안녕하세요. 이번 리뷰는 YOLO (You Only Look Once)를 베이스로 한 Open-Vocabulary Object Detection (통칭 OVD) 연구입니다. Arxiv에 며칠 전까지 수정된 따끈따끈한 논문이네요. 지난 리뷰에서 새로운 태스크들에 대한 간략한 설명은 PapersWithCode에서 보면 좋다고 말씀드렸는데, OVD 태스크를 처음 들어본 분들도 있으리라 생각이 들어 함께 살펴보겠습니다.

OVD는 학습 시의 제한된 수의 클래스를 넘어선 일반화를 목표로 하며, 이는 다른 말로 추론 시 정해지지 않은 무제한의 (open) 단어들에 대한 새로운 클래스를 탐지하는 것을 목표로 합니다. 목표만을 생각했을 시에는 Open-World Obejct Detection (OWOD)와 분명한 차이는 없으나, OVD는 추론 시 정해지지 않은 (학습 시 보지 못한) 클래스가 포함된 텍스트를 입력으로 받아 해당 클래스들을 포함한 이미지-텍스트 간 매칭을 중요시 여기는 반면, OWOD는 해당 novel 클래스에 대해 ‘Unknown’으로 인지한 이후 Incremental learning을 통해 ‘Unknown’으로 인지된 클래스에 대해 실제 해당하는 클래스로 인지하도록 학습한다는 점에서 미세한 차이를 보입니다. 어찌되었든 제가 하고자하는 연구 방향은 자율 주행 상황을 전제로 하므로, 이 때는 사용자가 특정 입력 구를 실시간으로 넣긴 어렵다는 점을 염두하여야 합니다. 하지만 자율 주행을 위한이 아닌 주행 시의 사용자와 상호 교류를 통한 시스템 관점에서는, 예를 들어 자율 주행 차 내의 사용자가 “저기 보이는 고양이의 품종을 알려줘”, “검정 상의를 입은 남성의 옷 브랜드를 알아봐줘” 등을 음성 입력 시 이를 수행해낼 수 있는 관점에서는 유용해보입니다 (물론 지금 말한 예시들은 지금은 뜬 구름 잡는 소리로 들릴 수도 있겠지만, 이런 예시로 사용될 수도 있다는 점을 강조하고자 하였습니다). 그럼 2024 신상의 OVD 연구는 어떻게 진행되는지, 바로 살펴보겠습니다.
Introduction
앞서 말한 OVD의 목표에 반하여, 현존하는 Object Detection (이하 OD) 연구는 탐지 시 사전에 정해진 범주 이내의 객체를 탐지하는 것이 목표입니다. 이는 다시 말하여 탐지할 수 있는 객체 수가 한정적이며 (Fixed-vocabulary), OD의 대표 데이터인 COCO는 80개의 클래스만 존재하므로, mAP가 100이여도 81번째의 새로운 클래스 (Novel class) 에 대해서는 탐지하지 못하는 한계가 있습니다. 이를 극복하고자 OVD 태스크가 등장하였고, 최근의 Vision-language Model (VLM)은 BERT 등의 Language Model로부터 얻은 지식을 활용하는 방식으로 수행되었습니다. 하지만 이들의 방식은 학습 데이터 내 어휘의 다양성이 한정적이며 학습 데이터가 부족하다는 아쉬움이 있습니다. 예를 들어 COCO를 기반으로 만든 OV-COCO 데이터의 경우, 텍스트 데이터와의 매칭을 고려해야하므로 총 48개의 클래스만이 존재합니다. 또 다른 방식으로는 대표적으로 Faster R-CNN의 RoI를 활용하여 Region-level로 대량의 Vision-language 데이터를 사전 학습하는 형태로 활용하여 효과를 보았지만, 저자는 이들의 방법이 실제 세계의 시나리오에서 활용되기엔 두 측면의 문제점이 있음을 지적합니다. 첫 번째는 해당 방법들의 연산량이 부담되며, 두 번째는 엣지 디바이스에 배포되기엔 모델의 구조가 너무 복잡하다는 문제입니다. 또한 이들의 방법들은 탐지 성능에만 집중하여 대형의 모델을 사전 학습하는 방식이 유망한 성능을 보임을 확인했지만, 비교적 소형의 모델을 사전 학습하는 방식으로 OVD에 좋은 효과를 보는 방식에 대해서는 아직 연구되고 있지 않았습니다.
저자는 위의 문제점들에 대비하여, 고효율의 모델을 목표로 하고자 YOLO를 활용한 OVD 모델을 제안하며, 기존의 YOLO 모델이 대규모의 사전 학습에 적응하고자 하는 방식을 탐색합니다. YOLO-World 모델의 구조는 YOLOv8과 CLIP로 구성하였으며 이외 이미지와 텍스트의 정보를 연결하고자 Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN)을 제안합니다. 흥미로운 점으로는 추론 시에는 텍스트 인코더를 제거하여 사용할 수 있다는 점인데, 텍스트 임베딩을 RepVL-PAN의 가중치로 매개변수화하여 Offline-vocabulary를 활용한다는 점입니다. 추론 시 텍스트 인코더를 제거함으로써 모델은 더 가벼워지며 배포에도 효율적일 수 있지만, 우리가 알아야할 점은 텍스트 인코더가 없다는 것이 텍스트 자체가 없다는 점은 아니란 점이죠. 이를 위해선 이전 문장의 Offline-vocabulary에 대해서도 이해함이 좋겠으며, 이는 뒤에서 다시 설명하겠습니다.
