안녕하세요. 오늘은 workshop 논문이긴 하지만, ViSiL 저자의 가장 최근 논문을 가져왔습니다. Self-supervised video retrieval & detection 논문인데… 모델은 ViSiL과 동일합니다. DnS 때도 그랬는데, 아마 확장 연구 개념으로 생각하는 것 같습니다.
Introduction
최근 video self-supervised learning과 관련된 논문을 많이 읽고 있는데요. 대부분의 논문들은 video action classification에 사용하기 위해, video representation을 학습하는 연구들이었는데요. 드디어 video retreival에서도 video self-supervised learning이 등장했습니다. (저도 한번 해볼까 하고 생각중인 내용이어서 관심이 있었습니다.) 본론으로 들어가기 전에 간단하게 연구 흐름을 조금 정리해보자면 ViSiL이 VCDB라는 데이터셋을 활용한 지도학습 방법론이고요. 그 뒤에 나온 DnS라는 논문이 DnS라는 데이터셋을 활용하여 Knowldege distillation을 통한 비지도학습 방법론이었습니다. 그리고 오늘 리뷰할 논문은 이제 다양한 데이터셋(VCDB, DnS, VCSL)을 활용한 self-supervised 방법론입니다.
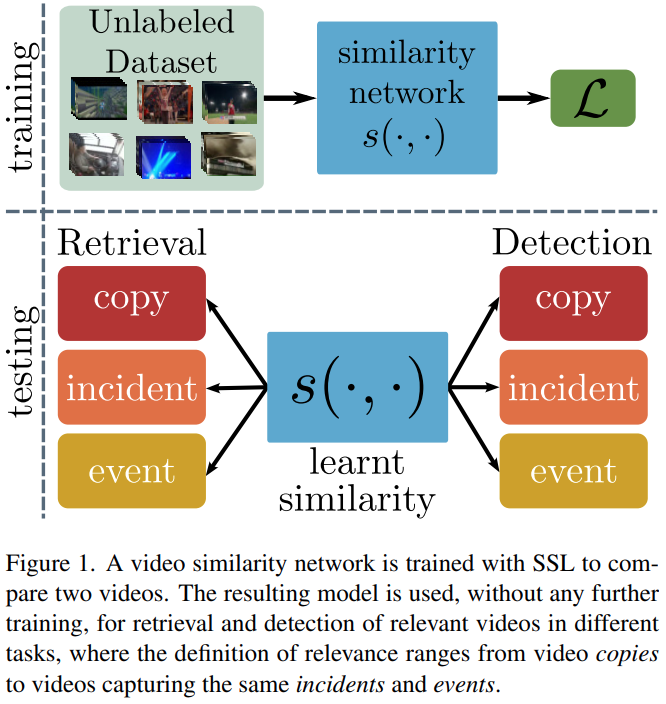
논문에서 제안하는 모델은 [그림 1]과 같이 유사도 기반의 학습 네트워크를 통해, Retreival과 Detection을 동시에 해결할 수 있는 모델인데요. 사실 뒤에 잘 읽어보시면 아시겠지만, 기본 구조가 ViSiL의 구조라 딱히 특별한 부분은 없는 것 같습니다. 차이점이 있다면…
- Self-supervised 연구기 때문에 라벨링이 없는 데이터셋을 사용하도록 변경
- Triplet Loss를 구성하는 것이 아니라, InfoNCE Loss로 변경
- 적용하는 Video augmentation의 변경
정도가 있습니다. 사실 크게 변경된 부분은 없어서 크게 설명드릴 부분이 없을 것 같네요. 다음으로 Retrieval과 Detection에 대해서도 설명해야하는데요. (* Detection에 대한 정의가 없어서… 정확하지는 않지만, video event classification 정도로 생각하고 읽으시면 될 것 같습니다.) Retrieval과 Detection 두가지 Task는 아래와 같은 부분에 대한 고민이 필요합니다.
- 비디오가 복제되었는가?
- 비디오가 같은 사건을 다루는가?
- 비디오가 같은 이벤트인가?
당연히 유사도의 관점에서 학습을 위해 고민해야하는 부분은 동일한데요 약간의 차이도 있습니다. Retrieval에서는 메트릭의 특성 때문에 Ranking이 중요합니다. 하지만 Detection에서는 classification이기 때문에 threshold만 넘으면 맞춘 것이기 때문에 Ranking이 그렇게 중요하지 않죠? 비슷하긴 한데 약간의 차이가 있다고 보시면 됩니다. 그래서 Contribution을 정리해보면…
- 비디오 유사도 측정을 위한 instance-discrimination 기반 SSL을 통해 retrieval과 detection에서 좋은 성능을 보임
- InfoNCE의 성능은 제안된 self-similarity와 hard-negative similarity에 의해 더 개선됨
- FIVR 데이터셋의 성능이 많이 높아짐에 따라 용도를 Detection용으로 변경함. 그리고 Detection과 Retreival을 동시에 벤치마킹하는 최초의 연구
라고 합니다.
