안녕하세요
오늘은 multimodal token compression관련 논문을 읽어보겠습니다.
Intro
최근의 Video-LLM은 video understanding에서 좋은 성능을 보여주고 있습니다. 하지만 비디오는 여러 프레임으로 구성되어 있고 또 각 프레임마다 visual token으로 변환되기 때문에 LLM에 들어가는 visual token 수가 폭발하게되고 . 특히 prefill stage가 느려진다고 합니다.
여기서 prefill stage는 LLM이 답변을 만들어 내기 전에 입력 token전체를 한번 처리해서 KV cache를 만드는 단계로 비디오 토큰이 많으면 이 단계가 매우 비싸집니다. 따라서 이 논문의 가장 큰 목표는 LLM에 넣기전에 성능은 최대한 유지하되 비디오 토큰을 잘 줄여보자!! 입니다.
저자들은 기존의 Image compression의 방법들이 이미지 하나 안에서의 중복은 줄일수 있지만 비디오의 프레임간의 temporal한 관계는 잘 활용하지 못한다고 지적합니다.
예를들어 아래의 fig1(a)를 살펴보면 축구선수가 공을 차고→ 골이 들어갔고 → 세레모니를 하는 장면이라고 칩시다. 비디오는 이 순서 자체에 의미가 있는건데 만약에 token purning을 하다가 중간 프레임이 빠지거나 프레임 순서가 뒤섞여지면 모델이 사건자체를 잘못 이해할수도 있습니다.
또한 fig1(b1)처럼 토큰을 일정한 방식으로 고르는 uniform sampling방식으로 선택하면 간단하고 빠르기야 하겠지만 그림의 기타 몸통과 배경이 비슷하다 판단되어 잘못 merge되는 것과 같은 중요한 물체가 빠지는 문제가 생길수 있습니다.
따라서 저자들은 단순히 토큰의 유사도나 어텐션만 보고 토큰을 줄이는것이 아니라 temporal context(프레임 순서, 연속성 같은 시간 문맥적 흐름)와 visual context(중요한 물체,배경 같은 세부적인 시각정보)를 지키면서 토큰을 줄이는 방법인 FastVID를 제안합니다.

이 방법은 크게 두단계로 나누어지는데,
먼저 Dynamic Temporal Segmentation으로 비디오를 냅다 고정된 길이로 자르는 것이 아니라 비슷한 연속 프레임끼리 묶어서 segment를 만듭니다. 즉 장면이 거의 안바뀌는 비슷한 연속 프레임들은 같은 segment로 묶고 장면 변화가 큰 곳을 경계로 나눕니다. 이렇게 하면 segment내부에는 중복성이 높아지겠죠! 그럼 결국 pruning하기 좋은 덩어리가 만들어지는 것입니다!
그 후 Density Spatiotemporal Pruning으로 각 segment안에서 모든 토큰을 다 쓰는것이 아니라 토큰을 줄일건데, 먼저 대표성이 높은 토큰(density peak token)을 anchor처럼 고릅니다. 이 방식을 Density-based sampling이라 하는데 여기서 이 density-based라는 말은 주변에 비슷한 토큰이 많으면서도 다른 토큰들과는 충분히 구분이 되는 토큰을 고른다는 말입니다!
조금 더 직관적으로 말하자면 Uniform sampling처럼 격자에서 대충 일정한 간격으로 뽑고 비슷한걸 merge하는 방식이 아니라, 배경처럼 반복되는 영역은 합치고 물체같은 중요한 시각적인 구조를 대표 할만한 토큰을 남기는 방식입니다.
따라서 전체장면이 어떤 구조이고 어떤 배경과 물체가 있는지와 같은 전체적인 시각적 맥락(global visual context)과 주요한 디테일들(salient details)을 보존하면서 토큰을 pruning하는 방식이 됩니다.
저자들은 이 방식을 inference-time으로 pruning을 진행한다고 합니다. training-time이 아닌 inference-time compression으로 진행한 이유는 training-time compression은 모델 구조나 학습 과정 자체에 compression 모듈을 넣는 방식이라 좋은 성능을 내려면 주로 다시 학습 하거나 파인튜닝해서 사용해야 하기 때문에 재학습에 대한 비용적인 단점이 있다고 합니다.
