

안녕하세요, 이번에는 무려 네이버 랩스에서 제안한 unseen object pose estimation의 과정 중 refiner를 다룬 논문을 읽어보았습니다. 생소한 내용도 많아서 읽는 데 상당히 오래 걸렸네요.. BOP challenge에 네이버 랩스가 출현하니 뭔가 반가운 것 같습니다. 리더보드에는 현재 4, 5등을 차지하고 있네요.
해당 논문은 3월 중순에 공개되었고, 코드 공개가 되지 않은 점이 아쉽네요.
리뷰 시작하도록 하겠습니다.
Introduction
RGB/RGB-D에 대한 이미지에서 물체에 대한 정확한 6D pose를 추정하는 것은 로봇 테스크와 증강 현실(AR) 어플리케이션 측면에서 매우 중요한 역할을 하고 있습니다. 6D pose 추정의 기본 셋업은 대상 물체에 대한 3D 모델이 주어지며 이는 학습 및 평가에서 사용할 수 있습니다. 대부분의 제안된 최신 방법론들은 학습 기반으로 동작하며, instance-level의 경우 물체 개별적으로 학습을 시켜야 합니다. 이러한 방식은 타겟으로 하는 물체에 대해 3D 형태를 학습을 해야 하며 개별적으로 한다는 것은 학습에 들어가는 시간 비용 또한 많이 들게 됩니다. 또한, 새로운(novel, unseen) 물체에 대해 다루는 것에도 어려움이 발생하게 됩니다.
최근에 MegaPose에서는 이러한 6D pose의 한계를 극복하고 지금까지 연구가 활발하게 이루어지고 있는데요. MegaPose에서 제안된 refiner는 3D shape를 학습하지는 않지만 간접적으로 3D 모델의 정보를 사용하여 렌더링된 이미지와 입력 이미지 사이의 상대적인 6D pose를 regression 하도록 설계되어있지만 해당 regression은 geometry 정보가 부족하다는 문제가 있습니다.
저자의 초점은 “3D 형태 정보를 활용하여 일반화 가능한 pose refinement를 위한 더 나은 설계가 있는지?”에 맞추었으며 2D optical flow 기반의 방법론들이 instance-level에서의 좋은 성능을 보이고 있어 해당 방법론들을 적용하였다고 합니다. 해당 방법론들은 렌더링된 이미지와 해당 뷰포인트에 대한 이미지 사이의 dense한 2D-2D correspondence를 추정하고 대상 물체의 3D 형태에 대한 2D-3D correspondence를 생성하여 PnP를 통해 6D pose를 얻을 수 있게 됩니다.
이번 논문에서는 타겟이 되는 물체에 대해 3D 모델의 정보를 통해 일반화 가능한 물체의 pose 추정을 위한 optical flow 기반의 refinement 방법인 GenFlow를 제안합니다. 이미지 내의 물체에 대한 init pose가 주어지면 GenFlow는 렌더링 된 이미지와 입력 이미지에 대한 optical flow(2D-2D correspondence)를 추정하고 PnP를 통해 6D pose를 refinement 하는 과정입니다.
Method
이번 GenFlow에 대해 설명하기에 앞서 Unseen object pose estimation를 수행하는 전반적인 흐름은 3-stage로 구성되는데요. 입력 이미지와 타겟 3D CAD 모델들이 주어지면, object detection → coarse pose estimation → pose refinement 의 단계로 동작합니다. 이번 GenFlow의 contribution은 pose refinement에 초점을 맞춘 연구라고 보시면 되겠습니다.
Preliminaries
2D Object Detection
unseen 물체를 검출하기 위해 기존 연구되었던 CNOS 모델을 사용하여 물체를 검출합니다.
Coarse Pose Estimation
앞의 detector를 통해 물체를 검출하는 과정 이후 initial pose를 예측하는 과정입니다. 쉽게 설명하면 물체에 대한 정확한 pose가 아닌 사전에 정의된 어떤 angle가 있을 때 가장 근접한 pose에 classification을 하는 것을 선행 연구인 MegaPose에서 제안됐었는데, 이를 좀 더 generalization 했다고 합니다. 이미지와 3D CAD 모델의 무작위 pose가 주어지면 coarse 모델은 해당 무작위 pose가 refiner에 의해 GT에 근접한 pose로 개선될 수 있는지에 대한 여부를 분류하는 역할을 하도록 하는데요. 무작위 pose는 N개의 사전에 정의된 rotation 집합들을 사용하여 임의의 pose를 생성하게 됩니다. 각 rotation에 대해 물체에 대한 3D 모델의 포인트가 2D bbox 내에 대략적으로 위치하도록 translation이 추정됩니다. 그럼 해당 모델에서는 임의의 pose 집합에 대한 예측 값들에 대한 score를 계산하게 될텐데요. 해당 score는 top-n개의 pose를 선택합니다.