추가적으로 YOLO를 Open-vacabulary에 대해 사전 학습하고자 대규모의 데이터에 대한 Region-text contrastive learning 방식을 제안합니다. 이는 뒤에서 다시 살펴볼 예정이며, 이외의 Detection, Grounding (Visual-Grounding), 그리고 Image-Text 쌍의 데이터를 통합하여 재구성한 Region-Text 쌍에 대해 대규모로 학습한 YOLO-World 모델은 VOD 태스크 외 다른 다운스트림 태스크에 대해서도 좋은 성능을 보인다고 합니다.
마지막으로 저자는 Prompt-then-detect 패러다임을 제안하는데, 해당 패러다임은 실세계의 시나리오 상 모델의 효율성을 높이고자 한 방식으로, 다음의 Figure 2에서 (a) 전통적인 Object Detector는 Fixed-vocabulary (Closed-set)에 대해서만 집중하여 새로운 클래스를 추론하지 못하는 문제점, (b) 이전 OV Detector는 ATSS, DINO, Swin 등의 무거운 백본을 사용하여 추론 속도가 느리다는 문제점에 반해 (c) 제안하는 YOLO-World의 Prompt-then-detect는 유저의 Prompt로부터 Offline-vocabulary를 구축하며, 프Prompt를 다시 인코딩할 필요 없이 사전에 인코딩한 Offline-vocabulary를 활용하여 효율적으로 대처할 수 있습니다.

Related Work
우선 OD에 대한 문제점은 Introduction에서 자세히 다루었으니, 지금은 현존하는 OVD 연구 몇몇만 살펴보겠습니다. 1. OWL-ViTs: Detection과 Grounding 데이터에 대해 ViT를 Fine-tuning 하는 방식의 원초적인 모델입니다. 2: GLIP: Phrase grounding를 사전 학습하여 OVD 태스크에 활용한 모델이며, Zero-Shot Object Detection (ZSOD)에서도 평가하였습니다. 3: Grounding DINO: DINO를 활용하여 Grounding 데이터에 대해 사전 학습한 모델을 Cross-modality Fusion을 통해 Detection Transformer에 통합합니다. 이외의 다양한 방법들은 BBox와 텍스트 간의 Region-text 매칭을 통해 Detection 데이터 (e.g. COCO)와 Image-Text 데이터 (e.g. Visual-grounding)를 통합하여 대규모로 Image-text 쌍의 데이터를 사전 학습하는 방식을 활용합니다.
Method
Pre-training Formulation: Region-Text Pairs
YOLO는 \Omega = \left\{\Beta_{i}, c_{i} \right\} 형태인 {Box, Category}의 Instance Annotation에 대해 학습합니다. 이번 논문에서 저자는 VOD에 맞추어 해당 포매팅을 Region-text 쌍인 \Omega = \left\{\Beta_{i}, t_{i} \right\}_{i=1}^{N} , {BBox, Text}로 재포매팅하여 학습에 활용합니다. 이 때의 Text는 BBox에 해당하는 Category (클래스 명), Noun phrase (명사구), 또는 Object Description (객체에 대한 설명)에 해당합니다. 또한, 제안하는 YOLO-World는 이미지와 텍스트를 입력으로 받아, 객체 검출을 위한 BBox \left\{\Beta_{k}\right\} 및, 이에 해당하는 Object의 임베딩 \left\{e_{k}\right\} 를 출력합니다.
Model Architecture
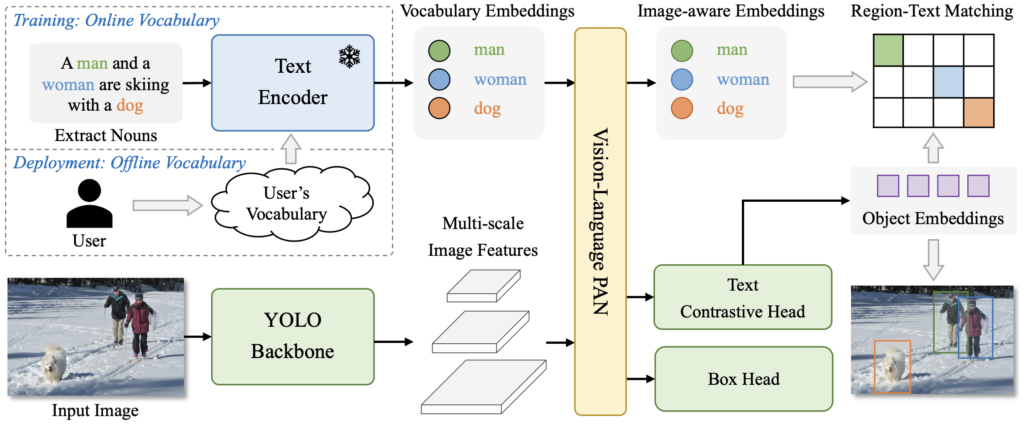
위의 Fig 3은 YOLO-World의 구조를 나타냅니다. 모델은 YOLO (이미지), CLIP (텍스트), 그리고 RepVL-PAN으로 구성되어 있습니다. 하나씩 살펴보겠습니다.