따라서 제안하는 FastVID는 inference-time acceleratio을 목표로 합니다. 이미 잘 학습된 Video LLM을 그대로 두고 입력비디오의 토큰을을 줄여서 빠르게 만드는쪽 입니다. 그렇기 때문에 plug-and-play pruning도 가능하게 됩니다.
2. Method
1. FastVID
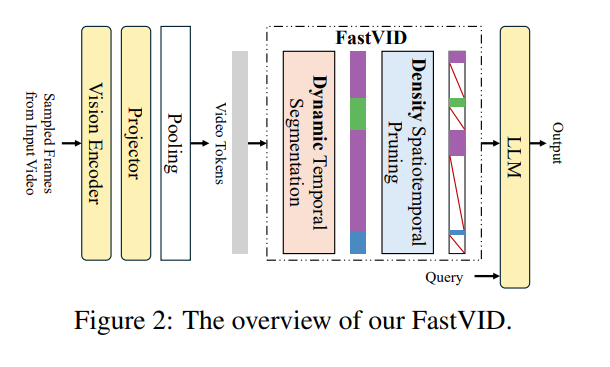
FastVID의 전반적인 파이프라인은 위의 그림과 같습니다
인풋 비디오의 프레임(uniform sampling)이 들어오면 → vision encoder가 feature와 token을 추출하고 → Projector와 Pooling으로 LLM이 처리할 수 있는 video token sequence로 정리한 뒤 → FastVID 단계로 중복 video token을 잘 줄이고 → 잘 줄여진 video 토큰과 query토큰을 같이 LLM이 받아 답변을 생성
FastVID에서는 2단계의 핵심 모듈이 있습니다.
인트로에 간략하게 언급했는데, 먼저 Dynamic Temporal Segmentation으로 이하 DySeg라고 지칭합니다. 두번째로 Density Spatiotemporal Pruning으로 이하 STPrune으로 부릅니다 푸룬주스가 생각나네여 DySeg가 “어디를 묶어서 압축할지”를 정하고, STPrune이 “그 안에서 어떤 token을 남길지”를 정합니다. 아래에서 각 단계를 자세히 살펴보겠습니다.
2. Dynamic Temporal Segmentation
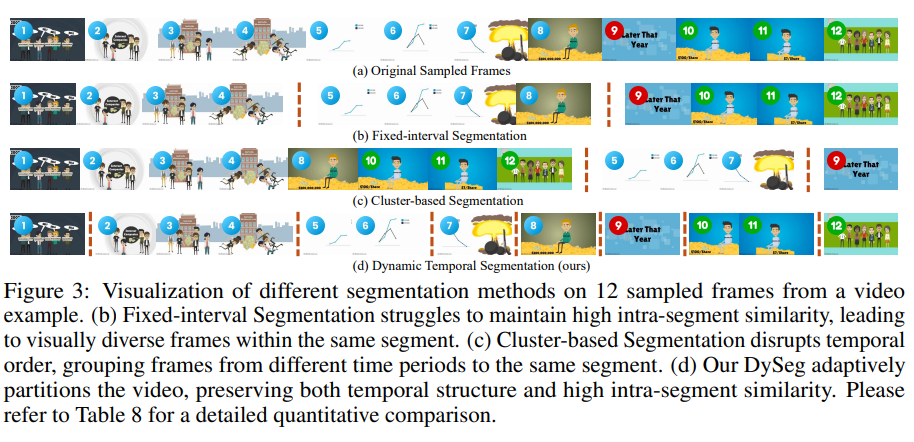
DySeg는 각 프레임을 대표하는 feature vector의 유사도를 기준으로 segment boundary를 정하고 그 boundary에 따라 video token sequnece를 시간순서가 유지되는 segment로 나누는 모듈입니다 결과부터 말하자면 segment 간 시간순서는 유지하고 segment내부에는 비슷하고 중복적인 프레임(토큰)들이 모이게 한다는 것 입니다. 즉 비디오 전체를 아무렇게나 클러스터링 해서 섞는게 아니라 시간 흐름은 보존하면서 비슷한 연속 구간까리 묶어주는 방식입니다.