해당 내용은 얼핏 보았을 때는 문제가 딱히 없어보이지만, 분류 기반으로 추정을 하면 novel 물체에 대해서도 다룰 수 있겠지만, 사전 정의된 rotation 만큼 이미지를 렌더링을 해야하기 때문에 cost가 상당히 많이 들게 됩니다.
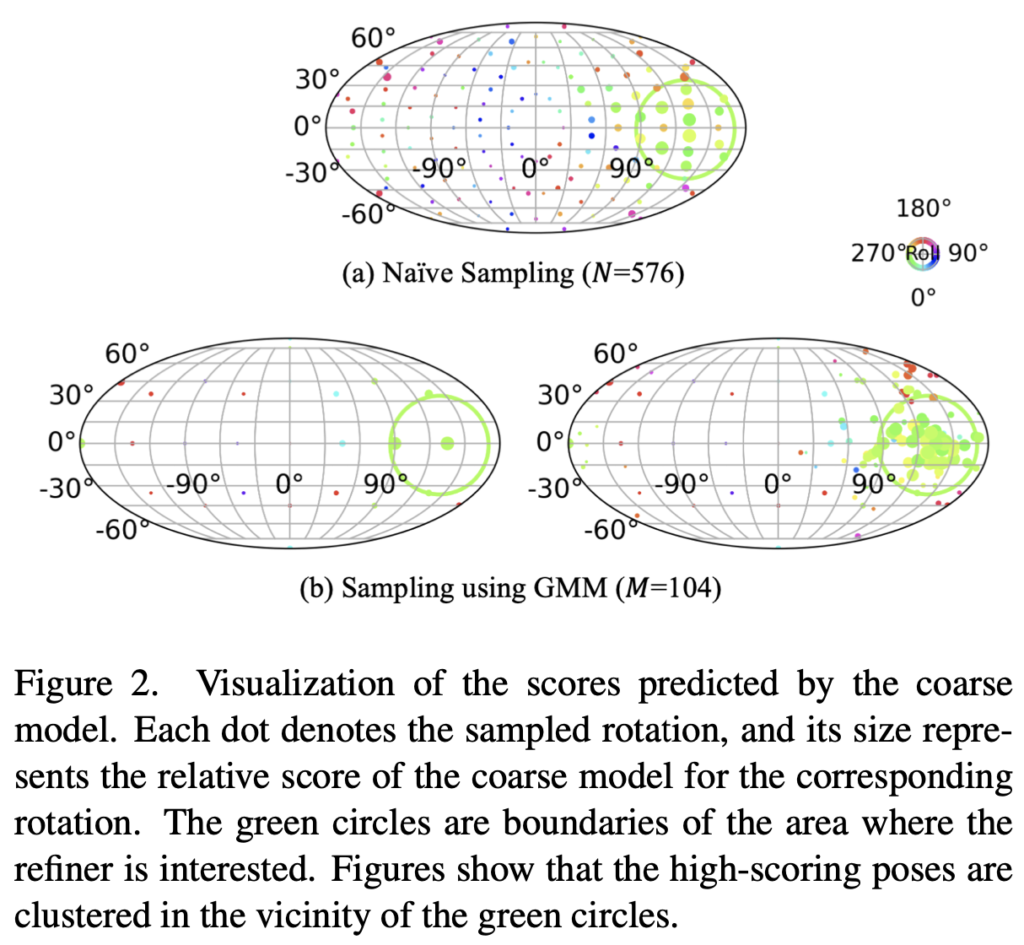
그림(2)는 rotation에 대한 score를 측정하여 나타낸 시각화인데요. 각 색깔은 우측의 rotation에 따라 달라지며, 초록색은 score가 높은 refiner의 interest 경계로, rotation 샘플에 대해서는 해당 영역에 클러스터링이 되는 특성을 통해 GMM(Gaussian Mixtured Model)을 사용하여 샘플링을 하였다고 합니다. 데이터의 분포를 좀 더 정확하게 모델링하여 효율적으로 샘플링하기 위한 수단으로 사용한 것으로 이해하였습니다.