- YOLO Detector
입력 이미지에 대해 Visual Feature를 추출하고자 YOLOv8을 사용합니다. YOLOv8에 대해 자세히는 모르나 YOLO의 백본인 Darknet을 사용하며 Path Aggregation Network (PAN, FPN과 유사)을 통해 Multi-scale의 Feature를 추출합니다. - Text Encoder
입력 텍스트에 대해, 사전 학습된 CLIP을 사용하여 텍스트 임베딩을 추출합니다. 이 과정은 다음과 같이 표현할 수 있습니다. W = TextEncoder \left(T \right) \in \mathbb{R}^{C \times D} . 이 때의 C와 D는 각각 명사 단어의 수, 임베딩 차원입니다. CLIP은 객체의 Visual 정보와의 연결에 중요한 역할을 하며 텍스트만 이용하는 인코더에 비해 이미지와 유사도를 통해 계산한다는 점에서 유의미합니다. 만약 입력이 Caption 또는 Referring Expression이라면, N-gram 알고리즘을 통해 임의의 개수만을 뽑아 명사구로 만들어 인코더의 입력으로 삼습니다. - Text Contrastive Head
YOLOv8을 따라 BBox에 대한 Regression, Feature 임베딩을 위한 Head를 따로 두며 이에 더불어 객체와 텍스트 간의 유사도 계산을 통한 Text Contrastive Head를 제안합니다. YOLO Detector에서 추출한 Visual 임베딩과, 텍스트 임베딩 사이의 Contrastive Head를 통해, 두 Feature간 유사도를 계산하며 이 때 \alpha, \beta 는 각각 Scaling, Shifting Factor로 Affine Transformation에 대한 학습 가능한 파라미터입니다. 이는 이미지와 텍스트 Feature 간 데이터의 분포를 맞추어 주어 학습을 안정시키는 효과가 있다고 합니다.
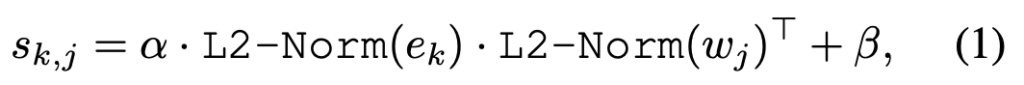
- Training with Online Vocabulary
학습에서는 YOLO의 Augmentation인 Mosaic Sample에 대해 (랜덤한 이미지 4개를 붙여 하나로 만듦, YOLOv4에서 처음 소개됨) Online-vocabulary를 설정하여 학습합니다. Online-vocabulary란 웹 등을 통해 실시간으로 업데이트되는 어휘들을 일컫으며, 고로 다양한 표현을 포함합니다. 각 Mosaic Sample에서는 최대 80개에 해당하는 단어들을 샘플링하며, 이 샘플링에는 Positive (실제 이미지에 매칭되는) 단어 외에도 Negative 단어 (이미지와 연관성이 없는)를 포함시켜 이들을 구분하여 Positive와 매칭시키도록 구상하였습니다. - Inference with Offline Vocabulary
추론 시에는 앞서 언급한 Prompt-then-detect 전략을 활용합니다. Fig 3을 살펴보면 유저로부터 입력 받은 Prompt (캡션 등) 를 인코딩 한 다음, Offline-vocabulary 임베딩을 포함하는 Offline-vocabulary 텍스트 임베딩 생성하며, 이 Offline-vocabulary의 텍스트 임베딩을 활용하면 각 입력에 대한 추가적인 계산을 하지 않아도 되는 효과를 얻을 수 있습니다.
Re-parameterizable Vision-Language PAN
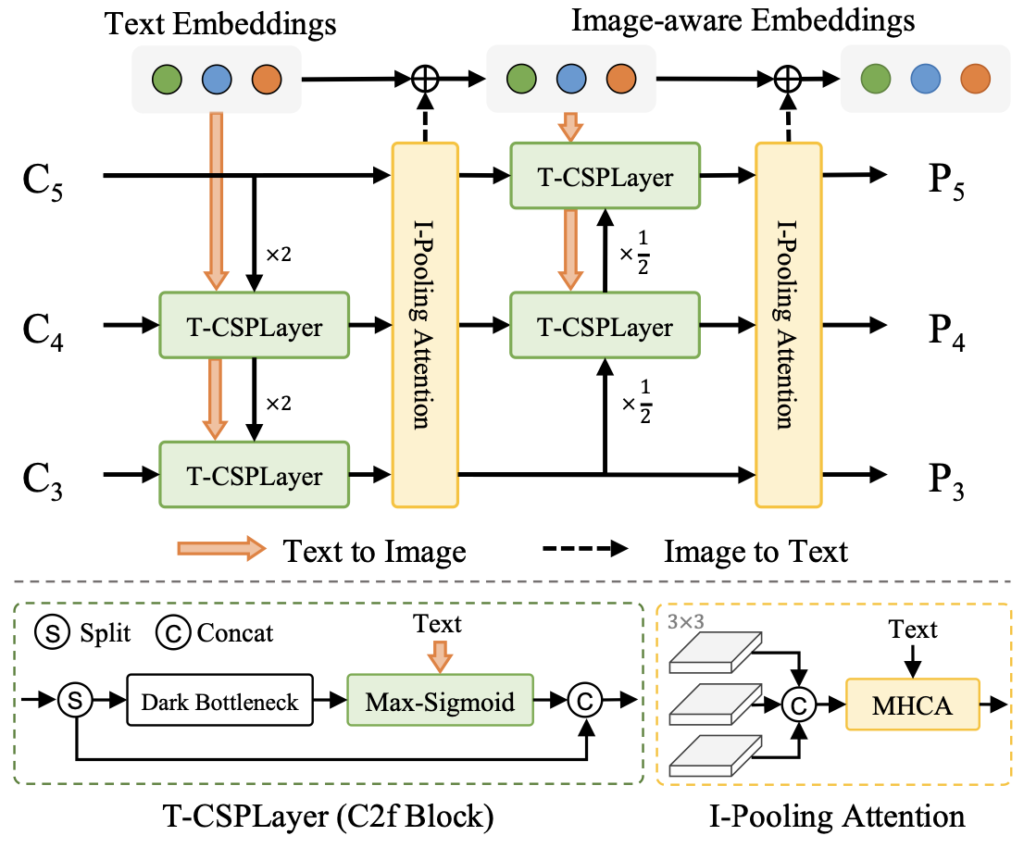
Fig 4는 RepVL-PAN의 구조로, YOLO의 Path Aggregation Network (PAN, FPN과 유사)을 통해 추출한 Multi-scale Feature map인 C_3, C_4, C_5 에 대해 다룹니다. 저자는 Text-guided CPSLayer (T-CSPLayer)와 Image-Pooling Attention (I-Pooling Attention)을 추가적으로 제안하는데, 이들의 개념이 어렵지 않으면서 목적이 이미지와 텍스트의 Feature 간 상호작용을 강화하는데 있다고 생각하시면 됩니다. 또한 Re-parameterizable에서 알 수 있듯 추론 시 위의 Inference with Offline-vocabulary에서 소개한 Offline-vocabulary 텍스트 임베딩을 Convolution이나 Linear 레이어의 가중치로 파라미터화하여 사용함으로써 배포 시 효율적임을 언급합니다.