구체적으로 살펴보자면 DySeg는 adjacent frame 즉 연속된 두 프레임 사이의 유사도(transition similarity, t_i)를 계산합니다. (총 F개의 프레임이 있으면 transition similarity값(t_i) F-1개가 생기겠죠!)
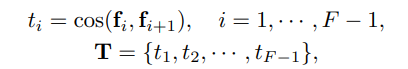
위의 구한 transition similarity(T)로 어디를 segment boundary로 할지를 정해야합니다. 두가지의 기준으로 boundary 후보를 뽑습니다
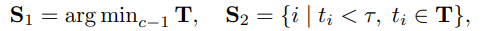
먼저 S1로, 이건 T안에서 가장 작은 유사도를 가진 지점 c-1개를 고릅니다. 쉽게 말하자면 1순위로 무조건 자를 구간인 장면 변화가 가장 큰 지점을 고르는 것 입니다.
여기서 c는 세그먼트 만들 최소 개수로 c개의 세그먼트를 만드려면 boundary는 최소 c-1개가 필요하겠죠. 두번째로는 S2로, transition similarity가 threshold τ보다 낮은곳을 고르는 것 입니다.
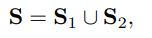
이렇게 고른 후 최종 boundary는 S1과 S2를 합친 지점들이 segment boundary가 됩니다.
이렇게 합집합으로 보는 이유는 예를들어 장면전환이 거의 없는 약간 단순한 비디오에서는 스레시 홀드로 구간을 자르는 S2가 비어있는 경우도 있기 때문입니다. 이때 segmentation이 아예 안되면 프루닝이 애매해지기 때문에 S1로 최소한의 바운더리를 만들어주는 것 입니다. 그럼 반대로 장면전환이 많고 복잡한 비디오에서는 더 세밀하게 나눠주는 역할을 해줄수도 있겠죠!
3. Density Spatiotemporal Pruning
STPrune은 DySeg로 만들어진 각 segment 내부에서 실제로 토큰을 줄이는 모듈로 여기서는 density-based pruning을 진행합니다. 즉 segment내부에 중복되는 토큰을 줄이되 중요한 정보를 담은 토큰은 최대한 남기는 방식으로 진행됩니다.
이때 STPrune은 두 방식으로 토큰을 줄입니다. 먼저 Density-based Token Merging(DTM)로 segment전체의 visual context를 보존하기 위한 방식과 Attention-based Token Selection(ATS)로 중요한 세부 visual detail을 보존하기 위한 방식을 사용합니다.
간단히 말하자면 DTM은 전체적인 장면 구조를 대표하는 토큰을 남기는것에 가깝고 ATS는 눈에 띄는 중요한 디테일 토큰을 남기자는 것에 가깝습니다.
먼저 STPrune의 token budget에 대해 이해해야 합니다. segment하나에 P개의 frame으로 구성되어있고, 프레임 하나당 N개의 토큰으로 구성되어있다면 segment 한개당 전체 토큰수는 PN입니다.
여기서 retention ratio(남길 비율)가 r이면 최종으로 남길 토큰수는 rPN입니다. 이 rPM을 전부 하나의 방식으로 퉁 골라내는게 아니라 DTM과 ATS가 나눠서 담당합니다.
DTM은 drPN개의 토큰을 남기고, ATS는 (1-d)rPN개의 토큰을 남깁니다. (이때 d는 DTM과 ATS사이의 비율 조절값입니다)
[Density-based Token Merging (DTM)]
그럼 DTM은 뭘 하려는 걸까요?
이름 그대로 토큰들중 대표 anchor 토큰을 고르고 나머지 토큰들을 그 anchor에 merge하는 방식 입니다.
여기서 중요한 부분은 anchor를 고르는 방법입니다. DTM은 density peak token을 anchor로 고릅니다. 좀 더 직관적으로 설명하자면 해당 토큰 주변에 비슷한 토큰들이 많이서 대표성이 있고 동시에 다른 대표 토큰과는 거리가 꽤나 있어서 구별성도 있는 토큰을 말합니다. 즉, 해당 장면을 대표하면서도 서로 다른 영역을 잘 커버할 수 있는 토큰을 고른는 것 입니다.

