안녕하세요. 이번 논문은 preference-aware 논문이지만 특이하게 implicit human feedback까지 고려하는 논문을 가져와봤습니다. 그럼 시작해보겠습니다.
1. Introduction
로봇 하드웨어와 physical manipulation 능력이 발전하면서, 로봇이 사람 사용자에 맞게 하는 일이 중요해졌습니다. 그 예로, 사람과 로봇이 함께 나사를 놓고 조이거나, 부품을 조립하거나, 요리를 하는 상황이 대표 예시인데요.
이런 collaboration이 잘 되려면 로봇은 단순히 task goal만 알아서는 부족합니다. 같은 목표를 달성하더라도 사람마다 선호하는 바가 다를 수 있기 때문입니다. 어떤 사람은 피자에 치즈를 먼저 올리고 싶고, 어떤 사람은 소스를 먼저 바르고 싶을 수 있습니다. 또, 어떤 사람은 작업대에 재료가 많이 올라와 있으면 불편하고, 어떤 사람은 여러 재료가 동시에 준비되어 있어도 괜찮을 수 있죠.
기존 interactive robot learning에서는 사람이 로봇에게 계속 명시적 피드백을 줍니다. 그러나 실제 collaboration에서는 사람이 task를 수행하느라 바쁘죠. 사람이 계속 로봇에게 피드백을 주라고 요구하면 부담이 커지고 심하면 이탈까지 갈 수 있습니다.
그래서 논문의 저자는 사람끼리 협업할 때를 관찰했는데요. 사람은 다른 사람의 행동을 보면서 그 사람의 preference를 자연스럽게 추론하죠. 그래서 이를 따라서 저자는 로봇도 이처럼 사람의 행동을 implicit feedback을 얻어야 한다고 말합니다.
그래서 본 논문의 contribution을 정리하면 다음과 같은데요.
- human-robot collaboration 전체에 대한 사람의 preference를 학습하는 새로운 formulation을 제안한다. (여기서 preference는 robot behavior에만 붙는 것이 아니라, 사람과 로봇이 함께 만드는 협collaboration에 붙음)
- PIE(Preference learning from Implicit and Explicit feedback)를 시뮬레이션과 real world 실험에서 평가한다.
- replication과 벤치마킹을 위해 오픈소스로 공개한다.

Figure 1을 통해 논문의 전체 아이디어를 확인할 수 있습니다. 사람과 로봇이 피자를 함께 만들고, 사람은 로봇 행동에 대해 버튼으로 명시적 피드백을 줄 수 있습니다. 동시에 사람의 실제 task action을 하면, 예를 들어 어떤 재료를 먼저 올리는지, 어떤 재료를 되돌리는지도 implicit feedback이 됩니다. 이 두 피드백을 함께 사용해 사람의 preference를 학습합니다.
2. Problem Setup: Learning Preferences Over a Human-Robot Collaboration
먼저, 사람 $H$와 로봇 $R$이 physical task를 함께 수행하며, 각자 맡은 역할이 고정되어 있다고 가정합니다. 피자 만들기를 예로 든다면, 로봇 $R$은 재료를 저장 공간에서 가져오고, 사람 H는 재료를 피자에 올립니다.
time-step $t$에서 사람 $H$와 로봇 $R$은 state $s$를 관찰하고 동시에 high-level action을 선택합니다. human action은 $a_H \in A_H$이고, robot action은 $a_R \in A_R$로 나타내며, 여기서 $A_H$는 human action space, A_R은 robot action space를 의미합니다.
예를 들어 로봇의 high-level action은 pick(<ingredient>, <location>) 또는 place(<ingredient>, <location>)일 수 있는데요. 사람의 high-level action은 add(pepperoni) 또는 return(pepperoni)일 수 있습니다.
저자는 collaboration의 shared reward를 goal reward와 preference reward의 합으로 정의하였습니다.
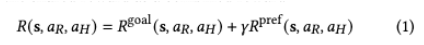
여기서 $R^{goal}$은 task goal를 얼마나 잘 달성했는지를 나타내고, $R^{pref}$는 사람의 preference를 얼마나 잘 따랐는지를 나타냅니다. $\gamma$는 두 reward 중 어느 쪽을 더 중요하게 볼지 조절하는 파라미터로 보시면 되겠습니다.
Goal Reward
역할이 고정되어 있으므로 goal reward을 사람 부분과 로봇 부분으로 나누는데요.