- Text-guided CSPLayer
기존 YOLO의 CSPLayer는 Top-down, Bottom-up으로 FPN과 유사한 역할을 효율적으로 (그레디언트를 끊어) 하기 위해 설계된 레이어로 저자는 이를 텍스트 정보를 넣는 방식으로 확장합니다. 이는 아주 단순한 방법으로, 텍스트 임베딩 W 와 이미지 피쳐 X_l \in \mathbb{R}^{H \times W \times D}, l \in \left\{3,4,5\right\}를 곱한 이후, max-sigmoid attention (max 값만 추출한 이후 시그모이드) 연산을 하여 연관성이 높은 값들만 추출해내겠다는 방식이죠. 아래의 수식으로 표현할 수 있습니다. 업데이트 된 이미지 피쳐 X_{l}^{'} 은 각 Multi-scale Feature와 다시 합쳐져 출력으로 나옵니다.
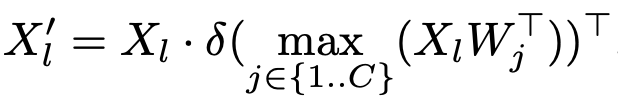
- Image-Pooling Attention
텍스트 임베딩에 이미지에 대한 정보를 결합하고자, Transformer의 Multi-Head Attention (MHA)을 활용합니다. 텍스트 임베딩과 이미지 간 연관성 (유사도) 계산을 다른 방식으로 한번 더 하죠. 방식은 아주 쉽게, 앞서 언급한 이미지 피쳐들, X_l \in \mathbb{R}^{H \times W \times D}, l \in \left\{3,4,5\right\} (T-CSPLayer를 통과한 이후)에 대해 3개의 Feature map에 Max pooling하여 3×3 크기로 맞추고, 그렇기에 총 (3×3)x3 (Feature map 크기 x 3개), 27개의 패치를 얻을 수 있습니다. 해당 27개의 패치에 대해 텍스트 임베딩과 MHA를 통해 텍스트 임베딩의 정보를 강화시킵니다.
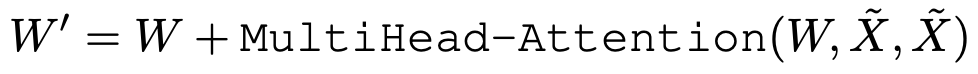
Pre-training Schemes
이제 다 왔습니다. 마지막으로 YOLO-World를 학습하기 위한 데이터 구축 및 손실 함수를 살펴보고 방법론을 마치겠습니다. 무엇인가 굉장히 많은 내용들이 짤막하게들 적혀있는데, YOLO의 최신 버전들처럼 몸에 좋다는 것들을 마구 결합한 집합체 느낌이 나네요. Open-vocabulary와 Offline-vocabulary는 의미가 명확하게 느껴지지 않는 점이 있는데, Appendix에 있는대로 Labeler의 입장에서 이 둘을 웹 상 정보, 사전의 정보로 생각하면 다소 이해됩니다.
- Learning from Region-Text Contrastive Loss
직전 리뷰한 MDETR 논문에서도 Image-Text 간의 Contrastive Loss를 통해 동일하게 맞춘 Feature Space상 Positive 간 유사도를 끌어올리는 효과, 이를 Alignment로 표현하는데 크게 다를 바 없습니다. 이에 더불어 CLIP을 떠올렸을 때 모델의 결과에 대해, Positive인 예측에 대해 해당하는 텍스트 인덱스에 부여하기 위한 Contrastive Loss입니다. 어찌되었든 기본적인 BBox Regression도 포함되어야 하니 IoU Loss와 Focal Loss를 활용하였고, 따라서 전체적인 Loss는 아래와 같이 정의됩니다. 수식에서 \lambda_{I} 는 Indicator Factor로, 입력 이미지가 Detection이나 Grounding 데이터로부터 온 이미지면 1 (BBox Regression을 포함하도록), Image-Text 데이터로부터 온 이미지면 0 (해당 데이터에서는 정확하지 않은, Noisy한 BBox들이 많아 이미지-텍스트 간 Contrastive만 고려하도록) 으로 설정합니다.