그럼 기존의 Cluster-based merging방식fig4(a)을 보자면, 이 방법은 토큰들을 클러스터로 묶고 각 클러스터 안에서 토큰들을 평균내거나 aggregatio해서 이어붙이는 방식입니다. 문제는 이 과정에서 원래 토큰의 positional information이 뭉개진다는 것 입니다. Video LLM에서는 어느 프레임의 어느 위치에 있던 토큰인지 자체가 의미를 가지기 때문에 토큰의 위치가 중요한데 cluster-based로 합치게 되면 위치정보가 프레임&토큰간에 뒤섞여서 시공간적 구조가 깨질수 있게 됩니다.
fig4(b)의 저자들의 방식인 DTM은 anchor토큰을 고르고 다른 토큰들을 anchor에 merge합니다. 하지만 fig4(a)와 중요한 차이는 anchor토큰의 원래 위치를 유지하는 것입니다. 즉 토큰정보를 합치기는 하지만 최종적으로 남아있는 토큰은 원래 anchor토큰이 있던 위치를 계속 대표하게 되는 것입니다. 이 부분이 나중에 positional encoding을 사용하는 LLM입장에서 토큰의 위치를 구조적으로 덜 망가뜨릴수 있게 되는것입니다. (structural coherence유지)
anchor토큰을 고르기 위해 해당 세그먼트에서 anchor가 되는 프레임들을 먼저 고릅니다. 그 후, 그 anchor프레임 안에서 anchor토큰을 고릅니다. 이때 anchor토큰을 해당 세그먼트 전체에서 막 고르지 않는 이유는 뭘까요? 요기도 좀 중요한 포인트인데 해당 segment 전체에서 anchor토큰을 고르면 한 객체의 다른 부분들이 여러 프레임에 흩어져서 골라질수도 있습니다. 예를들어 사람이 세그먼트 안에서 조금씩 움직이고 있다고 치면, 머리는 1번 프레임에서 몸통은 3번 프레임에서, 배경은 5번프레임에서 anchor로 잡힐수도 있게 됩니다. 이렇게 되면 객체는 조금씩 움직이고 있기 때문에 공간적인 위치가 어그러질수도 있습니다. 따라서 저자들은 anchor토큰을 segment전체에서 무작위로 뽑는 것이 아닌 특정한 anchor프레임들에서만 선택하는 것 입니다. 이때 anchor프레임은 P길이의 segment안에 고정간격 p로 anchor를 샘플링 합니다. (anchor프레임수=[P/p]개) 그럼 해당 segment에서는 drPN/[P/p]개의 토큰이 앵커토큰으로 선택됩니다.
anchor토큰을 고르는 DTM의 과정을 수식으로 살펴보겠습니다.
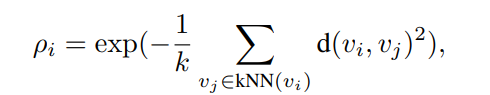
먼저 위의 수식처럼 local density(ρi)를 계산합니다. 여기는 anchor프레임 안의 어떤 토큰(vi)주변에 비슷한 토큰이 얼마나 많은지를 보는 값으로, vj는 vi와 가장 가까운 k개의 이웃 토큰들(vj)을 고르고, 이웃 토큰들과의 feature space에서 두 토큰의 유클리디안거리(d(vi,vj))를 계산합니다. 만약 이 토큰들과의 유클리디안 거리가 작으면 ρi값이 커질것(높은 local density)이고, 거리가 크다면 ρi값이 작아질것(낮은 local density)입니다.
이때 ρi가 높다고 무조건 anchor토큰으로 뽑게되면 넓은 배경영역이나 반복되는 구역저처럼 주변에 비슷한 토큰 많아서 ρi가 높아진건지 진짜 Density라서 높은건지를 알수가 없기 때문에 higher-density token까지의 거리값(δi)도 같이 다룹니다. 즉 다른 도 높은 density토큰과 충분히 떨어져있는지를 함께 고려해주는 것입니다
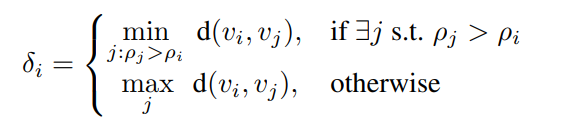
δi는 위의 수식으로 계산이 되는데, 간단히 말하자면 local density가 더 높은 토큰들 중에서 가장 가까운 토큰까지의 거리를 계산한다는 것 입니다.