SSL for Video Similarity
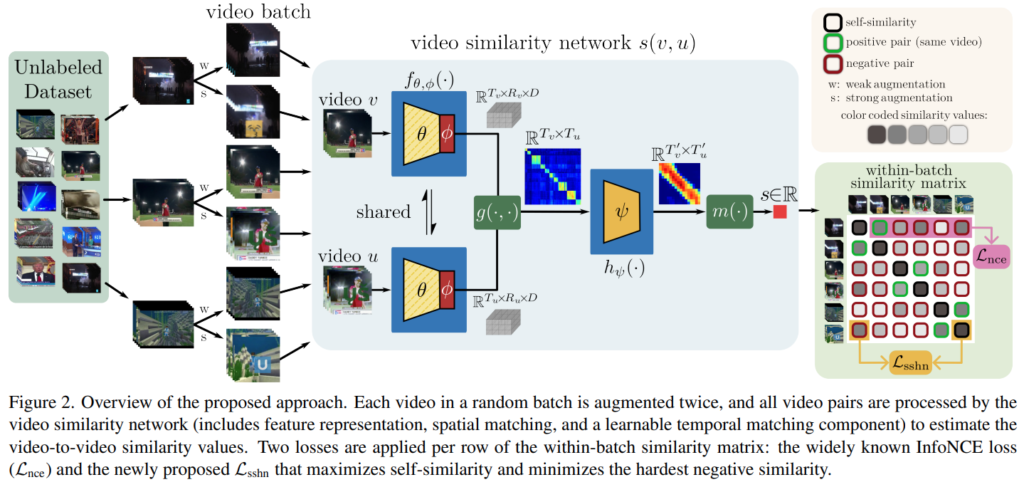
[그림 2]는 방법론의 구조도인데요. 우리가 학습해야하는 유사도는 Task에 따라 정의되기 마련입니다. 이 논문에서는 라벨 없이도 학습 과정에서 같은 이벤트의 비디오를 학습(Anchor-Positive 쌍으로 묶이는 비디오가 같은 이벤트)하고자 노력했다고 합니다. 논문의 Video Similarity network는 ViSiL과 도일하지만 이러한 것이 가능하도록 Augmentation 기법을 통해서 positive 영상을 생성하고, Loss function에도 수정이 가해졌는데 이 부분은 뒤에서 설명하도록 하겠습니다.
Similarity network
이 부분은 ViSiL에 해당하는 부분인데요. 이 논문에서 엄청나게 압축해서 설명해버려서… 겸사겸사 제가 만들어뒀던 발표자료를 좀 가져와서 간단하게 설명하고 넘어가도록 하겠습니다. ViSiL에서는 크게 두가지 단계로 유사도를 계산하는데요.
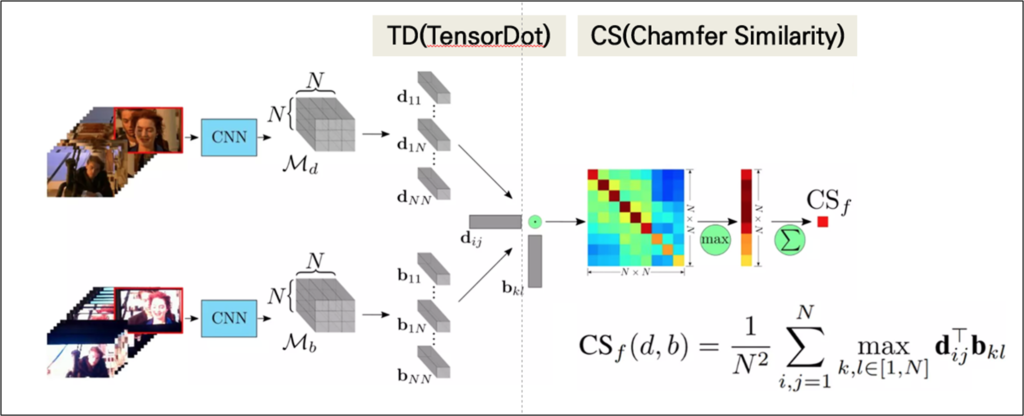
먼저, 프레임 간의 유사도 계산으로 frame-to-frame similarity를 구하는 과정입니다. ViSiL에서는 백본 네트워크에서 intermediate feature라고 부르는 Ln-iMAC feature를 추출해서 사용합니다. 여기서 Ln-iMAC은 N \times S \times C의 구조를 가지게 되는데요. 이 3차원 벡터를 기반으로 두 비디오의 유사도를 계산하기 위해서 우선 TensorDot을 수행하여, 두 비디오 간의 spatial matching을 수행해줍니다. 매칭을 수행했으니 N \times N의 유사도 행렬이 구해지겠죠? 이 행렬에서 Chamfer similarity를 수행해주는데, 유사도 행렬의 열에서 최대값을 선택하고 이 최대값들을의 합을 통해서 프레임간의 유사도를 계산할 수 있습니다.