해당 샘플링은 어떻게 하였는지 살펴보면, 그림2(b)의 왼쪽과 같이 사전에 정의된 M개의 rotation에 대해 top-k에 대한 score 샘플을 뽑고, 아래의 식(1)을 만족하는 GMM을 사용하여 각도 X에 대한 밀도 분포 p(X)를 생성합니다.
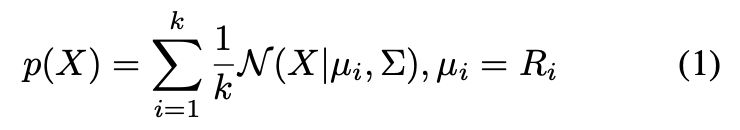
밀도 분포 p(X)에서 추가적으로 M개의 rotation을 샘플링하여 그림(2)(b)의 오른쪽과 같이 N개보다 더 적은 2M(M=104), K=16를 사용하면서 더 개선된 성능을 달성하는 렌더링 이미지를 생성하는 할 수 있었다고 합니다.
Pose Refinement
coarse pose 추정치가 주어지면, 해당 pose에 대해 refinement을 하는 과정입니다. 다른 refiner와 비슷하게 반복적인 과정을 통해 pose를 refine하게 됩니다.
GenFlow Refinement
Overview
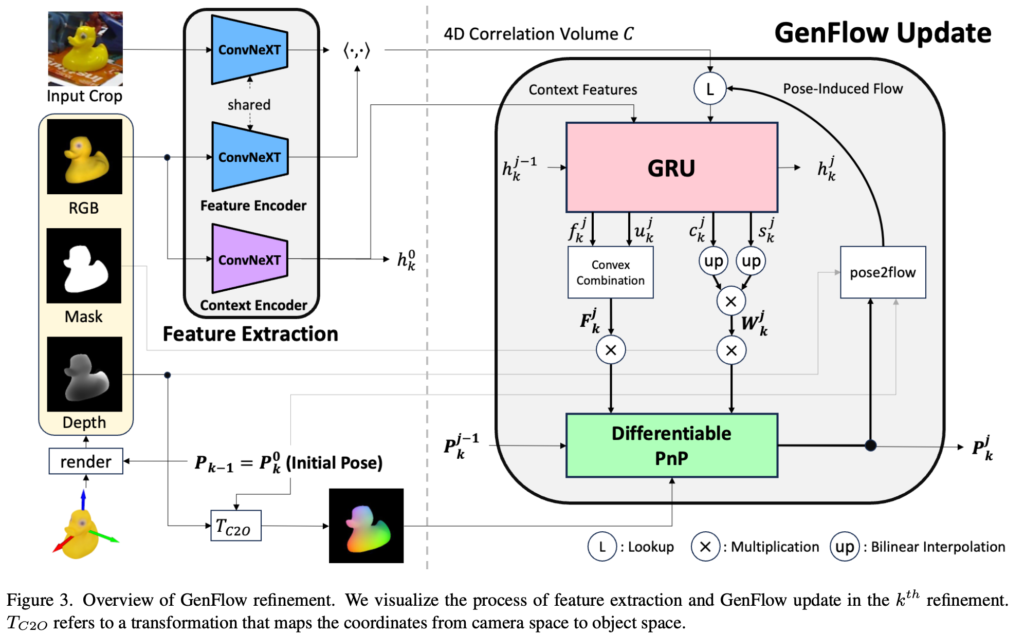
이제 본격적으로 GenFlow의 refiner의 구체적인 동작 과정을 살펴보겠습니다.
먼저 pose P와 intrinsic parameter에 대한 3D CAD 모델 M을 렌더링하여 합성 이미지를 얻습니다. 해당 렌더링 결과는 그림(3)의 입력 부분과 같이 RGB 이미지, Depth 이미지, Mask 이미지로 구성됩니다. 해당 RGB와 depth 이미지에서 feature를 추출하여 GenFlow 모듈을 통해 pose를 refinement하는 하게 됩니다.
Feature Extraction
입력 이미지와 렌더링된 이미지에 대해 동일한 Feature Encoder를 태워 특징을 추출하고 렌더링 이미지에서 context encoder를 태워 추가적인 특징을 추출하고, i번째 레이어에서 나온 각각의 feature map을 내적하여 correlation volume을 구성합니다.