즉 vi의 입장에서 vi보다 대표성 높은 토큰이 근처에 있는지를 확인하는 것 입니다.
먼저 위쪽 수식(min어쩌구)는 vi보다 density가 더 높은 토큰이 있을 경우인데, ρ가 높은 토큰들 중에서 가장 가까운 토큰과의 거리를 δi로 둡니다. 이때 δi가 작다면 density가 더 높은 토큰이 가까이에 있다는 뜻이고, 그럼 vi가 굳이 anchor가 될 필요가 없다는 말이 됩니다. 만약 δi이 크다면 density가 더 높은 토큰이 멀리 있다는 뜻이고 독립적으로 영역을 대표할 가능성이 있는 토큰이 됩니다.
다음으로 아래쪽 수식(max어쩌구)는 vi보다 density가 높은 토큰이 없는 경우로, 해당 토큰(vi)이 전체에서 density가 가장 높습니다. 따라서 density peak 후보로 무조건 인정이기 때문에 아예 δi를 크게 주기 위해 전체 토큰중 가장 먼 거리값을 넣어줍니다.
그후 ρi x δi로 이 둘을 곱해서 density score를 매겨서 이 점수가 높은 토큰을 token budget에 맞춰 density peak token, 즉 anchor token으로 선택합니다. 다시말해 ρi가 높다는 것은 주변에 비슷한 토큰이 많이서 대표성이 있다는 것이고, δi가 높다는 것은 다른 더 높은 density토큰과 멀리 떨어져 있어 구별성이 있는 토큰임을 말합니다.
이렇게 anchor토큰을 골랐다면 segment안에서 나머지 토큰들을 anchor에 붙여야겠죠! 저자들은 각 토큰을 cosine similarity를 사용하여 의미적으로 가장 가까운 anchor토큰에 할당합니다.
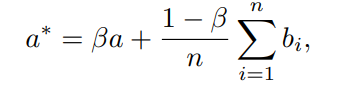
위 수식은 최종 anchor토큰을 수식으로 a는 원래 anchor토큰, bi는 anchor에 할당된 토큰들, n은 할당된 토큰 개수, a∗는 merge후 업뎃 된 anchor토큰, β는 anchor자체와 주변 토큰 평군을 얼마나 섞을지 정하는 비율입니다. 우항의 앞쪽항(βa)은 anchor자체의 정보를 일정비율로 유지하고, 뒷 항으로 주변 토큰들의 정보를 섞어줍니다. 즉 최종 a∗는 anchor토큰의 원래 정보 + 그 anchor가 대표하는 주변 토큰들의 평균 정보를 합친 대표(요약)토큰이 됩니다.
[Attention-based Token Selection (ATS)]
앞에서 다룬 DTM은 anchor토큰을 고르고 주변 토큰들을 그 anchor에 merge해서 segment의 전체적인 visual context를 보존하는 역할을 담당했습니다.
하지만 DTM(대표 anchor+주변토큰 merge)만 쓰게 된다면 작은 물체나 순간적이 디테일이 묻힐 수 있기 때문에 ATS과정을 추가해줍니다. 따라서 ATS는 DTM이 놓칠수 있는 salient visual details(중요한 세부 시각정보)를 추가적으로 보존하기 위한 단계입니다.
ATS를 통해 선택되는 토큰은 merge된 토큰이 아니라 attention score가 높다고 판단된 원래 토큰을 그대로 살려주는 방식입니다.
저자들은 이를 위해 [CLS] attention score를 사용합니다. [CLS] 토큰은 이미지 전체의 이미를 요악하는 역할을 하기 때문에 [CLS]가 어떤 패치토큰에 많이 attention되는지를 보면 해당 토큰이 전체 시각정보를 이해하는데 얼마나 중요한 토큰인지 판단 할수 있습니다.