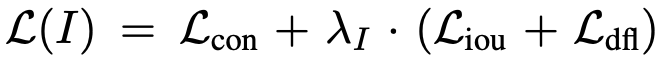
- Pseudo Labeling with Image-Text Data
바로 위에서 Image-Text 쌍의 데이터에 Noisy한 BBox들이 많다고 했는데, 그러므로 바로 활용하기 보단 저자들은 Automatic Labeling을 통해 Regioin-Text 쌍의 Pseudo Label을 생성합니다 (몇몇은 이미지와 해당 캡션만 존재하는 Image-Text 데이터에서, 객체의 BBox에 해당하는 Category를 부여). 이를 위해선, 기존의 방법들을 모두 활용하였네요. (1) N-gram 알고리즘을 활용해 텍스트에서 정해진 수의 명사 구만 추출하였으며, (2) 사전 학습된 OVD, GLIP을 활용해 각 이미지에 추출한 명사 구에 대한 Pseudo BBox를 생성합니다. (3) CLIP을 활용해 Image-Text 간 연관성과 Region-Text 간 연관성을 평가하고, 연관성이 낮은 Label을 제거합니다. 추가적으로 Noisy한 BBox들이 더 존재할 수 있으므로 NMS를 통해 객체 당 하나의 BBox를 선정하고자 노력하였으며, 이를 통해 CC3M (이미지에 대한 캡션이 존재) 데이터에서 246K 개의 이미지로부터 821K 개의 Pseudo Annotation을 생성하였습니다. 기존 데이터에선 BBox 정보가 없었던 점, 해당 이미지에 대한 캡션만 존재하였단 점을 고려하면 꽤나 유의미한 데이터 구성 과정이라고 보여집니다.
Experiments
주목할만한 점으로, 추론 시에는 V100 한 장을 활용하여 모든 모델의 속도를 평가하였는데 학습 시에는 V100 32장을 활용하였다고 합니다. 그걸 보자마자 떠오른 점은 “연구실 레벨에서 지금의 연구를 하려면 사전 학습된 모델을 더욱 활용해야하나”입니다. End-to-End로 모든 과정을 학습하는 것은 현재는 어려워보입니다.
- Pre-training Data
사전 학습에 활용한 데이터로는, Detection (Object-365)와 Grounding (GQA, Flickr) 데이터를 활용하였으며 앞서 Pseudo Labeling에서 설명한 Image-Text로부터 생성한 CC3M도 활용하였습니다. 아래의 표를 살펴보시죠. 굉장한 수준의 Image와 Annotation이 존재합니다. 왜 32장이나 필요한지도 이해되네요.
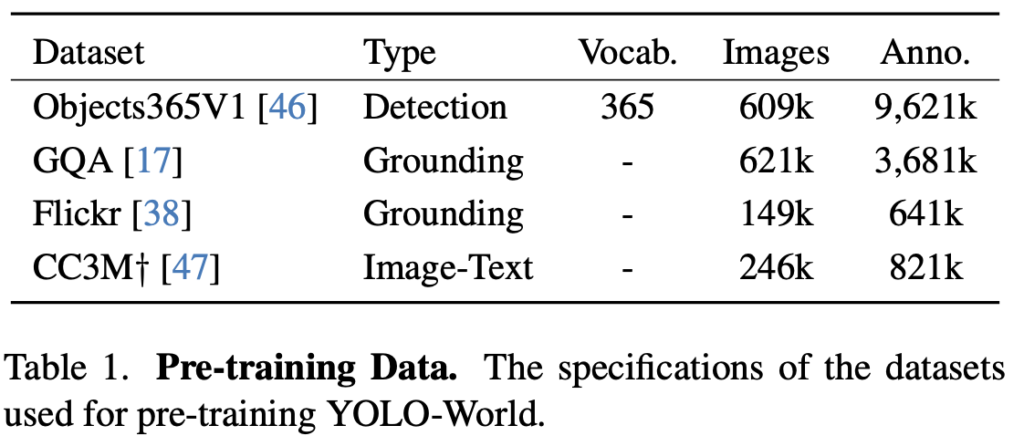
- Zero-shot Evaluation – Main Results on LVIS Object Detection
사전 학습 이후, LVIS 데이터 (몇몇 소수의 클래스가 데이터의 대부분을 차지하고, 나머지의 대부분은 데이터의 양이 부족한 Long-tailed의 instance segmentation 데이터)에 대해 Zero-shot 방식으로 평가하였습니다. 해당 데이터에는 1203개의 카테고리가 존재하여 사전 학습한 데이터의 카테고리보다 많아 성능을 평가하기 좋았다고 하네요. 아래 Table 2의 성능을 살펴보면 MDETR, GLIP 등이 보이며, MDETR을 제외한 다른 모델들은 모두 백본으로 Swin Transformer를 사용하여 파라미터 수에서 어마어마 하네요 (물론 ResNet-101도 파라미터 수는 많음을 알 수 있습니다) 가장 주목해야할 점은 FPS로 보이는데, YOLO-World-S의 경우 무려 74.1의 FPS, YOLO-L로 가도 52의 FPS인데 SoTA의 성능을 보입니다. (참고: AP_r, AP_c, AP_f 는 각각 카테고리의 빈도 수에 따라 Rare, Common, Frequent로 분류합니다.