GenFlow Module
앞서 구한 correlation volume과 context feature map에 대해 GenFlow 모듈이 동작하게 됩니다.
그림(3)의 우측과 같이 convolution 기반의 GRU(Gated Recurrent Unit), Differentiable PnP solver, pose2flow로 구성되어있는 것을 확인할 수 있습니다. 해당 모듈은 optical flow, confidence weight, 6D pose를 반복적으로 업데이트 하는 것을 목표로 하게 됩니다.
GenFlow Update
GRU Update
먼저 GRU는 어떻게 동작하는지에 대해 살펴보겠습니다.
j번째(refinement 횟수) 업데이트의 경우, GenFlow 모듈의 GRU에서는 previous hidden state h^{j-1}, correlation feature r^{j-1}, context feature를 사용하게 되는데요. GRU의 출력을 보면 \{h^{j}, f^{j}, u^{j}, c^{j}, s^{j}\}을 하는 것을 확인할 수 있습니다. 이는 업데이트 된 hidden state h^{j}, optical flow f^{j}, flow upsampling sampling mask u^{j}, certainty c^{j}, pose sensitivity s^{j}로 구성됩니다.
optical flow f는 mask u를 사용하여 이전 i-1번째 feature map의 해상도와 일치하도록 F로 upsampling 됩니다. 이때 bilinear interpolation을 적용한 후 c와 s를 곱하여 가중치 W를 얻습니다. certainty와 pose sensitivity에 대한 head는 각각 다른 손실 함수를 통해 학습됩니다.

그림(4)를 보시면 앞의 certainty와 sensitivity가 무엇인지에 대해 이해할 수 있으실 겁니다. 이렇게 각각에 대해 분리하게 되어 certainty를 추정하면 occlusion에 대해서도 강인하게 작동하도록 하는 효과도 얻을 수 있으며 upsampling된 optical flow와 confidence weight를 통해 가중치가 적용된 2D-3D correspondence를 생성하는 데에 사용되게 됩니다.
Pose Update
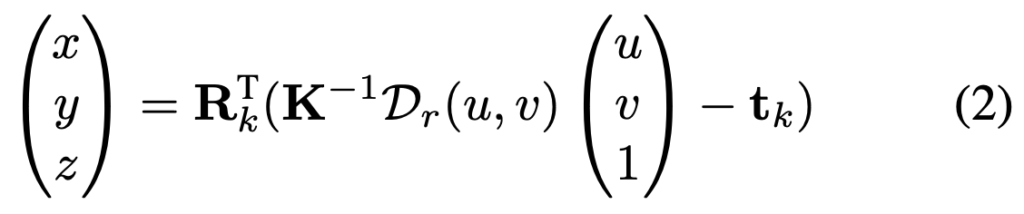
coarse pose 추정 과정을 통해 저희는 init pose를 얻을 수 있었습니다. 합성 depth 이미지와 intrinsic parameter K도 알고 있으므로 위 식(2)를 통해 depth 이미지 내 픽셀(2D)에 대해서 3D 공간에서의 좌표를 알 수 있겠네요. 이러한 과정을 통해 optical flow에 대한 2D-3D correspondence를 얻을 수 있습니다. 해당 correspondence의 confidence를 적용하기 위해 W를 사용하여 물체에 대한 영역만 고려하기 위해 렌더링된 마스크를 사용하게 됩니다. correspondence를 만들어 pose를 추정하도록 PnP solver를 적용합니다.
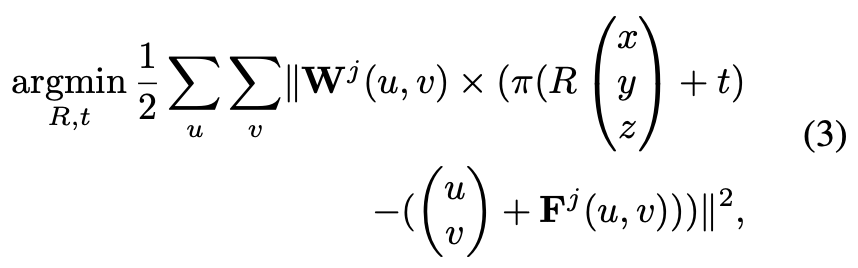
식(3)은 PnP solver에서 사용되는 최적화 함수인 Levenberg-Marquardt (LM) 알고리즘에서 가중치 W를 곱해주어 Weighted 2D-3D correspondence를 생성하도록 합니다. 식을 간단하게 살펴보면, \pi는 2D projection 함수이고 projection error의 합을 최소화하여 6D pose를 최적화 하게 됩니다.