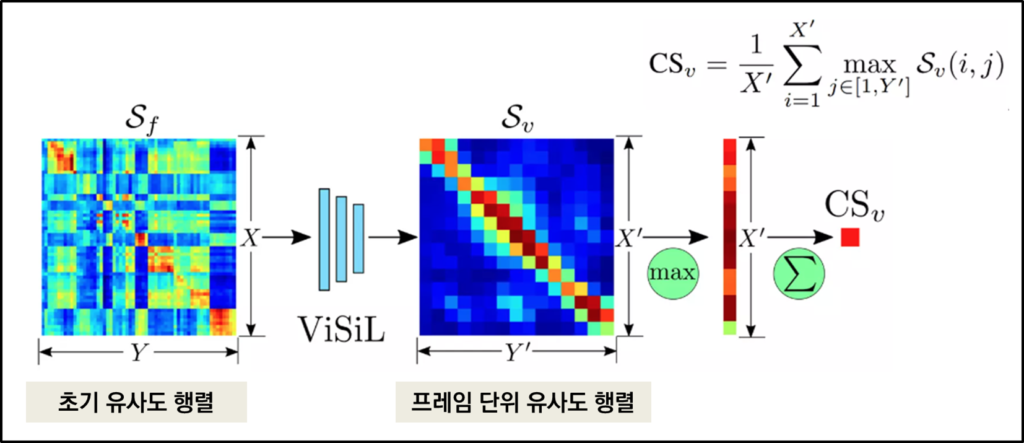
다음 단계로 이 프레임간의 유사도를 계산한 결과를 바탕으로 구해진 frame-to-frame similarity를 바탕으로 video-to-video similarity를 구해야하는데요. 여기서는 frame-to-frame similarity에 ViSiL의 video comparator를 적용하여 얻을 수 있는 refinement된 행렬에 Chamfer similarity를 적용하여 최종적으로 video-to-video similarity를 계산합니다.
그래서 쉽게 정리해보면 ViSiL에서 학습이 되는 부분은 video comparator라고 부르는 레이어만 학습이 되는 구조로 되어있고, 이 video comparator는 frame-to-frame similarity를 기반으로 유사한 비디오가 입력되었다면 보이게되는 패턴을 강조하여 반환하는 모델이라는 정도만 기억하면 될 것 같습니다.
Weak/strong video augmentations
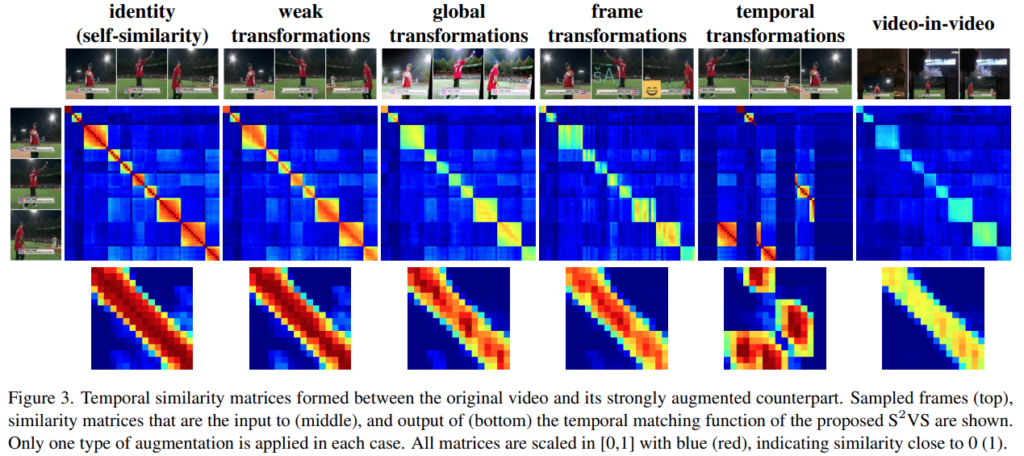
ViSiL에서는 Spatial augmentation과 Temporal augmentation을 적용했었는데요. 여기서는 Weak augmentation과 Strong Augmentation이라고 부르는 두 종류의 augnemtation을 적용합니다. Weak augmentation의 경우에는 기하학적 변환을 수행하는 resized crop이나 horizontal flip등을 지칭해서 이전의 Spatial augmentation에 해당한다고 보면 될 것 같습니다. Strong augnemtation의 경우에는 종류가 좀 많은데요. [그림 3]이 그 예시들이니 가장 왼쪽의 identity(원본)과 비교하면서 보면 좋을 것 같습니다.