Video LLM에서 자주 사용하는 SigLIP vision encoder는 보통 마지막 헤드까지 사용하는게 아니라 penultimate layer(마지막 직전 layer)의 피처를 사용합니다. 따라서 [CLS] 토큰이 생성되는 SigLIP 헤드가 생략되어있기 때문에 기본적으로 [CLS] attention score을 바로 얻을수가 없습니다. 저자들은 요 부분을 해결하기 위해 pretrained SigLIP head를 다시 붙여서 [CLS] attention score를 다시 계산할수 있도록 합니다. (이 SigLIP head의 파라미터는 15.2m로 전체 VideoLLM에 비해 가벼워서 추가적인 계산부담은 적다고 합니다.)
구체적으로 어떻게 되는지를 살펴보자면, pretrained SigLIP head에서 각 프레임의 [CLS] attention score map인 A∈R_(H×W)를 얻습니다. (토큰별 어텐션스코어로 H×W는 프레임 토큰의 그리드가 되겠죠!) 마지막으로 각 프레임마다 어텐션 스코어가 가장 높은 top (1−d)rN개의 토큰을 선택합니다.
정리하자면! 최종으로 남겨지는 토큰들은 DTM이 segment 전체의 visual context를 요약해 보존하는 대표 context를 담은 토큰으로 만들고, 이 과정에서 중요하지만 사라질수있는 세부 토큰을 ATS가 어텐션 스코어가 높은 원본 토큰을 골라 salient detail를 보존하는 방식입니다.
4. Experiment
세팅은 다음과 같습니다
- 사용한 모델 : LLaVA-OneVision, LLaVA-Video, Qwen2-VL, Qwen2.5-VL
- 벤치마크 : MVBench, LongVideoBench, MLVU, VideoMME
1. Main Results
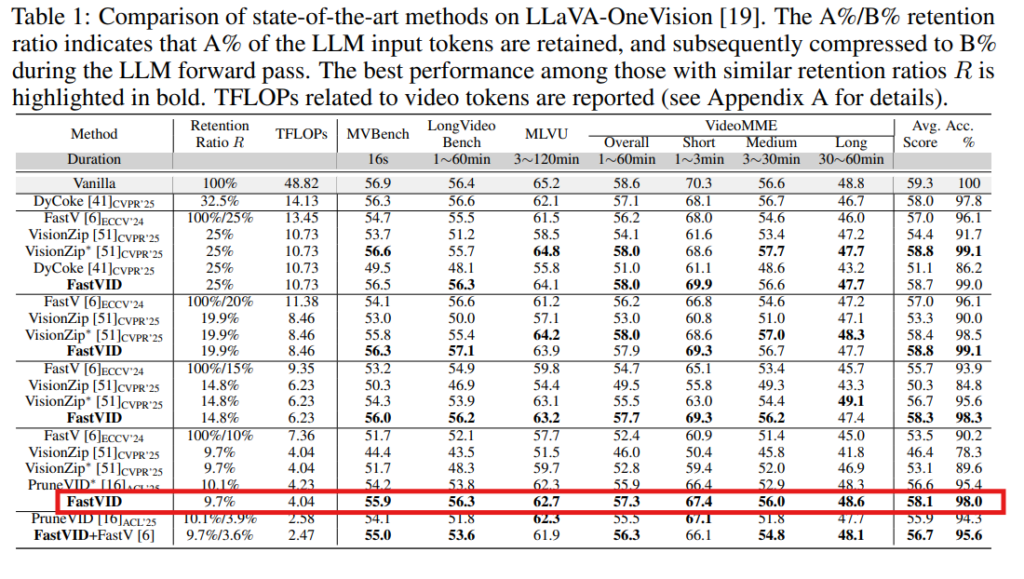
위의 table1은 LLaVA-OneVision결과로 이 논문의 대표 메인 결과입니다. 이 표에서 제일 중요한 부분은 마지막줄인데, FastVID가 토큰을 9.7%만 남김. 즉, 비디오 토큰을 90.3%를 프루닝 한건데 그렇게 과하게 해도 vanilla 성능과 비교해서 평균성능은 59.3 → 58.1로 아주 조금만 떨어지고 의 accuracy도 98.0%가 유지되는 것을 볼 수있습니다. 토큰을 확 줄였으니 TFLOPs는 48.82 → 4.04로 줄어든것도 확인할 수 있습니다.