저자는 해당 PnP 또한 학습시켜 사용하기 위해 differentiable PnP를 사용하게 되는데요. 저자가 제안한 것은 아니고, 기존의 Epro-pnp를 적용하였다고 합니다.
[1] Hansheng Chen, Pichao Wang, Fan Wang, Wei Tian, Lu Xiong, and Hao Li. Epro-pnp: Generalized end-to-end probabilistic perspective-n-points for monocular object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2781–2790, 2022.
Correlation Lookup
pose에 대해 입력 이미지와 렌더링 이미지 간의 optical flow인 pose-induced flow를 계산하는 과정입니다.
pose-induced flow은 depth 이미지의 점들을 3D로 차원을 올리고 렌더링된 이미지와 위치 변화를 계산하고, lookup operation에 타겟 물체의 3D 형상을 포함하기 위해 correlation volume C를 인덱싱 하기 위해 추정된 flow가 아닌 pose-induced flow를 사용하게 됩니다. 이는 3D 형태의 정보를 따르는 dense한 matching을 유도할 수 있다고 합니다.
해당 lookup operation을 통해 GenFlow Update를 위한 GRU의 입력으로 correlation feature를 얻을 수 있게 됩니다.
Cascade Architecture
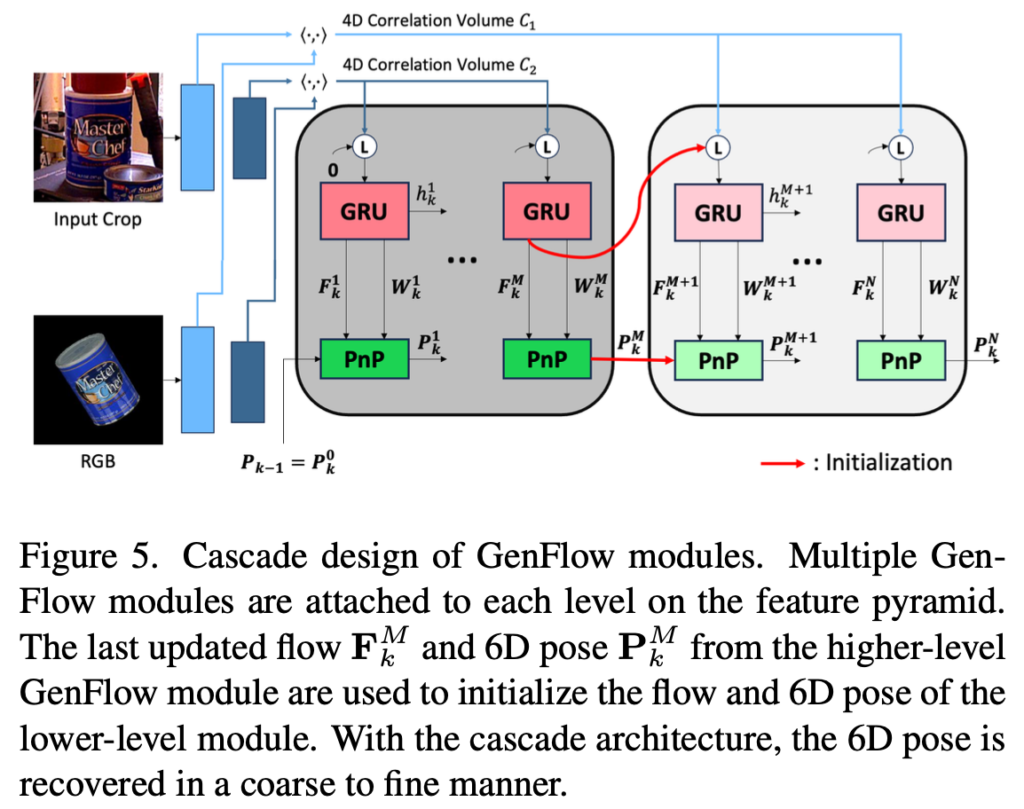
Feature pyramid 구조에서 영감을 받아 여러 GenFlow를 사용하기 위해 Cascade 구조를 사용하였다고 하는데요. 입력으로 correlation volume이 주어지면 각 volume에 GenFlow 모듈을 할당하고, 그림(5)와 같이 마지막 내부 업데이트의 optical flow와 refinement된 6D pose를 사용하여 다음 모듈에 대해서는 다시 해당 pose로 초기화를 시키도록 동작합니다. 이러한 cascade 구조는 단일 GenFlow 모듈을 사용하는 것보다 더 좋은 결과를 보여주었다고 하네요.