- Global transformations
모든 프레임에 동일하게 적용되는 변환으로, 서로 다른 기하학적 photometric한 변화(뒤틀거나, 휘도도를 바꾸거나 등등)를 의미합니다.
- Frame transformations
각각의 프레임에 독립적으로 적용되는 변환으로, overlay(임의의 이모티콘이나 텍스트를 덧씌우는 것)나 블러링을 적용하는 것을 의미합니다.
- Temporal transformations
fast forward, slow motion, reverse play, and frame pause와 같이 비디오의 temporal한 정보를 활용하는데 좋다고 알려진 변환들을 의미합니다. 그리고 추가적으로 Temporal Shuffle-Dropout(TSD)라는 방식을 제안하는데요.
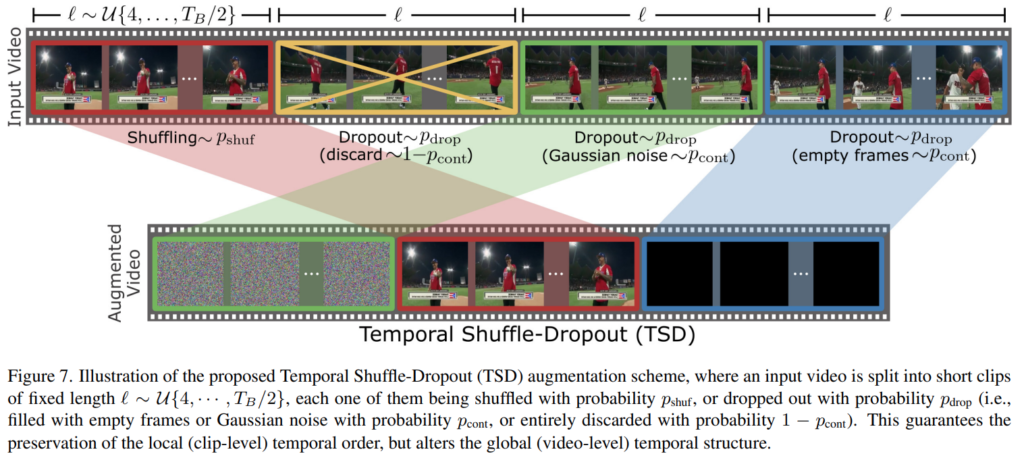
이건 [그림 7]과 같이 이제 원본 비디오에서 Shuffle을 통해서 비디오를 섞고, dropout을 적용한 영역에 대해서 가우시안 블러를 적용하거나 없애는 방식을 통해서 temporal한 augmentation을 수행하는 방식입니다.
- Video-in-video
위에서 설명한 strong augmenation이 적용된 두 비디오를 랜덤으로 섞는 방식으로 배치내에서 작동합니다.
이러한 Augmentation들은 [그림 3]의 self-similarity matrix를 통해 영향력을 확인할 수 있습니다. 원본과 대조해보면 기존의 weak transformation의 경우에는 영향력이 매우 낮고, stong으로 가면 대각선이 잘 안보이는 등의 변화가 큰 것을 볼 수 있는데요. 유사도를 계산한다는게 결국은 이 대각선이 잘 보이도록 모델을 학습하는 과정이라서, 모델이 이런 상황을 잘 학습해야 좋은 성능을 보이게 됩니다.