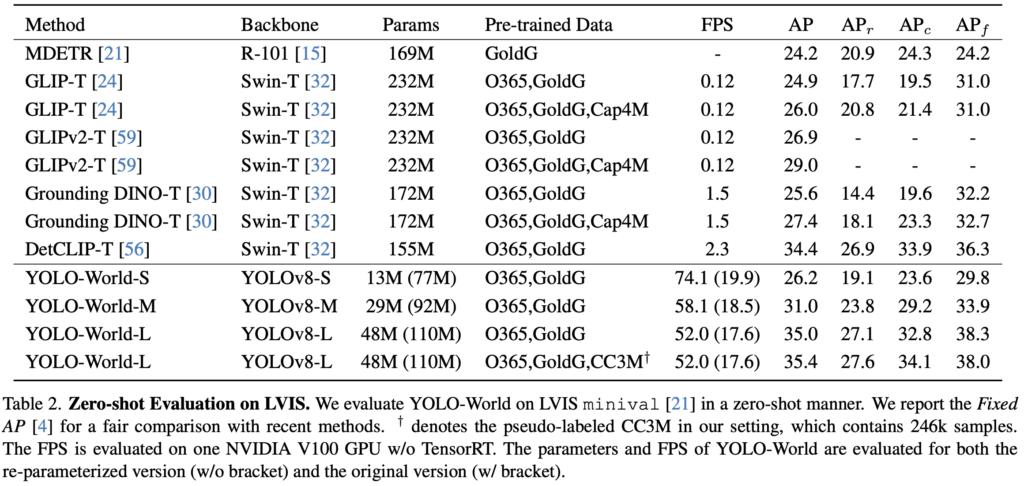
Ablation Experiments
YOLO-World-L으로 LVIS 데이터에서 Zero-shot Evaluation한 다양한 Ablation입니다. Table 3의 사전 학습 데이터를 많이 사용할 수록 더 좋은 성능을 보인다는 것이 입증되며 (저자는 이에 대해 “Table 3 demonstartes that adding more data can effectively improve the detection capabilities on large-vocabulary scenarios”로 설명합니다) “GQA 데이터를 포함시켰을 때의 성능 향상에 주목하고 있네요. 음, CC3M 데이터를 포함시켰을 때 Frequent Object에 대한 성능이 소폭 하락하는데, 이에 대한 저자의 고찰이 있을까 찾아보았지만 전체 AP만 언급되었을 뿐, 추가적인 설명은 없네요. 제 생각이건데 CC3M 데이터로부터 생성한 BBox는 Pesudo Labeling된 BBox이므로 오히려 데이터 양이 상대적으로 많은 Frequent 클래스에 대해선 노이즈로 작용했을 수 있지 않을까 싶습니다.
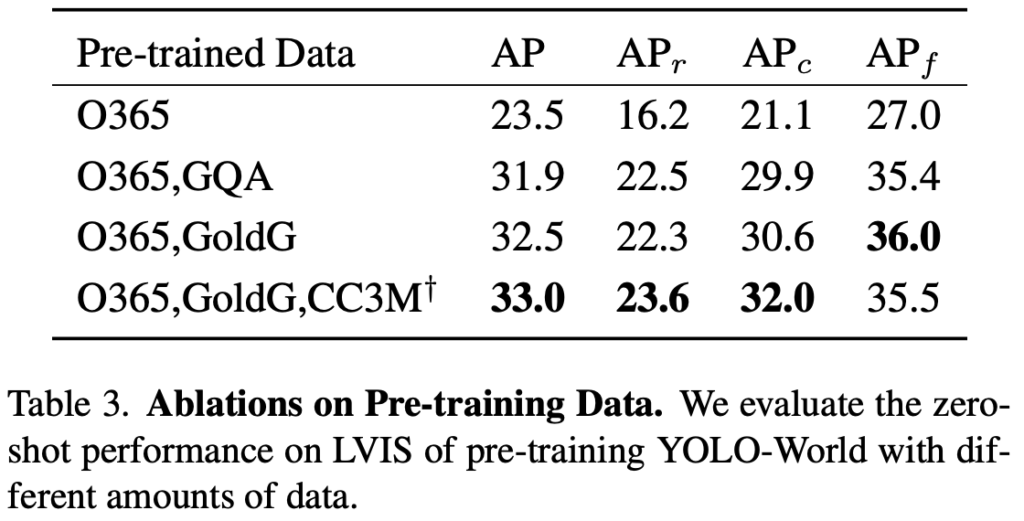
다음은 RepVL-PAN에 대한 Ablation (앞서 설명한 Text-guided CSPLayer과 Image-Pooling Attention)인데, 해당 표를 들고 온 이유는 아직 개제 이전으로 보이나 표의 캡션만 보면 T->I는 Text-guided CSPLayer, I->T는 Image-Pooling Layer로 보이는데, 왜 이렇게 표기한지 의문입니다. (T, I로만 표기했으면 좋았을텐데, 저는 순서인줄 알고 해당 Table 및 RepVL-PAN을 한참 다시 봤네요) 그보다 RepVL-PAN을 통해 1.6% 가량 성능을 향상하였지만, GQA 데이터를 포함시키는 것이 성능엔 정말 유의미하네요.