기존의 방법들과 비교해서 FastV나 VisionZip은 retention ratio(남길 토큰의 비율)가 낮아질수록 성능이 꽤 크게 떨어지는 것을 확인할수 있습니다.
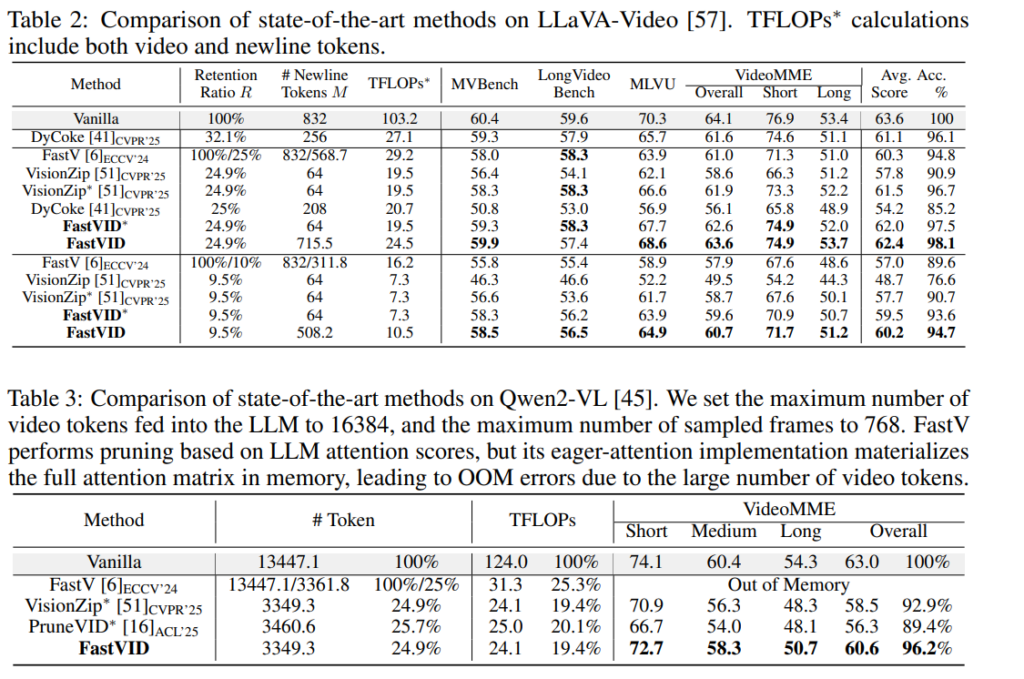
위의 table 2,3은 LLaVA-Video와 Qwen2-VL에서도 FastVID가 잘 작동하는지를 보는 실험결과입니다.
간단히 결과만 설명하자면 table2의 LLaVA-Video에서도 fastVID는 기존의 프루닝 방법들보다 retention ratio을 낮춰도 대체로 높은 성능을 보입니다. table3도 마찬가지로 FastVID는 VisionZip, PruneVID보다 높은 성능보입니다. Vanilla 비교해서도 꽤 유지되는 것을 확인할수 있습니다
2. Efficiency

FastVID가 FLOPs만 줄인 게 아니라 실제로 빨라졌는지를 확인하는 실험으로 LLaVA-OneVision에서 prefill time을 비교한 표입니다. ((VideoMME에서 A100GPU로 실험함)
prefill time은 모델이 첫번째 답변 토큰을 생성하기 전까지 걸리는 시간을 말합니다. 비교하는 두 방법론 모두 토큰수도 비슷하게 줄였고 TFLOPs도 비슷합니다. 하지만 실제로 prefill time은 차이가 꽤 나는것을 확인할수 있습니다.
PruneVID는 클러스터링을 기반으로 segmentation과 compression을 하기 때문에 프레임간 transition similarity로 빠르게 segment를 하는 FastVID와 비교해서 상대적으로 무겁다고 합니다.
즉 비슷한 token budget의 PruneVID보다 빠르면서더 더 높은 정확도를 보입니다.