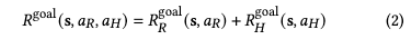
$R_R^{goal}$은 로봇이 자기 role을 goal에 맞게 했는지 보는 reward이고, $R_H^{goal}$은 사람이 자기 role을 goal에 맞게 했는지 보는 reward 입니다.
Preference Reward
먼저 논문에서는 preference reward가 goal reward와 충돌하지 않는다고 가정합니다. 또한 사람이 human action에 대해 가진 preference와 robot action에 대해 가진 preference가 같은 weight $w$로 표현될 수 있다고 둡니다.
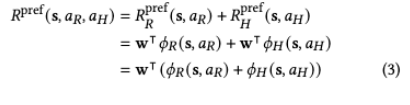
여기서 $w$는 preference weight를 의미합니다. $\phi_R(s,a_R)$는 robot action의 feature를 뽑는 함수이고, $\phi_H(s,a_H)$는 human action의 feature를 뽑는 함수입니다. 예를 들어서 “치즈를 소스보다 먼저 올리는가?” 같은 ordering preference나 “작업대에 재료가 몇 개까지 올라와 있는가?” 같은 workspace preference가 feature가 될 수 있습니다.
논문의 저자는 preference reward를 해석 가능하게 만들기 위해 linear function로 두는데요. 즉, feature에 weight를 곱해서 더합니다.
Individual Rewards and Robot Learning Objective
사람과 로봇이 합리적으로 행동한다고 가정하면, 각자 자신의 reward을 최대화하는데요. 로봇의 reward는 아래의 (4), 사람의 reward는 (5)와 같습니다.
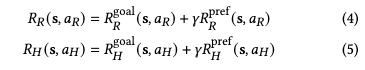
로봇의 학습 목표는 w를 추정하는 것인데요. 저자는 로봇이 goal reward와 어떤 feature를 preference에 중요할 수 있을지는 안다고 가정합니다. 즉, 로봇은 $R_{goal}, \phi_R, \phi_H는$ 알고 있음을 가정하는 가는 것이죠. 하지만 진짜 preference weight w는 모른는데요. 그래서 협업 중 얻은 human feedbac으로 w를 추정해야 합니다.
3. Preference Learning from Implicit and Explicit Feedback (PIE)
PIE(Preference learning from Implicit and Explicit feedback)는 사람의 명시적 피드백(과 암묵적 피드백을 함께 사용해 preference weight w를 추정합니다. 명시적 피드백은 사람이 robot behavior에 대해 직접 주는 binary evaluative feedback을 말합니다. 실제 실험에서는 버튼을 누르는 것으로 구현되었구요. 암묵적 피드백은 사람이 task를 하면서 선택한 human action을 말합니다.

Algorithm 1은 PIE의 작동 방식을 보여주는데요. input은 preference weight에 대한 prior belief $W=\{w_i\}_{i=1}^{M}$와 feedback set F입니다. F에는 받아들인 행동 $f^+$와 거부한 행동 $f^-$의 쌍이 들어가게 됩니다. output은 업데이트된 belief $W$와 업데이트된 feedback set $F$이 됩니다.
3.1 Implication of Explicit Human Feedback
명시적 인간 피드백은 사람이 로봇의 행동을 직접 평가하는 것인데요. 앞에서 말씀드린 것처럼 논문에서는 binary feedback을 사용합니다.
state $s$에서 로봇이 action $a_R$을 했다고 해봅시다. 사람이 이 action을 받아들일 만하다고 표시하면, $f^+_{exp}=\{a_R\}$이고 $f^-_{exp}=A_R(s)\setminus\{a_R\}$입니다. 즉, 실제로 한 robot action은 accepted behavior, 그 state에서 가능했지만 하지 않은 다른 robot action은 rejected behavior으로 봅니다.
반대로 사람이 이 action을 받아들일 수 없다고 표시하면, $f^+_{exp}=A_R(s)\setminus\{a_R\}$이고 $f^-_{exp}=\{a_R\}$입니다. 즉, 로봇이 한 action은 rejected behavior, 다른 가능한 action들이 accepted behavior으로 보게 됩니다.
논문의 저자는 이러한 명시적 피드백 해석이 INQUIRE 프레임워크를 따른다고 설명하는데요. 다만 본 논문에서는 로봇이 사람에게 질문을 하여 능동적으로 피드백을 받는 active preference learning는 다루지 않습니다.