Loss on video similarity
랜덤한 N개의 비디오 셋이 있다고 하면, 각각의 비디오는 앞서 설명한 augmentation이 1개씩은 적용되어서 배치에서 학습하는 비디오는 총 2N개로 \beta = [v_1,...,v_{2N}]이 됩니다. 이때 유사도 행렬 S \in [0,1]^{B\times B}를 계산하는데요. 이건 이제 배치내 비디오 유사도 행렬이라고 보면 되겠죠? 여기서 중요한 점은 유사도 행렬을 보면 B \times B 라서 대각행렬의 경우 자기 자신과의 유사도라서 1이 되는게 정상인데요. 여기서 유사도 값이 video comparator의 결과값이라 1이 아니라고 합니다. (이게 1이 아닌 이유는 sshn Loss에서 설명하겠습니다.) 그래서 이 상태에서 두가지 Loss를 쓰는데요
InfoNCE Loss
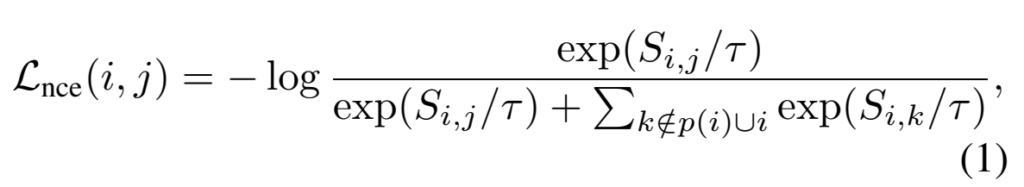
먼저 모르시는 분들이 없을 것 같은데, InfoNCE Loss입니다. Instance-discrimination을 학습하기 위해 사용하는데요. InfoNCE Loss 자체는 positive pair끼리 계산됩니다.
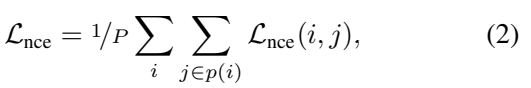
그래서 배치 전체로 봤을 때는, [수식 2]와 같이 모든 positive pair의 InfoNCE Loss의 평균을 사용합니다.
Self-similarity – hardest negative loss (sshn)
이전에 유사도 행렬의 대각 행렬의 값이 1이 아니라고 말했는데요. 그 이유는 이 sshn Loss가 그 특성을 이용한 학습을수행하기 때문입니다. 대각행렬(서로 같은 비디오)의 경우에는 1으로 되돌리고, hardest negative에 해당하는 유사도는 최대한 낮추는 형태로 학습이 수행되는데요.
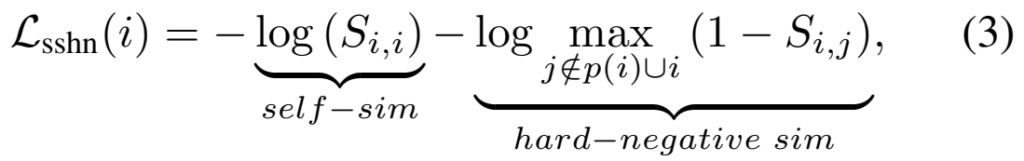
[수식 3]과 같은 구조를 가지고 있습니다. 수식을 보면 알겠지만 특정 행에 대해서 수행되는 Loss인데요. 지금 행에서 self-sim으로 표기된 서로 같은 비디오의 유사도의 값과 hard-negative sim으로 표기된 negative 영상들과의 유사도의 최대값을 서로 빼는 과정을 통해서, video comparator에서 탐지하는 유사도 패턴을 refinement 한다고 보면 될 것 같습니다. (“Kozachenko-Leonenko entropy estimator”라는 기존 연구를 참고했다고 말하는 부분인데, 기존 연구가 feature space에 대한 연구라면 여기서는 그걸 유사도 개념으로 직접적으로 적용하고, video comparator가 좀 더 극명한 차이를 보이도록 유도하는 것 같습니다.)
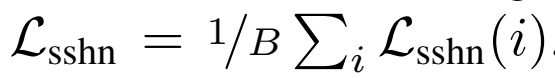
그리고 열단위로 수행되기 때문에, 열끼리 계산하고 평균내서 최종 sshn loss로 사용합니다.
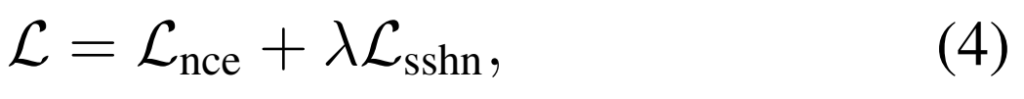
최종 Loss는 [그림 4]와 같고, sshn에서만 튜닝용 hyperparameter가 붙어있는 것 같지만, NCE Loss에서는 이미 내부적으로 튜닝용 hyperparameter를 쓰기 때문에 양쪽 모두 있다고 보면 됩니다.