3. Ablation
[DySeG]
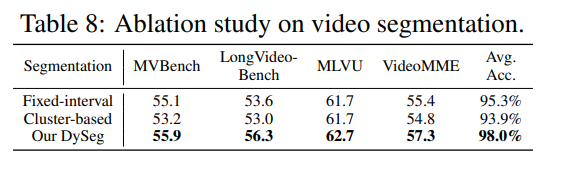
FastVID에서 첫번째 단계인 DySeg가 진짜 필요한지 보는 실험입니다.
Video LLM 토큰 프루닝에서는 temporal structure구조와 segment내부의 유사도를 보존하는게 중요한데, 결과적으로 DySeg는 연속 프레임 간 transition similarity를 이용해 시간 순서를 유지하면서도 유사한 프레임들이 같은 segment에 모이도록 하기때문에 가장 높은 성능을 보이는 것을 알수 있습니다.
[STPurune_DTM&ATS]
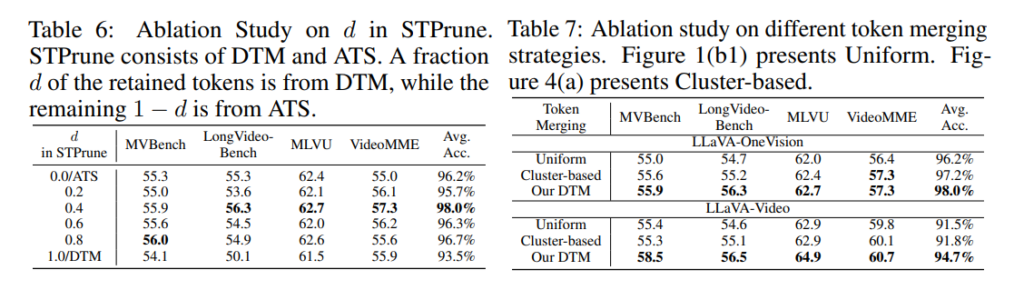
STPrune 내부 설계가 진짜 필요한지 보는 실험입니다.
table 6은 STPrune에서 DTM과 ATS의 비율을 조절한 ablation실험으로, DTM만 사용하는 것보다 ATS만 사용하는게 더 좋은 성능을 보이지만가장 좋은 결과는 두 모듈을 0.4비율로 같이 사용했을때 입니다. 즉 세그먼트 단계의 visual context를 보존하는 DTM과 salient detail을 보존하는 ATS가 서로 보완적인 역할을 한다는것을 알수 있습니다.
table7은 DTM을 다른 token merging 방식과 비교한 실험으로, 결과적으로 DTM이 두 모델에서 가장 좋은것을 볼수있습니다.
안녕하세요 황찬미 연구원님 좋은 리뷰 감사합니다.
DySeg의 boundary를 선정하는 방식이 Fixed-interval 혹은 Cluster-Based보다는 좋지만 비교군이 너무 휴리스틱한 방법들뿐이라 기존에 존재하는 Generic Event Boundary Detection (GEBD) 알고리즘을 활용하는 방법이 더 효율적일 것 같은데 GEBD 방법론과의 비교는 없었는지와 GEBD를 활용하는 것에 대한 찬미님의 의견이 궁금합니다. FastVID의 DTM과 ATS 모두 spatial 축, temporal 축 둘다에 사용되는 것인지 궁금합니다. 그리고 segment boundary를 선정한걸 기준으로 temporal 축은 segment 안에서만 고려되고 boundary 밖은 고려되지 않는 것인지도 궁금합니다.
감사합니다.
안녕하세요 찬미님 좋은 리뷰 감사합니다.
FastVID에서 Dynamic Temporal Segmentation을 먼저 수행하는 이유가 단순히 비슷한 프레임을 묶어서 compression하기 쉽게 만들기 위한 것인지, 아니면 pruning 과정에서 temporal order나 장면 흐름이 깨지는 것을 막기 위한 핵심적인 설계인지 궁금합니다. 제가 이해하기로는 이 논문의 핵심이 “얼마나 많은 token을 줄였는가”보다 “무엇을 보존하면서 줄였는가”에 가까운 것 같은데, 이 부분을 어떻게 해석하면 좋을까요?
감사합니다.