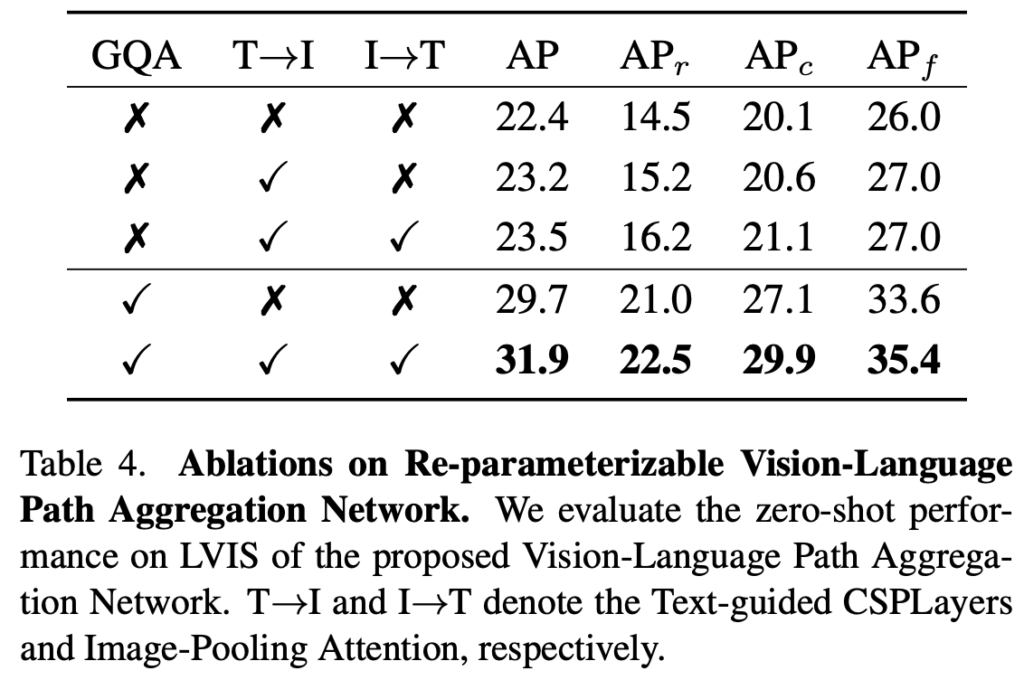
다음으로는 Text Encoder에 대한 Ablation으로 BERT에 비해 이미지와의 연관성을 보도록 설계된 CLIP의 형태가 더 좋은 성능을, 그 때 Fine-tuning하는 것 보다 Frozen하는 것이 더 좋은 성능을 보인다고 합니다. 아마 이 또한 다른 데이터들의 Noisy함 때문인지, 보통 우리가 아는 바와 같이 Fine-tuning이 더 좋은 성능을 보이진 못하네요.
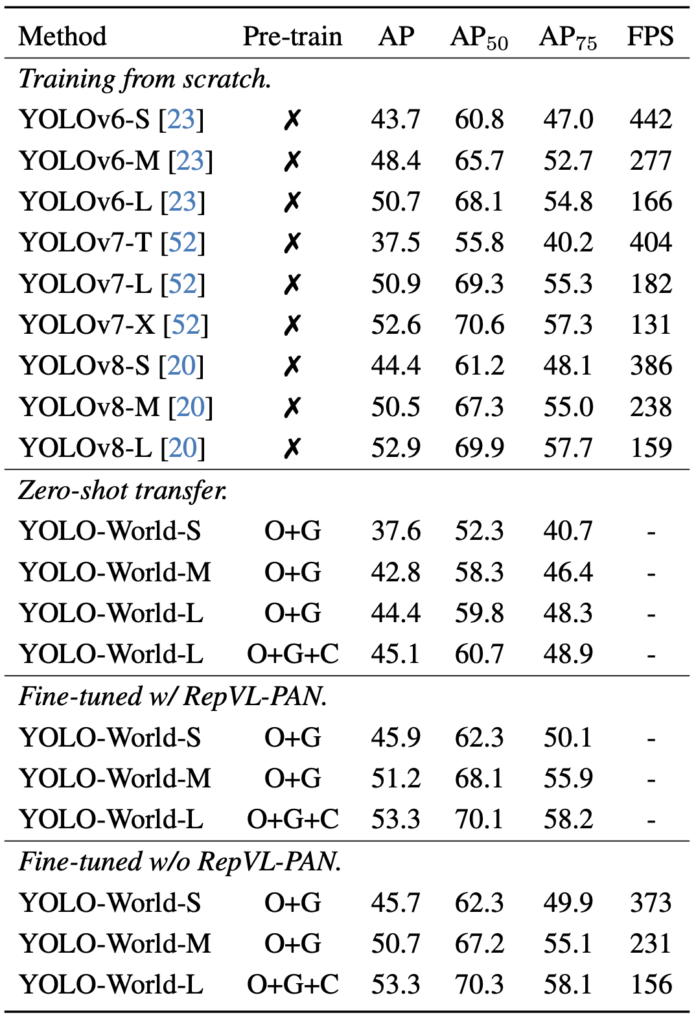
마지막으로, 그 유명한 COCO에서의 성능입니다. 사실 성능도 타 모델 대비 좋지만, 그보다 FPS에 집중하고 싶은데 YOLO 모델이 이렇게까지 빠른지는 몰랐네요. YOLOv8-L을 베이스 네트워크로 삼지만, YOLOv6-S의 경우 442 FPS가 나옵니다. Zero-Shot 성능과 RepVL-PAN에 대한 Fine-tuning 성능도 나오는데, 파라미터 수에 대한 내용은 당장 없지만 이렇게 보았을 때 YOLO가 정말 좋네요.
앞으로도 관련 해당 논문들을 살펴볼텐데, 현재까지는 큰 감이 잡힐듯, 잡히지 않을 듯 합니다. 문제점 발견이야 관련 논문을 많이 읽어보지 못하여 그렇다한들, 현재까진 대형 기업에 압도당하는 기분이네요 허허
안녕하세요, 좋은 리뷰 감사합니다.
OVD/OWOD에 대한 차이점을 풀어서 설명해주셔서 이해하는 데 도움이 되었습니다. 확실히 YOLO 기반의 연구라 FPS가 엄청 차이가 많이 나네요.
