
1. Introduction
RGB를 Depth로 변환 시킬때는 그림 1 의 왼쪽 처럼 Texture copy 가 발생 한다. 이 Texture Copy는 RGB의 특성을 Depth가 따라 가는 것으로 Depth 생성시에 성능저하의 원인이 된다. 그리고 Unsupervised 방식으로 Monodepth Estimation 을 할 경우 타겟 영상만이 아닌 근처를 보기 때문에 Occulusion이 생겨 학습을 방해 한다. 그림 1의 오른쪽을 보면 차에 의해서 L 에는 보이는 픽셀이 R에는 보이지 않게 된다. 이러한 상황이 문제가 되는 이유는 R이 L로 변형이 돼서 L과 비교가 될텐데 L에 없는 픽셀로 비교를 한다면 loss 계산의 신뢰성이 떨어진다는 문제가 생긴다.
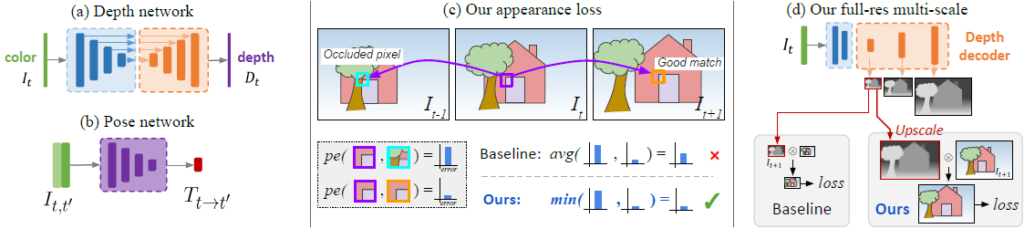
이 논문은 Monodepth의 후속 논문으로 Monodepth2 로 별칭이 붙어 있다. Monodepth 1과 다른 점은 Monodepth1은 Left와 Right 만을 사용해서 Unsupervised 방식으로 진행되었지만 , Monodepth2는 Sequence 한 Video 를 바탕으로 진행이 되는 점이 둘의 큰 architecture 적인 차이라고 할 수 있다.
2.Method
이 논문의 Key Contribution 은 아래와 같다.
- 1.monocular supervision 사용 시 occluded pixel이 발생하는 문제를 해결하기 위한 Loss 제안
- 2.관계없는 카메라 모션을 제거하기 위한 Auto Masking 제안
- 3.Multi-Scale 을 사용한 Loss 제안
각각에 대해 자세히 설명 하도록하겠다.
2.1 Per-Pixel Minimum Reprojection Loss

이 논문은 Sequence한 video를 사용하기 때문에 L을 기준으로 앞,뒤 프레임을 사용해 진행한다. 그랬을떄 영상간의 차이로 인해서 그림3 과 같이 Pixel 이 가려지는 형상이 발생한다. 이를 방지하기 위해서 아래와 같은 방식을 제안한다.
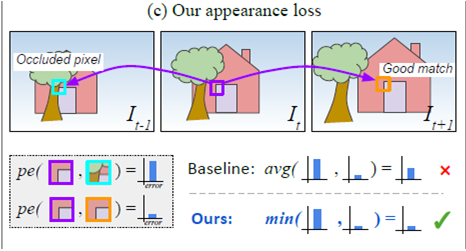
기존에는 픽셀끼리 비료할때 앞과 타겟을 비교한 것 그리고 뒤와 타겟을 비교한 것을 평균을 냈다 하지만 이렇게 될 경우 Occulution이 발생한 픽셀은 당연하게도 로스가 굉장히 크게 되는 형상이 발생하고 이는 학습에 영향을 끼친다. 이를 막기 위해서 그림 4와 같이 앞과 뒤 둘다 타겟 픽셀과 비교했을때 로스가 낮은 프레임의 연산만을 로스에 합치는 방식을 차용한다. 이렇게 될 경우 보다 높은 확률로 Occulution 이 생긴 프레임과의 비교를 막을 수 있게 된다.