Experiments
우선 Detection을 평가하기 위해서, 논문 저자들이 과거에 제안했던 FIVR 데이터셋에서 새로운 평가 단위를 추가했는데요. 기존의 DSVR/CSVR/ISVR로 불리는 평가셋을 DSVD/CSVD/ISVD로 변경하였습니다. 이 부분은 아직 공개가 안되어있어서 어떻게 바뀌었는지는 CVPR이 끝나면 알 수 있을 것 같습니다.
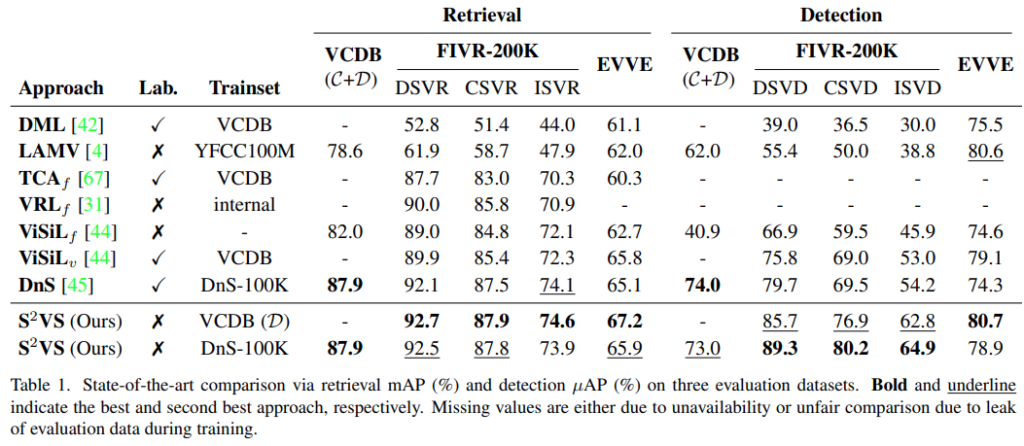
[표 1]을 보면 여러가지 학습 데이터를 사용합니다. 주로 VCDB와 DnS인데요. DnS는 FIVR와 매우 유사한 영상들이 담겨져있는 비디오라는 것을 감안하고 성능을 보면, 의외로 Retrieval에서는 VCDB로 학습하는 경우가 더 성능이 좋다는 것을 볼 수 있습니다. 논문 저자의 이전 논문과는 경향성이 달라진거라 이유를 좀 생각을 해보면 ViSiL의 video comparator와 sshn loss가 학습되는 과정에서 차이가 좀 있다고 생각하는데요. hardest negative를 골라서 학습하는 과정에서 DnS는 너무 유사한 비디오들이 모여있다 보니, 오히려 VCDB의 core-background 정도의 극명한 차이가 video comparator의 학습에 도움이 되지 않았을까? 라고 생각합니다.
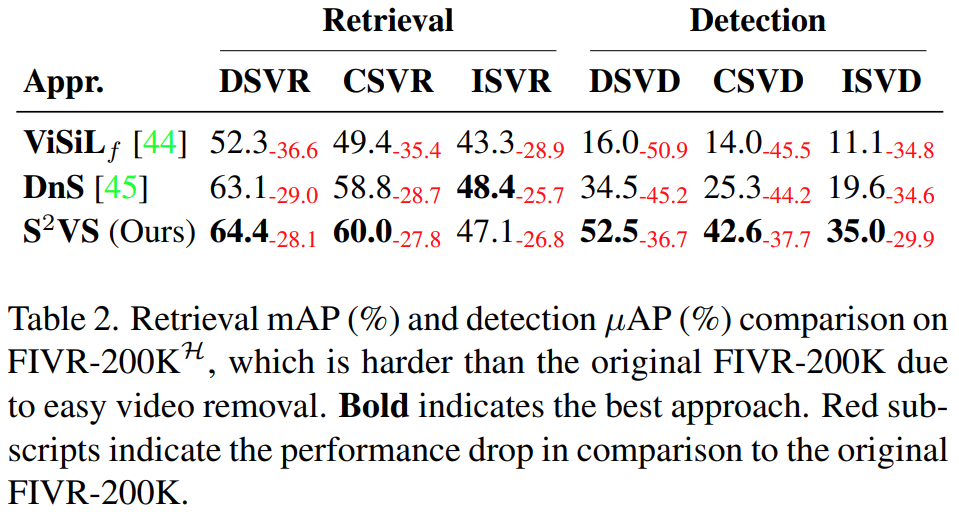
[표 2]는 FIVR-200K에서 성능을 높이는 쉬운 예시(어떤 쿼리와도 관련있다고 나오는 데이터베이스 비디오들)들을 모두 제거한 버전에서의 실험입니다. 이 경우에는 기존 방법론들과 더 극명한 차이를 가지게 되는데요. 제안하는 방법론이 완전 더 좋은 성능을 보이는 것 같지만… ViSiLf에는 video comparator가 없기 때문에, 올바른 비교로 보기는 어려울 것 같습니다.