Training
데이터셋, refiner, coarse 모델은 MegaPose에서 제안된 방법들을 적용합니다.
Dataset
ShapeNet, Google Scanned Object(GSO)
Refiner Model
3D 모델에 대한 GT 6D pose가 있는 이미지가 주어지게 되면, rotation과 translation에 각각 noise를 주어 init pose를 생성하기 위해 pose를 왜곡시키는 효과를 줍니다. 이는 MegaPose에서 사용한 동일한 학습 방법입니다.
Coarse Model
입력 이미지와 물체에 대한 pose가 주어지면, coarse 모델을 학습시켜 refiner가 init pose에서 GT pose에 근접한 6D pose를 추정할 수 있는지 분류하는 역할 수행하는데요. Nagative/Positive 샘플을 무작위로 생성하고 binary cross entropy loss를 통해 분류하도록 학습시킵니다. Nagative sample의 경우, refiner 모델에서 왜곡된 init pose를 사용하는 것과 동일한 방법을 사용합니다. 샘플을 생성하는 방법 또한 MegaPose에서 제안된 방법을 사용하였다고 하네요.
Implementation Details
Coarse Estimation
ImageNet으로 사전학습된 ConvNeXt를 backbone으로 사용하여 FC head를 통해 GMM을 통해 얻은 샘플로부터 top-k를 뽑을 수 있도록 분류를 수행하는 모델입니다.
GenFlow Refinement
256 \times 256 크기를 가지는 합성 이미지와 intrinsic parameter K를 사용하여 합성 이미지와 동일한 해상도로 크기가 resize된 crop 이미지를 얻고, coarse 모델과 마찬가지로 Feature 및 context encoder에 ConvNeXt를 사용합니다.
GRU는 ConvGRU unit으로 구현되어 있으며, optical flow f, upsampling flow mask u, certainty c, sensitivity s를 위한 4개의 CNN 기반의 head에 이어 2개의 GenFlow 모듈이 붙은 형태입니다.
optical flow와 upsampling mask는 upsampling 된 optical flow를 생성한다고 했었는데요. 해당 flow는 GT optical flow와 L_{1} loss를 통해 학습이 됩니다. 또한 pose의 loss에 대해서는 point matching loss를 적용하여 분리된 학습을 하기 위해 물체에 대한 rotation, 2차원 상 물체의 중심점, depth를 개별적으로 학습을 하는데요.
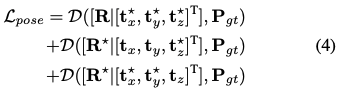
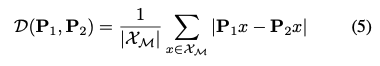
식(4)를 보시면 좀 더 이해하기 쉬울 것입니다. 먼저 (\cdot) 내부를 살펴보면 GT pose \mathbf P_{gt}가 주어졌을 때, 첫 번째 줄부터 (예측된 rotation + GT translation), (GT rotation + 예측된 2D center point), (GT rotation + GT center point + 예측된 depth)를 전체적인 GT를 서로 계산하여 loss를 계산합니다. \mathcal D는 3D 모델의 점 집합 \mathcal X_{\mathcal M}을 사용하는 두 6D pose인 \mathcal P_{1}, \mathcal P_{2} 사이의 거리를 의미하며, 식(5)와 같이 L_{1} loss로 계산하는 것을 확인할 수 있습니다.
certainty c는 init pose가 주어졌을 때 렌더링된 이미지를 입력 이미지(타겟)와 warping하여 projection 된 depth를 통해 타겟 이미지에 대한 depth를 얻을 수 있어 타겟에 대한 certainty c_{r \rightarrow t}도 같이 얻을 수 있습니다. 이를 통해 c와 c_{r \rightarrow t}간의 binary cross entropy loss인 L_{cert}를 통해 마스크를 생성하도록 학습합니다. certainty와 sensitivity에 대해서도 분리된 형태로 학습하기 위해 L_{pose} 계산할 때에는 certainty에 대한 역전파는 계산되지 않습니다.
