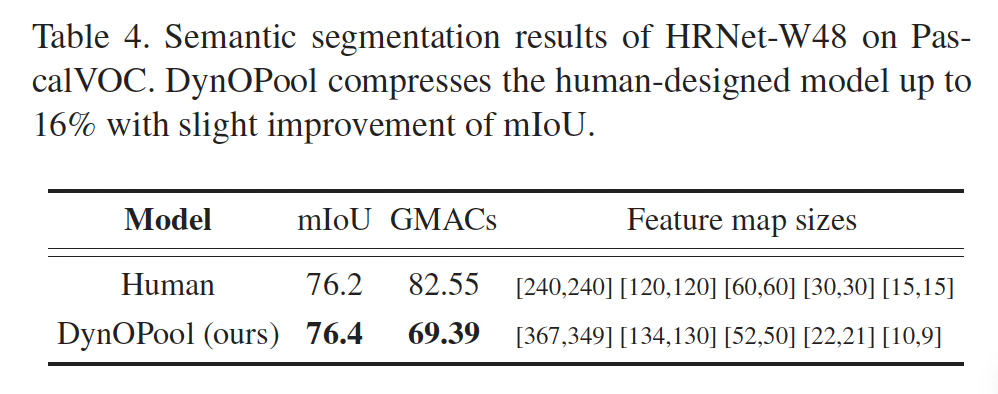
마지막으로 DynOPool의 효과를 더 검증하기 위해 semantic segmentation에 대해 수행한 추가 실험입니다. Semantic segmentation 모델은 보다 의미론적인 표현을 얻기 위해 다중 scale representation 학습이 일반적이라고 하는데요, 위 table4에서 보여지는 HRNet과 같은 모델은 전체 process 동안 고해상도 representation을 유지하고 고해상도에서 저해상도까지의 convolution stream을 병렬로 연결합니다.
Table4에서는 DynOPool의 성능을 평가하기 위해서 HRNet을 변형한 버전인 HRNet-W48을 백본 모델로 사용하고, 모델 내의 stride convolution을 DynOPool + 바닐라 conv로 대체하였습니다. 결과를 보시면, DynOPool은 약간의 mIOU 성능 개서노가 함께 human이 설계한 모델을 최대 16%까지 GMACs를 줄이는데 성공하였습니다.
리뷰 잘 봤습니다.
데이터셋마다 receptive field를 알아서 찾아준다는 것이 본 논문의 가장 큰 장점인 것 같습니다.
근데 결국에는 데이터 셋 마다 이 방법론을 학습 시키는 것에 대한 까다로움과 (수렴을 시켜야 하니) 데이터 셋 마다 reveptive field를 찾는 번거로움은 비슷할 거 같은데 그럼에도 해당 방법론의 장점이라면 무엇이 있을 수 있나요?
그리고 GMACs 가 어떻게 계산되는지도 간단하게 알려주시면 감사하겠습니다
안녕하세요. 좋은 리뷰 감사합니다.
논문에 계속 GMACs metric이 나오는 것 같은데, 이 metric이 FLOPs와 다른건가요 ? 댓글 쓰다보니 근택님 댓글이 달려서..ㅎㅎ 계산이 어떻게 되는지 알려주시면 감사합니다
리뷰 잘 읽었습니다.
새로운 관점의 논문이네요.
마지막 semantic segmentation 실험 결과에서 mIOU 0.2 상승은,, 음 사실상 random 성 때문에 충분히 발생할 수 있는 성능차라 의미있는 성능 향상일지에 대한 의문이 드네요. 더더욱 우측 feature map size를 보니 1번째 scale에서 기존 HRNet 대비 ours가 훨씬 더 크구요.
뭔가 연산량이 Ours가 더 많을수도 있을것이라는 생각이 드는데,, 그래서 저도 더더욱 GMACs라는 지표가 궁금해지네요.
그리고 본 논문을 아무래도 산자부 과제 및 contribution적 측면을 고려하면서 읽으신 거 같은데, 본 논문을 읽고 난 후 얻은 insight 라던가 적용할만한 껀덕지가 있는 거라던가,, 등등의 개인적 견해가 있나요?
감사합니다.
안녕하세요 윤서님!
좋은 리뷰 감사드립니다.
시행착오를 겪으면서, 하이퍼파라미터 튜닝을 하는 수고를 줄 뿐만 아니라 적절한 사이즈를 찾아서 성능향상에도 도움을 준다는 것이 인상깊었습니다.
또한 일반화 성능도 갖추고 있어, 임의의 네트워크 구조에 바로 적용이 가능한 방법론이여서 더 흥미로웠던 것 같습니다.
3.2 constraints for model complexity에 대해서 설명해주시는 부분에서 질문이 있습니다.
모델의 성능을 극대화하기 위해서 큰 scale factor를 사용해 중간 feature map의 resolution을 엄청 키우는 경우가 있다고 말씀해주셨는데요.
DynOPool 연산의 output으로 나오는 feature map의 해상도를 키우는 방향으로도 작동하는 것인지 궁금합니다.
만약 그것이 맞다면, 손실함수가 iteration에서 각 layer 별로 GMACs의 가중합으로 반영하여 계산된다는 것이 이해가 갑니다.
그러나 만약에 DynOPool 연산이 feature map을 줄이는 방향으로만 연산이 수행된다면, 모델이 성능을 극대화하기 위해서 큰 scale factor로 feature map의 resolution을 엄청키우는 것과 연산량에 해당하는 metric(GMACs)의 관계가 관련이 있는 것인지 궁금합니다.
감사합니다!
안녕하세요, 좋은 리뷰 감사합니다.
파라미터까지 무엇이 들어가야 할지에 대한 학습 방법이 나오는 것을 보니 되게 무궁무진 하네요.
1. 그림을 통해 다시 정리하자면 ~ 부분 그림이 빠진 걸까요?
2. DynOPool이 CNN의 적절한 receptive filter를 고려하여 연산을 할 수 있도록 pooling에 들어가는 scale factor는 N x N의 크기를 조절하는 factor로 이해를 하였습니다. 그럼, 해당 pooling에는 특정값 이상으로는 못 넘어가도록 하는 그런 임계값이라는 것도 존재하나요? 극단적일 수는 있으나, 사이즈가 큰 pooling 연산이 적용이 될 수도 있다는 생각이 들어서 그때는 모델이 어떤 판단을 하는지 궁금하네요.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
제목이 흥미로워 읽어봤는데, introduction 부분도 매우 설들력이 있었고 실험 결과도 좋아서 역시 CVPR 이구나 스러운 논문이었던 것 같습니다.
간단하게 궁금한 점이 있는데요, 식 중간에 stop gradient operator를 처음 접해서 이게 구체적으로 어떤 역할을 하는지에 대해서 잘 이해가 안되네요. stop gradient operator라는 것이 어떤 operator이고 이 방법론에서 사용한 이유에 대해서 궁금합니다.
(+ 적은 다음에 생각해보니 stop gradient operator라는게 requires_grad=False로 준건가 싶기도 하네요..?)
감사합니다.