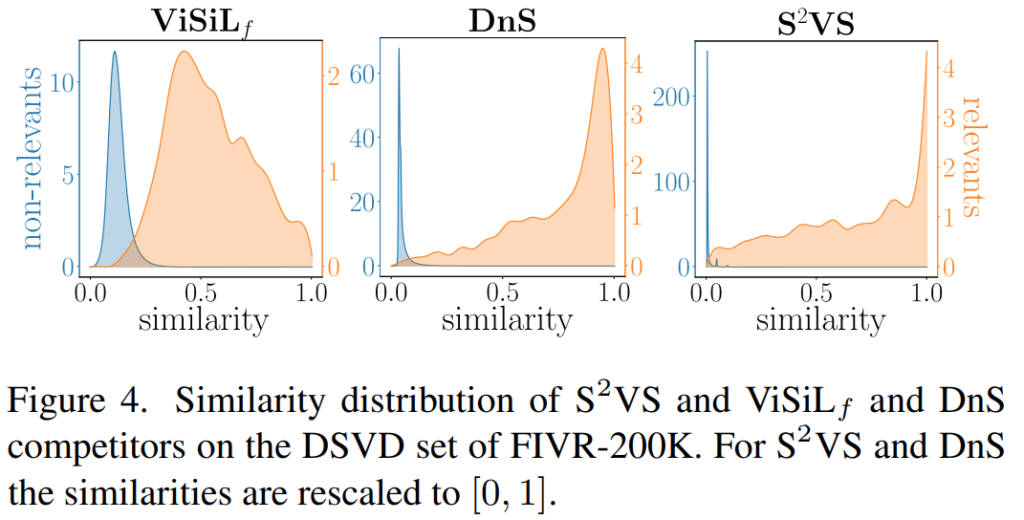
[그림 4]의 경우에는 유사도 분포를 보여주는데요. 해당 경우에도 마찬가지로 ViSiLf는 학습하는 부분이 없어서 비교군 정도로 보고 DnS와 SVS만 집중해서 보면 되는데요. DnS보다도 유사 비디오와 유사하지않은 비디오 간의 간격이 더 넓은 것을 봤을 때 학습이 잘 되었음을 보입니다.
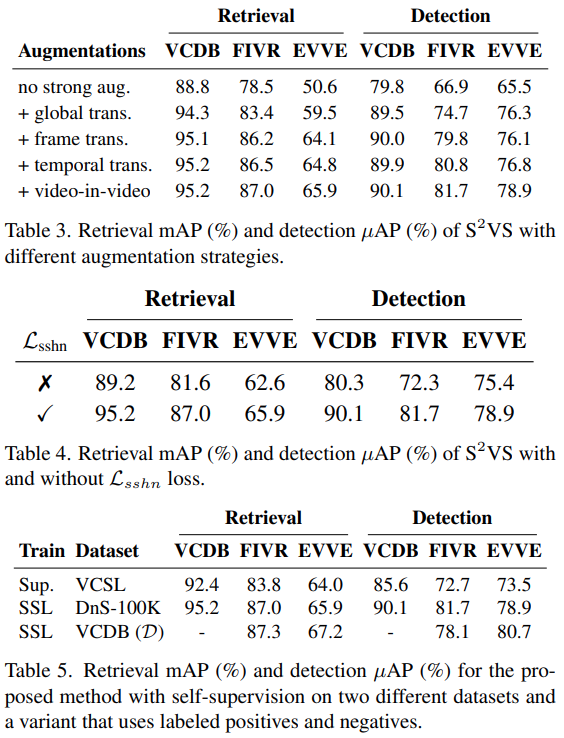
Ablation 실험들의 경우에는 관심 있는 분들이 보시면 될 것 같은데요. [표 5]의 경우가 VCSL이라고 video localization을 위해 최근에 새로 제안된 대용량 데이터셋으로 실험한 결과가 있어서 가져왔습니다. VCSL도 지도학습으로 학습하지 않아도 될텐데… 어쨋든 학습을 수행을 한 결과를 보면 아무래도 대용량 데이터셋이면서 본인들이 제안했던 DnS라는 데이터셋을 사용할 경우가 제일 좋은 성능을 보인다는 것을 확인할 수 있습니다.