3.2 Implication of Implicit Human Feedback
암묵적 인간 피드백은 본 방법론 파트에서 가장 중요하다고 볼 수 있는데요. 사람이 task 중 어떤 action을 선택했다면, 그 action은 그 사람의 preference에 어느 정도 맞는 행동이라고 볼 수 있습니다.
논문의 저자는 사람이 state s에서 action a_H를 선택할 확률을 Boltzmann rational policy로 모델링하는데요. 다음과 같은 식을 구성합니다.
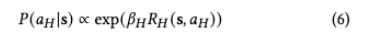
여기서 $\beta_H$는 사람이 얼마나 합리적으로 행동하는지를 조절하는데요. $\beta_H$가 크면 reward가 높은 action을 거의 고르고, $\beta_H$가 작으면 더 random 가까워지도록 합니다.
사람이 state s에서 action $a_H \in A_H(s)$를 선택하면, PIE는 $f^+_{imp}=\{a_H\}$로 보고, 다른 가능한 human action을 $f^-_{imp}=A_H(s)\setminus\{a_H\}$로 보는데요. 이 방식 덕분에 로봇은 사람이 버튼을 계속 누르지 않아도 collaboration 내내 preference에 대한 정보를 얻을 수 있다.
4.3 Estimating Belief Over Preference Weights
로봇은 feedback을 받을 때마다 implication를 cumulative feedback set F에 저장합니다. feedback의 modality m은 명시적 또는 암묵적을 가지는데요. 이 m이 중요한 것이, 명시적 피드백은 robot action을 기준으로 해석하고, 암묵적 피드백은 human action을 기준으로 해석하기 때문입니다.
로봇의 목표는 accepted behavior $f^+_m$이 나타날 likelihood를 가장 크게 만드는 preference weight $w$를 찾는 것인데요. likelihood 수식은 다음과 같습니다.
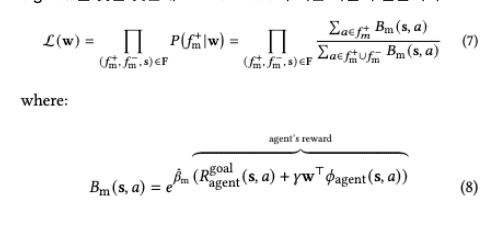
여기서 $B_m(s,a)$는 Boltzmann model의 지수 부분을 나타냅니다. $m$이 명시적이면 agent는 로봇 R이고, $m$이 암묵적이면 agent는 사람 H이게 됩니다.
$\hat{\beta}_m$은 로봇이 human feedback이 얼마나 합리적이라고 가정하는가를 나타내는데요. 중요한 점은 실제 사람의rationality $\beta_H$와 로봇의 assumption$ \hat{\beta}_m$이 다를 수 있다는 것입니다.
preference learning의 목표는 $w^*=\arg\max_w L(w)$인데요. 논문은 $W=\{w_i\}_{i=1}^{M}$라는 sample set으로 preference weight에 대한 non-parametric belief을 표현하고, log-likelihood $LL(w)=\log L(w)$에 대해 gradient ascent을 적용합니다. 수식은 다음과 같습니다.
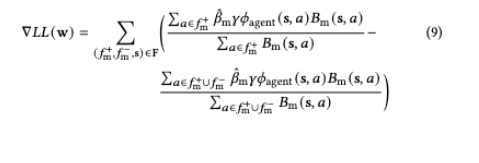
4. Evaluation in Simulation
시뮬레이션 평가에서 PIE가 어떤 조건에서 잘 작동하는지 확인하게 되는데요. 크게 보고 싶은 것은 2가지로 말할 수 있습니다.
- RQ1: 명시적 피드백만 쓰는 것, 암묵적 피드백만 쓰는 것, 둘을 함께 쓰는 PIE 중 무엇이 preference learning에 더 도움이 되는가?
- RQ2: human action의 합리성에 대한 로봇의 가정이 틀리면 PIE(의 성능이 얼마나 나빠지는가?
4.1 The Pizza-Making Task
실험 task는 pizza-making collaboration 입니다. 로봇은 ingredient를 집어 작업대에 놓고, 사람은 피자에 재료를 올리거나 되돌리게 됩니다. robot action은 pick(broccoli, storage) 또는 place(broccoli, workstation)처럼 표현되고, human action은 add(pepperoni) 또는 return(pepperoni)처럼 표현됩니다.
사람과 로봇은 pizza goal, 즉 어떤 재료가 필요한지는 알고 있는데요. 하지만 로봇은 사람이 어떤 순서를 좋아하는지, 작업대에 재료가 몇 개까지 올라와 있어도 괜찮은지는 모릅니다. 논문에서는 이런 preference를 총 8차원의 preference weight w로 표현하였습니다. 6개는 ordering preference, 2개는 workspace preference 입니다.