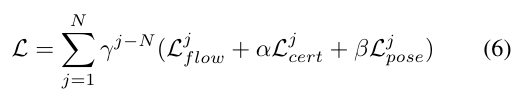
최종 loss는 식(6)과 같이 계산됩니다.
Experiments
Dataset
BOP core : LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HomebrewdDB, YCB-V
Evaluation Metrics
AR=\frac{AR_{VSD}+AR_{MSSD}+AR_{MSPD}}{3}- VSD(Visible Surface Discrepancy)
- 예측 pose와 GT Pose에서 렌더링된 depth 불일치로, 모든 점에 대해 고려하는 것이 아니라, visible region에 대해서만 측정
- MSSD(Maximum Symmetry-Aware Surface Distance)
- 대칭 정보를 고려하기 위해 예측된 pose와 GT pose 사이의 최대 거리를 계산
- MSPD(Maximum Symmetry-Aware Projection Distance)
- 예측된 pose와 GT pose에 대해 2D projection하여 좌표에 대한 최대 거리를 계산
BOP Benchmark Results
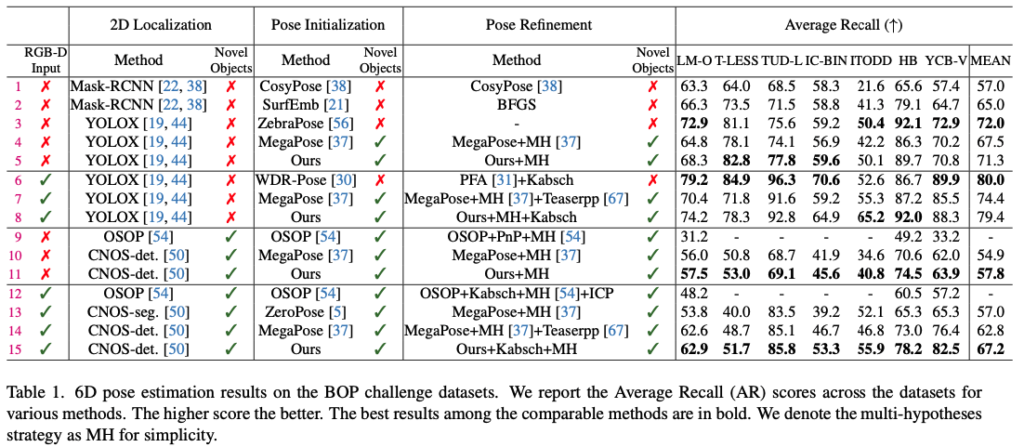
unseen 물체에 대한 결과는 입력 모달리티를 RGB만 사용한 9~11행과 RGB-D를 사용한 12~15행에 대해서 모두 비교 모델에 비해 성능이 우세한 것을 보여주고 있습니다. 참고로 Kabsch 알고리즘은 3D-3D correspondence를 생성하는 알고리즘입니다. RANSAC을 같이 사용하여 outlier를 제거하는 방식으로 사용합니다.
seen 물체에 대한 결과는 1~8행까지인데요. 타겟 데이터셋에 대해 학습된 2D detector에 대한 pose 추정 결과를 리포팅 하였습니다. 동일한 detector를 사용하여 비교를 해도 제안한 방법론이 MegaPose보다 우세한 결과를 보여주고 있네요.
Ablation study
Coarse Pose Estimation
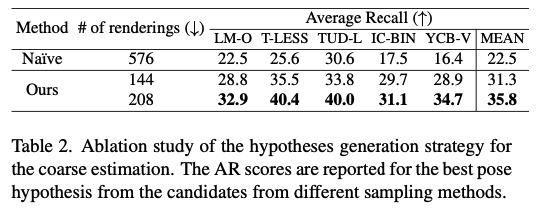
표(2)는 GMM 기반의 샘플링 방법에 대한 효과를 보여주는 실험 결과입니다. 576개의 rotation 샘플링에 비해 2M개의 렌더링(M=72, M=104)를 사용하는 것이 성능이 더 좋은 것을 확인할 수 있습니다.