Conclusions
SSL을 retrieval에 적용하는걸 생각해보고 있었는데… 따라가기 쉽지 않게 이리저리 새로운 것들을 많이 정의했네요. 논문 자체는 사실 아쉬운 것 같습니다. 여전히 ViSiL의 구조를 똑같이 사용하는 것도 그렇고. 실험도 조금 아쉬운 상태에다가 Detection에 대한 정의가 없어서 뭘 했는지 잘 모르겠습니다. 그래도 SSL이 드디어 retrieval에도 적용이 되었고, 학회 시작되면 코드와 데이터셋도 싹 공개할 것 같아서 그때까지는 기다려봐야겠습니다.
좋은 리뷰 감사합니다.
몇가지 궁금한 것이 있는데
1. FIVR에서의 detection은 어떻게 평가를 하나요? muAP가 뭔가요? 보통 detection은 얼마나 겹치는 지에 따라 threshold 별 성능을 측정하는데 테이블 보면 그렇게 진행한 것 같지는 않네요.
2. Self-Supervised 라면 기존의 anchor-positive 관계도 사용하면 안되는 것 같은데 그렇다면 positive pair는 그냥 동일 비디오에서 augmentation된 비디오만을 가정하나요?
3. FIVR-200K H는 뭔가요? 자세한 설명 부탁드립니다.
1. 해당 부분 데이터셋이나 코드 공개가 안되어있어서, 공개 후에야 알 수 있을 것 같습니다. 리뷰에서도 말했지만 설명이 없네요.
2. 네. VCDB 라벨링 정보를 바탕으로 학습하는게 아니라 augmentation 줘서 positive pair만들어서 학습합니다.
3. 리뷰에도 작성되어있는데 FIVR-200K 하드버전이라고 합니다. 이것도 자세한 정보가 없는데, 아마 학회 시작되면 데이터셋 갱신될 것 같습니다.
안녕하세요 좋은 리뷰 감사합니다.
해당 방법론에서 적용해주는 augmentation 중 temporal shuffle-dropout 방식도 하나의 positive를 만들어내기 위해 사용되는 것인가요?
이를 적용한 결과를 [그림 7]에서 볼 수 있었는데, temporal shuffle-dropout 내 discard, gaussian noise, empty를 각각 어느정도로 적용했는지에 대한 하이퍼파라미터도 제공하나요? 너무 심하게 변형을 가하면 retrieval 대상이 아니게 될 만큼 변할 수도 있을 것 같은데, 이에 대해 저자가 선택한 정도가 있는지 궁금합니다.
그리고 표 3에 augmentation 별 성능이 리포팅되어 있는데, “temporal trans.”의 성능은
fast forward, slow motion, reverse play, and frame pause + temporal shuffle-dropout
을 모두 적용했을 때의 성능인가요? 저 둘을 동시에 적용한 성능이라면 적용할 때의 순서도 정해둔 것인지 궁금합니다.
해당 방법론에서 적용해주는 augmentation 중 temporal shuffle-dropout 방식도 하나의 positive를 만들어내기 위해 사용되는 것인가요?
=> 네 맞습니다. SSL에서는 원래 이렇게 합니다.
이를 적용한 결과를 [그림 7]에서 볼 수 있었는데, temporal shuffle-dropout 내 discard, gaussian noise, empty를 각각 어느정도로 적용했는지에 대한 하이퍼파라미터도 제공하나요? 너무 심하게 변형을 가하면 retrieval 대상이 아니게 될 만큼 변할 수도 있을 것 같은데, 이에 대해 저자가 선택한 정도가 있는지 궁금합니다.
=> 이런 부분들에 대해서 하이퍼 파라미터 값을 명확하게 제공하고 있습니다. (코드도 곧 공개될듯 하네요)
그리고 표 3에 augmentation 별 성능이 리포팅되어 있는데, “temporal trans.”의 성능은
fast forward, slow motion, reverse play, and frame pause + temporal shuffle-dropout
을 모두 적용했을 때의 성능인가요? 저 둘을 동시에 적용한 성능이라면 적용할 때의 순서도 정해둔 것인지 궁금합니다.
=> 순서라기 보다는 확률적으로 적용된다고 보시면 됩니다.