2.2 Auto-Masking Stationary Pixels

Sequence 한 데이터를 사용할때 가정이 있다. 그건 카메라만 움직이고 촬영되는 것은 가만히 있는 다는 가정이다. 하지만 이러한 가정이 깨질 경우 깊이 추정에 많은 영향을 주게되어 Depth 영상에 “holes” 를 만들게 되는 문제가 발생한다.
그림 5를 보면 카메라와 자동차가 동시에 움직여서 가정이 깨지기 때문에 이를 방지하기 위한 마스크를 주었고 아래 사진은 정지된 카메라라 가정이 깨지게 돼서 전체적으로 마스크를 씌웠다.
이 마스크를 씌우는 것의 기준은 처음에는 타겟 영상과 동일한 픽셀 값이면 Loss 계산에 포함 시키지 않는 것이였다. 하지만 이렇게 될경우 어떤 것이 동일한 픽셀인지 정확 판별이 어려워 다음과 같은 방식을 도입했다.
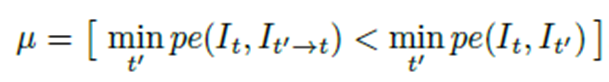
픽셀을 L처럼 변경시킨 R이미지와 실제 L의 Loss를 계산 했을때 실제 R과 L의 Loss 보다 작아야 Loss 계산에 포함 시키는 것이다. 이는 L과 R의 픽셀이 같을 경우 Loss값이 같게 될 것이므로 이러한 방식을 도입했고 이는 성능을 높혀주는데 한몫했다고 한다.
2.3 Multi-scale Estimation
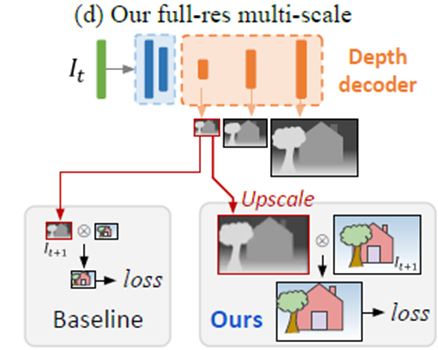
기존 Monodepth 1 또한 Multi scale로 해서 다양한 크기의 영상을 depth estimation 하고 다양한 크기의 물체를 학습할 수 있도록했다. 하지만 기존의 MS 방법론들은 그림 6의 베이스라인과 같이 GT를 작게 만들어 비교했는데 이렇게 비교할 경우 holes와 texture copy를 유발한다고 했다. 이러한 단점을 보완하기 위해 이 논문은 생성된 Depth 의 scale을 Upscale 하여 GT와 비교하는 방식으로 하니 성능이 향상되었다고 한다.
Results
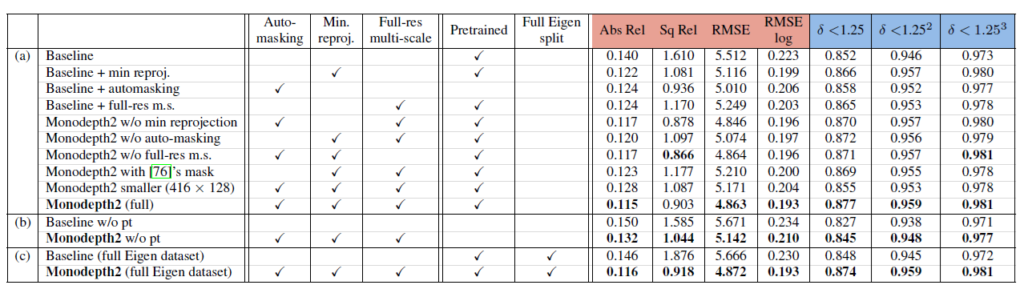
다른 성능 비교도 많지만 Ablation Study를 하며 각 모듈의 성능 향상이 중요할 것 같아 이것을 포함 시켰다. 2019년도 SOTA를 달성했다고 한다.