4.2 Simulating the Human in the Collaboration
시뮬레이션 속 사람은 Boltzmann rationality model을 따릅니다. 수식은 $P(a_H|s)\propto\exp(\beta_H R_H(s,a_H))$으로, 쉽게 말하면, reward가 높은 행동을 더 자주 고르지만,$ \beta_H$가 작으면 더 덜 일관적으로 행동하게 됩니다.
여기서 중요한 점은 이 실험에서 사람이 항상 명시적 피드백을 준다고 설정했다는 것입니다. 실제 사용자는 매번 버튼을 누르지 않으니 이 시뮬레이션은 실제보다 더 통제된 환경이라 볼 수 있습니다.
4.3 Evaluation Setup
논문은 두 메트릭을 보는데요. 첫째, L2 error는 추정한 preference weight가 ground truth preference weight $w^*$와 얼마나 다른지 보게 됩니다. 수식은$ \|w^*-\sum_i w_i/M\|$으로, 작을수록 사람 preference를 더 정확히 배운 것이라 볼 수 있습니다.
둘째, conflict percentage는 추정된 preference를 따라 로봇이 행동했을 때, true optimal action과 얼마나 자주 어긋나는지 보는 값입니다. 즉, w라는 숫자를 잘 맞췄는지 뿐 아니라 실제 robot behavior이 얼마나 덜 충돌하는지도 확인하게 됩니다.
5.4 Results
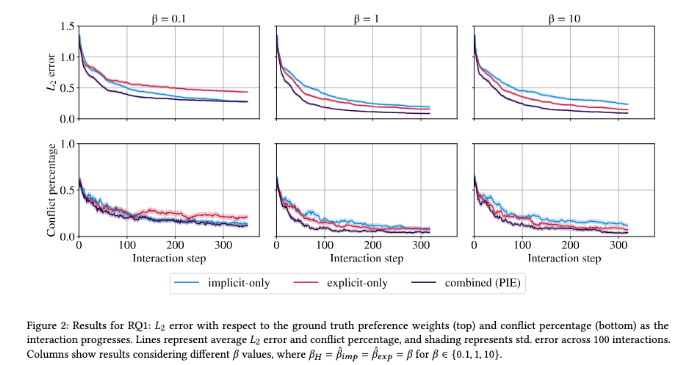
Figure 2는 100개의 시뮬레이션 상호작용에서 시간이 지날수록 L2 error와 conflict percentage가 어떻게 변하는지 보여줍니다. 비교 대상은 명시적 피드백만 쓰는 경우, 암묵적 피드백만 쓰는 경우, 둘을 합친 Combined feedback with PIE 입니다. Combined feedback with PIE가 대체로 가장 낮은 L2 error를 보이는 것을 알 수 있는데요. 즉, 사람이 버튼으로 직접 알려준 정보와 사람이 실제로 한 행동에서 나온 정보를 함께 쓰면, 로봇이 사람의 선호를 더 잘 추정하는 것을 알 수 있습니다.
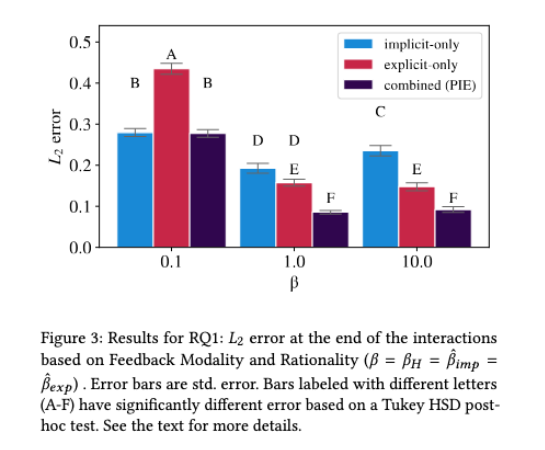
Figure 3은 Figure 2의 마지막 시점만 따로 모아 비교한 것입니다. 여기서는 feedback modality와 rationality 수준 $\beta\in\{0.1,1,10\}$이 같이 비교됩니다.