1. 간간히 VOD가 나오는데, OVD를 의미하는 걸로 이해하고 넘어갔는데, 맞나요?
2. Text Contrastive Head를 설명하시는 부분에 s_{k, j} 를 계산하는 데 e_{k}와 w_{j}는 무엇을 의미하나요?
3. Offline Vocabulary이 흥미로운데요, 해당 방법론은 그럼 예시로 하신 것처럼 웹상이 아닌 사전의 정보인데, 사전의 정보면 어느정도를 담고 있는지 궁금하네요. 정보라고 하면 크면 다다익선 이겠지만, 저자는 추론 속도 측면을 고려하게 된다면 이러한 Offline Vocabulary는 규모가 어느정도인지가 궁금하네요. 해당 방법론은 선행연구로 사용되는 방법론인가요 아니면 이번 논문에서 처음으로 제안한 것인지도 궁금합니다.
감사합니다.
네 안녕하세요. 리뷰 읽어주셔서 감사합니다.
1. 넵. OVD입니다. VOD로 표기된 부분은 오타입니다. ^_^
2. e_{k}는 Object에 대한 정보 (BBox 내 객체에 대한 임베딩 정보), w_{j}는 텍스트 인코더를 통해 나온 텍스트 임베딩 정보입니다.
3. 우선, 아쉽지만 저는 Online Vocabulary와 Offline Vocabulary에 대해 몇몇 글들을 살펴보며 추론해냈는데, Offline Vocabulary에 대한 정의를 찾아볼 수 없었습니다. 그렇기에 해당 규모를 알 수 없었는데 이 Online-Offline이 평소의 OVD 연구에 사용되는지를 조금 더 봐야할 듯 합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
YOLO의 입력 형태에서 텍스트는 명사구 혹은 객체에 대한 설명 둘 중 하나만 들어갈 수 있나요 ?? 문장 형태로 들어가게 되었을 때 N-gram 알고리즘으로 임의의 개수만을 뽑아 명사구로 만든다는 것은 문장을 랜덤하게 분할하여 그 안에 들어가있는 명사를 이용하여 명사구로 만든다는 의미가 맞을까요?
그리고 Image-Text 데이터에서 노이즈가 존재하는 BBox라는 것은 무엇을 의미하는지 .. 단순히 텍스트와 매칭되지 않는 FP와 같은 개념의 bbox를 의미하는걸까요?
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
N-gram 알고리즘은 자연어처리와 관련된 알고리즘으로 문장에 대해 알고리즘의 결과로 몇몇 명사를 뽑는 알고리즘으로 보입니다 (자연어처리에서 어렵지 않은 알고리즘으로 보이나, 그 의의가 더 중요하다고 생각 들었기에 해당 알고리즘의 동작 과정까진 찾아보지 않았습니다). 예시로 명사는 “Man”, 명사구는 “A fliying Man”과 같이 되는데, N-gram 알고리즘에선 명사들이 나온다고 보는게 맞을 것 같네요.
Image-Text 데이터, 예를 들어 VQA 데이터는 본래 BBox가 존재하지 않습니다. 이미지에 대한 캡션 (질문 등, VQA여서 이미지에 대한 설명이라고 하긴 모호하지만)이 주어진 이후, 논문의 방식대로 Pseudo BBox를 생성해내죠. 그렇기에 정확지 않은 BBox일 수 있고, 이를 노이즈하다고 표현합니다.
리뷰 잘 읽었습니다.
리뷰 최상단부, Introduction의 위쪽 영역에서 OVD와 OWOD의 차이점 설명이 매우 잘 읽히네요.
제가 이해한 바로는 OVD와 OWOD의 목적 자체는 ‘open class에 대한 일반화된 detect’ 로 동일하다. 다만 OVD는 text 입력이 필요한 반면, OWOD는 text가 필요한건 아니지만 추가적인 Incremental learning이 필요하다.
—-
그럼 여기서 OWOD를 OVD의 발전된 연구(?)로 생각하면 되나요?
아니면 OWOD는 OVD와는 달리 추가적인 Incremental learning stage가 필요하기 때문에 발전된 연구라기 보다는 결이 조금 다른 연구인가요??
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
음. 저는 원래 OWOD 논문을 읽으려다 OVD가 선행된 연구로 느껴져 해당 논문 몇몇을 살펴보고 있는데요, 제가 느끼기엔 발전된 연구는 아니고.. 아까는 제가 포함관계라고 설명드렸지만, 이는 목표로 하는 점은 비슷하 (Unseen Object에 대한, Vocabulary 내에 있지 않은 Object에 대한 탐지)지만, 그 방향이 조금 OWOD가 발전된 것 같아서 그렇게 말씀드렸습니다.
다시 말씀드리는 바처럼 OVD가 Vocabulary 내, 즉 학습하지 않은 클래스 내의 객체에 대한 탐지를 목표로 함은 맞고, OWOD도 그 Goal 자체는 동일하나 OWOD는 Incremental Learning (Online-Learning과 같은) 등으로 사람이 새로운 클래스의 물체에 대해 인지해내는 것과 같이 해당 클래스에 대해 관심을 가지다가, 한 번 해당 클래스의 정보를 알고 나면 그 물체를 앞으로는 잘 탐지하는 것과 같이 (그 과정까지 포함되어야 OWOD, Unseen에 대해서도 Text 등을 통해 BBox를 찾아내면 OVD), 조금 미묘한 차이가 있는데 참 얘는 얘와 정확히 어떻게 다르다고 설명드리긴 쉽지 않습니다.