GenFlow design
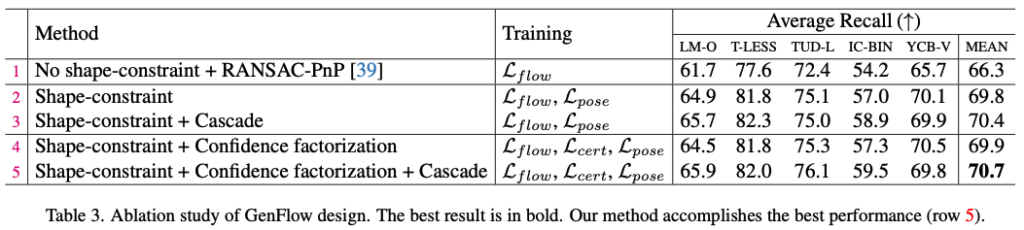
표(3)의 1행과 같이 \mathcal L_{flow}만으로 2D correspondence를 추정하는 학습 방법은 타겟에 대한 형태를 사용하지 않는 것이라고 볼 수 있습니다. 이는 6D pose 추정에 최적이 아니라고도 할 수 있겠네요.
이를 보완하여 2~5행과 같이 형태에 대한 제약(shape-constraint)을 준다면 3D shape에 대한 정보를 가이드하는 효과가 있는 것을 보여주는 결과네요. 또한, cascade로 confidence 분리를 통해 occlusion에 대해 강인한 6D pose를 얻을 수 있음을 증명합니다.
Conclusion
이번에는 refinement에 초점을 맞춘 GenFlow을 살펴보았습니다. GMM을 기반으로 하여 rotation에 대한 샘플링을 효과적으로 하여 refiner의 입력으로 줄 수 있었으며, 반복적인 refinement 과정을 통해 3D 형태에 대한 가이드와 함께 occlusion에 강인한 효과를 주어 비교 모델에 비해 우수한 성능을 보여주었습니다.
이상으로 이번 논문 리뷰 마치도록 하겠습니다.
감사합니다.
좋은 리뷰 감사합니다.
몇가지 질문이 있습니다.
1. 먼저 Coarse Pose Estimation단계에서 임의의 pose를 초기값으로 주고 이 pose가 refinement 가능한지는 어떤 기준으로 학습하게 되는 지 궁금합니다. (특정 score를 임계치를 두고 rotation이 그 이하의 오차인지를 분류하는 것인지 궁금합니다.)
2-1. cetrainty에 대해서, 초기 pose로 렌더링된 depth와 target 이미지에 대한 depth를 비교하여 다른 객체에 가려진 영역에 대한 정보를 파악하고자 한 것으로 이해하였습니다. 여기서 certainty c에 대한 loss를 계산할 때, 초기 pose를 신뢰하는것인가요?? 또한, 이 둘 사이의 어떤 기준을 주어 binary cross entropy로 계산하는 것인지 궁금합니다.
2-2. 또한, sensitivity는 어떻게 정의하여 loss를 구하는 것인지 확인이 어렵습니다. 이에 대해 조금 더 설명해주실 수 있나요??
3. 마지막으로 해당 방법론이 refinement에 집중한 방법론인데, 혹시 반복 횟수는 어떻게 정해져있는 지 궁금합니다.(다른 방법론과 공정한 비교가 가능한 세팅인지도 궁금합니다!)
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. coarse pose를 refiner로 넘겨줄 때 top-K를 뽑아서 넘겨주게 됩니다. top-K를 뽑는 기준은 threshold를 두는 것은 아니고 단순히 classification을 수행했을 때 확률이 가장 높은 pose들로 넘겨주는 것으로 주게 됩니다.
2. 초기 pose를 신뢰한다고 가정을 하고 타겟에 대한 certainty와 비교를 하게 됩니다. 이로써 c(렌더링) 와 C_{r→t}(렌더링 된 depth를 타겟으로 변환한 것)를 비교하여 각 픽셀에 대한 BCE loss를 통해 마스크를 생성하도록 합니다. 또한 sensitivity는 optical flow를 기반으로 물체의 텍스처와 edge 영역에 대해 강조하기 위해 설계되었으며, 이에 대한 loss는 식(4)는 GT에 비해 예측된 rotation, 2D center point, depth를 비교하여 얼마나 다른지를 측정하게 됩니다.
3. 최적의 성능은 8번을 반복하여 리포팅을 하였고, MegaPose와 공정한 비교를 위해 5번까지 돌린 결과가 리포팅되어 있습니다. 첫 번째 반복을 돌때부터 성능차이가 확실하게 나며, 모든 결과에 대해서 GenFlow의 refiner가 우세한 결과를 보여주고 있습니다.
감사합니다.