여기서 중요한 점은 Combined feedback with PIE가 $\beta=1$과 $\beta=10$에서 다른 조건보다 낮은 최종 L2 error를 보인다는 점입니다. 다만 $\beta=0.1$처럼 사람이 매우 덜 합리적으로 행동한다고 보는 조건에서는 error가 커지는 것을 볼 수 있는데요. 이는 PIE가 사람 행동을 선호preference의 단서로 쓰기 때문에, 행동이 너무 랜덤에 가까우면 배우기 어렵다는 점을 보여줍니다.
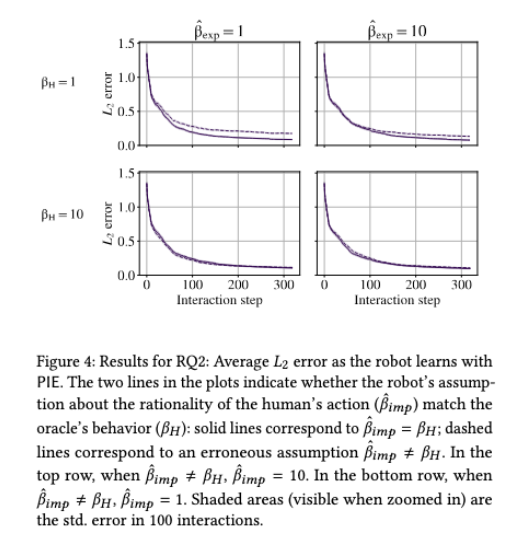
Figure 4는 RQ2의 핵심 그림이라 말할 수 있는데요. 실선은 로봇이 사람 행동의 rationality을 맞게 가정한 경우이고, 점선은 잘못 가정한 경우를 보여줍니다. Figure 4를 보면 점선이 대체로 실선보다 위에 있는 것을 볼 수 있는데, 즉, 잘못된 가정이 더 큰 L2 error로 이어진다고 말할 수 있습니다.
이 결과는 PIE의 장점과 약점을 동시에 보여준다고 할 수 있는데요. 장점은 사람 행동까지 learning signal로 쓸 수 있다는 것이고, 약점은 그 행동을 해석하려면 “사람이 얼마나 합리적으로 행동하는가”에 대한 모델이 필요하다는 것입니다.
5. Real-World Evaluation
실제 사용자 21명과 실제 로봇을 사용해 PIE를 평가하는데요. real-world human-robot interaction에서도 로봇이 collaboration preference를 배울 수 있는가?를 확인할 수 있습니다.
5.1 Results
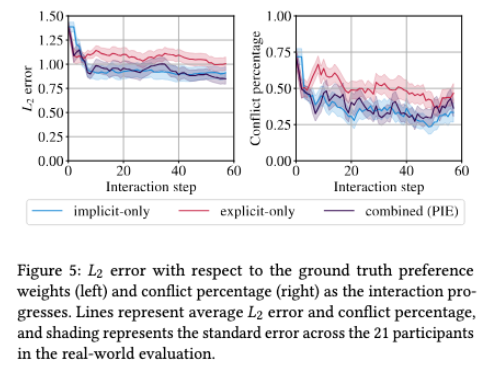
Figure 5는 실제 사용자 21명의 결과를 보여줍니다. 왼쪽은 L2 error이고, 오른쪽은 conflict percentage을 나타내는데요. 그림에서 Combined feedback with PIE는 최종 L2 error가 가장 낮은 쪽에 있음을 알 수 있습니다. 이는 실제 사람 데이터에서도 명시적 피드백과 암묵적 피드백을 함께 쓰는 것이 preference 추정에 도움이 될 수 있음을 보여주게 됩니다.
하지만 여기서 주요할 점이 있는데요. 논문의 저자가 말하길 real-world evaluation에서는 Feedback Modality 효과가 통계적으로 강하게 확정되지는 않았다고 보고하였습니다(p=0.07). 즉, “실제 사용자에서도 PIE가 확실히 이겼다”가 아니라 “시뮬레이션과 비슷한 방향의 경향이 real user 실험에서도 관찰되었다”로 볼 수 있습니다.
이렇게 리뷰를 마쳐보도록 하겠습니다. 저는 preference-aware 분야에서 주요한 점이 사람의 암묵적인 행동을 어떻게 파악하고 가져갈 것인지인데요. 모든 사람이 시연을 보여주기도 어려울 것이고 하나하나 내 선호 행동을 말하는 것도 번거로운 일이라 생각되어 가정용 로봇의 상용화를 위해서라면 암죽적인 행동도 고려해야하는 것이 아닐까?하는 생각이 들게 됩니다. 지금까지 읽어주셔서 감사합니다.